Component Oriented WebAssembly with WIT Interfaces Canonical ABI and Component Linking
1. Foundations of Component Oriented WebAssembly
1.1 WebAssembly Execution Model and Module Versus Component Concepts
WebAssembly has two related ideas that often get mixed together: the execution model and the packaging model. The execution model describes how code runs: a sandboxed instruction set, a linear memory, a value stack, and explicit imports for anything the sandbox needs. The packaging model describes how code is bundled and connected: a module is a single compilation unit with a fixed set of imports and exports, while a component is a higher-level unit that connects through interfaces.
Execution Model Essentials
A WebAssembly program runs inside an engine that provides a few core resources.
- Functions and calls: Calls move values between functions. The engine checks types at call boundaries.
- Linear memory: Memory is a byte array. Code reads and writes it using explicit load/store instructions.
- Tables: Indirect calls use tables of function references.
- Imports and exports: Anything outside the sandbox is accessed through imports; anything inside can be exposed through exports.
A key consequence is that WebAssembly code is intentionally low-level at the boundary. If you export a function that expects a pointer and length, the host must know how to interpret those bytes. That’s fine for tight coupling, but it becomes painful when you want portability across languages and hosts.
Module Packaging and Its Tradeoffs
A module is the classic unit. It declares imports like env.log and exports like add. The boundary is defined by the raw types the module exposes: integers, floats, and memory-related conventions.
Modules are great when:
- You control both sides of the boundary.
- You can agree on data layout conventions.
- You want minimal abstraction overhead.
Modules are awkward when:
- You want to connect independently developed pieces.
- You need consistent data representations across languages.
- You want the host to adapt without rewriting glue code.
A typical module boundary might look like this in concept: a guest function returns a pointer to a UTF-8 string stored in linear memory, and the host must read bytes until a terminator or use a length parameter. That convention is not enforced by the module type system; it’s enforced by documentation and discipline.
Component Packaging and Interface Driven Boundaries
A component wraps one or more modules behind an interface. Instead of exporting raw pointers and lengths as the primary contract, a component can export functions whose signatures are described in terms of WIT types like string, list<u8>, record, variant, option, and result.
The important shift is this: the component boundary is described at the interface level, and the runtime can apply the correct conversions. That means the host does not need to know the guest’s internal memory layout to pass a string or receive a structured record.
In practice, a component still runs on the same execution model underneath, but the boundary becomes more declarative. The engine (or tooling) can generate the glue that maps interface-level values to the lower-level representation expected by the underlying module.
Mind Map: Execution Model and Packaging
Example: Same Computation, Different Boundary Contracts
Consider a function that takes a text input and returns a structured response.
Module-style contract (convention heavy):
- Export
process(ptr: i32, len: i32) -> i32. - The returned
i32is a pointer to a serialized response in linear memory. - The host must know the serialization format and how to free memory.
Component-style contract (interface explicit):
- Export
process(input: string) -> result<record{message: string}, error>. - The host passes a
stringvalue without caring where bytes live. - The runtime handles conversion to the underlying module’s representation.
The computation is the same; the difference is where the complexity lives. Modules push it to the boundary glue. Components move it into standardized interface conversions.
Diagram: How Values Flow Across Boundaries
flowchart LR
A[Host] -->|Calls boundary| B[Component Interface]
B -->|Canonical conversions| C[Underlying Module]
C -->|Reads/writes| D[Linear Memory]
D --> C
C -->|Returns raw values| B
B -->|Converts to interface types| A
Practical Takeaway
When you choose modules, you’re choosing a boundary that is mostly about how values are represented. When you choose components, you’re choosing a boundary that is mostly about what values mean. Both rely on the same execution model, but components make the meaning explicit enough that different hosts and languages can connect without everyone agreeing on the same pointer-and-length folklore.
1.2 Why Components Enable Interface Driven Portability
Portability is usually blocked by two things: assumptions about data layout and assumptions about how code is called. Components help because they separate “what a program needs” from “how a program is built,” and they make the boundary explicit. Instead of treating a WebAssembly module as a blob that happens to run, you treat it as a unit that can be linked to other units through a declared interface.
The Core Idea: Stable Contracts at the Boundary
A component boundary is a contract with names and types. When you define a WIT interface, you describe the shapes of values that cross the boundary—functions, records, variants, lists, and error results. The key portability win is that the contract is not tied to one language’s calling conventions or one runtime’s internal representation.
Without components, you often end up with “tribal knowledge” like “strings are null-terminated UTF-8 in linear memory” or “this function expects a pointer plus length but the allocator is shared.” Those assumptions rarely survive moving to a different language or host. With components, the interface contract is the place where those assumptions live, and the canonical ABI defines how they are translated.
Mind Map: What “Interface Driven Portability” Means
From “Works on My Machine” to “Links Anywhere”
Consider a simple service: get_user(id) -> user. If you ship it as a raw module, the host must guess how id and user are represented. Maybe user is a pointer to a struct, maybe it’s two integers, maybe it’s a memory region that must be freed by the guest. Each guess becomes a portability bug.
With a component, the interface says what id is and what user looks like. The canonical ABI then specifies how a string or list is passed. The host can link the component without understanding the guest’s internal memory strategy, because the boundary translation handles it.
Concrete Example: Swapping Implementations
Imagine two implementations of the same interface: one in Rust, one in C. Both expose the same WIT world.
- The Rust version might naturally use owned
Stringvalues. - The C version might naturally use
char*and lengths.
Neither language’s natural representation is required to match the other. The interface contract plus canonical ABI rules define the shared meaning. The generated bindings provide the glue so the host calls both implementations the same way.
What Changes in Practice
- You stop exporting “memory tricks.” Instead, you export functions that accept and return interface types.
- You stop relying on shared conventions. The canonical ABI defines conversions for common shapes like strings, lists, and variants.
- You can test at the contract level. If the interface says
Result<user, error>, you can validate behavior without caring whether the guest uses exceptions, error codes, or panics internally.
The Boundary Is Where Portability Lives
Portability is not “no differences ever.” It’s “differences are contained.” Components contain differences by forcing every cross-boundary value to pass through a well-defined translation layer. That layer is what makes it reasonable to link the same component interface across languages and operating environments without rewriting the host each time.
A Small Rule of Thumb
If you can describe your integration problem as “the host and guest disagree about how values are represented,” you’re already thinking in component terms. The interface contract and canonical ABI are the tools that turn that disagreement into a deterministic conversion instead of a late-night debugging session.
1.3 Runtime Boundaries and Data Movement Costs
A component boundary is where two worlds meet: one side produces values in its native representation, and the other side consumes them in a representation it understands. In WebAssembly components, the “native” side is typically the guest’s language runtime view, while the “understood” side is the host’s view enforced by the WIT contract and the canonical ABI rules. The boundary is not just a call boundary; it is a conversion boundary.
What Counts as Boundary Work
Every cross-boundary call has three kinds of work:
- Marshaling: converting arguments from the caller’s representation into the callee’s expected representation.
- Memory mediation: ensuring that pointers, buffers, and strings refer to valid memory on the receiving side.
- Unmarshaling: converting return values back into the caller’s representation.
Even when the interface uses simple types, the canonical ABI may still perform conversions. For example, a string is not just “bytes”; it is a length plus an encoding expectation, and the receiving side must reconstruct a usable string view.
The Cost Model You Can Actually Reason About
Data movement costs usually come from two sources: copies and allocation.
- Copies happen when the receiving side cannot directly use the sender’s memory layout or lifetime.
- Allocation happens when the receiving side needs a new buffer to hold converted data, or when it must build a structured value (like a record or variant) from a flattened canonical form.
A useful rule of thumb: the more the interface shape forces ownership transfer or encoding conversion, the more likely you’ll see copies. The more the interface uses borrowed views with clear lifetimes, the more likely the runtime can avoid unnecessary work.
Mind Map: Boundary Costs
Concrete Example: String Arguments
Consider an interface function that takes a string and returns a u32 checksum.
- The caller has a string in its language runtime format.
- The canonical ABI must present the callee with a canonical representation: typically a pointer plus a length, with a defined encoding.
- If the caller’s string memory is already in the expected encoding and contiguous layout, the runtime may pass a view. If not, it must create a temporary buffer.
On the return path, the u32 is straightforward: no buffer mediation is needed. The interesting part is that the cost is dominated by the string conversion, not by the arithmetic.
Concrete Example: Buffer Parameters and Ownership
Now imagine an interface that processes a byte buffer:
- The caller passes a
list<u8>or abuffer-like shape. - The callee needs a contiguous region of bytes for processing.
- If the caller’s bytes are already contiguous and stable for the duration of the call, the runtime can often pass a view.
- If the caller’s representation is segmented or its lifetime is shorter than the callee requires, the runtime must copy into a temporary contiguous buffer.
The key detail is lifetime: “valid during the call” is different from “valid after the call.” If the interface design requires the callee to keep data beyond the call, then ownership must be explicit, and copying becomes the safe default.
Why Interface Shape Changes the Bill
Two interfaces can express the same logical operation but differ in cost:
- Many small fields: each field may trigger its own conversion and reconstruction steps.
- One bulk payload: a single buffer can be converted once, then parsed inside the callee.
This is not about making everything a blob. It’s about choosing shapes that match how data is naturally produced and consumed. If your data is already a byte array, a buffer-oriented interface avoids repeated stringification and re-parsing.
Practical Guidance for Keeping Costs Predictable
- Treat strings as potentially expensive: they often require encoding and temporary storage.
- Treat buffers as controllable: you can often design for “view during call” versus “owned after call.”
- Batch when it matches the workload: reduce call count when you repeatedly cross boundaries with small payloads.
- Model errors as data, not control flow: returning a
resultkeeps the boundary behavior explicit and keeps conversions localized to the error payload.
A boundary is where correctness is enforced through conversion. If you design interfaces so that conversions are rare and predictable, the runtime does less work and your performance becomes easier to explain.
1.4 Practical Mental Model for Linking Components with Interfaces
Think of component linking as a three-step handshake: names, shapes, and lifetimes. If you keep those three in your head, most “linking failed” errors become understandable instead of mysterious.
The Three-Step Handshake
Names answer: “Which thing are we connecting to which?” In WIT terms, that means the package, interface, and function names must line up between the world you import and the world you export. A mismatch here fails fast, because the linker can’t even decide what to wire.
Shapes answer: “Do the inputs and outputs match in representation?” This is where the canonical ABI matters. Even when two languages both say “string,” the boundary needs a precise contract for how that string is passed, how memory is described, and who owns what.
Lifetimes answer: “How long is the data valid, and who is responsible for releasing it?” Canonical ABI conversions often involve temporary buffers or handles. If you assume the wrong lifetime, you get bugs that look like random corruption.
A Mental Model You Can Use While Debugging
When linking fails, don’t start by rereading the whole interface. Instead, walk the handshake in order:
- Confirm the target: Are you linking the correct component to the correct world? If the world import list doesn’t match what the component exports, you’ll see errors that mention missing imports or unresolved exports.
- Confirm the signature: For each function, check parameter and result types. If a function takes a
list<u8>but the other side expects astring, the linker may accept the name but the canonical ABI mapping will not behave as you intended. - Confirm the ownership story: For strings and buffers, ask whether the callee expects the caller to keep memory alive, or whether the boundary copies into a temporary representation.
A useful rule: if the interface uses strings or lists, treat it as a data transfer boundary, not a shared-memory boundary.
Mind Map: Linking Components with Interfaces
Example: A Tiny Service Contract
Imagine an interface with one function:
process(input: string) -> result: string
A practical mental model says:
- The caller passes a string value into the boundary.
- The canonical ABI converts that string into a representation the callee understands.
- The callee returns a string, which is converted back for the caller.
Best practice: keep the contract simple and make the data flow explicit. If you need large data, prefer list<u8> with a clear “input is bytes, output is bytes” story rather than mixing “text” and “binary” semantics.
Example: Where Shapes Break Quietly
Suppose you change the interface from:
process(input: string) -> string
to:
process(input: list<u8>) -> list<u8>
Even if both are “text-ish,” the canonical ABI conversion rules differ. The linker might still connect the function if names match, but your runtime behavior changes because the boundary no longer performs the same encoding expectations. The mental model helps: shapes changed, so the boundary conversion changed.
Example: Lifetimes and Buffer Handling
Consider an interface that returns a buffer:
get_chunk(index: u32) -> chunk: list<u8>
The safe assumption is: the returned list is valid for the caller to consume immediately, and the boundary handles the necessary conversion. If you try to treat the returned bytes as if they were a direct view into the callee’s memory, you’re fighting the model. Instead, copy into your own storage if you need to keep it longer.
Putting It Together: A One-Page Checklist
Before you link, verify:
- Names: world and function identifiers match.
- Shapes: parameter and result types match exactly, including whether something is a string versus a list.
- Lifetimes: you never assume shared memory across the boundary; you treat transferred data as owned by the side that receives it.
If you follow this order, linking becomes a predictable engineering task rather than a guessing game.
1.5 Minimal End-to-End Example From Interface to Instantiation
A minimal end-to-end example answers one question: given a WIT interface, how do we go from “shape” to a running instance with correct data passing? We’ll keep the interface tiny, but we’ll still respect the boundary rules that matter.
Mind Map: Interface to Instantiation Flow
Step 1: Define a Tiny WIT Interface
We’ll define a world with one exported function. The function takes a string and returns a string. This is small enough to see the whole pipeline, but it still exercises canonical ABI string handling.
package demo:[email protected]
world string-echo {
export echo: func(input: string) -> string
}
Best practice: keep the interface “boring.” If you can’t explain what the string represents (UTF-8 text, bytes, or something else), you’ll eventually debug that mismatch at the boundary.
Step 2: Implement the Guest Export
In the guest, implement echo as a normal function. The key point is that the runtime will handle canonical lowering and lifting around the exported function.
// guest/src/lib.rs
use std::string::String;
// Pseudocode: generated bindings will adapt canonical ABI to this signature.
pub fn echo(input: String) -> String {
// Minimal behavior: return the same text.
input
}
Best practice: treat the guest function signature as the “logical” contract. The canonical ABI details belong to the generated glue, not to your business logic.
Step 3: Implement the Host Import Side
Even if the host is only instantiating and calling, it still needs a binding that matches the world’s interface. The host will call the guest’s exported function through generated stubs.
// host/src/main.rs
// Pseudocode: generated bindings provide a typed handle.
fn main() {
let mut linker = /* create linker */;
// Link the guest component into the world.
let instance = /* instantiate component */;
let out = instance.echo("hello from host".to_string());
assert_eq!(out, "hello from host");
}
Best practice: make the host call a single function with a single input. If that works, you’ve validated the interface shape, the ABI mapping, and the linking wiring.
Step 4: Understand Canonical ABI for Strings
For string, the canonical ABI typically represents the value as a pointer plus length in linear memory, with an agreed encoding (commonly UTF-8). When the host calls echo, the runtime:
- Lowers the host string into the guest memory representation.
- Calls the guest export with the lowered arguments.
- Lifts the returned guest string back into a host string.
Ownership matters. The guest must not assume it can keep using the input after the call unless the runtime’s conventions guarantee it. Similarly, the returned string must be produced in a way the runtime can lift safely.
Step 5: Link and Instantiate
Linking resolves the world’s exported function by name and signature. If the guest exports echo but with a mismatched signature, instantiation fails early. That’s good: it prevents “it runs but the bytes are wrong” scenarios.
A practical checklist for this minimal case:
- The world name matches exactly:
string-echo. - The function name matches exactly:
echo. - The parameter and result types match exactly:
string -> string. - The component you instantiate actually provides the export.
Step 6: Run the End-to-End Test
Use one input that contains plain ASCII, then one that contains non-ASCII characters. Non-ASCII catches encoding mistakes that ASCII won’t.
fn smoke_test(instance: &mut impl /* generated interface */) {
let a = instance.echo("abc".to_string());
assert_eq!(a, "abc");
let b = instance.echo("café".to_string());
assert_eq!(b, "café");
}
If both assertions pass, you’ve validated the full path: interface authoring, canonical ABI lowering and lifting for strings, component linking, and instantiation wiring.
Mind Map: What Can Break and How to Spot It
This minimal example is intentionally small, but it exercises the same core mechanics you’ll rely on for larger interfaces: stable shapes, correct ABI mapping, and linking that fails loudly when contracts don’t match.
2. WIT Interface Authoring and Interface Design Patterns
2.1 WIT Syntax and Core Constructs for Packages Interfaces and Worlds
WIT is the interface description language used to define what a component expects and what it provides. The core idea is simple: you write contracts in a language-agnostic way, then tooling generates bindings and the canonical ABI handles the messy parts of data representation.
Packages as Namespaces for Contracts
A WIT package groups related interface definitions so they can be imported by name. Think of a package as the “module folder” for interface contracts. Packages also carry versioning metadata in many toolchains, which helps keep builds reproducible.
A typical package structure is:
- A package name and optional namespace
- One or more interface definitions
- One or more world definitions that compose those interfaces
Best practice: keep packages small and cohesive. If a package contains unrelated contracts, you’ll end up importing more than you need and making compatibility checks harder.
Interfaces as Typed Sets of Imports and Exports
An interface defines a set of functions and types. When a component implements an interface, it provides those functions. When a component consumes an interface, it imports those functions.
WIT interfaces are written in terms of:
- Function signatures with parameter and result types
- Type definitions such as records, variants, lists, and options
- Conventions for errors using result-like patterns
Best practice: design interface shapes that are easy to map across languages. For example, prefer clear record fields over deeply nested anonymous structures, and use explicit error results rather than relying on language-specific exceptions.
Worlds as Composition Units
A world ties multiple interfaces together into a single “bundle” of imports and exports. A world is what you link against: it describes which interfaces the host must provide and which interfaces the guest must implement.
A world typically includes:
- Imported interfaces that the component expects from its environment
- Exported interfaces that the component offers to its environment
Best practice: keep world boundaries aligned with runtime responsibilities. If your world mixes unrelated capabilities, you’ll force every consumer to wire everything even when they only need one part.
Mind Map: Core Constructs and Their Relationships
WIT Core Constructs Mind Map
Example: Minimal Package with One Interface and One World
Below is a compact WIT sketch showing how the pieces fit. The exact syntax can vary slightly by tooling, but the structure is consistent: package → interface → world.
package example:math
interface calculator {
add: func(a: u32, b: u32) -> u32
}
world calc-world {
export calculator
}
This world exports the calculator interface. A host that links to calc-world will expect the component to provide an add function with the specified signature.
Example: World with Both Imports and Exports
Now the world consumes an interface from the host and exports another interface. This is common for adapters and services.
package example:service
interface clock {
now: func() -> u64
}
interface greeter {
greet: func(name: string) -> string
}
world greeter-world {
import clock
export greeter
}
A component implementing greeter-world must:
- Call the host’s
clock.nowwhen it needs time - Provide
greeter.greetto produce a greeting
Practical Rules That Prevent Confusing Contracts
- Name things consistently: interface names should describe capability, not implementation detail.
- Keep signatures explicit: avoid implicit conversions; make types match what you intend to transfer.
- Model errors in the type system: use result-style returns so every caller can handle failure paths.
- Treat worlds as wiring diagrams: if a world exports multiple unrelated interfaces, consider splitting it so consumers can link only what they need.
Mind Map: Designing Interfaces for Linking
Interface Design Mind Map
Summary of the Flow
Write a package to group contracts, define interfaces to specify typed functions and data, and compose those interfaces into worlds that describe import and export wiring. Once that structure is in place, the rest of the system can generate bindings and apply the canonical ABI rules without guessing what you meant.
2.2 Designing Imports and Exports with Stable Names and Shapes
Stable names and stable shapes are what make component linking boring—in the best way. “Name” answers which thing you mean. “Shape” answers what data form you mean. If either changes, linking may fail or, worse, succeed while doing the wrong thing.
The Two Stability Contracts
Stable names mean that the identifiers in your WIT interface remain consistent across versions. For imports, the host must find the exact names the component expects. For exports, other components or hosts must find the exact names the interface promises.
Stable shapes mean that the types and their structure remain consistent: function signatures, record fields, variant cases, list element types, and the way strings and buffers are represented at the boundary.
A practical rule: treat the WIT file as an API contract, not as an implementation detail. The canonical ABI handles representation, but it cannot guess your intent if your types change.
Designing Exports First, Then Imports
Start with exports because they describe what you provide. Then define imports that match how you want to consume dependencies.
For example, suppose you want a component that turns input text into a normalized form. Export a function that takes a string and returns a string. If you later decide you also need a configuration record, add a new function or a new parameter only if you can keep the existing one unchanged.
When you define an import, you’re writing a promise to the component author: “If you call this import, the host will provide it with this exact signature.” That means your import signatures should be narrow and explicit, not “convenient” abstractions that hide important type decisions.
Naming Conventions That Survive Refactors
Use names that are stable under refactoring of internal code. A good pattern is to name functions by behavior, not by implementation detail.
- Prefer
normalize_textovernormalize_utf8_bytes. - Prefer
get_user_profileoverfetch_row_42. - Keep module and interface names consistent across packages.
Also decide early whether you will use a single world with multiple interfaces or multiple worlds. Either works, but mixing patterns makes it harder to reason about linking errors.
Shape Discipline for Functions
A function’s shape includes:
- Parameter types and their nesting (records inside lists, variants inside records, etc.).
- Return type, including whether errors are modeled as
result. - Whether you pass strings and buffers as values or as structured records.
A common best practice is to model errors explicitly with result<T, E> rather than encoding error states in strings. That keeps the canonical ABI mapping predictable and makes it easier to test round trips.
Shape Discipline for Data Types
For records, keep field names stable and avoid reordering fields as a “cleanup.” Even if the canonical ABI can map records deterministically, your interface consumers rely on the declared structure.
For variants, treat case names as part of the contract. If you rename a case, you’ve changed the shape.
For lists, keep the element type stable. A list of u8 is not the same shape as a list of string, even if both “look like bytes” in your head.
Mind Map: Stability Checklist
Example: A Small Interface with Clear Boundaries
Imagine a component that offers normalization and consumes a logger.
- Export:
normalize_text(input: string) -> result<string, normalize-error> - Import:
log(level: string, message: string) -> result<(), log-error>
The stable name is normalize_text and log. The stable shape is that both accept strings and return result with explicit error types.
If you later change log to accept a record { level, message }, you changed the shape. That means the component that imports log must be updated, and any host that provides log must be updated too.
Example: Shape Changes That Break Linking
Here are three changes that typically cause incompatibility:
- Renaming a function:
normalize_text→normalize. - Changing a record field type:
timeout_ms: u32→timeout_ms: u64. - Changing error modeling:
result<T, E>→Twith error encoded in a string.
Each change alters either the name contract or the shape contract, so linking either fails or produces mismatched expectations.
Example: A Safe Extension Pattern
If you need extra configuration later, add a new export rather than modifying the old one.
- Keep
normalize_text(input: string) -> result<string, normalize-error>. - Add
normalize_text_with_options(input: string, options: normalize-options) -> result<string, normalize-error>.
This preserves existing consumers and keeps the canonical ABI mapping stable for the original function.
Practical Rules for Authors
- Treat every identifier in WIT as part of the public API.
- Treat every type constructor and nesting level as part of the shape.
- Prefer explicit error types over ad hoc string conventions.
- Extend by adding new functions or new interfaces, not by rewriting existing ones.
When you follow these rules, linking becomes a mechanical check rather than a guessing game. That’s the goal: make the boundary predictable so the implementation can stay flexible.
2.3 Choosing Between Functions Records Variants and Lists
WIT types look simple until you cross a boundary. Then the choice of shape determines how much work the canonical ABI must do: how many conversions happen, how much copying occurs, and how clearly errors are represented. A good rule is to pick the smallest interface shape that still communicates intent.
Mind Map: Type Shape Selection
Functions: Behavior with Tight Contracts
A WIT function is the unit of interaction. Choose it when you need an operation, not a data container. The best practice is to keep the signature “boringly explicit”: pass only what the callee needs, and return either a value or a structured result.
Example: a calculator service that returns either a number or an error.
package calc:example
interface math {
// Input is simple; output is structured.
add: func(a: u32, b: u32) -> result<u32, string>
}
Why this shape works: result is a variant-like contract with a clear success/failure split, and the function boundary stays easy to map in every language.
Records: Structured Data with Named Fields
Use records when the data has multiple fields that always travel together. Records communicate meaning through names, not through positional guessing. That matters across languages where “field 2 is the length” is a great way to create bugs.
Example: a request that always includes an id, a payload, and a timeout.
package kv:example
interface store {
get: func(req: record {
id: string,
timeout_ms: u32,
key: string,
}) -> result<record { value: string }, string>
}
Records also help the canonical ABI: it can lower and lift each field deterministically. If you find yourself using a record just to group unrelated values, consider splitting into multiple parameters or separate functions.
Variants: Mutually Exclusive Cases with Tags
Variants represent exactly one of several cases. Use them when the meaning changes based on the case, such as “not found” versus “found” versus “permission denied.” Variants are also the cleanest way to model errors without forcing every caller to parse strings.
Example: a lookup that distinguishes outcomes.
package kv:example
interface store {
lookup: func(key: string) -> variant {
found: record { value: string },
not-found,
denied: record { reason: string },
}
}
A practical guideline: keep variant cases mutually exclusive and avoid “catch-all” cases that hide real distinctions. When you do need a generic case, make it a last resort and include enough data to be actionable.
Lists: Variable Length Collections with Predictable Elements
Use lists when you truly have variable-length data. Lists are where boundary costs often show up: the runtime must represent a sequence, and element conversion happens for every item.
Example: returning a list of keys.
package kv:example
interface store {
list-keys: func(prefix: string) -> list<string>
}
If your list elements are complex, consider whether a record or variant would be clearer. For instance, a list of records is fine when every element has the same shape. A list of variants is fine when each element can be in different states, but it increases conversion work because each element carries a tag.
Integrated Decision Workflow
- Start with the question: is this interaction behavior or data? If behavior, use a function.
- If it’s data with named fields that always appear together, use a record.
- If it’s data where only one case applies at a time, use a variant.
- If it’s data with a variable number of elements, use a list.
- When in doubt, prefer the shape that makes invalid states unrepresentable.
Common Combinations That Stay Understandable
- Function returns
result<T, E>for success versus failure. - Function returns a variant for multiple non-error outcomes.
- Function takes a record for request context and returns a record for response data.
- Function returns a list of records when you need multiple items with the same schema.
The canonical ABI will do its job either way, but your interface shape determines how much effort it must spend translating intent into bytes. Choosing the right container types keeps both the contract and the implementation readable, even when the boundary is doing the heavy lifting.
2.4 Error Modeling with Result and Option Patterns
Error modeling in WIT is mostly about making failure explicit and predictable. Two common shapes do the job: option for “may be absent,” and result for “may fail.” The trick is choosing which one matches the meaning of the boundary.
Option Versus Result
Use option<T> when the caller should treat absence as a normal outcome. Typical examples include lookups that may not find a record, or parsing that returns “no value” without claiming something went wrong.
Use result<T, E> when there is a meaningful failure mode that the caller should handle differently. Examples include invalid input, permission problems, or internal errors.
A good rule: if the caller can continue with a reasonable fallback when the value is missing, option fits. If the caller must branch on the reason for failure, result fits.
Mind Map: Choosing Between Option and Result
Modeling Absence with Option
Consider a component that reads a user profile by id. If the id is unknown, that’s not an error; it’s just “no profile.”
WIT-style interface idea:
get-profile(id: u64) -> option<profile>
Caller logic should be straightforward:
- If
Some(profile), proceed. - If
None, return a 404-like response or ask for a different id.
Best practice: keep option payloads small and stable. If the profile is large, consider returning a handle or a smaller summary, then add a separate call for details.
Modeling Failure with Result
Now suppose the component also validates that the caller is allowed to access the profile. If authorization fails, that’s a failure with a reason.
WIT-style interface idea:
get-profile-checked(id: u64, token: string) -> result<profile, error>
Define error as a record or variant-like structure that the caller can pattern match. The key is to make error cases actionable without forcing the caller to guess.
A practical error shape:
errorincludes acodeand amessage.codeis stable across versions.messageis for human readability, not program logic.
Mind Map: Designing the Error Type
Example: Two Endpoints with Consistent Semantics
Imagine a component that supports both “lookup” and “enforced access.” The difference is semantic, so the types should reflect it.
lookup-profile(id: u64) -> option<profile>get-profile(id: u64, token: string) -> result<profile, profile-error>
This avoids a common mistake: returning Err(NotFound) from result when the caller could have handled absence as a normal branch. It also avoids the opposite mistake: returning None when the caller needs to know why access failed.
Example: Error Codes and Data
Here is a compact WIT-like sketch of an error record. The exact syntax depends on your tooling, but the modeling idea stays the same.
interface profile-service {
get-profile: func(id: u64, token: string)
-> result<profile, profile-error>;
}
record profile-error {
code: u32,
message: string,
field: option<string>,
}
The field is optional because not every error is about a specific input field. That keeps the error type uniform while still letting callers extract useful context.
Advanced Detail: Avoiding Ambiguous Contracts
Ambiguity usually comes from mixing absence and failure. If a function can return both “not found” and “internal error,” decide whether “not found” is expected absence (option) or a failure (result). Consistency matters more than purity.
Another subtlety is error granularity. If you expose too many error variants, callers end up treating most cases the same. If you expose too few, callers lose the ability to react correctly. A balanced approach is to group errors by how callers should respond: retry, ask for different input, or deny.
Finally, keep error values deterministic. If the same input leads to the same error code, callers can test behavior reliably. Messages can vary, but codes should not.
Mind Map: Caller Handling Patterns
With these patterns, your component contracts stay readable: absence is represented as absence, and failure is represented as failure. The caller’s branching logic becomes obvious from the type alone, which is exactly what you want at the boundary.
2.5 Practical Interface Design Walkthrough for a Small Service
Imagine a small service that turns text into a normalized form and optionally returns a list of detected issues. We’ll design a WIT interface that stays stable across languages, keeps error handling explicit, and makes the canonical ABI conversions predictable.
Step 1: Write the Service Contract in Plain Language
The service has one operation:
- Input: a UTF-8 string
text. - Output: a normalized string
normalized. - Optional:
issuesas a list of strings when the caller asks for them. - Errors: invalid input (for example, empty string) and internal failures.
Best practice: decide early which parts are always returned and which are conditional. Conditional outputs are fine, but they should be represented with option or a separate result variant so callers don’t guess.
Step 2: Choose the WIT Shapes That Match the Contract
We’ll model:
normalizedas astring.issuesaslist<string>wrapped inoption.- Errors as a
result<NormalizedResponse, ServiceError>.
This makes the canonical ABI story straightforward: strings and lists are well-defined, and result gives you a single return channel for success versus failure.
Step 3: Define the WIT interface
Below is a compact WIT sketch. It uses stable names and keeps the exported function signature simple.
package text.normalize:1.0.0;
type ServiceError = variant {
EmptyInput,
InternalError,
};
type NormalizeResponse = record {
normalized: string,
issues: option<list<string>>,
};
interface text-normalizer {
normalize: func(
text: string,
include-issues: bool
) -> result<NormalizeResponse, ServiceError>;
}
Best practice: keep the interface surface area small. If you later add fields, prefer extending the response record rather than changing the function signature.
Step 4: Make the Boundary Behavior Explicit
Canonical ABI will convert string and list<string> across the boundary. To avoid surprises:
- Specify that
textis UTF-8. - Specify that
normalizedis also UTF-8. - Specify that
issuesisnonewheninclude-issuesis false.
A common mistake is returning an empty list instead of none. That forces callers to interpret meaning from content. Using option makes intent unambiguous.
Step 5: Implement the Logic Behind the Interface
The implementation should be deterministic and should not leak internal error details. For example:
- If
textis empty, returnEmptyInput. - Otherwise, normalize by trimming whitespace and converting to lowercase.
- If
include-issuesis true, return issues such as “contains digits” or “contains multiple spaces”.
Here’s a language-agnostic pseudocode sketch.
function normalize(text, includeIssues):
if text == "":
return Err(EmptyInput)
normalized = trim(text)
normalized = lowercase(normalized)
if not includeIssues:
return Ok({ normalized, issues: None })
issues = []
if containsDigits(text):
issues.push("contains digits")
if hasMultipleSpaces(text):
issues.push("contains multiple spaces")
return Ok({ normalized, issues: Some(issues) })
Best practice: compute issues from the original input, not the normalized output, so the caller can understand what triggered the flags.
Step 6: Provide Concrete Examples for Callers
Example inputs and outputs help prevent interface drift.
Example: include-issues false
- Input:
text = " HeLLo ",include-issues = false - Output:
Ok({ normalized: "hello", issues: None })
Example: include-issues true
- Input:
text = "A1 B",include-issues = true - Output:
Ok({ normalized: "a1 b", issues: Some(["contains digits", "contains multiple spaces"]) })
Example: empty input
- Input:
text = "",include-issues = true - Output:
Err(EmptyInput)
Step 7: Mind Map the Design Decisions
Mind Map: Text Normalizer Interface Design
Step 8: Sanity Checks Before You Lock the Interface
- Can a caller distinguish “no issues requested” from “requested but none found”? With
option, yes. - Can a caller handle errors without inspecting strings? With
resultandvariant, yes. - Are all types boundary-friendly?
string,bool,record,option,list,result, andvariantare exactly the set you want for predictable canonical ABI conversions.
That’s the whole walkthrough: start from behavior, map it to stable WIT shapes, make boundary semantics explicit, and test with a few concrete examples so the interface stays boring in the best way.
3. Canonical ABI Fundamentals for Data Representation
3.1 What the Canonical ABI Does and Where It Applies
Canonical ABI is the “translation layer” between a component’s interface types and the low-level calling convention used by the WebAssembly engine. It exists because interface types are language-friendly and structured, while the runtime needs a predictable, engine-friendly representation.
At a high level, the canonical ABI performs two complementary jobs:
- Lowering: converting values produced by the caller into the representation expected by the callee.
- Lifting: converting values returned by the callee into the representation expected by the caller.
This translation is not optional when you cross the boundary defined by a WIT interface. If both sides agree on the same interface types, the canonical ABI ensures they still agree on how those types are represented at runtime.
Where It Applies
Canonical ABI applies at the boundary between:
- A component host and a component when the host calls an exported function or handles an imported one.
- Two components when one component imports a function from another through a WIT-defined interface.
- Generated bindings and the runtime when bindings call into component exports or implement component imports.
It does not replace the normal ABI inside a single compiled module. Inside a module, the compiler uses its own calling convention for its internal functions. Canonical ABI is about the interface boundary, where types must remain consistent across languages and toolchains.
What It Translates
Interface types include more than plain integers and floats. Canonical ABI must handle structured data such as:
- Strings: typically represented as a pointer plus length, with a defined encoding expectation.
- Lists: sequences with element types, requiring consistent layout for element boundaries.
- Records: fixed sets of named fields, requiring deterministic ordering.
- Variants: tagged unions, requiring a stable tag representation and payload mapping.
- Options and Results: presence/absence and success/error payloads, requiring consistent tagging.
The key idea is that interface types have a semantic shape, while the canonical ABI chooses a concrete runtime representation that both sides can reconstruct.
A Systematic View of the Boundary
Consider a call from a host into a component export.
- The host code holds values in its language representation.
- The generated binding (or host glue) invokes the component export using the canonical ABI.
- Lowering converts each argument into the runtime representation.
- The component function executes and returns values in its own internal representation.
- Lifting converts return values back into the host’s expected representation.
The same steps occur in reverse for imported functions implemented by the component.
Mind Map: Canonical ABI Responsibilities
Example: Record Lowering and Lifting
Suppose a WIT interface defines a record:
type Person = record { name: string, age: u32 }world app: export fn greet(p: Person) -> string
When the host calls greet, the host binding must:
- Convert
p.nameinto the canonical string representation (encoding plus length). - Place
p.ageinto the expected scalar slot. - Ensure the record fields are passed in the canonical order expected by the callee.
Inside the component, the function receives a representation it can interpret as Person. When it returns a string, the component returns the canonical string representation, and the binding lifts it back into a host string.
A practical best practice follows from this: keep interface shapes simple and explicit. If you model data as a record with clear fields, the canonical ABI has fewer degrees of freedom and fewer opportunities for mismatched assumptions.
Example: Variant Tagging and Error Results
If a WIT function returns result<u32, string>, the canonical ABI must represent:
- Whether the call succeeded.
- The success payload (
u32) or the error payload (string).
That means a stable tag plus a payload slot. The lifting step reads the tag and reconstructs either an Ok value or an Err value in the caller’s language.
This is why interface designers should treat error payload types as part of the contract, not as incidental details. The canonical ABI will faithfully move the payloads, but it cannot guess what your language expects if the interface types differ.
What Canonical ABI Does Not Do
Canonical ABI does not:
- Automatically “optimize away” copies when you pass complex data.
- Make mismatched interface definitions compatible.
- Change the meaning of types; it only standardizes representation at the boundary.
If two sides disagree on the WIT types, the boundary cannot be reconciled by canonical ABI alone. The contract must match first, then canonical ABI ensures the runtime representation matches.
Summary
Canonical ABI is the deterministic translation mechanism that makes WIT interface types work across component boundaries. It applies wherever interface-defined calls cross between host and component or between components, and it handles structured types by lowering arguments into a runtime representation and lifting results back into the caller’s expected form.
3.2 Memory Layout Rules for Scalars Strings and Lists
Canonical ABI needs a predictable “shape” for values crossing the component boundary. The rules below focus on scalars, strings, and lists, because they drive most real interfaces: counters, identifiers, text payloads, and repeated items.
Scalars Layout Rules
A scalar is a single value with no internal structure: integers, floats, booleans, and enums represented as integers. Canonical ABI treats scalars as fixed-size, so the boundary representation is straightforward and stable.
Core rule: the canonical ABI uses a fixed-width encoding for each scalar type, matching the component model’s expected bit width. That means you should not assume host endianness or native C struct layout; the canonical ABI defines the byte-level meaning.
Best practice: keep scalar types narrow and explicit in WIT. If you need a 32-bit counter, declare u32 rather than “whatever fits.” It prevents accidental truncation and makes the lowering and lifting rules unambiguous.
Example:
- WIT:
func add(a: u32, b: u32) -> u32 - Canonical ABI: both parameters are passed as 4-byte unsigned integers.
- Host code: reads exactly 4 bytes per argument, then writes exactly 4 bytes for the result.
Strings Layout Rules
Strings are where “it’s just text” stops being true. Canonical ABI represents strings as a pointer-like handle plus a length, so the runtime can copy or validate without guessing where the bytes live.
Core rule: a string is transferred as two pieces of information: a byte sequence and its length in bytes. The bytes represent UTF-8.
Canonical ABI expectations:
- The string is treated as UTF-8 bytes, not UTF-16 or platform-specific encodings.
- The length is the number of bytes, not the number of Unicode scalar values.
- The boundary representation does not require the host to keep the original memory alive after the call; the canonical ABI can copy as needed.
Best practice: avoid “string plus implicit terminator” assumptions. Even if your host language uses null-terminated strings, the canonical ABI contract is length-based.
Example:
- WIT:
func greet(name: string) -> string - Host passes:
(ptr, len)wherelenis the UTF-8 byte count. - If
name = "é", UTF-8 uses 2 bytes, solen = 2.
Lists Layout Rules
Lists are repeated elements with a uniform element type. Canonical ABI uses a length plus a contiguous region of element representations.
Core rule: a list is transferred as (ptr, len) where len is the number of elements, and the memory region contains the canonical ABI representation of each element back-to-back.
Element representation matters:
- If the list element is a scalar, each element occupies a fixed number of bytes.
- If the list element is a string, each element is represented by its own canonical string handle (and the runtime handles the nested copying/lifting rules).
Best practice: prefer lists of scalars for hot paths. Lists of strings work, but they multiply the number of boundary conversions because each string carries its own length and byte data.
Example:
- WIT:
func sum(xs: list<u32>) -> u64 - Host passes:
(ptr, len)where the region containslenconsecutive 4-byteu32values. - The callee reads exactly
len * 4bytes for the list payload.
Mind Map: Memory Layout Rules
Putting It Together with a Concrete Contract
Consider a small interface that mixes all three categories:
id: u32(scalar)label: string(string)values: list<u32>(list of scalars)
A correct mental model is: the canonical ABI can treat each parameter as a self-describing bundle. Scalars are self-contained fixed-size values. Strings and lists are self-describing because they carry lengths, so the runtime knows exactly how many bytes or elements to read.
Common pitfall: declaring a list of the wrong element type. If you declare list<u16> but the host actually packs u32, the boundary will still read the region as len * 2 bytes per element, producing incorrect values without necessarily crashing.
Rule of thumb: when you see (ptr, len) in your host bindings, treat it as “byte-accurate and length-accurate,” not “a pointer to a native container.” The canonical ABI contract is about exact layout, not about how your language stores data internally.
3.3 Ownership and Borrowing Semantics Across the Boundary
When a component calls another component through a WIT-defined interface, it is not just exchanging values. It is also negotiating who is responsible for the memory behind those values. Canonical ABI rules make this explicit, so you can write code that is correct even when the caller and callee are written in different languages.
The Core Idea of Ownership
Ownership answers one question: who must eventually release the resources represented by a value? In a typical in-language program, ownership is enforced by the language runtime or by conventions. Across a WebAssembly component boundary, ownership cannot rely on a shared allocator or a shared garbage collector. Instead, the canonical ABI defines transfer points.
A practical rule of thumb: if a value contains data that must live beyond the call, the interface shape must make that lifetime concrete. If the interface only allows the callee to use data during the call, then the caller retains ownership and the callee must not keep references.
Borrowing as a Call-Scoped Contract
Borrowing means “use this data without taking ownership.” Across the boundary, borrowing is usually call-scoped: the callee may read the provided bytes or strings while the call is executing, but it must not assume it can reference them after returning.
This is where many bugs start: a callee stores a pointer or slice for later use, but the caller’s memory may be reused or freed once the call ends. Canonical ABI conversions prevent this by either copying into callee-owned memory or by representing borrowed data in a way that cannot outlive the call.
How Canonical ABI Shapes Enforce Lifetimes
Canonical ABI lowering and lifting decide whether data is copied, and what the callee can safely do with it.
- For string and buffer parameters, the ABI typically treats the input as data the callee can read during the call. The callee receives a representation that is valid for that duration.
- For results, the ABI ensures the returned value is represented in a way the caller can safely consume. If the caller needs to keep it, the ABI provides a stable representation for that purpose.
The interface designer’s job is to pick shapes that match the intended lifetime. If you want the callee to return data that the caller will keep, return it as an owned result. If you want the callee to read data provided by the caller, accept it as an input.
Mind Map: Ownership and Borrowing Across the Boundary
Example: Call-Scoped Borrowing for a Buffer
Imagine an interface function that computes a checksum from bytes.
- The caller passes a buffer.
- The callee reads it during the call.
- The callee returns a small integer.
The ownership is simple: the caller owns the buffer, and the callee never needs to keep it.
Interface concept
- fn checksum(data: list<u8>) -> u32
Semantics
- Caller owns data
- Callee borrows data during the call
- Callee returns owned scalar
Best practice: treat input buffers as read-only and ephemeral. If you need the bytes later, copy them into callee-owned storage during the call.
Example: Returning Data That Must Outlive the Call
Now consider an interface that transforms bytes.
- The caller passes input bytes.
- The callee produces an output buffer.
- The caller keeps the output after the call.
Here, the output buffer is an owned result. The caller becomes responsible for consuming it according to the ABI’s conventions.
Interface concept
- fn transform(data: list<u8>) -> list<u8>
Semantics
- Caller owns input
- Callee borrows input during the call
- Callee returns owned output
- Caller owns output after return
Best practice: never return a reference into the input buffer. Even if it “works” in one language, it breaks when the ABI chooses to copy or when the caller’s memory is reclaimed.
Example: Ownership with Records and Error Results
Ownership rules extend naturally to structured values.
- If a record contains a buffer field, that field follows the same input/output lifetime rules as its position in the interface.
- For error results, treat error payloads as owned outputs. If you include a message or diagnostic bytes, the caller must be able to read them after the call.
A clean pattern is: keep error payloads small and self-contained, so the ABI can lift them without surprising lifetime coupling.
Practical Checklist for Correctness
- Assume inputs are borrowed and call-scoped.
- Assume outputs are owned results suitable for the caller to keep.
- Never store references to input memory for later use.
- Never return views into input buffers.
- Design interface shapes so the intended lifetime is unambiguous.
If you follow those rules, the canonical ABI becomes less of a mystery and more of a contract: it tells you where data is safe to use, and where it must be copied or re-materialized.
3.4 Handling Variants and Tagged Unions in Canonical ABI
Variants and tagged unions are how you express “one of several shapes” across the WebAssembly boundary. In the canonical ABI, the goal is simple: make the runtime representation unambiguous, so lifting and lowering can round-trip values without guessing.
Core Idea: Tag Plus Payload
A tagged union is represented as:
- A tag that identifies which case is active.
- A payload that carries the data for that case.
In canonical ABI terms, the tag is typically lowered as an integer-like discriminant, while the payload is lowered using the same canonical rules as records, lists, and strings. The important part is that the tag and payload are serialized in a consistent order and with consistent sizing rules.
Mind Map: Variant Representation in Canonical ABI
Foundational Rules That Prevent Surprises
Stable Case Ordering
Canonical ABI lowering assumes the variant’s cases have a stable mapping to tag values. That means the interface definition must not rely on “whatever order the compiler feels like today.” Treat case order in the WIT definition as part of the contract.
Payload Shape Depends on the Tag
Each tag selects a payload type. For example, case Ok might carry a record, while case Err carries a string. The ABI must encode enough information to know which payload layout to use when lifting.
Empty Payload Cases
Some variants carry no data for a case, like None. Canonical ABI still needs a tag; the payload is either omitted or encoded as a zero-sized representation. Lifting uses the tag to skip payload decoding.
Example: A Simple Result Variant
Assume a WIT-like definition:
resulthas cases:okwith payloadrecord { value: u32 }errwith payloadstring
On the wire, lowering produces a structure equivalent to:
tag = 0forokpayload = { value: <u32> }
For err:
tag = 1payload = <string bytes plus length encoding>
When lifting, the host reads the tag first, then decodes only the matching payload layout.
Practical Example: Round-Trip Logic
Below is pseudocode showing the essential control flow. The exact memory representation is handled by generated bindings, but the logic is the same.
function liftVariant(tag, payloadBytes): Variant
switch tag
case 0:
v = decodeRecord(payloadBytes, { value: u32 })
return Ok(v)
case 1:
s = decodeString(payloadBytes)
return Err(s)
default:
return Trap("unknown tag")
Advanced Details: Nested Variants and Mixed Payloads
Variants Inside Records
If a record contains a variant field, the record lowering writes its fields in canonical order. The variant field itself becomes a tag-plus-payload sub-encoding. Lifting reverses the process: decode record fields, and when the variant field is reached, decode its tag and payload.
Variants with Multiple Payload Fields
A case payload can itself be a record or a tuple-like grouping. Canonical ABI treats it as a structured payload: the payload encoding includes the canonical encodings for each member, so lifting can reconstruct the full payload without external context.
Handling Unknown Tags
If a host receives a tag value that does not correspond to any case in the interface, lifting cannot safely proceed. The correct behavior is to fail deterministically (often a trap) rather than attempting a best-effort decode. This keeps the boundary from turning into a guessing game.
Example: Variant Payload with Errors
Consider a variant used for error reporting:
errorcases:invalid_inputwith payloadrecord { field: string, reason: string }quota_exceededwith empty payload
Lowering invalid_input writes:
- tag for
invalid_input - payload encoding for the record, including both strings.
Lowering quota_exceeded writes:
- tag for
quota_exceeded - no payload bytes (or a canonical zero-sized payload).
Lifting reads the tag and either decodes the record or skips payload decoding entirely.
Best Practices That Fit the ABI Model
- Keep case payloads concrete: prefer records for multi-field payloads so canonical decoding is straightforward.
- Use empty payload cases sparingly but intentionally: they reduce payload size and make control flow clear.
- Avoid relying on implicit numeric meanings: treat tag values as an implementation detail derived from the interface definition.
- Test round-trips per case: verify that lowering then lifting returns the same tag and payload for every variant case.
When you follow these rules, tagged unions behave like a well-labeled suitcase: the tag tells you which compartment to open, and the payload tells you exactly what’s inside.
3.5 Worked Example of ABI Mapping for a Composite Type
This example maps a composite record across the component boundary using the canonical ABI rules. We’ll keep the types small enough to reason about, but realistic enough to show where mistakes usually happen.
The Composite Type Contract
Assume a WIT interface defines a function that takes a record and returns a record:
- Input record
UserProfile:id: u32name: stringflags: list<u8>
- Output record
UserSummary:id: u32display_name: string
The canonical ABI must translate these high-level shapes into a low-level calling convention. The key idea is that strings and lists are not passed as “native pointers to native memory.” Instead, they are passed as a pair of values that describe where the data lives and how long it is.
Mind Map: Data Shape to ABI Representation
Step 1: Lowering the Input Record
On the caller side, you start with a UserProfile value in the host language. The canonical ABI lowering produces arguments for the callee.
-
Scalar field
id: u32- This becomes a direct numeric argument.
- No pointer, no length.
-
String field
name: string- The canonical ABI expects UTF-8 bytes.
- Lowering creates:
name_ptr: a pointer to a contiguous byte buffername_len: the number of bytes
- The callee will interpret
name_ptr..name_ptr+name_lenas UTF-8.
-
List field
flags: list<u8>- For
list<u8>, each element is one byte. - Lowering creates:
flags_ptr: pointer to the first element byteflags_len: number of elements
- Because element size is 1,
flags_lenalso equals the byte length. This is convenient, but it’s still conceptually “element count,” not “string length.”
- For
A practical best practice is to treat the lowered representation as a temporary view. If the host runtime moves or frees buffers, you must ensure the canonical ABI call happens while the buffers are valid.
Step 2: Lifting the Output Record
The callee returns a UserSummary. Canonical ABI lifting converts the returned representation back into host types.
id: u32lifts directly.display_name: stringlifts from:display_ptrdisplay_len
The host then constructs a native string by decoding UTF-8 bytes from that memory region.
A correctness rule: the lifted string length is in bytes. If you need character counts for display logic, compute them after decoding.
Step 3: A Concrete Mapping Walkthrough
Let’s pick a specific input:
id = 7name = "Ava"(UTF-8 bytes:41 76 61, length 3)flags = [1, 0, 255](three bytes)
Lowered arguments conceptually become:
id_arg = 7name_ptr -> [0x41, 0x76, 0x61]name_len = 3flags_ptr -> [0x01, 0x00, 0xFF]flags_len = 3
Now suppose the callee computes display_name = "User Ava". That string is UTF-8 bytes:
"User Ava"=55 73 65 72 20 41 76 61display_len = 9
The returned canonical representation includes:
out_id = 7display_ptr -> those 9 bytesdisplay_len = 9
Lifting reconstructs the host string by decoding those bytes.
Mind Map: Where Bugs Hide
Step 4: Field Ordering and Determinism
Composite records are lowered field-by-field in a deterministic order defined by the interface type. If you ever see swapped fields in debugging output, it’s usually not “random ABI magic.” It’s almost always a mismatch between the generated binding’s field order and the caller’s expectations.
A good sanity check is to log the lowered scalar values and the two lengths (name_len, flags_len) before the call. If those match the source value, the remaining work is mostly about correct pointer validity and correct interpretation of byte buffers.
Step 5: Summary of the Mapping Rules Used Here
- Scalars pass as direct values.
- Strings pass as
(ptr, byte_len)over UTF-8 bytes. - Lists pass as
(ptr, elem_len)over contiguous elements. - Lifting reverses the process using the returned
(ptr, len)pairs. - Composite records are lowered deterministically by field order.
With this worked example, you can apply the same method to larger records: identify each field’s category (scalar, string, list, nested record), then map each category to its canonical representation and verify lengths and lifetimes before trusting the result.
4. Canonical ABI Lowering and Lifting for Strings and Buffers
4.1 String Encoding Expectations and Boundary Conversions
When a component boundary crosses languages, strings stop being “just text” and become “a contract.” The canonical ABI defines how strings are represented when they move between the component and the host, and it also defines what conversions happen automatically. The practical goal is simple: make sure both sides agree on encoding, length, and ownership so you don’t end up with mojibake (garbled characters) or accidental truncation.
What “String” Means at the Boundary
In WIT, a string is a sequence of Unicode scalar values. The canonical ABI standardizes the wire representation so that a guest component can pass text to a host (or another component) without each side inventing its own encoding rules.
At the boundary, the canonical ABI typically uses UTF-8 as the external encoding for strings. That means:
- The byte sequence is UTF-8.
- The length is measured in bytes, not characters.
- The receiving side must decode UTF-8 bytes into its local string type.
A key best practice is to treat “length” as bytes whenever you’re reasoning about the boundary. If you count characters in your head, you will eventually be wrong for non-ASCII text.
Boundary Conversion Pipeline
Think of string passing as a pipeline with three stages: encode, transfer, decode.
- Encode on the sender: Convert the local string into UTF-8 bytes.
- Transfer via canonical ABI: Provide the receiver with a pointer/length pair (or equivalent representation) that describes the UTF-8 byte sequence.
- Decode on the receiver: Convert UTF-8 bytes back into the receiver’s native string type.
If the receiver gets invalid UTF-8 bytes, behavior depends on the runtime and binding strategy. Some bindings reject invalid sequences; others may replace invalid sequences with a replacement character. Either way, you should avoid producing invalid UTF-8 in the first place by ensuring your sender always provides valid text.
Mind Map: String Encoding Expectations
Example: ASCII Versus Unicode Length
Suppose you pass the string "café".
- In characters, it’s 4 letters.
- In UTF-8 bytes, it’s 5 bytes because
étakes 2 bytes.
If you mistakenly treat the length as “characters,” you might allocate 4 bytes and cut off the second byte of é, producing invalid UTF-8 on the receiver.
A robust practice is to never manually compute boundary lengths unless you are explicitly working with UTF-8 bytes. If you must compute lengths, compute them from the UTF-8 byte representation you will actually send.
Example: Correct Boundary Handling with Explicit UTF-8 Bytes
Below is a language-agnostic sketch of the logic you want your bindings to follow. The point is the order: encode to UTF-8 bytes first, then use the byte length.
local_text = "café"
utf8_bytes = encode_utf8(local_text)
byte_len = length(utf8_bytes)
send(pointer=utf8_bytes_start, length=byte_len)
receiver_bytes = read(pointer, length)
receiver_text = decode_utf8(receiver_bytes)
If you reverse the steps—using a character count to set length—you risk truncating multi-byte sequences.
Example: Designing Interfaces to Reduce String Ambiguity
For small strings, passing a string directly is usually fine. For larger payloads, you may prefer an interface that passes bytes explicitly (for example, a list<u8> or a buffer-like pattern) so you can control when encoding happens.
A practical rule of thumb:
- Use
stringwhen the meaning is text and both sides benefit from automatic UTF-8 decoding. - Use byte-oriented types when the payload is already structured data, or when you want to avoid repeated encode/decode cycles.
Ownership and Lifetime Expectations
Even though this subsection focuses on encoding, ownership affects conversions. The sender must ensure the UTF-8 bytes remain valid for the duration of the call (or until the receiver has copied/consumed them, depending on the ABI rules). The receiver must not assume it can keep a borrowed view of the sender’s memory unless the interface explicitly guarantees that.
A safe pattern is: treat boundary strings as ephemeral unless the interface and bindings document otherwise. If you need to store the text, copy it into the receiver’s own memory after decoding.
Practical Checklist for String Conversions
- Confirm that the boundary representation is UTF-8 bytes.
- Treat lengths as byte counts.
- Encode first, then compute length from the encoded bytes.
- Decode immediately on the receiver, then copy if you must persist.
- Avoid mixing character counts with byte lengths in any custom glue code.
With these expectations aligned, string passing becomes predictable: the boundary transports bytes, and each side interprets those bytes as UTF-8 text according to the canonical ABI rules.
4.2 Byte Buffers and Slice Like Data Transfer Patterns
Byte buffers are the most common “shape” for crossing a WebAssembly component boundary. In practice, you want a pattern that is easy to reason about: who owns the bytes, how long they remain valid, and what exactly gets copied.
Core Idea: Treat Buffers as Explicit Contracts
A slice like transfer usually needs three pieces of information:
- Pointer to the first byte in linear memory.
- Length in bytes.
- Ownership and lifetime rule that both sides follow.
With the canonical ABI, the safest default is: the caller provides a buffer, the callee writes into it, and the callee does not retain the pointer after returning. If you need the callee to keep data, you must define a separate “allocate and return” pattern.
Mind Map: Buffer Transfer Patterns
Pattern 1: Caller Provided Output Buffer
This pattern is great when the callee can write into a buffer whose maximum size is known or can be negotiated.
Contract shape:
- Input:
in_ptr,in_len - Output:
out_ptr,out_cap - Return:
out_lenand a status code
Why it works: the host controls allocation, so the callee never needs to guess memory management.
Example: a component function that serializes a small record into bytes.
// Pseudocode for interface intent
fn encode(input: &[u8], out: &mut [u8]) -> Result<usize, EncodeError> {
// Validate input length before reading
// Write bytes into out
// Return number of bytes written
}
Best practice: treat out_cap as a hard limit. If the buffer is too small, return an error that includes the required size so the host can retry.
Pattern 2: Two Phase Size Negotiation
When the output size is not known up front, use a “query then write” flow.
Step A: call required_size(in_ptr, in_len).
Step B: allocate exactly that many bytes on the host.
Step C: call write(in_ptr, in_len, out_ptr, out_len).
This avoids guessing and reduces the chance of partial writes.
Host:
need = required_size(input)
buf = alloc(need)
written = write(input, buf)
assert(written == need)
Pattern 3: Callee Allocated Return Buffer
Sometimes the callee naturally produces bytes and you want it to allocate them. Then you must define how the host frees them.
Contract shape:
- Return:
ret_ptr,ret_len - Plus: a
free(ret_ptr, ret_len)function or a handle based API
Best practice: keep the free function in the same component so the host does not need to know allocator details.
// Pseudocode for intent
fn compute(input: &[u8]) -> (ptr: u32, len: u32);
fn free_bytes(ptr: u32, len: u32);
Canonical ABI Details That Matter
- Always pass lengths in bytes. Don’t rely on element counts unless the interface explicitly defines element size.
- Validate lengths before reading. A wrong length can turn into out of bounds reads or silent truncation.
- Define behavior for unused capacity. If the host passes a larger buffer than needed, specify whether the callee leaves trailing bytes unchanged or zeroes them.
- Avoid retaining pointers. If the callee stores
ptrfor later, you must redesign the interface to return an owned handle or copy the bytes.
Practical Example: Buffer Too Small Error
A clean error contract makes retries deterministic.
Return status options:
Ok(written_len)Err(BufferTooSmall(required_len))
Host behavior: allocate required_len and call again.
Caller:
status = encode(input, out_buf)
if status == BufferTooSmall(need):
out_buf = alloc(need)
status = encode(input, out_buf)
This keeps the interface honest: the callee reports what it needs, and the host supplies it without guessing.
Summary Checklist
- Use pointer + length for slice like transfers.
- Pick an ownership model and state it in the interface.
- Prefer caller provided output for simplicity.
- Use two phase negotiation when sizes are unknown.
- If returning allocated bytes, provide a free mechanism.
- Validate lengths and define trailing byte behavior.
4.3 Zero Copy Constraints and When Copies Are Required
Zero copy is a tempting goal, but the canonical ABI has rules that prevent “free” transfers in many realistic cases. The key idea is simple: the boundary needs a stable, well-defined representation. When the source language’s in-memory layout doesn’t match that representation, the runtime must translate, which usually means copying.
What Zero Copy Really Means at the Boundary
In canonical ABI terms, “zero copy” is not a promise that bytes never move. It means the implementation can avoid materializing an intermediate buffer for the canonical representation.
For example, if a guest function receives a list<u8> and the host already has a contiguous byte region with the expected element layout, the runtime may pass a view rather than allocate and copy. If the host has a non-contiguous representation (or the guest expects a different encoding), the runtime must copy.
Constraints That Block Zero Copy
Contiguous Memory Requirements
Canonical ABI lowering and lifting often assume contiguous memory for sequences like list<u8>, string, and nested lists. If the source value is spread across multiple allocations, the runtime must gather it into a contiguous region.
Encoding and Normalization for Strings
Strings cross the boundary with a defined encoding expectation. If one side stores text as UTF-8 bytes and the other stores it as UTF-16 code units, the runtime must convert. Conversion implies copying because the byte sequence changes.
Ownership and Lifetime Boundaries
Even if the bytes are contiguous, the runtime must ensure the receiver can safely access them for the required lifetime. If the sender cannot guarantee that the underlying memory remains valid after the call returns, the runtime must copy into a buffer with a safe lifetime.
Nested and Composite Types
Composite types like records containing lists, or variants containing payloads, multiply the number of places where representation mismatches can occur. A single nested field that requires conversion forces copying for that field, and sometimes for the whole structure depending on how the runtime batches conversions.
Variants and Error Payloads
Variants and result-like patterns often require tagging and payload layout. If the source language represents variants differently (for example, different tag sizes or different payload packing), the runtime must translate, which typically means copying payload data.
When Copies Are Required in Practice
Rule of Thumb for Byte Sequences
Copies are required when any of these are true:
- The data is not already in the canonical element layout.
- The encoding differs (especially for strings).
- The sender’s memory lifetime cannot cover the receiver’s needs.
- The value is nested in a way that forces per-field canonicalization.
Rule of Thumb for Strings
Copies are required when:
- The internal string representation differs from the canonical encoding.
- The boundary needs a normalized representation (for example, consistent UTF-8 bytes).
- The receiver needs the string after the call and the sender cannot extend lifetime.
Mind Map: Zero Copy Constraints and Copy Triggers
Example: Byte Buffer Interface and the Copy Decision
Consider a WIT interface that accepts a byte buffer and returns a transformed buffer.
package demo:bytes
interface transform {
transform: func(input: list<u8>) -> list<u8>
}
If the host already has a contiguous u8 slice and the guest consumes it only during the call, the runtime can often pass a view for input. The returned list<u8> usually requires allocation on the receiver side because the guest must produce a new canonical representation.
If instead the host constructs the bytes from multiple chunks (for example, a rope or a list of segments), the runtime must first assemble a contiguous buffer for input. That assembly is a copy.
Example: String Interface and Why Conversion Happens
package demo:text
interface echo {
echo: func(s: string) -> string
}
If the guest stores strings as UTF-8 bytes, the boundary may avoid copying for s during the call. If the host stores strings as UTF-16, the runtime must convert to the canonical encoding for string. That conversion creates a new byte sequence, so a copy is required.
Even when conversion is avoided for the input, returning string can still require copying if the receiver’s internal representation differs.
Practical Takeaways for Interface Design
- Use
list<u8>for raw binary data when you want the boundary to work with contiguous byte sequences. - Treat
stringas an encoding boundary, not as “just text,” and assume conversion may be needed. - Keep ownership expectations clear by designing interfaces so the receiver doesn’t need to retain references beyond the call.
- For hot paths, prefer simple shapes with fewer nested conversions; each nested field is another chance for representation mismatch.
4.4 Streaming Like Workflows Using Chunked Interfaces
Streaming is what you want when the whole payload is too big to hold comfortably, or when you want to start producing output before the input is fully available. With component interfaces, you don’t get “true streaming” for free; you get a disciplined way to move data in pieces. The trick is to design a chunked contract that keeps ownership rules clear and makes progress observable.
Core Idea: Chunked Request and Response
A chunked workflow usually has three phases:
- Initialize: negotiate sizes or capabilities, and establish a session identifier.
- Transfer: send input chunks with an explicit end marker.
- Finalize: flush remaining work and return a final status or trailing output.
In WIT terms, you model this with an interface that exposes methods like start, push-chunk, and finish. Each call carries a list<u8> (or a string if your data is text) plus a session handle.
A best practice is to keep each chunk self-contained: it should not rely on hidden internal buffering assumptions. That makes correctness easier to reason about and simplifies testing.
Mind Map: Chunked Workflow Shape
Designing the Interface
Here is a compact interface shape that supports both request streaming and response streaming. The response can be optional per chunk, which is useful for transforms that emit output gradually.
Example: Chunked Transform Interface
package stream.example
interface transformer {
start: func() -> result<u32, string>
push-chunk: func(session: u32, chunk: list<u8>, is_last: bool)
-> result<option<list<u8>>, string>
finish: func(session: u32) -> result<option<list<u8>>, string>
}
The option<list<u8>> return means “this call may or may not produce output.” That avoids forcing every chunk to generate a response chunk, which keeps the contract honest.
A practical rule: if you can compute output only after seeing more input, return none until you’re ready.
Canonical ABI Implications for Chunks
When you pass list<u8> across the boundary, the canonical ABI will lower and lift it using the runtime’s agreed representation. You should assume that each call may involve copying or at least boundary conversion work. Therefore, chunk size matters.
A good starting point is to choose a chunk size that balances:
- Call overhead: fewer, larger chunks reduce per-call costs.
- Memory pressure: smaller chunks reduce peak memory usage.
- Latency: smaller chunks let the consumer see partial results sooner.
The interface should not require the host to guess perfectly. If you need a size hint, add it to start as an input parameter, and keep it optional.
Example: Host Loop That Streams Chunks
The host reads input, sends chunks, and collects output chunks as they arrive.
session = transformer.start().unwrap()
for each chunk in input_chunks:
is_last = (chunk is final)
out = transformer.push_chunk(session, chunk, is_last).unwrap()
if out is some(bytes): write(bytes)
final_out = transformer.finish(session).unwrap()
if final_out is some(bytes): write(bytes)
Notice the discipline: the host never assumes that output corresponds 1:1 with input chunks. The contract allows “no output yet,” which keeps implementations flexible.
Error Handling That Doesn’t Confuse Ownership
For chunked calls, errors should be specific about where the failure happened. Returning result<..., string> is fine for a first version, but in production you typically use a structured error record so the host can decide whether to retry, abort, or report.
A key best practice: once push-chunk returns an error, stop sending more chunks for that session. The interface should treat the session as invalid after failure, and the host should call finish only if the contract explicitly allows cleanup.
Advanced Detail: Progress Without Extra Methods
Sometimes you want the host to know whether the component is making progress without adding a separate status method. You can do this by encoding progress into the response:
- Return
nonefor “accepted but no output yet.” - Return
some(bytes)when output is produced. - Optionally, include a small “heartbeat” output format like a fixed header record, but only if you truly need it.
This keeps the interface small and avoids turning the contract into a control plane.
Advanced Detail: Session Lifetime and Determinism
Session-based streaming is deterministic if you define:
- What
startguarantees (fresh state, empty buffers). - What
finishguarantees (all remaining output emitted, session can be dropped). - What happens if the host never calls
finish(usually: resources leak unless the runtime cleans up; so the contract should encourage callingfinishin afinally-style pattern).
Even without extra runtime features, this clarity prevents “it worked on my machine” bugs caused by mismatched expectations about cleanup.
Practical Checklist
- Use
start,push-chunk, andfinishto make phases explicit. - Represent chunks as
list<u8>and output asoption<list<u8>>when output timing varies. - Choose chunk sizes that balance overhead, memory, and latency.
- Stop on error and treat the session as invalid unless the contract says otherwise.
- Define session lifetime rules so cleanup behavior is predictable.
4.5 Practical Buffer Interface Example with Correct Lifetimes
A buffer interface is where canonical ABI rules become real. The goal is simple: pass bytes across the boundary without guessing who owns the memory, and without accidentally using a pointer after it has been invalidated.
Core Idea: Separate Borrowed Views from Owned Storage
In WIT, you typically model a buffer as either:
- A borrowed view: the callee reads bytes during the call and does not keep them.
- An owned value: the callee receives a buffer it may store, and the runtime can manage its lifetime.
Canonical ABI enforces this by converting between guest and host representations. The conversion may allocate temporary memory, so “pointer stability” across calls is not something you can rely on.
Interface Shape That Makes Lifetimes Obvious
Use a request buffer input and a response buffer output. The input is treated as read-only during the call. The output is treated as owned by the callee until it returns, then owned by the caller after return.
Mind Map: Buffer Lifetimes and Ownership
WIT Definition for a Byte Processing Service
This interface takes bytes and returns bytes. The contract is that the implementation reads the input only while executing the function.
Example: WIT Buffer Contract
package buf:example
interface processor {
process: func(input: list<u8>) -> list<u8>;
}
Why list<u8>? Canonical ABI knows how to lower and lift lists of scalars. You avoid manual pointer juggling and let the runtime handle representation.
Guest Implementation in Rust with Correct Lifetimes
The key lifetime rule: do not return references to the input buffer. Instead, create an owned output buffer.
Example: Rust Implementation
use wit_bindgen::generate;
// Assume bindings generated for the processor interface.
struct Impl;
impl Impl {
fn process_bytes(input: Vec<u8>) -> Vec<u8> {
// Read input during the call.
// Produce a new owned buffer for the return value.
input.into_iter().map(|b| b ^ 0xAA).collect()
}
}
// Export process(input) -> output using generated glue.
Even if the runtime could theoretically avoid copies, your code must still be correct if it does copy. The implementation above is correct because it never stores or returns anything derived by reference from input.
Host Side: Treat Output as Owned
On the host, you receive a list<u8> lifted into the host language’s owned representation. You can safely use it after the call completes.
Mind Map: What Each Side May Assume
A Common Bug and How to Avoid It
Bug pattern: converting the input to a slice and storing it in a struct for later use.
- If you store a reference to the input, you risk using memory that was only valid during the call.
- If you store a raw pointer, you risk dangling pointers after canonical ABI conversion.
Correct pattern: copy what you need into owned storage.
Example: Buggy Lifetime Pattern
struct Bad {
saved: Option<&'static [u8]>,
}
// This is conceptually wrong: the input slice is not 'static.
Example: Correct Lifetime Pattern
struct Good {
saved: Option<Vec<u8>>,
}
impl Good {
fn save_input(&mut self, input: Vec<u8>) {
// Own the bytes you keep.
self.saved = Some(input);
}
}
Practical Checklist for Buffer Interfaces
- Model byte data as
list<u8>(or a structured list) so canonical ABI can do the conversions. - Read input only during the function call; never store borrowed references.
- Return owned buffers; never return references to temporary data.
- Treat lengths as authoritative and validate before indexing.
- Assume copies may happen; write code that remains correct even when they do.
With these rules, the buffer boundary becomes predictable: lifetimes are scoped to the call, ownership is explicit in the types, and the canonical ABI does the conversion work without you having to guess what memory is still around.
5. Canonical ABI for Complex Types and Error Handling
5.1 Records and Nested Structures With Deterministic Layout
Canonical ABI needs a predictable mapping from high-level types to a byte-level representation. Records and nested structures are where that predictability matters most, because one field’s layout affects the next field’s offsets, and nesting multiplies the number of rules you must follow.
Core Idea of Deterministic Layout
A record is a fixed set of named fields. In the canonical ABI, the record’s serialized form is deterministic: the same record type always maps to the same sequence of bytes, with the same field order and the same alignment behavior. Determinism is what lets a caller written in one language pass data to a callee written in another language without guessing.
Deterministic layout is not “whatever the compiler feels like today.” It is a contract: field order, representation of each field, and how padding is handled are defined by the ABI rules.
Record Field Order and Naming
Field names are for readability; layout is for bytes. The ABI uses the declared field order in the WIT definition. That means you should treat field reordering as a breaking change, even if the record still “looks the same” at the source level.
Best practice: keep record field order stable and use additive changes when evolving interfaces. If you must change meaning, add a new field and keep the old one until you can migrate.
Nested Records and Offset Propagation
When a record contains another record, the nested record is serialized as a contiguous region inside the outer record. The outer record’s field offsets depend on the nested record’s size and alignment.
A practical way to reason about it:
- Determine the canonical representation of each leaf field (scalars, strings, lists, variants).
- Compute the size and alignment of each nested record.
- Place nested record bytes at the correct offset within the parent record.
- Repeat until you reach the top-level record.
This is why deterministic layout is easier to debug when you keep record shapes simple and avoid mixing many different kinds of fields in one structure.
Mind Map: Records and Nested Structures
Example: A Simple Record with Nested Record
Consider a WIT-like conceptual type:
Addressrecord:street: string,zip: u32Userrecord:id: u32,home: Address
In canonical ABI terms, User contains a u32 leaf followed by the serialized representation of Address. The Address serialization includes the representation for street and the zip field.
Key nuance: strings are not “inline text.” They are represented using the canonical string form (typically a pointer-like handle plus length semantics at the boundary). That means the outer record does not just store characters; it stores the canonical representation required to reconstruct the string on the other side.
Example: Computing Layout Bottom-Up
Let’s reason about offsets without committing to a specific numeric alignment value.
User.idis a scalar leaf. Its canonical representation has a known size and alignment.User.homeis a nested record. Before placing it, the ABI aligns the current offset according toAddress’s alignment.- Inside
Address,streetis represented using the canonical string form, andzipis au32leaf. - The size of
Addressdetermines how much spaceUser.homeconsumes, which determines the final size ofUser.
If you ever see mismatched data in a nested record, the first suspect is usually a field representation mismatch (for example, treating a string as if it were a fixed-size buffer) or a field order mismatch.
Best Practices for Record Shapes
- Keep leaf types consistent across languages. If a field is a string in WIT, treat it as a string everywhere; do not “optimize” by assuming a particular encoding.
- Avoid reordering fields. Even if two languages compile the same record, the ABI contract is the WIT definition order.
- Use nested records to group meaning, not to hide complexity. Nesting is fine, but deeply nested structures make offset debugging harder.
- Prefer clear boundaries for variable-sized fields. Strings and lists introduce canonical representations that are more than raw bytes.
Mind Map: Debugging Deterministic Layout
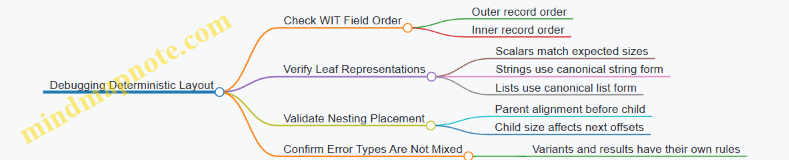
Summary
Records and nested structures are deterministic because the ABI defines how each field becomes bytes and how nested regions are placed within parent records. Treat field order as part of the public contract, compute layout bottom-up when reasoning about offsets, and remember that variable-sized leaves like strings are represented canonically rather than as raw inline data.
5.2 Options Results and Error Payload Design
Canonical ABI makes “what happened” explicit, but you still have to decide how to represent it. This section focuses on designing WIT contracts that use option, result, and structured error payloads in a way that is predictable across languages and easy to test.
Core Building Blocks
An option<T> represents “maybe a value.” A result<T, E> represents “either a value or an error.” In practice, you’ll use option for absence that is not an error (like “record not found”), and result for operations that can fail (like “parsing failed”).
A good rule: if the caller can continue without special handling, prefer option. If the caller must change behavior, prefer result.
Designing Error Payloads That Stay Stable
Error payloads should be structured, not just strings. A stable error payload lets the caller branch on machine-readable fields and still show a human-readable message.
A common pattern is a record with:
code: a small enum or string identifier for programmatic handlingmessage: a short description suitable for logsdetails: optional structured data for debugging or remediation
Keep payloads shallow. Deep nesting increases conversion work and makes tests harder to write.
Mind Map: Choosing Between Option and Result
Mind Map: Error Payload Shape
Example: WIT Contract for Option and Result
Below is a compact WIT sketch showing both patterns. The key is that the error payload is a record, not a free-form string.
package example:[email protected];
interface catalog {
get_user: func(id: u64) -> option<user>;
create_user: func(name: string) -> result<user, create-error>;
}
record user {
id: u64,
name: string,
}
record create-error {
code: string,
message: string,
details: option<create-error-details>,
}
record create-error-details {
field: string,
min_len: u32,
max_len: u32,
}
This contract supports three caller behaviors:
- If
get_userreturnsnone, the caller treats it as “not found.” - If
create_userreturnsok, the caller uses the returneduser. - If
create_userreturnserr, the caller can branch oncodeand optionally inspectdetails.
Example: Error Payload Design with Predictable Branching
Suppose create_user can fail for invalid names. Use a small set of codes like name_too_short, name_too_long, and name_invalid_chars. The caller can implement logic like:
- If
codeisname_too_shortorname_too_long, show the allowed range usingdetails. - Otherwise, log
messageand fall back to a generic error response.
The payload fields are intentionally redundant: code is for branching, message is for logs, and details is for structured remediation.
Canonical ABI Implications for Payloads
When you use result<T, E>, the canonical ABI needs a consistent representation for the discriminant and the payload. That means your error record should avoid patterns that force excessive conversions, like large lists of nested records when a small code plus a few fields would do.
For option<Details>, the ABI will represent presence versus absence. This is exactly what you want: callers can check whether details exists without guessing.
Practical Testing Strategy for Error Contracts
Test three categories of cases:
- Success cases: verify the
okvalue matches expected fields. - Error cases with
details: some: verifycodeanddetailsfields are correct. - Error cases with
details: none: verifycodeandmessageare still present and meaningful.
A small but effective invariant: message should never be empty, even when details is absent. That keeps logs useful and avoids “mystery errors” during integration.
Mind Map: Invariants That Prevent Confusing Errors
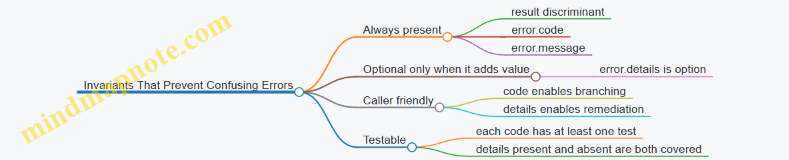
With these choices, your WIT interfaces communicate intent clearly: option means “missing but normal,” result means “failure,” and the error payload provides enough structure to handle failures without parsing fragile strings.
5.3 Variants with Multiple Cases and Payloads
Variants let an interface express “one of several shapes,” where each case can carry its own payload. In WIT, this is typically modeled as a variant with named cases. In the canonical ABI, the key job is to represent which case is active and to serialize the payload in a way that the callee and caller agree on.
Core Concept: Case Tag Plus Payload
A variant value has two parts:
- A discriminant that identifies the active case.
- A payload whose type depends on that case.
Best practice: keep payload types simple and stable. If you need rich data, prefer records inside the payload rather than mixing unrelated fields across cases.
Canonical ABI Representation Rules
Canonical ABI lowering and lifting for variants follows a consistent pattern:
- The case tag is encoded as an integer-like value.
- The payload is encoded using the canonical rules for the payload type of that case.
- The overall representation is sized to fit the largest payload among the cases, or uses an equivalent canonical layout strategy defined by the ABI.
Practical implication: even if only one case is used at runtime, the ABI layout must still be able to carry any case payload. That’s why interface design affects performance.
Designing Variants That Behave Well
When you design a variant with multiple cases and payloads, you’re really designing three things: the tag mapping, the payload shapes, and the error-handling story.
Case naming and stability. Case names become part of the contract. Renaming a case breaks compatibility even if the payload types stay the same.
Payload symmetry. If cases have wildly different payload sizes, the ABI representation may reserve space for the largest one. Keeping payloads reasonably aligned reduces overhead.
Avoid “empty payload” confusion. If a case carries no data, model it explicitly as a unit-like payload rather than omitting fields. That makes the tag-only case unambiguous.
Mind Map: Variant Contract to Canonical ABI
Example: A Command Variant with Payloads
Consider a command interface where the caller can request different actions. Each case carries its own payload.
WIT Shape
Pinghas no payload.SetNamecarries astring.AddNumberscarries a record with twou32fields.
The caller sends a single variant value. The callee reads the tag, then decodes the payload according to the matching case.
Reasoning Through One Call
- Caller constructs the variant with case
SetName. - Canonical ABI lowering encodes the tag for
SetName. - The payload encoder applies canonical string rules.
- Callee lifts the tag, selects
SetName, then lifts the string payload. - Callee executes the action using the decoded payload.
If the tag were wrong, the callee would decode bytes using the wrong payload type, producing incorrect results. That’s why tag correctness is non-negotiable.
Example: Variant Payloads with Nested Records
A common pattern is a variant whose payload is a record. This keeps the payload self-describing and reduces the chance of mixing fields.
Example payload idea:
Writecase payload:{ path: string, bytes: list<u8> }Deletecase payload:{ path: string }
Even though both cases share path, they remain separate payload shapes. That separation makes it clear which fields are required for each case.
Correctness and Validation Practices
- Validate tag values on lifting. If a host or guest produces an invalid tag, treat it as a contract violation rather than guessing.
- Keep payload decoding deterministic. Don’t rely on implicit defaults for missing fields; the payload type defines what must be present.
- Use explicit unit payloads for tag-only cases so the ABI layout and lifting logic stay consistent.
Worked Mini-Scenario: Mixed Payload Sizes
Suppose Ping has no payload, SetName has a string, and AddNumbers has a small record. The ABI must still represent all cases. The practical design takeaway is to avoid adding a huge payload case alongside small ones unless you truly need it; otherwise, the variant representation tends to be dominated by the largest payload.
Summary
Variants with multiple cases and payloads are a clean way to express “one of several typed messages.” The canonical ABI’s job is to make the tag and payload encoding unambiguous across languages. Good interface design—stable case names, explicit unit payloads, and payloads structured as records—keeps both correctness and performance under control.
5.4 Canonical ABI Behavior for Empty and Unit Types
Empty and unit types look boring until you cross a boundary and discover that “no data” still has rules. Canonical ABI needs deterministic behavior so both sides agree on what bytes exist, what pointers mean, and what “nothing” costs.
Core Idea for Empty and Unit
A unit value represents “exactly one possible value.” In practice, it carries no payload, but it still exists as a value that can be passed, returned, or stored.
An empty type represents “no possible values.” You cannot construct one on the guest side, so any function that claims to return empty must be unreachable at runtime.
Canonical ABI must therefore define:
- How the boundary encodes unit so it has a stable, zero-footprint representation.
- How the boundary treats empty so it cannot be confused with a real payload.
- How lifting and lowering behave when there is nothing to convert.
Mind Map: Empty and Unit Across the Boundary
Unit Lowering and Lifting Rules
For unit, canonical ABI uses a representation that requires no payload bytes. That means:
- Lowering unit to the host does not allocate memory and does not write a string or buffer.
- Lifting unit from the host does not read memory.
Even though there are no bytes, the call still has to follow the ABI’s calling convention. Think of unit as “a return register that is always considered valid.” The important part is that both sides agree that the unit value does not depend on any pointer or length.
A practical example is a function that performs an action and returns unit:
// Guest side concept
fn record_event() -> () {
// do work
}
On the host side, the binding code should treat the return as “unit succeeded,” with no attempt to dereference any returned pointer.
Unit in Composite Signatures
Unit becomes more interesting when it appears inside records, results, or lists.
- In a record, a unit field contributes no payload bytes, but the record still has a deterministic layout because the ABI defines offsets for each field. The unit field’s “offset” is effectively a no-op.
- In a result,
result<unit, E>means theokbranch carries no payload. Theerrbranch carries the error payload, so the ABI must still encode which branch is active.
Here is a conceptual shape for a result that returns either unit or an error record:
interface audit {
record error { code: u32 }
result<unit, error> log(string msg)
}
The ABI must encode the discriminant for result even though the unit branch has no payload. That discriminant is the only “data” needed to interpret the call.
Empty Type Behavior and Unreachable Paths
For empty, canonical ABI cannot invent a value. If a function signature says it returns empty, the only valid runtime behavior is that the function never returns normally.
So the boundary behavior is:
- Lowering an empty value is impossible because you cannot construct one.
- Lifting an empty return must treat any “normal return” as a contract violation.
In practice, bindings typically map this to a trap or an unreachable signal. The key is that the host must not interpret some random bytes as an empty value.
A conceptual example is a function that validates input and either returns nothing (unit) or aborts (empty):
interface validator {
// If valid, returns unit. If invalid, does not return.
validate(string input) -> unit
}
If you instead model invalid as empty, you would be saying “invalid is impossible to represent as a value,” which pushes the responsibility to runtime control flow. Canonical ABI then expects the guest to trap or otherwise prevent a normal return.
Testing Empty and Unit Correctly
Good tests focus on what the boundary can observe:
- For unit, assert that the host sees success without any pointer dereference or buffer reads.
- For empty, assert that the host observes an unreachable outcome when the guest violates the contract.
A simple unit test checks that the call completes and that no output buffers are touched. An empty test checks that the call does not produce a usable value and that the failure mode is consistent with the binding’s unreachable handling.
Summary of the Behavior
Unit is encoded as “no payload, always valid,” while empty is encoded as “no payload, but normal return is impossible.” Canonical ABI keeps both sides aligned by making unit independent of memory and making empty dependent on unreachable control flow rather than on any bytes that could be misinterpreted.
5.5 Worked Example: Implementing a Typed Error Contract
We’ll build a tiny component interface that returns either a success value or a typed error. The goal is to make error handling predictable across languages by using WIT types and the canonical ABI’s rules for lifting and lowering.
Step 1: Define the Contract in WIT
Start with a single function that takes an input and returns a result.
- Success payload: a record with a computed value.
- Error payload: a record with a stable error code and a message.
Mind the shape: stable field names and explicit types make generated bindings consistent.
package calc:[email protected];
interface calc {
type Error = record {
code: u32,
message: string,
};
type Ok = record {
value: u32,
};
type Outcome = result<Ok, Error>;
fn compute(input: u32) -> Outcome;
}
Best practice: keep the error record fields simple and language-agnostic. A string is fine, but avoid embedding complex nested structures in the error unless you really need them.
Step 2: Decide Error Semantics
Define the rules your component follows.
- If
input == 0, returnerrwithcode = 1and message “zero input”. - If
inputis even, returnokwithvalue = input / 2. - If
inputis odd and nonzero, returnerrwithcode = 2and message “odd input”.
This gives you deterministic behavior for tests and makes it easy to verify that lifting and lowering preserve the error payload.
Step 3: Implement the Component Logic
Below is a Rust-like sketch showing the mapping between WIT result and native error handling. The exact syntax depends on your toolchain, but the structure is the key.
fn compute(input: u32) -> Outcome {
if input == 0 {
return Outcome::Err(Error {
code: 1,
message: "zero input".to_string(),
});
}
if input % 2 == 0 {
return Outcome::Ok(Ok { value: input / 2 });
}
Outcome::Err(Error {
code: 2,
message: "odd input".to_string(),
})
}
Best practice: construct the error record in one place so you don’t accidentally vary messages across call sites. The canonical ABI will faithfully transport what you return.
Step 4: Understand Canonical ABI Behavior for result
A WIT result<Ok, Error> becomes a canonical representation that distinguishes success from failure and carries the payload.
- The boundary needs a tag indicating which side is active.
- For record payloads, each field is lowered using canonical rules.
- For
string, the lowering uses the canonical string representation, and lifting reconstructs the host string type.
Practical implication: you can treat the error as data, not as control flow. The host receives a typed error record, not a generic exception.
Step 5: Host Side Handling with Typed Errors
On the host, you should pattern-match on the result and read the error fields directly.
outcome = component.compute(3)
if outcome is Ok:
print(outcome.value)
else:
print(outcome.code)
print(outcome.message)
Best practice: avoid converting the error into a string early. Keep code and message separate so callers can branch on code without parsing text.
Step 6: Mind Map of the Error Contract Pipeline
Mind Map: Typed Error Contract Pipeline
Step 7: Worked Test Cases
Use three inputs to cover both branches and the edge case.
- Input
0→Err { code: 1, message: "zero input" } - Input
2→Ok { value: 1 } - Input
3→Err { code: 2, message: "odd input" }
Best practice: assert both code and message in tests. If a mismatch appears, it’s usually a contract shape issue or a string encoding/lifetime issue, not a logic bug.
Step 8: Common Pitfalls and How This Contract Avoids Them
- Unstable error shapes: changing field names breaks generated bindings. This contract fixes the shape up front.
- Overly clever error types: mixing multiple error representations forces host-side guessing. Here, every failure is the same
Errorrecord. - Throwing errors across the boundary: canonical ABI transports data, so return
resultvalues instead of relying on host exceptions.
That’s the full loop: define a typed error contract in WIT, implement it deterministically, and handle it on the host as structured data with predictable canonical ABI behavior.
6. Component Linking with WIT Worlds and Bindings
6.1 Worlds Imports Exports and How Linking Resolves Them
A WIT world is the unit of composition: it declares what a component expects from its environment (imports) and what it provides to its environment (exports). Linking is the process of connecting these expectations to actual implementations, while ensuring the interface shapes match closely enough that data can be converted safely.
Core Concepts That Make Linking Work
A world typically contains one or more interfaces. Each interface defines functions and types. When you write a world, you are essentially writing a contract for two directions:
- Imports: names the component will call on the outside.
- Exports: names the component offers for the outside to call.
The key detail is that linking does not “guess” semantics. It resolves by interface identity and member names, then checks that the signatures are compatible under the canonical ABI rules.
Mind Map: World Composition and Resolution
How Linking Resolves Imports
Consider a component that needs a clock service. In WIT terms, the world declares an import interface like clock with a function now. The component’s generated bindings will expect a callable target for clock:now.
When you link, you provide another component (or host binding) that exports the required interface and function. Linking then performs three checks:
- Interface match: the imported interface identity must correspond to an exported one.
- Member match: the function name must exist on the exported interface.
- Signature match: parameter and result types must be compatible so canonical ABI lowering and lifting can be applied.
If any check fails, linking fails early. This is intentional: it prevents runtime surprises where the callee and caller disagree about how strings, lists, or variants are represented.
Example: Import Resolution for a Clock
package demo:clock
interface clock {
now: func() -> u64
}
world app {
import clock
export app
}
interface app {
tick: func() -> u64
}
In this setup, app imports clock. The tick export can call clock:now internally. Linking must connect clock from an external provider to the import slot.
How Linking Resolves Exports
Exports are the reverse direction. When you link an “app” component into a host, the host needs to call app:tick. The host does not care how tick is implemented; it cares that the exported interface exists and that the signature matches what the host expects.
Export resolution also triggers canonical ABI conversions. If the host passes a string or list, the runtime must translate it into the representation expected by the component, and translate results back.
Mind Map: Export Visibility to the Host
The Practical Linking Pipeline
A useful way to think about linking is as a pipeline with checkpoints:
- World selection: you choose which world a component implements.
- Import wiring: for each import, you locate an export that satisfies it.
- Compatibility validation: you verify member names and type shapes.
- ABI glue insertion: the runtime prepares conversions for each call boundary.
- Instantiation: the component is instantiated with the wired dependencies.
The “ABI glue insertion” step is where canonical ABI matters. Even if two languages both claim to use “strings,” they still need a shared rule for how those strings are passed across the boundary.
Example: Two Components Linked by a Shared Interface
package demo:kv
interface store {
get: func(key: string) -> option<string>
}
world producer {
export store
}
world consumer {
import store
export consumer
}
interface consumer {
read: func(key: string) -> option<string>
}
- The producer component exports
store:get. - The consumer component imports
storeso itsreadcan callstore:get.
During linking, the consumer’s import store:get is resolved to the producer’s export store:get. The runtime then ensures that option<string> is represented consistently across the call boundary.
Common Failure Modes and What They Mean
Linking errors are usually precise. A few patterns help interpret them:
- Missing export: the provider world does not export the required interface.
- Member name mismatch: the interface matches, but a function name differs.
- Type shape mismatch: the names match, but a parameter or result type differs in a way that breaks canonical ABI conversion.
When you see these, the fix is almost always in the WIT contract: align interface identity, member names, and type shapes so linking can do its job without guesswork.
6.2 Generating Bindings for Multiple Languages
Bindings are the glue between a WIT-defined interface and the host language’s types. The goal is simple: when your component calls an imported function or exports one, the generated code must translate values and errors according to the Canonical ABI rules, without you writing a custom marshalling layer for every language.
What Bindings Generation Produces
A typical generation run yields three things:
- Type-safe signatures that mirror the WIT world’s functions and types.
- Conversion code that maps language values to the canonical representation (for example, strings, lists, records, and variants).
- Linking glue that connects the generated stubs to the component’s imports and exports.
A practical best practice is to treat the generated bindings as part of your contract surface. If you change the WIT, regenerate bindings and run tests that exercise boundary conversions.
Step-by-Step Workflow Across Languages
Start from the WIT Shape
Bindings generation is only as good as the interface shape. Prefer clear, explicit types:
- Use records for structured data.
- Use variants for tagged outcomes.
- Use option and result for absence and failure.
This keeps the generated code predictable and reduces “mystery conversions.”
Choose the Target Language Bindings
Different languages have different idioms, but the generator should preserve the WIT meaning. For example, a WIT result<T, E> becomes a language-level success/error pattern that still carries the same payload types.
When you compare generated code across languages, focus on two invariants:
- Type mapping matches the WIT definition (no silent coercions).
- Error payloads preserve structure (especially for variants and records).
Generate Bindings for Each Language
Run the generator for each language you want to support. Keep the WIT package version pinned in your build so that all languages compile against the same contract.
A small but effective practice: generate into language-specific directories and commit the generated artifacts only if your team’s workflow requires it. Otherwise, generate in CI and fail the build if regeneration changes outputs.
Implement Exports Using Generated Types
In the component implementation, write business logic using the generated types. That way, conversions happen at the boundary, not throughout your codebase.
For example, if your WIT exports fn compute(input: record) -> result<record, error>, your implementation should return the generated result type directly.
Use Generated Imports in the Host
On the host side, generated imports become callable functions with the correct parameter and return types. The host should not manually pack canonical ABI values; it should pass language-level values and let the bindings do the translation.
Mind Map: Binding Generation Pipeline
Example: One WIT Contract, Two Language Bindings
Imagine a WIT world that defines a simple greeting service:
greet(name: string) -> result<string, GreetingError>GreetingErroris a variant with cases likeEmptyNameandTooLong
Language Implementation Pattern
In each language, you implement the exported greet using the generated types:
- Accept a language string.
- Validate it.
- Return a success string or a generated error variant.
The bindings handle:
- String encoding and length handling.
- Variant tagging and payload mapping.
- Lifting/lowering across the component boundary.
Host Calling Pattern
The host calls the generated import:
- Pass a language string.
- Receive a generated result type.
- Pattern match on success versus error.
This keeps the host logic readable while still enforcing the contract.
Advanced Details That Matter in Practice
Deterministic Type Behavior
If your WIT uses records with multiple fields, ensure your language-side construction sets every field explicitly. Generated code typically assumes full initialization; leaving fields unset can lead to runtime errors or incorrect payloads.
Variant Case Coverage
When a WIT variant has multiple cases, generated code often expects exhaustive handling in languages that support it. Even in languages without exhaustiveness checks, write explicit branches for each case so you don’t accidentally treat an error as a success.
Buffer and String Lifetimes
Bindings for strings and lists must manage ownership rules consistent with the Canonical ABI. The practical takeaway: treat generated parameters and return values as normal language values, and don’t try to reuse internal buffers across calls unless the generated API explicitly supports it.
Quick Checklist Before You Ship
- Regenerate bindings after every WIT change.
- Implement exports using generated types, not hand-rolled conversions.
- In the host, call generated imports and pattern match on generated results.
- Add tests that cover at least one success path and one error path for each variant case.
That’s the whole point of multi-language bindings: you write the contract once, then let the generator enforce the boundary rules consistently across languages.
6.3 Mapping Interface Names to Host and Guest Symbols
When you write a WIT interface, you’re describing what a component expects and provides. Mapping interface names to host and guest symbols is about how those expectations become callable functions and accessible values in each side of the boundary. The goal is simple: the same WIT contract should produce predictable symbol names and predictable calling behavior, even when the host and guest are written in different languages.
Core Idea: Names Are Contracts
WIT names form a stable identity for items like functions, records, and types. During linking, the runtime uses those names to match imports and exports. Binding generators then translate WIT items into language-level symbols. If the mapping is inconsistent, you get failures that look like “missing export” or “wrong signature,” even though the WIT file is correct.
A practical way to think about it is three layers:
- WIT identity: package, world, interface, and item names.
- Component linking identity: the runtime’s import/export matching keys.
- Language symbols: function names, method names, and module paths in the generated bindings.
Step 1: Understand the Linking Key
At link time, the runtime resolves a guest’s exports against a host’s imports. The matching key is derived from the WIT world and the interface item names. That means you should treat WIT item names as part of your public API surface.
Best practice: keep interface item names stable and avoid renaming after you have multiple components depending on them. If you must rename, create a new function name and keep the old one as a thin adapter for a while.
Step 2: Predict the Generated Symbol Shape
Binding generators typically follow a deterministic naming scheme:
- Function exports/imports become language functions.
- Records and variants become language structs/enums or equivalent types.
- Namespaces from WIT packages and interfaces become module or type prefixes.
The exact scheme varies by language, but the principle stays: the generator uses WIT names to avoid collisions and to keep the mapping reversible.
Best practice: choose WIT names that are valid and idiomatic in your target languages. For example, avoid characters that force heavy escaping or create awkward identifiers.
Step 3: Handle Host Versus Guest Direction
Mapping differs depending on whether you’re implementing the interface in the guest or the host.
- Guest exports: the guest must provide functions with the expected ABI behavior. The generated bindings usually call into your implementation via a wrapper.
- Host imports: the host must provide functions that the guest can call. The generated host stubs translate from canonical ABI representations into host language values.
A common mistake is to implement the host function with the right logic but the wrong signature shape. The generator may compile, but the runtime will fail when it tries to lift/lower parameters.
Step 4: Make Symbol Mapping Visible with a Naming Checklist
Use a checklist to verify that the mapping is consistent across layers:
- The WIT function name matches the import/export name.
- The parameter and result types match exactly, including option/result wrappers.
- The host implementation is wired to the generated stub, not a hand-written function with a similar signature.
- Any module or namespace prefix in the generated code matches your build layout.
Mind Map: Mapping Interface Names to Symbols
Example: A Small Interface and Its Mapping
Suppose your WIT world defines a function add in an interface math:
- WIT:
math.add(a: u32, b: u32) -> u32 - Linking: guest exports
math.add, host importsmath.add - Binding symbols:
- Guest side: a generated function like
math_addoraddinside amathmodule - Host side: a generated import stub that calls your host handler
- Guest side: a generated function like
Best practice: implement the host handler by delegating to the generated stub’s expected entry point. If you bypass the stub, you risk skipping the canonical ABI lifting step for parameters and results.
Example: Debugging a Name Mismatch Without Guesswork
If linking fails, treat it as a mapping problem first, not a logic problem. A systematic approach:
- Confirm the WIT item name is identical on both sides.
- Confirm the world and interface are the same, not just the function name.
- Confirm the host is providing the generated import stub, not a similarly named function.
- Confirm the parameter and result types match exactly, including wrappers.
When you follow this order, you avoid the classic trap of rewriting the function body while the runtime is still unable to find the correct symbol to call.
6.4 Composing Components with Shared Interfaces
Composing components with shared interfaces means multiple components agree on the same WIT contract, so you can swap implementations without rewriting the rest of the system. The trick is to keep the interface stable while allowing each component to own its internal details, including memory management and error formatting.
Shared Interface as the System Spine
Start by treating the WIT interface as the “spine” that connects components. If two components both implement the same world exports, they can be linked into the same host wiring with no changes to the host. This works best when the interface describes behavior and data shapes, not how the component stores state.
A practical rule: design interfaces around operations that are meaningful across languages. For example, a store component should expose put and get rather than exposing internal maps, file handles, or database clients.
Mind Map: Composition Strategy
A Shared World and Two Implementations
Define a small shared world that both components implement. The world exports a process function that takes input bytes and returns output bytes plus a typed result.
Example: shared WIT contract
package demo:processor
interface processor {
process: func(input: list<u8>) -> result<list<u8>, string>
}
world processor-world {
export processor
}
Now create two components that export the same processor-world. One might compress data, the other might encrypt it. The host never needs to know which one it is using.
Example: component A and component B behavior
Component A
- process: returns input with a simple transformation
- error: returns result::err("bad input")
Component B
- process: returns input with a different transformation
- error: returns result::err("unsupported format")
Even though the error strings differ, the host still handles errors uniformly because the interface says the error type is string.
Linking: Host Wiring Without Interface Changes
When composing, the host imports the shared world and links it to any component that exports the same world. The host’s code stays the same because it calls process through the canonical ABI boundary.
A common best practice is to keep the host wiring logic separate from business logic. That way, swapping implementations is a configuration change, not a code change.
Example: host composition flow
1) Host imports processor-world
2) Host selects an implementation component artifact
3) Runtime links exports to imports
4) Host calls process(input)
5) Host receives canonical ABI converted list<u8> and result
Composing Multiple Components in a Pipeline
Shared interfaces also help when components are chained. You can define a second shared interface for each stage, or reuse the same interface if the output shape matches the input shape.
If both stages accept list<u8> and return result<list<u8>, string>, you can reuse the same shared world and treat each stage as a plug-in.
Example: two-stage pipeline
Stage 1: processor-world
- output bytes become Stage 2 input bytes
Stage 2: processor-world
- returns final bytes or an error
Host behavior
- call Stage 1
- if Ok, call Stage 2
- if Err, stop and return the error
This pattern reduces interface proliferation. The cost is that you must ensure the shared contract truly matches the data flow between stages.
Data Boundary Discipline That Keeps Composition Honest
Composition breaks when components assume shared memory or rely on implicit lifetime rules. Canonical ABI exists to prevent that, but you still need to follow the contract.
Best practices:
- Treat returned
list<u8>as owned by the caller after the call. Don’t stash pointers into component memory. - Keep error handling consistent with the interface type. If the interface says
string, don’t smuggle structured errors through ad-hoc encodings. - Prefer explicit transformations at the boundary. If a component needs to parse structured data, it should do so internally and return bytes in the agreed format.
Validation: Contract Tests for Shared Interfaces
Before composing, validate that each implementation matches the shared interface behavior. Interface compatibility checks confirm signatures match; contract tests confirm semantics match.
A minimal test set for the shared process contract:
- Round trip: known input produces expected output bytes.
- Error path: invalid input returns
result::errwith the correct error type. - Boundary sizes: empty input and large input behave without panics or truncated buffers.
With these in place, composing components becomes a matter of wiring, not guesswork. The shared interface does the heavy lifting, and the components stay free to be different inside.
6.5 Practical Linking Example with a Two Component Pipeline
A two component pipeline is the smallest setup that still shows real linking behavior: one component produces data, the next consumes it, and the boundary is defined by a WIT interface. The goal is to keep the interface stable while each component can be written in a different language or compiled separately.
The Pipeline Scenario
We will build:
- Producer component: accepts a request and returns a payload.
- Consumer component: accepts that payload and returns a transformed result.
To keep the example concrete, the payload will be a byte buffer representing UTF-8 text. The producer will return "hello" plus a suffix; the consumer will uppercase it.
Mind Map: Two Component Linking Flow
Step 1: Define the WIT Interface
The interface should describe exactly what crosses the boundary. Here we define a single world with two functions: one for producing payloads and one for consuming them. In practice, you may split these into separate interfaces, but keeping them together makes the linking story easier to follow.
Mind Map: Interface Shape Choices
- WIT Interface Design
- Use `string` for human input
- Use `bytes` for opaque payload
- Keep function signatures symmetric
- Producer: request -> bytes
- Consumer: bytes -> bytes
- Prefer `result` for failures
- `result`
- Avoid implicit state
- No hidden globals in the interface
Step 2: Producer Component Implementation
The producer exports a function that takes a string and returns bytes. The implementation can be simple: build a new string, encode it as UTF-8, and return the bytes.
Best practice: treat the returned bytes as owned by the ABI boundary. The canonical ABI will handle the conversion into the consumer’s expected representation.
Example: Producer Logic
- Input:
request = "world" - Producer output bytes:
"hello world"
Step 3: Consumer Component Implementation
The consumer imports the producer function and uses it inside its own exported run function. The consumer’s run takes a string, calls the producer to get bytes, uppercases the text, and returns bytes.
Best practice: keep the consumer’s transformation deterministic. If you later add error handling, it should be explicit in the WIT signature rather than hidden behind panics or host-specific behavior.
Example: Consumer Logic
- Input:
input = "world" - Calls producer: returns bytes for
"hello world" - Uppercases:
"HELLO WORLD" - Returns bytes for
"HELLO WORLD"
Step 4: Host Instantiation and Linking
The host is responsible for instantiating components and wiring imports to exports. Conceptually:
- Instantiate Producer.
- Instantiate Consumer.
- Link Consumer’s imported function to Producer’s exported function.
This is where interface compatibility matters. If the WIT signatures disagree even slightly, the canonical ABI conversions won’t match and linking fails.
Mind Map: Linking Responsibilities
Step 5: Canonical ABI Details That Matter Here
Even though the example is small, the canonical ABI rules explain why the interface uses string and bytes rather than raw pointers.
- Crossing the boundary converts
stringinto the consumer’s expected representation. - Crossing the boundary converts
bytesinto the consumer’s expected representation. - Ownership is governed by the ABI contract, so you avoid guessing who frees what.
Best practice: avoid designing interfaces that require the guest to return a pointer into its linear memory. Use bytes and let the ABI handle the safe transfer.
Step 6: End-to-End Walkthrough
Assume the host runs the consumer’s run export.
- Host calls
consumer.run("world"). - Consumer calls imported
producer.handle("world"). - Producer returns bytes for
"hello world". - Consumer uppercases and returns bytes for
"HELLO WORLD". - Host receives the final bytes and can decode them as UTF-8.
Example: Expected Output
- Final output bytes decode to:
HELLO WORLD
Step 7: Common Linking Pitfalls
- Name mismatch: the WIT function name must match what the consumer imports.
- Type mismatch:
stringvsbytesis not interchangeable. - Shape mismatch: changing the interface signature requires rebuilding both sides.
- Error modeling omission: if you add failures later, update the WIT signature and keep the error payload type stable.
This pipeline is intentionally small, but it exercises the core mechanics: interface-driven linking, canonical ABI conversions for string and bytes, and host-mediated composition of independently built components.
7. Tooling Workflow from WIT to Build Artifacts
7.1 Project Layout for WIT Packages and Component Sources
A good project layout makes interface changes boring. When you edit WIT, you want the build to reliably regenerate bindings, recompile component sources, and fail fast if something no longer matches. The layout below keeps WIT definitions, generated code, and hand-written component logic in separate, predictable places.
Core Directory Strategy
Use three top-level areas: wit/ for interface definitions, crates/ (or src/) for component implementations, and target/ for generated artifacts. Keep the host code separate from guest components so that interface evolution doesn’t accidentally couple them.
A practical structure looks like this:
wit/packages/for reusable WIT packagesworlds/for world definitions that bundle imports and exports
crates/component-foo/for a guest component implementationcomponent-bar/for another guest component implementationhost/for the runtime embedding and linking logic
target/for generated bindings and build outputs
WIT Packages and Worlds
Treat a WIT package as the unit of reuse. Put shared types and interface definitions there, and avoid mixing unrelated domains. Worlds are the unit of composition: they describe what a component expects and provides.
Inside wit/packages/, group by package name and version-like intent (even if you don’t encode versions in the filesystem, the grouping helps humans). For example, a logging contract might live in wit/packages/logging/ while a storage contract lives in wit/packages/storage/.
Inside wit/worlds/, define a world per composition scenario. A world can import multiple packages and export a single cohesive surface.
Source Organization for Components
Each component crate should contain:
src/lib.rsorsrc/main.rswith the component implementation- a small module that adapts between your internal types and the generated bindings
- tests that validate the adapter logic using representative values
Keep the adapter thin. If your internal model is User { id, email }, the adapter should map it to the WIT record shape and handle Option and Result conversions. That way, when the WIT record changes, the compiler points you to one place.
Build Integration and Regeneration
Bindings generation should be deterministic and driven by the WIT files, not by manual edits to generated code. Your build should:
- Locate WIT packages and worlds
- Generate bindings into
target/(or a dedicated generated directory) - Compile component crates against those bindings
- Fail if the WIT contract and implementation disagree
A common best practice is to never commit generated bindings. If you do commit them, you risk stale code silently surviving interface edits.
Mind Map: Project Layout
Example: Minimal Layout for Two Components
Imagine a pipeline where component-foo transforms input bytes and component-bar stores results. Both share a storage package for a put interface.
wit/packages/storage/storage.wit- defines
put(record)and error types
- defines
wit/worlds/pipeline/pipeline.wit- imports
storageand exportstransform-and-store
- imports
crates/component-foo/- implements the transformation logic
- adapts to the WIT types used by the world
crates/component-bar/- implements the storage logic
- adapts to the same WIT contract
crates/host/- links
component-fooandcomponent-barinto thepipelineworld
- links
Mind Map: Data Flow Through the Adapter
Practical Rules That Prevent Pain
- Put WIT in one place and component code in another; mixing them makes diffs noisy.
- Keep adapters small and test them directly; it’s easier than debugging a failing link.
- Name worlds by the composition purpose, not by the implementation detail.
- Keep host wiring separate so guest components remain language-agnostic in their structure.
If you follow these rules, interface edits become a controlled change: WIT updates regenerate bindings, adapters recompile, and linking either succeeds with matching shapes or fails with a clear mismatch.
7.2 Using Interface Definitions to Drive Code Generation
Interface definitions are the source of truth for component boundaries. Code generation turns that truth into language-specific types and glue code, so you stop hand-writing conversions and start enforcing contracts. The trick is to treat the generated layer as a deterministic translation pipeline: WIT types become host/guest representations, and the generator emits the boring parts consistently.
From WIT Shapes to Generated APIs
Start with a WIT package that declares a world and one or more interfaces. The generator reads the WIT and produces:
- Language types that mirror WIT records, variants, options, and results.
- Stubs and adapters that translate between language-native values and the canonical ABI representation.
- Linking entry points that match the world’s imports and exports.
A practical way to think about it: WIT defines what crosses the boundary; generated code defines how values are represented and moved.
Mind Map: Interface Definitions to Code Generation
A Minimal WIT Contract That Generates Clean Types
Consider a tiny interface for a calculator service. The WIT contract might include a function that returns a result type rather than throwing exceptions.
package example:calc
interface math {
add: func(a: u32, b: u32) -> u32
divide: func(a: u32, b: u32) -> result<u32, string>
}
world app {
export math
}
When you generate bindings, you should expect the target language to expose:
add(a, b) -> u32as a direct call.divide(a, b) -> Result<u32, String>(or the language equivalent).
Best practice: model errors as part of the signature. That keeps error handling explicit in both the guest implementation and the host caller.
How Generation Handles Canonical ABI Details
You generally do not write canonical ABI code by hand. The generator emits adapters that:
- Convert WIT strings into the target language’s string type using the canonical ABI’s expected representation.
- Convert WIT lists into a pair of pointer/length style representations, then back.
- Convert WIT variants into tagged representations that preserve case identity.
- Convert WIT results into the target language’s success/error types.
This matters because it makes your business logic look like normal code. The generated layer is where the boundary rules live.
Workflow: Regenerate, Then Implement
A systematic workflow prevents “drift” between WIT and implementation.
- Write or edit WIT so the interface expresses the contract you want.
- Regenerate bindings for each language target.
- Implement only the generated trait or interface in the guest.
- Compile to catch mismatches early.
- Link components and run integration tests.
If you change WIT, regeneration should be the first step. Treat compilation errors as a helpful map of what needs updating.
Mind Map: What Changes When WIT Changes
Example: Implementing the Generated Export in a Guest
The exact syntax varies by language, but the pattern is consistent: you implement the generated export surface, and the generator handles ABI translation.
// Pseudocode shape of generated expectations
// Implement the generated trait for the world export.
struct MathImpl;
impl math::Math for MathImpl {
fn add(&self, a: u32, b: u32) -> u32 {
a + b
}
fn divide(&self, a: u32, b: u32) -> Result<u32, String> {
if b == 0 {
Err("division by zero".to_string())
} else {
Ok(a / b)
}
}
}
Notice what’s missing: no manual pointer juggling, no string encoding logic, no tag decoding. Those are handled by the generated wrappers.
Practical Best Practices for Code Generation
- Keep interface names stable: renaming forces regeneration and increases the chance of linking mismatches.
- Prefer explicit error payload types:
result<T, string>is clearer than “panic-style” failures. - Use small interfaces: smaller contracts generate smaller, easier-to-review glue.
- Regenerate in CI: ensure generated code matches the committed WIT.
Advanced Detail: Controlling Generated Shapes Through WIT
When you model data in WIT, you’re also controlling how the generator represents it. For example, choosing a record versus a tuple-like structure affects readability of generated types. Choosing option<T> versus result<T, E> affects whether absence is treated as a normal state or an error.
The goal is not to make WIT “look nice”; it’s to make the generated API match how you want to reason about data and failures in your implementation language.
7.3 Build Steps for Component Artifacts and Dependency Graphs
A reliable build for component artifacts starts with a simple rule: treat the WIT package graph as the source of truth, then generate everything else from it. That keeps interface drift from turning into “works on my machine” drift.
Step 1: Establish the Source Graph
Begin by listing every WIT package you own and every world you implement. In practice, you want three sets:
- Interface sources:
.witfiles that define packages, interfaces, and worlds. - Component implementations: language code that exports or imports those interfaces.
- Host bindings: code that wires host functions to imported interfaces.
A good build script reads WIT first, then decides what to generate. If you generate bindings before you know which worlds are in play, you’ll regenerate later and waste time.
Step 2: Normalize WIT Inputs
Before generation, normalize your WIT inputs into a consistent layout. Common best practices:
- Keep package names stable and avoid renaming after code generation.
- Ensure every world has a clear import/export boundary.
- Pin the WIT directory structure so the build can locate packages deterministically.
This is where you catch mismatches early, such as a world expecting result<string, error> while an implementation returns a different error record.
Step 3: Generate Bindings from WIT
Bindings generation is deterministic if you feed it the same WIT inputs and target language settings. The build should:
- Generate bindings for each implementation target.
- Generate host-side bindings for each world that the host instantiates.
- Record the generated output paths so later steps can depend on them.
A practical habit: commit generated bindings only when your team agrees on it; otherwise, generate them during the build and cache them.
Step 4: Compile Language Code into Component Artifacts
Now compile each implementation into a component artifact. The key is to ensure the compiler sees the same generated bindings the linker will later use.
For correctness, treat each component as having two “contracts”:
- Type contract: matches the WIT interface shapes.
- Link contract: matches the world’s import/export names.
If either contract changes, the build should rebuild the affected component and any dependents.
Step 5: Build the Dependency Graph and Topologically Order Linking
Linking order matters because components can depend on other components through imported worlds. Model dependencies explicitly so your build system can link in a stable order.
Dependency Graph Mind Map
Step 6: Validate Interface Compatibility Before Linking
Before you link, run a compatibility check that compares:
- Exported functions and their signatures.
- Record and variant shapes.
- Error payload types.
- Expected canonical ABI conversions for strings and buffers.
This check prevents a common failure mode: the linker may accept the shape superficially, but canonical ABI lowering will fail at runtime when lifetimes or ownership assumptions don’t match.
Step 7: Link Components into a Final Instantiation Graph
Linking produces a component that can be instantiated by a host. In a multi-component pipeline, each stage exports a world that the next stage imports.
Linking Mind Map
Step 8: Example Build Plan for a Two-Component Pipeline
Example:
Goal: Component B consumes Component A via a shared WIT world.
1) Read wit/ directory
2) Generate bindings for A and B
3) Compile A -> target/a-component.wasm
4) Compile B -> target/b-component.wasm
5) Validate A exports match B imports
6) Link B with A -> target/pipeline-component.wasm
7) Run pipeline tests with a host that supplies remaining imports
Step 9: Make Rebuilds Predictable with Dependency Edges
To avoid accidental stale artifacts, create build edges:
- Edge from WIT file changes to generated bindings.
- Edge from generated bindings to compiled component artifacts.
- Edge from compiled artifacts to linked outputs.
A simple way to visualize the edges:
flowchart TD
WIT[WIT Sources] --> GEN[Generated Bindings]
GEN --> COMP_A[Compile Component A]
GEN --> COMP_B[Compile Component B]
COMP_A --> LINK[Link Pipeline]
COMP_B --> LINK
LINK --> OUT[Final Component Artifact]
Step 10: Capture Build Metadata for Debugging
When a build fails, you want to know what changed and what was expected. Record:
- The WIT package versions or commit hashes used for generation.
- The exact world names used for linking.
- The resolved dependency graph edges.
This turns “linking failed” into “linking failed because world x exported y with a different record field order,” which is the kind of failure you can fix quickly.
With these steps, your build becomes a pipeline: WIT in, bindings generated, components compiled, compatibility validated, dependencies linked, and outputs produced in a deterministic order.
7.4 Verifying Interface Compatibility Before Linking
Before you link components, you want to know whether the WIT contracts actually match. “Compatible” here means more than “names look the same”: the interface shape, type constructors, and canonical ABI lowering rules must line up so that lifting and lowering produce the same runtime values.
Compatibility Checklist That Catches Real Failures
Start with a quick pass that rules out the common mismatch categories.
- Package and interface identity: Confirm the WIT package name and interface name are the ones you intend to connect. Two interfaces can share function names but differ in type definitions.
- World import and export roles: Imports must be satisfied by exports with the same signatures. A frequent mistake is swapping a provider and consumer world.
- Function signature equivalence: Compare parameter and result types structurally, not textually. For example,
list<u8>andstringare both “text-ish,” but they lower differently. - Type definition alignment: If a type is a
typealias in WIT, ensure both sides resolve to the same underlying definition. If one side uses a record with fields in a different order, you’ll get a mismatch. - Variant and error contract agreement: For
variant, case names and payload types must match. Forresult, theokanderrtypes must match exactly. - Resource and handle semantics: If the interface uses resources, verify that both sides agree on ownership and lifetime expectations expressed by the component model.
A practical way to think about it: linking is only safe when the canonical ABI mapping is deterministic in the same way on both sides.
Mind Map: Interface Compatibility Flow
Example: Signature Mismatch That Looks Harmless
Suppose you have a consumer expecting a function that returns a string:
- Consumer import:
fn greet(name: string) -> string - Provider export:
fn greet(name: string) -> list<u8>
Both are “bytes,” but canonical ABI lowering treats string as UTF-8 with a specific representation, while list<u8> is a length-plus-elements list. Even if the provider returns UTF-8 bytes, the consumer will lift them using the string rules and interpret the layout incorrectly.
A good verification step is to classify each type into its ABI category:
stringandlist<u8>are different categories.list<T>depends onT’s category.variantdepends on case payload categories.
Example: Record Field Order and Variant Cases
Records are structurally defined, but canonical ABI lowering depends on the exact field sequence used by the interface definition. If you define:
record Person { name: string, age: u32 }
and another component defines:
record Person { age: u32, name: string }
then the record shapes differ in a way that can’t be corrected by “same field names.” Your verification should compare the full record schema, including field order.
For variants, case names and payload types must match. If one side uses:
variant { NotFound: record { id: u64 } }
and the other uses:
variant { NotFound: u64 }
then the tag and payload layout differ, and lifting will produce the wrong case payload.
A Systematic Verification Procedure
Use this order to keep the work bounded and the errors readable.
- Extract the import signatures from the consumer world.
- Extract the export signatures from the provider world.
- Match by function name and then compare signatures.
- Recursively compare referenced types using a type graph walk.
- Normalize aliases so that
typeindirections don’t hide differences. - Check canonical ABI sensitive categories explicitly:
- strings vs lists
- record field order
- variant case payloads
- result ok/err types
- resource handle types
- Produce a mismatch report that points to the first divergence path, such as:
greet -> return type -> string vs list<u8>lookup -> err type -> result err variant case payload mismatch
Example: Minimal Compatibility Report Format
When verification fails, you want a message that tells you where to look, not just that something is wrong.
Mismatch in function greet
- Expected: greet(name: string) -> string
- Found: greet(name: string) -> list<u8>
- Type path: return type
- ABI category: string vs list<u8>
- Action: update provider export signature to return string
This format makes it easy to fix the interface definition rather than guessing at runtime behavior.
Practical Best Practices for Verification
- Keep WIT type definitions centralized so both sides import the same package types instead of re-declaring them.
- Prefer explicit record and variant schemas over ad-hoc “equivalent” shapes.
- Treat string and byte buffers as distinct types even when they carry similar data.
- Run compatibility checks as part of the build step so mismatches are caught before any linking artifacts are produced.
With these checks in place, linking becomes a mechanical step rather than a gamble.
7.5 Practical Build Script Walkthrough for Reproducible Outputs
Reproducible builds start with two questions: what inputs affect the output, and how do we prevent accidental variation. In a WIT-driven component workflow, the usual culprits are generated bindings, tool versions, file ordering, and nondeterministic build directories. The goal of this walkthrough is a build script that produces the same component artifacts from the same WIT and source tree.
Define Inputs and Outputs First
Treat the build as a function:
- Inputs:
wit/files, component source code,Cargo.lockor equivalent lockfiles, and the exact toolchain versions. - Outputs:
.wasmcomponent artifacts and generated binding code.
A practical best practice is to write down the expected output paths and fail the build if they are missing. That way, a broken generation step doesn’t silently produce stale artifacts.
Pin Tooling and Make Generation Deterministic
If your bindings are generated, generation must be deterministic. Pin versions of the code generator and the language toolchain. Also ensure the generator reads WIT files in a stable order; if your build system enumerates files, sort them.
Mind Map: Reproducible Build Script
Use a Clean Staging Directory
Stale generated code is the silent saboteur. Use a staging directory that is either cleaned every run or keyed by a content hash of the WIT directory. For simplicity, this walkthrough uses a clean directory.
Example Build Script
This example assumes a Rust guest component and a WIT-driven binding generation step. Adjust commands to match your environment, but keep the structure: set strict shell options, clean staging, generate, compile, and then hash.
#!/usr/bin/env Bash
set -euo pipefail
ROOT="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
STAGING="$ROOT/.staging"
OUT="$ROOT/dist"
rm -rf "$STAGING" "$OUT"
mkdir -p "$STAGING" "$OUT"
# 1) Validate WIT inputs exist
test -d "$ROOT/wit" || { echo "Missing wit/"; exit 1; }
# 2) Generate Bindings into Staging
# Replace GEN_CMD with your generator invocation
GEN_CMD=("wit-bindgen" "--out-dir" "$STAGING" "$ROOT/wit")
"${GEN_CMD[@]}"
# 3) Build Guest Component with Pinned Toolchain
# Use Cargo.lock and a pinned toolchain in your environment
cargo build --release --target wasm32-wasip1-threads
# 4) Copy the Final Component Artifact to Dist
cp "$ROOT/target/wasm32-wasip1-threads/release"/*.wasm "$OUT/"
The generator command is the part that most often drifts. Pin its version in your build environment and keep the flags stable. If your generator supports a “no timestamps” or “stable output” mode, use it.
Add Artifact Hashing for Proof
Hashes turn “it seems reproducible” into “it is reproducible.” After copying artifacts, compute a manifest file. On a second run, compare the manifest.
# 5) Create a Deterministic Hash Manifest
MANIFEST="$OUT/artifacts.sha256"
: > "$MANIFEST"
# Sort Filenames So the Manifest Order Is Stable
for f in $(ls -1 "$OUT"/*.wasm | sort); do
sha256sum "$f" >> "$MANIFEST"
done
echo "Wrote $MANIFEST"
Verification Loop That Catches Real Problems
Run the script twice in a row. If hashes differ, inspect which step is nondeterministic. Common causes:
- Generated bindings include absolute paths.
- Build output embeds build timestamps.
- File enumeration order differs between runs.
A practical debugging move is to hash the staging directory after generation, before compilation. If staging hashes match but final hashes differ, the nondeterminism is in compilation or packaging.
Keep the Script Self-Documenting
A build script should explain itself through structure. Use clear variable names (STAGING, OUT), keep steps numbered, and ensure every failure is loud. For example, the script above fails immediately if wit/ is missing, rather than producing empty or misleading output.
Finally, record the build date in your CI logs using a fixed example date like 2026-03-25 if you need it for traceability. The artifact hashes remain the source of truth.
8. Language Integration Patterns for Portable Components
8.1 Rust Integration With WIT Generated Bindings
Rust integration with WIT generated bindings is mostly about making the boundary boring: you define a contract once, generate bindings, and then implement the guest side in Rust with types that map cleanly to the canonical ABI. The key is to treat the generated code as the “translation layer” and keep your business logic in normal Rust types.
The Core Workflow
- Author the WIT interface for the functions and types you want to expose.
- Generate Rust bindings for the target world and interface.
- Implement the exported functions using the generated traits and types.
- Use the canonical ABI types correctly by following the generated signatures.
- Test with a small host harness to confirm that your data shapes round-trip.
A practical rule: if the generated signature says it takes a String-like wrapper or a Vec<u8>-like buffer wrapper, don’t “help” it by converting to raw pointers. Let the bindings handle the canonical ABI lowering and lifting.
Generated Types and What They Mean
WIT generation typically produces:
- Traits that your Rust component implements.
- Type aliases or wrappers for WIT-defined records, variants, options, results, and lists.
- Conversion helpers that ensure your Rust values match the ABI representation.
When you implement a function, you should see Rust types that are intentionally shaped to match the WIT contract. If you find yourself manually encoding tags for variants or building discriminated unions by hand, you’re probably fighting the bindings.
Implementing an Exported Function
Suppose your WIT defines a service with a function that takes a request record and returns a result.
// Generated trait name and types depend on your WIT.
// The important part is the signature shape.
use my_world::my_api::{MyService, Request, Response, Error};
struct MyServiceImpl;
impl MyService for MyServiceImpl {
fn handle(&self, req: Request) -> Result<Response, Error> {
// Business logic stays normal and readable.
let upper = req.message.to_uppercase();
Ok(Response { message: upper })
}
}
Best practice: keep the implementation side-effect free when possible. If you must do I/O, isolate it behind a small internal function so that your exported boundary remains easy to test.
Handling Strings and Buffers Correctly
Canonical ABI string and buffer handling is where most integration bugs hide. The generated bindings usually provide the right input/output types, but you still need to respect ownership.
- Treat incoming buffers as read-only.
- Return owned values (the bindings will lift them into the ABI representation).
- Avoid borrowing across the boundary; the generated types are designed so you don’t have to.
A common pattern is to accept a Vec<u8>-like wrapper, process it, and return a new buffer wrapper.
use my_world::my_api::{MyService, BytesRequest, BytesResponse};
struct MyServiceImpl;
impl MyService for MyServiceImpl {
fn transform(&self, req: BytesRequest) -> BytesResponse {
let mut out = req.data.clone();
out.reverse();
BytesResponse { data: out }
}
}
If cloning feels wasteful, that’s a sign you should revisit your interface shape (for example, whether you can stream or whether you can reuse buffers). But don’t optimize prematurely; first ensure correctness.
Error Modeling with Result
WIT results map naturally to Rust Result<T, E> when the generator supports it. The important part is that your error type must match the WIT error contract.
Best practice: make errors structured, not stringly. If your WIT error is a record with fields like code and message, mirror that structure in Rust so callers can branch on fields instead of parsing text.
Mind Map: Rust Integration with WIT Generated Bindings
Advanced Details That Stay Practical
Trait Implementation Boundaries
Your exported functions are called by the runtime through the generated glue. That means your Rust code should not assume a particular calling thread model unless your host guarantees it. If you need shared state, use Arc and keep synchronization explicit.
Deterministic Behavior for Tests
For interface-level tests, prefer deterministic transformations (like uppercasing, reversing, or validating a checksum). This makes it easy to confirm that canonical ABI lifting and lowering preserve the intended structure.
Debugging Type Mismatches
When linking fails, the most common cause is an interface mismatch: a record field name or type shape differs between what the host expects and what the guest exports. In Rust, the compiler can’t see the host’s WIT, so your best debugging move is to compare the WIT definitions and regenerate bindings for both sides.
Example: A Small End-to-End Export
A clean minimal component exports one function and uses generated types for inputs and outputs.
use my_world::my_api::{MyService, PingResponse};
struct MyServiceImpl;
impl MyService for MyServiceImpl {
fn ping(&self) -> PingResponse {
PingResponse { ok: true }
}
}
Even in this tiny example, the pattern matters: you implement the generated trait, return the generated response type, and let the canonical ABI glue handle the rest.
8.2 C and C Plus Plus Integration with ABI Safe Interfaces
C and C++ are great at controlling layout and performance, which is exactly why ABI-safe interfaces matter. The goal is simple: write C/C++ code that treats WIT-defined types as contracts, not as “whatever happens to work today.” The canonical ABI handles the messy parts—string and list representation, ownership boundaries, and variant tagging—so your C/C++ layer can stay predictable.
Core Concepts for C and C Plus Plus
Start with three rules.
- Treat WIT types as data shapes, not native structs. A WIT
recorddoes not equal a C struct layout unless the canonical ABI says so. - Assume boundary conversions happen. Strings and lists are typically represented as pointers plus lengths in the canonical ABI, but the exact lowering and lifting rules are what you must follow.
- Make ownership explicit in your wrapper. If the canonical ABI hands you memory, you must release it using the generated conventions, not
freeby guesswork.
A practical mental model: your C/C++ code implements functions with signatures generated from the WIT contract, and it never “reinterprets” raw pointers as higher-level types.
Mind Map: C and C Plus Plus Integration Flow
Designing ABI Safe C Interfaces
When you implement a WIT-exported function in C/C++, you typically receive canonical ABI representations for parameters and must produce canonical ABI representations for results.
A common pattern is to keep your internal types “normal” and translate at the boundary.
- Boundary layer: uses generated conversion helpers and canonical ABI structs.
- Core layer: uses your preferred C/C++ structs, enums, and error types.
This separation prevents accidental coupling to canonical ABI details.
Example: A Simple Record with Strings
Suppose your WIT defines a record like User { id: u32, name: string } and an exported function greet(user: User) -> string.
In C/C++, you do not assume string is a null-terminated char*. Instead, you use the generated canonical ABI string representation and convert it to a C++ std::string (or a C buffer) using the provided helpers.
// Pseudocode shaped like generated bindings
// Keep it boundary-only; core logic uses normal types.
typedef struct {
uint32_t len;
const uint8_t* ptr;
} wit_string_view;
typedef struct {
uint32_t id;
wit_string_view name;
} wit_user;
// Generated signature style may vary by toolchain.
// The key is: treat name as (ptr,len), not C string.
char* greet_impl(const wit_user* user, uint32_t* out_len);
Your implementation should:
- Validate
useris non-null. - Convert
user->nameusing(ptr,len). - Build the greeting in your internal representation.
- Return the output string in the canonical ABI form expected by the generated wrapper.
If the generated code provides a “return string” helper, use it. If it expects you to allocate, follow the documented allocator hooks from the bindings rather than calling malloc and hoping.
Example: Variants and Results Without Guessing
For result<T, E>, the canonical ABI typically encodes a tag plus payload. Your C/C++ code should map that tag to a local enum and then convert the payload using the generated lifting/lowering helpers.
A safe workflow:
- Switch on the variant/result tag.
- For each case, convert the payload using the helper for that exact WIT type.
- For errors, construct the canonical error payload using the generated constructors.
This avoids the classic mistake: treating the payload pointer as if it always points to the same native layout.
Memory Management and Cleanup
Canonical ABI boundaries often require explicit cleanup for lifted strings and lists. The generated bindings usually provide functions like wit_free_* or scoped cleanup helpers.
Best practice is to:
- Use a single exit path in each exported function.
- Free any lifted allocations before returning.
- Never store canonical ABI pointers beyond the function call.
Practical Checklist for C/C++ Implementations
- Use generated signatures exactly. Don’t “simplify” them.
- Convert at the boundary only. Keep canonical ABI types out of core logic.
- Validate lengths. A
(ptr,len)string can still be invalid iflendoesn’t match accessible memory. - Handle all variant cases. Missing a case is a correctness bug, not a “should never happen.”
- Release canonical allocations. Use the binding-provided cleanup routines.
Mind Map: Common Failure Modes
Example: Minimal Boundary Wrapper Structure
When the function is small, the wrapper can be almost mechanical: convert inputs, call core logic, convert outputs, clean up.
// Boundary wrapper sketch
// Core logic stays in normal C++ types.
struct User { uint32_t id; std::string name; };
std::string greet_core(const User& u) {
return "Hello, " + u.name + " (" + std::to_string(u.id) + ")";
}
// Exported function uses generated canonical ABI types.
// The wrapper converts and returns canonical ABI output.
This structure keeps the ABI rules in one place and makes it easier to review correctness: if the conversion is correct, the rest is ordinary C++.
8.3 Go Integration with Interface Driven Bindings
Go is a good fit for component hosts because it has straightforward tooling and a clear memory model. The key is to treat the WIT interface as the contract that drives code generation, then make Go’s types and lifetimes match the canonical ABI rules.
Go Binding Workflow That Stays Honest
Start with a WIT package that defines a world with functions and types. Generate Go bindings from that WIT so your Go code never “guesses” the ABI. Your project ends up with two sides:
- Guest side: Go implements the exported functions required by the world.
- Host side: Go instantiates the component and calls imported functions.
A practical best practice is to keep the WIT package in a dedicated directory and make Go code depend on the generated bindings, not on hand-written signatures.
Mind Map: Go Integration with Interface Driven Bindings
Type Mapping Rules That Prevent Subtle Bugs
Canonical ABI conversions are where most integration mistakes happen. In Go, you should map WIT types to generated wrapper types and only convert to native Go types at the edges.
- Strings: treat them as byte sequences with an explicit length. Convert to
stringonly after the wrapper has lifted the canonical representation. - Lists and Buffers: prefer passing slices through generated buffer wrappers. If the wrapper requires an explicit “free” step, call it promptly after the call returns.
- Records: keep field order and names aligned with the WIT definition. Generated record structs help you avoid mismatches.
- Variants: use the generated tagged union types so the tag and payload are consistent.
Example: Implementing a Simple Service in Go
Assume WIT defines a world with a function greet(name: string) -> result<string, string>. The generated Go bindings typically provide an interface you implement.
// Generated types and interfaces are assumed to exist.
// You implement the exported functions required by the world.
type Greeter struct{}
func (g Greeter) Greet(name string) (witResult[string, string]) {
if name == "" {
return witResult[string, string]{Err: "name must not be empty"}
}
return witResult[string, string]{Ok: "Hello, " + name}
}
The important part is not the string concatenation; it’s that you return the generated result wrapper. That wrapper encodes the canonical ABI expectation for result without you manually constructing tags.
Example: Host Calling a Guest Export
On the host side, generated wrappers usually expose a method that takes native Go values and returns lifted results.
// Pseudocode using generated host bindings.
// Instantiate the component, then call the export.
host := NewComponentHost(runtimeConfig)
inst, err := host.Instantiate("./greeter_component.wasm")
if err != nil {
panic(err)
}
res, err := inst.Exports().Greet("Ada")
if err != nil {
panic(err)
}
if res.IsOk() {
println(res.Ok())
} else {
println("error: " + res.Err())
}
Notice how the host code never touches canonical ABI buffers directly. That’s the point of interface driven bindings: you keep conversions in one place.
Ownership and Lifetimes in Go
Go’s garbage collector does not know about guest memory. If a generated wrapper returns a view into guest memory, it will either:
- copy into Go-owned memory during lifting, or
- require an explicit release step.
A safe rule is: treat any “borrowed” data as valid only until the wrapper’s call returns. If you need to keep data, copy it into Go memory immediately.
Error Handling That Matches the Contract
When WIT uses result<T, E>, implementers should map validation failures into the error variant, not into Go panics or transport errors. Reserve Go errors for host/instantiation failures or runtime issues, and keep contract errors inside the WIT result.
Debugging Checklist That Works
When linking fails or calls return unexpected values, check these in order:
- The WIT package used for generation matches the component you instantiate.
- Your Go implementation returns the generated wrapper types for results and variants.
- You do not store borrowed buffers beyond the call boundary.
- You handle empty and unit cases exactly as the WIT definition states.
If you follow those rules, Go integration stays predictable: the interface defines the shape, the generated bindings enforce it, and your code focuses on business logic rather than ABI archaeology.
8.4 Managing Memory and Resource Cleanup Across Boundaries
When a component boundary is crossed, you’re not just passing values—you’re also crossing rules about who owns memory, who frees it, and what “done” means. Canonical ABI conversions help with data layout, but they do not magically solve resource lifetimes for you. This section gives a practical framework for memory and cleanup that works whether your guest is Rust, C, or Go.
Ownership Model That Matches Reality
Start by classifying every boundary-crossing value into one of three buckets:
- Borrowed input: the host provides data for the call; the guest must not outlive the call.
- Owned output: the guest produces data; the host must eventually release it.
- Ephemeral scratch: temporary buffers created during conversion; these should be freed before returning.
A good rule: if the guest needs data after the call returns, it must copy it into its own owned storage before returning.
Cleanup Mechanisms You Can Actually Use
Canonical ABI typically handles conversion buffers for you, but resources like file handles, sockets, database transactions, and heap allocations created by your code are still your responsibility.
Use explicit cleanup patterns:
-
Scoped cleanup inside the exported function
- Allocate temporary buffers.
- Perform work.
- Free buffers before returning.
-
Explicit “close” or “drop” exports for long-lived resources
- Return an opaque handle (an integer or record).
- Provide an exported function to release that handle.
- Make the release idempotent: releasing twice should be safe.
-
Error-path cleanup symmetry
- Every early return must still run the same cleanup logic.
- In languages with RAII, this is mostly automatic; in C-like code, it must be structured manually.
Mind Map: Boundary Lifetimes and Cleanup
Example: Borrowed Input and Safe Copy
Suppose the host calls a guest function with a byte buffer and expects the guest to parse it immediately. The guest should treat the buffer as borrowed.
// Pseudocode style
fn parse_request(input: &[u8]) -> Result<Parsed, Error> {
// input is borrowed for the duration of the call
let owned = input.to_vec();
// Now owned can outlive the call if needed internally
let parsed = parse(&owned)?;
Ok(parsed)
}
The key is the to_vec() step: it converts borrowed data into owned storage before any asynchronous or deferred processing would be attempted.
Example: Owned Output with Explicit Release
For owned outputs, return a handle and provide a release function. This avoids passing raw pointers across the boundary.
// Pseudocode style
typedef uint32_t resource_handle;
resource_handle create_resource(/* inputs */);
int resource_read(resource_handle h, /* out params */);
int resource_release(resource_handle h); // idempotent
On the host side, call resource_release exactly once per successful create_resource. If your host code may call release in multiple paths, make the release idempotent to prevent double-free.
Example: Error Paths That Don’t Leak
A common bug is allocating a buffer, failing validation, and returning without freeing. Structure code so cleanup is centralized.
// Pseudocode style
int do_work(/* inputs */) {
void* buf = malloc(1024);
if (!buf) return -1;
int ok = validate(buf);
if (!ok) {
free(buf);
return -2;
}
int rc = compute(buf);
free(buf);
return rc;
}
If you have multiple allocations, free them in reverse order of allocation on every exit path.
Advanced Details That Prevent Subtle Bugs
- Don’t smuggle host pointers into guest state: even if the pointer value “looks” stable, it’s not a valid lifetime guarantee.
- Make release functions cheap and predictable: they should not require complex state that might already be gone.
- Keep buffer sizes explicit: when returning variable-length data, always communicate length alongside the payload so the host can release correctly.
- Treat “empty” as a real case: an empty buffer or a null-like handle should still follow the same cleanup rules.
Practical Checklist for Interface Authors
- Every exported function documents whether inputs are borrowed and whether outputs are owned.
- Long-lived resources use handles plus an explicit release export.
- Release is idempotent and safe under repeated calls.
- All error paths run the same cleanup logic as success paths.
- No raw pointers are stored across calls.
With these rules, memory and resource cleanup becomes a contract you can reason about, rather than a collection of “it usually works” assumptions.
8.5 Practical Cross Language Example with Identical WIT Contracts
This section shows one WIT contract implemented in two languages and linked through the same host. The goal is simple: if both components agree on the WIT types, the host can wire them without caring whether the guest is Rust or Go.
The Shared Contract
Create a WIT package that defines a small “calculator” service. It takes two integers and returns either a result or a typed error. The contract uses result so error handling is explicit and consistent.
package calc:[email protected]
interface Math {
add: func(a: s32, b: s32) -> result<s32, CalcError>
div: func(a: s32, b: s32) -> result<s32, CalcError>
}
type CalcError = variant {
DivideByZero
Overflow
}
world math-world {
export Math
}
Best practice: keep the interface small enough that you can reason about every conversion and every error case. When you later add more operations, you’ll know exactly which parts of the boundary you’re changing.
Mind Map: Contract to Components to Host
Rust Component Implementation
Rust implements the interface and returns Result<i32, CalcError>. The key is that the error variant names must match the WIT variant cases.
// Rust sketch
enum CalcError { DivideByZero, Overflow }
fn add(a: i32, b: i32) -> Result<i32, CalcError> {
a.checked_add(b).ok_or(CalcError::Overflow)
}
fn div(a: i32, b: i32) -> Result<i32, CalcError> {
if b == 0 { return Err(CalcError::DivideByZero); }
a.checked_div(b).ok_or(CalcError::Overflow)
}
Best practice: use checked arithmetic so overflow becomes a contract-level error instead of a panic. That keeps behavior consistent across languages.
Go Component Implementation
Go implements the same operations. The important part is mapping the error to the same variant cases. In practice, generated bindings will provide a way to construct the correct variant.
// Go sketch
type CalcErrorKind int
const (
DivideByZero CalcErrorKind = iota
Overflow
)
type CalcError struct { Kind CalcErrorKind }
func add(a int32, b int32) (int32, *CalcError) {
r := int64(a) + int64(b)
if r < -2147483648 || r > 2147483647 { return 0, &CalcError{Overflow} }
return int32(r), nil
}
func div(a int32, b int32) (int32, *CalcError) {
if b == 0 { return 0, &CalcError{DivideByZero} }
return a / b, nil
}
Best practice: keep the same numeric range checks as the Rust version. Even when the canonical ABI is consistent, your language-level arithmetic rules still need to agree.
Host Wiring with Identical WIT Contracts
The host treats both components as “math-world” exporters of Math. It calls add and div, then inspects the returned result. The host code does not change between Rust and Go because the WIT contract is identical.
Host steps
1. Load component A (Rust) or component B (Go)
2. Instantiate as math-world
3. Call add(2, 3)
4. Call div(10, 0)
5. Print either the s32 value or the error tag
Best practice: in the host, handle errors by tag rather than by string messages. This avoids accidental differences in formatting and keeps the boundary behavior deterministic.
Mind Map: Error Handling Flow

What “Identical Contract” Means in Practice
Identical WIT contracts mean three things: the interface signatures match exactly, the variant case names match exactly, and the host uses the same generated bindings for both components. When those conditions hold, the canonical ABI handles the mechanical conversion, and your only remaining job is to ensure each language implementation follows the same rules for overflow and division by zero.
Quick Walkthrough Run
Test with add(2, 3) expecting Ok(5). Then test div(10, 0) expecting Err(DivideByZero). Finally test an overflow case such as add(2147483647, 1) expecting Err(Overflow). If all three outcomes match for both Rust and Go components, the contract and linking are doing their job.
9. Host Integration and Runtime Embedding Across Environments
9.1 Host Responsibilities for Instantiation and Linking
A WebAssembly component host is the part that turns interface contracts into running code. It does three jobs in a strict order: load artifacts, link them according to WIT contracts, and instantiate with the right runtime configuration. If you get the order wrong, you’ll usually see failures that look like “type mismatch” even when the real issue is “wrong wiring.”
Core Responsibilities
Artifact Loading and Identity
The host must locate the component artifacts (and any dependencies) that correspond to the WIT packages used by the application. It should treat component identity as more than a filename: the host needs to ensure the artifact’s exported world matches what the application expects. A practical best practice is to keep a small registry in the host that maps a logical name like image-processor to a specific component file and expected interface version.
Linking Worlds and Resolving Imports
Linking connects a component’s imports to providers. In WIT terms, a world declares what it needs and what it offers. The host chooses which component instance satisfies each import. A common mistake is to link by “function name” rather than by the world’s interface shape. The host should rely on the generated bindings’ type information so that the canonical ABI conversions happen consistently.
Instantiation with Correct Runtime Configuration
Instantiation creates the runtime state for the component. The host must supply any required configuration such as memory limits, fuel or timeouts (if supported by the runtime), and host-provided services exposed through interfaces. Even when the component has no explicit imports, the host may still need to set up standard services like logging or clock access if those are modeled as interfaces.
Step-by-Step Instantiation Flow
- Parse and validate WIT expectations: confirm the application’s required world and the component’s provided world are compatible.
- Select providers for imports: for each import in the required world, pick a component that exports the matching interface.
- Create a linking plan: record which instance satisfies which import, including any adapter layers needed for canonical ABI conversions.
- Instantiate providers first: instantiate leaf components that have no internal dependencies.
- Instantiate the consumer: instantiate the main component after its imports are available.
- Run contract-level sanity checks: call a small “smoke” function or validate a known constant to catch wiring errors early.
Mind Map: Host Responsibilities
Example: Wiring a Two Component Pipeline
Imagine a pipeline where text-normalizer produces normalized text and word-counter consumes it.
text-normalizerexports a worldnormalize-worldwithnormalize(input) -> output.word-counterimportsnormalize-worldand exportscount(normalized) -> result.
A host should:
- Load both components.
- Link
word-counter’s import ofnormalize-worldto thetext-normalizerexport. - Instantiate
text-normalizerfirst. - Instantiate
word-counterwith the linked provider. - Call
word-counter.countwith a sample input and verify the result.
Example: Minimal Smoke Check Pattern
A smoke check is a tiny call that confirms the host wiring and ABI conversions are correct. It should use stable inputs and validate outputs precisely.
Smoke check plan
- Call normalize with input: "Hello, WASM!"
- Expect output: "hello wasm"
- Call count with normalized output
- Expect count: 2
- If any step fails, report which world import could not be satisfied
Error Handling and Diagnostics
When linking fails, the host should report the mismatch in terms of interface shape: which world import could not be resolved, which function signature differed, and whether the failure is at linking time or instantiation time. For canonical ABI issues, the host should distinguish “conversion contract mismatch” from “runtime trap inside the component.” A good rule is: linking errors are about types and wiring; instantiation errors are about configuration and environment; traps are about component behavior.
Resource Lifecycle Responsibilities
The host must also manage lifecycle. Instances should be created with clear ownership rules, and shutdown should drop instances in reverse dependency order. If the host exposes services through interfaces, it should ensure those service objects remain valid for the duration of all dependent component instances.
A host that follows these responsibilities consistently ends up with predictable behavior: linking errors point to interface problems, instantiation errors point to environment problems, and runtime failures point to component logic. That separation makes debugging less guessy and more mechanical.
9.2 Configuring Runtime Options for Deterministic Behavior
Determinism means the same inputs produce the same observable outputs, including timing-sensitive behavior like ordering, error text, and byte-level serialization. In component-based WebAssembly, determinism is mostly about runtime configuration and boundary discipline: you decide which sources of nondeterminism are allowed, and you make the rest explicit.
Foundational Knobs That Affect Determinism
Start by listing the runtime behaviors that can vary across machines or runs:
- Time and clocks: “current time” calls must be either disabled or routed through a deterministic provider.
- Randomness: any RNG used by the guest must be seeded deterministically or replaced with a fixed stream.
- Threading and scheduling: if the runtime enables parallel execution, ordering can change.
- I/O and environment: filesystem reads, environment variables, and network responses must be controlled.
- Logging and formatting: log ordering and formatting can differ if buffering or concurrency is enabled.
A practical rule: if the guest can observe it, you must either fix it or mediate it through an interface you control.
Deterministic Configuration Strategy
Use a layered approach: lock down the runtime first, then lock down the host-to-component boundary.
- Freeze execution model: prefer single-threaded execution for deterministic runs, or ensure the runtime uses a deterministic scheduler.
- Provide deterministic host functions: route time, randomness, and system services through explicit host imports.
- Standardize serialization: ensure the canonical ABI mappings are consistent by keeping interface types stable and avoiding ad-hoc string formatting.
- Control error surfaces: normalize error codes and messages so they don’t depend on platform-specific wording.
- Make ordering explicit: if your interface returns lists, define a stable order at the source component.
Mind Map: Deterministic Runtime Options
Example: Deterministic Time and Randomness Through Host Imports
Assume your component imports now_ms() and rand_u32(). The deterministic host supplies both values from a fixed script.
Host state
- now_ms_value = 1712345678000
- rand_stream = [7, 11, 13, 17]
- rand_index = 0
now_ms()
- return now_ms_value
rand_u32()
- v = rand_stream[rand_index]
- rand_index += 1
- return v
Best practice: keep the host state local to the instantiation, not global. If you reuse a runtime instance across tests, you must reset the state or you’ll get “deterministic but wrong” results.
Example: Stabilizing Ordering Across Component Boundaries
If a component returns a list of records, nondeterminism often sneaks in from internal maps or concurrent processing. Fix it at the component boundary by sorting before returning.
Input
- items: map-like collection
Deterministic output rule
- sort by record.id ascending
- then serialize list in that order
Result
- same inputs produce same list bytes
This is especially important when the canonical ABI lowers lists into sequences of elements: the runtime can’t guess your intended order.
Example: Error Normalization for Consistent Outputs
Even when the guest computes the same condition, error text can differ by platform. Prefer structured error payloads with stable codes.
Error contract
- code: u32
- message: string
Normalization rule
- message is generated from code via a fixed table
- never includes platform-specific details
If you must include details, include them as explicit fields in the payload rather than embedding them into free-form strings.
Advanced Details That Matter in Practice
- Instantiation reuse: deterministic runs should either recreate instances per test or reset all host-mediated state.
- Buffering and output capture: if logs are captured asynchronously, ordering can change. For deterministic tests, collect logs synchronously or tag them with a sequence number.
- Resource limits: memory growth behavior can vary if the runtime uses different growth strategies. Keep memory sizing explicit when possible.
- Interface stability: changing WIT types changes canonical ABI lowering. Determinism requires that the interface contract stays fixed for a given test suite.
Checklist for a Deterministic Runtime Configuration
- Time is provided by a deterministic host function.
- Randomness is seeded or replaced with a fixed stream.
- Execution is single-threaded or deterministically scheduled.
- Lists and maps have a defined stable ordering before returning.
- Errors use stable codes and normalized messages.
- Host state is reset per instantiation or per test.
- Logging and output capture preserve ordering.
With these controls in place, “same inputs” becomes a statement you can actually test, not just a hope you write in a test plan.
9.3 Handling Standard I O and Logging Through Interfaces
Standard I/O and logging are the first things people try to “just wire up” when embedding a component runtime. In a component world, you want two properties at once: (1) the guest component never assumes a specific host environment, and (2) the host can still route output to files, consoles, or structured log systems. The clean way is to treat I/O and logging as ordinary interface calls, with explicit contracts for text, severity, and error reporting.
Core Idea: Make I O a Contract
Define a small interface that covers the minimum you need: writing text lines, writing raw bytes, and emitting log records. Keep the contract narrow so canonical ABI conversions stay predictable.
A practical pattern is to split concerns:
- Output: “Send bytes or text to the host.”
- Logging: “Send structured log fields to the host.”
- Errors: “Return a result so the guest can react.”
This avoids the common trap where the guest prints and hopes the host is listening.
Interface Shape for Text and Bytes
For text, prefer a string-like representation in the WIT contract. For bytes, use a list<u8> or a buffer-like record so the host knows exactly what it received.
Best practice: include an explicit newline policy. If the guest always sends complete lines, the host can avoid guessing.
Example: a guest writes a log line and also writes a user-facing message.
package app:io;
interface output {
write-line: func(msg: string) -> result<(), string>;
write-bytes: func(data: list<u8>) -> result<(), string>;
}
interface logging {
log: func(level: string, message: string, trace_id: option<string>) -> result<(), string>;
}
The host implementation can map level to its own severity enum, and it can attach trace_id to whatever correlation mechanism it uses.
Logging Semantics That Don’t Surprise Anyone
Logging contracts should specify:
- Level vocabulary: use a small set like
debug,info,warn,error. - Trace correlation: an optional
trace_idkeeps the contract flexible. - Backpressure behavior: return
resultso the guest can handle failures.
If your host can fail to write (disk full, closed console, transport down), the guest should not silently continue. Returning result<(), string> gives you a place to surface the failure.
Host Responsibilities for Routing
The host decides where output goes. Typical routing rules:
write-linegoes to standard output.write-bytesgoes to standard output in binary mode.loggoes to a logging sink, possibly with timestamps and formatting.
The host can also enforce policies like truncation limits. If the host truncates, it should do so deterministically and reflect that in the returned error or by a clear convention.
Example: Wiring Guest Calls to Host Streams
Below is a minimal host-side sketch. The key is that the host owns the actual I/O objects.
fn write_line(msg: String) -> Result<(), String> {
use std::io::Write;
let mut out = std::io::stdout().lock();
out.write_all(msg.as_bytes()).map_err(|e| e.to_string())?;
out.write_all(b"\n").map_err(|e| e.to_string())?;
out.flush().map_err(|e| e.to_string())?;
Ok(())
}
fn log(level: String, message: String, trace_id: Option<String>) -> Result<(), String> {
let prefix = match level.as_str() {
"debug" => "D",
"info" => "I",
"warn" => "W",
"error" => "E",
_ => "?",
};
let tid = trace_id.map(|t| format!(" trace_id={t}"))
.unwrap_or_default();
write_line(format!("[{prefix}] {message}{tid}"))
}
This keeps the guest ignorant of stdout locking, formatting, and flushing strategy.
Mind Map: Standard I O and Logging Through Interfaces
Advanced Details Without the Headaches
- Avoid mixing user output and diagnostics: route them through different calls or different levels so the host can separate streams.
- Keep log payloads small: large messages increase conversion and copying costs across the boundary.
- Return errors with actionable text: the guest can’t fix a disk error, but it can decide whether to stop, retry, or degrade.
- Be consistent about line boundaries: if the guest sends partial lines, the host will have to buffer, which complicates correctness.
Putting It Together in a Single Flow
A typical flow is: the guest emits log for diagnostics and uses write-line for user-visible messages. Both return result, so the guest can stop work if the host reports an I/O failure. The host remains the only place that knows what “standard output” means in the current environment.
9.4 Environment Specific Concerns for File Network and Time Access
When a component runs inside different hosts, the “same” interface can behave differently because the host owns the real world: files, sockets, clocks, and permissions. The goal is to keep your component logic deterministic with respect to inputs, while treating environment access as a controlled side effect.
Foundational Principle: Separate Pure Logic from Host Effects
Define your WIT so that the component receives all data it needs and returns all results it produces. For environment access, prefer patterns where the component requests an operation and the host performs it, or where the host provides the data as arguments.
A practical rule: if your component needs a file, don’t make it guess paths or permissions. Instead, pass a logical identifier (like resource_id) and let the host map it to a real path. For time, pass a timestamp or a “current time” value from the host rather than calling a clock inside the component.
File Access Concerns and Best Practices
File access usually breaks portability in three ways: path semantics, encoding, and permissions.
Path semantics. Hosts differ in path separators, root directories, and sandboxing rules. Use a stable logical name in the interface, and let the host translate it.
Encoding and newline behavior. Text files can be UTF-8, UTF-16, or mixed; line endings can be \n or \r\n. If you need text, define the interface in terms of UTF-8 bytes and specify that the component treats input as UTF-8.
Permissions and atomicity. Some environments allow read-only access, others allow writes, and some require atomic updates. Model writes as “write content to a target” rather than “open a path and mutate it.”
Example: Logical Resource Reads
Define an interface where the component asks for bytes by ID.
package app:[email protected];
interface store {
read-bytes: func(resource_id: string) -> list<u8>;
write-bytes: func(resource_id: string, data: list<u8>) -> result<(), string>;
}
In the host, resource_id might map to /var/app/data/<id> on Linux, or to an app sandbox directory on mobile. The component never needs to know.
Network Access Concerns and Best Practices
Networking adds failure modes: timeouts, partial reads, DNS differences, and proxy rules. The component should not assume that a request succeeds quickly or that a response arrives in one piece.
Timeout control. Put timeout parameters in the interface so the host can enforce them consistently. If the component needs retries, it should do so based on explicit error codes returned by the host.
Request/response framing. Avoid “stream until EOF” unless you control both ends. Prefer explicit lengths or message boundaries.
Security boundaries. Hosts may restrict outbound destinations. Model destinations as logical endpoints (like service_name) rather than raw URLs.
Example: Framed HTTP-Like Request
A simple request contract can be framed as bytes in and bytes out.
package app:[email protected];
interface client {
request: func(
endpoint: string,
payload: list<u8>,
timeout_ms: u32
) -> result<list<u8>, string>;
}
The host decides how endpoint maps to a real URL, how to set headers, and how to enforce timeouts.
Time Access Concerns and Best Practices
Time is tricky because it’s both a value and a policy. Portability issues include clock source differences, time zones, and monotonic versus wall time.
Use host-provided time. If you need “now,” pass it in. This makes tests reproducible and avoids differences between host clock implementations.
Choose the right time type. For durations and measuring elapsed time, use monotonic durations when possible. For timestamps that represent real-world moments, use wall time in a specified format.
Define a date format when you serialize time. If you exchange timestamps as strings, specify ISO-8601 in UTC (for example, 2026-03-25T10:15:30Z).
Example: Host Supplies Current Time
Instead of calling time inside the component, define a function that accepts now_unix_ms.
package app:[email protected];
interface clocked {
compute-expiry: func(now_unix_ms: u64, ttl_ms: u64) -> u64;
}
The host supplies now_unix_ms, and the component performs pure arithmetic.
Mind Map: Environment Access Responsibilities
Advanced Integration Detail: Error Contracts That Stay Portable
When environment operations fail, the component needs stable error semantics. If the host returns raw OS errors, portability suffers. Instead, standardize error categories in the interface, such as NotFound, PermissionDenied, Timeout, and InvalidInput.
A clean approach is to return result<T, string> where the string is a controlled error code, not a free-form message. The host can still include human-readable context, but the component should branch only on the code.
Practical Checklist for Host-Dependent Interfaces
- Use logical identifiers for files and endpoints.
- Pass time values into the component.
- Frame network payloads explicitly.
- Define UTF-8 expectations for text.
- Standardize error codes so component logic stays stable.
With these choices, the component remains portable even when the host is not.
9.5 Practical Host Example: Wiring Interfaces to System Services
A host is the “grown-up in the room” that provides system services like time, logging, and filesystem access, then connects them to component interfaces. The goal is to keep the guest component portable while letting the host handle environment-specific details.
Step 1: Define the Host-Facing Contract
Start with a WIT world that describes what the guest needs from the host. Keep the contract small and explicit: one interface for logging, one for time, one for filesystem operations.
Best practice: model errors as typed results so the guest can react without parsing strings.
Step 2: Implement Host Functions in the Host Language
Your host implementation should translate between system types and the canonical ABI shapes produced by WIT bindings.
Logging example:
- Guest calls
log(level, message). - Host maps
levelto its own logging framework. - Host returns
result<(), error>whereerrorincludes a stable code and message.
Time example:
- Guest calls
now_utc(). - Host returns an integer timestamp plus a precision enum.
- Host never returns host-specific structs; it returns only WIT-defined types.
Filesystem example:
- Guest calls
read_file(path). - Host reads bytes from the OS.
- Host returns
result<bytes, fs_error>.
Step 3: Wire the World and Link Components
Linking connects the guest’s imports to the host’s exports. In practice, you create a host component (or binding layer) that satisfies the world imports, then instantiate the guest component with that binding.
Best practice: validate interface compatibility before instantiation so failures happen early and are easier to diagnose.
Step 4: Handle Canonical ABI Data Movement
When the guest passes strings or buffers, the runtime performs canonical ABI lowering and lifting. Your host should treat returned buffers as owned by the host binding layer until the guest consumes them.
Rule of thumb: if you return a byte buffer, ensure the binding layer can safely keep it alive for the duration required by the guest call.
Step 5: Add a Small End-to-End Scenario
Consider a guest “reporter” component that:
- Reads a configuration file.
- Logs what it found.
- Attaches a timestamp.
- Returns a summary string.
The host provides:
read_filefor configuration.logfor diagnostics.now_utcfor timestamps.
Example: Host Wiring Flow
Guest imports: log, now_utc, read_file
Host exports: log, now_utc, read_file
Link guest to host
Instantiate
Call guest run(config_path)
Guest calls host services
Host returns canonical ABI values
Guest returns summary to host
Host prints summary
Mind Map: Host Wiring to System Services
Step 6: Concrete Host Implementation Sketch
Below is a conceptual outline of the host-side functions. The exact API depends on your runtime and language bindings, but the structure stays the same.
function log(level, message) -> result<(), LogError>
map level to host logger
try write message
if fail return Err({code: "LOG_FAIL", message})
return Ok(())
function now_utc() -> result<Timestamp, TimeError>
t = system_time_utc()
return Ok({seconds: t.sec, nanos: t.nsec})
function read_file(path) -> result<bytes, FsError>
try bytes = os_read_all(path)
if fail return Err({code: "NOT_FOUND" or "IO", message})
return Ok(bytes)
Step 7: Error Handling That Doesn’t Leak Host Details
When the guest receives an error, it should map it to its own behavior. For example:
- If
read_filereturnsNOT_FOUND, the guest can return a summary like “missing config” without crashing. - If
logfails, the guest can continue but return an error code indicating diagnostics were unavailable.
Best practice: keep error records stable across environments so the guest logic stays consistent.
Step 8: A Minimal Narrative Run
Assume the host is running on a typical OS. The guest calls run("config.json").
- Host reads bytes from disk.
- Host logs the byte length.
- Host fetches UTC time.
- Guest returns a summary string containing the timestamp and a short digest of the file.
The important part is not the digest; it’s that the guest never touches OS APIs directly, and the host never needs to know the guest’s internal logic. The boundary stays clean, and the component remains portable.
10. Performance and Correctness Considerations for Canonical ABI
10.1 Measuring Boundary Overhead With Representative Workloads
Boundary overhead is the cost of moving values across a component boundary using the canonical ABI. It shows up as extra CPU work (lowering and lifting), extra memory traffic (copies and temporary buffers), and sometimes extra allocations. The tricky part is that overhead depends heavily on the shape of your interface values, not just on how many calls you make.
What to Measure First
Start with three metrics that cover most surprises:
- Latency per call: wall-clock time for a single boundary crossing, measured with enough samples to smooth jitter.
- CPU time per call: time spent in the process, which helps separate “waiting” from “doing.”
- Allocation count and bytes: temporary allocations during lowering/lifting, which often correlate with copies.
A good baseline workload is one that is representative of your real data sizes and call patterns. If your service usually handles small strings and occasional large buffers, measure both. If you stream chunks, measure chunk sizes and chunk counts.
Choosing Representative Workloads
Use a small matrix of workloads rather than one “average” benchmark.
- Scalar heavy: many integers and booleans, minimal strings. This isolates call overhead.
- String heavy: short strings (e.g., 8–32 bytes) and medium strings (e.g., 1–4 KiB). This isolates encoding and copying.
- Buffer heavy: byte buffers sized like your typical payloads (e.g., 4 KiB, 64 KiB, 1 MiB). This isolates buffer lifting/lowering.
- Composite heavy: records with nested fields and variants. This isolates tag handling and layout conversions.
- Error path: inputs that trigger
option/resultfailures. This isolates error payload conversions.
Keep the business logic inside the component minimal so the boundary cost dominates. For example, return the input length, echo a small transformed value, or compute a checksum over the received bytes.
A Measurement Plan That Doesn’t Lie
A measurement plan should control for confounders:
- Warm-up: run a few thousand calls before recording to reduce one-time costs.
- Fixed sizes: avoid variable-length inputs unless that variability is part of the real workload.
- Batching: if your real system batches requests, benchmark both single-call and batched-call patterns.
- Isolation: run the host and guest in the same process when possible, or at least keep the environment consistent.
If you can, compare three configurations:
- Same-process baseline: call the guest logic directly without crossing the boundary.
- Boundary crossing: call through the component interface.
- Boundary crossing with larger payloads: repeat with the biggest realistic sizes.
The difference between baseline and boundary crossing is your boundary overhead for that workload.
Interpreting Results
Overhead usually scales in one of three ways:
- Flat overhead: nearly constant per call, typical for scalar-heavy interfaces.
- Linear overhead: grows with string or buffer length, typical for copying and encoding.
- Piecewise overhead: changes behavior at certain sizes, often due to internal buffering or allocation thresholds.
Allocation metrics help explain why. If allocations jump when payload size increases, your interface shape likely forces temporary buffers.
Mind Map: Boundary Overhead Measurement
Example Workload Design
Suppose your interface has a function that takes a string and returns a result<u32, string>. A representative benchmark set might include:
- 10,000 calls with 16-byte strings that succeed.
- 10,000 calls with 2,048-byte strings that succeed.
- 10,000 calls with 2,048-byte strings that fail and return an error string of 64 bytes.
Inside the component, do not parse JSON or do expensive work. Just compute the input length and return it, or return an error immediately. This makes the boundary conversions the dominant cost.
Example: Separating Call Overhead from Data Conversion
To separate “call mechanics” from “data conversion,” use two interface shapes:
- Shape A:
fn ping(x: u32) -> u32. - Shape B:
fn process(s: string) -> u32where the component returnss.len().
If ping shows a flat latency curve while process grows with string size, you’ve confirmed that the canonical ABI work is dominated by string lowering/lifting rather than the call itself. Then you can focus optimization on interface shapes that reduce copying or temporary allocations.
Practical Checklist for Your Benchmark Run
- Measure at least two payload sizes per data category.
- Record allocations alongside time.
- Include one failing path workload.
- Compare against a direct-call baseline when feasible.
- Keep the component logic intentionally small.
This approach turns “boundary overhead” from a vague complaint into a set of measurable, interface-shape-specific costs you can act on.
10.2 Minimizing Copies with Interface Shape Choices
Copies happen when the boundary needs a different representation than the one your language naturally uses. The canonical ABI can translate between shapes, but translation often means allocating temporary buffers or re-encoding data. The good news is that interface shape choices strongly influence whether the runtime can move data with fewer conversions.
Start with the Boundary Contract
A canonical ABI boundary typically has two jobs: (1) map values into a canonical memory representation and (2) map results back into the guest or host representation. If your interface uses shapes that match your language’s natural layout closely, the runtime can reduce work.
A practical rule: prefer small, explicit shapes over “big generic” ones. For example, a list of small records may still require per-element conversions, while a single buffer may be copied once.
Choose Between Scalars, Records, and Lists
Scalars like integers and booleans are usually cheap because they map cleanly. Records are next: they require field-by-field mapping, but the structure is predictable.
Lists are where copy pressure often rises. A list usually implies:
- determining element count
- allocating space for the canonical representation
- converting each element
If your data is naturally a contiguous buffer, consider exposing it as a buffer-like type rather than a list of bytes or a list of small integers.
Prefer Buffer Shapes over Byte Lists
A common mistake is modeling raw bytes as list<u8>. That forces element-by-element conversion and may allocate multiple intermediate arrays.
Instead, model payloads as a buffer: a pointer/length pair in the canonical ABI sense. Even when a copy is unavoidable, you usually pay it once.
Example: Byte List Versus Buffer
- Byte list:
list<u8>- conversion cost scales with length
- more opportunities for intermediate allocations
- Buffer:
buffer<u8>-like shape- conversion cost is mostly proportional to total size
- fewer intermediate objects
Use Options and Results Without Over-Allocating
option<T> and result<T, E> are great for correctness, but they can also add overhead if you represent large payloads inside them.
Best practice: keep the “success” payload small when possible, and move large data through a separate buffer parameter. If you must return large data in a result, ensure the payload type is buffer-shaped so the canonical ABI can treat it as a single unit.
Mind the Direction of Data Flow
Minimizing copies depends on whether data flows guest-to-host or host-to-guest.
- If the host calls into the component with large inputs, you want the input shape to be buffer-like so the host can pass a contiguous region.
- If the component returns large outputs, you want the output shape to be buffer-like so the runtime can produce one contiguous canonical representation.
When you model everything as nested lists, you often force the runtime to build canonical structures element-by-element, regardless of direction.
Reuse Through Interface Structure
You cannot control internal runtime allocation directly, but you can reduce churn by designing interfaces that encourage reuse.
Two patterns help:
- Caller-allocated output buffers: the caller provides a buffer, and the component writes into it.
- Chunked processing: the component processes fixed-size chunks, so each call handles a bounded amount of data.
Both patterns reduce the number of times you create large temporary canonical objects.
Mind Map: Copy Sources and Shape Choices
Worked Example: A Small Transform Interface
Imagine an interface that transforms input data and returns output data.
Design A: list-based bytes
- Input:
list<u8> - Output:
list<u8> - Likely outcome: per-element conversions and multiple intermediate arrays.
Design B: buffer-based bytes
- Input:
buffer<u8>-like shape - Output:
buffer<u8>-like shape - Likely outcome: one contiguous conversion per direction.
If you also add an error contract, keep the error payload small (e.g., an error code plus a short message), and keep the large output out of the error path.
A Quick Checklist Before You Lock the Interface
- Are any large payloads modeled as lists of bytes or lists of small integers?
- Are strings returned in a way that forces repeated re-encoding?
- Does a
resultcarry large data inside the success variant? - Can the caller allocate the output buffer to avoid repeated large allocations?
- Are you processing data in chunks to bound per-call canonical work?
These choices don’t just affect performance; they also make behavior easier to reason about when you test across languages and operating environments.
10.3 Reducing Allocation Pressure With Reusable Buffers
Allocation pressure at the component boundary usually comes from two places: temporary buffers created during canonical ABI lowering and lifting, and per-call allocations in host or guest glue code. Reusable buffers reduce both by turning “allocate every call” into “borrow a buffer, fill it, return it.” The goal is not to eliminate allocations entirely, but to make them predictable and bounded.
Core Idea: Separate Buffer Ownership from Data Lifetimes
In canonical ABI, strings and lists are represented as pairs of pointers and lengths (or equivalent handles) plus a convention for when the memory is valid. Reusable buffers work best when you treat the buffer as an owned scratch area and treat the transferred data as a view over that scratch area.
A practical rule: the buffer is owned by the side that allocates it, while the boundary data is only valid for the duration of the call (unless your interface explicitly models longer lifetimes). This keeps correctness simple and avoids “dangling view” bugs.
Mind Map: Where Allocations Sneak In
Design Pattern: Caller-Provided Output Buffers
When an interface returns data, the most allocation-friendly shape is one where the caller provides the destination buffer. With WIT, you can model this by passing a buffer-like record or by using a “write into output” pattern.
Example interface shape (conceptual):
- Input: request bytes and length
- Output: a preallocated output buffer plus a returned length
- Error: a result type that includes an error code and optional message
Even if the canonical ABI still needs to marshal some metadata, the bulk payload can be written into a reused region rather than allocating a fresh container each call.
Example: Reusing a Byte Buffer in a Host Loop
Assume the host repeatedly calls a guest function that transforms input bytes into output bytes (for instance, compression or hashing with a prefix). The host can keep a pool of byte arrays and reuse them.
// Pseudocode: host-side reusable buffer pool
struct BufferPool { pool: Vec<Vec<u8>> }
fn call_transform(pool: &mut BufferPool, input: &[u8]) -> Vec<u8> {
let mut out = pool.pool.pop().unwrap_or_else(|| vec![0u8; 4096]);
let mut out_len: usize = 0;
// Fill out and set out_len via the component call
// guest_transform(input_ptr, input_len, out_ptr, out_cap, &mut out_len)
out.truncate(out_len);
pool.pool.push(out.clone()); // if you must return ownership
out
}
In a real implementation, you’d avoid the clone() by returning the buffer itself to the caller or by using a pool lease object. The key point is that the expensive allocation happens when the pool grows, not on every call.
Reset Discipline: Length over Reallocation
Reusable buffers should be reset by updating length fields, not by creating new containers. For byte buffers, that means:
- Keep capacity stable.
- Overwrite bytes in place.
- Set the effective length to the produced size.
For string-like data, prefer returning bytes and decoding at the edge where you already have a reason to allocate. If you must return strings, decode into a reused UTF-8 buffer when possible, or decode only when the caller actually needs a string.
Pooling for Concurrency Without Cross-Talk
If calls can happen concurrently, a single shared buffer will cause data races or corrupted results. Use either:
- One buffer per in-flight call (a pool of buffers), or
- A thread-local buffer per worker.
A simple pool works well when you can bound concurrency. Track peak simultaneous leases to size the pool so you don’t fall back to frequent growth.
Interface Shape Choices That Reduce Hidden Copies
Some interface shapes force copies even with reusable buffers:
- Returning variable-length lists by value often triggers allocation on the lifting side.
- Passing nested records with many small fields can create intermediate temporaries.
To reduce copies:
- Prefer “single contiguous payload” patterns for bulk data.
- Keep per-call metadata small and fixed-size when you can.
- Use result types for errors, but avoid embedding large error messages unless you truly need them.
Correctness Checklist
Reusable buffers are safe when these conditions hold:
- The buffer is not reused until the component call has fully completed.
- The interface contract does not promise that returned views remain valid after the call.
- Any pool lease is exclusive to one in-flight call.
- Reset uses length updates, and any leftover bytes are ignored.
Practical Measurement: Prove It with Allocation Counts
Before and after changes, measure allocations per call and peak memory usage. A good target is “no new allocations in the steady state” for the hot path. If you still see allocations, inspect whether they come from:
- string decoding,
- intermediate container creation in glue code,
- or buffer growth due to underestimated capacities.
Reusable buffers work best when paired with a capacity strategy: start with a reasonable default, then adjust based on observed payload sizes so the pool rarely grows.
10.4 Correctness Checks for Lifetimes and Ownership Rules
Canonical ABI correctness is mostly about two things: who owns the bytes at each step, and how long those bytes remain valid. If you get either wrong, you may still “work” in tests while failing under load, different languages, or different host runtimes.
Core Ownership Model for Canonical ABI
Think of every boundary call as a short-lived transaction:
- Inputs cross from caller to callee as values with a defined representation.
- Outputs cross back as values with a defined representation.
- Any memory that is borrowed must be borrowed only for the duration the ABI requires.
A practical rule: treat all string and buffer parameters as ephemeral unless the interface contract explicitly says otherwise. In WIT terms, this usually means you should assume the callee may need to copy, and the caller must not reuse borrowed memory beyond the call.
Mind Map: Lifetimes and Ownership Checks
Invariants You Should Enforce in Code
-
Pointer validity window: any pointer passed across the boundary must remain valid for the ABI’s required duration. For many canonical ABI patterns, that duration is “during the call.”
-
Length correctness: for buffers and strings, the length must match the actual byte count. A common bug is computing length in characters while the ABI expects bytes.
-
Single ownership of allocations: if the ABI requires the callee to allocate output memory, then only the ABI-managed free path should reclaim it. If you free manually, you risk double-free.
-
No hidden aliasing: if you reuse the same backing buffer for multiple calls, ensure the ABI does not retain references after the call. Otherwise, later calls can overwrite earlier data.
Example: Safe Buffer Passing Pattern
Suppose your WIT interface accepts a byte sequence and returns a transformed byte sequence. The correctness checks are about making the ownership explicit in your implementation.
// Pseudocode-style Rust checks
fn process(input: &[u8]) -> Vec<u8> {
// Invariant: input length is bytes, not chars
let n = input.len();
assert!(n <= 1_000_000);
// Copy into owned storage if you need to outlive the call
let owned = input.to_vec();
// Transform using owned data
let mut out = Vec::with_capacity(n);
for b in owned {
out.push(b.wrapping_add(1));
}
// Invariant: output is owned by the callee
out
}
Even if the ABI provides a borrowed view for input, the moment you need to store or process asynchronously, you must create an owned copy. The assertion is not about performance; it’s about catching mismatched lengths early.
Example: String Ownership and Round-Trip Validation
For strings, correctness often fails due to encoding assumptions. A good check is a round trip: convert from ABI representation to your internal string type, then back, and verify equality.
fn round_trip(s: &str) -> String {
// Invariant: internal representation is valid UTF-8
assert!(s.is_char_boundary(s.len()));
// Simulate conversion to ABI bytes and back
let bytes = s.as_bytes();
let rebuilt = std::str::from_utf8(bytes).expect("ABI bytes must be UTF-8");
// Invariant: no loss of data
rebuilt.to_string()
}
If your host or language binding uses a different encoding expectation, this test will fail consistently rather than producing subtle corruption.
Advanced Checks for Complex Types
For records, variants, and nested structures, ownership issues often show up as shape mismatches:
- Variants: validate the discriminant before reading payload fields. If the discriminant is invalid, treat it as an error rather than attempting to interpret memory.
- Nested lists: verify each element’s length and ensure you don’t reuse a temporary buffer across elements.
- Options and Results: ensure the “none/error” state does not accidentally carry stale pointers.
A simple pattern is to build a validator that walks the decoded structure and checks invariants before any business logic runs.
Debugging Checklist for Lifetime Bugs
When something goes wrong, these checks narrow the cause quickly:
- Length mismatch between pointer+length pairs.
- Output memory freed by the wrong side.
- Borrowed input used after the call returns.
- Variant discriminant not matching the expected case set.
If you add these checks at the boundary layer, you’ll catch violations at the exact moment they occur, not after they have been smeared across unrelated code paths.
Practical Testing Strategy
Use three test types:
- Round-trip tests for strings and buffers to validate encoding and length.
- Stress tests that repeat calls with different sizes to catch aliasing and reuse bugs.
- Negative tests that feed malformed shapes, ensuring your code rejects them without reading invalid memory.
The goal is not to prove perfection; it’s to make ownership and lifetime rules observable, so failures are deterministic and actionable.
10.5 Practical Optimization Pass on an Existing Interface Contract
Optimization starts with admitting what you already have: a stable WIT contract that works, but may move too much data, allocate too often, or encode errors in a way that forces extra conversions. The goal of this pass is not to “make it faster” in the abstract; it is to reduce boundary work while keeping the contract readable and compatible.
Step 1: Establish a Baseline with Interface-Level Metrics
Before changing anything, measure the boundary costs you can attribute to the interface shape.
- Count calls per request path and identify the hottest functions.
- Track bytes moved for each call: inputs, outputs, and error payloads.
- Record allocation pressure on both sides: how many buffers are created per call.
A simple rule helps: if a call returns a string or list, assume at least one copy unless you can prove otherwise. Then confirm with profiling.
Step 2: Identify Interface Shape Hotspots
Most canonical ABI overhead comes from how data crosses the boundary.
- Strings and lists: frequent conversions and length-prefix handling.
- Nested records: repeated lifting and lowering for each field.
- Variants: tagged payloads that may require extra branching and allocation.
- Error results: error payloads that are larger than the success path.
Write down the top three hotspots and the exact types involved. If the contract has a “convenience” type that bundles everything, it is often the first place to split.
Step 3: Apply Targeted Contract Changes
Use small, mechanical changes that preserve semantics.
-
Split “fat” results into smaller outputs
- Before:
process(input: string) -> result<string, error> - After:
process(input: string) -> result<handle, error>plusread_output(handle) -> result<buffer, error>
This reduces the amount of data moved when callers only need part of the output.
- Before:
-
Replace repeated strings with stable identifiers
- Before: return a long “type name” string every call.
- After: return an integer or enum-like variant case, and let the host map it to text.
Canonical ABI still has to move the value, but you avoid moving large UTF-8 payloads.
-
Prefer lists of bytes for opaque payloads
If the payload is already bytes, don’t wrap it in higher-level structures that require field-by-field lifting. -
Make error payloads small and structured
- Keep error variants to a short code plus optional small context.
- Avoid embedding full request echoes in errors.
Step 4: Ensure Canonical ABI Behavior Matches Your Intent
Optimization fails when the contract changes but the ABI still forces the same work.
- For strings, confirm the encoding expectation is consistent and that you are not converting the same text twice.
- For buffers, confirm the contract uses a clear ownership model so the host knows when it can drop the data.
- For variants, confirm the payload types are minimal for the common cases.
A practical check: after each change, re-run the baseline measurements and verify that bytes moved per call decreased, not just that CPU time shifted.
Step 5: Keep Compatibility and Versioning Simple
If you must change types, do it in a way that avoids breaking existing callers.
- Add new functions rather than changing signatures in place.
- Introduce new interface versions only when the old types cannot represent the new behavior.
- Keep the old contract working long enough to migrate callers.
Mind Map: Optimization Pass Workflow
Example: From One-Shot Output to Handle-Based Streaming
Suppose your current contract returns a full output string.
package demo:opt;
interface worker {
process: func(input: string) -> result<string, string>;
}
If callers often need only a prefix, switch to a handle pattern.
package demo:opt;
interface worker {
process: func(input: string) -> result<u32, string>;
read_output: func(handle: u32) -> result<list<u8>, string>;
}
Now the common path can avoid moving large strings. The host can decide whether to call read_output at all, and if it does, it can treat the bytes as opaque until it needs decoding.
Step 6: Validate with Correctness Checks
Optimization must not change meaning.
- Round-trip tests for each type conversion.
- Error-path tests that confirm error codes and payload sizes.
- Stress tests that call the optimized functions repeatedly to catch leaks or ownership mistakes.
A good final sanity check is to compare the old and new contracts on the same inputs and assert that observable outputs are identical where they should be, and intentionally different only where the contract semantics changed.
11. Testing and Validation for Component Interfaces
11.1 Interface Level Tests With Golden Data and Contract Assertions
Interface-level tests focus on the boundary contract: given inputs that match the WIT types, the component must produce outputs that match the same contract, including shape, encoding expectations, and error conventions. These tests run without spinning up full multi-component systems, so failures point to the interface mapping rather than to orchestration.
Core Idea
Golden data tests lock in expected serialized representations and semantic results. Contract assertions then verify invariants that should always hold, such as “a string round-trips without losing Unicode scalar values” or “a list length matches the declared count.” Together, they catch both drift in data conversion and mistakes in interface wiring.
Test Scope and Boundaries
Start by testing the generated bindings layer and the component’s exported functions as a black box. Treat the canonical ABI conversion as part of the system under test. Keep the host minimal: it should only provide the calls and capture results.
A good rule: if a bug would show up as “wrong bytes on the wire” or “wrong variant case,” it belongs in interface-level tests.
Mind Map: Interface Level Test Strategy
Golden Data Design
Golden data should be stable, readable, and tied to the interface. Use a test vector structure that includes:
- The WIT-level input values.
- The expected WIT-level output values.
- Optionally, the expected canonical ABI representation for strings, lists, and variants.
For string and list types, byte-level goldens are useful because canonical ABI conversions can fail in subtle ways, like incorrect length computation or missing null terminators when an implementation assumes C strings.
Example: Golden Vector Structure
{
"name": "greeting_round_trip",
"input": {"name": "Ada"},
"expected": {"message": "Hello, Ada"},
"golden_bytes": {
"message_utf8": "48656c6c6f2c20416461"
}
}
Keep goldens small and specific. If a test covers too many fields, a mismatch becomes a scavenger hunt.
Contract Assertions That Matter
Golden comparisons confirm exact expectations; contract assertions confirm invariants even when you don’t store byte-level goldens.
Recommended assertions:
- String Integrity: the returned string must match exactly, including empty strings and non-ASCII characters.
- List Length: the list length in the result must equal the number of elements produced.
- Variant Tag Correctness: the variant case must match the expected tag, not just the payload.
- Error Shape: for
result-like patterns, the success and error branches must be mutually exclusive and correctly typed. - Determinism: repeated calls with the same input must yield identical outputs.
Example: Contract Assertions in Pseudocode
call f(input)
assert result.is_ok == expected.is_ok
if ok:
assert result.value.message == expected.message
assert len(result.value.items) == expected_len
else:
assert result.error.code == expected_code
assert result.error.detail == expected_detail
Test Vector Coverage Plan
Use a systematic matrix so you don’t “accidentally” skip edge cases:
- Scalars: min, max, zero, and a typical value.
- Strings: empty, ASCII, and at least one multi-byte Unicode string.
- Lists: empty and a non-trivial length (e.g., 3) to exercise iteration.
- Records: nested records with at least one optional or nullable field.
- Variants: every case at least once, including the case with no payload.
- Errors: each error case at least once, including payload-carrying errors.
Failure Reporting That Saves Time
When a golden mismatch occurs, report:
- Test vector name.
- Which field mismatched.
- For byte goldens, show a short hex diff around the first differing byte.
- For variants, show expected case tag and actual case tag.
This turns “it failed” into “it failed because field X was encoded as Y.”
Minimal Worked Example Flow
- Load golden vectors from a local file.
- For each vector, call the exported function with the WIT-level input.
- Compare the WIT-level output to the expected output.
- If byte goldens exist, compare the canonical ABI representation for the relevant fields.
- Run contract assertions for invariants not covered by byte goldens.
A test suite built this way catches both semantic drift (wrong values) and ABI drift (wrong encoding), which is exactly what interface-level tests are for.
11.2 Property Based Testing for Type Conversions and Round Trips
Property based testing checks behavior by generating many inputs and verifying properties that should always hold. For canonical ABI conversions, the key properties are about round trips and shape preservation: values should survive conversion to the canonical representation and back, and the resulting data should match the original in a way the interface contract promises.
Core Idea: Round Trip Properties
A round trip property typically looks like this: take a value x in the high level type, convert it to the canonical ABI representation, then lift it back to the high level type, and assert equality (or an agreed equivalence) with x.
For example, if your WIT interface uses string, list<u8>, option<T>, or result<T, E>, you can test that lifting returns the same logical value. When equality is tricky (like floating point, or when ownership affects representation), define a comparison that matches the contract: same bytes for strings, same element order for lists, same tag for variants, and same error payload for results.
Mind Map: What to Generate and What to Assert
Designing Generators That Respect the Contract
Generators should produce only values that are valid for the interface, unless you are explicitly testing rejection behavior. For strings, generate valid UTF-8 and include edge cases like empty and long strings. For lists, vary lengths including zero. For option, generate both none and some with nested values. For result, generate both ok and err and ensure error payloads cover all fields.
A practical trick: mirror the WIT type structure in your generator. If the WIT type is a record with fields (a: u32, b: string), generate records by generating a and b independently, then assembling them. This keeps the test data aligned with what the canonical ABI can represent.
Asserting Equality Without Guessing
Canonical ABI conversions can involve intermediate representations. Your assertions should compare the logical value after lifting.
- Strings: compare the exact UTF-8 bytes or the exact lifted string content, but be consistent.
- Lists: compare length and element order.
- Variants: compare the tag and the payload value for the active case.
- Results: compare
okvserr, then compare payloads.
If your types include numeric fields, decide how to handle edge cases. For integers, equality is straightforward. For floats (if present in your interface), compare with a tolerance only if the contract allows it; otherwise, treat bitwise equality as the oracle.
Example: Round Trip for a Record with Option and Result
// Pseudocode for property tests
prop_round_trip_record(input in gen_record()) {
let canon = lower_to_canonical(input.clone());
let lifted = lift_from_canonical(canon);
assert_eq!(lifted, input);
}
prop_round_trip_result(input in gen_result()) {
let canon = lower_to_canonical(input.clone());
let lifted = lift_from_canonical(canon);
assert_eq!(lifted, input);
}
If your canonical ABI layer exposes bytes, you can add a determinism property: lowering the same input twice should yield identical canonical bytes. That catches accidental nondeterminism from uninitialized padding or inconsistent string/buffer handling.
Example: Shape Invariants for Lists and Variants
Round trip equality can miss subtle shape bugs if your equality is too forgiving. Add explicit shape assertions.
prop_list_shape(list in gen_list()) {
let canon = lower_to_canonical(list);
assert_eq!(canon.length, list.length);
let lifted = lift_from_canonical(canon);
assert_eq!(lifted, list);
}
prop_variant_shape(v in gen_variant()) {
let canon = lower_to_canonical(v.clone());
assert_eq!(canon.tag, v.tag());
let lifted = lift_from_canonical(canon);
assert_eq!(lifted, v);
}
Negative Testing for Conversion Failures
Not every failure should be tested with random inputs. For canonical ABI, focus negative tests on cases that violate the contract: malformed UTF-8 if your implementation accepts raw bytes, invalid discriminants for variants, or canonical structures with inconsistent lengths. The property here is that lifting either returns the expected error representation or rejects in a predictable way.
Practical Workflow for Building Confidence
Start with small types: scalars and strings. Add lists next, then records, then sum types. Keep the first properties strict and simple, and only relax equivalence when the contract requires it. When a property fails, shrink the failing input to the smallest counterexample and use it to pinpoint whether the bug is in lowering, lifting, or the equality oracle.
A good test suite ends up feeling boring: it repeatedly checks the same invariants across many generated values, and when it fails, it fails with a minimal example you can reason about without guessing.
11.3 Integration Tests for Multi Component Linking Scenarios
Integration tests answer a specific question: “Do these separately built components still agree once they are linked and run together?” In a component world, the agreement is mostly about interface shape and canonical ABI behavior, not about matching internal implementation details. A good test suite therefore treats linking as a first-class behavior and exercises both the happy path and the failure modes that appear only after multiple components are composed.
Mind Map: Integration Test Coverage
A Systematic Test Plan
Start with a minimal two-component pipeline: Component A produces data, Component B consumes it, and the host wires them using the same WIT contract. This keeps the first failures easy to interpret. Once that passes, add a third component that transforms or validates the data, so you can catch issues that only show up when values traverse multiple canonical ABI conversions.
- Link-time tests: Attempt to link the components and assert success or failure. If linking fails, you want the failure to be immediate and specific, such as a mismatch in a record field type or a variant case name.
- Run-time tests: Call exported functions through the linked graph and assert outputs. For canonical ABI, focus on conversions that are easy to get subtly wrong: strings, lists, and variants.
- Cross-component error tests: Force Component A to return an error and confirm Component B receives the same structured error, not a generic trap.
- Repeated-call tests: Run the same scenario in a loop to catch lifetime mistakes and buffer reuse bugs that might not appear in a single call.
Example: Two Component Pipeline with Contract Assertions
Assume a WIT world where Component A exports make_request and Component B imports it as part of a handle function. The integration test should verify that the request payload survives the boundary conversion and that the response matches exactly.
Test name: pipeline_string_and_buffer_round_trip
Arrange
- Link Component A and Component B with the same WIT package
- Prepare input string: "hello"
- Prepare input bytes: [0x00, 0x01, 0x02, 0xFF]
Act
- Call host entry that triggers A then B
Assert
- Response status equals expected success code
- Response body bytes equal original bytes
- Response message string equals "ok"
The key is that the assertions are about observable behavior at the end of the pipeline, not about how either component stores data internally.
Example: Negative Linking and Error Propagation
A common integration failure is “it links, but the error shape is wrong.” To prevent that, add two tests.
Test name: link_fails_on_record_shape_mismatch
Arrange
- Build Component B against WIT where record field type differs
Act
- Attempt to link A and B
Assert
- Linking fails with a type compatibility error
- No runtime call is attempted
Test name: error_result_propagates_structured_payload
Arrange
- Configure Component A to return Result::Err with a typed error payload
Act
- Call the multi-component pipeline
Assert
- Component B returns Result::Err
- Error payload fields match exactly
- No trap occurs
This pair of tests forces the suite to distinguish between interface incompatibility (link-time) and contract-correct error handling (run-time).
Advanced Details Without Extra Complexity
When you add a third component, keep the test inputs small but varied. Use one golden case for deterministic transforms and one boundary case for each conversion category:
- Strings: empty string and a non-ASCII string.
- Lists: empty list and a list with several elements.
- Variants: each case at least once, especially the case that carries a payload.
Finally, include a repeated-call test that runs the same pipeline 100 times with alternating inputs. If canonical ABI lifting or lowering mishandles ownership, this is where it usually shows up as corrupted output or inconsistent error payloads.
Mind Map: Oracles and Failure Interpretation
Integration tests are successful when failures point to the layer: linking, conversion, or error mapping. That clarity saves time and keeps the suite from turning into a guessing game.
11.4 Negative Tests for Error Paths and Invalid Inputs
Negative tests prove that your component boundary fails in predictable ways, not just that it succeeds. In a WIT + canonical ABI setup, most “interesting” failures come from mismatched shapes, invalid discriminants, malformed string/buffer representations, and resource-lifetime mistakes. The goal is to test the contract you wrote, not the accident you happened to get.
What to Test First
Start with the smallest contract surface that can fail:
- Type shape violations: wrong record field order, missing cases, or unexpected variant tags.
- Value constraints: empty strings where non-empty is required, negative lengths, or out-of-range enum-like values.
- Representation errors: invalid UTF-8, dangling pointers, or buffers that claim a length larger than the provided memory.
- Error propagation: the component must return the specified
result/option/variant error, not trap. - Host-side misuse: host passes bad inputs; guest must respond with the defined error.
A good rule: every negative test should assert both behavior (error returned) and shape (error payload matches the contract).
Mind Map: Negative Test Coverage
Designing Error Contracts That Are Testable
If your interface uses result<T, E>, make E structured enough to be asserted. For example, include a stable error code and an optional detail string. That lets tests verify that the component didn’t just fail, it failed the right way.
A practical pattern:
- Define an error variant like
invalid-argument { reason: string }. - Keep reasons short and deterministic so tests don’t depend on incidental formatting.
- Avoid “catch-all” errors unless you also include a code that distinguishes the cause.
Example: Table-Driven Invalid Inputs
The following pseudo-test layout shows how to keep cases systematic. Each case includes the input, the expected error discriminant, and optional payload checks.
cases = [
{ name: "empty", input: "", expect: { code: "empty" } },
{ name: "bad-utf8", inputBytes: [0xFF], expect: { code: "bad-utf8" } },
{ name: "oversize", input: "a" * 1000000, expect: { code: "too-large" } },
{ name: "wrong-tag", input: { variantTag: 99 }, expect: { code: "unknown-tag" } },
{ name: "len-mismatch", input: { ptr: 0x1, len: 999 }, expect: { code: "bad-buffer" } }
]
for case in cases:
result = call_component(case.input)
assert result is Err
assert result.Err.code == case.expect.code
if case.expect has detail:
assert result.Err.detail == case.expect.detail
Even if your actual test framework differs, the structure should remain: one loop, many cases, strict assertions.
Example: Asserting Canonical ABI Error Behavior
Canonical ABI conversions can fail before your component logic runs. To test this, you need a harness that can intentionally construct malformed representations.
Common invalid inputs to include:
- String: provide a byte sequence that is not valid UTF-8 while claiming it is a string.
- Buffer: provide a pointer/length pair where length exceeds the available memory region.
- Variant: pass a discriminant that does not map to any case.
Your assertions should distinguish:
- Contract-defined errors: component returns
Errwith a known code. - Conversion failures: if the runtime traps instead of returning an error, document it and decide whether to adjust the interface to make failures representable.
Advanced Negative Scenarios Without Guesswork
Once basic invalid inputs work, add boundary-specific cases:
- List length extremes: zero-length lists and very large lengths that should be rejected.
- Nested structure corruption: valid outer record with an invalid inner variant tag.
- Resource lifetime misuse: host reuses or drops a buffer before the guest consumes it; the expected outcome should be either a defined error or a trap you can reproduce.
For each scenario, assert the exact failure mode. If you accept traps for some cases, keep them limited to states that truly cannot be represented by your error contract.
Practical Test Harness Checklist
- Every invalid case asserts the returned discriminant (not just “it failed”).
- Every error payload field that matters is checked for exact equality.
- Tests include at least one malformed input that fails during ABI conversion, not only inside component logic.
- The suite is table-driven so adding a new invalid case is a one-line change.
A negative test suite should read like a map of the ways things can go wrong at the boundary. If it does, you’ll spend less time chasing surprises and more time fixing the actual contract behavior.
11.5 Practical Test Harness Example with Automated Build and Run
A practical harness should test three things without hand-waving: (1) the interface contract is consistent across components, (2) the canonical ABI conversions behave as expected for real data, and (3) the host wiring produces the same results every time. The goal is repeatability, not cleverness.
Test Harness Overview
Use a three-stage flow: build artifacts, run a host that links components, then assert on observable outputs. Keep the assertions close to the interface types so failures point to the contract, not to ad-hoc parsing.
Test Harness Mind Map
Minimal Scenario Set
Start with a small set that covers the canonical ABI conversions you care about.
- String round-trip: pass a UTF-8 string through a guest function and compare the returned string.
- Buffer echo: send a byte buffer and confirm length and exact bytes.
- Record mapping: pass a record with multiple fields, then verify field-by-field equality.
- Variant dispatch: send a tagged union value and ensure the guest selects the correct case.
- Typed error: trigger a guest error and confirm the host receives the expected error variant and payload.
Each scenario should be deterministic: fixed inputs, fixed expected outputs, and no reliance on time or randomness.
Automated Build and Run Script
Assume a repository layout with wit/, guest/, and host/. The script below builds the guest component, builds the host runner, then runs the runner with a single command.
#!/usr/bin/env Bash
set -euo pipefail
ROOT="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
cd "$ROOT"
# 1) Generate bindings from WIT
# (Command names vary by toolchain; keep it deterministic.)
wit-bindgen --out-dir host/src/bindings wit/*.wit
wit-bindgen --out-dir guest/src/bindings wit/*.wit
# 2) Build Guest Component
cargo build -p guest --release
# 3) Build Host Runner
cargo build -p host --release
# 4) Run Tests via Host Runner
./target/release/host --component ./target/release/guest_component.wasm
If your toolchain uses a different build step for components, keep the interface generation step explicit so CI doesn’t accidentally use stale bindings.
Host Runner Test Structure
In the host runner, treat each scenario as a function that returns a structured result. Avoid stringly-typed comparisons; compare typed values or normalized representations.
struct ScenarioResult {
name: &'static str,
ok: bool,
details: String,
}
fn run_all_tests() -> Vec<ScenarioResult> {
vec![
test_string_round_trip(),
test_buffer_echo(),
test_record_mapping(),
test_variant_dispatch(),
test_typed_error(),
]
}
fn assert_eq_bytes(expected: &[u8], actual: &[u8]) -> Result<(), String> {
if expected == actual { Ok(()) }
else { Err(format!("bytes differ: expected_len={}, actual_len={}", expected.len(), actual.len())) }
}
Split normalization from assertions. For example, if canonical ABI returns a buffer as (ptr, len) plus a separate ownership rule, normalize it into Vec<u8> once, then reuse it in multiple assertions.
Example Scenario: Buffer Echo
This scenario catches the most common canonical ABI mistakes: incorrect length handling, missing copies when required, and ownership confusion.
fn test_buffer_echo() -> ScenarioResult {
let name = "buffer_echo";
let input: Vec<u8> = vec![0, 1, 2, 255, 254];
let output = call_guest_buffer_echo(&input);
match assert_eq_bytes(&input, &output) {
Ok(()) => ScenarioResult { name, ok: true, details: "".into() },
Err(e) => ScenarioResult { name, ok: false, details: e },
}
}
The helper call_guest_buffer_echo should return a fully owned Vec<u8> so the test doesn’t depend on guest memory lifetimes.
Example Scenario: Typed Error Mapping
For typed errors, assert on the error variant and its payload. If the error contract uses a result<_, error-type>, ensure the host observes the correct case.
fn test_typed_error() -> ScenarioResult {
let name = "typed_error";
let err = call_guest_fails_with_expected_error();
let ok = match err {
GuestError::InvalidInput { code } => code == 42,
_ => false,
};
ScenarioResult {
name,
ok,
details: if ok { "".into() } else { "unexpected error variant or payload".into() },
}
}
Reporting and Exit Codes
Finally, print a compact per-scenario summary and exit non-zero if any scenario fails. That makes the harness CI-friendly and keeps failures actionable.
fn main() {
let results = run_all_tests();
let failed = results.iter().filter(|r| !r.ok).count();
for r in &results {
if r.ok { println!("PASS {}", r.name); }
else { println!("FAIL {} {}", r.name, r.details); }
}
if failed > 0 { std::process::exit(1); }
}
This harness is small enough to understand quickly, but it still exercises the canonical ABI paths that usually break first: strings, buffers, structured records, variants, and typed errors.
12. Case Studies for End-to-End Component Systems
12.1 Case Study: Building a Portable Key Value Service Interface
A key value service is a good first “real” component because it forces you to decide what types cross the boundary, how errors are represented, and how callers provide data efficiently. In this case study, we design a small interface that supports get, put, and delete, then implement it as a portable component that can be linked into different hosts.
Starting with the Interface Contract
We want a contract that is stable across languages and operating environments. That means:
- Use explicit types for keys and values.
- Model absence and failure without relying on language exceptions.
- Keep the boundary shape simple enough that canonical ABI conversions are predictable.
We choose:
keyas a UTF-8 string.valueas a byte buffer so callers can store arbitrary data.getreturnsoption<buffer>to represent “not found”.putreturnsresult<_, error>to represent failures like quota limits.
Mind Map: Key Value Interface Design
WIT Interface Sketch
Below is a compact WIT-style sketch of the contract. The exact syntax may vary by toolchain, but the shapes are the important part.
package kv:example
interface store {
get: func(key: string) -> option<list<u8>>
put: func(key: string, value: list<u8>) -> result<unit, error>
delete: func(key: string) -> result<bool, error>
}
record error {
code: u32,
message: string,
}
Best practice: keep the buffer as list<u8> rather than a custom record. Canonical ABI already knows how to lower lists of integers, and that reduces surprises when generating bindings.
Canonical ABI Choices That Matter
Strings and buffers are where most boundary bugs hide.
- String encoding: treat
keyas UTF-8. The host and guest should agree that the interface expects valid UTF-8; if a caller passes invalid bytes, it should fail before crossing the boundary. - Buffer ownership:
list<u8>implies the callee receives a materialized sequence. That avoids “borrowed memory” problems, at the cost of copying. For a key value service, this is usually acceptable because values are already data-heavy. - Option and result:
option<list<u8>>cleanly represents “not found” without inventing sentinel values.result<unit, error>keeps error payloads structured.
Example: Implementing the Contract in a Component
Conceptually, the component maintains an in-memory map from string to bytes. The implementation must:
- Return
nonewhen a key is missing. - Return
ok(unit)after storing. - Return
ok(true)orok(false)for delete depending on whether a key existed. - Return
err(error)for operational failures.
// Pseudocode for behavior, not a full program
fn get(key: String) -> Option<Vec<u8>> {
map.get(&key).cloned()
}
fn put(key: String, value: Vec<u8>) -> Result<(), Error> {
if value.len() > MAX_BYTES { return Err(Error::quota()); }
map.insert(key, value);
Ok(())
}
fn delete(key: String) -> Result<bool, Error> {
Ok(map.remove(&key).is_some())
}
Best practice: enforce size limits inside the component so the error contract stays consistent across hosts.
Mind Map: Boundary Data Flow
Linking into a Host with Predictable Semantics
When you link this component into a host, the host should treat the interface as the source of truth:
- The host should not assume anything about internal storage.
- The host should handle
noneas a normal outcome. - The host should surface
error.codeanderror.messagein logs or UI, but it should not parse message text for control flow.
A practical integration test uses a fixed sequence:
put("a", [1,2,3])returnsok.get("a")returnssome([1,2,3]).delete("a")returnsok(true).get("a")returnsnone.
This sequence validates both the data conversions and the semantic contract, without requiring any host-specific behavior.
Summary of Best Practices Embedded Here
- Model absence with
optionand failures withresult. - Use
list<u8>for portable byte buffers. - Keep error payloads structured with stable fields.
- Validate inputs inside the component so behavior is consistent after linking.
- Test the contract as a sequence of observable outcomes rather than internal state.
12.2 Case Study: Implementing a Typed Image Processing Pipeline
Goal and Constraints
We’ll build a small pipeline that takes an input image, applies a typed sequence of operations, and returns a processed image. The pipeline is implemented as a component with a WIT-defined interface so the same contract can be used from multiple languages and hosts.
Constraints drive design choices:
- The interface must be stable and explicit about types.
- Pixel data must cross the boundary in a way that the canonical ABI can lift and lower reliably.
- Errors must be typed so callers can handle them without parsing strings.
Mind Map: Pipeline Architecture
Step 1: Define the Typed Contract
Start with a narrow interface: one function that processes an image and one function that validates inputs. The validation function helps hosts fail early before allocating large buffers.
Key types:
ImageFormatis an enum-like record that includes width, height, and a format tag.PixelBufferis a byte buffer plus format metadata.Operationis a variant that can represent a small set of operations.- Errors are a typed variant so callers can branch on error kinds.
A practical choice: represent operations as a list of variants. That keeps the interface extensible without changing the function signature.
Step 2: Model Operations as Variants
Operations might include:
Grayscalewith no parameters.Resizewith target width and height.AdjustBrightnesswith an integer delta.
Using variants means the canonical ABI can lower and lift the tagged union deterministically. It also forces you to handle each case explicitly in the component implementation.
Mind Map: Data Flow and Ownership
Step 3: Canonical ABI for Buffers
For pixel data, use a byte buffer representation that maps cleanly to canonical ABI lowering and lifting. The interface should avoid passing raw pointers. Instead, pass a buffer as a length plus bytes, and treat returned buffers as owned by the caller only after the component returns.
Best practice: keep the buffer representation consistent across all operations. Even if a resize changes dimensions, the output buffer still follows the same PixelBuffer shape.
Step 4: Example WIT Interface Shape
Below is a compact sketch of the interface types and function signatures. The exact WIT syntax may vary by toolchain, but the shape is what matters: typed operations, typed errors, and explicit buffer passing.
package image.pipeline:1.0.0
interface pipeline {
type ImageFormat = record { width: u32, height: u32, kind: string }
type PixelBuffer = record { format: ImageFormat, bytes: list<u8> }
type Operation = variant {
grayscale: record {}
resize: record { width: u32, height: u32 }
adjust_brightness: record { delta: i32 }
}
type Error = variant {
invalid_format: record { reason: string }
unsupported_operation: record { op: string }
bad_dimensions: record { reason: string }
}
process: func(input: PixelBuffer, ops: list<Operation>) -> result<PixelBuffer, Error>
validate: func(input: PixelBuffer) -> result<unit, Error>
}
Step 5: Component Implementation Logic
Inside the component:
- Call
validatelogic at the start ofprocess. - Iterate over
opsand apply each transformation in order. - On the first failure, return
Errwith a typed payload. - Allocate the output buffer once after you know the final dimensions.
This avoids partial outputs and keeps error handling predictable.
Example: Operation Matching and Typed Errors
fn apply_ops(input: PixelBuffer, ops: Vec<Operation>) -> Result<PixelBuffer, Error> {
let mut format = input.format.clone();
let mut bytes = input.bytes;
for op in ops {
match op {
Operation::Grayscale => {
bytes = grayscale(bytes)?;
}
Operation::Resize { width, height } => {
if width == 0 || height == 0 {
return Err(Error::BadDimensions { reason: "zero size".into() });
}
format.width = width;
format.height = height;
bytes = resize(bytes, width, height)?;
}
Operation::AdjustBrightness { delta } => {
bytes = adjust_brightness(bytes, delta)?;
}
}
}
Ok(PixelBuffer { format, bytes })
}
Step 6: Host Side Example Flow
The host constructs PixelBuffer from input bytes and a chosen kind string. It then builds a list of operations and calls process. The host receives result<PixelBuffer, Error> and branches on the error variant.
A small but important best practice: keep the host’s kind consistent with what the component expects. If the component only supports "rgba8", validate early and return invalid_format rather than attempting a conversion.
Step 7: Testing the Contract End to End
Test three layers together:
- Round trip:
validateaccepts known-good inputs. - Determinism: applying
grayscaletwice yields the same output. - Error typing: invalid dimensions return
bad_dimensionswith a stable reason string.
Mind the boundary: tests should confirm that the returned buffer length matches the expected dimensions and that the error variant is the one you intended.
Mind Map: Test Matrix
Summary of Design Choices
This pipeline case study keeps the interface small, typed, and buffer-safe. Variants model operations cleanly, typed errors make failures actionable, and a consistent buffer representation keeps canonical ABI behavior straightforward. The result is a component that can be linked and called from different hosts without rewriting the contract logic each time.
12.3 Case Study: Designing a Plugin Style World with Multiple Implementations
A plugin-style world is a component contract that lets a host discover and use multiple implementations without changing the host logic. In WebAssembly component terms, you define a WIT world that declares what the host expects, then you ship one or more components that implement that world’s exported functions.
Mind Map: Plugin Style World Anatomy
Step 1: Define the Plugin Contract in WIT
Start by deciding what the host controls and what the plugin controls. A common pattern is: the host provides configuration and input data, and the plugin returns processed output.
Use a record for configuration so fields are explicit and stable. Use a variant for results so you can represent success and typed failure without relying on strings.
Example: WIT World Shape
package plugin:[email protected]
interface processor {
process: func(config: config, input: list<u8>) -> result
}
record config {
mode: u32,
threshold: u32,
}
variant result {
ok: list<u8>,
err: error,
}
variant error {
invalid_config,
unsupported_mode,
}
world plugin_world {
export processor
}
Best practice: keep the plugin’s exported surface small. If you later add features, add them as new functions or new interfaces, not by changing existing parameter shapes.
Step 2: Implement Multiple Plugins with the Same Export
Create two components that both export processor.process but behave differently. One plugin might treat input as raw bytes and apply a simple transformation; another might validate a header format.
Example: Two Implementations
// Plugin A: simple thresholding
fn process(config: Config, input: Vec<u8>) -> Result<Vec<u8>, Error> {
if config.mode != 1 { return Err(Error::UnsupportedMode); }
let t = config.threshold as u8;
Ok(input.into_iter().map(|b| if b > t { 255 } else { 0 }).collect())
}
// Plugin B: expects a 2-byte header
fn process(config: Config, input: Vec<u8>) -> Result<Vec<u8>, Error> {
if config.mode != 2 { return Err(Error::UnsupportedMode); }
if input.len() < 2 { return Err(Error::InvalidConfig); }
Ok(input[2..].iter().map(|b| b.wrapping_add(1)).collect())
}
Best practice: map internal errors to the WIT error variant. This keeps the host from parsing ad-hoc messages and makes failures consistent.
Step 3: Host Selection Logic Without Interface Changes
The host should not need to know plugin-specific details beyond the shared contract. Selection can be based on configuration fields, a plugin identifier, or a registry entry.
Example: Host Dispatch Pattern
host receives request
parse config.mode
choose plugin component
call plugin.process(config, input)
if result is ok
return bytes
else
return typed error
Best practice: treat the host as a pure orchestrator. If you find yourself adding conditionals for plugin quirks, consider moving those quirks behind the plugin contract.
Step 4: Canonical ABI Details That Matter Here
Your contract uses list<u8> and string-free types, which is a good start for predictable boundary behavior. Still, you must be careful about ownership.
- For
list<u8>inputs, the plugin receives a view of bytes; it should copy only if it needs to retain data after the call. - For
list<u8>outputs, the plugin constructs a new buffer to return. The canonical ABI will handle lifting into the host representation.
Best practice: avoid returning huge buffers when you can return smaller structured results. If you need streaming, add a chunked interface rather than forcing one massive list<u8>.
Step 5: Linking Multiple Implementations Cleanly
In a plugin world, you typically link one host to one plugin at a time. To support multiple plugins, you either:
- Instantiate the chosen plugin component dynamically per request, or
- Instantiate all candidate plugins up front and dispatch to the selected instance.
Best practice: keep each plugin in its own package version. If you change the WIT contract, you want the mismatch to fail at link time, not at runtime.
Step 6: Contract Tests That Catch ABI and Type Mistakes
Write tests that validate behavior at the interface boundary.
Example: Minimal Contract Test Cases
- Mode 1 with threshold 10 returns only 0 or 255 bytes.
- Mode 2 with input shorter than 2 bytes returns
err.invalid_config. - Mode mismatch returns
err.unsupported_mode.
Best practice: include at least one test that stresses empty input and one that stresses a large input buffer. These are the cases where list handling and allocation behavior show up immediately.
Step 7: Implementation Decisions
Mind Map Revisited for Implementation Decisions
12.4 Case Study: Creating a Cross Language SDK Style Component Wrapper
A common SDK goal is to let application code call a service without caring which language or runtime produced it. In a component world, the “service” is a component that exposes a WIT-defined interface, while the SDK wrapper is another component (or a host-side library) that presents a stable, ergonomic API to the application. The tricky part is keeping the wrapper’s types aligned with the canonical ABI so data conversions happen predictably.
The Contract First
Start by writing a small WIT interface that your wrapper will expose to application code. Keep the surface area tight: one request type, one response type, and explicit error modeling.
Example: WIT interface shape for a “compute” call
- Input:
record { x: u32, y: u32 } - Output:
result<record { sum: u32 }, error> - Error:
record { code: u32, message: string }
Best practice: use result rather than out-of-band error codes. It forces callers to handle failure paths and makes canonical ABI lifting rules consistent.
Wrapper Architecture
The wrapper typically has three layers:
- Application-facing API: idiomatic types for the application language.
- WIT boundary: the wrapper component’s exported interface.
- Upstream adapter: calls the underlying service component.
If the wrapper is itself a component, it imports the upstream service interface and exports the SDK interface. If the wrapper is a host library, it still uses generated bindings, but instantiation and linking happen in the host.
Mind Map: Data Flow and Responsibilities
Canonical ABI Mapping in Practice
Records and strings are where most surprises show up. Canonical ABI lowering/lifting ensures the same logical types become the same physical representation across languages.
Best practice: treat strings as owned boundary values. In many languages, you’ll receive a string that is safe to read but not safe to keep as a reference into the component’s linear memory. In the wrapper, copy into the application’s native string type immediately.
Example: Wrapper call flow
- Application calls
sdk_compute(x, y). - Wrapper constructs the WIT
requestrecord. - Wrapper calls upstream
service_compute(request). - Upstream returns
result<response, error>. - Wrapper lifts the result:
- On success, extract
sum. - On failure, map
codeandmessageinto the SDK error type.
- On success, extract
- Wrapper returns to application with idiomatic error handling.
Keeping the SDK Ergonomic Without Breaking the Contract
An SDK wrapper often wants a simpler signature than the raw WIT interface. For example, the application might prefer compute(x: u32, y: u32) -> Result<u32, SdkError> rather than passing a record.
To do this safely:
- Keep the wrapper’s exported WIT interface aligned with the service contract.
- Perform ergonomic reshaping inside the wrapper implementation, not in the WIT boundary.
That means the wrapper may export a WIT function that still takes a record, while the application-facing language binding exposes a convenience method.
Example: Minimal Wrapper Interface and Error Type
Example: SDK-facing WIT interface
compute: func(request: record { x: u32, y: u32 }) -> result<record { sum: u32 }, record { code: u32, message: string }>
Best practice: ensure the error record fields are stable and named exactly. Canonical ABI lifting will map by shape, not by “meaning,” so a mismatch in field order or type can lead to confusing runtime failures.
Linking Strategy and Compatibility Checks
Before instantiation, validate that the wrapper and upstream service agree on:
- WIT package name and interface name
- Function signatures and type shapes
- Error record structure
In practice, this means your build pipeline should generate bindings from the same WIT source for both wrapper and service. If you generate from different WIT snapshots, you can end up with “compatible-looking” code that fails at linking time.
Testing the Wrapper Like an Adult
Test three categories:
- Success path: known inputs produce known sums.
- Error path: upstream returns an error and the wrapper preserves
codeandmessage. - Boundary conversion: strings and records survive round-trip without truncation or mis-typed fields.
Example test case idea: call compute(1, 2) and assert the wrapper returns sum = 3. Then call with values that trigger upstream validation and assert the wrapper error contains the exact code and a non-empty message.
A Small Implementation Checklist
- Use
resultfor errors. - Copy strings into native types immediately after lifting.
- Reshape ergonomics outside the WIT boundary.
- Generate bindings from the same WIT definitions.
- Assert error payload fields in tests.
This case study’s wrapper is “SDK style” because the application sees a clean, predictable API, while the component boundary remains strict enough that canonical ABI conversions stay boring—which is exactly what you want.
12.5 Case Study: Debugging Linking Failures with Interface Mismatch Diagnosis
A linking failure usually looks like a wall of text, but it almost always points to one of a few concrete mismatches: the interface shape differs, a type name resolves differently, or the host binding expects a different calling convention for strings and buffers. This case study shows a systematic way to diagnose the problem without guessing.
Scenario and Symptom
You have two components that should connect through a shared WIT interface contract.
- Producer component exports
process. - Consumer component imports
process. - The build or instantiation fails during linking with an error indicating an interface mismatch.
The first step is to capture the exact mismatch message and identify which side it refers to: “import expects … got …” usually means the consumer’s generated bindings don’t match the producer’s exported component.
Step 1: Confirm You Are Comparing the Same Contract
A surprisingly common cause is that both sides reference different WIT packages or worlds with the same-looking names.
Best practice: treat the WIT package name and world name as part of the API surface. If the producer and consumer use different package identifiers, the linker may treat them as incompatible even if the signatures look identical.
Quick check
- Verify the producer exports the function under the same world and interface name.
- Verify the consumer imports from the same world.
- Ensure there is no accidental duplication of the WIT package directory.
Step 2: Compare Function Signatures at the Shape Level
Even when names match, the canonical ABI depends on the exact type structure.
Common mismatches include:
stringvslist<u8>for payloadsoption<T>vsresult<T, E>for error signalingvariantcase labels differing by spelling or orderingrecordfields missing, renamed, or with different element types
Best practice: compare the full signature, not just the parameter count.
Example: Payload Type Drift
Producer exports:
process(payload: list<u8>) -> result<list<u8>, string>
Consumer imports:
process(payload: string) -> result<string, string>
The linker can’t reconcile these because canonical ABI lowering for string and list<u8> produces different memory representations.
Step 3: Diagnose Canonical ABI Sensitive Types
Canonical ABI is strict about how data is represented across the boundary.
Pay special attention to:
- Strings: encoding and ownership rules
- Lists: element type and whether it’s bytes or a structured list
- Variants: case tags and payload types
- Records: field order and exact types
Best practice: if you see a mismatch involving string, list, option, result, or variant, assume the ABI mapping differs and re-check the WIT definitions first.
Step 4: Use a Minimal Repro to Isolate the Offending Type
Reduce the interface to the smallest function that still fails.
- Keep only one exported/imported function.
- Replace complex records with a single scalar or a single list.
- Reintroduce types one at a time.
This turns a “linking failed” problem into a “this specific type shape breaks compatibility” problem.
Step 5: Apply a Targeted Fix and Rebuild
Fixes are usually one of these:
- Rename a variant case to match exactly.
- Change
stringtolist<u8>(or vice versa) on both sides. - Align record field types and ensure no field is missing.
- Ensure the same error type is used in
result<T, E>.
After each fix, rebuild and re-run linking. Don’t batch multiple changes; you want the first successful build to tell you what was wrong.
Mind Map: Interface Mismatch Diagnosis Workflow
Example: Variant Case Label Mismatch
Producer defines:
variant { Ok: list<u8>, Err: string }
Consumer expects:
variant { ok: list<u8>, Err: string }
Case labels are part of the contract. Even if the payload types match, the tag mismatch prevents canonical ABI agreement.
Example: Record Field Type Mismatch
Producer defines:
record { id: u32, payload: list<u8> }
Consumer expects:
record { id: u64, payload: list<u8> }
The linker can’t reconcile the record layout because canonical ABI must know the exact scalar widths.
Closing Checklist
When linking fails, work in this order:
- Confirm world and package identity.
- Compare full function signatures.
- Inspect canonical ABI sensitive types.
- Isolate with a minimal repro.
- Apply one targeted fix and rebuild.
If you follow that sequence, the “mismatch” stops being mysterious and becomes a concrete, fixable difference in the WIT contract.