Precision Medicine And Genomic Data Driven Healthcare Innovation
1. Introduction to Precision Medicine and Genomic Data
1.1 Defining Precision Medicine: Concepts and Scope
Precision medicine, also known as personalized medicine, is an innovative approach to disease treatment and prevention that takes into account individual variability in genes, environment, and lifestyle for each person. Unlike the traditional ‘one-size-fits-all’ model, precision medicine aims to tailor healthcare strategies to the unique characteristics of each patient, enhancing efficacy and minimizing adverse effects.
Core Concepts of Precision Medicine
- Individual Variability: Recognizes genetic, environmental, and lifestyle differences among individuals.
- Targeted Therapies: Treatments designed based on specific molecular or genetic profiles.
- Predictive Analytics: Using data to predict disease risk and treatment response.
- Prevention and Early Detection: Identifying predispositions to prevent disease onset.
Mind Map: Core Components of Precision Medicine
Scope of Precision Medicine
- Disease Diagnosis: Utilizing genomic data to improve accuracy and speed of diagnosis.
- Therapeutic Decisions: Selecting treatments based on molecular targets.
- Drug Development: Designing drugs tailored to genetic subtypes.
- Patient Monitoring: Using biomarkers and digital health tools for real-time tracking.
- Population Health: Stratifying populations for preventive interventions.
Example: Precision Medicine in Oncology
Traditional chemotherapy often affects both cancerous and healthy cells, leading to significant side effects. Precision medicine enables oncologists to analyze a tumor’s genetic mutations and prescribe targeted therapies that specifically attack cancer cells with those mutations.
- Case: A patient with non-small cell lung cancer (NSCLC) undergoes genomic profiling revealing an EGFR mutation. Instead of standard chemotherapy, the patient receives an EGFR inhibitor, resulting in improved outcomes and reduced toxicity.
Mind Map: Precision Medicine in Oncology
Example: Pharmacogenomics
Pharmacogenomics studies how genes affect a person’s response to drugs. For example, patients with certain CYP2C19 gene variants metabolize the blood thinner clopidogrel less effectively, increasing the risk of clotting. Testing for this variant allows clinicians to prescribe alternative medications.
Mind Map: Pharmacogenomics in Precision Medicine
Summary
Precision medicine represents a paradigm shift in healthcare, emphasizing the customization of medical care based on individual genetic and environmental factors. Its scope spans diagnosis, treatment, prevention, and population health, supported by advances in genomic technologies and data analytics. By integrating best practices such as genomic profiling and pharmacogenomic testing, healthcare providers can improve patient outcomes and reduce healthcare costs.
End of section 1.1
1.2 The Role of Genomic Data in Modern Healthcare
Genomic data has become a cornerstone in transforming modern healthcare by enabling more precise, predictive, and personalized approaches to disease diagnosis, treatment, and prevention. This section explores the multifaceted role of genomic data, illustrating its applications with clear examples and visual mind maps to facilitate understanding.
Understanding Genomic Data
Genomic data refers to the complete DNA sequence information of an individual or organism. It includes variations such as single nucleotide polymorphisms (SNPs), insertions, deletions, copy number variations, and structural rearrangements. These variations can influence disease susceptibility, drug response, and other health-related traits.
Mind Map: Core Roles of Genomic Data in Healthcare
Disease Diagnosis
Genomic data enables accurate diagnosis of diseases, especially those with a genetic basis. For example, whole exome sequencing (WES) can identify mutations causing rare inherited disorders that traditional diagnostic methods might miss.
Example: A child with unexplained developmental delays underwent WES, revealing a mutation in the MECP2 gene, confirming Rett syndrome. This diagnosis guided appropriate clinical management and genetic counseling.
Treatment Personalization
Genomic insights allow clinicians to tailor treatments based on an individual’s genetic makeup.
-
Pharmacogenomics: Understanding how genetic variants affect drug metabolism can optimize drug choice and dosage.
Example: Patients with certain CYP2C19 gene variants metabolize clopidogrel poorly. Genomic testing helps cardiologists prescribe alternative antiplatelet drugs to reduce adverse events.
-
Targeted Therapies: In oncology, tumor genomic profiling identifies actionable mutations.
Example: Non-small cell lung cancer patients with EGFR mutations receive tyrosine kinase inhibitors, improving survival compared to standard chemotherapy.
Mind Map: Treatment Personalization Using Genomic Data
Risk Prediction and Prevention
Genomic data helps identify individuals at high risk for certain diseases, enabling early interventions.
Example: BRCA1/BRCA2 gene testing identifies women at increased risk for breast and ovarian cancer, who may then opt for enhanced screening or preventive surgery.
Additionally, polygenic risk scores aggregate multiple genetic variants to estimate risk for complex diseases like diabetes or heart disease.
Research and Drug Development
Genomic data accelerates the discovery of new drug targets and biomarkers.
Example: Genomic profiling of tumors in clinical trials allows stratification of patients likely to respond to experimental therapies, improving trial success rates.
Public Health Applications
Population-scale genomic data supports infectious disease surveillance and understanding genetic diversity.
Example: During the COVID-19 pandemic, genomic sequencing of viral samples tracked variants and informed public health responses.
Mind Map: Summary of Genomic Data Applications
Conclusion
Genomic data is integral to modern healthcare innovation, enabling a shift from one-size-fits-all approaches to precision medicine. By leveraging genomic insights, healthcare professionals can improve diagnostic accuracy, tailor treatments, predict disease risk, and contribute to research and public health efforts. The continued integration of genomic data promises to enhance patient outcomes and transform healthcare delivery.
1.3 Historical Evolution and Milestones in Genomic Medicine
The journey of genomic medicine is a fascinating story of scientific discovery, technological innovation, and clinical transformation. Understanding its historical evolution provides essential context for appreciating current capabilities and future potential.
Early Foundations: From Mendel to Molecular Biology
- Gregor Mendel (1865): The father of genetics, Mendel’s work on pea plants established the basic principles of heredity.
- Discovery of DNA Structure (1953): James Watson and Francis Crick unveiled the double helix structure of DNA, laying the groundwork for molecular genetics.
- Central Dogma of Molecular Biology (1958): Describes the flow of genetic information from DNA to RNA to protein.
The Era of Genetic Mapping and Sequencing
-
Human Genome Project (HGP) (1990-2003): A landmark international effort to sequence the entire human genome.
- Example: The HGP provided a reference genome that accelerated gene discovery and disease association studies.
-
Development of Sanger Sequencing: Enabled the first methods for DNA sequencing, crucial for the HGP.
- Positional Cloning: Technique used to identify genes based on their chromosomal location, instrumental in discovering disease genes like CFTR (cystic fibrosis).
Post-Genome Era: High-Throughput Technologies and Bioinformatics
-
Next-Generation Sequencing (NGS) (Mid-2000s): Revolutionized genomics by enabling rapid, cost-effective sequencing.
- Example: NGS allowed whole-exome and whole-genome sequencing in clinical diagnostics, such as identifying mutations in rare genetic disorders.
-
Genome-Wide Association Studies (GWAS): Enabled identification of genetic variants linked to complex diseases.
-
Emergence of Bioinformatics: Development of computational tools to analyze and interpret massive genomic datasets.
Precision Medicine and Clinical Integration
-
Pharmacogenomics: Tailoring drug therapies based on genetic profiles to improve efficacy and reduce adverse effects.
- Example: Testing for CYP2C19 variants to guide clopidogrel dosing in cardiovascular patients.
-
Targeted Cancer Therapies: Use of genomic profiling to identify actionable mutations, e.g., EGFR mutations in non-small cell lung cancer treated with tyrosine kinase inhibitors.
-
CRISPR-Cas9 Gene Editing (2012): A breakthrough enabling precise genome modifications, opening new therapeutic avenues.
Milestones Timeline Summary
| Year | Milestone | Impact |
|---|---|---|
| 1865 | Mendel’s Laws of Inheritance | Foundation of genetics principles |
| 1953 | DNA Double Helix Discovery | Molecular basis of heredity established |
| 1990 | Human Genome Project Launch | Comprehensive human genome sequencing initiated |
| 2003 | Human Genome Project Complete | Reference human genome available for research and clinics |
| 2005 | Next-Generation Sequencing | High-throughput sequencing accelerates genomics |
| 2012 | CRISPR-Cas9 Gene Editing | Precise genome editing technology developed |
Integrated Example: From Discovery to Patient Care
Consider the case of BRCA1/2 gene mutations:
- Initially identified through genetic linkage studies in families with high breast cancer incidence.
- Sequencing technologies enabled rapid testing for these mutations.
- Clinical guidelines now recommend genetic testing for at-risk individuals.
- Personalized prevention strategies and targeted therapies (e.g., PARP inhibitors) have improved outcomes.
This example illustrates how historical milestones collectively enabled a genomic medicine success story.
Summary
The historical evolution of genomic medicine reflects a continuous interplay between scientific discovery, technological innovation, and clinical application. Each milestone has contributed to transforming healthcare from a one-size-fits-all approach to a precise, data-driven discipline tailored to individual genetic profiles.
1.4 Best Practice: Integrating Genomic Data into Clinical Decision-Making with Case Study on Oncology
Overview
Integrating genomic data into clinical decision-making represents a transformative approach in oncology, enabling personalized treatment plans tailored to the genetic profile of a patient’s tumor. This best practice section explores practical steps, challenges, and illustrative examples to guide healthcare professionals in leveraging genomic insights effectively.
Key Steps in Integrating Genomic Data into Clinical Practice
Example: Workflow for Genomic Integration in Oncology
- Sample Collection: Obtain tumor tissue or blood samples for genomic sequencing.
- Sequencing & Bioinformatics: Use NGS to identify mutations, copy number variations, and gene fusions.
- Interpretation: Employ bioinformatics pipelines and clinical databases (e.g., COSMIC, ClinVar) to classify variants.
- Clinical Correlation: Discuss findings in a molecular tumor board to determine actionable targets.
- Treatment Plan: Select targeted therapies or immunotherapies based on genomic alterations.
- Patient Communication: Explain genomic results and treatment rationale clearly.
- Monitoring: Use liquid biopsies to track tumor genomics over time and adjust therapy accordingly.
Case Study: Precision Oncology in Non-Small Cell Lung Cancer (NSCLC)
Background: NSCLC is a leading cause of cancer mortality. Genomic profiling has identified driver mutations such as EGFR, ALK, and ROS1 that guide targeted therapy.
Implementation:
- A 58-year-old patient diagnosed with advanced NSCLC undergoes tumor biopsy.
- NGS panel reveals an EGFR exon 19 deletion.
- Molecular tumor board recommends first-line treatment with an EGFR tyrosine kinase inhibitor (TKI).
- Patient consents and begins therapy.
- Follow-up liquid biopsies detect emergence of T790M resistance mutation after 12 months.
- Therapy is switched to a third-generation TKI targeting T790M.
Outcome: Personalized genomic data enabled tailored treatment, prolonged progression-free survival, and minimized unnecessary toxicity.
Best Practices Summary
Additional Example: Integrating Genomic Data in Breast Cancer
- Genomic Test: Oncotype DX assesses recurrence risk based on gene expression.
- Clinical Use: Helps decide on chemotherapy necessity in early-stage hormone receptor-positive breast cancer.
- Impact: Avoids overtreatment and personalizes therapy intensity.
Visual Summary: Genomic Data Flow in Clinical Oncology
Conclusion
Integrating genomic data into oncology clinical decision-making requires a structured approach combining advanced sequencing technologies, robust bioinformatics, multidisciplinary collaboration, and patient-centered communication. Real-world examples like NSCLC demonstrate how this integration improves outcomes by enabling precision therapies tailored to individual tumor genetics.
1.5 Challenges and Ethical Considerations in Genomic Data Usage
Genomic data usage in precision medicine offers transformative potential but also presents significant challenges and ethical considerations. Understanding these is crucial for medical researchers, bioinformatics specialists, and healthcare strategists to responsibly harness genomic information.
Key Challenges in Genomic Data Usage
-
Data Privacy and Confidentiality
- Genomic data is uniquely identifiable and sensitive.
- Risk of unauthorized access or data breaches.
- Example: A hospital’s genomic database was hacked, exposing patient genetic information, raising concerns about misuse.
-
Data Security
- Protecting data during storage, transfer, and analysis.
- Implementing encryption and secure access controls.
-
Data Volume and Complexity
- Genomic datasets are massive and complex.
- Requires advanced computational infrastructure.
- Example: Whole genome sequencing generates ~200 GB per patient, challenging storage and processing.
-
Interoperability and Standardization
- Diverse data formats and standards hinder data sharing.
- Need for common ontologies and data models.
-
Interpretation and Clinical Validity
- Variants of uncertain significance complicate clinical decisions.
- Example: A variant found in a patient’s BRCA gene may not have clear implications, requiring cautious interpretation.
-
Equity and Access
- Disparities in access to genomic testing and therapies.
- Risk of exacerbating healthcare inequalities.
-
Regulatory and Legal Challenges
- Varying regulations across countries.
- Intellectual property issues around genomic data.
Ethical Considerations in Genomic Data Usage
-
Informed Consent
- Patients must understand what genomic testing entails, including potential risks and benefits.
- Example: Consent forms that explain possible incidental findings and data sharing policies.
-
Data Ownership and Control
- Who owns genomic data—the patient, the healthcare provider, or the research institution?
- Ethical frameworks advocate for patient autonomy.
-
Return of Results and Incidental Findings
- Deciding which genomic findings to return to patients.
- Balancing clinical utility with potential anxiety or harm.
-
Privacy vs. Research Advancement
- Sharing data accelerates research but may compromise individual privacy.
- Example: Large-scale genomic consortia use de-identified data but must ensure re-identification risks are minimized.
-
Genetic Discrimination
- Potential misuse of genomic data by employers or insurers.
- Laws like GINA (Genetic Information Nondiscrimination Act) in the US aim to prevent this.
-
Cultural Sensitivity and Respect
- Different populations may have varying views on genetic testing.
- Engaging communities respectfully is essential.
Mind Map: Challenges in Genomic Data Usage
Mind Map: Ethical Considerations in Genomic Data Usage
Integrated Example: Implementing Ethical Genomic Data Use in a Cancer Research Hospital
Scenario: A cancer research hospital implements a precision medicine program using patient genomic data.
- Challenge: Ensuring patient genomic data privacy while enabling research collaborations.
- Best Practice: The hospital adopts a robust consent process explaining data use and sharing.
- Technical Measures: Data encryption, role-based access, and anonymization techniques are applied.
- Ethical Approach: Patients are given options to receive incidental findings or opt out.
- Outcome: Enhanced patient trust, compliance with regulations, and accelerated research discoveries.
Summary
Navigating the challenges and ethical considerations in genomic data usage requires a multidisciplinary approach combining technical safeguards, clear policies, patient engagement, and adherence to legal frameworks. By embedding best practices and learning from real-world examples, healthcare innovators can responsibly advance precision medicine for improved patient outcomes.
2. Genomic Technologies Enabling Precision Medicine
2.1 Next-Generation Sequencing (NGS): Techniques and Applications
Next-Generation Sequencing (NGS) has revolutionized genomic research and clinical diagnostics by enabling rapid, high-throughput sequencing of DNA and RNA. This technology allows for comprehensive analysis of genomes, exomes, transcriptomes, and epigenomes, facilitating precision medicine approaches.
Overview of NGS Techniques
NGS encompasses various sequencing platforms and chemistries, each suited for different applications. The core principle involves massively parallel sequencing, generating millions of short reads that are computationally assembled and analyzed.
Common NGS Techniques
- Whole Genome Sequencing (WGS): Sequencing the entire genome to identify all genetic variants.
- Whole Exome Sequencing (WES): Targeting only the protein-coding regions (~1-2% of the genome) for cost-effective variant detection.
- Targeted Sequencing: Focusing on specific genes or regions of interest, often used in cancer panels.
- RNA Sequencing (RNA-Seq): Sequencing the transcriptome to analyze gene expression and splicing.
- Epigenomic Sequencing: Techniques like ChIP-Seq and Bisulfite Sequencing to study DNA-protein interactions and methylation patterns.
Mind Map: NGS Techniques
Applications of NGS in Healthcare and Biotechnology
-
Genetic Disease Diagnosis:
- Example: Using WES to identify causative mutations in rare inherited disorders, such as diagnosing a child with a previously undiagnosed neurodevelopmental condition.
-
Oncology:
- Example: Targeted sequencing panels detect actionable mutations in tumors (e.g., EGFR mutations in lung cancer) to guide targeted therapies.
-
Pharmacogenomics:
- Example: Sequencing genes like CYP2C19 to predict patient response to drugs such as clopidogrel, optimizing drug choice and dosage.
-
Infectious Disease:
- Example: Metagenomic sequencing for pathogen identification in complex infections, enabling rapid and precise treatment.
-
Prenatal Screening:
- Example: Non-invasive prenatal testing (NIPT) using cell-free fetal DNA sequencing to detect chromosomal abnormalities.
-
Agricultural Biotechnology:
- Example: Sequencing crop genomes to identify traits for improved yield and disease resistance.
Mind Map: NGS Applications
Best Practice Example: Implementing Targeted NGS Panels in Clinical Oncology
Context: A hospital integrates a targeted NGS panel covering 50 cancer-related genes to personalize treatment for lung cancer patients.
Steps:
- Sample collection and DNA extraction from tumor biopsies.
- Library preparation using hybrid capture for target enrichment.
- Sequencing on an Illumina platform generating paired-end reads.
- Bioinformatics pipeline for variant calling, annotation, and clinical interpretation.
- Multidisciplinary tumor board reviews results to guide therapy.
Outcome: Increased identification of actionable mutations leading to tailored therapies, improved patient outcomes, and reduced unnecessary treatments.
Challenges and Considerations
- Data Complexity: Managing and interpreting large datasets requires robust bioinformatics infrastructure.
- Quality Control: Ensuring sample quality and sequencing accuracy is critical.
- Turnaround Time: Clinical applications demand rapid processing.
- Cost: While costs have decreased, budget considerations remain.
- Ethical Issues: Incidental findings and patient consent must be managed carefully.
Summary
Next-Generation Sequencing is a cornerstone technology driving genomic data-driven healthcare innovation. By understanding its techniques and diverse applications, medical researchers, bioinformatics specialists, and healthcare strategists can harness NGS to advance precision medicine initiatives effectively.
2.2 CRISPR and Gene Editing: Revolutionizing Therapeutic Approaches
Introduction
CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) technology has transformed the landscape of gene editing, enabling precise, efficient, and cost-effective modifications of DNA sequences. This revolutionary tool is driving therapeutic innovations by allowing scientists to correct genetic defects, engineer immune cells, and develop novel treatments for a broad range of diseases.
What is CRISPR?
- A natural bacterial defense mechanism adapted for gene editing
- Uses a guide RNA (gRNA) to target specific DNA sequences
- Cas9 enzyme acts as molecular scissors to cut DNA at targeted sites
Mind Map: CRISPR Basics
Therapeutic Applications of CRISPR
-
Monogenic Disease Correction
- Example: Sickle Cell Disease
- CRISPR edits the mutated HBB gene in hematopoietic stem cells
- Edited cells reintroduced to patient to produce healthy red blood cells
- Example: Sickle Cell Disease
-
Cancer Immunotherapy
- Example: Engineering CAR-T Cells
- CRISPR used to knock out PD-1 gene to enhance T-cell activity
- Improves immune response against tumors
- Example: Engineering CAR-T Cells
-
Infectious Disease Treatment
- Example: HIV
- CRISPR targets and disrupts CCR5 receptor gene to prevent HIV entry
- Example: HIV
-
Rare Genetic Disorders
- Example: Duchenne Muscular Dystrophy
- Exon skipping via CRISPR to restore dystrophin protein expression
- Example: Duchenne Muscular Dystrophy
Mind Map: Therapeutic Applications
Best Practices in CRISPR Therapeutics
- Target Validation: Confirm gene target relevance and minimize off-target effects
- Delivery Methods: Optimize vectors (viral, lipid nanoparticles) for efficient and safe delivery
- Ethical Considerations: Ensure informed consent and address germline editing concerns
- Preclinical Testing: Use relevant animal models to assess efficacy and safety
Example: CRISPR Treatment for Sickle Cell Disease
- Patient’s hematopoietic stem cells extracted
- CRISPR edits BCL11A enhancer to reactivate fetal hemoglobin production
- Edited cells infused back to patient
- Clinical trials show promising results with symptom alleviation
Challenges and Future Directions
- Minimizing off-target mutations to ensure safety
- Enhancing delivery to specific tissues and cell types
- Expanding applications beyond monogenic diseases
- Regulatory frameworks adapting to gene editing therapies
Mind Map: Challenges & Future Directions
Summary
CRISPR and gene editing technologies represent a paradigm shift in therapeutic development, offering unprecedented precision and versatility. By integrating best practices in target validation, delivery, and ethical oversight, healthcare innovators can harness CRISPR to develop transformative treatments that address previously intractable diseases.
References and Further Reading
- Doudna, J.A., Charpentier, E. (2014). The new frontier of genome engineering with CRISPR-Cas9. Science, 346(6213).
- Frangoul, H., et al. (2021). CRISPR-Cas9 Gene Editing for Sickle Cell Disease and β-Thalassemia. New England Journal of Medicine, 384(3), 252-260.
- Cox, D.B.T., Platt, R.J., Zhang, F. (2015). Therapeutic genome editing: prospects and challenges. Nature Medicine, 21(2), 121-131.
2.3 Bioinformatics Tools for Genomic Data Analysis: Best Practices with Example Pipelines
Bioinformatics tools are the backbone of genomic data analysis, enabling researchers and clinicians to extract meaningful insights from complex datasets. This section explores best practices for selecting and using bioinformatics tools, illustrated with example pipelines that demonstrate practical workflows.
Best Practices in Bioinformatics Tool Usage
-
Tool Selection Based on Data Type and Objective
- Choose tools optimized for your specific data (e.g., whole genome sequencing, RNA-Seq, epigenomics).
- Example: Use BWA or Bowtie2 for short-read alignment; STAR for RNA-Seq alignment.
-
Reproducibility and Documentation
- Use workflow management systems (e.g., Snakemake, Nextflow) to automate and document pipelines.
- Version control your scripts and document software versions.
-
Data Quality Control (QC)
- Implement QC steps early and throughout the pipeline.
- Example tools: FastQC for raw read quality; MultiQC to aggregate QC reports.
-
Scalability and Efficiency
- Utilize parallel processing and cloud resources when handling large datasets.
- Example: Use GATK’s Spark-enabled tools for variant calling.
-
Validation and Benchmarking
- Validate results with known datasets or orthogonal methods.
- Benchmark tools using community datasets (e.g., Genome in a Bottle).
Example Pipeline 1: Whole Genome Sequencing (WGS) Variant Calling
Explanation:
- Start with raw FASTQ files.
- Perform QC using FastQC and aggregate reports with MultiQC.
- Trim low-quality bases and adapters with Trimmomatic.
- Align reads to reference genome using BWA-MEM.
- Sort and mark duplicates using SAMtools and Picard.
- Call variants with GATK HaplotypeCaller.
- Filter variants based on quality metrics.
- Annotate variants using ANNOVAR or Variant Effect Predictor (VEP).
- Interpret variants with clinical databases like ClinVar.
- Visualize variants in Integrative Genomics Viewer (IGV).
Example Pipeline 2: RNA-Seq Differential Expression Analysis
Explanation:
- Begin with raw RNA-Seq FASTQ files.
- Conduct QC with FastQC and MultiQC.
- Trim adapters and low-quality sequences using Cutadapt.
- Align reads to reference transcriptome/genome with STAR.
- Count reads per gene using FeatureCounts.
- Normalize counts and perform differential expression analysis using DESeq2 or EdgeR.
- Conduct functional enrichment analysis (Gene Ontology, pathways).
- Visualize results with heatmaps and volcano plots.
Example Pipeline 3: Epigenomic Data Analysis (ChIP-Seq)
Explanation:
- Start with raw ChIP-Seq reads.
- Perform QC and trimming.
- Align reads to reference genome using Bowtie2.
- Sort alignments with SAMtools.
- Call peaks representing protein-DNA binding sites with MACS2.
- Annotate peaks to genomic features using HOMER or ChIPseeker.
- Visualize binding profiles with IGV or heatmaps.
Summary Table of Common Bioinformatics Tools
| Analysis Step | Tool Examples | Description |
|---|---|---|
| Quality Control | FastQC, MultiQC | Assess raw data quality |
| Trimming | Trimmomatic, Cutadapt, TrimGalore | Remove adapters and low-quality bases |
| Alignment | BWA, Bowtie2, STAR | Map reads to reference genome |
| Sorting & Deduplication | SAMtools, Picard | Organize and clean alignment files |
| Variant Calling | GATK, FreeBayes | Identify genetic variants |
| Annotation | ANNOVAR, VEP, HOMER | Add biological context to variants/peaks |
| Differential Expression | DESeq2, EdgeR | Identify genes with significant expression changes |
| Peak Calling | MACS2 | Detect enriched regions in ChIP-Seq data |
| Visualization | IGV, Heatmap tools | Visualize genomic data and results |
Final Recommendations
- Always tailor pipelines to your specific research question and data type.
- Validate each step with control datasets.
- Keep abreast of new tools and updates in the rapidly evolving bioinformatics landscape.
- Collaborate with bioinformatics specialists to optimize workflows.
By following these best practices and leveraging established pipelines, medical researchers and bioinformatics specialists can unlock the full potential of genomic data to drive healthcare innovation.
2.4 Data Quality and Validation in Genomic Studies
Ensuring high data quality and rigorous validation in genomic studies is foundational to the success of precision medicine initiatives. Poor quality data can lead to inaccurate interpretations, misdiagnoses, and ineffective treatments. This section explores the key aspects of data quality and validation, best practices, and illustrative examples to guide researchers and healthcare strategists.
Key Components of Data Quality in Genomic Studies
- Accuracy: Correctness of the genomic data reflecting the true biological sequence.
- Completeness: Coverage of the genome or targeted regions without significant gaps.
- Consistency: Uniformity of data across different samples, platforms, and time points.
- Reproducibility: Ability to obtain the same results under consistent conditions.
- Timeliness: Data availability aligned with clinical or research needs.
Mind Map: Core Elements of Data Quality
Common Sources of Data Quality Issues
- Sample contamination or degradation
- Sequencing errors (e.g., homopolymer errors in some platforms)
- Incomplete or biased coverage
- Bioinformatics pipeline inconsistencies
- Data entry or annotation mistakes
Best Practices for Ensuring Data Quality
-
Sample Quality Control (QC):
- Use standardized protocols for sample collection, storage, and processing.
- Assess DNA/RNA integrity using metrics like RIN (RNA Integrity Number).
-
Sequencing Quality Metrics:
- Monitor Phred quality scores to assess base call accuracy.
- Ensure sufficient sequencing depth (e.g., 30x coverage for whole genome).
-
Bioinformatics QC Steps:
- Use tools like FastQC for raw read quality assessment.
- Apply trimming and filtering to remove low-quality reads and adapters.
- Detect and correct batch effects using normalization techniques.
-
Validation of Variants:
- Confirm key variants using orthogonal methods such as Sanger sequencing.
- Use replicate samples or technical replicates to assess reproducibility.
-
Data Annotation and Curation:
- Employ standardized databases (e.g., dbSNP, ClinVar) for variant annotation.
- Regularly update annotation pipelines to reflect latest knowledge.
Mind Map: Best Practices for Data Quality Assurance
Example: Ensuring Data Quality in a Cancer Genomics Study
Context: A research team sequences tumor samples to identify actionable mutations.
- Sample QC: Tumor biopsies are snap-frozen immediately after collection to preserve DNA integrity.
- Sequencing QC: Achieved an average coverage of 100x to confidently detect somatic mutations.
- Bioinformatics QC: Used FastQC and Trim Galore to clean raw reads; applied batch effect correction due to samples processed on different days.
- Variant Validation: Key driver mutations confirmed via Sanger sequencing.
- Outcome: High-confidence mutation calls enabled personalized therapy selection.
Validation Strategies in Genomic Studies
- Internal Validation: Using subsets of data or replicates within the study to confirm findings.
- External Validation: Comparing results with independent datasets or cohorts.
- Functional Validation: Laboratory experiments to confirm biological relevance (e.g., gene expression assays).
Mind Map: Validation Strategies
Example: Variant Validation Workflow
- Initial variant calling from NGS data.
- Filter variants based on quality metrics (e.g., read depth, allele frequency).
- Cross-check variants against known databases.
- Select clinically relevant variants for orthogonal validation.
- Perform Sanger sequencing on selected variants.
- Integrate validated variants into clinical reports.
Summary
Maintaining rigorous data quality and validation protocols is essential for reliable genomic insights that drive precision medicine. By combining robust sample handling, sequencing quality control, bioinformatics rigor, and thorough validation, researchers and clinicians can confidently translate genomic data into actionable healthcare innovations.
2.5 Case Study: Using Whole Genome Sequencing to Diagnose Rare Diseases
Whole Genome Sequencing (WGS) has revolutionized the diagnosis of rare diseases by enabling comprehensive analysis of an individual’s complete genetic makeup. Unlike targeted gene panels or exome sequencing, WGS captures both coding and non-coding regions, structural variants, and complex rearrangements, which are often critical in rare disease diagnosis.
Overview of Whole Genome Sequencing in Rare Disease Diagnosis
- Comprehensive Variant Detection: WGS detects single nucleotide variants (SNVs), insertions/deletions (indels), copy number variants (CNVs), and structural variants.
- Unbiased Approach: No prior assumptions about candidate genes are needed.
- Improved Diagnostic Yield: Studies show WGS can increase diagnostic rates by 10-20% compared to exome sequencing.
Mind Map: Workflow of WGS in Rare Disease Diagnosis
Example: Diagnosing a Child with Undiagnosed Neurological Symptoms
Background: A 5-year-old child presents with developmental delay, seizures, and muscle weakness. Previous metabolic and targeted genetic tests were inconclusive.
Approach: The clinical team orders WGS to identify potential genetic causes.
Findings:
- WGS reveals a novel pathogenic variant in the SCN1A gene, known to cause Dravet syndrome.
- Variant was missed in prior targeted panels due to atypical mutation location.
Outcome:
- Diagnosis confirmed.
- Treatment plan adjusted to avoid sodium channel blockers.
- Family offered genetic counseling for recurrence risk.
Best Practices Illustrated in This Case
- Comprehensive Phenotyping: Detailed clinical data guided interpretation of WGS results.
- Multidisciplinary Collaboration: Geneticists, neurologists, and bioinformaticians worked together.
- Use of Updated Databases: Variant interpretation leveraged ClinVar, HGMD, and population databases.
- Iterative Analysis: Reanalysis of WGS data after initial negative results led to diagnosis as new knowledge emerged.
Mind Map: Variant Interpretation Framework
Additional Example: Diagnosing a Rare Metabolic Disorder
Scenario: A newborn with unexplained metabolic acidosis and failure to thrive.
WGS Result: Identification of a homozygous mutation in the MUT gene causing methylmalonic acidemia.
Impact: Early diagnosis enabled prompt dietary management and improved prognosis.
Challenges and Considerations
- Data Interpretation Complexity: Large volume of variants requires robust filtering.
- Variants of Uncertain Significance: May require functional studies or family testing.
- Turnaround Time and Cost: WGS is becoming more affordable but still resource-intensive.
- Ethical Issues: Incidental findings and data privacy must be managed carefully.
Summary
Whole Genome Sequencing is a powerful tool for diagnosing rare diseases, especially when traditional methods fail. By integrating comprehensive genomic data with clinical expertise and best practices in bioinformatics, healthcare providers can deliver precise diagnoses and personalized care.
References & Resources
- ACMG Standards and Guidelines for Interpretation of Sequence Variants
- ClinVar Database: https://www.ncbi.nlm.nih.gov/clinvar/
- Genome Aggregation Database (gnomAD): https://gnomad.broadinstitute.org/
- Case studies from the Undiagnosed Diseases Network (UDN)
3. Data Integration and Management in Genomic Healthcare
3.1 Building Robust Genomic Data Repositories
Introduction
Genomic data repositories are foundational to precision medicine, enabling the storage, management, and retrieval of vast amounts of genomic information. Building a robust genomic data repository involves careful planning around data architecture, scalability, security, and interoperability to ensure that genomic data can be effectively used for research and clinical applications.
Key Components of a Robust Genomic Data Repository
- Data Ingestion: Efficient pipelines to import raw and processed genomic data from sequencing platforms and external sources.
- Data Storage: Scalable storage solutions that accommodate large volumes of high-throughput sequencing data.
- Data Annotation & Metadata: Comprehensive metadata standards to describe samples, sequencing methods, and clinical context.
- Data Access & Query: User-friendly interfaces and APIs to enable researchers and clinicians to query and retrieve data.
- Security & Compliance: Measures to protect sensitive genomic information and comply with regulations like HIPAA and GDPR.
- Data Backup & Disaster Recovery: Strategies to prevent data loss and ensure business continuity.
Best Practices for Building Genomic Data Repositories
-
Adopt Scalable Cloud-Based Storage Solutions
- Example: The Broad Institute’s Terra platform uses Google Cloud to store and analyze petabytes of genomic data, allowing dynamic scaling based on demand.
-
Implement Standardized Metadata Schemas
- Example: Using the Minimum Information About a Microarray Experiment (MIAME) or the Genomic Data Commons (GDC) metadata standards to ensure consistent data annotation.
-
Ensure Interoperability Through APIs and Data Formats
- Example: Utilizing GA4GH (Global Alliance for Genomics and Health) APIs to facilitate data sharing across platforms.
-
Integrate Robust Security Protocols
- Example: Encryption at rest and in transit, role-based access controls, and audit trails as implemented by the NIH’s dbGaP repository.
-
Design for Data Versioning and Provenance Tracking
- Example: Tracking changes in datasets over time to maintain reproducibility and data integrity.
Mind Map: Building Robust Genomic Data Repositories
Example: The Genomic Data Commons (GDC)
The GDC is a comprehensive data repository that aggregates genomic and clinical data from cancer studies. It exemplifies best practices by:
- Using standardized metadata schemas to harmonize data.
- Providing open-access APIs for data retrieval.
- Implementing strict data security and controlled access for sensitive patient data.
- Supporting scalable cloud infrastructure to handle large datasets.
This repository enables researchers worldwide to access and analyze genomic data efficiently, accelerating cancer research and precision oncology.
Example: NIH’s Database of Genotypes and Phenotypes (dbGaP)
The dbGaP repository stores genotype and phenotype data from studies investigating the interaction of genotype and phenotype in humans. Key features include:
- Controlled access mechanisms to protect participant privacy.
- Detailed metadata and data dictionaries for clarity.
- Integration with bioinformatics tools for downstream analysis.
Summary
Building robust genomic data repositories requires a holistic approach that balances scalability, accessibility, security, and interoperability. Leveraging cloud technologies, adopting metadata standards, and implementing stringent security protocols are essential best practices. Real-world examples like GDC and dbGaP provide practical insights into successful repository design and management.
References & Further Reading
- Global Alliance for Genomics and Health (GA4GH): https://www.ga4gh.org/
- Genomic Data Commons: https://gdc.cancer.gov/
- NIH dbGaP: https://www.ncbi.nlm.nih.gov/gap
- Terra Platform: https://terra.bio/
- FAIR Data Principles: https://www.go-fair.org/fair-principles/
3.2 Interoperability Standards for Genomic and Clinical Data
Interoperability is the cornerstone of effective integration between genomic data and clinical information systems. It ensures that diverse data types—from sequencing results to electronic health records (EHRs)—can be seamlessly exchanged, interpreted, and utilized to drive precision medicine initiatives.
Why Interoperability Matters
- Enables comprehensive patient profiles combining genetic and clinical insights.
- Facilitates collaborative research and data sharing across institutions.
- Supports clinical decision-making with accurate, timely genomic information.
- Enhances scalability and sustainability of healthcare IT infrastructure.
Key Interoperability Standards
HL7 FHIR (Fast Healthcare Interoperability Resources)
- Modern standard for exchanging healthcare information electronically.
- Supports genomic data through specialized resources like
MolecularSequenceandObservation. - Enables RESTful APIs for real-time data retrieval and updates.
GA4GH (Global Alliance for Genomics and Health) Standards
- Focuses specifically on genomic data sharing.
- Includes frameworks like the
Phenopacketsschema to represent phenotypic and genomic data. - Promotes responsible, secure data exchange globally.
DICOM Genomics
- Extension of the DICOM standard traditionally used for imaging.
- Supports storage and communication of genomic variant data alongside imaging.
OMOP Common Data Model (CDM)
- Standardizes clinical data for observational research.
- Extensions exist to incorporate genomic data, enabling integrated analytics.
Mind Map: Interoperability Standards Overview
Best Practice Example: Integrating Genomic Data into EHR Using HL7 FHIR
Scenario: A healthcare provider wants to incorporate patients’ genomic test results into their EHR to support personalized treatment plans.
Approach:
- Use the HL7 FHIR
MolecularSequenceresource to represent raw genomic sequences. - Summarize clinically relevant variants using the
Observationresource with standardized coding (e.g., LOINC, HGVS nomenclature). - Implement FHIR RESTful APIs to enable the EHR system to query and retrieve genomic data on demand.
- Ensure data security and patient consent are managed according to HIPAA and GDPR.
Outcome: Clinicians can access actionable genomic insights directly within the patient’s health record, enabling more informed decisions.
Mind Map: HL7 FHIR Genomic Data Integration Workflow
Example: GA4GH Phenopackets for Phenotype-Genotype Data Sharing
Context: Researchers collaborating internationally need to share detailed patient phenotype and genotype data to identify novel disease associations.
Implementation:
- Use the Phenopackets schema to encode patient clinical features, family history, and genomic variants in a standardized JSON format.
- Share Phenopackets via secure APIs or data repositories.
- Facilitate computational analysis across datasets from different institutions.
Benefit: Streamlined data sharing accelerates discovery while maintaining patient privacy and data integrity.
Mind Map: GA4GH Phenopackets Structure
Challenges and Solutions
| Challenge | Solution / Best Practice | Example |
|---|---|---|
| Diverse data formats | Adopt common standards like FHIR and Phenopackets | Hospital integrates genomic lab data using FHIR resources |
| Semantic inconsistencies | Use controlled vocabularies (e.g., HGVS, LOINC, HPO) | Variant descriptions standardized across systems |
| Data privacy and consent | Implement consent management frameworks and encryption | Patient consent recorded and enforced via EHR access control |
| System integration complexity | Employ middleware platforms that translate between standards | Middleware converts lab-specific formats to FHIR-compliant data |
Summary
Interoperability standards such as HL7 FHIR, GA4GH Phenopackets, DICOM Genomics, and OMOP CDM form the backbone of genomic and clinical data integration. By adopting these standards and best practices, healthcare organizations can unlock the full potential of precision medicine, enabling seamless data exchange, improved clinical workflows, and enhanced patient outcomes.
3.3 Best Practice: Implementing FAIR Data Principles with Real-World Examples
The FAIR data principles—Findability, Accessibility, Interoperability, and Reusability—serve as a foundational framework to optimize the management and utilization of genomic and healthcare data. Implementing these principles ensures that data generated in precision medicine initiatives are maximally useful, shareable, and sustainable across research and clinical domains.
Understanding FAIR Principles
FAIR Data Principles Mind Map
Stepwise Implementation of FAIR in Genomic Healthcare Data
-
Assign Persistent Identifiers:
- Example: Using Digital Object Identifiers (DOIs) for genomic datasets in repositories like the European Nucleotide Archive (ENA).
-
Rich Metadata Annotation:
- Example: Annotating patient genomic data with clinical metadata using standardized schemas such as the Minimum Information About a Microarray Experiment (MIAME).
-
Standardized Data Formats and Ontologies:
- Example: Encoding variant data in Variant Call Format (VCF) and annotating phenotypes with Human Phenotype Ontology (HPO) terms.
-
Secure and Standardized Access Protocols:
- Example: Implementing OAuth 2.0 authentication for controlled access to sensitive patient genomic data in cloud platforms.
-
Clear Licensing and Provenance:
- Example: Applying Creative Commons licenses and recording data origin, processing steps, and versioning in metadata.
Real-World Example 1: The Global Alliance for Genomics and Health (GA4GH)
- Context: GA4GH develops interoperable standards and frameworks to enable responsible genomic data sharing worldwide.
- FAIR Implementation:
- Uses standardized APIs (e.g., GA4GH API) for data findability and accessibility.
- Promotes ontologies and data models for interoperability.
- Provides guidelines for data stewardship ensuring reusability.
GA4GH FAIR Implementation Mind Map
Real-World Example 2: NIH’s dbGaP (Database of Genotypes and Phenotypes)
- Context: dbGaP archives and distributes data from studies that have investigated the interaction of genotype and phenotype.
- FAIR Implementation:
- Assigns accession numbers for findability.
- Provides controlled access mechanisms ensuring data accessibility.
- Uses standardized phenotypic vocabularies and data formats for interoperability.
- Includes detailed metadata and data use certifications for reusability.
Real-World Example 3: The European Bioinformatics Institute (EBI) - ENA and BioSamples
- Context: EBI maintains large-scale genomic data repositories supporting FAIR principles.
- FAIR Implementation:
- Persistent identifiers (ENA accession numbers) for datasets.
- Metadata standards for sample description (BioSamples database).
- Open protocols for data retrieval.
- Licensing and provenance information clearly documented.
Practical Tips for Healthcare Organizations Implementing FAIR
- Adopt community-recognized standards and ontologies early.
- Invest in metadata curation and training for data stewards.
- Leverage cloud platforms with built-in FAIR compliance features.
- Establish clear data governance policies that address privacy and consent.
- Engage with global consortia to stay aligned with evolving FAIR practices.
Summary
Implementing FAIR principles in genomic data-driven healthcare innovation is not only a technical challenge but also an organizational and cultural one. By embedding these principles into data management workflows, healthcare organizations can accelerate research discoveries, improve patient outcomes, and foster collaboration across disciplines.
3.4 Privacy, Security, and Compliance in Genomic Data Handling
Genomic data is inherently sensitive and uniquely identifiable, making privacy, security, and regulatory compliance critical pillars in its management. Mishandling such data can lead to breaches of confidentiality, discrimination, and loss of trust among patients and research participants. This section explores best practices, frameworks, and real-world examples to ensure genomic data is protected throughout its lifecycle.
Key Concepts in Genomic Data Privacy and Security
- Privacy: Protecting individual identity and sensitive information from unauthorized access.
- Security: Technical and organizational measures to safeguard data integrity, confidentiality, and availability.
- Compliance: Adherence to legal and ethical standards governing genomic data use.
Mind Map: Core Components of Genomic Data Privacy and Security
Best Practices for Privacy and Security
-
Data Encryption:
- Encrypt genomic data both at rest and in transit using industry-standard protocols (e.g., AES-256 for storage, TLS 1.3 for transmission).
- Example: A biotech company encrypts all sequencing data stored in its cloud environment and uses VPN tunnels for secure data transfer between labs and clinical sites.
-
Access Controls:
- Implement role-based access control (RBAC) to restrict data access strictly to authorized personnel.
- Use multi-factor authentication (MFA) to add an additional layer of security.
- Example: A hospital restricts genomic data access to genetic counselors and oncologists involved in patient care, requiring MFA for system login.
-
Data Anonymization and De-identification:
- Remove or mask personally identifiable information (PII) before sharing genomic datasets.
- Use pseudonymization techniques to allow data linkage without revealing identities.
- Example: A research consortium shares de-identified genomic datasets with collaborators, ensuring no direct identifiers are included.
-
Audit Trails and Monitoring:
- Maintain detailed logs of data access and modifications.
- Use automated monitoring tools to detect unusual access patterns.
- Example: A genomic data repository uses SIEM (Security Information and Event Management) systems to monitor and alert on suspicious activities.
-
Regulatory Compliance:
- Ensure adherence to regional and international regulations such as HIPAA (Health Insurance Portability and Accountability Act), GDPR (General Data Protection Regulation), and GINA (Genetic Information Nondiscrimination Act).
- Regularly update policies and train staff on compliance requirements.
- Example: A clinical lab undergoes annual HIPAA compliance audits and provides mandatory training on genomic data privacy.
-
Incident Response Planning:
- Develop and test breach notification and mitigation plans.
- Communicate transparently with affected individuals and authorities in case of data breaches.
- Example: After detecting unauthorized access, a genomic research center promptly notifies participants and regulators, while enhancing security protocols.
Mind Map: Regulatory Landscape for Genomic Data
Real-World Example: Implementing Privacy in a Genomic Research Project
Context: A multi-institutional study collecting whole genome sequences from patients with rare diseases.
Privacy Measures Implemented:
- Data stored in encrypted cloud storage with access limited to authorized researchers.
- Participant consent forms explicitly describe data use, sharing, and privacy safeguards.
- Genomic data is pseudonymized; identifiers are stored separately in a secure database.
- Regular audits ensure compliance with GDPR and local regulations.
Outcome: The project successfully balances data utility for research with robust privacy protections, fostering participant trust and enabling valuable scientific discoveries.
Summary
Protecting genomic data privacy and security requires a multi-layered approach combining technical safeguards, policy frameworks, and ethical considerations. By adopting best practices such as encryption, access controls, anonymization, and compliance adherence, healthcare and biotechnology organizations can responsibly harness genomic data to drive innovation while maintaining patient trust and legal integrity.
3.5 Case Example: Cloud-Based Genomic Data Platforms in Collaborative Research
Cloud-based genomic data platforms have revolutionized collaborative research by enabling seamless data sharing, scalable computing resources, and integrated analytics across geographically dispersed teams. This case example explores how such platforms facilitate precision medicine research, highlighting best practices and real-world examples.
Overview of Cloud-Based Genomic Data Platforms
Cloud platforms provide infrastructure to store, process, and analyze vast genomic datasets without the limitations of local hardware. Key features include:
- Scalability: Dynamically allocate computing resources based on workload.
- Accessibility: Enable global access for multidisciplinary teams.
- Security & Compliance: Implement robust data protection and regulatory adherence.
- Integration: Support interoperability with various bioinformatics tools and clinical databases.
Mind Map: Core Components of Cloud-Based Genomic Platforms
Best Practice: Implementing a Cloud-Based Genomic Platform
- Define Collaborative Objectives: Identify research goals and data sharing needs.
- Select Cloud Provider: Choose based on compliance, cost, and tool ecosystem.
- Establish Data Governance: Define policies for data access, privacy, and audit trails.
- Integrate Bioinformatics Pipelines: Automate workflows for reproducibility.
- Enable User Training: Ensure all collaborators are proficient with platform tools.
- Monitor and Optimize: Continuously assess performance and security.
Real-World Example: The Terra Platform by Broad Institute
- Description: Terra is a cloud-native platform designed for biomedical researchers to access data, run analysis workflows, and collaborate.
- Features:
- Supports large-scale genomic datasets like TCGA and GTEx.
- Integrates workflow languages such as WDL (Workflow Description Language).
- Provides secure data sharing with granular access controls.
- Use Case: Multiple institutions collaboratively analyzed cancer genomic data to identify novel biomarkers, accelerating discovery by eliminating data silos.
Mind Map: Collaborative Research Workflow on Cloud Platforms
Example: Collaborative Rare Disease Genomics Project
- Scenario: Researchers from multiple countries pool genomic data of rare disease patients.
- Platform Use: Cloud storage allows centralized data access; standardized pipelines ensure consistent variant calling.
- Outcome: Identification of novel pathogenic variants leading to improved diagnostics.
Security and Ethical Considerations
- Implement multi-factor authentication and role-based access.
- Use data anonymization and de-identification techniques.
- Ensure compliance with international regulations (e.g., GDPR, HIPAA).
Summary
Cloud-based genomic data platforms empower collaborative research by providing scalable, secure, and accessible environments. By following best practices and leveraging platforms like Terra, research teams can accelerate genomic discoveries that drive precision medicine forward.
4. Bioinformatics and Computational Approaches
4.1 Algorithms for Variant Calling and Annotation
Variant calling and annotation are foundational steps in genomic data analysis, enabling the identification and interpretation of genetic variations that may influence disease risk, drug response, or other phenotypic traits. This section explores the key algorithms used in variant calling and annotation, illustrated with practical examples and mind maps to clarify complex workflows.
What is Variant Calling?
Variant calling is the process of identifying differences between a sequenced genome and a reference genome. These differences include single nucleotide variants (SNVs), insertions and deletions (indels), copy number variations (CNVs), and structural variants.
What is Variant Annotation?
Variant annotation involves adding biological context to the called variants by linking them to known databases, predicting their functional impact, and assessing clinical relevance.
Mind Map: Overview of Variant Calling and Annotation Workflow
Common Algorithms for Variant Calling
-
GATK HaplotypeCaller
- Uses local de-novo assembly of haplotypes in an active region to improve accuracy.
- Example: Widely used in germline variant calling for human whole-genome and exome sequencing.
-
FreeBayes
- Bayesian genetic variant detector designed for small polymorphisms.
- Example: Effective in calling variants in pooled or polyploid samples.
-
Samtools/BCFtools
- Uses a probabilistic model based on pileup data.
- Example: Fast and lightweight; often used for initial variant discovery.
-
Strelka2
- Optimized for both germline and somatic variant calling.
- Example: Frequently applied in cancer genomics for tumor-normal paired samples.
-
Manta
- Specialized in structural variant detection.
- Example: Detects large insertions, deletions, and complex rearrangements.
Mind Map: Variant Calling Algorithms and Their Use Cases
Variant Annotation Tools and Approaches
-
SnpEff
- Predicts effects of variants on genes (e.g., synonymous, missense, nonsense).
- Example: Annotating variants in a BRCA1 gene to assess pathogenicity.
-
Variant Effect Predictor (VEP)
- Developed by Ensembl; integrates multiple databases.
- Example: Provides allele frequencies, conservation scores, and clinical significance.
-
ANNOVAR
- Annotates variants with functional information and population frequencies.
- Example: Filtering out common variants based on gnomAD frequencies.
-
ClinVar Database
- Repository of clinically relevant variants.
- Example: Identifying known pathogenic variants linked to inherited diseases.
-
COSMIC
- Catalogue of somatic mutations in cancer.
- Example: Annotating tumor variants to identify driver mutations.
Mind Map: Variant Annotation Components
Example Workflow: Variant Calling and Annotation in a Cancer Genomics Study
- Data Input: Paired tumor-normal whole-exome sequencing FASTQ files.
- Preprocessing: Align reads to human reference genome (hg38) using BWA-MEM.
- Variant Calling: Use Strelka2 to detect somatic SNVs and indels.
- Filtering: Apply quality filters (e.g., minimum depth 20x, variant allele frequency >5%).
- Annotation: Annotate variants with VEP, integrating ClinVar and COSMIC databases.
- Interpretation: Identify actionable mutations such as EGFR L858R for targeted therapy.
Best Practices
- Combine Multiple Callers: Use consensus approaches to improve variant detection accuracy.
- Apply Stringent Filtering: Balance sensitivity and specificity by tuning quality thresholds.
- Update Annotation Databases Regularly: Ensure clinical relevance with the latest data.
- Validate Key Variants: Confirm important findings with orthogonal methods like Sanger sequencing.
By understanding and applying these algorithms and annotation tools, bioinformatics specialists and medical researchers can unlock the full potential of genomic data to drive precision medicine innovations.
4.2 Machine Learning in Genomic Data Interpretation: Practical Frameworks
Machine learning (ML) has become an indispensable tool in genomic data interpretation, enabling researchers and clinicians to extract meaningful patterns from vast and complex datasets. This section explores practical frameworks for applying ML to genomic data, emphasizing best practices and real-world examples.
Understanding the Role of Machine Learning in Genomics
Genomic data is characterized by its high dimensionality, complexity, and heterogeneity. ML algorithms can uncover hidden relationships, predict phenotypic outcomes, and assist in variant classification, among other applications.
Key objectives of ML in genomics include:
- Variant effect prediction
- Patient stratification
- Biomarker discovery
- Drug response prediction
Practical Framework for Machine Learning in Genomic Data Interpretation
Below is a stepwise framework to guide ML application in genomics:
Step 1: Data Collection and Integration
Collect diverse data types such as whole genome sequences, RNA expression profiles, epigenetic markers, and clinical phenotypes. For example, The Cancer Genome Atlas (TCGA) provides multi-omics datasets linked with patient outcomes.
Example: Combining genomic variants with electronic health records (EHR) to predict adverse drug reactions.
Step 2: Data Preprocessing
Genomic data often contains noise and missing values. Preprocessing steps include:
- Quality control: Removing low-quality reads or samples.
- Normalization: Adjusting for batch effects or sequencing depth.
- Feature selection: Reducing dimensionality by selecting relevant genes or variants.
Example: Using Principal Component Analysis (PCA) to reduce thousands of gene expression features to principal components before ML modeling.
Step 3: Model Selection
Choosing the right ML model depends on the problem and data:
Example: Using Random Forest classifiers to predict pathogenicity of genetic variants based on annotated features.
Step 4: Training and Validation
Robust training and validation strategies are critical to avoid overfitting and ensure generalizability.
- Cross-validation: k-fold or stratified to balance classes.
- Hyperparameter tuning: Grid search or Bayesian optimization.
Example: Training an SVM model on labeled cancer mutation data with 5-fold cross-validation to classify tumor subtypes.
Step 5: Interpretation and Explainability
Understanding model decisions is essential in healthcare.
- Feature importance: Identify which genes or variants drive predictions.
- SHAP (SHapley Additive exPlanations): Quantify contribution of each feature.
Example: Using SHAP values to explain why a patient’s genomic profile predicts high risk for a specific disease.
Step 6: Deployment and Integration
Deploy ML models within clinical decision support systems (CDSS) to aid clinicians.
- Ensure models are updated with new data.
- Monitor performance continuously.
Example: Integrating a pharmacogenomic ML model into an EHR system to provide real-time drug dosing recommendations.
Example Case Study: Predicting Breast Cancer Subtypes Using ML
- Data: Gene expression profiles from breast cancer patients.
- Approach: Preprocess data with normalization and PCA.
- Model: Train a Random Forest classifier to categorize subtypes (Luminal A, Luminal B, HER2-enriched, Basal-like).
- Outcome: Achieved >85% accuracy with interpretable feature importance highlighting key genes.
Summary Mind Map
Machine learning frameworks, when carefully designed and implemented, empower genomic medicine by transforming raw data into actionable insights. Emphasizing interpretability and clinical integration ensures these tools translate into improved patient outcomes.
4.3 Best Practice: Developing Predictive Models for Patient Stratification with Example Workflows
Patient stratification is a cornerstone of precision medicine, enabling clinicians to categorize patients into subgroups based on predicted clinical outcomes, treatment responses, or disease risks. Developing robust predictive models for patient stratification involves integrating genomic data with clinical and other omics datasets, applying appropriate computational techniques, and validating results for clinical utility.
Key Steps in Developing Predictive Models for Patient Stratification
Step 1: Data Collection and Integration
- Genomic Data: Whole genome/exome sequencing, SNP arrays, transcriptomics.
- Clinical Data: Patient demographics, medical history, lab results.
- Multi-Omics Data: Proteomics, metabolomics, epigenomics enrich model context.
Example: In breast cancer, integrating tumor gene expression profiles with clinical staging improves subtype classification.
Step 2: Data Preprocessing
- Quality Control: Remove low-quality reads or samples.
- Normalization: Adjust for batch effects and technical variability.
- Feature Selection: Identify relevant biomarkers (e.g., gene signatures) using statistical tests or domain knowledge.
Example: Using LASSO regression to select a subset of genes predictive of chemotherapy response.
Step 3: Model Development
- Algorithm Selection: Common algorithms include Random Forests, Support Vector Machines (SVM), Neural Networks, and Gradient Boosting.
- Training: Use labeled datasets to train models.
- Cross-Validation: k-fold or leave-one-out methods to prevent overfitting.
Example Workflow:
Step 4: Model Evaluation
- Metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC) are used.
- Calibration plots assess how predicted probabilities align with actual outcomes.
Example: A model predicting cardiovascular event risk achieves an AUC of 0.85, indicating strong discriminative ability.
Step 5: Clinical Integration and Continuous Monitoring
- Translate model predictions into actionable clinical decisions.
- Develop user-friendly interfaces and decision support tools.
- Continuously update models with new data to maintain accuracy.
Example: Implementing a genomic risk score dashboard in an electronic health record (EHR) system to guide statin therapy.
Example Workflow: Stratifying Patients with Acute Myeloid Leukemia (AML) Using Genomic Data
Explanation:
- Genomic variants (e.g., FLT3, NPM1 mutations) combined with clinical features (age, white blood cell count) are used to train a Random Forest model.
- The model stratifies patients into risk groups to guide treatment intensity.
Additional Tips and Best Practices
- Data Diversity: Use diverse cohorts to improve model generalizability.
- Explainability: Employ interpretable models or post-hoc explanation tools (e.g., SHAP, LIME) to build clinician trust.
- Collaboration: Engage multidisciplinary teams including bioinformaticians, clinicians, and statisticians.
- Regulatory Compliance: Ensure models meet clinical validation and regulatory standards before deployment.
Summary
Developing predictive models for patient stratification is a multi-step process that requires careful data handling, algorithmic rigor, and clinical insight. By following best practices and leveraging example workflows, healthcare professionals can harness genomic data to deliver personalized, effective care.
4.4 Visualization Techniques for Complex Genomic Data
Visualizing complex genomic data is essential for interpreting vast datasets, identifying patterns, and communicating findings effectively to both specialists and non-specialists. This section explores key visualization techniques, best practices, and practical examples to help medical researchers, bioinformatics specialists, and healthcare strategists harness the power of genomic data.
Importance of Visualization in Genomic Data
- Genomic datasets often contain millions of data points (e.g., variants, gene expression levels).
- Visualization aids in pattern recognition, anomaly detection, and hypothesis generation.
- Facilitates communication between interdisciplinary teams.
Common Visualization Techniques
-
Genome Browser Views
- Interactive platforms like UCSC Genome Browser and Ensembl.
- Visualize gene locations, variants, regulatory elements along chromosomes.
- Example: Viewing BRCA1 gene variants to understand breast cancer risk.
-
Heatmaps
- Represent gene expression or mutation frequency across samples.
- Color gradients indicate intensity or presence/absence.
- Example: Heatmap of gene expression profiles in tumor vs. normal tissues.
-
Manhattan Plots
- Used in Genome-Wide Association Studies (GWAS).
- X-axis: genomic coordinates; Y-axis: -log10(p-value) of association.
- Highlights significant loci associated with diseases.
-
Circos Plots
- Circular layout to show relationships between genomic regions.
- Useful for structural variants, gene fusions, or interchromosomal interactions.
- Example: Visualizing chromosomal translocations in leukemia.
-
Phylogenetic Trees
- Depict evolutionary relationships between sequences.
- Applied in pathogen genomics to track mutations.
-
Variant Annotation Tracks
- Layered views showing variant type, predicted impact, and clinical significance.
Best Practices for Effective Genomic Data Visualization
- Clarity and Simplicity: Avoid overcrowding; focus on key insights.
- Interactive Elements: Enable zoom, filter, and tooltip features for detailed exploration.
- Color Coding: Use consistent and colorblind-friendly palettes.
- Contextual Information: Include legends, axis labels, and annotations.
- Integration: Combine multiple data types (e.g., expression + mutation) for holistic views.
Mind Map: Visualization Techniques Overview
Example 1: Heatmap Visualization of Gene Expression
A bioinformatics specialist analyzing RNA-seq data from breast cancer patients generates a heatmap showing differential gene expression between tumor and adjacent normal tissue samples. The heatmap uses a red-to-green color scale where red indicates upregulation and green indicates downregulation.
- Insight: Clusters of genes with similar expression patterns emerge, suggesting potential biomarkers.
- Best Practice: Interactive heatmaps allow filtering by gene sets and zooming into clusters.
Example 2: Circos Plot for Structural Variant Analysis
In a study of leukemia patients, researchers use Circos plots to visualize chromosomal translocations detected via whole genome sequencing.
- The circular plot displays chromosomes arranged around the circle.
- Lines inside the circle connect translocated regions.
- Insight: Identifies recurrent translocations linked to disease prognosis.
- Best Practice: Annotate translocation lines with gene names and clinical relevance.
Mind Map: Case Study - Circos Plot Analysis
Tools and Resources
- IGV (Integrative Genomics Viewer): Desktop application for genome browsing.
- Plotly & D3.js: Libraries for interactive web-based visualizations.
- ComplexHeatmap (R package): Advanced heatmap generation.
- Circos: Software for circular visualization of genomic data.
- Phylo.io: Web tool for phylogenetic tree visualization.
Summary
Effective visualization of complex genomic data transforms raw information into actionable insights. By employing diverse visualization techniques—ranging from genome browsers to Circos plots—and adhering to best practices, healthcare professionals can enhance data interpretation, foster collaboration, and ultimately drive innovation in precision medicine.
4.5 Case Study: AI-Driven Drug Target Identification from Genomic Profiles
Introduction
The integration of artificial intelligence (AI) with genomic data has revolutionized drug discovery by enabling the identification of novel drug targets with higher precision and speed. This case study explores how AI-driven approaches leverage genomic profiles to pinpoint actionable targets, accelerating therapeutic development.
Background
Traditional drug target identification is often time-consuming and costly, relying heavily on experimental methods. With the explosion of genomic data, AI algorithms can analyze complex datasets to uncover patterns and relationships that are otherwise difficult to detect.
Step-by-Step AI-Driven Drug Target Identification Workflow
Example: AI Identifies Novel Targets in Triple-Negative Breast Cancer (TNBC)
Context: TNBC lacks targeted therapies due to its heterogeneity. Researchers applied AI to genomic and transcriptomic data from TNBC patients to find new drug targets.
Process:
- Collected whole-exome sequencing and RNA-seq data from 200 TNBC patients.
- Applied deep learning autoencoders to reduce dimensionality and capture key genomic features.
- Used Random Forest classifiers to correlate genomic features with patient outcomes.
- Prioritized genes involved in cell cycle regulation and DNA repair pathways.
Outcome:
- Identification of a previously underexplored gene, RAD51C, as a potential drug target.
- Subsequent in vitro experiments confirmed that inhibiting RAD51C reduced TNBC cell proliferation.
Best Practices for AI-Driven Drug Target Identification
Additional Example: AI and Genomic Data in Alzheimer’s Disease
- Researchers used machine learning to analyze genomic variants associated with Alzheimer’s.
- Identified TREM2 as a promising target involved in microglial function.
- AI models predicted druggability and potential off-target effects.
- This accelerated the development of monoclonal antibodies targeting TREM2.
Visualization of AI Model Workflow
Conclusion
AI-driven drug target identification from genomic profiles exemplifies the power of combining computational methods with biological data. By following best practices and validating findings experimentally, healthcare researchers and bioinformatics specialists can accelerate the discovery of effective therapies tailored to patient-specific genomic landscapes.
5. Clinical Applications of Precision Medicine
5.1 Oncology: Targeted Therapies Based on Tumor Genomics
Precision medicine has revolutionized oncology by enabling treatments tailored to the unique genomic profile of a patient’s tumor. Targeted therapies exploit specific genetic alterations driving cancer progression, improving efficacy and reducing side effects compared to traditional chemotherapy.
Understanding Tumor Genomics in Oncology
Tumor genomics involves analyzing the DNA mutations, copy number variations, gene fusions, and epigenetic changes within cancer cells. These alterations can activate oncogenes or deactivate tumor suppressor genes, fueling uncontrolled growth.
Key genomic alterations include:
- Point mutations (e.g., EGFR mutations in lung cancer)
- Gene amplifications (e.g., HER2 amplification in breast cancer)
- Gene fusions (e.g., BCR-ABL in chronic myeloid leukemia)
- Microsatellite instability and mutational burden
Mind Map: Components of Tumor Genomics in Targeted Therapy
Best Practice: Molecular Profiling to Guide Therapy Selection
Example: In non-small cell lung cancer (NSCLC), molecular profiling is standard to detect actionable mutations such as EGFR, ALK, ROS1, and BRAF. Patients with EGFR mutations benefit from tyrosine kinase inhibitors (TKIs) like osimertinib, which specifically target the mutated receptor.
Steps:
- Obtain tumor biopsy or circulating tumor DNA (liquid biopsy).
- Perform comprehensive genomic profiling using NGS panels.
- Interpret results to identify actionable mutations.
- Select targeted therapy based on mutation and approved indications.
- Monitor response and resistance mechanisms.
Mind Map: Workflow for Targeted Therapy in Oncology
Examples of Targeted Therapies Based on Tumor Genomics
| Cancer Type | Genomic Alteration | Targeted Therapy Example | Mechanism of Action |
|---|---|---|---|
| Breast Cancer | HER2 Amplification | Trastuzumab (Herceptin) | Monoclonal antibody targeting HER2 receptor |
| Chronic Myeloid Leukemia | BCR-ABL Fusion | Imatinib (Gleevec) | Tyrosine kinase inhibitor of BCR-ABL fusion |
| Melanoma | BRAF V600E Mutation | Vemurafenib | BRAF kinase inhibitor |
| NSCLC | EGFR Mutations | Osimertinib | EGFR tyrosine kinase inhibitor |
| Colorectal Cancer | KRAS Wild-Type | Cetuximab | EGFR monoclonal antibody |
Case Study: Targeted Therapy in HER2-Positive Breast Cancer
HER2-positive breast cancer accounts for approximately 20% of breast cancer cases and is characterized by aggressive tumor growth due to HER2 gene amplification.
Best Practice Implementation:
- Perform immunohistochemistry (IHC) and FISH testing to confirm HER2 status.
- Initiate trastuzumab therapy combined with chemotherapy.
- Monitor cardiac function regularly due to potential cardiotoxicity.
Outcome: Trastuzumab has significantly improved survival rates and reduced recurrence in HER2-positive patients.
Addressing Resistance Mechanisms
Tumors can develop resistance to targeted therapies through secondary mutations, pathway bypass, or phenotypic changes.
Example: In EGFR-mutated NSCLC, the T790M mutation confers resistance to first-generation TKIs. Osimertinib, a third-generation TKI, was developed to overcome this resistance.
Best Practice: Regular genomic monitoring through liquid biopsies can detect emerging resistance mutations early, allowing timely therapy adjustments.
Mind Map: Overcoming Resistance in Targeted Therapy
Summary
Targeted therapies based on tumor genomics exemplify the power of precision medicine in oncology. By understanding and exploiting the genetic drivers of cancer, clinicians can offer personalized treatments that improve outcomes and quality of life. Integrating comprehensive genomic profiling, continuous monitoring, and adaptive treatment strategies represents the best practice for harnessing tumor genomics in cancer care.
5.2 Pharmacogenomics: Personalizing Drug Prescriptions
Pharmacogenomics is the study of how an individual’s genetic makeup influences their response to drugs. By understanding genetic variations, healthcare providers can tailor drug prescriptions to maximize efficacy and minimize adverse effects, advancing the goal of precision medicine.
Why Pharmacogenomics Matters
- Variability in Drug Response: Patients often respond differently to the same medication due to genetic differences.
- Adverse Drug Reactions (ADRs): Genetic factors can increase the risk of side effects.
- Optimizing Dosage: Genetics can inform the right dose for each patient, avoiding under- or overdosing.
Key Concepts in Pharmacogenomics
Mind Map: Core Concepts of Pharmacogenomics
Examples of Pharmacogenomic Applications
Warfarin Dosing
- Background: Warfarin is a blood thinner with a narrow therapeutic window.
- Genetic Factors: Variants in CYP2C9 and VKORC1 genes affect metabolism and sensitivity.
- Best Practice: Genetic testing before prescribing warfarin helps determine the optimal starting dose.
Clopidogrel (Plavix) Response
- Background: Clopidogrel is an antiplatelet drug used to prevent strokes and heart attacks.
- Genetic Factors: CYP2C19 poor metabolizers have reduced activation of clopidogrel, leading to decreased efficacy.
- Example: Patients with CYP2C19 loss-of-function alleles may be prescribed alternative antiplatelet agents.
Codeine Metabolism
- Background: Codeine is a pain reliever metabolized into morphine.
- Genetic Factors: Ultra-rapid metabolizers of CYP2D6 convert codeine to morphine quickly, risking toxicity.
- Clinical Implication: Avoid codeine in ultra-rapid metabolizers to prevent overdose.
Best Practices for Implementing Pharmacogenomics in Clinical Settings
Mind Map: Best Practices for Pharmacogenomics Implementation
Real-World Example: St. Jude Children’s Research Hospital
- Program: Preemptive pharmacogenomic testing integrated into EHR.
- Outcome: Improved drug safety and personalized dosing protocols for pediatric patients.
Summary
Pharmacogenomics empowers healthcare providers to personalize drug prescriptions based on genetic profiles, improving therapeutic outcomes and reducing adverse events. Incorporating pharmacogenomic data into clinical workflows through best practices and decision support tools is essential for realizing its full potential.
For further reading, consider exploring resources like the Clinical Pharmacogenetics Implementation Consortium (CPIC) guidelines, which provide evidence-based recommendations for gene-drug pairs.
5.3 Best Practice: Integrating Genomic Testing into Routine Clinical Practice with Example Protocols
Integrating genomic testing into routine clinical practice is a transformative step toward personalized healthcare. It enables clinicians to tailor diagnosis, treatment, and prevention strategies based on a patient’s unique genetic makeup. To achieve this integration effectively, healthcare organizations must adopt structured protocols, multidisciplinary collaboration, and patient-centered communication.
Key Components of Integration Protocols
- Patient Selection and Indications: Identifying which patients will benefit most from genomic testing (e.g., cancer patients, rare disease suspects, pharmacogenomics candidates).
- Pre-Test Counseling: Educating patients about the purpose, benefits, risks, and limitations of genomic testing.
- Sample Collection and Handling: Standardizing procedures for obtaining and preserving biological samples (blood, saliva, tumor biopsy).
- Laboratory Testing and Quality Control: Partnering with certified genomic labs and ensuring adherence to quality standards.
- Data Interpretation and Reporting: Utilizing bioinformatics pipelines and expert review to generate clinically actionable reports.
- Post-Test Counseling and Clinical Decision Making: Discussing results with patients and integrating findings into treatment plans.
- Data Storage and Privacy: Securing genomic data in compliance with regulations like HIPAA and GDPR.
Mind Map: Workflow for Integrating Genomic Testing into Clinical Practice
Example Protocol: Genomic Testing in Oncology
- Patient Identification: Patients with advanced solid tumors refractory to standard therapies.
- Pre-Test Counseling: Genetic counselor explains tumor genomic profiling, potential outcomes, and implications.
- Sample Collection: Tumor biopsy collected during diagnostic or therapeutic procedure.
- Testing: Next-Generation Sequencing (NGS) panel targeting actionable mutations.
- Data Interpretation: Molecular tumor board reviews variants to identify targetable mutations.
- Reporting: Clinician receives a report highlighting actionable mutations and potential targeted therapies.
- Post-Test Counseling: Oncologist discusses results and personalized treatment options with the patient.
- Follow-Up: Treatment response monitored; data fed back into institutional database for continuous learning.
Example Protocol: Pharmacogenomic Testing for Medication Optimization
- Patient Identification: Patients starting medications with known pharmacogenomic interactions (e.g., warfarin, clopidogrel).
- Pre-Test Counseling: Explanation of how genetic variants affect drug metabolism and response.
- Sample Collection: Buccal swab or blood sample collected during clinic visit.
- Testing: Genotyping for relevant pharmacogenes (e.g., CYP2C9, VKORC1).
- Data Interpretation: Clinical Pharmacogenetics Implementation Consortium (CPIC) guidelines applied.
- Reporting: Pharmacogenomic report integrated into the electronic health record (EHR).
- Post-Test Counseling: Clinician adjusts drug dose or selects alternative medication based on genotype.
- Follow-Up: Monitor therapeutic efficacy and adverse effects.
Best Practices Summary
- Multidisciplinary Collaboration: Involve genetic counselors, clinicians, bioinformaticians, and pharmacists.
- Standardized Consent Process: Ensure patients understand genomic testing implications.
- Use of Clinical Decision Support Tools: Integrate genomic data into EHRs with alerts and guidance.
- Continuous Education: Train healthcare providers on genomic literacy and updates.
- Patient-Centered Communication: Tailor discussions to patient needs and literacy levels.
- Data Governance: Maintain strict privacy, security, and data sharing policies.
Additional Mind Map: Stakeholders and Roles in Genomic Testing Integration
Integrating genomic testing into routine clinical practice is a dynamic process that requires clear protocols, teamwork, and patient engagement. By following these best practices and example protocols, healthcare providers can harness genomic data to improve diagnostic accuracy, personalize therapies, and ultimately enhance patient outcomes.
5.4 Rare Genetic Disorders: Diagnosis and Treatment Innovations
Rare genetic disorders, often defined as conditions affecting fewer than 1 in 2,000 individuals, pose significant challenges in diagnosis and treatment due to their complexity and variability. Precision medicine, empowered by genomic data, is revolutionizing how these disorders are identified and managed.
Understanding Rare Genetic Disorders
- Definition & Prevalence: Over 7,000 rare diseases exist, many with a genetic basis.
- Diagnostic Challenges: Phenotypic overlap, limited clinical awareness, and scarcity of data.
Mind Map: Diagnostic Workflow for Rare Genetic Disorders
Best Practice: Early and Comprehensive Genomic Testing
Example: A pediatric patient with unexplained developmental delay underwent Whole Exome Sequencing (WES), revealing a pathogenic variant in the MECP2 gene, confirming Rett syndrome. Early diagnosis enabled tailored therapeutic interventions and family counseling.
- Practice Highlights:
- Use of WES/WGS as first-tier tests when phenotype is unclear.
- Integration of clinical and genomic data for interpretation.
- Collaboration with genetic counselors for patient support.
Treatment Innovations
- Gene Therapy: Directly targeting the genetic cause.
- Example: FDA-approved gene therapy for spinal muscular atrophy (SMA) using onasemnogene abeparvovec.
- RNA-based Therapies: Modulating gene expression.
- Example: Nusinersen for SMA, an antisense oligonucleotide.
- Enzyme Replacement Therapy (ERT): Supplementing deficient enzymes.
- Example: ERT in Gaucher disease.
- Small Molecule Drugs: Targeting specific pathways.
- Example: Ivacaftor for cystic fibrosis with specific CFTR mutations.
Mind Map: Treatment Modalities for Rare Genetic Disorders
Case Study: Innovative Treatment in Duchenne Muscular Dystrophy (DMD)
- Background: DMD is caused by mutations in the dystrophin gene leading to muscle degeneration.
- Innovation: Exon-skipping therapies (e.g., eteplirsen) allow cells to bypass faulty exons, restoring partial dystrophin production.
- Outcome: Improved muscle function and delayed disease progression.
Integrating Patient Data for Personalized Care
- Utilizing longitudinal genomic and clinical data to adapt treatment plans.
- Example: Monitoring biomarkers and adjusting enzyme replacement dosages.
Summary
Precision medicine approaches, combining advanced genomic diagnostics with innovative therapies, are transforming the landscape for rare genetic disorders. Early diagnosis through comprehensive sequencing and tailored treatments such as gene therapy and RNA-based drugs provide hope for improved patient outcomes.
References & Further Reading
- National Organization for Rare Disorders (NORD): https://rarediseases.org/
- FDA Approved Gene Therapies: https://www.fda.gov/vaccines-blood-biologics/cellular-gene-therapy-products/approved-cellular-and-gene-therapy-products
- GeneReviews: https://www.ncbi.nlm.nih.gov/books/NBK1116/
5.5 Case Study: Precision Medicine in Cardiovascular Disease Management
Cardiovascular disease (CVD) remains the leading cause of mortality worldwide, yet its management is rapidly evolving through the integration of precision medicine and genomic data. This case study explores how genomic insights and data-driven approaches are transforming cardiovascular care, highlighting best practices and real-world examples.
Overview: Precision Medicine in CVD
Precision medicine in cardiovascular disease involves tailoring prevention, diagnosis, and treatment strategies based on individual genetic profiles, lifestyle, and environmental factors. This approach aims to improve outcomes by moving beyond the traditional “one-size-fits-all” model.
Mind Map: Key Components of Precision Medicine in CVD
Genomic Profiling and Risk Assessment
One of the best practices in CVD precision medicine is the use of polygenic risk scores (PRS), which aggregate the effects of multiple genetic variants to estimate an individual’s predisposition to diseases such as coronary artery disease (CAD).
Example: The UK Biobank study demonstrated that individuals with high PRS had a threefold increased risk of CAD compared to those with low scores. This enabled clinicians to identify high-risk patients early and implement preventive strategies.
Pharmacogenomics in Cardiovascular Therapy
Pharmacogenomics plays a critical role in optimizing drug therapy for CVD patients, particularly for medications like clopidogrel and warfarin.
-
Clopidogrel: Variants in the CYP2C19 gene affect drug metabolism. Patients with loss-of-function alleles exhibit reduced drug efficacy, increasing the risk of adverse cardiovascular events.
-
Best Practice: Genetic testing prior to prescribing clopidogrel allows clinicians to select alternative antiplatelet agents (e.g., prasugrel) for poor metabolizers.
-
Example: The Clinical Pharmacogenetics Implementation Consortium (CPIC) guidelines provide actionable recommendations based on CYP2C19 genotype.
Integrating Genomic Data into Clinical Workflows
Successful implementation requires seamless integration of genomic data into Electronic Health Records (EHR) with clinical decision support systems (CDSS).
Example: The Geisinger Health System incorporated genomic data into their EHR, enabling alerts for high-risk genotypes and personalized medication suggestions, resulting in improved patient outcomes and reduced adverse drug reactions.
Multi-Omics and Biomarker Discovery
Beyond genomics, proteomics and metabolomics contribute to a comprehensive understanding of CVD.
Example: The Framingham Heart Study identified novel protein biomarkers linked to heart failure risk, which when combined with genetic data, enhanced predictive accuracy.
Patient Engagement and Ethical Considerations
Empowering patients through education and genetic counseling is vital.
Example: Mayo Clinic’s cardiovascular genetic counseling program provides patients with personalized risk information and lifestyle recommendations, improving adherence and satisfaction.
Ethical considerations include data privacy, informed consent, and equitable access to genomic testing.
Mind Map: Workflow for Precision Cardiovascular Care
Real-World Example: The eMERGE Network
The Electronic Medical Records and Genomics (eMERGE) Network integrates genomic data with EHRs across multiple institutions to study cardiovascular phenotypes.
- They demonstrated improved identification of patients at risk for arrhythmias through genomic screening.
- Implementation of pharmacogenomic alerts reduced adverse drug events related to cardiovascular medications.
Summary of Best Practices
- Utilize polygenic risk scores for early risk detection.
- Implement pharmacogenomic testing to optimize drug therapy.
- Integrate genomic data into EHRs with clinical decision support.
- Combine multi-omics data for comprehensive risk assessment.
- Engage patients with genetic counseling and education.
- Address ethical, privacy, and access challenges proactively.
Precision medicine in cardiovascular disease management exemplifies how genomic data-driven healthcare innovation can lead to personalized, effective, and safer patient care. By adopting these best practices and learning from successful case examples, healthcare providers can significantly improve cardiovascular outcomes.
6. Healthcare Systems and Policy for Genomic Medicine
6.1 Designing Healthcare Infrastructure to Support Genomic Medicine
The integration of genomic medicine into healthcare systems requires a thoughtfully designed infrastructure that supports data generation, storage, analysis, and clinical application. This section explores the critical components and best practices for building such infrastructure, illustrated with practical examples and mind maps to clarify complex relationships.
Key Components of Healthcare Infrastructure for Genomic Medicine
- Data Acquisition Systems: Sequencing platforms, sample collection protocols, and quality control.
- Data Storage Solutions: Secure, scalable storage capable of handling large genomic datasets.
- Computational Resources: High-performance computing (HPC), cloud computing, and bioinformatics pipelines.
- Interoperability Frameworks: Standards and protocols to integrate genomic data with electronic health records (EHRs).
- Clinical Decision Support Systems (CDSS): Tools that translate genomic data into actionable clinical insights.
- Security and Compliance: Ensuring patient privacy, data encryption, and adherence to regulations such as HIPAA and GDPR.
- Training and Support: Educating healthcare professionals on genomic data interpretation and system use.
Mind Map: Core Infrastructure Elements for Genomic Medicine
Best Practice Example: Building a Cloud-Enabled Genomic Infrastructure at a Regional Hospital
Context: A regional hospital aimed to incorporate genomic testing into oncology care.
Implementation Steps:
- Sequencing & Data Acquisition: Partnered with a certified genomic lab for sample sequencing.
- Cloud Storage: Adopted a HIPAA-compliant cloud provider to store raw and processed genomic data securely.
- Computational Analysis: Deployed bioinformatics pipelines on cloud HPC instances to analyze sequencing data rapidly.
- EHR Integration: Utilized FHIR standards to integrate genomic reports into the hospital’s EHR system, enabling clinicians to access genomic insights alongside patient records.
- Clinical Decision Support: Integrated variant interpretation software that flags actionable mutations and suggests targeted therapies.
- Security Measures: Implemented multi-factor authentication and data encryption both at rest and in transit.
- Training: Conducted workshops for oncologists and genetic counselors on interpreting genomic reports and using the new systems.
Outcome: The hospital reduced turnaround time for genomic reports by 40%, improved treatment personalization, and enhanced clinician confidence in using genomic data.
Mind Map: Workflow for Cloud-Enabled Genomic Infrastructure
Additional Example: National Genomic Data Network
Description: A country-wide initiative to create a federated genomic data network linking multiple hospitals and research centers.
Infrastructure Highlights:
- Distributed storage nodes connected via secure VPN.
- Standardized data formats and APIs to enable seamless data sharing.
- Centralized governance for data access and ethical oversight.
- Integration with national EHR systems to facilitate clinical use.
Impact: Enabled large-scale genomic studies, accelerated rare disease diagnosis, and fostered collaboration across institutions.
Summary
Designing healthcare infrastructure to support genomic medicine requires a multi-layered approach balancing technology, security, interoperability, and user engagement. By leveraging cloud computing, adhering to data standards, and investing in clinician training, healthcare organizations can effectively integrate genomic data into clinical workflows, ultimately improving patient outcomes.
6.2 Reimbursement Models and Economic Considerations
Precision medicine and genomic healthcare innovations present unique challenges and opportunities in reimbursement and economic frameworks. Understanding these models is critical for healthcare strategists and bioinformatics specialists to ensure sustainable integration of genomic technologies.
Overview of Reimbursement Models
- Fee-for-Service (FFS): Traditional model where providers are paid for each service rendered.
- Value-Based Care (VBC): Payment tied to patient outcomes and quality metrics.
- Bundled Payments: Single payment for a group of services related to a treatment or condition.
- Capitation: Providers receive a fixed amount per patient regardless of services used.
Economic Considerations in Genomic Medicine
- High Upfront Costs: Genomic sequencing and analysis can be expensive initially.
- Long-Term Cost Savings: Early diagnosis and targeted therapies can reduce downstream costs.
- Cost-Effectiveness Analysis: Evaluating the balance between cost and clinical benefit.
- Health Technology Assessment (HTA): Systematic evaluation of genomic interventions for reimbursement decisions.
Mind Map: Reimbursement Models in Genomic Medicine
Best Practice: Implementing Value-Based Reimbursement for Genomic Tests
Example:
A leading oncology center partnered with payers to implement a value-based reimbursement model for genomic profiling in lung cancer. The agreement linked payments to metrics such as:
- Percentage of patients receiving targeted therapies based on genomic results
- Improvement in progression-free survival
- Reduction in unnecessary treatments
This approach incentivized the use of genomic data to optimize patient outcomes while controlling costs.
Mind Map: Economic Considerations in Genomic Healthcare
Case Example: Medicare Coverage for Pharmacogenomic Testing
In 2020, the Centers for Medicare & Medicaid Services (CMS) expanded coverage for pharmacogenomic testing for certain cardiovascular drugs. This decision was based on evidence demonstrating:
- Improved drug safety and efficacy
- Reduction in adverse drug reactions
- Overall cost savings by preventing hospital admissions
This example highlights how evidence-based economic assessments can influence reimbursement policies.
Challenges and Solutions
| Challenge | Solution Example |
|---|---|
| Lack of standardized coding | Adoption of new CPT codes for genomic tests |
| Uncertain clinical utility | Conducting real-world evidence studies |
| High cost of tests | Negotiating volume-based discounts with labs |
| Payer skepticism | Demonstrating improved patient outcomes |
Mind Map: Strategies to Address Reimbursement Challenges
Summary
Reimbursement models for genomic medicine are evolving from traditional fee-for-service towards value-based frameworks that emphasize patient outcomes and cost-effectiveness. Successful economic integration requires collaboration among healthcare providers, payers, and policymakers, supported by robust clinical and economic evidence.
By adopting best practices such as value-based reimbursement agreements and leveraging health technology assessments, healthcare organizations can promote sustainable innovation in precision medicine.
6.3 Best Practice: Policy Frameworks Encouraging Genomic Data Sharing with International Examples
Genomic data sharing is a cornerstone of advancing precision medicine globally. Effective policy frameworks are essential to facilitate responsible, secure, and ethical sharing of genomic information across institutions and borders. This section explores best practices in policy development, highlighting international examples that have successfully fostered genomic data sharing.
Key Principles of Effective Genomic Data Sharing Policies
- Privacy and Confidentiality: Protecting individual patient data through robust anonymization and consent protocols.
- Ethical Governance: Ensuring transparent oversight and adherence to ethical standards.
- Interoperability: Promoting standardized data formats and protocols for seamless integration.
- Accessibility: Balancing open access with controlled data sharing to maximize research utility.
- Sustainability: Creating policies that support long-term data stewardship and funding.
Mind Map: Core Components of Genomic Data Sharing Policy Frameworks
International Examples of Policy Frameworks
-
The Global Alliance for Genomics and Health (GA4GH)
- Overview: GA4GH is an international coalition that develops frameworks and standards to enable responsible genomic data sharing.
- Best Practices: Their Framework for Responsible Sharing of Genomic and Health-Related Data emphasizes human rights, privacy, and data security.
- Example: The GA4GH Data Use Ontology (DUO) standardizes data access permissions, facilitating cross-border data sharing.
-
European Union’s General Data Protection Regulation (GDPR)
- Overview: GDPR provides a comprehensive legal framework for data protection, including genomic data, across EU member states.
- Best Practices: It enforces strict consent requirements, data minimization, and rights for data subjects.
- Example: The EU’s European Genome-phenome Archive (EGA) operates under GDPR-compliant policies, enabling secure data sharing for research.
-
The NIH Genomic Data Sharing Policy (United States)
- Overview: Mandates that NIH-funded genomic data be shared broadly to accelerate research.
- Best Practices: Requires data submission to controlled-access repositories with defined access committees.
- Example: The database of Genotypes and Phenotypes (dbGaP) manages controlled access to genomic datasets.
-
The Australian Genomics Health Alliance
- Overview: A national initiative promoting genomic data sharing within a secure and ethically governed framework.
- Best Practices: Emphasizes patient consent, data security, and integration with clinical care.
- Example: Their policy supports data sharing between research and clinical environments to improve diagnostics.
Mind Map: International Genomic Data Sharing Initiatives and Their Policy Highlights
Practical Example: Implementing a Policy Framework in a Multinational Research Consortium
-
Scenario: A consortium of research institutions from the EU, USA, and Australia collaborates on a rare disease genomic study.
-
Policy Integration Steps:
- Harmonizing Consent: Develop a unified informed consent form respecting GDPR and NIH requirements.
- Data Security Measures: Implement encryption and anonymization protocols compliant with all jurisdictions.
- Access Controls: Use GA4GH DUO to define data access levels and permissions.
- Ethical Oversight: Establish an international ethics committee to oversee data use.
- Data Sharing Platform: Deploy a cloud-based repository with tiered access, enabling secure data exchange.
-
Outcome: Enhanced collaboration, accelerated discovery, and maintained compliance with diverse regulatory environments.
Summary
Policy frameworks that encourage genomic data sharing must balance innovation with privacy, ethical, and legal considerations. International initiatives like GA4GH, GDPR, NIH policies, and national alliances provide exemplary models. By adopting standardized, transparent, and patient-centric policies, healthcare organizations and researchers can unlock the full potential of genomic data to drive precision medicine forward.
6.4 Training and Education for Healthcare Professionals in Genomics
The rapid advancement of genomics and its integration into precision medicine demands that healthcare professionals (HCPs) acquire new knowledge and skills to effectively utilize genomic data in clinical practice. Training and education are critical to bridge the gap between genomic science and patient care, ensuring that clinicians, researchers, and healthcare strategists can confidently interpret and apply genomic information.
Importance of Genomic Education for Healthcare Professionals
- Improved Patient Outcomes: Understanding genomics enables personalized treatment plans.
- Informed Clinical Decisions: Accurate interpretation of genetic tests reduces diagnostic errors.
- Ethical and Legal Awareness: Knowledge of consent, privacy, and data handling.
- Interdisciplinary Collaboration: Facilitates teamwork between geneticists, bioinformaticians, and clinicians.
Core Competencies for Genomic Literacy
- Basic genetic concepts (DNA, genes, mutations)
- Genomic technologies and testing methods
- Interpretation of genomic reports
- Ethical, legal, and social implications (ELSI)
- Communication skills for discussing genomic results with patients
Mind Map: Core Competencies in Genomic Education
Best Practices in Genomic Training
-
Modular Learning Programs: Flexible courses tailored to different professional roles.
- Example: The National Human Genome Research Institute (NHGRI) offers online modules for clinicians covering pharmacogenomics and cancer genomics.
-
Case-Based Learning: Real-world scenarios to apply genomic knowledge.
- Example: Using patient cases with BRCA1/2 mutations to discuss hereditary breast cancer management.
-
Interdisciplinary Workshops: Collaborative sessions involving genetic counselors, bioinformaticians, and physicians.
- Example: Workshops at academic medical centers where teams analyze genomic data together.
-
Continuous Education and Certification: Regular updates and credentialing to keep pace with evolving science.
- Example: The American Board of Medical Genetics and Genomics (ABMGG) certification programs.
-
Use of Digital Tools and Simulations: Interactive platforms for hands-on experience.
- Example: Virtual labs simulating variant interpretation using ClinVar and other databases.
Mind Map: Best Practices in Genomic Training
Example Program: “Genomics in Clinical Practice” Workshop
- Audience: Physicians, nurses, genetic counselors
- Format: 3-day intensive workshop
- Content:
- Day 1: Basics of genomics and sequencing technologies
- Day 2: Interpretation of genomic reports and variant classification
- Day 3: Ethical considerations and patient communication
- Outcome: Participants complete a case study and receive a certificate
Strategies to Overcome Educational Barriers
- Time Constraints: Offer microlearning modules and asynchronous content.
- Resource Limitations: Utilize open-access materials and partnerships with genomic centers.
- Varied Backgrounds: Pre-assessment to customize learning paths.
Mind Map: Overcoming Barriers in Genomic Education
Real-World Example: Mayo Clinic Genomic Medicine Training
Mayo Clinic developed a comprehensive genomic education program for its healthcare staff, combining online modules, case discussions, and hands-on genomic data interpretation. This program improved clinicians’ confidence in ordering and interpreting genetic tests, leading to more personalized patient care and better integration of genomics into routine practice.
Summary
Training and education in genomics are essential pillars for the successful implementation of precision medicine. By adopting best practices such as modular learning, case-based approaches, and interdisciplinary collaboration, healthcare professionals can build genomic literacy effectively. Overcoming barriers through flexible and accessible education ensures that genomic innovation translates into improved patient outcomes and healthcare transformation.
6.5 Case Example: National Genomic Initiatives and Their Impact on Public Health
National genomic initiatives represent large-scale efforts by governments and healthcare systems to integrate genomic data into public health strategies. These initiatives aim to accelerate precision medicine, improve disease prevention, and enhance population health outcomes by leveraging genomic insights.
Overview of National Genomic Initiatives
- Purpose: To collect, analyze, and apply genomic data at a population level.
- Goals: Early disease detection, personalized treatment, research facilitation, and public health surveillance.
- Stakeholders: Governments, healthcare providers, researchers, bioinformatics specialists, and patients.
Prominent Examples of National Genomic Initiatives
The UK Biobank
- Description: A large-scale biomedical database with genomic and health data from 500,000 UK participants.
- Impact: Enabled discovery of genetic risk factors for diseases like cardiovascular disease and diabetes.
- Best Practice: Open-access data sharing with strict privacy controls.
All of Us Research Program (USA)
- Description: Aims to gather genomic and health data from 1 million diverse participants.
- Impact: Focuses on diversity to reduce health disparities and improve personalized care.
- Best Practice: Community engagement and transparent consent processes.
Genomics England 100,000 Genomes Project
- Description: Sequenced genomes of NHS patients with rare diseases and cancers.
- Impact: Improved diagnosis rates and informed targeted therapies.
- Best Practice: Integration of genomic data into routine clinical workflows.
China Precision Medicine Initiative
- Description: Large-scale genomic data collection to support precision medicine development.
- Impact: Advances in cancer genomics and pharmacogenomics tailored to Chinese populations.
- Best Practice: Collaboration between academic institutions and industry.
Mind Map: Key Components of National Genomic Initiatives
Impact on Public Health
-
Enhanced Disease Prevention:
- Genomic risk profiling enables targeted screening programs.
- Example: BRCA gene testing in populations at risk for breast and ovarian cancer.
-
Improved Diagnostic Accuracy:
- Early and precise diagnosis of rare genetic disorders.
- Example: Rapid whole genome sequencing in neonatal intensive care units.
-
Personalized Therapeutics:
- Tailoring drug prescriptions based on pharmacogenomic data reduces adverse drug reactions.
- Example: Warfarin dosing adjusted using CYP2C9 and VKORC1 genotypes.
-
Population Health Insights:
- Identification of genetic variants influencing disease prevalence.
- Example: Sickle cell trait frequency informing targeted interventions in specific ethnic groups.
-
Reduction of Health Disparities:
- Inclusion of diverse populations ensures equitable benefits from genomic medicine.
- Example: All of Us program’s focus on underrepresented minorities.
Best Practices Demonstrated by National Initiatives
- Robust Consent Frameworks: Transparent and dynamic consent models that respect participant autonomy.
- Data Security & Privacy: Implementation of encryption, de-identification, and controlled access.
- Interdisciplinary Collaboration: Integration of clinicians, bioinformaticians, ethicists, and policymakers.
- Community Engagement: Building trust through education and involvement in decision-making.
- Sustainable Funding Models: Ensuring long-term viability of genomic programs.
Additional Mind Map: Challenges and Solutions in National Genomic Initiatives
Conclusion
National genomic initiatives have transformed the landscape of public health by embedding genomic data into healthcare systems. Through well-structured programs like the UK Biobank and Genomics England, these initiatives exemplify best practices in data management, ethical governance, and clinical integration. Their impact is evident in improved disease prevention, personalized treatments, and more equitable healthcare delivery. For healthcare strategists and bioinformatics specialists, understanding these initiatives provides a blueprint for designing and implementing genomic-driven innovations that can revolutionize patient care on a population scale.
7. Patient Engagement and Ethical Dimensions
7.1 Informed Consent in Genomic Testing: Best Practices
Informed consent is a cornerstone of ethical genomic testing, ensuring that patients understand the scope, benefits, risks, and implications of genomic analysis before proceeding. Given the complexity and sensitivity of genomic data, best practices in informed consent are essential to protect patient autonomy, privacy, and trust.
Key Components of Informed Consent in Genomic Testing
- Purpose of Testing
- Scope and Limitations
- Potential Benefits
- Possible Risks and Uncertainties
- Data Privacy and Sharing Policies
- Future Use of Genomic Data
- Right to Withdraw Consent
- Implications for Family Members
Mind Map: Components of Informed Consent
Best Practices for Obtaining Informed Consent
-
Use Clear, Non-Technical Language: Avoid jargon to ensure patient comprehension.
-
Provide Written and Verbal Information: Supplement consent forms with discussions and educational materials.
-
Discuss Potential Incidental Findings: Explain the possibility of uncovering unrelated but medically relevant information.
-
Address Data Privacy and Security: Clarify how genomic data will be stored, used, and shared.
-
Include Options for Data Sharing: Allow patients to choose whether their data can be used for research or shared with third parties.
-
Offer Genetic Counseling: Provide access to trained professionals to help interpret results and implications.
-
Document Consent Thoroughly: Keep detailed records of consent discussions and decisions.
-
Allow Time for Questions: Encourage patients to ask questions and consider their options before consenting.
Example Scenario: Informed Consent in Oncology Genomic Testing
Context: A patient diagnosed with metastatic lung cancer is offered genomic testing to identify actionable mutations for targeted therapy.
- The clinician explains the purpose: identifying mutations that can guide treatment.
- Discusses limitations: not all mutations may be detected; results may not guarantee effective treatment.
- Reviews potential benefits: personalized therapy options, improved outcomes.
- Explains risks: possible discovery of germline mutations with hereditary implications.
- Addresses data privacy: data stored securely, shared only with care team unless patient consents otherwise.
- Offers genetic counseling to discuss family risk.
- Provides written materials and answers patient questions.
- Patient signs consent form after full understanding.
Mind Map: Example Consent Discussion Flow
Example: Consent Form Excerpt (Simplified)
Purpose: To analyze your tumor’s genetic makeup to identify mutations that may guide treatment.
Risks: Testing may reveal information about inherited conditions affecting you or your family.
Data Use: Your genomic data will be stored securely and used only for your care unless you agree to research use.
Consent: I understand the above and agree to genomic testing.
Summary
Informed consent in genomic testing must be a transparent, patient-centered process that balances technical complexity with clear communication. Incorporating best practices such as plain language, counseling, and thorough documentation helps ensure ethical standards and empowers patients to make informed decisions about their genomic healthcare.
7.2 Communicating Genomic Results to Patients Effectively
Communicating genomic results to patients is a critical step in precision medicine that requires clarity, empathy, and tailored approaches. Given the complexity of genomic data, healthcare professionals must ensure patients understand their results, implications for health, and potential next steps. This section explores best practices, strategies, and examples to enhance communication effectiveness.
Key Principles for Effective Communication
- Simplicity: Use plain language avoiding jargon.
- Contextualization: Relate results to patient’s personal and family health history.
- Empathy: Recognize emotional impact and provide support.
- Interactive Dialogue: Encourage questions and confirm understanding.
- Actionability: Clearly explain what the patient can do next.
Mind Map: Core Elements of Communicating Genomic Results
Stepwise Approach to Communication
- Pre-Test Counseling: Set expectations about possible outcomes and uncertainties.
- Result Disclosure: Deliver results in person or via telehealth with adequate time.
- Explain Findings: Use analogies and visuals to describe variants and risks.
- Discuss Implications: Health management, family risk, reproductive options.
- Provide Resources: Written materials, support groups, genetic counseling.
- Document and Follow-up: Ensure patient has access to results and understands next steps.
Example: Explaining a BRCA1 Mutation Result
- Plain Language Explanation: “Your test found a change in a gene called BRCA1, which means you have a higher chance of developing breast or ovarian cancer compared to the average person.”
- Visual Aid: Show a simple diagram of how BRCA1 helps repair DNA and what happens when it’s altered.
- Actionable Steps: Discuss increased screening, preventive options, and informing family members.
Mind Map: Patient Questions and How to Address Them
Best Practice Example: Use of Interactive Digital Tools
A healthcare provider uses a tablet-based app during counseling sessions that includes:
- Interactive genome maps
- Personalized risk calculators
- Video explanations from genetic counselors
This approach improves patient engagement and comprehension, as evidenced by higher satisfaction scores and better adherence to recommended follow-ups.
Addressing Emotional and Ethical Concerns
- Recognize anxiety or distress and provide immediate emotional support.
- Respect patient autonomy in decision-making.
- Maintain confidentiality and discuss data privacy.
Summary
Effective communication of genomic results hinges on clarity, empathy, and patient-centered approaches. Utilizing visual aids, analogies, and interactive tools can demystify complex information. Encouraging dialogue and providing ongoing support ensures patients are empowered to make informed health decisions.
Additional Resources
- National Society of Genetic Counselors: https://www.nsgc.org/
- Genetics Home Reference: https://ghr.nlm.nih.gov/
- Example Patient Brochure on Genomic Testing (link to downloadable PDF)
7.3 Addressing Disparities in Access to Precision Medicine
Precision medicine promises tailored healthcare solutions based on individual genetic, environmental, and lifestyle factors. However, disparities in access to these advanced healthcare options persist globally and within countries, often driven by socioeconomic, geographic, racial, and systemic barriers. Addressing these disparities is critical to ensure equitable healthcare outcomes and to fully realize the potential of precision medicine.
Understanding Disparities in Precision Medicine Access
- Socioeconomic Barriers: High costs of genomic testing and targeted therapies limit access for low-income populations.
- Geographic Barriers: Rural and underserved areas often lack infrastructure and specialists trained in genomic medicine.
- Racial and Ethnic Disparities: Underrepresentation of minority populations in genomic databases leads to less effective diagnostics and treatments.
- Health Literacy and Awareness: Limited understanding of precision medicine among patients and some healthcare providers.
- Policy and Insurance Coverage: Variability in reimbursement policies affects patient affordability.
Mind Map: Factors Contributing to Disparities in Precision Medicine Access
Best Practices to Address Disparities
-
Enhancing Representation in Genomic Research
- Actively recruit diverse populations in clinical trials and genomic studies.
- Example: The NIH’s All of Us Research Program aims to collect data from one million diverse participants to improve representation.
-
Reducing Cost Barriers
- Subsidize genomic testing for underserved populations through government programs or philanthropic initiatives.
- Example: Some cancer centers offer no-cost or reduced-cost genomic profiling for low-income patients.
-
Expanding Infrastructure and Telemedicine
- Deploy tele-genomics services to reach rural or remote patients.
- Example: Telehealth platforms providing genetic counseling remotely, such as the Geisinger Health System’s tele-genetics program.
-
Improving Health Literacy and Provider Training
- Develop culturally sensitive educational materials for patients.
- Train healthcare providers on genomic medicine and communication strategies.
- Example: The Global Genomics Nursing Alliance provides resources to improve genomic literacy among nurses worldwide.
-
Policy Advocacy and Insurance Reform
- Advocate for broader insurance coverage of genomic tests and targeted therapies.
- Example: Some states in the US have passed laws mandating coverage for genetic testing in cancer care.
Mind Map: Strategies to Reduce Disparities in Precision Medicine
Real-World Examples
-
All of Us Research Program (USA): Aims to build a diverse health database representing underrepresented groups to improve precision medicine applicability.
-
Geisinger Health System Tele-Genetics: Provides remote genetic counseling to rural patients, overcoming geographic barriers.
-
Genomic Data Sharing Initiatives: Projects like the Global Alliance for Genomics and Health (GA4GH) promote equitable data sharing to include diverse populations.
-
Community-Based Participatory Research (CBPR): Engages minority communities directly in research design and implementation, increasing trust and relevance.
-
Philanthropic Programs: Organizations like the Cancer Genome Atlas have partnered with foundations to provide free genomic testing for underserved cancer patients.
Conclusion
Addressing disparities in access to precision medicine requires a multifaceted approach that combines inclusive research practices, cost reduction strategies, infrastructure development, education, and supportive policies. By implementing these best practices, healthcare systems can move towards equitable genomic healthcare, ensuring that the benefits of precision medicine reach all populations regardless of background or location.
7.4 Case Study: Patient-Centric Genomic Data Portals Enhancing Engagement
Patient-centric genomic data portals represent a transformative approach in precision medicine, empowering patients by providing direct access to their genomic information, educational resources, and communication tools with healthcare providers. These portals not only enhance patient engagement but also improve health outcomes by fostering informed decision-making and personalized care.
Key Features of Patient-Centric Genomic Data Portals
- Secure Access to Genomic Data: Patients can view their raw and interpreted genomic data.
- Educational Resources: Simplified explanations of genomic variants, implications, and treatment options.
- Interactive Tools: Risk calculators, family history input, and phenotype-genotype correlation tools.
- Communication Channels: Direct messaging with genetic counselors and clinicians.
- Data Sharing Controls: Patients manage consent and sharing preferences with researchers or family.
Mind Map: Components of a Patient-Centric Genomic Data Portal
Example 1: The My46 Genomic Portal
Overview: My46 is a web-based platform developed to give patients control over their genomic test results and preferences.
Best Practices Demonstrated:
- User-Friendly Interface: Simplifies complex genomic data into understandable formats.
- Consent Management: Allows patients to decide which results they want to receive.
- Educational Support: Provides context and implications for each genomic finding.
Impact: Patients reported increased satisfaction and empowerment in managing their health.
Example 2: The NIH All of Us Research Program Portal
Overview: This portal offers participants access to their genomic data alongside health records and survey data.
Best Practices Demonstrated:
- Integrated Data Views: Combines genomic, clinical, and lifestyle data for holistic insights.
- Community Engagement: Features forums and educational webinars.
- Privacy Controls: Robust settings for data sharing with researchers.
Impact: Enhanced participant engagement and trust, leading to higher retention rates.
Mind Map: Benefits of Patient-Centric Genomic Portals
Implementation Best Practices
- Co-Design with Patients: Involve patients in portal design to ensure usability and relevance.
- Clear, Non-Technical Language: Use layman terms and visual aids to explain genomic concepts.
- Mobile Accessibility: Ensure portals are optimized for smartphones and tablets.
- Regular Updates: Keep educational content and data interpretations current with scientific advances.
- Robust Security Measures: Implement multi-factor authentication and encryption.
Summary
Patient-centric genomic data portals are pivotal in bridging the gap between complex genomic information and patient understanding. By integrating secure data access, educational tools, and communication features, these portals foster active patient participation in healthcare. The examples of My46 and the NIH All of Us portal illustrate how best practices can be applied to create effective platforms that enhance engagement, trust, and ultimately, health outcomes.
7.5 Ethical Challenges in Gene Editing and Future Directions
Gene editing technologies, particularly CRISPR-Cas9, have revolutionized the potential for treating genetic disorders and advancing precision medicine. However, these powerful tools also raise profound ethical questions that must be carefully considered to ensure responsible innovation and equitable healthcare.
Key Ethical Challenges in Gene Editing
Safety and Unintended Consequences
Gene editing can cause off-target mutations that may lead to unintended health risks. For example, a clinical trial aiming to edit the CCR5 gene to confer HIV resistance raised concerns after unexpected immune responses were observed in animal models.
Best Practice Example: Rigorous preclinical testing combined with advanced bioinformatics tools to predict and minimize off-target effects. The use of high-fidelity Cas9 variants has improved editing precision.
Germline Editing vs Somatic Editing
Editing somatic cells affects only the treated individual, whereas germline editing alters DNA in eggs, sperm, or embryos, passing changes to future generations. This raises ethical concerns about consent and long-term consequences.
Example: The controversial case of the Chinese scientist who edited embryos to create gene-edited babies sparked global debate and led to calls for moratoriums on germline editing.
Equity and Access
Gene editing therapies are often expensive and available only in advanced healthcare settings, risking exacerbation of existing health disparities.
Example: Sickle cell disease gene therapies show promise but are currently accessible primarily in high-income countries.
Best Practice: Developing scalable, cost-effective delivery methods and policies to ensure equitable access.
Consent and Autonomy
Obtaining informed consent is complex, especially when editing embryos or germline cells where the future individual cannot consent.
Example: Ethical frameworks recommend extensive counseling and transparent communication with patients and families.
Dual Use and Misuse
Gene editing could be misused for non-therapeutic enhancements or bioweapons.
Best Practice: International collaborations to establish guidelines and surveillance mechanisms.
Regulatory and Governance Issues
There is no unified global regulatory framework for gene editing, leading to inconsistent policies.
Example: The International Summit on Human Genome Editing promotes dialogue among scientists, ethicists, and policymakers.
Future Directions
Example Mind Map: Ethical Challenges and Future Directions
Gene Editing Ethics Mind Map
Conclusion
Ethical challenges in gene editing are complex and multifaceted, requiring ongoing dialogue among scientists, ethicists, policymakers, and the public. By adopting best practices such as rigorous safety testing, transparent consent processes, equitable access policies, and international cooperation, the promise of gene editing can be realized responsibly. Future innovation must be guided by ethical frameworks that balance scientific progress with societal values.
Additional Resources and Examples
- The Nuffield Council on Bioethics Report (2018): Provides comprehensive ethical analysis on genome editing.
- Case Study: The use of CRISPR to treat Leber congenital amaurosis (a genetic eye disorder) in clinical trials highlights the balance between innovation and patient safety.
- Public Engagement Example: The “Your DNA, Your Say” global survey initiative gathers public opinions on genomic data and editing.
8. Emerging Trends and Future Directions
8.1 Integration of Multi-Omics Data for Holistic Patient Profiles
The integration of multi-omics data represents a transformative approach in precision medicine, enabling a comprehensive understanding of patient biology by combining diverse molecular layers. Multi-omics encompasses genomics, transcriptomics, proteomics, metabolomics, epigenomics, and more. By synthesizing these data types, clinicians and researchers can construct holistic patient profiles that reveal complex disease mechanisms, identify novel biomarkers, and tailor personalized therapeutic strategies.
What is Multi-Omics Integration?
Multi-omics integration refers to the process of combining and analyzing datasets from multiple omics disciplines to gain a systems-level insight into biological processes. Instead of analyzing each omics layer in isolation, integration allows for the discovery of interactions and regulatory mechanisms that drive health and disease.
Why Integrate Multi-Omics Data?
- Comprehensive Molecular Insight: Single-omics data may miss critical regulatory layers; integration captures the full biological context.
- Improved Biomarker Discovery: Multi-omics signatures are often more robust and predictive.
- Enhanced Patient Stratification: Enables identification of subgroups with distinct molecular profiles.
- Personalized Therapeutics: Supports the design of targeted interventions based on multi-layer molecular abnormalities.
Mind Map: Components of Multi-Omics Integration
Best Practice: Stepwise Approach to Multi-Omics Integration
-
Data Collection and Quality Control
- Collect high-quality datasets from each omics platform.
- Perform normalization and batch effect correction.
-
Data Preprocessing and Harmonization
- Map data to common identifiers (e.g., genes, proteins).
- Handle missing data appropriately.
-
Integration Strategy Selection
- Choose between early integration (concatenation), intermediate integration (feature extraction), or late integration (model ensemble).
-
Analytical Methods
- Use multivariate statistical models (e.g., PCA, PLS-DA).
- Apply machine learning algorithms (e.g., random forests, neural networks).
- Construct biological networks to identify key regulators.
-
Validation and Interpretation
- Validate findings in independent cohorts.
- Interpret biological relevance with pathway and functional enrichment analyses.
Example: Multi-Omics Integration in Breast Cancer Subtyping
Researchers integrated genomics, transcriptomics, and proteomics data from breast cancer patients to refine tumor subtypes beyond traditional classifications. By combining somatic mutation profiles, gene expression patterns, and protein abundance, they identified novel subgroups with distinct prognoses and therapeutic vulnerabilities.
- Outcome: Improved patient stratification led to more precise treatment recommendations.
- Practice Highlight: Use of network-based integration to reveal driver pathways.
Mind Map: Analytical Techniques for Multi-Omics Integration
Example: Integrative Multi-Omics in Rare Disease Diagnosis
A clinical team used whole genome sequencing (genomics), RNA sequencing (transcriptomics), and metabolite profiling (metabolomics) to diagnose a patient with an undiagnosed neurodevelopmental disorder. The combined data pinpointed a pathogenic variant affecting a metabolic pathway, which was not evident from genomics alone.
- Outcome: Enabled targeted treatment and genetic counseling.
- Practice Highlight: Integration helped overcome limitations of single-omics diagnostics.
Challenges and Solutions
| Challenge | Solution / Best Practice |
|---|---|
| Data heterogeneity | Standardize data formats and normalization |
| Missing or incomplete data | Imputation methods and robust statistical models |
| Computational complexity | Use scalable algorithms and cloud computing |
| Interpretation of complex results | Employ domain experts and pathway analysis tools |
Future Directions
- Integration of additional omics layers such as microbiomics and exposomics.
- Real-time multi-omics data collection via wearable biosensors.
- AI-driven automated integration and interpretation pipelines.
Summary
Integrating multi-omics data is a cornerstone of next-generation precision medicine, providing a holistic view of patient biology. By following best practices in data collection, preprocessing, and analysis, healthcare professionals can unlock deeper insights, improve diagnostics, and personalize treatments effectively.
8.2 Real-Time Genomic Monitoring and Wearable Technologies
Real-time genomic monitoring represents a transformative frontier in precision medicine, enabling continuous or near-continuous assessment of an individual’s genomic and related biomolecular data. Coupled with wearable technologies, this approach offers unprecedented opportunities for early disease detection, personalized treatment adjustments, and proactive health management.
What is Real-Time Genomic Monitoring?
Real-time genomic monitoring involves the dynamic tracking of genomic markers, gene expression profiles, or epigenetic changes as they occur or evolve in the body. Unlike traditional static genomic testing, which provides a snapshot, real-time monitoring captures temporal changes, facilitating timely clinical interventions.
Role of Wearable Technologies
Wearables equipped with biosensors can collect physiological and molecular data continuously. Recent advances have enabled integration of microfluidic devices, biosensors, and even nanopore sequencing components into wearable formats, making real-time genomic data acquisition feasible outside laboratory settings.
Mind Map: Components of Real-Time Genomic Monitoring with Wearables
Examples of Real-Time Genomic Monitoring and Wearables
Wearable Biosensors for Circulating Tumor DNA (ctDNA) Detection
Example: Researchers have developed wearable patches that collect sweat or interstitial fluid and detect ctDNA fragments indicative of tumor mutations. This enables oncologists to monitor tumor dynamics and treatment response in real-time without invasive biopsies.
Best Practice: Integrate wearable ctDNA sensors with cloud-based analytics platforms that provide alerts for mutation emergence or resistance markers, allowing timely therapy adjustments.
Real-Time Epigenetic Monitoring via Wearable Devices
Example: Epigenetic modifications such as DNA methylation can change rapidly in response to environmental factors or disease states. Wearable devices capable of sampling saliva or sweat and analyzing methylation patterns are under development to monitor stress responses or early disease signals.
Best Practice: Use multi-omics data integration combining epigenetic markers with physiological data (heart rate, cortisol levels) from wearables to improve predictive accuracy.
Portable Nanopore Sequencing Devices
Example: Oxford Nanopore Technologies has developed portable sequencers that can be integrated with wearable or handheld devices, enabling near real-time sequencing of nucleic acids in field or clinical settings.
Best Practice: Employ these devices for infectious disease monitoring, such as tracking viral mutations in pandemics, combined with wearable physiological sensors for comprehensive patient monitoring.
Mind Map: Clinical Applications of Real-Time Genomic Wearables
Challenges and Considerations
- Sensor Sensitivity: Detecting low-abundance nucleic acids in non-invasive samples like sweat or saliva requires highly sensitive biosensors.
- Data Privacy: Continuous genomic data collection raises significant privacy concerns; encryption and secure data handling protocols are essential.
- Battery Life & Wearability: Devices must balance power consumption with user comfort to ensure compliance.
- Regulatory Approval: Wearable genomic devices require rigorous validation and regulatory clearance before clinical use.
Future Outlook
The convergence of genomics, wearable biosensors, and AI-driven analytics promises a future where personalized health insights are delivered continuously and non-invasively. This will empower clinicians and patients alike to make informed decisions in real-time, improving outcomes and reducing healthcare costs.
Summary
Real-time genomic monitoring via wearable technologies is an emerging paradigm in precision medicine. By enabling continuous assessment of genomic and molecular markers, these innovations facilitate proactive, personalized healthcare. Successful implementation depends on advances in biosensor technology, data analytics, privacy safeguards, and clinical integration.
For healthcare strategists, bioinformatics specialists, and medical researchers, understanding and adopting these technologies will be critical to driving the next wave of genomic data-driven healthcare innovation.
8.3 Best Practice: Leveraging Blockchain for Genomic Data Security with Pilot Examples
Introduction
Genomic data is highly sensitive and valuable, making its security and privacy paramount in precision medicine. Traditional centralized databases are vulnerable to breaches, unauthorized access, and data tampering. Blockchain technology offers a decentralized, immutable, and transparent framework that can revolutionize genomic data security.
Why Blockchain for Genomic Data Security?
- Decentralization: Eliminates single points of failure by distributing data across multiple nodes.
- Immutability: Once data is recorded, it cannot be altered or deleted, ensuring data integrity.
- Transparency & Auditability: Every transaction is recorded and traceable, enabling accountability.
- Smart Contracts: Automate data access permissions and consent management.
- Enhanced Privacy: Cryptographic techniques protect sensitive information.
Mind Map: Blockchain Benefits for Genomic Data Security
Best Practices for Implementing Blockchain in Genomic Data Security
-
Hybrid Storage Model:
- Store genomic data off-chain in secure databases or cloud storage.
- Record cryptographic hashes of the data on-chain to ensure integrity.
- Example: The DNA sequence is stored securely off-chain; its hash is stored on the blockchain to verify authenticity.
-
Use of Smart Contracts for Consent Management:
- Automate patient consent, granting or revoking access dynamically.
- Ensure transparency in who accesses data and for what purpose.
- Example: A smart contract automatically logs and enforces patient consent for research use.
-
Role-Based Access Control (RBAC):
- Define roles (e.g., researcher, clinician, patient) with specific permissions.
- Smart contracts enforce these roles to prevent unauthorized access.
-
Data Encryption and Privacy-Preserving Techniques:
- Encrypt genomic data before storage.
- Use zero-knowledge proofs or homomorphic encryption to allow computations without revealing raw data.
-
Interoperability and Standards Compliance:
- Align blockchain solutions with healthcare data standards (e.g., HL7 FHIR).
- Facilitate integration with existing healthcare IT systems.
Mind Map: Best Practices for Blockchain Implementation
Pilot Examples of Blockchain in Genomic Data Security
-
Nebula Genomics
- Overview: A platform enabling individuals to own and control their genomic data.
- Blockchain Use: Uses blockchain to manage data access permissions and incentivize data sharing.
- Best Practice Highlight: Employs smart contracts for transparent consent management.
- Example: A user can grant a pharmaceutical company access to specific genomic segments for a defined period, with all transactions recorded on blockchain.
-
EncrypGen
- Overview: A marketplace for buying and selling genomic data securely.
- Blockchain Use: Records transactions and data provenance on blockchain.
- Best Practice Highlight: Hybrid storage with encrypted genomic data off-chain and hashes on-chain.
- Example: Researchers purchase access to anonymized genomic datasets with blockchain ensuring traceability and data integrity.
-
Gene-Chain Project
- Overview: A pilot project integrating blockchain with genomic databases in a hospital setting.
- Blockchain Use: Implements role-based access control and audit trails.
- Best Practice Highlight: Combines blockchain with existing EHR systems using HL7 FHIR standards.
- Example: Clinicians access patient genomic data only after blockchain-verified consent, ensuring compliance and security.
Mind Map: Pilot Projects Using Blockchain for Genomic Data
Challenges and Considerations
- Scalability: Blockchain networks can face performance bottlenecks; hybrid models help mitigate this.
- Data Privacy Regulations: Compliance with GDPR, HIPAA, and other regulations must be ensured.
- User Adoption: Educating patients and clinicians on blockchain benefits and usage.
- Cost: Infrastructure and maintenance costs need to be justified by security gains.
Conclusion
Leveraging blockchain technology for genomic data security offers a promising path to enhance trust, privacy, and control in precision medicine. By adopting best practices such as hybrid storage, smart contracts for consent, and role-based access control, healthcare organizations can safeguard sensitive genomic information while enabling innovative research and personalized care.
Pilot projects like Nebula Genomics, EncrypGen, and Gene-Chain demonstrate practical, real-world applications that can serve as blueprints for future implementations.
References & Further Reading
- “Blockchain for Genomic Data Sharing and Privacy,” Nature Genetics, 2020.
- Nebula Genomics Whitepaper: https://nebula.org/whitepaper
- EncrypGen Platform Overview: https://encrypgen.com
- Gene-Chain Project Report, 2022.
8.4 The Role of Artificial Intelligence in Next-Generation Precision Medicine
Artificial Intelligence (AI) is rapidly transforming precision medicine by enabling the analysis of vast and complex genomic datasets, integrating multi-omics information, and supporting clinical decision-making with unprecedented accuracy and speed. AI-driven approaches facilitate personalized treatment plans, early disease detection, and drug discovery, ultimately improving patient outcomes.
Mind Map: AI Applications in Precision Medicine
AI-Driven Genomic Data Analysis
AI algorithms, especially deep learning models, excel at interpreting complex genomic sequences. For example, convolutional neural networks (CNNs) can detect subtle patterns in DNA sequences to identify pathogenic variants that traditional methods might miss.
Example: DeepVariant, developed by Google, uses deep learning to improve the accuracy of variant calling from next-generation sequencing data, outperforming conventional pipelines.
Multi-Omics Data Integration
Precision medicine benefits from integrating diverse biological data types. AI models can combine genomics, transcriptomics, proteomics, and metabolomics data to create comprehensive patient profiles.
Example: The MOFA (Multi-Omics Factor Analysis) framework uses machine learning to identify shared and unique factors across omics layers, aiding in disease subtype classification and biomarker discovery.
Clinical Decision Support Systems (CDSS)
AI-powered CDSS analyze patient genomic and clinical data to stratify patients into risk categories and recommend personalized therapies.
Example: IBM Watson for Oncology integrates genomic data with clinical guidelines and literature to suggest tailored cancer treatment options, enhancing oncologists’ decision-making.
AI in Drug Discovery and Development
AI accelerates drug discovery by predicting drug-target interactions, repurposing existing drugs, and optimizing clinical trial designs.
Example: Atomwise uses deep learning to screen billions of compounds virtually, identifying promising drug candidates for diseases with genetic underpinnings.
Patient Monitoring and Real-Time Analytics
Wearable devices generate continuous health data streams. AI analyzes this data alongside genomic information to detect early signs of disease or adverse reactions.
Example: Cardiogram combines wearable heart rate data with AI to detect atrial fibrillation, which can be linked to genetic predispositions, enabling early intervention.
Ethical and Regulatory Considerations
AI models must be transparent, unbiased, and respect patient privacy to be trusted in clinical settings.
Best Practice: Implementing explainable AI (XAI) techniques ensures clinicians understand AI-driven recommendations, fostering adoption and compliance.
Summary
AI is a cornerstone of next-generation precision medicine, enhancing genomic data interpretation, enabling multi-omics integration, supporting clinical decisions, and accelerating drug development. By combining AI with genomic insights, healthcare can become more predictive, preventive, and personalized.
Additional Mind Map: AI Workflow in Precision Medicine
This comprehensive approach ensures AI models remain accurate, reliable, and clinically relevant over time.
8.5 Case Study: Precision Medicine in Pandemic Response and Infectious Disease Control
Introduction
Precision medicine, traditionally associated with oncology and rare genetic disorders, has increasingly demonstrated its critical role in infectious disease management and pandemic response. Leveraging genomic data allows for rapid pathogen identification, tracking mutations, tailoring treatments, and optimizing public health strategies. This case study explores how precision medicine principles were applied during recent pandemics, highlighting best practices and real-world examples.
Mind Map: Precision Medicine in Pandemic Response
Genomic Surveillance: Early Detection and Variant Tracking
During the COVID-19 pandemic, genomic sequencing of SARS-CoV-2 was pivotal for identifying variants of concern (VOCs) such as Alpha, Delta, and Omicron. Countries like the UK established the COVID-19 Genomics UK Consortium (COG-UK), sequencing tens of thousands of viral genomes weekly.
Best Practice: Rapid, large-scale sequencing combined with open data sharing accelerated variant detection and informed public health responses.
Example: The identification of the Alpha variant in late 2020 led to targeted lockdowns and vaccine strategy adjustments in the UK.
Diagnostic Innovations Enabled by Genomics
Precision medicine facilitated the development of highly sensitive and specific diagnostic tools.
-
CRISPR-based diagnostics: SHERLOCK and DETECTR platforms enabled rapid, point-of-care detection of viral RNA with minimal equipment.
-
Example: The FDA authorized a CRISPR-based COVID-19 test by Sherlock Biosciences, reducing turnaround time from days to under an hour.
Best Practice: Integrating genomic insights into diagnostic design improves sensitivity to emerging variants.
Therapeutic Personalization: Host and Pathogen Genomics
Understanding both viral mutations and host genetic factors enabled personalized treatment approaches.
-
Host genomics: Studies identified genetic variants influencing COVID-19 severity, such as those affecting immune response genes (e.g., IFN pathways).
-
Example: The use of monoclonal antibodies was tailored based on variant susceptibility, avoiding ineffective treatments against resistant strains.
Best Practice: Incorporate patient genomic data and pathogen sequencing to optimize antiviral therapy selection.
Vaccine Development and Population Genomics
Genomic data accelerated vaccine development and informed population-specific strategies.
-
mRNA vaccines: Pfizer-BioNTech and Moderna rapidly designed vaccines targeting the spike protein sequence derived from viral genomes.
-
Population genomics: Identifying HLA allele distributions helped predict vaccine responsiveness and adverse reactions.
Example: Adjusting booster formulations to cover emerging variants like Omicron improved vaccine efficacy.
Best Practice: Continuous genomic monitoring to update vaccine targets in real-time.
Public Health Integration: Data Sharing and Predictive Modeling
Effective pandemic control required integrating genomic data with epidemiological and clinical data.
-
Data platforms: GISAID provided an open-access repository for sharing viral genomes globally.
-
Contact tracing: Genomic data helped confirm transmission chains and outbreak sources.
-
Predictive modeling: Combining genomic and mobility data improved forecasting of outbreak hotspots.
Example: South Korea’s integration of genomic data with aggressive testing and tracing curbed COVID-19 spread efficiently.
Best Practice: Foster international collaboration and real-time data sharing to enhance response agility.
Mind Map: Key Examples and Best Practices
Conclusion
This case study underscores how precision medicine and genomic data have transformed pandemic response and infectious disease control. By integrating pathogen and host genomics with innovative diagnostics, therapeutics, vaccines, and public health strategies, healthcare systems can respond faster and more effectively to emerging infectious threats.
Call to Action: Continued investment in genomic infrastructure, data sharing, and interdisciplinary collaboration is essential to harness the full potential of precision medicine in future pandemics.
9. Practical Implementation Strategies for Healthcare Organizations
9.1 Assessing Organizational Readiness for Genomic Medicine Adoption
Adopting genomic medicine within a healthcare organization is a transformative process that requires thorough assessment and strategic planning. Organizational readiness is critical to ensure successful integration of genomic technologies, workflows, and culture. This section explores key dimensions to evaluate readiness, supported by practical examples and mind maps to visualize the assessment framework.
Key Dimensions of Organizational Readiness
-
Leadership Commitment and Vision
- Is there executive sponsorship for genomic medicine initiatives?
- Are strategic goals aligned with precision medicine adoption?
-
Infrastructure and Technology
- Availability of genomic sequencing platforms or partnerships
- Robust IT systems for data storage, analysis, and integration
-
Workforce Capability and Training
- Presence of trained genetic counselors, bioinformaticians, and clinicians
- Ongoing education programs for staff on genomic medicine
-
Data Management and Governance
- Policies for genomic data privacy, security, and sharing
- Compliance with regulatory standards (e.g., HIPAA, GDPR)
-
Clinical Workflow Integration
- Processes to incorporate genomic testing into patient care pathways
- Decision support tools for interpreting genomic data
-
Financial and Economic Considerations
- Budget allocation for genomic technologies and personnel
- Reimbursement strategies and cost-effectiveness analysis
-
Patient Engagement and Ethical Frameworks
- Mechanisms for informed consent and patient education
- Addressing ethical concerns related to genomic data use
Mind Map: Organizational Readiness Assessment Framework
Example: Readiness Assessment at a Mid-Sized Academic Medical Center
Context: A 300-bed academic hospital aiming to implement precision oncology services.
-
Leadership: The Chief Medical Officer (CMO) champions the initiative, integrating it into the hospital’s 5-year strategic plan.
-
Infrastructure: The hospital partners with a commercial NGS provider and upgrades its electronic health record (EHR) to incorporate genomic data fields.
-
Workforce: Genetic counselors are hired; oncologists receive targeted training workshops.
-
Data Governance: A genomic data governance committee is established to oversee compliance and patient privacy.
-
Workflow: Clinical pathways are redesigned to include genomic testing for eligible cancer patients, supported by decision support alerts in the EHR.
-
Finance: Initial funding is secured through grants and pilot program budgets; reimbursement policies are negotiated with insurers.
-
Patient Engagement: Educational materials and consent forms are developed with patient advocacy groups.
Outcome: The center successfully launches its precision oncology program within 12 months, demonstrating improved patient stratification and treatment outcomes.
Mind Map: Example Readiness Assessment Breakdown
Practical Tips for Conducting a Readiness Assessment
- Use a Multidisciplinary Team: Include stakeholders from clinical, IT, legal, finance, and patient advocacy.
- Conduct Gap Analysis: Compare current capabilities against desired genomic medicine goals.
- Leverage Surveys and Interviews: Gather insights from frontline staff and leadership.
- Pilot Small: Start with focused genomic applications (e.g., pharmacogenomics) before scaling.
- Document and Communicate Findings: Create clear reports to guide decision-making.
By systematically assessing these dimensions, healthcare organizations can identify strengths, gaps, and actionable steps to prepare for successful genomic medicine adoption, ultimately improving patient outcomes and operational efficiency.
9.2 Building Multidisciplinary Teams: Roles and Collaboration Models
Precision medicine and genomic data-driven healthcare innovation demand the collaboration of diverse experts. Building effective multidisciplinary teams (MDTs) is critical to harnessing the full potential of genomic insights for patient care and research.
Key Roles in Multidisciplinary Teams
- Medical Researchers: Design and conduct studies to discover genomic markers and validate clinical relevance.
- Bioinformatics Specialists: Analyze genomic data, develop pipelines, and interpret complex datasets.
- Healthcare Strategists: Align genomic initiatives with organizational goals, manage resources, and oversee implementation.
- Clinicians (Oncologists, Geneticists, Pharmacologists, etc.): Apply genomic findings to patient diagnosis, treatment, and monitoring.
- Data Scientists: Build predictive models, integrate multi-omics data, and support decision-making.
- Ethicists and Legal Experts: Ensure compliance with ethical standards, patient consent, and data privacy laws.
- Patient Advocates: Represent patient interests, improve communication, and enhance engagement.
- IT Specialists: Manage infrastructure, data security, and interoperability.
Collaboration Models
-
Centralized Model: All experts operate within a single organizational unit, facilitating rapid communication and decision-making.
-
Distributed Model: Team members are spread across departments or institutions but collaborate through digital platforms.
-
Hybrid Model: Combines centralized leadership with distributed execution, balancing flexibility and control.
Mind Map: Roles and Collaboration in Multidisciplinary Teams
Best Practice Example: Collaborative Genomic Tumor Board
A leading cancer center implemented a Genomic Tumor Board (GTB) comprising oncologists, molecular pathologists, bioinformaticians, and genetic counselors. The GTB meets weekly to review patients’ genomic profiles and recommend personalized treatment plans.
-
Process:
- Bioinformatics team processes sequencing data and generates reports.
- Clinicians present patient history and clinical context.
- Researchers provide insights on emerging biomarkers.
- Ethicists ensure patient consent and data use compliance.
-
Outcome: Improved treatment precision, increased enrollment in targeted clinical trials, and enhanced patient outcomes.
Mind Map: Example Workflow of a Genomic Tumor Board
Example: Cross-Functional Team in Rare Disease Diagnosis
A hospital formed a multidisciplinary team to tackle rare genetic diseases, including clinical geneticists, bioinformaticians, neurologists, and social workers.
-
Collaboration:
- Bioinformaticians analyze whole-exome sequencing data.
- Clinicians correlate genomic variants with phenotypes.
- Social workers support families through counseling and resources.
-
Impact: Reduced diagnostic odyssey time, improved patient support, and tailored treatment approaches.
Tips for Effective MDT Collaboration
- Establish clear communication channels (e.g., regular meetings, shared digital platforms).
- Define roles and responsibilities explicitly to avoid overlap.
- Foster a culture of mutual respect and continuous learning.
- Use collaborative tools like electronic health records (EHRs) integrated with genomic data.
- Encourage patient involvement through advocates and transparent communication.
Building multidisciplinary teams with clearly defined roles and effective collaboration models is foundational to advancing precision medicine. By leveraging diverse expertise and fostering seamless communication, healthcare organizations can accelerate innovation and improve patient outcomes.
9.3 Best Practice: Stepwise Implementation Roadmap with Real-World Examples
Implementing precision medicine and genomic data-driven healthcare innovation requires a structured, stepwise approach to ensure successful integration, adoption, and sustainability. Below is a detailed roadmap outlining key phases, accompanied by mind maps and real-world examples to illustrate best practices.
Step 1: Assess Organizational Readiness
- Evaluate existing infrastructure, workforce expertise, and data capabilities.
- Identify gaps in technology, personnel, and workflows.
- Engage leadership and secure executive sponsorship.
Example: The Mayo Clinic conducted a comprehensive readiness assessment before launching its Center for Individualized Medicine, identifying key technology upgrades and training needs.
Step 2: Build a Multidisciplinary Team
- Assemble clinicians, bioinformaticians, genetic counselors, IT specialists, and data scientists.
- Define roles, responsibilities, and communication channels.
- Foster a culture of collaboration and continuous learning.
Example: At Stanford Medicine, the Genomic Medicine team includes experts from diverse fields working together to interpret genomic data and translate findings into clinical care.
Step 3: Develop Data Infrastructure and Integration
- Implement scalable genomic data storage solutions.
- Ensure interoperability between genomic databases and electronic health records (EHR).
- Adopt standards such as HL7 FHIR Genomics for data exchange.
Example: The UK’s 100,000 Genomes Project utilized a cloud-based platform integrating genomic data with patient records, enabling researchers and clinicians to access comprehensive datasets securely.
Step 4: Pilot Implementation and Workflow Integration
- Select a pilot clinical area (e.g., oncology, rare diseases).
- Develop protocols for genomic testing, data interpretation, and clinical decision support.
- Train clinical staff on new workflows.
- Collect feedback and monitor key performance indicators (KPIs).
Example: Geisinger Health System piloted pharmacogenomic testing in cardiovascular patients, integrating results into EHR alerts to guide medication choices, resulting in improved patient outcomes.
Step 5: Scale and Optimize
- Expand genomic services to additional clinical areas.
- Refine data analytics and decision support tools based on pilot learnings.
- Establish continuous education programs.
- Develop policies for data governance and patient engagement.
Example: The Mount Sinai Health System scaled their genomic medicine program from oncology to cardiology and neurology, incorporating AI-driven analytics to improve diagnostic accuracy.
Step 6: Measure Impact and Continuous Improvement
- Track clinical outcomes, cost-effectiveness, and patient satisfaction.
- Use data to refine protocols and workflows.
- Publish findings to contribute to the broader scientific community.
Example: The Personalized Medicine Program at Vanderbilt University Medical Center continuously evaluates patient outcomes and cost savings, publishing results that inform national guidelines.
Summary Mind Map: Stepwise Implementation Roadmap
Final Notes
- Flexibility: Adapt the roadmap to your organization’s unique context.
- Stakeholder Engagement: Involve patients, clinicians, and IT early and often.
- Technology Adoption: Prioritize scalable, interoperable solutions.
- Education: Continuous training is critical for sustained success.
By following this structured roadmap, healthcare organizations can effectively implement precision medicine initiatives that leverage genomic data to improve patient outcomes and drive healthcare innovation.
9.4 Measuring Outcomes and Continuous Improvement in Genomic Healthcare
Measuring outcomes and fostering continuous improvement are critical components in the successful integration of genomic healthcare within medical institutions. This process ensures that genomic initiatives deliver tangible benefits to patients, optimize clinical workflows, and adapt to emerging scientific insights.
Key Metrics for Measuring Outcomes in Genomic Healthcare
To effectively measure outcomes, healthcare organizations should focus on a combination of clinical, operational, and patient-centered metrics:
- Clinical Outcomes: Diagnostic accuracy, treatment efficacy, reduction in adverse drug reactions, survival rates, and disease progression.
- Operational Metrics: Turnaround time for genomic testing, data integration efficiency, clinician adoption rates, and cost-effectiveness.
- Patient-Centered Outcomes: Patient satisfaction, engagement levels, understanding of genomic information, and quality of life improvements.
Mind Map: Outcome Measurement Framework
Best Practice Example: Implementing a Genomic Outcome Dashboard
A leading academic medical center developed a real-time genomic outcome dashboard that integrates data from electronic health records (EHR), genomic laboratories, and patient-reported outcomes. This dashboard tracks key performance indicators (KPIs) such as:
- Percentage of patients receiving genomically guided therapies
- Average time from sample collection to genomic report delivery
- Rates of adverse drug reactions prevented through pharmacogenomic testing
- Patient comprehension scores based on post-consultation surveys
By visualizing these metrics, the center identifies bottlenecks, monitors clinical impact, and prioritizes areas for staff training and process refinement.
Continuous Improvement Cycle in Genomic Healthcare
Continuous improvement relies on iterative cycles of data collection, analysis, and action. The Plan-Do-Study-Act (PDSA) model is widely used:
- Plan: Identify areas needing improvement, such as reducing genomic test turnaround times.
- Do: Implement targeted interventions, e.g., automating sample tracking.
- Study: Analyze outcome data to assess impact.
- Act: Standardize successful changes or revise strategies.
Mind Map: Continuous Improvement Cycle
Example: Reducing Genomic Test Turnaround Time
A hospital noticed delays in delivering genomic test results impacting treatment decisions. Applying the PDSA cycle:
- Plan: Target a 20% reduction in turnaround time within 6 months.
- Do: Introduced barcode scanning for sample tracking and streamlined lab workflows.
- Study: Monitored turnaround times weekly; observed a 25% reduction.
- Act: Adopted new workflow as standard practice and expanded barcode use to other departments.
This improvement enhanced clinician confidence and patient satisfaction.
Leveraging Patient Feedback for Improvement
Patient-reported outcomes and feedback provide valuable insights into the effectiveness of genomic healthcare delivery. For example, surveys assessing patient understanding of genomic results can highlight communication gaps.
Example: A bioinformatics team collaborated with genetic counselors to develop simplified genomic report summaries. Post-implementation surveys showed a 40% increase in patient comprehension scores, guiding further refinements.
Mind Map: Integrating Patient Feedback
Summary
Measuring outcomes and driving continuous improvement in genomic healthcare requires a structured approach combining quantitative metrics, patient perspectives, and iterative process enhancements. By adopting best practices such as outcome dashboards, PDSA cycles, and patient feedback integration, healthcare organizations can maximize the clinical and operational benefits of precision medicine initiatives.
9.5 Case Example: Successful Genomic Medicine Programs in Academic Medical Centers
Academic medical centers (AMCs) have become pivotal hubs for advancing genomic medicine due to their unique integration of research, clinical care, and education. This section explores successful genomic medicine programs within AMCs, highlighting best practices, implementation strategies, and tangible outcomes.
Overview of Successful Genomic Medicine Programs
- Integration of Research and Clinical Care: AMCs leverage cutting-edge genomic research to directly inform patient care.
- Multidisciplinary Collaboration: Teams composed of geneticists, bioinformaticians, clinicians, and ethicists work cohesively.
- Patient-Centered Approaches: Programs emphasize informed consent, education, and personalized treatment plans.
Case Study 1: The Broad Institute and Massachusetts General Hospital Partnership
-
Program Highlights:
- Utilizes whole genome sequencing (WGS) for cancer patients.
- Implements rapid genomic data analysis pipelines to guide targeted therapies.
- Incorporates AI-driven variant interpretation tools.
-
Best Practice: Seamless integration of genomic data into electronic health records (EHR) for real-time clinical decision-making.
-
Example: A patient with metastatic lung cancer received a targeted therapy based on an EGFR mutation identified through WGS, leading to significant tumor regression.
Case Study 2: Stanford Center for Genomics and Personalized Medicine
-
Program Highlights:
- Focus on pharmacogenomics to optimize drug prescriptions.
- Development of clinical decision support systems (CDSS) to alert clinicians about gene-drug interactions.
-
Best Practice: Embedding pharmacogenomic alerts within the EHR to reduce adverse drug reactions.
-
Example: A patient with a CYP2C19 variant was prescribed an alternative antiplatelet drug, preventing potential treatment failure.
Mind Map: Key Components of Successful Genomic Medicine Programs in AMCs
Best Practices Derived from AMC Programs
-
Multidisciplinary Collaboration: Establish teams that include clinicians, genetic counselors, bioinformaticians, and IT specialists to ensure comprehensive care.
-
Robust Data Infrastructure: Develop secure, interoperable platforms that integrate genomic data with clinical records.
-
Clinical Decision Support Systems: Implement real-time alerts and guidance tools within EHRs to assist clinicians in interpreting genomic data.
-
Patient-Centric Communication: Prioritize clear communication strategies to explain genomic findings and implications to patients.
-
Continuous Training and Education: Provide ongoing education for healthcare providers to stay current with genomic advances.
Example Workflow: Implementing a Genomic Medicine Program at an AMC
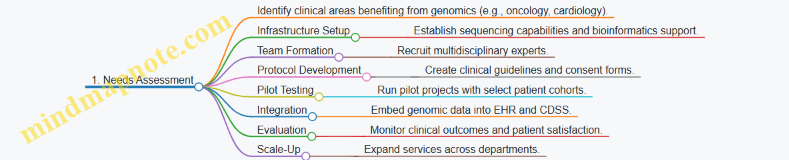
Additional Example: University of California, San Francisco (UCSF) Genomic Medicine Initiative
- Focus: Rare disease diagnosis and precision oncology.
- Innovation: Use of rapid exome sequencing in neonatal intensive care units (NICU) to accelerate diagnosis.
- Outcome: Reduced diagnostic odyssey time from months to days, enabling timely interventions.
Summary
Successful genomic medicine programs at academic medical centers exemplify the power of integrating advanced genomic technologies with clinical expertise and patient-centered care. By adopting best practices such as multidisciplinary collaboration, robust data management, and effective communication, AMCs are transforming healthcare delivery and setting benchmarks for precision medicine worldwide.
10. Conclusion and Call to Action
10.1 Summary of Key Insights and Best Practices
Precision medicine and genomic data-driven healthcare innovation represent a transformative shift in how diseases are understood, diagnosed, and treated. This section synthesizes the core insights and best practices discussed throughout the blog, providing a clear roadmap for researchers, bioinformatics specialists, and healthcare strategists.
Key Insights
- Integration of Genomic Data into Clinical Practice: Leveraging genomic information enables personalized treatment plans, improving patient outcomes.
- Technological Advancements: Tools like Next-Generation Sequencing (NGS) and CRISPR have revolutionized data generation and therapeutic possibilities.
- Data Management and Interoperability: Robust, secure, and interoperable data systems are essential for effective genomic healthcare.
- Computational Approaches: Machine learning and AI enhance variant interpretation, patient stratification, and drug discovery.
- Clinical Applications: Precision medicine is especially impactful in oncology, pharmacogenomics, and rare disease diagnosis.
- Policy and Infrastructure: Supportive healthcare policies and infrastructure foster adoption and scalability.
- Patient Engagement and Ethics: Transparent communication and ethical frameworks ensure patient trust and equitable access.
- Emerging Trends: Multi-omics integration, real-time monitoring, and blockchain are shaping the future landscape.
Best Practices with Examples
-
Clinical Integration of Genomic Data
- Practice: Incorporate genomic testing early in diagnostic workflows.
- Example: In oncology, using tumor genomic profiling to select targeted therapies, such as EGFR inhibitors for lung cancer patients with specific mutations.
-
Data Quality Assurance
- Practice: Implement rigorous validation pipelines for sequencing data.
- Example: Using control samples and replicate sequencing runs to ensure variant calling accuracy.
-
FAIR Data Principles (Findable, Accessible, Interoperable, Reusable)
- Practice: Adopt standardized metadata schemas and open data repositories.
- Example: The use of GA4GH (Global Alliance for Genomics and Health) standards to share genomic datasets across institutions.
-
Machine Learning for Patient Stratification
- Practice: Develop predictive models that integrate genomic and clinical data.
- Example: AI algorithms identifying high-risk cardiovascular patients based on polygenic risk scores and lifestyle factors.
-
Ethical Patient Communication
- Practice: Use clear, jargon-free language and provide genetic counseling.
- Example: Patient portals that explain genomic test results with visual aids and access to genetic counselors.
-
Policy Frameworks Encouraging Data Sharing
- Practice: Establish international collaborations with clear data governance.
- Example: The UK Biobank enabling researchers worldwide to access genomic and health data under strict privacy controls.
-
Stepwise Implementation Roadmap
- Practice: Begin with pilot programs, evaluate outcomes, then scale.
- Example: Academic medical centers initiating precision oncology clinics before expanding to other specialties.
Mind Maps
Mind Map 1: Core Components of Precision Medicine
Mind Map 2: Best Practices Framework
Mind Map 3: Future Directions
Final Reflection
The journey toward fully realizing precision medicine’s potential is ongoing. By embracing these key insights and embedding best practices into research, clinical workflows, and healthcare strategies, stakeholders can drive meaningful innovation that improves patient care and public health globally.
10.2 Overcoming Barriers to Widespread Adoption
Precision medicine and genomic data-driven healthcare innovation hold immense promise, but their widespread adoption faces several barriers. Addressing these challenges requires a multifaceted approach involving technology, policy, education, and patient engagement. Below, we explore key barriers and actionable strategies to overcome them, supported by illustrative examples and mind maps.
Key Barriers to Adoption
Technological Challenges
Barrier: Fragmented data systems and lack of interoperability hinder seamless integration of genomic data into clinical workflows.
Best Practice: Adopt standardized data formats (e.g., HL7 FHIR Genomics) and invest in scalable cloud-based platforms.
Example: The NIH’s All of Us Research Program uses a cloud-based data ecosystem that integrates genomic and clinical data, enabling researchers and clinicians to access harmonized datasets efficiently.
Cost and Economic Barriers
Barrier: High costs of genomic sequencing and infrastructure limit accessibility, especially in resource-constrained settings.
Best Practice: Implement cost-sharing models and leverage economies of scale through centralized genomic testing labs.
Example: The UK’s 100,000 Genomes Project centralized sequencing efforts, reducing per-sample costs and accelerating turnaround times.
Education and Training
Barrier: Many healthcare professionals lack sufficient genomic literacy to interpret and apply genomic data effectively.
Best Practice: Integrate genomics into medical curricula and offer continuous professional development programs.
Example: The Global Genomics Nursing Alliance (G2NA) provides resources and training modules to empower nurses worldwide in genomic healthcare.
Ethical, Privacy, and Regulatory Concerns
Barrier: Concerns about data privacy, consent, and regulatory uncertainty slow adoption.
Best Practice: Implement robust data governance frameworks and transparent consent processes.
Example: The European General Data Protection Regulation (GDPR) sets strict guidelines for genomic data privacy, promoting trust and compliance.
Cultural and Social Barriers
Barrier: Distrust in genomic medicine and unequal access exacerbate health disparities.
Best Practice: Engage communities through culturally sensitive outreach and ensure equitable access.
Example: The All of Us Research Program prioritizes recruitment from underrepresented populations to build trust and improve health equity.
Summary Table of Barriers and Solutions
| Barrier Category | Specific Challenge | Best Practice Example |
|---|---|---|
| Technology | Data fragmentation | NIH All of Us cloud platform |
| Cost | High sequencing costs | UK 100,000 Genomes Project centralized labs |
| Education | Genomic literacy gap | Global Genomics Nursing Alliance training |
| Ethical & Privacy | Data privacy and consent | GDPR and dynamic consent models |
| Cultural & Social | Distrust and disparities | All of Us community engagement initiatives |
Final Thoughts
Overcoming barriers to the widespread adoption of precision medicine requires coordinated efforts across technology, policy, education, and community engagement. By learning from successful initiatives and implementing best practices, healthcare systems can unlock the full potential of genomic data to transform patient care.
10.3 Future Opportunities for Innovation and Collaboration
The future of precision medicine and genomic data-driven healthcare is rich with opportunities for innovation and collaboration that promise to transform patient care, accelerate research, and optimize healthcare delivery. This section explores key avenues where advancements are anticipated, supported by illustrative examples and mind maps to visualize complex interconnections.
Integration of Multi-Disciplinary Data Streams
Combining genomic data with other biological, environmental, and lifestyle data (multi-omics, exposomics, clinical data) will enable more comprehensive patient profiles.
Example: The NIH’s All of Us Research Program integrates genomic data with electronic health records (EHRs), wearable devices, and environmental data to create a diverse, large-scale dataset for precision medicine research.
AI and Machine Learning-Driven Insights
Artificial intelligence (AI) and machine learning (ML) will increasingly analyze vast genomic datasets to uncover novel biomarkers, predict disease risk, and tailor therapies.
Example: DeepVariant, a Google AI tool, improves the accuracy of variant calling from sequencing data, enabling more reliable genomic interpretations.
Collaborative Data Sharing Ecosystems
Future innovation depends on secure, interoperable platforms that facilitate data sharing across institutions, countries, and disciplines while respecting privacy.
Example: The Global Alliance for Genomics and Health (GA4GH) develops frameworks and tools to enable responsible genomic data sharing worldwide.
Personalized Therapeutics and Gene Editing
Advances in gene editing (e.g., CRISPR) and personalized drug development will enable precise correction of genetic defects and tailored treatments.
Example: The FDA-approved CAR-T cell therapies for certain leukemias demonstrate how genomic insights translate into personalized immunotherapies.
Patient-Centric Digital Health Platforms
Empowering patients with access to their genomic data and integrating it with digital health tools will enhance engagement and self-management.
Example: Platforms like 23andMe provide consumers with genetic reports and health insights, fostering awareness and proactive health management.
Global and Cross-Sector Partnerships
Collaborations between academia, industry, healthcare providers, and governments will accelerate innovation and broaden the impact of precision medicine.
Example: The UK Biobank partnership involves government funding, academic research, and industry collaboration to create one of the largest genomic and health datasets globally.
Summary
The future landscape of precision medicine is shaped by the convergence of advanced technologies, collaborative ecosystems, and patient empowerment. By embracing these opportunities, stakeholders can drive innovations that deliver more effective, equitable, and personalized healthcare.
This section encourages medical researchers, bioinformatics specialists, and healthcare strategists to actively participate in these emerging trends and foster cross-disciplinary collaborations to unlock the full potential of genomic data-driven healthcare innovation.
10.4 Encouraging Stakeholder Engagement: Researchers, Clinicians, and Patients
Engaging all stakeholders—researchers, clinicians, and patients—is pivotal for the successful implementation and advancement of precision medicine and genomic data-driven healthcare innovation. Meaningful collaboration ensures that genomic insights translate effectively into clinical practice, while also addressing patient needs and ethical considerations.
Mind Map: Stakeholder Engagement in Precision Medicine
Researchers: Driving Innovation and Data Interpretation
Researchers are the backbone of genomic medicine innovation. Their engagement involves generating high-quality genomic data, developing analytical tools, and translating findings into actionable clinical insights.
Best Practices:
- Collaborative Research Networks: Establish consortia that include clinicians and patient representatives to align research goals with clinical needs.
- Transparent Data Sharing: Use platforms like GA4GH (Global Alliance for Genomics and Health) to share datasets responsibly.
Example: The All of Us Research Program actively involves researchers collaborating with healthcare providers and patients to create a diverse genomic database that informs precision medicine.
Clinicians: Bridging Genomics and Patient Care
Clinicians are essential for interpreting genomic data in the context of patient care and communicating results effectively.
Best Practices:
- Genomic Education Programs: Continuous training on genomic literacy and interpretation (e.g., workshops, CME courses).
- Clinical Decision Support Tools: Integration of genomic data into Electronic Health Records (EHR) with alerts and recommendations.
Example: At Mayo Clinic, clinicians use integrated genomic reports within the EHR to guide targeted cancer therapies, supported by multidisciplinary tumor boards.
Patients: Empowering Through Knowledge and Participation
Patient engagement ensures that individuals understand genomic testing, consent appropriately, and participate actively in their healthcare journey.
Best Practices:
- Patient-Centric Portals: Platforms like MyGeneRank allow patients to access their genomic data with easy-to-understand explanations.
- Educational Outreach: Use multimedia resources (videos, brochures) tailored to diverse literacy levels.
Example: The Genomics England 100,000 Genomes Project includes patient advisory panels that influence project design and communication strategies.
Mind Map: Patient Engagement Strategies
Cross-Stakeholder Collaboration: Creating Synergy
Integrated efforts among researchers, clinicians, and patients foster innovation and trust.
Best Practices:
- Multidisciplinary Teams: Regular meetings involving all stakeholders to discuss cases and research findings.
- Shared Platforms: Use of collaborative tools like cBioPortal or ClinGen for data sharing and interpretation.
- Ethics and Policy Forums: Inclusion of patient voices in ethical discussions and policy formulation.
Example: The Clinical Genome Resource (ClinGen) initiative brings together researchers, clinicians, and patients to curate clinically relevant genomic variants.
Summary
Encouraging stakeholder engagement requires structured communication, education, and collaborative frameworks. By empowering researchers, clinicians, and patients with the right tools and opportunities, precision medicine can achieve its full potential in transforming healthcare.
For further reading, consider exploring:
- The role of patient advocacy groups in genomic medicine
- Case studies on multidisciplinary genomic tumor boards
- Platforms enabling secure genomic data sharing
10.5 Final Case Reflection: Transformative Impact of Genomic Data Driven Healthcare
As we conclude this exploration of precision medicine and genomic data-driven healthcare innovation, it is essential to reflect on a transformative case that encapsulates the profound impact of integrating genomic data into clinical practice. This reflection highlights how genomic insights can revolutionize patient outcomes, healthcare workflows, and research paradigms.
Case Overview: The Genomic-Driven Treatment of Acute Myeloid Leukemia (AML)
Acute Myeloid Leukemia (AML) is a heterogeneous blood cancer with historically poor prognosis and limited treatment options. Traditional chemotherapy often leads to variable outcomes due to the disease’s genetic complexity. The integration of genomic data has transformed AML management by enabling personalized therapeutic strategies.
Mind Map: Genomic Data Impact on AML Treatment
Detailed Reflection
1. Patient Stratification Through Genomic Profiling
By sequencing the genomes of AML patients, clinicians can identify specific mutations such as FLT3, NPM1, and IDH1/2. This stratification enables categorizing patients into risk groups, which guides treatment intensity and choice.
Example: A patient with a FLT3 mutation may receive a FLT3 inhibitor combined with chemotherapy, improving survival compared to chemotherapy alone.
2. Targeted Therapeutic Interventions
Genomic data has facilitated the development and approval of targeted drugs that specifically inhibit mutated proteins driving AML progression.
Example: Midostaurin, a FLT3 inhibitor, was approved after demonstrating improved outcomes in FLT3-mutated AML patients.
3. Treatment Monitoring Using Genomic Biomarkers
Genomic techniques allow detection of minimal residual disease (MRD) at a molecular level, enabling early intervention if relapse is detected.
Example: Quantitative PCR assays targeting NPM1 mutations monitor MRD, guiding decisions on stem cell transplantation.
4. Outcome Improvements and Reduced Toxicity
Precision medicine reduces exposure to ineffective treatments, minimizing adverse effects and improving quality of life.
Example: Patients without high-risk mutations avoid aggressive therapies, reducing hospitalization and side effects.
5. Accelerated Research and Clinical Trials
Genomic insights have reshaped clinical trial designs, focusing on molecularly defined patient cohorts, thus increasing trial efficiency and success rates.
Example: Basket trials enrolling patients based on mutation status rather than cancer type.
Mind Map: Broader Transformative Impacts of Genomic Data Driven Healthcare
Final Thoughts
The AML case exemplifies how genomic data-driven healthcare is not just a theoretical concept but a practical, life-saving approach that is reshaping medicine. By harnessing genomic information, healthcare providers can deliver more precise, effective, and compassionate care. This transformation extends beyond oncology, influencing diverse medical fields and promising a future where medicine is truly personalized.
As medical researchers, bioinformatics specialists, and healthcare strategists, embracing these innovations and best practices will be pivotal in driving forward the next generation of healthcare solutions.