Advanced System Design Patterns for High Availability and Scalable Applications
1. Introduction to High Availability and Scalability
1.1 Defining High Availability and Scalability in Modern Systems
Introduction
In the realm of modern software systems, High Availability (HA) and Scalability are two foundational pillars that ensure applications remain reliable, performant, and capable of handling growth. Understanding these concepts deeply is crucial for senior software engineers and technical leads tasked with architecting resilient and scalable solutions.
What is High Availability?
High Availability refers to a system’s ability to remain operational and accessible for a very high percentage of time, minimizing downtime and service interruptions.
- Typically expressed as a percentage uptime (e.g., 99.99% availability).
- Focuses on fault tolerance, redundancy, and quick recovery.
Mind Map: High Availability
Example: High Availability in Action
Consider an e-commerce platform deployed across two geographically separate data centers. If one data center experiences a failure, traffic is automatically routed to the other without downtime, ensuring customers can continue shopping seamlessly.
What is Scalability?
Scalability is the capability of a system to handle increased load by adding resources, maintaining or improving performance.
- Can be vertical (scaling up) or horizontal (scaling out).
- Involves both scaling infrastructure and application design.
Mind Map: Scalability
Example: Scalability in Practice
A social media platform experiences a sudden surge in users during a viral event. Horizontal scaling allows spinning up additional application servers automatically to handle the increased traffic without degrading user experience.
Interplay Between High Availability and Scalability
While both aim to improve system robustness, they address different concerns:
- High Availability focuses on minimizing downtime and ensuring continuous service.
- Scalability focuses on maintaining performance under growing load.
Often, scalable systems contribute to availability by distributing load and avoiding bottlenecks, but designing for both requires balancing trade-offs.
Mind Map: HA and Scalability Relationship
Summary
Understanding the definitions and nuances of High Availability and Scalability is the first step toward designing resilient, performant systems. By leveraging redundancy, fault tolerance, and flexible scaling strategies, modern applications can meet demanding SLAs and user expectations.
Additional Example: Simple Web Application
Imagine a web app hosted on a single server:
- Without HA: If the server crashes, the app is down.
- With HA: Multiple servers behind a load balancer ensure if one fails, others serve requests.
- Without Scalability: Fixed number of servers may struggle under peak load.
- With Scalability: Auto-scaling adds servers dynamically based on traffic.
This simple scenario illustrates the practical impact of these concepts.
References for Further Reading
- “Designing Data-Intensive Applications” by Martin Kleppmann
- AWS Well-Architected Framework: Reliability Pillar
- Google Cloud Architecture Framework
1.2 Key Challenges in Designing High Availability Systems
Designing systems that achieve high availability (HA) is a complex endeavor that requires addressing multiple technical and operational challenges. High availability means minimizing downtime and ensuring that services remain accessible and functional despite failures or unexpected conditions. Below, we explore the key challenges, supported by mind maps and practical examples to clarify these concepts.
Understanding Failure Modes
Failures can occur at various levels: hardware, software, network, or even human errors. Anticipating and mitigating these failures is critical.
Example: A cloud storage service experienced downtime due to a network partition between data centers, causing inconsistent data reads. The design lacked proper partition tolerance.
Ensuring Redundancy Without Complexity Overhead
Redundancy is essential but can introduce complexity, leading to new failure points.
Example: An e-commerce platform implemented multi-region database replication but faced challenges with data conflicts and increased latency due to asynchronous replication.
Balancing Consistency, Availability, and Partition Tolerance (CAP Theorem)
The CAP theorem states that in the presence of a network partition, a distributed system must choose between consistency and availability.
Example: A banking application prioritizes consistency over availability to avoid incorrect transactions, leading to temporary service unavailability during network partitions.
Handling State and Session Management
Maintaining user sessions and state across distributed nodes is challenging but critical for HA.
Example: A web application initially used sticky sessions for user login but faced availability issues when a node went down. Moving to a distributed session store improved availability.
Monitoring and Detecting Failures Proactively
Without effective monitoring, failures can go unnoticed, leading to prolonged downtime.
Example: A microservices architecture implemented centralized logging and alerting, enabling faster detection and resolution of cascading failures.
Managing Upgrades and Deployments Without Downtime
Rolling out updates while maintaining availability requires careful orchestration.
Example: A SaaS provider used blue-green deployment to upgrade services with zero downtime, reducing risk during updates.
Summary Mind Map
By understanding these challenges and incorporating best practices, architects and engineers can design systems that deliver high availability while balancing complexity and performance.
1.3 Scalability Dimensions: Vertical, Horizontal, and Diagonal Scaling
Scalability is a fundamental property of modern systems, enabling them to handle increasing loads gracefully. Understanding the different dimensions of scalability helps architects and engineers design systems that can grow efficiently and sustainably. The three primary dimensions are Vertical Scaling, Horizontal Scaling, and Diagonal Scaling.
Vertical Scaling (Scale-Up)
Vertical scaling involves adding more resources (CPU, RAM, storage) to a single machine or node to improve its capacity.
- Advantages:
- Simplicity: Easier to implement since it involves upgrading existing hardware or VM specs.
- No need to change application architecture significantly.
- Disadvantages:
- Limited by hardware constraints.
- Single point of failure remains.
- Can be expensive at scale.
Example: A database server initially running on a machine with 8 CPU cores and 32GB RAM is upgraded to a machine with 32 CPU cores and 256GB RAM to handle more queries.
Mind Map:
Horizontal Scaling (Scale-Out)
Horizontal scaling means adding more machines or nodes to a system to distribute load.
- Advantages:
- Virtually unlimited scaling potential.
- Improves fault tolerance by distributing load.
- Cost-effective using commodity hardware.
- Disadvantages:
- Increased complexity in distributed system management.
- Requires stateless or state-synchronized application design.
Example: A web application adds more instances behind a load balancer to handle increased traffic. Each instance runs the same application code and shares session state via a distributed cache.
Mind Map:
Diagonal Scaling
Diagonal scaling is a hybrid approach combining vertical and horizontal scaling. It involves scaling up individual nodes to a certain capacity and then scaling out by adding more nodes.
- Advantages:
- Balances cost and performance.
- Allows incremental scaling based on workload.
- Can optimize resource utilization.
- Disadvantages:
- More complex to manage than pure vertical or horizontal scaling.
- Requires careful capacity planning.
Example: An analytics platform initially scales up its processing nodes to handle larger batch jobs. Once vertical limits are reached, it adds more nodes and distributes jobs across them.
Mind Map:
Practical Considerations
| Dimension | When to Use | Example Scenario |
|---|---|---|
| Vertical Scaling | When simplicity and low complexity are priorities; limited scaling needed | Upgrading a single database server for better performance |
| Horizontal Scaling | When high availability and fault tolerance are critical; workload is easily distributed | Adding web servers behind a load balancer for a high-traffic site |
| Diagonal Scaling | When workload grows unpredictably; balance between cost and performance needed | Scaling a machine learning cluster by upgrading nodes and adding new ones |
Integrated Example: E-Commerce Platform
- Vertical Scaling: Upgrade the primary database server to handle more transactions during seasonal sales.
- Horizontal Scaling: Add more web servers and application servers behind load balancers to handle increased user traffic.
- Diagonal Scaling: Scale up the caching layer nodes for faster data retrieval, then add more cache nodes as demand grows.
This approach ensures the system remains responsive and available during peak loads without over-provisioning resources.
Summary
Understanding and applying vertical, horizontal, and diagonal scaling allows system architects to design flexible, resilient, and cost-effective systems. Each dimension has its place depending on workload characteristics, budget, and architectural constraints. Combining these approaches often yields the best results for complex, high-demand applications.
1.4 Overview of System Design Patterns for Resilience and Performance
In designing systems that are both resilient and performant, engineers rely on a set of proven design patterns. These patterns help build applications that gracefully handle failures, scale efficiently under load, and maintain responsiveness. This section explores key system design patterns, illustrating their purpose, benefits, and practical examples.
Key System Design Patterns
Circuit Breaker Pattern
Purpose: Prevent cascading failures by stopping calls to a failing service.
How it works: When a downstream service fails repeatedly, the circuit breaker “opens,” causing immediate failure responses without calling the service. After a timeout, it tries to “half-open” to test if the service has recovered.
Example:
Imagine a payment processing microservice that depends on an external fraud detection API. If the fraud API becomes unresponsive, the circuit breaker trips, and the payment service immediately rejects requests or falls back to a cached decision, preventing system-wide slowdowns.
Circuit Breaker Mind Map
Bulkhead Pattern
Purpose: Isolate failures in one part of the system so they do not affect others.
How it works: Resources (threads, connections) are partitioned into isolated pools. Failure or overload in one pool does not exhaust resources for others.
Example:
In an e-commerce platform, separate thread pools handle payment processing, inventory updates, and user notifications. If payment processing threads are saturated, inventory and notifications continue unaffected.
Bulkhead Mind Map
Load Balancer Pattern
Purpose: Distribute incoming traffic across multiple servers to improve throughput and availability.
How it works: Requests are routed based on algorithms like round-robin, least connections, or IP hash.
Example:
A video streaming service uses a load balancer to distribute user requests across multiple streaming servers, ensuring no single server is overwhelmed and improving user experience.
Load Balancer Mind Map
Cache Aside Pattern
Purpose: Improve read performance by caching data on demand.
How it works: Application first checks cache; if data is missing, it fetches from the database and populates the cache.
Example:
A social media app caches user profile data. When a profile is requested, the app checks Redis cache first, reducing database load and latency.
Cache Aside Mind Map
Event Sourcing and CQRS
Purpose: Separate read and write workloads and maintain an immutable log of changes.
How it works: All changes are stored as events. Reads are served from a separate optimized model.
Example:
An order management system records every order event (created, updated, shipped) as an immutable event. The read model is updated asynchronously for fast queries.
Event Sourcing & CQRS Mind Map
Summary
These patterns form the foundation for building resilient and scalable systems. By combining them thoughtfully, engineers can design architectures that gracefully handle failures, scale with demand, and maintain high performance.
In subsequent chapters, we will dive deeper into each pattern with real-world examples and best practices.
1.5 Setting Expectations: Trade-offs Between Availability, Consistency, and Partition Tolerance
Designing distributed systems that are highly available and scalable inevitably involves making trade-offs among three fundamental properties: Availability, Consistency, and Partition Tolerance. This section explores these trade-offs, commonly known as the CAP Theorem, and provides practical examples and mind maps to clarify these concepts.
Understanding the CAP Theorem
The CAP theorem states that in the presence of a network partition, a distributed system can provide only two of the following three guarantees:
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a (non-error) response – without guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite arbitrary message loss or failure of part of the system.
Since network partitions are inevitable in distributed systems, architects must choose between consistency and availability during these partitions.
Mind Map: CAP Theorem Overview
Trade-off Scenarios
| Scenario | Description | Example Systems |
|---|---|---|
| CP (Consistency + Partition Tolerance) | System sacrifices availability during partitions to maintain consistency. | HBase, MongoDB (in some configs) |
| AP (Availability + Partition Tolerance) | System sacrifices consistency to remain available during partitions. | Cassandra, DynamoDB |
| CA (Consistency + Availability) | Achievable only when no partitions occur (rare in distributed systems). | Traditional RDBMS in single node |
Mind Map: Trade-off Scenarios
Practical Example 1: Banking System (CP)
Context: A banking application must ensure that account balances are always accurate and consistent.
- Consistency: Critical to prevent overdrafts or double spending.
- Availability: Can tolerate some downtime during network partitions.
Design Choice: Use a CP system that may reject or delay transactions during partitions to maintain data correctness.
Implementation: Use distributed consensus algorithms like Paxos or Raft to ensure consistency.
Practical Example 2: Social Media Feed (AP)
Context: A social media platform displaying user feeds prioritizes availability to ensure users always see content, even if it might be slightly stale.
- Availability: Users expect fast responses, even during network issues.
- Consistency: Slight delays in feed updates are acceptable.
Design Choice: Use an AP system that serves cached or eventually consistent data.
Implementation: Employ eventual consistency models with background synchronization.
Mind Map: Example Systems and Their CAP Choices
Hybrid and Tunable Consistency Models
Modern systems often provide tunable consistency levels to balance availability and consistency based on use case:
- Strong Consistency: Guarantees latest data (CP).
- Eventual Consistency: Guarantees data will converge eventually (AP).
- Causal Consistency: Ensures causally related operations are seen in order.
Example: Cassandra allows clients to specify consistency levels per operation (e.g., ONE, QUORUM, ALL).
Mind Map: Tunable Consistency
Summary
- Network partitions are inevitable; systems must tolerate them (P).
- Choosing between consistency and availability depends on business requirements.
- Understanding trade-offs helps design systems aligned with user expectations and failure modes.
- Tunable consistency models provide flexibility to optimize for different scenarios.
Further Reading and Tools
- CAP Theorem - Martin Kleppmann’s explanation
- Designing Data-Intensive Applications by Martin Kleppmann
- Apache Cassandra Consistency Levels
This foundational understanding will guide the design decisions in subsequent chapters, where we explore specific patterns and architectures that embody these trade-offs.
2. Designing for Fault Tolerance and Redundancy
2.1 Understanding Single Points of Failure and Their Impact
What is a Single Point of Failure (SPOF)?
A Single Point of Failure (SPOF) is any component, system, or resource in an architecture whose failure will cause the entire system or application to fail or become unavailable. Identifying and mitigating SPOFs is critical in designing highly available and resilient systems.
Why SPOFs Matter
- System Downtime: A SPOF can bring down the entire system, leading to service interruptions.
- Reduced Reliability: Even if other components are healthy, the failure of a SPOF compromises the whole system.
- Business Impact: Downtime can translate to lost revenue, customer dissatisfaction, and reputational damage.
Common Examples of SPOFs
- Single Database Instance: If the database server goes down, the application cannot access data.
- Single Load Balancer: Failure of the load balancer stops traffic routing.
- Monolithic Application Server: One server hosting the entire app without failover.
- Network Switch or Router: A single network device failure can isolate parts of the system.
Mind Map: Identifying Single Points of Failure
Impact Analysis Mind Map
Example 1: SPOF in a Web Application Architecture
Consider a traditional web application with the following components:
- Single web server
- Single database server
- Single load balancer
If the database server fails:
- The web server cannot retrieve or store data.
- The entire application becomes non-functional.
If the load balancer fails:
- Incoming traffic cannot be routed to the web server.
- Users experience downtime despite the web server being healthy.
This architecture clearly has multiple SPOFs.
Example 2: SPOF in a Microservices Environment
Imagine a microservices-based system where:
- A critical authentication service runs on a single instance.
- Other services depend on authentication for user validation.
If the authentication service instance crashes:
- All dependent services fail to authenticate users.
- The entire system’s user-facing functionality is impacted.
This authentication service instance is a SPOF.
Best Practices to Identify SPOFs
- System Mapping: Create detailed architecture diagrams highlighting dependencies.
- Dependency Analysis: List all critical components and their failure impact.
- Load Testing: Simulate failures to observe system behavior.
- Monitoring and Alerts: Detect and alert on component failures early.
Summary
Understanding SPOFs is the foundation of building resilient systems. By identifying components whose failure can cripple the system, engineers can design redundancy, failover mechanisms, and fault-tolerant architectures to mitigate risks and ensure continuous availability.
2.2 Active-Active vs Active-Passive Redundancy Models with Examples
Designing systems for high availability often involves choosing the right redundancy model. Two of the most common patterns are Active-Active and Active-Passive redundancy. Understanding their differences, benefits, trade-offs, and practical applications is critical for senior engineers and technical leads aiming to build resilient and scalable systems.
What is Redundancy in System Design?
Redundancy means having additional components, systems, or resources that can take over or share the workload if the primary system fails or becomes overloaded. It is a fundamental technique to avoid single points of failure and ensure continuous service availability.
Active-Active Redundancy Model
Definition: In an Active-Active model, multiple nodes or instances run simultaneously, actively handling requests or workloads in parallel. All active nodes share the load and are capable of serving traffic at any time.
Key Characteristics:
- All nodes are operational and serving traffic concurrently.
- Load is distributed across all active nodes.
- Failover is automatic and seamless since all nodes are already active.
- Typically requires data synchronization and conflict resolution mechanisms.
Advantages:
- Improved resource utilization since all nodes are active.
- Better scalability as load can be balanced dynamically.
- Faster failover with minimal downtime.
Challenges:
- Complexity in data consistency and synchronization.
- Potential for split-brain scenarios if network partitions occur.
- More complex monitoring and orchestration.
Mind Map: Active-Active Redundancy Model
Example: Multi-Region Web Application
Imagine a global e-commerce platform with two data centers in different regions (US-East and EU-West). Both data centers actively serve user requests. A global load balancer distributes incoming traffic based on latency and availability.
- Each data center runs a full copy of the application and database cluster.
- Data replication is asynchronous but eventually consistent.
- If US-East goes down, EU-West continues serving traffic without interruption.
This setup maximizes availability and reduces latency for users worldwide.
Active-Passive Redundancy Model
Definition: In an Active-Passive model, one node (or cluster) actively handles all traffic, while one or more passive nodes remain on standby, ready to take over if the active node fails.
Key Characteristics:
- Only one active node serves traffic at any time.
- Passive nodes are idle or perform minimal background tasks.
- Failover requires detecting failure and switching traffic to the passive node.
- Often simpler to implement than Active-Active.
Advantages:
- Simpler data consistency since only one active writer exists.
- Easier to implement and manage.
- Reduced risk of split-brain scenarios.
Challenges:
- Resource underutilization (passive nodes idle most of the time).
- Failover may introduce some downtime or latency.
- Scalability is limited compared to Active-Active.
Mind Map: Active-Passive Redundancy Model
Example: Primary-Backup Database Setup
Consider a financial application using a primary MySQL database server with a secondary standby server:
- The primary server handles all read/write operations.
- The secondary server replicates data asynchronously and remains passive.
- If the primary fails, an orchestrator promotes the secondary to primary.
- Clients reconnect to the new primary to resume operations.
This approach ensures data integrity with minimal complexity but may cause a brief outage during failover.
Comparison Table
| Feature | Active-Active | Active-Passive |
|---|---|---|
| Number of Active Nodes | Multiple | One |
| Load Distribution | Yes | No |
| Failover Time | Near Instant | Some delay (failover time) |
| Complexity | High | Moderate |
| Data Consistency | Complex (requires conflict handling) | Simpler (single writer) |
| Resource Utilization | High | Low (passive nodes idle) |
| Scalability | High | Limited |
Best Practices for Choosing Between Active-Active and Active-Passive
-
Use Active-Active when:
- You need maximum uptime and seamless failover.
- Your system supports eventual consistency or strong consensus.
- You want to scale horizontally and distribute load.
-
Use Active-Passive when:
- Simplicity and data consistency are priorities.
- Your workload is write-heavy and requires a single source of truth.
- You can tolerate short failover delays.
Summary
Both Active-Active and Active-Passive redundancy models are essential tools in the system designer’s toolkit. The choice depends on the application’s availability requirements, consistency model, complexity tolerance, and scalability needs. By understanding these models deeply and applying them with real-world examples, senior engineers can architect systems that balance reliability, performance, and operational simplicity.
2.3 Circuit Breaker Pattern: Preventing Cascading Failures
Introduction
In distributed systems, failures are inevitable. When one service or component fails, it can trigger a domino effect causing other services to become overwhelmed or fail as well. This phenomenon is known as cascading failure. The Circuit Breaker pattern is a design pattern that helps prevent such failures by detecting when a service is failing and temporarily halting requests to it, allowing it to recover.
What is the Circuit Breaker Pattern?
The Circuit Breaker pattern acts like an electrical circuit breaker in your home. When a fault is detected, the breaker trips and stops the flow of electricity to prevent damage. Similarly, in software systems, the circuit breaker monitors calls to an external service or resource. If failures exceed a threshold, it “opens” the circuit, preventing further calls to the failing service for a configurable period.
States of a Circuit Breaker
How It Works
- Closed State: The circuit breaker allows all requests to pass through and monitors failures.
- Failure Threshold Exceeded: If failures reach a threshold (e.g., 5 consecutive failures), the circuit breaker trips to the Open state.
- Open State: Requests are immediately failed or fallback logic is triggered without calling the failing service.
- Timeout Expiry: After a timeout, the circuit breaker moves to Half-Open state to test if the service has recovered.
- Half-Open State: A limited number of requests are allowed. If they succeed, the circuit closes; if they fail, it reopens.
Benefits of Using Circuit Breaker
- Prevents cascading failures: Stops flooding a failing service with requests.
- Improves system stability: Allows failing services time to recover.
- Enables graceful degradation: Fallbacks or cached responses can be served.
- Provides monitoring insights: Tracks failure rates and system health.
Example Scenario: Circuit Breaker in a Microservices Architecture
Imagine a payment processing microservice that depends on an external credit card validation API. If the external API becomes slow or unresponsive, the payment service could get overwhelmed waiting for responses, causing delays or failures in the entire system.
By implementing a circuit breaker:
- When the credit card API fails repeatedly, the circuit breaker opens.
- The payment service immediately returns a fallback response (e.g., “Service temporarily unavailable, please try again later”) without waiting.
- After a timeout, the circuit breaker tests the API again.
- If the API is healthy, the circuit closes and normal operation resumes.
Best Practices
- Set appropriate thresholds: Tune failure and success thresholds based on service SLAs.
- Implement fallback logic: Provide meaningful degraded responses or cached data.
- Monitor circuit breaker metrics: Track open/close events and failure rates.
- Combine with retries: Use retries with exponential backoff cautiously to avoid overwhelming services.
- Use libraries/frameworks: Leverage mature circuit breaker implementations (e.g., Netflix Hystrix, Resilience4j).
Summary
The Circuit Breaker pattern is a critical tool for building resilient, highly available systems. By proactively detecting failures and halting requests to unhealthy services, it prevents cascading failures and improves overall system stability. Integrating circuit breakers with fallback strategies and monitoring enables graceful degradation and faster recovery in complex distributed architectures.
2.4 Bulkhead Pattern: Isolating Failures to Protect System Health
The Bulkhead pattern is a critical design approach in building resilient, high availability systems. Inspired by the compartments in a ship’s hull that prevent flooding from sinking the entire vessel, the Bulkhead pattern isolates different parts of a system to contain failures and prevent cascading outages.
What is the Bulkhead Pattern?
The Bulkhead pattern involves partitioning a system into isolated components or resources so that a failure in one part does not bring down the entire system. This isolation can be at various levels such as thread pools, service instances, database connections, or even physical hardware.
Why Use the Bulkhead Pattern?
- Failure Containment: Limits the blast radius of failures.
- Improved Stability: Keeps unaffected components running smoothly.
- Resource Management: Prevents resource starvation by isolating resource pools.
Mind Map: Bulkhead Pattern Overview
Types of Bulkheads
- Thread Pool Bulkheads: Separate thread pools for different tasks or services to prevent thread starvation.
- Connection Pool Bulkheads: Dedicated database or network connection pools per service or function.
- Service Instance Bulkheads: Deploying multiple instances or containers with isolated resources.
- Physical Bulkheads: Using separate hardware or virtual machines.
Mind Map: Types of Bulkheads
Practical Example: Implementing Bulkhead Pattern in a Microservices Architecture
Imagine an e-commerce platform with multiple microservices: Order Processing, Payment, Inventory, and Notification.
Problem: If the Payment service experiences heavy load or failures, it might exhaust shared thread pools or database connections, causing delays or failures in other services.
Solution: Apply Bulkhead pattern by isolating resources:
- Assign separate thread pools for each microservice.
- Use dedicated database connection pools per service.
- Deploy services in isolated containers with resource limits.
Example in Java (Thread Pool Bulkhead):
// Define separate thread pools for services
ExecutorService paymentThreadPool = Executors.newFixedThreadPool(10);
ExecutorService orderThreadPool = Executors.newFixedThreadPool(20);
// Payment service task submitted to its own pool
paymentThreadPool.submit(() -> {
// Payment processing logic
});
// Order service task submitted to its own pool
orderThreadPool.submit(() -> {
// Order processing logic
});
This isolation ensures that a surge or failure in the Payment service thread pool does not impact the Order service.
Mind Map: Bulkhead Pattern Implementation Example
Best Practices for Bulkhead Pattern
- Define clear boundaries: Identify critical components to isolate.
- Monitor resource usage: Track thread pools, connections, and container metrics.
- Fail fast and degrade gracefully: Use circuit breakers alongside bulkheads.
- Automate resource allocation: Use orchestration tools (e.g., Kubernetes) to enforce limits.
Additional Example: Bulkhead with Circuit Breaker Integration
Combining Bulkhead with Circuit Breaker enhances resilience:
- Bulkhead limits resource usage per component.
- Circuit Breaker detects failures and stops calls to failing components.
// Using resilience4j library
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(10)
.build();
Bulkhead bulkhead = Bulkhead.of("paymentBulkhead", bulkheadConfig);
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("paymentCircuitBreaker");
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, () -> paymentService.call());
decoratedSupplier = Bulkhead
.decorateSupplier(bulkhead, decoratedSupplier);
Try<String> result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback response");
This code snippet shows how to isolate payment service calls using Bulkhead and protect it with a Circuit Breaker.
Summary
The Bulkhead pattern is essential for building fault-tolerant systems by isolating failures and managing resource usage. When combined with other resilience patterns like Circuit Breakers, it significantly improves system stability and availability.
References
- Martin Fowler on Bulkhead Pattern
- Resilience4j Bulkhead Documentation
- Microservices Patterns by Chris Richardson
2.5 Practical Example: Implementing Circuit Breaker and Bulkhead in a Microservices Architecture
In this section, we will explore how to implement the Circuit Breaker and Bulkhead patterns within a microservices architecture to enhance fault tolerance and system resilience. These patterns help prevent cascading failures and isolate faults, ensuring high availability.
Understanding the Context
Imagine an e-commerce platform composed of multiple microservices:
- Order Service: Handles order processing
- Payment Service: Processes payments
- Inventory Service: Manages stock levels
- Notification Service: Sends emails and SMS
Failures in any of these services can impact the entire system. Implementing Circuit Breaker and Bulkhead patterns helps mitigate these risks.
Circuit Breaker Pattern
The Circuit Breaker pattern prevents an application from repeatedly trying to execute an operation that’s likely to fail, allowing the system to recover gracefully.
Mind Map: Circuit Breaker Pattern
Example: Implementing Circuit Breaker in Payment Service
// Using Resilience4j library in Java
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 50% failure rate to trip
.waitDurationInOpenState(Duration.ofSeconds(30)) // wait 30s before retry
.slidingWindowSize(10) // last 10 calls
.build();
CircuitBreaker circuitBreaker = CircuitBreaker.of("paymentService", config);
Supplier<String> paymentSupplier = CircuitBreaker.decorateSupplier(circuitBreaker, () -> {
// Call to external payment gateway
return paymentGateway.processPayment();
});
Try<String> result = Try.ofSupplier(paymentSupplier)
.recover(throwable -> "Payment service unavailable, please try later.");
System.out.println(result.get());
In this example, if the failure rate exceeds 50% over the last 10 calls, the circuit breaker opens, and calls fail fast for 30 seconds before trying again.
Bulkhead Pattern
The Bulkhead pattern isolates different parts of a system to prevent failures in one component from cascading to others.
Mind Map: Bulkhead Pattern
Example: Implementing Bulkhead in Notification Service
// Using Resilience4j Bulkhead
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(5) // limit concurrent calls
.maxWaitDuration(Duration.ofMillis(500)) // max wait time
.build();
Bulkhead bulkhead = Bulkhead.of("notificationService", bulkheadConfig);
Supplier<String> notificationSupplier = Bulkhead.decorateSupplier(bulkhead, () -> {
// Call to send notification
return notificationClient.sendNotification();
});
Try<String> result = Try.ofSupplier(notificationSupplier)
.recover(throwable -> "Notification service busy, please retry later.");
System.out.println(result.get());
Here, the notification service limits concurrent calls to 5, preventing overload and isolating failures.
Combined Usage in Microservices Architecture
Integrating both patterns provides robust fault tolerance:
- Circuit Breaker prevents repeated failing calls
- Bulkhead limits resource usage per service
Mind Map: Combined Circuit Breaker and Bulkhead
Example: Wrapping a Remote Call with Both Patterns
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, Bulkhead.decorateSupplier(bulkhead, () -> {
return remoteService.call();
}));
Try<String> result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Service unavailable, fallback response.");
System.out.println(result.get());
This layered approach ensures that calls are first limited by Bulkhead, then monitored by Circuit Breaker.
Summary of Best Practices
- Tune thresholds carefully: Avoid too sensitive or too lenient settings.
- Use fallback methods: Provide graceful degradation.
- Monitor metrics: Track circuit breaker states and bulkhead usage.
- Test under failure scenarios: Use chaos testing to validate resilience.
By implementing Circuit Breaker and Bulkhead patterns thoughtfully, microservices architectures can achieve higher availability and resilience against cascading failures.
3. Load Balancing Patterns for Scalability and Availability
3.1 Fundamentals of Load Balancing: Algorithms and Strategies
Load balancing is a critical component in designing scalable and highly available systems. It distributes incoming network or application traffic across multiple servers or resources to ensure no single server becomes a bottleneck, thereby improving responsiveness and availability.
What is Load Balancing?
Load balancing is the process of distributing client requests or network load efficiently across multiple backend servers or resources. It helps achieve:
- Scalability: By spreading workload, systems can handle more traffic.
- High Availability: If one server fails, others can take over.
- Fault Tolerance: Reduces the risk of downtime.
Core Load Balancing Algorithms
Below is a mind map summarizing the main load balancing algorithms:
Detailed Explanation of Algorithms
-
Round Robin
- Requests are distributed evenly in a circular order.
- Example: If you have 3 servers (A, B, C), requests go A → B → C → A → B → C …
- Best Practice: Works well when servers have similar specs and request loads.
-
Weighted Round Robin
- Each server is assigned a weight proportional to its capacity.
- Servers with higher weights receive more requests.
- Example: Server A (weight 3), Server B (weight 1) → A, A, A, B, A, A, A, B …
-
Least Connections
- Directs traffic to the server with the fewest active connections.
- Useful when requests have variable processing times.
- Example: If Server A has 5 active connections and Server B has 2, next request goes to Server B.
-
Weighted Least Connections
- Similar to Least Connections but factors in server weights.
- Balances load more intelligently when servers differ in capacity.
-
IP Hash
- Uses a hash of the client’s IP address to consistently route requests to the same server.
- Ensures session persistence without sticky sessions.
- Example: Client IP 192.168.1.10 always routed to Server B.
-
Random
- Selects a server randomly.
- Simple but can cause uneven load distribution.
Load Balancing Strategies
Examples
Example 1: Round Robin Load Balancer with NGINX
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}
This configuration distributes incoming HTTP requests evenly across three backend servers.
Example 2: Least Connections with HAProxy
frontend http_front
bind *:80
default_backend servers
backend servers
balance leastconn
server srv1 192.168.1.1:80 check
server srv2 192.168.1.2:80 check
server srv3 192.168.1.3:80 check
HAProxy sends requests to the server with the fewest active connections, improving performance when request processing times vary.
Example 3: IP Hash for Session Persistence
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
}
This ensures that clients with the same IP address are always routed to the same backend server, useful for session affinity.
Best Practices
- Choose the algorithm based on your workload characteristics (e.g., uniform vs variable request sizes).
- Combine load balancing with health checks to avoid routing traffic to unhealthy servers.
- Use weighted algorithms when server capacities differ.
- For stateful applications, consider session persistence strategies like IP Hash or cookies.
- Monitor load balancer metrics to detect and troubleshoot bottlenecks.
Summary
Load balancing is foundational for building scalable and highly available applications. Understanding the strengths and trade-offs of different algorithms and strategies enables you to tailor your system design to your specific needs, improving performance and reliability.
3.2 Client-Side vs Server-Side Load Balancing Explained
Load balancing is a critical component of scalable and highly available systems. It distributes incoming network traffic across multiple servers to ensure no single server becomes a bottleneck or point of failure. Understanding the distinction between client-side and server-side load balancing is essential for designing resilient architectures.
What is Load Balancing?
Load balancing is the process of distributing workloads evenly across multiple computing resources, such as servers, clusters, or network links, to optimize resource use, maximize throughput, reduce latency, and ensure fault tolerance.
Client-Side Load Balancing
In client-side load balancing, the client is responsible for selecting the server instance to which it sends requests. This approach requires the client to have knowledge of available servers and their health status.
How it works:
- The client maintains a list of available servers (service instances).
- It applies a load balancing algorithm (e.g., round-robin, random, weighted) to select a target server.
- The client sends the request directly to the chosen server.
Advantages:
- Reduces load on a central load balancer, improving scalability.
- Enables more granular control and customization of load balancing logic.
- Can reduce latency by allowing clients to choose the nearest or least loaded server.
Disadvantages:
- Clients need to maintain up-to-date server lists, which adds complexity.
- Health checking and server discovery must be implemented on the client side.
- Difficult to update load balancing logic without updating clients.
Example: Netflix Ribbon
Netflix Ribbon is a client-side load balancer used in microservices architectures. It integrates with service discovery tools like Eureka to get the list of available servers and applies load balancing algorithms on the client side.
Simple Example in Pseudocode:
servers = ["server1", "server2", "server3"]
# Round-robin index
index = 0
def get_next_server():
global index
server = servers[index]
index = (index + 1) % len(servers)
return server
# Client sends request
server = get_next_server()
response = send_request(server, request_data)
Server-Side Load Balancing
In server-side load balancing, the client sends requests to a single load balancer endpoint. The load balancer then distributes the requests to backend servers based on its configured algorithm.
How it works:
- Clients send requests to a load balancer (hardware or software).
- The load balancer monitors backend server health.
- It applies load balancing algorithms (round-robin, least connections, IP hash, etc.) to forward requests.
Advantages:
- Simplifies client logic; clients only need to know the load balancer’s address.
- Centralized health monitoring and routing.
- Easier to update load balancing policies without changing clients.
Disadvantages:
- Load balancer can become a bottleneck or single point of failure if not highly available.
- Adds an extra network hop, potentially increasing latency.
Example: NGINX as a Load Balancer
NGINX can be configured as a reverse proxy and load balancer, routing incoming HTTP requests to multiple backend servers.
NGINX Configuration Snippet:
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}
Comparative Mind Map
Hybrid Approaches
Some architectures combine both client-side and server-side load balancing to leverage the benefits of each. For example, a client might use client-side load balancing within a data center and rely on server-side load balancing for cross-region traffic.
Summary Table
| Feature | Client-Side Load Balancing | Server-Side Load Balancing |
|---|---|---|
| Responsibility | Client | Load Balancer |
| Server List Management | Client maintains and updates | Load balancer maintains |
| Health Checks | Client or service discovery mechanism | Load balancer performs |
| Scalability | High (no central bottleneck) | Depends on load balancer capacity |
| Latency | Potentially lower (direct connection) | Slightly higher (extra hop) |
| Complexity | Higher client complexity | Simpler clients |
Practical Example Scenario
Scenario: A microservices architecture deployed in Kubernetes.
-
Client-Side Load Balancing: The service discovery mechanism (e.g., Kubernetes DNS or service mesh) provides the client pods with the list of pod IPs. The client library (like Envoy sidecar or a custom client) selects which pod to call.
-
Server-Side Load Balancing: Kubernetes Service acts as a load balancer with a virtual IP, forwarding requests to backend pods.
Both approaches are often combined: the client uses server-side load balancing via the Kubernetes Service, while sidecars or service meshes implement client-side load balancing for finer control.
Understanding when and how to apply client-side versus server-side load balancing is key to building scalable, resilient systems. The choice depends on the architecture, operational complexity, latency requirements, and failure tolerance desired.
3.3 DNS Load Balancing and Global Traffic Management
DNS Load Balancing and Global Traffic Management are critical techniques for distributing client requests across multiple servers or data centers, ensuring high availability, fault tolerance, and optimal performance on a global scale.
What is DNS Load Balancing?
DNS Load Balancing leverages the Domain Name System (DNS) to distribute incoming traffic by returning different IP addresses for the same domain name based on various algorithms or policies. It is often used to balance load across geographically distributed servers or data centers.
Key Characteristics:
- Operates at the DNS resolution level
- Simple to implement and widely supported
- Can direct users to the closest or healthiest server
- Limited control over session persistence
Global Traffic Management (GTM)
Global Traffic Management extends DNS Load Balancing by integrating health checks, geographic routing, latency-based routing, and failover capabilities to intelligently route users to the best available endpoint.
GTM Features:
- Health monitoring of endpoints
- Geo-DNS: routing based on user location
- Latency-based routing
- Weighted routing
- Failover and disaster recovery support
Mind Map: DNS Load Balancing and Global Traffic Management
Common DNS Load Balancing Algorithms
| Algorithm | Description | Use Case Example |
|---|---|---|
| Round Robin | Cycles through a list of IPs sequentially | Simple load distribution across identical servers |
| Weighted Round Robin | Assigns weights to IPs to distribute traffic unevenly | Prioritize more powerful servers |
| Geo DNS | Routes based on client geographic location | Direct users to nearest data center |
| Failover DNS | Routes to backup IP if primary is unavailable | Disaster recovery and high availability |
Example: Implementing Geo DNS for a Global Web Application
Imagine a SaaS company with data centers in the US, Europe, and Asia. They want users to connect to the closest data center to minimize latency.
- Setup: Configure DNS records with multiple A records, each pointing to a data center IP.
- Geo DNS Provider: Use a DNS provider that supports Geo DNS (e.g., AWS Route 53, Cloudflare, NS1).
- Routing Policy: Define geographic regions (e.g., North America, Europe, Asia) and assign corresponding IPs.
- Health Checks: Enable health checks to detect data center outages.
- Failover: If a data center is down, traffic is routed to the next closest healthy data center.
Example DNS Records:
| Domain | Type | Value (IP) | Geo-Location |
|---|---|---|---|
| app.example.com | A | 192.0.2.1 | North America |
| app.example.com | A | 198.51.100.1 | Europe |
| app.example.com | A | 203.0.113.1 | Asia |
Mind Map: Geo DNS Implementation Steps
Challenges and Best Practices
-
DNS Caching and TTL: DNS responses are cached by clients and resolvers, which can delay failover. Use lower TTL values (e.g., 30-60 seconds) to improve responsiveness but balance against increased DNS query load.
-
Session Persistence: DNS load balancing does not guarantee session stickiness. For stateful applications, consider combining DNS load balancing with application-level session management or sticky sessions at the load balancer level.
-
Health Checks: Always configure health checks to avoid routing traffic to unhealthy endpoints.
-
Monitoring: Continuously monitor DNS performance and traffic patterns to detect anomalies.
-
Fallback Strategies: Design fallback routes to handle complete region outages gracefully.
Real-World Example: AWS Route 53 Latency-Based Routing
AWS Route 53 offers latency-based routing, a form of DNS load balancing that routes users to the region with the lowest latency.
Scenario: A global video streaming service wants users to connect to the region with the fastest response.
Implementation Steps:
- Create latency alias records for each regional endpoint.
- Route 53 measures latency from the user’s location to each endpoint.
- DNS queries receive IPs of the lowest latency region.
Benefits:
- Improved user experience due to reduced latency.
- Automatic failover if a region becomes unhealthy.
Summary
DNS Load Balancing and Global Traffic Management are foundational patterns for building globally distributed, highly available, and scalable applications. By intelligently routing traffic based on geography, latency, and health, systems can optimize performance and resilience.
Integrating these patterns with other system design best practices ensures robust, fault-tolerant architectures capable of serving users worldwide efficiently.
3.4 Example: Designing a Multi-Region Load Balancer with Failover
Designing a multi-region load balancer with failover is a critical pattern to ensure both high availability and low latency for global applications. This example will walk through the architecture, components, and best practices, integrating mind maps and practical examples to clarify the concepts.
Overview
A multi-region load balancer routes user requests to the nearest or healthiest region, ensuring minimal latency and continuous availability even if one region fails. Failover mechanisms automatically redirect traffic from a failed region to a healthy one.
Mind Map: Multi-Region Load Balancer Architecture
Step 1: DNS Layer with GeoDNS and Latency-Based Routing
- GeoDNS directs users to the closest region based on geographic location.
- Latency-based routing sends traffic to the region with the lowest network latency.
- Failover routing reroutes traffic if the primary region is unhealthy.
Example: Using AWS Route 53, configure a latency-based routing policy with health checks on endpoints in multiple regions.
# Route 53 Latency Routing Example
- Record Name: www.example.com
- Routing Policy: Latency
- Regions:
- us-east-1 (Primary)
- eu-west-1 (Secondary)
- Health Checks:
- HTTP GET /health
- Interval: 30 seconds
- Failure Threshold: 3
Step 2: Global Traffic Manager (GTM)
The GTM monitors health and manages failover policies.
- Performs continuous health checks on regional load balancers.
- Automatically updates DNS records or routes traffic to healthy regions.
Example: Implement a GTM using open-source tools like NGINX Plus or commercial solutions such as F5 BIG-IP DNS.
Step 3: Regional Load Balancers
Each region has its own load balancer distributing traffic to backend services.
- Use Application Load Balancers (ALB) for HTTP/HTTPS traffic.
- Use Network Load Balancers (NLB) for TCP/UDP traffic.
Example: In AWS, deploy an ALB in us-east-1 and eu-west-1, each routing to auto-scaled EC2 instances.
# ALB Target Group Example
- Targets:
- EC2 Instance 1
- EC2 Instance 2
- Health Check Path: /health
- Deregistration Delay: 300 seconds
Step 4: Backend Services
Backend services should be designed for eventual consistency and data replication across regions to handle failover gracefully.
- Use multi-region database replication (e.g., Amazon Aurora Global Database).
- Ensure stateless services or session replication for stateful services.
Step 5: Monitoring and Alerting
- Monitor health check statuses and failover events.
- Set up alerts for region outages or degraded performance.
Example: Use Prometheus and Grafana dashboards to visualize health and traffic distribution.
Practical Example Scenario
Scenario: A global e-commerce platform wants to serve customers from North America and Europe with minimal latency and high availability.
- Deploy regions in us-east-1 and eu-west-1.
- Configure Route 53 with latency-based routing and health checks.
- Use AWS ALBs in each region to distribute traffic to microservices.
- Backend databases replicate data asynchronously with conflict resolution.
- GTM monitors health and triggers DNS failover.
Failover Flow:
- Users in Europe are routed to eu-west-1.
- eu-west-1 experiences an outage.
- Health checks fail, GTM updates DNS to route Europe traffic to us-east-1.
- Traffic continues uninterrupted with minimal latency impact.
Best Practices
- Health Checks: Use comprehensive health checks that verify application-level readiness, not just network availability.
- DNS TTL: Set low TTL (e.g., 60 seconds) on DNS records to enable quick failover.
- Session Management: Use sticky sessions cautiously; prefer stateless designs or distributed session stores.
- Testing: Regularly test failover scenarios using chaos engineering principles.
- Security: Secure DNS and load balancer endpoints with TLS and proper authentication.
This example demonstrates how combining DNS routing, global traffic management, regional load balancers, and resilient backend services can create a robust multi-region load balancing architecture with automatic failover, ensuring high availability and scalability for global applications.
3.5 Best Practices for Health Checks and Dynamic Load Balancer Configuration
Ensuring that your load balancer routes traffic only to healthy instances is critical for maintaining both high availability and optimal performance. Dynamic load balancer configuration enables your system to adapt in real-time to changing conditions, such as scaling events or instance failures.
Key Concepts
- Health Checks: Mechanisms to verify the operational status of backend services.
- Dynamic Configuration: Automatic updating of load balancer routing rules based on health and metrics.
Best Practices for Health Checks
Use Multiple Health Check Types
- TCP Health Checks: Verify if the port is open and accepting connections.
- HTTP/HTTPS Health Checks: Check specific application endpoints for expected responses.
- Custom Health Endpoints: Implement application-specific health checks that verify dependencies (e.g., database connectivity, cache availability).
Design Lightweight and Fast Health Checks
- Keep health check endpoints minimal to avoid adding load.
- Avoid expensive computations or heavy database queries.
Set Appropriate Health Check Intervals and Timeouts
- Balance between detection speed and system overhead.
- Example: Check every 10 seconds with a 2-second timeout.
Implement Graceful Startup and Shutdown
- During startup, mark instances as “warming up” to avoid premature traffic.
- On shutdown, deregister instances to prevent new requests.
Use Circuit Breakers in Health Checks
- If a service is flapping between healthy and unhealthy, circuit breakers can prevent oscillations.
Best Practices for Dynamic Load Balancer Configuration
Automate Instance Registration and Deregistration
- Use service discovery tools (e.g., Consul, etcd, Eureka) integrated with load balancers.
- Example: When a new instance spins up, it registers itself and becomes a routing target.
Use Weighted Load Balancing
- Assign weights based on instance capacity or health metrics.
- Dynamically adjust weights to optimize traffic distribution.
Implement Blue-Green and Canary Deployments
- Dynamically route a subset of traffic to new versions.
- Use load balancer rules to gradually shift traffic.
Monitor and React to Metrics
- Integrate load balancer with monitoring systems.
- Automatically remove or add instances based on CPU, memory, or request latency.
Ensure Consistency Across Multiple Load Balancers
- In multi-region or multi-availability zone setups, synchronize configurations.
Mind Maps
Health Checks Mind Map
Dynamic Load Balancer Configuration Mind Map
Practical Example: Dynamic Load Balancer with Health Checks in Kubernetes
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app-image:v1
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
timeoutSeconds: 2
Explanation:
- Readiness Probe ensures the pod only receives traffic when healthy.
- Liveness Probe restarts the pod if it becomes unhealthy.
- Kubernetes automatically updates the load balancer endpoints based on pod health.
Additional Example: Weighted Load Balancing with NGINX Plus
upstream backend {
server backend1.example.com weight=5 max_fails=3 fail_timeout=30s;
server backend2.example.com weight=1 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
}
}
- Weights reflect capacity or priority.
- max_fails and fail_timeout configure health check failure handling.
- Dynamic reconfiguration can be automated using NGINX Plus API.
Summary
| Best Practice | Benefit | Example Tool/Technique |
|---|---|---|
| Multiple Health Check Types | Comprehensive health verification | HTTP/HTTPS probes, TCP checks |
| Lightweight Health Checks | Minimize overhead | Simple /health endpoint |
| Graceful Startup and Shutdown | Avoid routing to unhealthy or terminating instances | Kubernetes readiness/liveness probes |
| Automated Instance Registration | Real-time load balancer updates | Consul, Kubernetes Service |
| Weighted Load Balancing | Traffic optimization based on capacity | NGINX Plus, HAProxy |
| Monitoring-Driven Configuration | Adaptive scaling and routing | Prometheus + Alertmanager |
By implementing these best practices, you ensure your load balancer intelligently routes traffic only to healthy instances, adapts dynamically to system changes, and maintains a resilient, scalable application environment.
4. Data Replication and Consistency Patterns
4.1 Synchronous vs Asynchronous Replication: Trade-offs and Use Cases
Replication is a cornerstone for building highly available and scalable systems, ensuring data durability and fault tolerance across distributed environments. Understanding the differences between synchronous and asynchronous replication is critical for designing systems that meet your application’s consistency, latency, and availability requirements.
What is Replication?
Replication involves copying data from one database or storage node (the primary) to one or more secondary nodes to ensure redundancy and improve read scalability.
Mind Map: Overview of Replication Types
Synchronous Replication
Definition: In synchronous replication, the primary node waits for all replicas to confirm that they have written the data before acknowledging the write operation to the client.
Trade-offs:
- Pros:
- Guarantees strong consistency across replicas.
- Minimizes data loss in case of failover.
- Cons:
- Increased write latency due to waiting for replicas.
- Reduced throughput under high load.
- Network latency impacts overall system performance.
Example: Consider a banking application where a funds transfer must be recorded reliably before confirming success to the user. Using synchronous replication ensures that if the primary fails, the replicas have the latest data, preventing inconsistencies.
Asynchronous Replication
Definition: In asynchronous replication, the primary node acknowledges the write operation immediately after writing locally, without waiting for replicas to confirm.
Trade-offs:
- Pros:
- Lower write latency and higher throughput.
- Better performance for write-heavy workloads.
- Cons:
- Potential data loss if primary fails before replicas catch up.
- Eventual consistency model; replicas lag behind primary.
Example: A social media platform storing user posts may use asynchronous replication to optimize for low latency writes. Slight delays in replication are acceptable since eventual consistency is sufficient.
Mind Map: Trade-offs Comparison
Use Case Decision Guide
| Use Case Type | Replication Type | Reasoning |
|---|---|---|
| Financial transactions | Synchronous | Requires strong consistency and no data loss. |
| Inventory management | Synchronous | Accurate stock levels critical. |
| Analytics and reporting | Asynchronous | Can tolerate eventual consistency. |
| Content delivery | Asynchronous | Prioritizes low latency and scalability. |
| IoT sensor data | Asynchronous | High volume, eventual consistency acceptable. |
Practical Example: Implementing Both Replication Modes
Imagine a global e-commerce platform:
- Order Processing Service: Uses synchronous replication to ensure orders are never lost and inventory is accurate.
- User Activity Logs: Uses asynchronous replication to collect data for analytics without impacting user experience.
Summary
- Synchronous replication favors consistency and durability at the cost of latency.
- Asynchronous replication favors performance and availability but risks temporary inconsistency.
- Choosing the right replication mode depends on your application’s tolerance for latency, consistency, and potential data loss.
References & Further Reading
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Database vendor documentation (e.g., PostgreSQL, MySQL, Cassandra replication)
- Cloud provider replication services (AWS RDS, Google Cloud Spanner)
4.2 Master-Slave and Multi-Master Replication Patterns
Replication is a fundamental technique to enhance data availability, fault tolerance, and read scalability in distributed systems. Two widely adopted replication patterns are Master-Slave and Multi-Master replication. This section explores their architectures, trade-offs, and practical examples.
Master-Slave Replication Pattern
In the Master-Slave pattern, one node acts as the master (or primary) that handles all write operations, while one or more slave (or secondary) nodes asynchronously replicate data from the master and serve read requests.
Characteristics:
- Writes are directed only to the master.
- Reads can be served by slaves, enabling read scalability.
- Slaves replicate data asynchronously or synchronously from the master.
- If the master fails, a failover mechanism promotes a slave to master.
Advantages:
- Simple to implement and reason about.
- Read scalability by distributing read load.
- Easier conflict management since writes are centralized.
Disadvantages:
- Master is a single point of failure unless failover is implemented.
- Potential replication lag causing stale reads on slaves.
- Write scalability limited by master capacity.
Mind Map: Master-Slave Replication
Example: Implementing Master-Slave Replication in PostgreSQL
PostgreSQL supports streaming replication where the master streams WAL (Write-Ahead Log) entries to slaves.
- Master handles all writes.
- Slaves continuously apply WAL entries asynchronously.
- Application directs reads to slaves and writes to master.
-- On master: Enable WAL archiving and configure replication user
-- On slave: Start replication and follow master WAL stream
Best Practice: Use synchronous replication if data consistency is critical, but be aware of increased write latency.
Multi-Master Replication Pattern
Multi-Master replication allows multiple nodes to accept write operations concurrently and replicate changes to each other.
Characteristics:
- Multiple nodes act as masters.
- Writes can occur on any master node.
- Conflict detection and resolution mechanisms are essential.
- Enables high availability and write scalability.
Advantages:
- No single point of failure for writes.
- Improved write throughput by distributing load.
- Better fault tolerance.
Disadvantages:
- Increased complexity in conflict resolution.
- Potential for data inconsistency if conflicts are not handled properly.
- Higher network overhead due to bi-directional replication.
Mind Map: Multi-Master Replication
Example: Multi-Master Replication with Apache Cassandra
Apache Cassandra uses a peer-to-peer architecture where all nodes are equal and can accept writes.
- Writes are sent to any node.
- Data is replicated asynchronously to other nodes based on replication factor.
- Tunable consistency levels allow balancing between availability and consistency.
- Conflicts resolved using timestamps (last write wins).
Example Scenario: A globally distributed user profile service where users can update their profiles from multiple regions simultaneously.
-- Define replication strategy
CREATE KEYSPACE user_profiles WITH replication = {
'class': 'NetworkTopologyStrategy',
'us-east': 3,
'eu-west': 3
};
Best Practice: Design conflict resolution carefully and choose appropriate consistency levels based on application needs.
Comparison Table
| Aspect | Master-Slave | Multi-Master |
|---|---|---|
| Write Scalability | Limited to master node | High, distributed across nodes |
| Read Scalability | High via slaves | High, all nodes serve reads |
| Complexity | Lower | Higher due to conflict handling |
| Fault Tolerance | Master failover needed | High, no single master |
| Data Consistency | Stronger (with sync replication) | Eventual, depends on conflict resolution |
Summary
- Use Master-Slave replication when write centralization and simpler conflict management are priorities.
- Use Multi-Master replication for high write availability and distributed write workloads, especially in geo-distributed environments.
- Always consider trade-offs between consistency, availability, and complexity.
- Implement robust monitoring and failover mechanisms to maintain system health.
Additional Resources
- PostgreSQL Streaming Replication Documentation
- Apache Cassandra Architecture
- Designing Data-Intensive Applications by Martin Kleppmann
4.3 Eventual Consistency and Conflict Resolution Strategies
Understanding Eventual Consistency
Eventual consistency is a consistency model used in distributed systems where updates to a data item will propagate to all replicas eventually, but not necessarily immediately. Unlike strong consistency, which requires all replicas to be synchronized before acknowledging a write, eventual consistency allows temporary divergence between replicas, improving availability and partition tolerance.
This model is particularly useful in large-scale, geo-distributed systems where network latency and partitions are common.
Key Concepts
- Convergence: All replicas will eventually become consistent if no new updates are made.
- Availability: System remains available for reads and writes even during partitions.
- Partition Tolerance: System continues to operate despite network failures.
Mind Map: Eventual Consistency Overview
Conflict Resolution Strategies
When replicas diverge, conflicts may occur. Resolving these conflicts is critical to maintaining data integrity.
Last Write Wins (LWW)
- Uses timestamps to determine the most recent update.
- Simple but can lead to lost updates if clocks are not synchronized.
Vector Clocks
- Each replica maintains a vector of counters representing causal history.
- Detects concurrent updates and helps in merging.
Operational Transformation (OT)
- Used in collaborative editing (e.g., Google Docs).
- Transforms operations to maintain consistency.
Conflict-free Replicated Data Types (CRDTs)
- Data structures designed to merge automatically without conflicts.
- Examples: G-Counter, PN-Counter, LWW-Element-Set.
Application-Level Resolution
- Custom logic defined by the application domain.
- Example: Merging shopping cart items by summing quantities.
Mind Map: Conflict Resolution Strategies
Practical Example: Shopping Cart with Eventual Consistency
Imagine a geo-distributed e-commerce platform where users can add items to their shopping cart from multiple devices.
- Each region maintains a replica of the user’s cart.
- Updates propagate asynchronously to other replicas.
Conflict Scenario:
- User adds 2 units of item A in region 1.
- User adds 3 units of item A in region 2 concurrently.
Resolution Using CRDT (PN-Counter):
- Each replica maintains a positive and negative counter per item.
- Additions increment the positive counter.
- Removals increment the negative counter.
- Final quantity = positive - negative.
This ensures that when replicas sync, the quantities merge correctly without losing any updates.
Code Snippet: Simple PN-Counter for Shopping Cart Item
class PNCounter:
def __init__(self):
self.positive = 0
self.negative = 0
def increment(self, count=1):
self.positive += count
def decrement(self, count=1):
self.negative += count
def value(self):
return self.positive - self.negative
def merge(self, other):
self.positive = max(self.positive, other.positive)
self.negative = max(self.negative, other.negative)
# Usage
cart_item_region1 = PNCounter()
cart_item_region2 = PNCounter()
cart_item_region1.increment(2) # User adds 2 units
cart_item_region2.increment(3) # User adds 3 units concurrently
# Merge replicas
cart_item_region1.merge(cart_item_region2)
print(f"Final quantity: {cart_item_region1.value()}") # Output: 5
Best Practices for Eventual Consistency
- Design for Idempotency: Ensure operations can be retried without side effects.
- Use Logical Clocks: Prefer vector clocks or Lamport timestamps over system clocks.
- Implement Monitoring: Detect and alert on conflict rates.
- Educate Users: Provide UI feedback when data is syncing or conflicts occur.
- Choose Appropriate Data Structures: Use CRDTs where automatic merging is feasible.
Summary
Eventual consistency enables highly available and partition-tolerant systems by relaxing immediate consistency guarantees. Effective conflict resolution strategies, such as CRDTs and vector clocks, are essential to maintain data integrity. By combining these patterns with thoughtful application design, engineers can build scalable, resilient distributed applications that gracefully handle network partitions and concurrent updates.
4.4 Practical Example: Designing a Geo-Distributed Database with Multi-Master Replication
Designing a geo-distributed database with multi-master replication is a complex but powerful approach to achieve both high availability and low latency for global applications. In this section, we will walk through the design considerations, patterns, and a practical example illustrating how to implement such a system.
Key Objectives
- High availability: System remains operational despite regional failures.
- Low latency: Local reads and writes to the nearest data center.
- Data consistency: Manage conflicts and ensure eventual consistency.
- Scalability: Support increasing load across regions.
Mind Map: Geo-Distributed Multi-Master Replication Design
Step 1: Choose the Database and Replication Model
For multi-master replication, databases like Cassandra, CockroachDB, Couchbase, or DynamoDB Global Tables are popular choices. They support writes in multiple regions and replicate data asynchronously or synchronously.
Example: Using Cassandra with NetworkTopologyStrategy for replication across multiple data centers.
Step 2: Define Data Partitioning and Replication Strategy
- Partitioning: Data is partitioned (sharded) by a key (e.g., user ID) to distribute load.
- Replication: Each partition is replicated to multiple nodes in different regions.
Example:
replication_strategy:
class: NetworkTopologyStrategy
us_east: 3
eu_west: 3
ap_southeast: 3
This means 3 replicas per region.
Step 3: Conflict Resolution
Since writes can happen concurrently in multiple regions, conflicts may arise.
Common strategies:
- Last Write Wins (LWW): Simplest, but may lose updates.
- Vector Clocks: Track causality to detect conflicts.
- Application-level Merging: Custom logic to merge conflicting data.
Example: Using vector clocks in a collaborative document editing app to merge changes.
Step 4: Consistency Model
- Eventual Consistency: Updates propagate asynchronously; replicas converge over time.
- Causal Consistency: Guarantees ordering of causally related updates.
Trade-off: Strong consistency reduces availability and increases latency.
Step 5: Handling Network Partitions and Failures
- Use gossip protocols for node membership and failure detection.
- Implement hinted handoff to temporarily store writes when nodes are down.
- Use read repair to fix inconsistencies during reads.
Practical Example: Multi-Region User Profile Service
Imagine a global social media platform where users update their profiles from any region.
Requirements:
- Users expect low latency profile updates.
- System must be highly available.
- Conflicts are rare but must be handled gracefully.
Design:
- Database: Cassandra cluster deployed in three regions: US East, EU West, AP Southeast.
- Replication: NetworkTopologyStrategy with 3 replicas per region.
- Writes: Allowed in any region (multi-master).
- Conflict Resolution: Last Write Wins using timestamps.
- Consistency: Eventual consistency with tunable consistency levels (e.g., QUORUM for reads/writes when possible).
Example Code Snippet (CQL):
CREATE KEYSPACE user_profiles WITH replication = {
'class': 'NetworkTopologyStrategy',
'us_east': 3,
'eu_west': 3,
'ap_southeast': 3
};
CREATE TABLE user_profiles.profiles (
user_id UUID PRIMARY KEY,
name text,
bio text,
last_updated timestamp
);
Write example:
from cassandra.cluster import Cluster
from datetime import datetime
cluster = Cluster(['us-east-db1.example.com'])
session = cluster.connect('user_profiles')
user_id = '123e4567-e89b-12d3-a456-426614174000'
name = 'Alice'
bio = 'Loves hiking and photography.'
last_updated = datetime.utcnow()
session.execute(
"""
INSERT INTO profiles (user_id, name, bio, last_updated)
VALUES (%s, %s, %s, %s)
""",
(user_id, name, bio, last_updated)
)
Read example with QUORUM consistency:
from cassandra import ConsistencyLevel
rows = session.execute(
"SELECT * FROM profiles WHERE user_id=%s",
(user_id,),
consistency_level=ConsistencyLevel.QUORUM
)
for row in rows:
print(row.name, row.bio)
Mind Map: Conflict Resolution Flow
Best Practices
- Use tunable consistency: Adjust consistency levels per operation to balance latency and correctness.
- Monitor replication lag: Detect delays that could cause stale reads.
- Implement conflict resolution suited to your domain: For example, merging shopping cart items vs. overwriting profile info.
- Test failure scenarios: Simulate network partitions and node failures.
Summary
Designing a geo-distributed database with multi-master replication involves balancing availability, latency, and consistency. By choosing the right database technology, replication strategy, and conflict resolution method, you can build a system that serves global users efficiently and reliably.
This practical example with Cassandra illustrates how to configure replication, handle conflicts, and tune consistency to meet application needs.
4.5 Best Practices for Data Backup, Snapshots, and Disaster Recovery
Ensuring data durability and quick recovery in the event of failures is a cornerstone of designing highly available and scalable systems. This section explores best practices around data backup, snapshot management, and disaster recovery (DR) strategies, woven with practical examples and mind maps to clarify concepts.
Key Concepts Mind Map
Establishing a Robust Backup Strategy
- Full Backups: Complete copy of data at a point in time. Ideal for initial backups but costly in storage and time.
- Incremental Backups: Only data changed since last backup is saved. Efficient but requires all increments for restore.
- Differential Backups: Data changed since last full backup. Balances restore speed and storage.
Example:
A SaaS application storing user documents performs a weekly full backup every Sunday night and incremental backups every 6 hours. This approach minimizes storage costs while ensuring data can be restored to within 6 hours of any failure.
Leveraging Snapshots for Fast Recovery
Snapshots capture the state of a system or volume at a specific time, often near-instantaneous and storage-efficient.
- Crash-Consistent Snapshots: Captures data as-is, without application coordination. Fast but may cause data inconsistency.
- Application-Consistent Snapshots: Coordinates with applications (e.g., via VSS on Windows or fsfreeze on Linux) to ensure data integrity.
Example:
In a distributed database cluster, application-consistent snapshots are scheduled during low-traffic periods to ensure backups do not corrupt ongoing transactions. Snapshots are retained for 30 days and replicated to a secondary region.
Defining Recovery Objectives
- RPO (Recovery Point Objective): Maximum acceptable data loss measured in time.
- RTO (Recovery Time Objective): Maximum acceptable downtime.
These objectives guide backup frequency, snapshot intervals, and DR plan complexity.
Example:
An online payment gateway requires an RPO of 5 minutes and RTO of 15 minutes. To meet this, continuous data replication combined with automated failover and frequent snapshots are implemented.
Disaster Recovery Planning and Execution
-
Failover Models:
- Active-Passive: Secondary site is idle until failover.
- Active-Active: Both sites serve traffic, providing load balancing and redundancy.
-
Testing DR Plans: Regular drills validate recovery procedures and uncover gaps.
-
Automation: Use Infrastructure as Code (IaC) and orchestration tools to automate failover and recovery.
Example:
A financial services company uses an active-active multi-region deployment with automated DNS failover. DR drills are conducted quarterly, simulating region outages to verify recovery within RTO.
Mind Map: Disaster Recovery Workflow
Additional Best Practices
- Offsite and Immutable Backups: Store backups in geographically separate locations and use immutable storage to prevent tampering.
- Backup Encryption: Protect backup data both at rest and in transit.
- Retention Policies: Define how long backups and snapshots are kept to balance compliance and cost.
- Versioning: Maintain multiple backup versions to protect against corruption or ransomware.
Example:
A healthcare system encrypts backups using customer-specific keys and stores them in a WORM (Write Once Read Many) compliant cloud storage bucket, ensuring regulatory compliance and protection against ransomware.
Summary
A comprehensive backup and disaster recovery strategy is essential for high availability and scalability. By combining frequent backups, consistent snapshots, clear recovery objectives, and automated DR workflows, systems can achieve resilience against data loss and downtime.
For further reading, consider exploring tools like Velero for Kubernetes backups, AWS Backup for cloud-native services, and disaster recovery frameworks such as AWS Elastic Disaster Recovery or Azure Site Recovery.
5. Caching Strategies to Enhance Performance and Availability
5.1 Cache Aside, Read-Through, and Write-Through Patterns Explained
In high availability and scalable applications, caching is a critical technique to reduce latency and offload backend systems. Understanding different caching patterns helps engineers choose the right approach based on consistency, complexity, and performance requirements. This section explains three fundamental caching patterns: Cache Aside, Read-Through, and Write-Through, with detailed examples and mind maps to visualize their workflows.
Cache Aside Pattern
Overview: Cache Aside, also known as Lazy Loading, is a pattern where the application code is responsible for loading data into the cache on-demand. The cache is treated as a side store, and the application first checks the cache before querying the database.
Workflow:
Key Characteristics:
- Cache is populated only when data is requested and not found.
- Application controls cache invalidation and updates.
- Suitable for read-heavy workloads with relatively infrequent writes.
Example:
# Python example of Cache Aside
cache = {}
def get_user(user_id):
if user_id in cache:
print("Cache hit")
return cache[user_id]
else:
print("Cache miss")
user = query_database(user_id) # Simulate DB call
cache[user_id] = user
return user
def query_database(user_id):
# Simulate database fetch
return {"id": user_id, "name": "User" + str(user_id)}
# Usage
user = get_user(1)
user = get_user(1) # This time cache hit
Best Practices:
- Implement cache expiration to avoid stale data.
- Handle cache invalidation carefully on data updates.
- Use this pattern when cache misses are acceptable and eventual consistency suffices.
Read-Through Pattern
Overview: In the Read-Through pattern, the cache itself is responsible for loading data from the database when a cache miss occurs. The application interacts only with the cache layer, which abstracts the data source.
Workflow:
Key Characteristics:
- Simplifies application code by delegating loading logic to the cache.
- Cache acts as a facade over the data store.
- Often implemented in caching solutions like Redis with modules or custom middleware.
Example:
class ReadThroughCache:
def __init__(self):
self.cache = {}
def get(self, key):
if key in self.cache:
print("Cache hit")
return self.cache[key]
else:
print("Cache miss - loading from DB")
value = self.load_from_db(key)
self.cache[key] = value
return value
def load_from_db(self, key):
# Simulate DB fetch
return f"Value_for_{key}"
cache = ReadThroughCache()
print(cache.get('item1')) # Cache miss
print(cache.get('item1')) # Cache hit
Best Practices:
- Use when you want to centralize caching logic.
- Ensure cache loading logic handles DB failures gracefully.
- Combine with TTLs and eviction policies.
Write-Through Pattern
Overview: Write-Through caching ensures that writes go through the cache and are synchronously written to the underlying data store. This guarantees cache and database consistency at the cost of write latency.
Workflow:
Key Characteristics:
- Simplifies consistency since cache and DB are always in sync.
- Write latency is higher due to synchronous DB writes.
- Suitable for systems where strong consistency is critical.
Example:
class WriteThroughCache:
def __init__(self):
self.cache = {}
self.database = {}
def write(self, key, value):
print(f"Writing {key} to cache and DB")
self.cache[key] = value
self.write_to_db(key, value)
def write_to_db(self, key, value):
# Simulate DB write
self.database[key] = value
def read(self, key):
return self.cache.get(key, None)
cache = WriteThroughCache()
cache.write('item1', 'value1')
print(cache.read('item1')) # Should print 'value1'
print(cache.database) # DB also has the value
Best Practices:
- Use when data correctness is paramount.
- Monitor write latency and optimize DB performance.
- Consider write-back or asynchronous alternatives if write latency is a bottleneck.
Summary Mind Map
By understanding these caching patterns, senior engineers and technical leads can design systems that balance performance, consistency, and complexity according to their application’s unique needs.
5.2 Distributed Caching: Techniques and Tools
Distributed caching is a critical technique for improving application performance and scalability by storing frequently accessed data closer to the application layer, reducing latency and load on primary data stores. This section explores the core techniques, popular tools, and practical examples to help you design and implement effective distributed caching solutions.
What is Distributed Caching?
Distributed caching involves spreading cached data across multiple nodes or servers, enabling horizontal scalability, fault tolerance, and high availability. Unlike local caches that reside on a single machine, distributed caches allow multiple application instances to share cached data consistently.
Why Use Distributed Caching?
- Scalability: Cache capacity grows with the number of nodes.
- Fault Tolerance: Data is replicated or partitioned to avoid single points of failure.
- Performance: Reduces latency by serving data from cache rather than hitting slower databases.
- Consistency: Enables shared state across distributed application instances.
Core Distributed Caching Techniques
Partitioning (Sharding)
Partitioning divides the cache dataset across multiple nodes to distribute load and increase capacity.
- Consistent Hashing: Maps keys to nodes in a way that minimizes reorganization when nodes are added or removed.
- Range-Based Partitioning: Assigns key ranges to nodes, simpler but less flexible.
Replication
Replication ensures data availability and fault tolerance by copying data across nodes.
- Master-Slave: One master node handles writes; slaves replicate data for reads.
- Peer-to-Peer: All nodes are equal and replicate data among themselves.
Eviction Policies
To manage limited cache memory, eviction policies decide which data to remove.
- LRU: Removes least recently accessed items.
- LFU: Removes least frequently accessed items.
- TTL: Removes items after a set expiration time.
Cache Coherency Patterns
Ensures cache and underlying data store remain consistent.
- Write-Through: Writes go to cache and backing store synchronously.
- Write-Behind: Writes go to cache first and asynchronously to backing store.
- Cache Aside: Application manages cache population and invalidation.
Data Serialization
Efficient serialization formats reduce network overhead and improve performance.
- JSON is human-readable but larger.
- Protocol Buffers and Avro are compact and faster.
Popular Distributed Caching Tools
Redis
- In-memory data structure store supporting strings, hashes, lists, sets.
- Supports clustering and replication.
- Persistence options for durability.
- Pub/Sub messaging for cache invalidation.
Memcached
- Simple, high-performance key-value store.
- No persistence; purely in-memory.
- Easy to deploy and scale.
Hazelcast
- In-memory data grid supporting distributed caching and computing.
- Near cache feature stores frequently accessed data locally.
Apache Ignite
- Distributed in-memory computing platform.
- Supports SQL queries and ACID transactions.
Couchbase
- Combines caching and NoSQL database.
- Supports multi-dimensional scaling and cross data center replication.
Example: Implementing Distributed Cache with Redis Cluster
import redis
# Connect to Redis Cluster
cluster_nodes = [
{'host': 'redis-node1', 'port': 7000},
{'host': 'redis-node2', 'port': 7001},
{'host': 'redis-node3', 'port': 7002}
]
client = redis.RedisCluster(startup_nodes=cluster_nodes, decode_responses=True)
# Cache Aside Pattern Example
def get_user_profile(user_id):
cache_key = f'user:profile:{user_id}'
profile = client.get(cache_key)
if profile:
print('Cache hit')
return profile
else:
print('Cache miss, fetching from DB')
profile = fetch_user_profile_from_db(user_id) # Assume this fetches from DB
client.set(cache_key, profile, ex=3600) # Cache with 1 hour TTL
return profile
# Usage
user_profile = get_user_profile('12345')
This example demonstrates the cache-aside pattern using Redis Cluster. When the profile is not found in cache (cache miss), it fetches from the database and populates the cache with an expiration time.
Best Practices
- Choose the right eviction policy based on your workload characteristics.
- Use consistent hashing to minimize cache rebalancing during scaling.
- Implement cache warming strategies to pre-populate cache after restarts.
- Monitor cache hit/miss ratios to tune cache size and policies.
- Design for eventual consistency when using asynchronous replication.
- Secure your cache cluster with authentication, encryption, and network isolation.
Summary
Distributed caching is a cornerstone for building high-performance, scalable applications. By understanding partitioning, replication, eviction, and coherency techniques, and leveraging mature tools like Redis and Hazelcast, engineers can significantly reduce latency and improve fault tolerance. Practical implementation patterns such as cache-aside empower developers to maintain cache consistency while optimizing resource usage.
5.3 Handling Cache Invalidation and Stale Data Challenges
Cache invalidation and stale data are among the most critical challenges when implementing caching strategies in scalable systems. Improper handling can lead to inconsistent user experiences, data corruption, or outdated information being served, which can degrade system reliability and trustworthiness.
Understanding Cache Invalidation
Cache invalidation is the process of removing or updating cached data when the underlying source data changes. Since caches are copies of data, they can become stale if not synchronized properly.
Common Cache Invalidation Strategies:
- Time-Based Expiration (TTL): Cached data is automatically invalidated after a predefined time-to-live.
- Explicit Invalidation: Application logic triggers cache removal or update when data changes.
- Write-Through / Write-Behind Caches: Cache updates happen synchronously or asynchronously with the data store.
Mind Map: Cache Invalidation Strategies
Handling Stale Data Challenges
Stale data occurs when the cache serves outdated information. This can happen due to delayed invalidation, replication lag, or eventual consistency models.
Techniques to Mitigate Stale Data:
- Cache Versioning / Tags: Associate versions or tags with cached entries to detect outdated data.
- Read-Through Cache with Validation: Validate cache freshness on read, possibly falling back to the source.
- Hybrid Approaches: Combine TTL with explicit invalidation to balance freshness and performance.
- Cache Stampede Prevention: Use locking or request coalescing to avoid thundering herd problems when cache expires.
Mind Map: Stale Data Mitigation Techniques
Practical Example: Implementing Cache Invalidation in a Product Catalog Service
Imagine a scalable e-commerce platform with a product catalog service that caches product details to reduce database load and improve response times.
Scenario:
- Product details are cached with a TTL of 10 minutes.
- When product information is updated (e.g., price change), the cache must be invalidated immediately to avoid showing stale prices.
Implementation Steps:
-
Time-Based Expiration: Set a TTL of 10 minutes on cached product entries to ensure periodic refresh.
-
Explicit Invalidation: When an update occurs:
- The product service publishes an event (e.g., via a message queue) indicating the product ID has changed.
- A cache invalidation service listens to these events and deletes the corresponding cache entry.
-
Cache Stampede Prevention: When cache expires or is invalidated, multiple requests for the same product might hit the database simultaneously. To prevent this:
- Use a distributed lock (e.g., Redis Redlock) to allow only one request to rebuild the cache.
- Other requests wait or serve stale data with a warning.
Code Snippet (Pseudo-code):
# On product update
def update_product(product_id, new_data):
database.update(product_id, new_data)
message_queue.publish('product_updated', product_id)
# Cache invalidation listener
def on_product_updated(event):
product_id = event.data
cache.delete(f'product:{product_id}')
# Cache read with stampede prevention
def get_product(product_id):
cached = cache.get(f'product:{product_id}')
if cached:
return cached
else:
with distributed_lock(f'lock:product:{product_id}'):
# Double check cache after acquiring lock
cached = cache.get(f'product:{product_id}')
if cached:
return cached
product = database.get(product_id)
cache.set(f'product:{product_id}', product, ttl=600)
return product
Best Practices Summary
- Combine TTL with explicit invalidation to balance performance and freshness.
- Use event-driven cache invalidation for real-time updates.
- Implement cache stampede prevention to avoid database overload.
- Monitor cache hit/miss ratios and stale data incidents.
- Design your cache keys and versioning carefully to enable selective invalidation.
By thoughtfully handling cache invalidation and stale data, systems can maintain high availability and responsiveness without sacrificing data correctness or user experience.
5.4 Example: Implementing a Multi-Level Cache in a Scalable Web Application
In this section, we explore a practical example of implementing a multi-level caching strategy to improve performance and availability in a scalable web application. Multi-level caching involves using multiple cache layers, each with different characteristics, to optimize data retrieval times and reduce load on backend systems.
Why Multi-Level Caching?
- Reduce Latency: Serve data faster by using caches closer to the user.
- Lower Backend Load: Minimize expensive database or API calls.
- Improve Availability: Cache layers can serve data even if backend is temporarily unavailable.
Typical Multi-Level Cache Architecture
Step 1: Define Cache Layers and Responsibilities
| Cache Level | Location | Technology | Purpose | TTL (Time to Live) |
|---|---|---|---|---|
| L1 | Application Server | In-memory | Ultra-fast access for hot data | Seconds to minutes |
| L2 | Distributed Cache | Redis Cluster | Shared cache for session & data | Minutes to hours |
| L3 | CDN / Disk Cache | CDN / Disk | Long-lived static content cache | Hours to days |
Step 2: Example Scenario
Imagine a scalable e-commerce web application that displays product details. The product data is stored in a database, but to reduce latency and database load, we implement a multi-level cache:
- L1 Cache: Local in-memory cache on each web server for the most frequently accessed products.
- L2 Cache: Redis cluster shared among all web servers.
- L3 Cache: CDN caching static product images and descriptions.
Step 3: Cache Access Flow
Step 4: Code Example (Simplified Node.js)
const L1Cache = new Map(); // Simple in-memory cache
const redis = require('redis');
const redisClient = redis.createClient();
async function getProduct(productId) {
// Check L1 Cache
if (L1Cache.has(productId)) {
console.log('L1 cache hit');
return L1Cache.get(productId);
}
// Check L2 Cache (Redis)
const l2Data = await redisClient.get(productId);
if (l2Data) {
console.log('L2 cache hit');
const product = JSON.parse(l2Data);
// Update L1 Cache
L1Cache.set(productId, product);
return product;
}
// Cache miss: fetch from DB
console.log('Cache miss: fetching from DB');
const product = await fetchProductFromDB(productId); // Assume this function exists
// Update caches
L1Cache.set(productId, product);
redisClient.setex(productId, 3600, JSON.stringify(product)); // TTL 1 hour
return product;
}
Step 5: Cache Invalidation Strategies
- Time-Based Expiry: Use TTLs to automatically expire cache entries.
- Write-Through Cache: Update cache immediately on data changes.
- Cache Aside: Application explicitly invalidates or updates cache after DB writes.
Example mind map for invalidation:
Step 6: Best Practices
- Keep L1 cache small and fast: Avoid memory bloat on app servers.
- Use distributed cache for shared state: Enables consistency across multiple instances.
- Leverage CDN for static content: Offload bandwidth and improve global availability.
- Monitor cache hit ratios: Use metrics to tune TTLs and cache sizes.
- Handle cache stampede: Use locking or request coalescing to prevent thundering herd.
Summary
By implementing a multi-level caching strategy, the web application achieves:
- Reduced latency through fast local caches.
- Improved scalability by sharing cache state across instances.
- Enhanced availability by serving cached data during backend outages.
This approach balances speed, consistency, and resource utilization effectively for scalable web applications.
5.5 Best Practices for Cache Monitoring and Auto-Scaling
Effective cache monitoring and auto-scaling are critical to maintaining performance, availability, and cost-efficiency in scalable applications. This section explores best practices, supported by mind maps and practical examples, to help you design resilient caching layers that adapt dynamically to workload changes.
Cache Monitoring Best Practices
Monitoring your cache system enables proactive detection of performance bottlenecks, cache misses, and resource saturation. Here are key metrics and strategies:
Key Metrics to Monitor
- Cache Hit Ratio: Percentage of requests served from cache vs total requests.
- Eviction Rate: Frequency at which cached items are removed due to capacity limits.
- Latency: Time taken to retrieve data from cache.
- Memory Usage: Amount of memory consumed by the cache.
- CPU Utilization: Processing load on cache nodes.
- Error Rate: Number of failed cache operations.
Monitoring Strategies
- Real-time Dashboards: Use tools like Grafana or Kibana to visualize cache metrics.
- Alerting: Set thresholds for critical metrics (e.g., hit ratio below 80%) to trigger alerts.
- Logging: Enable detailed logs for cache operations to troubleshoot issues.
- Health Checks: Periodic probes to verify cache node responsiveness.
Mind Map: Cache Monitoring Components
Cache Auto-Scaling Best Practices
Auto-scaling your cache layer ensures it can handle varying workloads without manual intervention, improving availability and cost efficiency.
Scaling Triggers
- Memory Thresholds: Scale out when memory usage exceeds a set percentage (e.g., 75%).
- CPU Load: Scale based on CPU utilization spikes.
- Request Rate: Increase cache nodes when incoming request rate rises.
- Eviction Rate: High eviction rates may indicate insufficient cache capacity.
Scaling Approaches
- Horizontal Scaling: Add or remove cache nodes dynamically (e.g., adding Redis cluster shards).
- Vertical Scaling: Increase resources (CPU, memory) of existing cache nodes.
- Hybrid Scaling: Combine horizontal and vertical scaling for fine-grained control.
Mind Map: Cache Auto-Scaling Workflow
Practical Example: Auto-Scaling Redis Cache Cluster on Kubernetes
Scenario: A web application uses a Redis cluster deployed on Kubernetes to cache session data. Traffic fluctuates significantly during the day.
Implementation Steps:
- Metrics Collection: Use Prometheus to scrape Redis exporter metrics, including memory usage, CPU, and cache hit ratio.
- Thresholds Setup: Configure Horizontal Pod Autoscaler (HPA) to scale Redis pods when memory usage exceeds 70% or CPU usage exceeds 60%.
- Scaling Policy: Define minimum and maximum pod counts (e.g., min 3, max 10).
- Cooldown Period: Set a cooldown period of 5 minutes to avoid rapid scaling oscillations.
- Alerting: Integrate alerts for cache hit ratio drops below 85% to investigate cache effectiveness.
Outcome: The Redis cluster scales out during peak traffic, maintaining low latency and high availability, and scales in during off-peak hours to save costs.
Additional Tips
- Cache Warm-up: After scaling out, pre-populate cache to avoid cold start latency.
- Graceful Scaling: Use rolling updates and draining to prevent cache unavailability during scaling.
- Capacity Planning: Combine auto-scaling with capacity planning to handle unexpected spikes.
- Testing: Regularly test scaling policies under simulated loads.
Summary Mind Map: Integrating Monitoring and Auto-Scaling
By implementing these best practices for cache monitoring and auto-scaling, senior engineers and technical leads can ensure their caching layers remain performant, resilient, and cost-effective even under dynamic workloads.
6. Messaging and Event-Driven Architectures for Resilience
6.1 Message Queues vs Event Streams: Choosing the Right Tool
Designing resilient, scalable, and decoupled systems often involves asynchronous communication patterns. Two foundational patterns in this space are Message Queues and Event Streams. Understanding their differences, use cases, and trade-offs is critical for senior engineers and technical leads aiming to build high availability and scalable applications.
What Are Message Queues?
Message Queues are communication mechanisms where messages are stored in a queue and consumed by one or more consumers. They typically follow a point-to-point communication model.
- Messages are sent to a queue.
- Consumers receive and process messages, usually removing them from the queue.
- Guarantees like at-least-once or exactly-once delivery can be configured.
Common Use Cases: Task distribution, workload balancing, asynchronous processing, and decoupling tightly coupled services.
What Are Event Streams?
Event Streams represent a continuous, append-only log of events that multiple consumers can subscribe to independently. They follow a publish-subscribe model.
- Events are appended to a stream (log).
- Consumers read events independently at their own pace.
- Events are immutable and retained for a configurable period.
Common Use Cases: Event sourcing, audit logs, real-time analytics, and data integration pipelines.
Mind Map: Key Characteristics Comparison
Mind Map: Choosing Between Message Queues and Event Streams
Detailed Comparison Table
| Aspect | Message Queues | Event Streams |
|---|---|---|
| Communication Model | Point-to-Point | Publish-Subscribe |
| Message Retention | Messages removed after consumption | Events retained for configurable duration |
| Consumer Model | One consumer per message (usually) | Multiple consumers read independently |
| Ordering Guarantee | Usually per queue | Ordering per partition or topic |
| Delivery Semantics | At-least-once, Exactly-once (varies) | At-least-once, with replay capabilities |
| Use Cases | Task queues, async processing | Event sourcing, analytics, audit logs |
Example 1: Message Queue Use Case
Scenario: A payment processing system where each payment request must be processed exactly once.
- Payments are enqueued in a message queue (e.g., RabbitMQ, AWS SQS).
- Worker services consume payment messages, process them, and acknowledge.
- If a worker fails, the message remains in the queue for retry.
Benefits: Ensures reliable, ordered, and load-balanced processing of payment tasks.
Example 2: Event Stream Use Case
Scenario: An e-commerce platform tracking user activity for real-time analytics and personalized recommendations.
- User actions (page views, clicks) are published as events to an event stream (e.g., Apache Kafka).
- Multiple consumers subscribe:
- Analytics service consumes events to update dashboards.
- Recommendation engine consumes events to update user profiles.
- Audit service stores events for compliance.
Benefits: Multiple independent consumers can process the same data without interfering with each other. Events can be replayed to rebuild state or recover from failures.
Practical Considerations
- Latency: Message queues often have lower latency for task dispatching.
- Scalability: Event streams scale well for high-throughput, multi-consumer scenarios.
- Complexity: Event streams require more infrastructure and operational expertise.
- Data Retention: Event streams enable long-term storage and replay; message queues typically do not.
Summary
Choosing between message queues and event streams depends on your system’s requirements around message durability, consumer patterns, replayability, and complexity. For task-oriented, single-consumer workflows, message queues are often simpler and more efficient. For event-driven, multi-consumer architectures requiring auditability and replay, event streams are the preferred choice.
Additional Resources
- RabbitMQ Official Documentation
- Apache Kafka Documentation
- Martin Kleppmann’s book Designing Data-Intensive Applications (Chapter on Messaging and Streams)
By mastering the distinctions and appropriate applications of message queues and event streams, technical leads can architect systems that are both highly available and scalable, tailored to their unique business needs.
6.2 Publish-Subscribe Pattern for Decoupling Components
The Publish-Subscribe (Pub/Sub) pattern is a powerful architectural design that facilitates asynchronous communication between components by decoupling the message producers (publishers) from the message consumers (subscribers). This pattern is especially valuable in building scalable, loosely coupled, and highly available systems.
What is the Publish-Subscribe Pattern?
In the Pub/Sub model, publishers emit messages to a topic or channel without knowledge of who will consume them. Subscribers express interest in one or more topics and receive messages asynchronously when they are published.
This decoupling allows components to evolve independently, scale separately, and improves system resilience.
Key Characteristics
- Asynchronous Communication: Publishers and subscribers operate independently.
- Loose Coupling: Publishers do not need to know about subscribers.
- Scalability: Multiple subscribers can consume messages concurrently.
- Flexibility: Easy to add or remove subscribers without impacting publishers.
Mind Map: Core Concepts of Publish-Subscribe Pattern
How It Works: Step-by-Step
- Publisher sends a message to a topic on the message broker.
- Message Broker receives the message and routes it to all subscribers registered for that topic.
- Subscribers receive the message asynchronously and process it.
This flow ensures that publishers and subscribers do not depend on each other’s availability or implementation.
Example: Building a Notification System
Imagine an e-commerce platform where various services need to notify users about order status updates, promotions, and system alerts.
- Publishers: Order Service, Marketing Service, System Monitor
- Subscribers: Email Service, SMS Service, Push Notification Service
Flow:
- Order Service publishes “Order Shipped” events to the
order-statustopic. - Marketing Service publishes promotional messages to the
promotionstopic. - System Monitor publishes alerts to the
system-alertstopic.
Subscribers listen to their respective topics and send notifications accordingly.
Mind Map: Notification System Using Pub/Sub
Practical Implementation Example: Using Apache Kafka
// Publisher (Producer) Example in Java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
String topic = "order-status";
String message = "Order #1234 Shipped";
producer.send(new ProducerRecord<>(topic, message));
producer.close();
// Subscriber (Consumer) Example in Java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "email-service-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-status", "promotions", "system-alerts"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: %s from topic: %s\n", record.value(), record.topic());
// Process message (e.g., send email)
}
}
Best Practices
- Design Topics Thoughtfully: Use meaningful topic names and organize by business domain.
- Idempotency: Ensure subscribers can handle duplicate messages gracefully.
- Message Ordering: Use partitions or sequence numbers if ordering matters.
- Backpressure Handling: Implement buffering or throttling to handle spikes.
- Monitoring: Track message lag and broker health.
When to Use Publish-Subscribe Pattern
- When you need to decouple components to improve maintainability.
- When multiple consumers need to react to the same event.
- For event-driven and real-time processing systems.
- When scaling consumers independently from producers is required.
Summary
The Publish-Subscribe pattern is a cornerstone for building scalable, resilient, and loosely coupled systems. By abstracting communication through topics and brokers, it empowers teams to build flexible architectures that can evolve without tight dependencies.
Leveraging this pattern with robust message brokers like Kafka, RabbitMQ, or cloud-native services (AWS SNS, Google Pub/Sub) enables high availability and fault tolerance in distributed systems.
6.3 Event Sourcing and CQRS for Scalable and Auditable Systems
Event Sourcing and Command Query Responsibility Segregation (CQRS) are powerful architectural patterns that help build scalable, auditable, and maintainable systems. They are often used together to separate the concerns of command processing (writes) and query handling (reads), while ensuring a reliable audit trail of all state changes.
What is Event Sourcing?
Event Sourcing is a pattern where state changes are stored as a sequence of immutable events rather than just storing the current state. Instead of persisting the latest snapshot of data, every change to the application state is captured as an event and appended to an event store.
Key Benefits:
- Complete audit trail of all changes
- Ability to reconstruct past states by replaying events
- Facilitates temporal queries and debugging
- Enables event-driven integrations
Example: Consider a banking application where instead of storing the current account balance, every deposit and withdrawal is stored as an event:
- Event: AccountCreated { accountId: 123, owner: “Alice” }
- Event: MoneyDeposited { accountId: 123, amount: 1000 }
- Event: MoneyWithdrawn { accountId: 123, amount: 200 }
The current balance can be derived by replaying these events.
What is CQRS?
CQRS stands for Command Query Responsibility Segregation. It separates the system into two parts:
- Command Side: Handles commands that change state (writes).
- Query Side: Handles queries that read state.
This separation allows optimizing read and write models independently, improving scalability and performance.
Example: In an e-commerce system:
- Commands: PlaceOrder, CancelOrder, UpdateOrder
- Queries: GetOrderDetails, ListOrdersByCustomer
The write model might be normalized and transactional, while the read model can be denormalized for fast querying.
How Event Sourcing and CQRS Work Together
- Commands generate events that are stored in the event store (Event Sourcing).
- The event store acts as the source of truth.
- Events are asynchronously projected into read models optimized for queries (CQRS).
This architecture enables:
- Scalability by scaling read and write sides independently.
- Auditability by storing all events.
- Flexibility to add new read models without changing the write model.
Mind Map: Event Sourcing and CQRS Overview
Practical Example: Building an Order Management System
Scenario:
A system where users can place orders, update order status, and query order details.
Step 1: Define Events
[
{ "type": "OrderPlaced", "data": { "orderId": "123", "customerId": "C001", "items": [{ "productId": "P100", "quantity": 2 }] } },
{ "type": "OrderStatusUpdated", "data": { "orderId": "123", "status": "Shipped" } }
]
Step 2: Command Handling (Write Model)
- Receive command
PlaceOrder - Validate business rules (e.g., product availability)
- Generate
OrderPlacedevent - Append event to event store
Step 3: Event Store
- Append-only log of events
- Durable and ordered
Step 4: Projections (Read Model)
- Listen to events asynchronously
- Update denormalized views (e.g., orders by customer, order status summary)
- Serve queries from optimized read database
Step 5: Query Handling
- Queries like
GetOrderDetailsread from the projection
Mind Map: Order Management System with Event Sourcing & CQRS
Best Practices
- Event Versioning: Plan for schema evolution of events to maintain backward compatibility.
- Idempotency: Ensure event handlers and command processors are idempotent to handle retries safely.
- Eventual Consistency: Design the system to tolerate eventual consistency between command and query sides.
- Snapshotting: Use snapshots to optimize event replay for large event streams.
- Monitoring: Track event processing lag and failures.
Summary
Event Sourcing combined with CQRS offers a robust approach to building scalable, auditable systems by separating write and read concerns and persisting all state changes as immutable events. While it introduces complexity, the benefits in traceability, flexibility, and scalability make it a compelling choice for complex domains such as finance, e-commerce, and logistics.
6.4 Example: Building an Event-Driven Order Processing System with Retry and Dead Letter Queues
In this section, we will explore how to design and implement an event-driven order processing system that leverages retry mechanisms and dead letter queues (DLQs) to ensure resilience, fault tolerance, and high availability.
Overview
An event-driven architecture decouples components by communicating through asynchronous events. For an order processing system, this means that when an order is placed, an event is emitted and various services (e.g., payment, inventory, shipping) react to this event independently.
However, failures can occur during event processing due to transient issues (e.g., network glitches, temporary service downtime). To handle such failures gracefully, retry mechanisms and dead letter queues are essential.
Key Components
Step 1: Emitting and Consuming Events
- Order Service emits an
OrderPlacedevent when a customer places an order. - Payment Service consumes
OrderPlaced, processes payment, and emitsPaymentProcessedorPaymentFailed. - Downstream services react similarly.
Example event (JSON):
{
"eventType": "OrderPlaced",
"orderId": "12345",
"customerId": "98765",
"items": [
{"productId": "A1", "quantity": 2},
{"productId": "B7", "quantity": 1}
],
"timestamp": "2024-06-01T12:00:00Z"
}
Step 2: Implementing Retry Logic
Retries help recover from transient failures. Key considerations:
- Retry count limit: Avoid infinite retries.
- Backoff strategy: Exponential backoff reduces load during outages.
- Idempotency: Ensure event handlers can safely process the same event multiple times.
Example pseudocode for retry with exponential backoff:
import time
import random
def process_event(event):
max_retries = 5
base_delay = 1 # seconds
for attempt in range(1, max_retries + 1):
try:
# Process the event
handle_event(event)
return True
except TransientError as e:
delay = base_delay * (2 ** (attempt - 1)) + random.uniform(0, 0.5)
print(f"Attempt {attempt} failed, retrying in {delay:.2f} seconds")
time.sleep(delay)
# After max retries, send to DLQ
send_to_dead_letter_queue(event)
return False
Step 3: Dead Letter Queue (DLQ) Usage
A DLQ is a special queue that stores events that failed processing after all retry attempts.
Benefits:
- Prevents blocking the main event stream.
- Enables offline analysis and manual intervention.
- Can trigger alerts or automated remediation.
Example DLQ message schema:
{
"originalEvent": { /* original event data */ },
"errorMessage": "Payment service timeout",
"failedAt": "2024-06-01T12:05:00Z",
"retryCount": 5
}
Step 4: Putting It All Together
Step 5: Example with AWS SQS and Lambda
- Use SQS as the event queue.
- Configure Lambda functions as event consumers.
- Enable Lambda’s built-in retry and configure a DLQ (another SQS queue).
Example AWS Lambda configuration snippet (in CloudFormation YAML):
Resources:
OrderPlacedQueue:
Type: AWS::SQS::Queue
OrderProcessingFunction:
Type: AWS::Lambda::Function
Properties:
Handler: index.handler
Runtime: python3.9
Environment:
Variables:
DLQ_URL: !Ref OrderDLQ
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt OrderPlacedQueue.Arn
OrderDLQ:
Type: AWS::SQS::Queue
LambdaEventSourceMapping:
Type: AWS::Lambda::EventSourceMapping
Properties:
EventSourceArn: !GetAtt OrderPlacedQueue.Arn
FunctionName: !Ref OrderProcessingFunction
BatchSize: 10
MaximumRetryAttempts: 3
DestinationConfig:
OnFailure:
Destination: !GetAtt OrderDLQ.Arn
Best Practices Summary
- Idempotency: Design event handlers to safely reprocess events.
- Backoff and jitter: Use exponential backoff with random jitter to avoid thundering herd problems.
- Monitoring: Track retry counts and DLQ metrics to detect systemic issues.
- Alerting: Set up alerts on DLQ message accumulation.
- Dead Letter Processing: Implement automated or manual workflows to handle DLQ messages.
This example demonstrates how retry and dead letter queues can be integrated seamlessly into an event-driven order processing system to improve reliability and fault tolerance, ensuring that transient failures do not cause data loss or system downtime.
6.5 Best Practices for Idempotency and Message Ordering
Designing robust messaging systems requires careful handling of idempotency and message ordering to ensure data consistency, prevent duplication, and maintain system reliability. This section dives deep into best practices, supported by mind maps and practical examples.
Understanding Idempotency in Messaging
Idempotency means that processing the same message multiple times has the same effect as processing it once. This is critical in distributed systems where retries and duplicates are common.
Key Concepts:
- Idempotent Operations: Operations that can be safely repeated without changing the result beyond the initial application.
- Idempotency Keys: Unique identifiers attached to messages or requests to detect duplicates.
- Stateful vs Stateless Idempotency: Whether the system keeps track of processed messages or relies on operation design.
Mind Map: Idempotency Best Practices
Practical Example: Implementing Idempotency in an Order Processing Service
# Simplified Python example using a Redis store for idempotency keys
def process_order(message):
order_id = message['order_id']
idempotency_key = f"order:{order_id}"
if redis_client.exists(idempotency_key):
print("Duplicate message detected. Skipping processing.")
return
# Process the order
create_order_in_db(message)
# Mark message as processed
redis_client.set(idempotency_key, 'processed', ex=3600) # expire key after 1 hour
This approach ensures that if the same order message is received multiple times (due to retries or duplicates), it only processes once.
Understanding Message Ordering
Message ordering guarantees that messages are processed in the sequence they were produced or intended. Ordering is crucial for workflows where state changes depend on the sequence.
Ordering Types:
- Global Ordering: All messages processed in a strict sequence (rare and expensive).
- Partitioned Ordering: Ordering guaranteed within partitions or keys (common in Kafka, Kinesis).
Mind Map: Message Ordering Strategies
Practical Example: Ensuring Ordering in a Kafka Consumer
// Java example using Kafka consumer with partitioned ordering
public void consumeMessages() {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("orders-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// Process messages in order per partition
processOrder(record.value());
}
consumer.commitSync();
}
}
Kafka guarantees message order within a partition, so by partitioning on order ID or customer ID, ordering is preserved.
Combining Idempotency and Ordering
In real-world systems, both idempotency and ordering must be handled together to avoid data corruption and ensure correctness.
- Use idempotency keys to handle duplicates.
- Partition messages by keys to maintain ordering.
- Implement sequence numbers in messages to detect missing or out-of-order messages.
- Buffer and reorder messages on the consumer side if necessary.
Mind Map: Integrated Idempotency and Ordering
Additional Best Practices
- Use Exactly-Once Semantics (EOS) if supported: Some brokers like Kafka with transactions support EOS to simplify idempotency.
- Design operations to be naturally idempotent: For example, setting a value instead of incrementing.
- Monitor and alert on duplicate message rates and ordering violations.
- Document assumptions and guarantees clearly for all system components.
Summary
Idempotency and message ordering are foundational for building resilient, scalable event-driven systems. By combining unique idempotency keys, partitioned ordering, and consumer-side logic, developers can build systems that gracefully handle retries, duplicates, and out-of-order messages.
References
- Martin Kleppmann, Designing Data-Intensive Applications (Idempotency and Ordering chapters)
- Apache Kafka Documentation on Exactly-Once Semantics and Partitioning
- AWS SQS FIFO Queues documentation
7. Autoscaling and Elasticity Patterns
7.1 Horizontal Pod Autoscaling and Cluster Autoscaling in Kubernetes
Horizontal Pod Autoscaling (HPA) and Cluster Autoscaling are fundamental patterns in Kubernetes for achieving elasticity and scalability in cloud-native applications. They enable systems to dynamically adjust resource allocation based on workload demands, ensuring optimal performance and cost efficiency.
What is Horizontal Pod Autoscaling (HPA)?
HPA automatically scales the number of pod replicas in a Kubernetes deployment, replication controller, or replica set based on observed CPU utilization or other select metrics.
- Key Metrics: CPU utilization (default), memory usage, custom metrics (e.g., request latency, queue length).
- Goal: Maintain target metric thresholds by increasing or decreasing pod count.
Mind Map: Horizontal Pod Autoscaling Overview
Example: Basic HPA Configuration
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: frontend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
This example configures an HPA for the frontend deployment, scaling pods between 2 and 10 replicas to maintain an average CPU utilization of 50%.
What is Cluster Autoscaling?
Cluster Autoscaler automatically adjusts the number of nodes in a Kubernetes cluster based on pod resource requests and scheduling needs.
- Scale Up: Adds nodes when pods cannot be scheduled due to insufficient resources.
- Scale Down: Removes underutilized nodes when pods can be rescheduled elsewhere.
Mind Map: Cluster Autoscaler Components and Workflow
Example: Cluster Autoscaler Deployment Snippet (AWS EKS)
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-autoscaler
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: cluster-autoscaler
template:
metadata:
labels:
app: cluster-autoscaler
spec:
containers:
- name: cluster-autoscaler
image: k8s.gcr.io/autoscaling/cluster-autoscaler:v1.22.2
command:
- ./cluster-autoscaler
- --cloud-provider=aws
- --nodes=2:10:my-node-group
- --balance-similar-node-groups
- --skip-nodes-with-local-storage=false
- --skip-nodes-with-system-pods=false
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 300Mi
volumeMounts:
- name: ssl-certs
mountPath: /etc/ssl/certs/ca-certificates.crt
readOnly: true
volumes:
- name: ssl-certs
hostPath:
path: /etc/ssl/certs/ca-bundle.crt
This deployment configures the Cluster Autoscaler to manage a node group named my-node-group with a minimum of 2 and maximum of 10 nodes.
Integrating HPA and Cluster Autoscaler
- HPA scales pods based on workload.
- Cluster Autoscaler scales nodes to provide sufficient capacity for pods.
Together, they enable seamless elasticity:
- Workload Increase
- HPA adds pods
- If nodes insufficient
- Cluster Autoscaler adds nodes
- Workload Decrease
- HPA removes pods
- Cluster Autoscaler removes idle nodes
Example Scenario
- A spike in user traffic causes CPU utilization to exceed 50%.
- HPA increases pod replicas from 3 to 8.
- Existing nodes cannot schedule all pods.
- Cluster Autoscaler adds 3 new nodes.
- Traffic subsides; HPA scales pods down to 2.
- Cluster Autoscaler detects underutilized nodes and removes 2 nodes.
Best Practices
- Set realistic min/max replicas and nodes to avoid resource exhaustion or overprovisioning.
- Use custom metrics for HPA when CPU/memory are insufficient indicators.
- Monitor scaling events to detect oscillations or scaling delays.
- Configure appropriate cooldown periods to prevent rapid scale up/down cycles.
- Ensure Metrics Server is properly deployed for HPA to function.
- Test autoscaling behavior under load in staging environments.
Summary
Horizontal Pod Autoscaling and Cluster Autoscaling are powerful Kubernetes patterns that enable applications to respond dynamically to changing workloads. By combining pod-level scaling with node-level scaling, systems can maintain high availability and performance while optimizing resource usage and cost.
7.2 Predictive Autoscaling Using Machine Learning Models
Introduction
Predictive autoscaling leverages machine learning (ML) models to forecast future workloads and proactively adjust resources before demand spikes or drops occur. Unlike reactive autoscaling, which responds to current system metrics, predictive autoscaling anticipates changes, enabling smoother scaling transitions, reduced latency, and optimized resource utilization.
Why Predictive Autoscaling?
- Proactive Resource Management: Avoids lag in scaling decisions that can cause performance degradation.
- Cost Efficiency: Prevents over-provisioning by scaling precisely according to predicted demand.
- Improved User Experience: Maintains low latency and high availability during traffic surges.
Core Components of Predictive Autoscaling
Data Collection and Feature Engineering
Predictive autoscaling starts with gathering historical data:
- System Metrics: CPU usage, memory consumption, request rates.
- Application Logs: Error rates, response times.
- External Signals: Calendar events, marketing campaigns.
Feature engineering transforms raw data into meaningful inputs:
- Time-based features: Hour of day, day of week.
- Lag features: Previous time steps’ metrics.
- Rolling averages and variances: To capture trends and volatility.
Model Selection
Common ML models used for predictive autoscaling include:
| Model Type | Description | Example Use Case |
|---|---|---|
| Linear Regression | Simple, interpretable forecasting | Predicting CPU usage based on time |
| ARIMA | Time series forecasting with seasonality | Traffic prediction with daily cycles |
| LSTM (Neural Nets) | Captures complex temporal dependencies | Handling irregular traffic spikes |
| Prophet (Facebook) | Robust to missing data and outliers | Event-driven traffic prediction |
Example: Predictive Autoscaling with LSTM
Scenario:
A video streaming platform experiences daily traffic peaks in the evening and occasional spikes during new content releases. The goal is to predict CPU usage 15 minutes ahead to scale the backend service accordingly.
Steps:
- Data Preparation: Collect CPU usage metrics every minute for the past 3 months.
- Feature Engineering: Create lag features for the past 30 minutes, encode time-of-day.
- Model Training: Train an LSTM model to predict CPU usage 15 minutes into the future.
- Prediction: Use the model to forecast CPU usage continuously.
- Scaling Decision: If predicted CPU usage exceeds 70%, trigger scale-out; below 40%, trigger scale-in.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# Example input shape: (batch_size, time_steps, features)
model = Sequential([
LSTM(50, input_shape=(30, 1)),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
# X_train shape: (samples, 30, 1), y_train shape: (samples, 1)
model.fit(X_train, y_train, epochs=20, batch_size=64)
# Predict CPU usage 15 minutes ahead
predicted_cpu = model.predict(X_test)
Autoscaling Decision Logic
Best Practices
- Regular Model Retraining: Incorporate new data to adapt to changing traffic patterns.
- Incorporate Multiple Features: Use external signals like marketing events or holidays.
- Combine Predictive and Reactive Scaling: Use predictions to prepare and reactive scaling to handle unexpected spikes.
- Monitor Model Accuracy: Track prediction errors and adjust thresholds accordingly.
- Implement Safety Nets: Set minimum and maximum scaling limits to avoid resource exhaustion or excessive costs.
Summary
Predictive autoscaling using machine learning models enables systems to anticipate demand changes and adjust resources proactively. By integrating time series forecasting models, feature engineering, and well-defined scaling policies, technical leads can design highly available and cost-efficient scalable applications.
Additional Resources
- AWS Auto Scaling with Predictive Scaling
- Google Cloud Predictive Autoscaling
- Time Series Forecasting with LSTM
- Facebook Prophet Documentation
7.3 Queue-Based Autoscaling for Workload-Driven Systems
Queue-based autoscaling is a powerful pattern for dynamically adjusting the number of processing instances based on the workload demand reflected in message queues. It is particularly effective in systems where workloads are asynchronous and can be decoupled via queues, such as background job processing, event handling, or batch processing systems.
Why Queue-Based Autoscaling?
- Workload-driven scaling: Instead of relying solely on CPU or memory metrics, scaling decisions are based on the actual queue length or message backlog, providing a more direct correlation to demand.
- Smooth handling of traffic spikes: When the queue length increases, more workers are provisioned to process the backlog faster.
- Cost efficiency: When the queue is empty or low, the system scales down to save resources.
Core Concepts
- Queue Length: Number of messages waiting to be processed.
- Processing Rate: How fast workers consume messages.
- Scaling Thresholds: Predefined queue length values that trigger scaling up or down.
- Cooldown Periods: Time intervals to avoid rapid scaling fluctuations.
Mind Map: Queue-Based Autoscaling Components
How It Works: Step-by-Step Example
Consider a background image processing service that consumes tasks from an AWS SQS queue.
- Monitor Queue Length: A controller continuously polls the SQS queue to check the number of pending messages.
- Evaluate Thresholds:
- If queue length > 1000, trigger scale-up.
- If queue length < 100, trigger scale-down.
- Scale Up: Increase the number of worker instances (e.g., containers or EC2 instances) to process messages faster.
- Scale Down: Decrease the number of workers when backlog is low to reduce costs.
- Cooldown: After scaling, wait for a cooldown period (e.g., 5 minutes) before evaluating again to prevent thrashing.
Example: Kubernetes Horizontal Pod Autoscaler (HPA) with Custom Metrics
Kubernetes HPA can be configured to autoscale pods based on custom metrics like queue length.
- Setup: Use a metrics adapter (e.g., Prometheus Adapter) to expose queue length as a custom metric.
- HPA Configuration: Define min and max replicas and target queue length.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: image-processor-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: image-processor
minReplicas: 2
maxReplicas: 20
metrics:
- type: External
external:
metric:
name: sqs_queue_length
target:
type: AverageValue
averageValue: 500
This configuration tells Kubernetes to maintain an average queue length of 500 messages per pod, scaling pods up or down accordingly.
Best Practices
- Set appropriate thresholds: Avoid too sensitive thresholds that cause frequent scaling.
- Use cooldown periods: Prevent rapid scaling up and down (thrashing).
- Monitor processing latency: Queue length alone may not reflect processing delays.
- Combine with other metrics: CPU, memory, and error rates can complement queue length.
- Graceful shutdown: Ensure workers finish processing current messages before termination.
Additional Mind Map: Scaling Decision Flow
Real-World Example: Video Transcoding Pipeline
A video platform uses a queue-based autoscaling system for its transcoding workers:
- Queue: AWS SQS holds video transcoding jobs.
- Workers: Containers running FFmpeg consume jobs.
- Autoscaling: Based on SQS queue length, Kubernetes scales the number of transcoding pods.
This setup ensures that during peak upload times, more transcoding workers spin up to handle the backlog, and during quiet periods, resources scale down, optimizing cost and responsiveness.
Queue-based autoscaling is an essential pattern for workload-driven systems, enabling responsive, cost-effective scaling that aligns tightly with actual demand.
7.4 Example: Designing an Autoscaling Architecture for a Video Streaming Platform
Designing an autoscaling architecture for a video streaming platform requires careful consideration of workload patterns, resource utilization, and user experience. Video streaming platforms typically experience highly variable traffic — from steady baseline loads to sudden spikes during live events or popular content releases. Autoscaling ensures the platform can dynamically adjust resources to maintain performance and availability without overspending.
Key Components of the Video Streaming Platform
- Ingestion Layer: Handles video uploads and live stream ingestion.
- Transcoding Service: Converts raw video into multiple formats and bitrates.
- Content Delivery Network (CDN): Distributes video content globally with low latency.
- Playback Service: Manages user requests and streaming sessions.
- Analytics & Monitoring: Tracks user engagement, QoS, and system metrics.
Autoscaling Objectives
- Scale transcoding services based on incoming video processing workload.
- Scale playback services based on concurrent viewers.
- Ensure low latency and high availability during traffic spikes.
- Optimize cost efficiency by scaling down during off-peak hours.
Autoscaling Strategies
-
Horizontal Pod Autoscaling (HPA) for Microservices:
- Use Kubernetes HPA to scale transcoding and playback pods based on CPU, memory, and custom metrics like queue length or concurrent streams.
-
Queue-Based Autoscaling:
- Transcoding jobs are queued; autoscaling triggers based on queue depth.
-
Predictive Autoscaling:
- Use historical traffic data and ML models to predict spikes (e.g., during live events) and pre-scale resources.
-
Cluster Autoscaling:
- Automatically add/remove nodes in the Kubernetes cluster to accommodate pod scaling.
Mind Map: Autoscaling Architecture Overview
Example: Implementing Queue-Based Autoscaling for Transcoding
- Scenario: Incoming videos are placed in a job queue (e.g., RabbitMQ, Kafka).
- Metric: Queue depth (number of pending transcoding jobs).
- Autoscaling Rule:
- If queue depth > 50, increase transcoding pods by 2.
- If queue depth < 10, decrease transcoding pods by 1.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: transcoding-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: transcoding-service
minReplicas: 2
maxReplicas: 20
metrics:
- type: External
external:
metric:
name: transcoding_queue_depth
target:
type: AverageValue
averageValue: "50"
Example: Predictive Autoscaling Workflow
Best Practices
- Multi-metric Autoscaling: Combine CPU, memory, and custom business metrics for more accurate scaling.
- Cooldown Periods: Prevent rapid scale up/down cycles by enforcing cooldown intervals.
- Graceful Pod Termination: Ensure in-flight video processing or streaming sessions are not abruptly terminated.
- Autoscaling Testing: Use load testing and chaos engineering to validate autoscaling behavior.
Summary
Autoscaling a video streaming platform involves integrating multiple scaling patterns tailored to different components. By leveraging queue-based autoscaling for transcoding, HPA for playback, and predictive models for traffic surges, the system can maintain high availability and performance while optimizing costs.
This example illustrates how best practices and real-world metrics can be combined to build a resilient, scalable video streaming architecture.
7.5 Best Practices for Scaling State-Dependent Services
Scaling state-dependent services presents unique challenges compared to stateless services. Maintaining consistency, availability, and performance while managing state across distributed instances requires careful architectural decisions. This section explores best practices to effectively scale stateful services, supported by clear examples and mind maps to visualize key concepts.
Understanding the Challenges
- State Management Complexity: Unlike stateless services, stateful services must manage session data, user context, or transactional state.
- Data Consistency: Ensuring data consistency across multiple instances is critical.
- Scaling Constraints: Horizontal scaling is harder because state must be shared or partitioned.
Best Practices Mind Map
Use Sticky Sessions (Session Affinity)
Concept: Route requests from the same client to the same service instance to maintain session state locally.
Example: In a web application with user login sessions, the load balancer uses cookies or IP hashing to ensure the user’s requests hit the same backend instance.
Pros: Simple to implement.
Cons: Limits load distribution and fault tolerance; if an instance fails, session data is lost.
Best Practice: Combine sticky sessions with session replication or external session stores to improve reliability.
Externalize State Management
Concept: Decouple state from the service instances by storing it in external, highly available systems.
Examples:
- Use Redis or Memcached for session storage.
- Use distributed databases like Cassandra or DynamoDB for user data.
Benefits: Enables true horizontal scaling; service instances become stateless.
Example: A chat application stores user presence and message queues in Redis, allowing any service instance to serve any user.
Partition State (Sharding)
Concept: Split state data across multiple nodes based on keys (e.g., user ID) to distribute load.
Example: A gaming platform shards player state by geographic region, routing requests to the appropriate shard.
Considerations:
- Design consistent hashing or directory services for routing.
- Handle re-sharding carefully to avoid downtime.
Leverage Stateful Service Mesh and Orchestration
Concept: Use orchestration platforms like Kubernetes StatefulSets to manage stateful pods with stable network IDs and persistent storage.
Example: Deploy a stateful database cluster (e.g., PostgreSQL) using StatefulSets to maintain identity and storage.
Best Practice: Combine with persistent volumes and automated failover mechanisms.
Event Sourcing and CQRS
Concept: Store state changes as a sequence of immutable events rather than current state snapshots.
Benefits:
- Enables rebuilding state from events.
- Supports auditability and temporal queries.
- Facilitates scaling by separating read and write workloads.
Example: An order management system records all order events (created, updated, shipped) in an event store; read models are updated asynchronously.
Example Scenario: Scaling a Stateful Shopping Cart Service
Problem: Shopping cart data is user-specific and must persist across sessions.
Approach:
- Externalize cart state to a distributed cache (Redis).
- Use sticky sessions as a fallback for performance.
- Partition carts by user ID to distribute load.
- Employ event sourcing to track cart changes.
Result: The service scales horizontally, maintains consistency, and recovers gracefully from failures.
Monitoring and Testing
- Implement detailed health checks to monitor state synchronization.
- Use load testing tools simulating stateful user sessions.
- Apply chaos engineering to test failover and data consistency under failure.
Summary
Scaling state-dependent services demands a blend of architectural patterns and tooling:
- Avoid local-only state when possible.
- Externalize and partition state for scalability.
- Use orchestration tools designed for stateful workloads.
- Employ event-driven patterns for resilience and auditability.
- Continuously monitor and test to ensure reliability.
By following these best practices, technical leads and senior engineers can design scalable, highly available stateful services that meet demanding application requirements.
8. Designing for Disaster Recovery and Business Continuity
8.1 RPO and RTO: Setting Realistic Recovery Objectives
In the realm of disaster recovery and business continuity, two critical metrics define the effectiveness and expectations of your recovery strategy: Recovery Point Objective (RPO) and Recovery Time Objective (RTO). Understanding and setting realistic RPO and RTO values are foundational steps toward designing systems that can withstand failures and resume operations with minimal data loss and downtime.
What is RPO?
Recovery Point Objective (RPO) refers to the maximum acceptable amount of data loss measured in time. It answers the question:
“How much data can we afford to lose in case of a failure?”
For example, an RPO of 15 minutes means that in the event of a disaster, the system can tolerate losing up to 15 minutes worth of data.
What is RTO?
Recovery Time Objective (RTO) is the maximum acceptable length of time that a system can be down after a failure before normal operations are restored. It answers the question:
“How quickly must the system be back online after an outage?”
For example, an RTO of 1 hour means the system must be recovered and operational within one hour after an incident.
Mind Map: Understanding RPO and RTO
Why Setting Realistic RPO and RTO Matters
- Aligns Business and IT Expectations: Ensures recovery strategies meet business needs without over-engineering.
- Cost Optimization: Tighter RPO and RTO often require more expensive infrastructure and complex solutions.
- Risk Management: Helps prioritize systems and data based on criticality.
Factors Influencing RPO and RTO
| Factor | Impact on RPO | Impact on RTO |
|---|---|---|
| Backup Frequency | More frequent backups reduce RPO | N/A |
| Data Replication Method | Synchronous replication lowers RPO | May reduce RTO by faster failover |
| Automation Level | N/A | Higher automation reduces RTO |
| System Complexity | N/A | More complex systems increase RTO |
| Infrastructure | Faster storage and network reduce RPO and RTO |
Example Scenario: E-Commerce Platform
| Metric | Value | Explanation |
|---|---|---|
| RPO | 5 minutes | Orders placed within last 5 minutes may be lost in worst case. Achieved via near real-time replication. |
| RTO | 30 minutes | System must be back online within 30 minutes to avoid revenue loss and customer dissatisfaction. |
Implementation:
- Use synchronous replication between primary and secondary databases.
- Automate failover processes with health checks.
- Frequent incremental backups every 5 minutes.
Mind Map: Steps to Define RPO and RTO
Practical Example: Setting RPO and RTO for a SaaS Application
Context: SaaS platform offering project management tools.
- Critical Data: User project data, comments, attachments.
- Non-Critical Data: Analytics logs, usage statistics.
| Data Type | RPO | RTO | Recovery Strategy |
|---|---|---|---|
| User Project Data | 1 minute | 15 minutes | Synchronous DB replication, automated failover |
| Comments | 5 minutes | 30 minutes | Asynchronous replication, incremental backups |
| Attachments | 15 minutes | 1 hour | Object storage versioning, periodic snapshots |
| Analytics Logs | 1 hour | 4 hours | Batch backups, eventual consistency acceptable |
Outcome: This tiered approach balances cost and risk, ensuring critical data is protected with minimal loss and downtime, while less critical data uses cost-effective strategies.
Best Practices for Setting RPO and RTO
- Collaborate closely with business stakeholders to understand impact.
- Use data classification to prioritize recovery objectives.
- Continuously monitor and adjust objectives based on evolving business needs.
- Automate recovery processes to meet aggressive RTOs.
- Regularly test disaster recovery plans to validate RPO and RTO adherence.
Summary
Setting realistic RPO and RTO values is a cornerstone of effective disaster recovery planning. By understanding the trade-offs and aligning them with business priorities, organizations can design resilient systems that minimize data loss and downtime while optimizing costs and complexity.
Next section will dive into multi-region failover strategies that help achieve these recovery objectives in practice.
8.2 Multi-Region Failover Strategies with Active-Active and Active-Passive Models
Designing systems that remain available and performant during regional failures is critical for global applications. Multi-region failover strategies ensure business continuity by distributing workloads across geographically dispersed data centers. This section explores two primary models: Active-Active and Active-Passive, detailing their architectures, benefits, challenges, and practical examples.
Overview of Multi-Region Failover
Multi-region failover enables systems to withstand regional outages by rerouting traffic and workloads to healthy regions. It involves data replication, traffic management, and consistent state synchronization.
Active-Active Model
In an Active-Active setup, multiple regions actively serve traffic simultaneously. This model maximizes resource utilization and provides seamless failover.
Key Characteristics:
- All regions handle read and write operations concurrently.
- Data replication is bi-directional and often asynchronous or conflict-resolving.
- Load balancing distributes traffic across regions.
Benefits:
- Minimal downtime during failover.
- Improved latency by serving users from the nearest region.
- Better resource utilization.
Challenges:
- Data consistency complexities due to concurrent writes.
- Conflict resolution mechanisms needed.
- Increased operational complexity.
Mind Map: Active-Active Model
Example: Multi-Region Active-Active E-Commerce Platform
Imagine an e-commerce platform with data centers in US-East and EU-West. Both regions accept orders and inventory updates. The system uses a multi-master database replication with conflict resolution based on vector clocks. A global load balancer routes users to the nearest region with health checks to detect failures.
- Scenario: US-East region suffers an outage.
- Failover: Traffic automatically rerouted to EU-West.
- Result: Users experience minimal disruption.
Best practices include implementing idempotent operations to handle duplicate requests and designing eventual consistency boundaries to tolerate replication lag.
Active-Passive Model
In an Active-Passive setup, one region actively serves all traffic while the passive region remains on standby, ready to take over if the active region fails.
Key Characteristics:
- Only one region handles traffic at a time.
- Passive region replicates data continuously or periodically.
- Failover involves switching traffic to the passive region.
Benefits:
- Simpler data consistency (single writer).
- Easier to implement and maintain.
- Reduced risk of data conflicts.
Challenges:
- Potential downtime during failover.
- Underutilized passive resources.
- Failover automation complexity.
Mind Map: Active-Passive Model
Example: Active-Passive Disaster Recovery for a Banking Application
A banking system runs primarily in the US-West region with a passive standby in US-East. The primary database replicates data asynchronously to the standby. In case of failure detected by health probes, an automated failover triggers DNS updates to redirect traffic to US-East.
- Scenario: US-West data center experiences power failure.
- Failover: DNS TTL is low, enabling quick switch to US-East.
- Result: Some downtime occurs during DNS propagation, but data consistency is guaranteed.
Best practices include:
- Using low DNS TTL values to reduce failover time.
- Regular failover drills to validate readiness.
- Monitoring replication lag to ensure data freshness.
Comparative Summary
| Aspect | Active-Active | Active-Passive |
|---|---|---|
| Traffic Handling | Concurrent in all regions | Single active region |
| Data Consistency | Eventual consistency, conflict prone | Strong consistency, single writer |
| Failover Speed | Near-instantaneous | Dependent on DNS/load balancer update |
| Complexity | High | Moderate |
| Resource Utilization | High | Lower (passive idle) |
Practical Tips for Implementation
- Global Load Balancing: Use latency-based DNS routing (e.g., AWS Route 53, Google Cloud DNS) or anycast IPs for Active-Active.
- Data Replication: Choose databases supporting multi-master replication (e.g., Cassandra, CockroachDB) for Active-Active; use primary-secondary replication for Active-Passive.
- Health Checks: Implement multi-layer health checks (application, network, database) to detect failures promptly.
- Failover Automation: Automate failover with orchestration tools (e.g., Kubernetes operators, Terraform scripts) to minimize human error.
- Testing: Conduct regular failover drills and chaos engineering experiments to validate resilience.
Summary
Multi-region failover strategies are essential for building resilient, globally available systems. Active-Active models offer superior availability and performance but require sophisticated conflict resolution and operational expertise. Active-Passive models provide simpler consistency guarantees at the cost of potential downtime and resource inefficiency. Selecting the right model depends on application requirements, tolerance for downtime, and operational capabilities.
By combining these strategies with robust monitoring, automation, and testing, organizations can ensure business continuity and deliver seamless user experiences across the globe.
8.3 Chaos Engineering: Proactively Testing System Resilience
Chaos Engineering is the discipline of experimenting on a system to build confidence in its ability to withstand turbulent conditions in production. It is a proactive approach to uncover weaknesses before they manifest as outages.
What is Chaos Engineering?
- Definition: Systematic injection of faults to validate system robustness.
- Goal: Identify vulnerabilities and improve system resilience.
- Scope: Can be applied at infrastructure, application, or network levels.
Why Chaos Engineering Matters
- Complex distributed systems have unpredictable failure modes.
- Traditional testing often misses rare but impactful failures.
- Enables teams to prepare for real-world incidents by simulating failures.
Core Principles of Chaos Engineering
- Start with a Hypothesis: Define expected system behavior under failure.
- Vary Real-World Conditions: Inject faults that mimic production issues.
- Automate Experiments: Run chaos tests regularly and automatically.
- Minimize Blast Radius: Start small to avoid impacting customers.
- Learn and Improve: Use results to harden the system.
Mind Map: Chaos Engineering Overview
Common Fault Injection Scenarios
| Fault Type | Description | Example Impact |
|---|---|---|
| Instance Termination | Randomly kill server instances | Service unavailability |
| Network Latency | Introduce delays in network communication | Increased response times |
| Packet Loss | Drop network packets | Partial service degradation |
| CPU/Memory Saturation | Exhaust system resources | Slowdowns or crashes |
| Disk Failures | Simulate disk I/O errors | Data unavailability or corruption |
Example: Chaos Engineering in a Microservices Architecture
Scenario: Test resilience of an order processing microservice during database latency spikes.
- Hypothesis: The order service should queue requests and retry without dropping orders when DB latency increases.
- Fault Injection: Inject artificial latency of 2 seconds on database calls.
- Experiment: Run load tests while injecting latency.
- Observation: Monitor request success rate, queue length, and error rates.
- Result: Identify if orders are lost or delayed beyond SLA.
- Action: Implement circuit breaker and retry policies if needed.
Mind Map: Fault Injection Experiment Workflow
Best Practices for Chaos Engineering
- Start Small: Limit impact by targeting non-critical components initially.
- Automate and Schedule: Integrate chaos tests into CI/CD pipelines.
- Collaborate Across Teams: Share findings with development, ops, and SRE teams.
- Use Realistic Faults: Model failures based on historical incidents.
- Monitor Closely: Use comprehensive observability to detect issues.
- Document and Share Learnings: Maintain a knowledge base of experiments and outcomes.
Tools and Platforms
- Chaos Monkey (Netflix): Randomly terminates instances to test resilience.
- Gremlin: Provides a full suite of fault injection capabilities.
- LitmusChaos: Kubernetes-native chaos engineering framework.
- AWS Fault Injection Simulator: Cloud-native fault injection service.
Summary
Chaos Engineering empowers teams to proactively discover weaknesses by simulating failures in a controlled manner. By embedding chaos experiments into the development lifecycle, organizations can significantly improve system reliability and prepare for unexpected disruptions.
8.4 Example: Implementing a Disaster Recovery Plan for a Financial Services Application
Designing a robust Disaster Recovery (DR) plan for a financial services application is critical due to the sensitive nature of financial data, strict regulatory requirements, and the need for uninterrupted service availability. This section walks through a comprehensive example of implementing such a plan, integrating best practices and patterns discussed earlier.
Key Objectives of the DR Plan
- Recovery Point Objective (RPO): Less than 5 minutes
- Recovery Time Objective (RTO): Under 30 minutes
- Data Integrity: Zero data loss and consistency across regions
- Compliance: Meet financial regulatory standards (e.g., PCI DSS, SOX)
- Availability: 99.999% uptime even during disasters
Mind Map: Disaster Recovery Plan Components
Step 1: Data Replication Strategy
Approach: Use synchronous multi-region replication to ensure zero data loss.
Example:
- Primary data center located in US-East.
- Secondary data center in US-West.
- Use a distributed database like CockroachDB or Google Spanner that supports synchronous replication.
Code snippet (pseudo-configuration):
replication:
mode: synchronous
regions:
- us-east-1
- us-west-2
conflict_resolution: last_write_wins
Best Practice: Ensure network latency between regions is low enough to support synchronous replication without impacting performance.
Step 2: Failover Strategy
Approach: Implement an Active-Active failover model with automatic traffic redirection.
Example:
- Use DNS-based global load balancing with health checks.
- Employ Route 53 (AWS) or Cloudflare Load Balancer to monitor primary region health.
- On failure detection, traffic automatically shifts to secondary region.
Mind Map: Failover Workflow
Example Scenario: If US-East region experiences an outage, DNS TTL is lowered to 30 seconds and traffic is routed to US-West until US-East recovers.
Step 3: Backup and Restore
Approach: Maintain automated daily snapshots with incremental backups stored offsite.
Example:
- Use AWS Backup or Azure Backup to schedule snapshots.
- Store backups encrypted in a separate region.
- Retain backups for 90 days to meet compliance.
Best Practice: Regularly test restore procedures to ensure backup integrity.
Step 4: Monitoring and Alerting
Approach: Implement comprehensive observability for early detection of failures.
Example:
- Use Prometheus for metrics collection.
- Grafana dashboards visualize system health.
- Alerts configured for latency spikes, error rates, and replication lag.
Sample Alert Rule (Prometheus):
alert: ReplicationLagHigh
expr: replication_lag_seconds > 5
for: 5m
labels:
severity: critical
annotations:
summary: "Replication lag is above threshold"
description: "Replication lag has been above 5 seconds for more than 5 minutes."
Step 5: Testing and Drills
Approach: Regularly perform DR drills and chaos engineering experiments.
Example:
- Schedule quarterly failover drills simulating region outage.
- Use tools like Chaos Monkey to randomly terminate instances.
Mind Map: DR Drill Process
Step 6: Security and Compliance
Approach: Encrypt data at rest and in transit; enforce strict access controls.
Example:
- Use TLS 1.3 for all network communication.
- Enable database encryption with customer-managed keys.
- Implement role-based access control (RBAC) with audit logging.
Summary Table: Disaster Recovery Implementation
| Component | Strategy | Tools/Technologies | Best Practice Example |
|---|---|---|---|
| Data Replication | Synchronous Multi-Region | CockroachDB, Google Spanner | Monitor replication lag closely |
| Failover | Active-Active with DNS Load Balancing | AWS Route 53, Cloudflare | Use low DNS TTL and health checks |
| Backup & Restore | Automated Snapshots + Offsite Backup | AWS Backup, Azure Backup | Regular restore testing |
| Monitoring & Alerting | Metrics + Alerts | Prometheus, Grafana | Alert on replication lag and error spikes |
| Testing & Drills | Scheduled DR Drills + Chaos Engineering | Chaos Monkey, Custom Scripts | Document and iterate after each drill |
| Security & Compliance | Encryption + RBAC + Audit Logs | TLS, KMS, IAM | Enforce least privilege and audit all access |
Final Thoughts
Implementing a disaster recovery plan for financial services applications requires meticulous planning, integration of multiple patterns, and continuous validation. The example above demonstrates how to combine synchronous replication, active-active failover, automated backups, observability, rigorous testing, and security controls into a cohesive strategy that meets stringent financial industry requirements.
By following these practices, technical leads and senior engineers can architect systems that not only survive disasters but maintain trust and compliance in highly regulated environments.
8.5 Best Practices for Regular DR Drills and Automation
Disaster Recovery (DR) drills and automation are critical components to ensure that your system can withstand and quickly recover from unexpected failures. Regularly testing your DR plans through drills and automating recovery processes reduces downtime, uncovers hidden weaknesses, and builds confidence in your system’s resilience.
Why Regular DR Drills Matter
- Validate the effectiveness of your DR plan
- Train teams to respond efficiently under pressure
- Identify gaps in documentation, communication, and tooling
- Ensure compliance with regulatory requirements
- Build organizational muscle memory for disaster scenarios
Key Best Practices for DR Drills
Planning Your DR Drills
- Define Clear Objectives: Are you testing failover speed, data integrity, communication protocols, or all of these?
- Scope and Frequency: Start with tabletop exercises, then progress to partial and full failover drills. Schedule drills quarterly or bi-annually depending on business needs.
- Stakeholder Involvement: Include engineering, operations, security, and business continuity teams.
Preparation
- Up-to-Date Documentation: Ensure your DR runbooks, contact lists, and architecture diagrams reflect the current system.
- Communication Plan: Define how and when stakeholders are notified during drills.
- Backup Verification: Confirm backups are complete, consistent, and accessible.
Execution
- Simulate Realistic Scenarios: Examples include data center outages, ransomware attacks, or network partitioning.
- Cross-Team Collaboration: Encourage teams to communicate and coordinate as they would in a real disaster.
- Monitoring: Use dashboards and logs to track drill progress and detect issues.
Post-Drill Activities
- Postmortems: Conduct blameless reviews focusing on what went well and what needs improvement.
- Documentation Updates: Incorporate findings to improve DR plans and automation scripts.
Automation in DR Drills
Automation reduces human error and accelerates recovery. Key automation practices include:
Example: Automating a Multi-Region Failover Drill
Scenario: Your application runs in two AWS regions (us-east-1 and us-west-2). You want to automate a failover drill to test recovery from a regional outage.
Steps:
-
Infrastructure as Code: Use Terraform to provision identical infrastructure in both regions.
-
Automated Failover: Write scripts that:
- Update Route 53 DNS records to redirect traffic from the primary to the secondary region.
- Promote a read replica database in the secondary region to primary.
- Reconfigure load balancers to accept traffic.
-
Continuous Testing: Schedule the failover drill monthly using a CI/CD pipeline (e.g., Jenkins, GitHub Actions).
-
Validation: Automated health checks verify application responsiveness post-failover.
-
Rollback: After validation, scripts revert DNS and database roles back to the primary region.
-
Post-Drill Reporting: Generate reports summarizing drill duration, errors, and recovery time.
Example: Tabletop DR Drill for Ransomware Attack
Objective: Test communication and recovery procedures in case of ransomware encrypting primary data stores.
Process:
- Gather stakeholders in a conference room or virtual meeting.
- Present a scenario where primary databases are compromised.
- Walk through steps to isolate infected systems, activate backups, and restore services.
- Discuss roles, responsibilities, and communication channels.
- Identify gaps and update DR documentation accordingly.
Summary Checklist for Effective DR Drills and Automation
- Define clear drill objectives and scope
- Keep DR documentation current and accessible
- Involve all relevant teams and stakeholders
- Simulate realistic and varied disaster scenarios
- Automate failover and recovery processes where possible
- Schedule regular drills and automate testing pipelines
- Monitor drills with observability tools
- Conduct blameless postmortems and update plans
- Train teams continuously to improve response readiness
By embedding regular DR drills and automation into your operational culture, you ensure your systems are not only designed for high availability but also proven to recover swiftly and reliably when disaster strikes.
9. Security Patterns for Highly Available and Scalable Systems
9.1 Securing Distributed Systems Without Sacrificing Availability
Designing security into distributed systems is a critical challenge, especially when high availability is a core requirement. Security mechanisms often introduce latency, complexity, or potential points of failure that can reduce system availability. This section explores strategies and best practices to secure distributed systems while maintaining their availability.
Key Challenges
- Latency Overhead: Security checks (e.g., encryption, authentication) can add latency.
- Single Points of Failure: Centralized security components can become bottlenecks.
- Complexity: Increased complexity can lead to misconfigurations and vulnerabilities.
- Availability vs Security Trade-offs: Overly strict security can block legitimate traffic.
Mind Map: Balancing Security and Availability in Distributed Systems
Best Practices with Examples
Decentralize Authentication and Authorization
Centralized authentication services can become bottlenecks or single points of failure. Use distributed identity providers or federated authentication to improve availability.
Example:
- Use OAuth 2.0 with multiple authorization servers deployed across regions.
- Employ JWT tokens that can be validated locally by services without always querying the auth server.
User logs in -> Auth server issues JWT with expiry and claims -> Microservices validate JWT signature locally -> No need for constant auth server calls
This reduces latency and dependency on a single auth server.
Implement Token Caching and Grace Periods
To reduce authentication overhead, cache validated tokens or sessions at service edges with expiration and refresh mechanisms.
Example:
- API Gateway caches JWT token validation results for 5 minutes.
- If token is revoked, a short TTL ensures stale tokens expire quickly.
Use Mutual TLS (mTLS) for Service-to-Service Encryption
Encrypt traffic between services to prevent man-in-the-middle attacks without sacrificing performance.
Example:
- Kubernetes clusters use mTLS via service mesh (e.g., Istio) to secure intra-cluster communication.
This offloads encryption to sidecars, keeping application code simple and availability high.
Employ Zero Trust Network Architecture
Never trust any network by default, even internal ones. Authenticate and authorize every request.
Example Mind Map:
This minimizes blast radius of breaches and supports availability by limiting attack surface.
Redundancy and Failover for Security Components
Ensure critical security infrastructure (auth servers, key management systems) are deployed redundantly.
Example:
- Deploy multiple instances of Key Management Service (KMS) across availability zones.
- Use consensus protocols (e.g., Raft) for distributed key management.
Rate Limiting and Throttling to Prevent Abuse
Protect services from DoS attacks and abuse without blocking legitimate users.
Example:
- API Gateway enforces per-user rate limits with burst capacity.
- Exceeding limits triggers exponential backoff and alerts.
Asynchronous Security Checks Where Possible
Offload non-critical security validations to asynchronous pipelines to reduce request latency.
Example:
- Log all access attempts and run anomaly detection offline.
- Use webhooks or event-driven alerts for suspicious activity.
Example Scenario: Securing a Distributed E-Commerce Platform
Context: A global e-commerce platform with microservices architecture requires strong security without compromising availability.
Approach:
- Use OAuth 2.0 with JWT tokens issued by multiple regional auth servers.
- API Gateway validates JWT tokens locally and caches validation results.
- All service-to-service communication secured with mTLS via Istio service mesh.
- Key Management Service deployed in active-active mode across regions.
- Rate limiting applied at API Gateway to prevent abuse.
- Security logs streamed asynchronously to a centralized SIEM for anomaly detection.
Outcome:
- Authentication latency reduced by 40% due to local JWT validation.
- No downtime caused by auth server failures due to redundancy.
- Encrypted communication ensures data privacy without impacting throughput.
Summary
Securing distributed systems without sacrificing availability requires thoughtful design that decentralizes critical security functions, leverages caching and asynchronous processing, and builds redundancy into security infrastructure. By adopting zero trust principles, encrypting all communication, and implementing rate limiting, systems can remain both secure and highly available.
Additional Resources
- OAuth 2.0 and OpenID Connect
- Istio Service Mesh Security
- Zero Trust Architecture - NIST
- JWT Best Practices
9.2 Rate Limiting and Throttling Patterns to Prevent Abuse
Introduction
Rate limiting and throttling are essential design patterns to protect high availability and scalable systems from abuse, overload, and denial-of-service (DoS) attacks. They help maintain system stability by controlling the number of requests a client can make within a given timeframe.
Key Concepts
- Rate Limiting: Restricts the number of requests a client can make in a specified time window.
- Throttling: Temporarily slows down or blocks requests when usage exceeds predefined thresholds.
Both patterns aim to prevent resource exhaustion and ensure fair usage.
Common Rate Limiting Strategies
Mind Map: Rate Limiting Strategies
Example: Fixed Window Rate Limiting
Imagine an API that allows 100 requests per minute per user.
- The system tracks the count of requests per user in the current minute.
- If the count exceeds 100, further requests are rejected until the next minute.
Code snippet (pseudo-code):
class FixedWindowRateLimiter:
def __init__(self, max_requests, window_seconds):
self.max_requests = max_requests
self.window_seconds = window_seconds
self.requests = {} # user_id -> (window_start, count)
def allow_request(self, user_id):
current_time = int(time.time())
window_start = current_time - (current_time % self.window_seconds)
if user_id not in self.requests or self.requests[user_id][0] != window_start:
self.requests[user_id] = (window_start, 0)
count = self.requests[user_id][1]
if count < self.max_requests:
self.requests[user_id] = (window_start, count + 1)
return True
return False
Throttling Patterns
Throttling can be implemented as:
- Hard Throttling: Reject requests immediately when limits are exceeded.
- Soft Throttling: Gradually slow down responses or introduce delays.
Mind Map: Rate Limiting vs Throttling
Distributed Rate Limiting
In distributed systems, rate limiting must be coordinated across multiple nodes.
- Centralized Store: Use Redis or Memcached to maintain counters.
- Token Bucket with Distributed Locks: Ensure atomic token consumption.
Example: Using Redis INCR with expiry for fixed window limiting.
import redis
r = redis.Redis()
def allow_request(user_id, max_requests=100, window=60):
key = f"rate_limit:{user_id}"
current = r.incr(key)
if current == 1:
r.expire(key, window)
return current <= max_requests
Best Practices
- Return appropriate HTTP status codes (e.g., 429 Too Many Requests).
- Include
Retry-Afterheaders to inform clients when to retry. - Use client identifiers (API keys, IP addresses) carefully to avoid unfair blocking.
- Combine rate limiting with authentication and authorization.
- Monitor rate limiting metrics and adjust thresholds dynamically.
Real-World Example: API Gateway Rate Limiting
An API Gateway (e.g., Kong, AWS API Gateway) can enforce rate limits per API key.
- Define limits per tier (free, premium).
- Automatically reject or queue requests exceeding limits.
- Provide dashboards for clients to monitor usage.
Summary
Rate limiting and throttling are critical to maintaining system availability and fairness. Choosing the right pattern depends on use case, traffic patterns, and system architecture. Implementing these with clear feedback to clients and monitoring ensures robust protection against abuse.
Additional Mind Map: Implementing Rate Limiting in Microservices
9.3 Circuit Breakers for Security: Handling DDoS and Attack Mitigation
Introduction
Circuit breakers are traditionally used to improve system resilience by preventing cascading failures in distributed systems. However, their utility extends beyond fault tolerance into security, particularly in mitigating Distributed Denial of Service (DDoS) attacks and other abusive behaviors. By intelligently detecting abnormal traffic patterns and temporarily blocking or throttling requests, circuit breakers can act as a frontline defense mechanism.
Why Use Circuit Breakers for Security?
- Prevent Resource Exhaustion: Stop overwhelming backend services during attack spikes.
- Protect Downstream Dependencies: Avoid cascading failures caused by malicious traffic.
- Improve System Stability: Maintain availability for legitimate users even under attack.
How Circuit Breakers Help Mitigate DDoS Attacks
- Detect abnormal request rates or error rates.
- Open the circuit to reject or delay requests once thresholds are breached.
- Automatically reset after a cooldown period to test if the system is healthy.
Mind Map: Circuit Breakers in Security Context
Example 1: Implementing a Circuit Breaker to Mitigate API Abuse
Scenario: A public-facing API is experiencing a sudden surge of requests from a single IP range, suspected to be a DDoS attack.
Implementation Steps:
- Monitor Request Rate: Track the number of requests per IP per minute.
- Set Threshold: If requests exceed 1000 per minute from the same IP, trigger the circuit breaker.
- Open Circuit: Reject further requests from that IP for 5 minutes.
- Half-Open State: After 5 minutes, allow a small number of requests to test if traffic normalized.
- Close Circuit: If traffic is normal, resume accepting requests; otherwise, keep circuit open.
Code Snippet (Pseudocode):
class SecurityCircuitBreaker:
def __init__(self, threshold, cooldown):
self.threshold = threshold
self.cooldown = cooldown
self.state = 'CLOSED'
self.last_opened = None
self.request_counts = {}
def record_request(self, ip):
count = self.request_counts.get(ip, 0) + 1
self.request_counts[ip] = count
if count > self.threshold and self.state == 'CLOSED':
self.open_circuit()
def open_circuit(self):
self.state = 'OPEN'
self.last_opened = time.time()
print('Circuit opened due to suspicious activity')
def allow_request(self, ip):
if self.state == 'OPEN':
if time.time() - self.last_opened > self.cooldown:
self.state = 'HALF-OPEN'
return True # Allow limited requests
else:
return False # Reject requests
elif self.state == 'HALF-OPEN':
# Logic to test if traffic is normal
return True
else:
return True
Example 2: Integrating Circuit Breaker with API Gateway for DDoS Protection
Scenario: An API Gateway manages traffic for multiple microservices. To prevent overload, it uses circuit breakers to detect and block abusive clients.
Best Practices:
- Use rate limiting combined with circuit breakers.
- Maintain per-client state to isolate offenders.
- Log and alert on circuit breaker state changes for security monitoring.
Architecture Diagram (Mind Map):
Best Practices for Using Circuit Breakers in Security
- Define Clear Thresholds: Use historical traffic data to set realistic limits.
- Combine with Other Controls: Use alongside firewalls, WAFs, and rate limiters.
- Graceful Degradation: Serve cached or static content when circuit is open.
- Logging and Alerting: Track circuit breaker events for forensic analysis.
- Test Regularly: Simulate attacks to validate circuit breaker effectiveness.
Summary
Circuit breakers are a powerful pattern not only for fault tolerance but also as a security mechanism to mitigate DDoS and other abusive behaviors. By intelligently detecting anomalies and temporarily blocking traffic, they help maintain system availability and protect backend resources. Integrating circuit breakers with API gateways, load balancers, and microservices, combined with proper monitoring and alerting, forms a robust defense layer in modern scalable applications.
9.4 Example: Integrating OAuth and API Gateway Security in a Scalable Microservices Environment
In modern microservices architectures, securing APIs while maintaining scalability and high availability is paramount. This section explores how to integrate OAuth 2.0 authentication and authorization with an API Gateway to protect microservices effectively.
Overview
OAuth 2.0 is a widely adopted authorization framework that enables third-party applications to obtain limited access to HTTP services. When combined with an API Gateway, it centralizes security enforcement, simplifies token validation, and provides a scalable entry point for microservices.
Mind Map: OAuth and API Gateway Integration
OAuth and API Gateway Security Integration Mind Map
Step-by-Step Example
Setup OAuth 2.0 Authorization Server
- Use an open-source or cloud-based OAuth 2.0 provider (e.g., Keycloak, Okta, Auth0).
- Configure client applications and define scopes and roles.
Deploy API Gateway
- Choose an API Gateway that supports OAuth integration (e.g., Kong, AWS API Gateway, NGINX, or Envoy).
- Configure the gateway to validate incoming OAuth tokens.
Token Validation at API Gateway
- When a client sends a request with an access token, the API Gateway:
- Extracts the token from the
Authorizationheader. - Validates the token signature and expiry.
- Checks scopes and roles against the requested resource.
- Extracts the token from the
Request Routing and Forwarding
- After successful validation, the API Gateway forwards the request to the appropriate microservice.
- Optionally, the gateway can propagate user identity information via headers.
Microservice Token Trust
- Microservices trust the API Gateway and may perform lightweight token validation or rely on gateway enforcement.
- For sensitive operations, microservices can perform introspection calls to the authorization server.
Code Snippet: Token Validation Middleware in API Gateway (Node.js Express Example)
const jwt = require('jsonwebtoken');
const jwksClient = require('jwks-rsa');
const client = jwksClient({
jwksUri: 'https://YOUR_AUTH_SERVER/.well-known/jwks.json'
});
function getKey(header, callback) {
client.getSigningKey(header.kid, function(err, key) {
const signingKey = key.getPublicKey();
callback(null, signingKey);
});
}
function validateToken(req, res, next) {
const token = req.headers['authorization']?.split(' ')[1];
if (!token) {
return res.status(401).send('Access token missing');
}
jwt.verify(token, getKey, {}, (err, decoded) => {
if (err) {
return res.status(401).send('Invalid token');
}
// Check scopes or roles
if (!decoded.scope || !decoded.scope.includes('read:data')) {
return res.status(403).send('Insufficient scope');
}
req.user = decoded;
next();
});
}
module.exports = validateToken;
Example Architecture Diagram (Mind Map)
Best Practices
- Use JWTs with short expiration times to reduce risk if tokens are compromised.
- Implement token revocation or introspection for immediate invalidation.
- Centralize authentication and authorization logic at the API Gateway to simplify microservices.
- Use HTTPS for all communications to protect tokens in transit.
- Propagate user context securely to downstream services when needed.
- Implement rate limiting and throttling at the gateway to prevent abuse.
- Log all authentication and authorization events for auditing and troubleshooting.
Summary
Integrating OAuth 2.0 with an API Gateway provides a robust, scalable security model for microservices environments. It centralizes token validation and authorization enforcement, reduces complexity within microservices, and supports high availability by offloading security concerns to a dedicated layer. By following the outlined steps and best practices, teams can build secure, scalable, and maintainable systems.
9.5 Best Practices for Secure Configuration and Secrets Management
Secure configuration and secrets management are critical pillars in building highly available and scalable systems without compromising security. Mismanagement can lead to data breaches, unauthorized access, and service disruptions. This section covers best practices, practical examples, and mind maps to help senior engineers and technical leads implement robust secrets management strategies.
Key Principles of Secure Configuration and Secrets Management
- Least Privilege: Grant only the minimum access necessary.
- Separation of Duties: Differentiate roles for secret creation, storage, and usage.
- Auditability: Maintain logs of secret access and changes.
- Automated Rotation: Regularly rotate secrets to reduce exposure.
- Encryption at Rest and Transit: Protect secrets both in storage and during communication.
- Avoid Hardcoding Secrets: Never embed secrets directly in code or configuration files.
Mind Map: Secure Secrets Management Overview
Best Practices with Examples
Use Dedicated Secrets Management Tools
Example: Using HashiCorp Vault to store database credentials.
- Vault provides dynamic secrets generation, leasing, and revocation.
- Applications authenticate with Vault using tokens or cloud-native auth methods (e.g., AWS IAM).
# Example: Retrieve a database credential dynamically
vault read database/creds/my-role
Avoid Hardcoding Secrets in Source Code
Bad Practice:
String dbPassword = "SuperSecret123!"; // Avoid this
Better Practice: Inject secrets at runtime via environment variables or secret stores.
export DB_PASSWORD=$(vault read -field=password database/creds/my-role)
Encrypt Secrets at Rest and in Transit
- Use TLS for all communication with secret stores.
- Enable encryption on storage backends (e.g., AWS KMS for S3 buckets).
Implement Role-Based Access Control (RBAC)
- Define fine-grained policies limiting who/what can access secrets.
Example: AWS IAM policy allowing read-only access to a specific secret.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["secretsmanager:GetSecretValue"],
"Resource": "arn:aws:secretsmanager:region:account-id:secret:my-db-secret"
}
]
}
Automate Secret Rotation
- Schedule automatic rotation of keys and passwords.
- Update dependent services seamlessly.
Example: AWS Secrets Manager supports automatic rotation with Lambda functions.
Integrate Secrets Management into CI/CD Pipelines
- Avoid storing secrets in pipeline definitions.
- Use pipeline plugins or environment variables to inject secrets securely.
Example: Jenkins credentials plugin to inject secrets at build time.
Audit and Monitor Secret Access
- Enable detailed logging.
- Set up alerts for unusual access patterns.
Example: Using Vault audit devices to log all secret access.
Mind Map: Secret Lifecycle Management
Practical Example: Securely Managing API Keys in a Microservices Environment
Scenario: A microservices application requires an API key to access a third-party payment gateway.
Implementation Steps:
- Store the API key in AWS Secrets Manager.
- Assign an IAM role to the microservice’s compute environment (e.g., ECS task role) with permission to read the secret.
- At service startup, retrieve the API key programmatically:
import boto3
import os
client = boto3.client('secretsmanager')
secret_name = os.environ.get('PAYMENT_API_SECRET_NAME')
response = client.get_secret_value(SecretId=secret_name)
api_key = response['SecretString']
-
Use the API key in service requests without ever hardcoding it.
-
Configure automatic rotation in AWS Secrets Manager with a Lambda function that updates the payment gateway and the secret store.
-
Monitor access logs in Secrets Manager and set up CloudWatch alarms for anomalous activity.
Additional Tips
- Use Environment-Specific Secrets: Separate secrets for dev, staging, and production.
- Implement Multi-Factor Authentication (MFA): For accessing secret management consoles.
- Regularly Review and Revoke Unused Secrets: Reduce attack surface.
- Educate Teams: Ensure developers understand the risks of poor secrets management.
By following these best practices and leveraging modern secrets management tools, teams can significantly reduce security risks while maintaining the availability and scalability of their systems.
10. Monitoring, Observability, and Alerting for High Availability
10.1 Metrics, Logs, and Traces: The Three Pillars of Observability
Observability is a critical aspect of designing and operating high availability and scalable systems. It empowers engineers to understand system behavior, diagnose issues quickly, and maintain reliability at scale. The three foundational pillars of observability are Metrics, Logs, and Traces. Each pillar offers unique insights and, when combined, provides a comprehensive view of system health and performance.
Metrics
Definition: Metrics are numerical measurements collected over time that represent the state or performance of a system.
Characteristics:
- Quantitative and structured
- Time-series data
- Aggregated and easy to visualize
Common Metrics Examples:
- CPU usage (%)
- Memory consumption (MB)
- Request rate (requests per second)
- Error rate (%)
- Latency (ms)
Use Case: Metrics are ideal for monitoring system health, setting up alerts, and triggering autoscaling.
Example: Monitoring HTTP request latency to detect performance degradation.
# Example Prometheus metric format
http_request_duration_seconds_bucket{le="0.1"} 24054
http_request_duration_seconds_bucket{le="0.2"} 33444
http_request_duration_seconds_bucket{le="0.5"} 100392
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 144320
Logs
Definition: Logs are timestamped, unstructured or semi-structured records of discrete events that occur within a system.
Characteristics:
- Textual and detailed
- Context-rich
- Useful for forensic analysis and debugging
Common Log Types:
- Application logs
- System logs
- Security logs
Use Case: Logs help diagnose root causes of failures, track user activity, and audit system behavior.
Example: An error log entry when a payment transaction fails.
{
"timestamp": "2024-06-15T14:23:45Z",
"level": "ERROR",
"service": "payment-service",
"message": "Transaction failed due to insufficient funds",
"transactionId": "abc123",
"userId": "user789"
}
Traces
Definition: Traces represent the journey of a request as it propagates through various services and components in a distributed system.
Characteristics:
- Distributed and correlated
- Capture timing and causal relationships
- Visualized as spans in a trace tree
Use Case: Traces help identify latency bottlenecks, understand service dependencies, and debug distributed transactions.
Example: A trace showing a user request flowing through API Gateway -> Auth Service -> Order Service -> Database.
TraceID: 4bf92f3577b34da6a3ce929d0e0e4736
Spans:
- API Gateway (start: 0ms, duration: 5ms)
- Auth Service (start: 5ms, duration: 10ms)
- Order Service (start: 15ms, duration: 30ms)
- Database (start: 20ms, duration: 25ms)
Mind Maps
Mind Map 1: Overview of Observability Pillars
Mind Map 2: Metrics Details
Mind Map 3: Logs Details
Mind Map 4: Traces Details
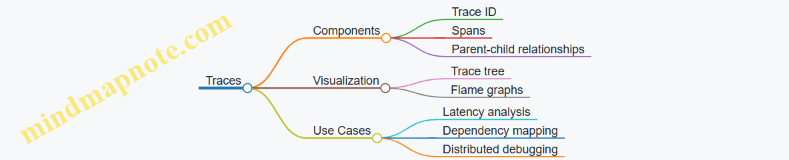
Integrated Example: Diagnosing a Slow API Endpoint
Scenario: Users report slow responses from an e-commerce API.
- Metrics: Alert triggered due to increased 95th percentile latency in
http_request_duration_secondsmetric. - Logs: Inspect logs from the API service reveal repeated timeout errors connecting to the inventory service.
- Traces: Distributed tracing shows that the inventory service call spans are significantly longer than usual, causing the bottleneck.
Resolution: Scaling the inventory service instances and optimizing database queries reduces latency.
Best Practices
- Collect all three pillars: Metrics for broad monitoring, logs for detailed context, and traces for distributed insights.
- Correlate data: Use trace IDs in logs and metrics to link data points.
- Use structured logging: Facilitates querying and analysis.
- Automate alerting: Based on metrics thresholds and anomaly detection.
- Visualize traces: Use tools like Jaeger or Zipkin for intuitive debugging.
By mastering metrics, logs, and traces, senior engineers and technical leads can build observability into their systems, enabling proactive maintenance and rapid incident response essential for high availability and scalability.
10.2 Designing Health Checks and Readiness Probes
Designing effective health checks and readiness probes is a cornerstone for maintaining high availability and reliability in distributed systems. These mechanisms enable orchestration platforms, load balancers, and monitoring tools to understand the state of your services and make informed decisions about traffic routing, scaling, and recovery.
What Are Health Checks and Readiness Probes?
- Health Checks verify that a service or component is alive and functioning at a basic level.
- Readiness Probes determine if a service is ready to accept traffic, ensuring it has completed initialization and dependencies are met.
Both are essential for preventing downtime and ensuring smooth deployments.
Key Concepts Mind Map
Types of Probes
| Probe Type | Purpose | When to Use | Example Scenario |
|---|---|---|---|
| Liveness | Checks if the app is alive (not crashed) | Detects deadlocks or crashes, triggers restart | App stuck in infinite loop |
| Readiness | Checks if app is ready to serve traffic | Prevents sending traffic before app is ready | Waiting for DB connection |
| Startup | Checks if app has started successfully | Used during startup to avoid premature liveness failures | Slow initialization processes |
Designing Effective Health Checks
- Keep it lightweight: Avoid expensive computations or database queries.
- Use meaningful endpoints: e.g.,
/healthzor/readyreturning HTTP 200 for success. - Avoid side effects: Health checks should not modify state.
- Fail fast: Quickly detect failures to trigger recovery.
Example: Kubernetes Probe Definitions
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 3
- Liveness probe checks the
/healthzendpoint to confirm the app is alive. - Readiness probe checks the
/readyendpoint to confirm the app is ready to serve traffic.
Example: Implementing Health and Readiness Endpoints in Node.js
const express = require('express');
const app = express();
let isDbConnected = false;
// Simulate DB connection
setTimeout(() => {
isDbConnected = true;
}, 10000); // DB connects after 10 seconds
app.get('/healthz', (req, res) => {
// Basic liveness check
res.status(200).send('OK');
});
app.get('/ready', (req, res) => {
// Readiness depends on DB connection
if (isDbConnected) {
res.status(200).send('Ready');
} else {
res.status(503).send('Not Ready');
}
});
app.listen(8080, () => {
console.log('Server started on port 8080');
});
This example shows a simple app that only becomes “ready” after the database connection is established.
Mind Map: Designing Probes for Complex Systems
Best Practices
- Separate liveness and readiness endpoints: They serve different purposes.
- Include dependency checks in readiness probes: For example, database or cache availability.
- Set appropriate timeouts and thresholds: Avoid false positives or prolonged downtime.
- Secure health endpoints: Avoid exposing sensitive information.
- Monitor probe results: Use alerts to detect systemic issues early.
Example: Readiness Probe with Dependency Check (Pseudo-code)
from flask import Flask, jsonify
import requests
app = Flask(__name__)
def check_database():
# Simulate DB check
try:
# db.ping()
return True
except Exception:
return False
@app.route('/healthz')
def healthz():
return jsonify(status='ok'), 200
@app.route('/ready')
def ready():
if check_database():
return jsonify(status='ready'), 200
else:
return jsonify(status='not ready'), 503
if __name__ == '__main__':
app.run(port=8080)
Summary
Designing health checks and readiness probes is critical for robust, highly available systems. By implementing lightweight, meaningful, and secure probes, you enable orchestration platforms and load balancers to maintain system health and deliver seamless user experiences.
Remember to tailor probes to your system’s complexity, dependencies, and operational requirements.
10.3 Alerting Strategies to Minimize Noise and Maximize Actionability
In high availability and scalable systems, alerting is a critical component of operational excellence. However, poorly designed alerting strategies can lead to alert fatigue, where engineers become desensitized to notifications due to excessive noise, ultimately increasing the risk of missing critical incidents. This section explores best practices and practical examples to design alerting systems that minimize noise and maximize actionability.
Key Principles of Effective Alerting
- Relevance: Alerts should be meaningful and directly tied to actionable issues.
- Prioritization: Differentiate alerts by severity to focus attention where it matters most.
- Context: Provide sufficient context in alerts to enable quick diagnosis.
- Noise Reduction: Avoid redundant or flapping alerts.
- Automation: Integrate with incident management tools for streamlined workflows.
Mind Map: Core Alerting Strategy Components
Threshold Tuning and Dynamic Baselines
Static thresholds often generate excessive alerts during normal fluctuations. Instead, consider:
- Dynamic thresholds: Use statistical models or machine learning to define normal behavior baselines.
- Anomaly detection: Trigger alerts only when metrics deviate significantly from expected patterns.
Example:
A web service monitors request latency. Instead of alerting when latency exceeds a fixed 200ms, it uses a moving average and standard deviation to alert only if latency exceeds the baseline by 3 standard deviations, reducing false positives during traffic spikes.
Severity Levels and Escalation Policies
Classify alerts into categories such as:
- Critical: Immediate action required (e.g., service down).
- Warning: Potential issues to monitor.
- Info: Informational alerts for awareness.
Escalation policies ensure critical alerts reach the right on-call engineers promptly.
Example:
An alert for database connectivity failure triggers a critical alert that pages the on-call engineer immediately, while a warning for increased error rates sends a notification to a Slack channel for team visibility.
Contextual Alerting
Include relevant metadata such as:
- Service/component name
- Recent deployment info
- Correlated logs or traces
- Suggested remediation steps or runbook links
This reduces time to resolution by enabling engineers to act without excessive investigation.
Example:
An alert for high CPU usage includes a link to the runbook describing steps to restart the affected service and a link to recent deployment logs to check if a new release caused the spike.
Noise Reduction Techniques
- Deduplication: Group similar alerts to avoid flooding.
- Suppression windows: Temporarily suppress alerts during known maintenance or deployments.
- Flapping detection: Identify and suppress alerts that frequently toggle between states.
Example:
During a rolling deployment, alerts related to transient errors are suppressed for 10 minutes to prevent noise, with a summary alert generated if issues persist beyond the window.
Mind Map: Noise Reduction Strategies
Automation and Integration
Integrate alerting with incident management platforms (PagerDuty, Opsgenie) and chat tools (Slack, MS Teams) to:
- Automatically create incidents
- Assign to appropriate teams
- Trigger auto-remediation scripts when possible
Example:
An alert for service degradation automatically creates a Jira ticket and notifies the responsible team in Slack, while a script attempts to restart the service before escalating.
Comprehensive Example: Designing an Alert for a Payment Processing Service
Scenario: The payment service experiences intermittent latency spikes impacting transaction times.
- Metric Monitored: Transaction latency
- Alerting Strategy:
- Use dynamic baseline anomaly detection rather than static thresholds.
- Classify alerts as Warning if latency is 2 standard deviations above baseline, Critical if 4 standard deviations.
- Include context: service version, recent deploy timestamp, and link to troubleshooting runbook.
- Deduplicate alerts within 5 minutes to avoid flooding.
- Suppress alerts during scheduled deployment windows.
- Integrate with PagerDuty for critical alerts and Slack for warnings.
Outcome: Engineers receive actionable, prioritized alerts with context, reducing noise and accelerating response.
Summary
Effective alerting balances sensitivity with specificity. By tuning thresholds, prioritizing alerts, enriching context, reducing noise, and automating workflows, teams can maintain high availability and scalability without succumbing to alert fatigue.
References & Further Reading:
- “Site Reliability Engineering” by Google - Chapter on Monitoring Distributed Systems
- Prometheus Alertmanager Documentation
- PagerDuty Alerting Best Practices
- “The Art of Monitoring” by James Turnbull
10.4 Example: Setting Up a Centralized Observability Stack with Prometheus, Grafana, and Jaeger
In modern distributed systems, observability is critical to maintain high availability and scalability. A centralized observability stack enables teams to collect, visualize, and analyze metrics, logs, and traces from multiple services in a unified manner. This section walks through setting up a robust observability stack using Prometheus for metrics, Grafana for visualization, and Jaeger for distributed tracing.
Why Centralized Observability?
- Unified View: Correlate metrics, logs, and traces across services.
- Faster Troubleshooting: Quickly identify bottlenecks and failures.
- Proactive Monitoring: Set alerts and detect anomalies early.
Components Overview
Step 1: Setting Up Prometheus
Prometheus collects and stores time-series metrics from instrumented applications and infrastructure.
- Installation: Use Docker or Kubernetes Helm chart.
# Run Prometheus with Docker
docker run -d --name prometheus -p 9090:9090 \
-v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
- Basic prometheus.yml example:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'my-service'
static_configs:
- targets: ['my-service:8080']
- Best Practice: Use service discovery (e.g., Kubernetes, Consul) for dynamic environments.
Step 2: Instrumenting Your Application for Metrics
- Use client libraries (Go, Java, Python, etc.) to expose
/metricsendpoint.
Example in Python (using prometheus_client):
from prometheus_client import start_http_server, Counter
import random
import time
REQUEST_COUNT = Counter('request_count', 'Total HTTP Requests')
if __name__ == '__main__':
start_http_server(8080)
while True:
REQUEST_COUNT.inc(random.randint(1, 5))
time.sleep(5)
Step 3: Setting Up Grafana
Grafana connects to Prometheus and other data sources to visualize metrics.
- Installation:
docker run -d --name=grafana -p 3000:3000 grafana/grafana
-
Add Prometheus Data Source:
- URL:
http://prometheus:9090 - Access: Server
- URL:
-
Create Dashboards: Use built-in templates or create custom panels.
Example Dashboard Panels:
- Request rate over time
- Error rate percentage
- CPU and memory usage
Step 4: Setting Up Jaeger for Distributed Tracing
Jaeger helps trace requests as they flow through microservices.
- Installation:
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 14250:14250 \
-p 9411:9411 \
jaegertracing/all-in-one:1.31
- Instrument your application: Use OpenTelemetry or Jaeger client libraries.
Example in Go:
import (
"github.com/opentracing/opentracing-go"
jaeger "github.com/uber/jaeger-client-go"
jaegercfg "github.com/uber/jaeger-client-go/config"
)
func initTracer() (opentracing.Tracer, io.Closer) {
cfg := jaegercfg.Configuration{
ServiceName: "my-service",
Sampler: &jaegercfg.SamplerConfig{
Type: "const",
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
},
}
tracer, closer, err := cfg.NewTracer()
if err != nil {
log.Fatalf("Could not initialize jaeger tracer: %s", err.Error())
}
opentracing.SetGlobalTracer(tracer)
return tracer, closer
}
- View traces: Access Jaeger UI at
http://localhost:16686.
Step 5: Correlating Metrics and Traces
- Use trace IDs as labels in Prometheus metrics to link traces and metrics.
- Grafana supports mixed dashboards with metrics and traces panels.
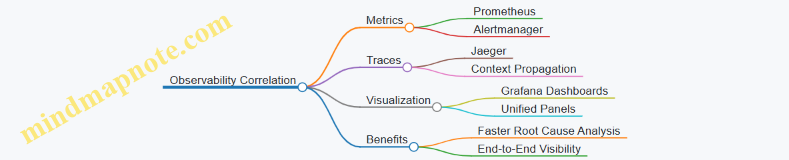
Step 6: Setting Up Alerting
- Configure Prometheus Alertmanager to send alerts (Slack, Email, PagerDuty).
Example alert rule:
groups:
- name: example_alerts
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "High error rate detected"
description: "More than 5% of requests are failing."
- Integrate alerts into Grafana for unified incident management.
Summary Mind Map
Final Best Practices
- Automate deployment using Infrastructure as Code (Helm, Terraform).
- Secure endpoints with authentication and TLS.
- Use sampling wisely to balance trace volume and cost.
- Regularly review and update dashboards and alerts based on evolving system behavior.
- Integrate logs (e.g., Loki, ELK stack) for full observability coverage.
By implementing this centralized observability stack, senior engineers and technical leads can achieve comprehensive visibility into their systems, enabling rapid detection and resolution of issues while supporting scalability and high availability goals.
10.5 Best Practices for Continuous Improvement Using Postmortems and Root Cause Analysis
Continuous improvement is essential for maintaining and enhancing the availability and scalability of complex systems. Postmortems and Root Cause Analysis (RCA) are foundational practices that help teams learn from incidents, prevent recurrence, and foster a culture of transparency and resilience.
What is a Postmortem?
A postmortem is a structured review conducted after an incident or outage to understand what happened, why it happened, and how to prevent it in the future. It focuses on facts, not blame, and aims to improve system reliability.
What is Root Cause Analysis (RCA)?
RCA is a methodical approach to identify the underlying causes of an incident rather than just addressing symptoms. It helps uncover systemic issues that might otherwise go unnoticed.
Key Best Practices for Effective Postmortems and RCA
Establish a Blameless Culture
- Encourage open and honest communication.
- Focus on learning rather than blaming individuals.
Document Incidents Thoroughly
- Capture timelines, system states, logs, and alerts.
- Include all relevant stakeholders in the documentation.
Use Structured Frameworks for RCA
- Techniques such as the “5 Whys”, Fishbone (Ishikawa) diagrams, and Fault Tree Analysis.
Identify Both Technical and Process Root Causes
- Look beyond code or infrastructure failures to organizational or procedural gaps.
Prioritize Actionable and Measurable Improvements
- Define clear remediation steps with owners and deadlines.
Share Findings Transparently
- Distribute postmortem reports across teams to spread knowledge.
Track and Follow Up on Action Items
- Ensure that corrective actions are implemented and verified.
Automate Incident Detection and Data Collection
- Use monitoring and observability tools to gather data automatically.
Conduct Regular Postmortem Reviews
- Schedule periodic reviews to assess trends and systemic risks.
Mind Map: Postmortem Process Overview
Mind Map: Root Cause Analysis Techniques
Example: Postmortem for a Distributed Cache Outage
Incident Summary: At 03:15 UTC, the distributed cache cluster experienced a partial outage causing increased latency and errors in the web application.
Timeline:
- 03:15: Monitoring alerts triggered high cache miss rates.
- 03:20: Engineers identified a network partition between cache nodes.
- 03:30: Failover procedures initiated.
- 03:45: Cache cluster stabilized.
Root Cause Analysis (5 Whys):
- Why did cache miss rates spike? Because some cache nodes were unreachable.
- Why were nodes unreachable? Because of a network partition.
- Why did the network partition occur? Because a router firmware update caused instability.
- Why was the update applied without rollback testing? Because deployment process lacked a staging environment.
- Why was there no staging environment? Because of resource constraints and prioritization.
Action Items:
- Implement a staging environment for network device updates (Owner: Network Team, Due: 2 weeks).
- Automate rollback procedures for network firmware updates (Owner: DevOps, Due: 1 month).
- Enhance monitoring to detect network instability earlier (Owner: SRE, Due: 3 weeks).
Outcome: The postmortem was shared across engineering and operations teams. Follow-up reviews confirmed implementation of fixes and improved incident response times.
Example: Using Fishbone Diagram for Latency Spike
Latency Spike Incident
├── People
│ ├── Insufficient training on new deployment
│ └── Lack of on-call coverage
├── Process
│ ├── Incomplete deployment checklist
│ └── No rollback plan
├── Technology
│ ├── Memory leak in service
│ └── Inefficient database queries
└── Environment
├── High traffic volume
└── Network congestion
By analyzing each category, teams can identify multiple contributing factors and address them holistically.
Tips for Writing Effective Postmortem Reports
- Use clear, concise language.
- Include visual aids like timelines and diagrams.
- Highlight lessons learned explicitly.
- Avoid jargon to ensure accessibility.
- Emphasize next steps and accountability.
Summary
Continuous improvement through postmortems and RCA enables teams to build more resilient, scalable systems by learning from failures. By adopting a blameless culture, using structured analysis techniques, and following up on actionable improvements, organizations can reduce incident frequency and impact over time.
Further Reading & Tools
- “The Site Reliability Workbook” by Betsy Beyer et al.
- “Accelerate” by Nicole Forsgren et al.
- Tools: Jira, Confluence, Miro (for diagrams), PagerDuty, Prometheus, Grafana
Embracing these best practices will help senior engineers and technical leads foster a culture of reliability and continuous learning, critical for high availability and scalable applications.
11. Case Studies: Real-World Applications of Advanced Patterns
11.1 High Availability Design in a Global E-Commerce Platform
Designing a high availability (HA) system for a global e-commerce platform involves addressing multiple challenges such as handling massive traffic spikes, ensuring zero downtime during deployments, and maintaining data consistency across geographically distributed regions. This section explores an advanced HA design with practical examples and mind maps to help senior software engineers and technical leads architect resilient e-commerce systems.
Key Requirements for High Availability in Global E-Commerce
- 99.99% uptime to ensure continuous shopping experience
- Global low-latency access for users worldwide
- Fault tolerance to handle failures gracefully
- Data consistency for orders, inventory, and payments
- Scalable infrastructure to handle flash sales and seasonal peaks
Mind Map: High Availability Design Components
Multi-Region Deployment for Fault Isolation and Low Latency
Best Practice: Deploy application instances across multiple geographic regions (e.g., US-East, EU-West, AP-South) to reduce latency and provide fault isolation.
Example:
- Use cloud provider regions and availability zones.
- Employ Global DNS Load Balancing (e.g., AWS Route 53 latency-based routing) to direct users to the nearest healthy region.
- Implement Active-Active deployment so all regions serve traffic simultaneously, improving availability.
Mind Map:
Load Balancing and Traffic Management
Best Practice: Use a combination of global and regional load balancers to distribute traffic efficiently.
Example:
- Global Load Balancer routes traffic to regional load balancers.
- Regional load balancers distribute requests to multiple application instances.
- Health checks ensure traffic is only sent to healthy instances.
Example Diagram:
User -> Global DNS LB -> Regional LB -> App Instances
Data Layer: Geo-Distributed Databases with Multi-Master Replication
Best Practice: Use multi-master replication to allow writes in multiple regions while maintaining eventual consistency.
Example:
- Use databases like Cassandra, CockroachDB, or DynamoDB Global Tables.
- Conflict resolution strategies to handle concurrent updates (e.g., last-write-wins, vector clocks).
Mind Map:
Caching Strategies for Performance and Availability
Best Practice: Implement multi-level caching to reduce database load and improve response times.
Example:
- Use CDNs (e.g., Cloudflare, Akamai) for static assets.
- Employ distributed caches (e.g., Redis, Memcached) close to application servers.
- Cache product catalog and pricing data with TTL-based invalidation.
Example:
User Request -> CDN Cache -> App Cache -> Database
Resilient Application Architecture
Best Practice: Design microservices with fault isolation and graceful degradation.
Example:
- Use Circuit Breaker pattern to prevent cascading failures when a downstream service is slow or unavailable.
- Apply Bulkhead pattern to isolate resources for critical services like payment processing.
Code Snippet (Circuit Breaker Pseudocode):
if circuit_breaker.is_open():
return fallback_response()
try:
response = downstream_service.call()
circuit_breaker.record_success()
return response
except Exception:
circuit_breaker.record_failure()
return fallback_response()
Event-Driven Order Processing
Best Practice: Decouple order processing using asynchronous messaging to improve availability and scalability.
Example:
- Orders are published to a message queue (e.g., Kafka, RabbitMQ).
- Multiple consumers process orders independently (inventory check, payment, shipping).
- Use Dead Letter Queues to handle failed messages for manual inspection.
Mind Map:
Monitoring, Health Checks, and Automated Recovery
Best Practice: Implement comprehensive monitoring and proactive recovery mechanisms.
Example:
- Use Prometheus and Grafana to monitor latency, error rates, and resource utilization.
- Health endpoints for readiness and liveness probes in Kubernetes.
- Automate failover and scaling based on metrics.
- Employ chaos engineering tools (e.g., Chaos Monkey) to simulate failures and validate resilience.
Summary
Building a highly available global e-commerce platform requires a holistic approach combining multi-region deployments, resilient microservices, geo-distributed data, caching, and event-driven architectures. Integrating these patterns with robust monitoring and automation ensures the platform can handle failures gracefully and scale seamlessly during peak demand.
Additional Resources
- Designing Data-Intensive Applications by Martin Kleppmann
- AWS Well-Architected Framework - Reliability Pillar
- Circuit Breaker Pattern - Martin Fowler
- Chaos Engineering Principles
11.2 Scalable Messaging Architecture in a Social Media Application
Designing a scalable messaging architecture for a social media application involves addressing several critical challenges: high throughput, low latency, fault tolerance, message ordering, and eventual consistency. This section explores how advanced messaging patterns and best practices can be applied to build a resilient and scalable messaging system that supports millions of users exchanging messages in real-time.
Key Requirements and Challenges
- High Throughput: Support millions of messages per second.
- Low Latency: Deliver messages with minimal delay.
- Fault Tolerance: Ensure no message loss during failures.
- Ordering Guarantees: Preserve message order within conversations.
- Scalability: Seamlessly handle user growth and traffic spikes.
- Durability: Persist messages reliably.
Core Components of the Messaging Architecture
Messaging Patterns Applied
Publish-Subscribe Pattern
- Users publish messages to topics representing chat rooms or direct message channels.
- Subscribers (other users or services) receive messages asynchronously.
- Decouples producers and consumers, improving scalability.
Message Queues with Partitioning
- Partition messages by conversation ID to maintain ordering.
- Enables parallel processing and load distribution.
Event Sourcing
- Store all message events as immutable logs.
- Allows replaying events for recovery or analytics.
Dead Letter Queues (DLQ)
- Capture undeliverable or malformed messages.
- Enables troubleshooting and retry mechanisms.
Example Architecture Flow
sequenceDiagram
participant User as User Client
participant Broker as Message Broker
participant Storage as Message Storage
participant Delivery as Real-time Delivery Service
User->>Broker: Publish message to topic (e.g., chat-room-123)
Broker->>Storage: Persist message event
Broker->>Delivery: Push message to subscribers
Delivery->>User: Deliver message in real-time
Delivery-->>Broker: Acknowledge delivery
Practical Example: Implementing a Scalable Messaging System with Apache Kafka
Scenario: Users send direct messages and group chat messages. The system must guarantee message ordering per conversation and scale horizontally.
-
Topic Design:
- Create Kafka topics per message type (e.g.,
direct-messages,group-messages). - Use partition key as conversation ID to ensure ordering within a conversation.
- Create Kafka topics per message type (e.g.,
-
Producer Implementation:
- User clients publish messages to Kafka topics via a REST API or WebSocket gateway.
- The producer assigns the partition key based on conversation ID.
-
Consumer Implementation:
- Multiple consumer instances subscribe to topics.
- Each consumer processes messages from assigned partitions, ensuring ordered processing.
-
Message Persistence:
- Consumers write messages to a durable database (e.g., Cassandra, DynamoDB) for long-term storage.
-
Real-Time Delivery:
- Delivery service pushes messages to online users via WebSocket or push notifications.
-
Failure Handling:
- Use Kafka’s offset management for exactly-once or at-least-once processing.
- Dead Letter Queue captures failed messages for manual inspection.
Mind Map: Kafka-Based Messaging Flow
Best Practices
- Partition by Conversation: Guarantees ordering and enables parallelism.
- Idempotent Producers and Consumers: Avoid duplicate message processing.
- Backpressure and Rate Limiting: Protect system from overload.
- Monitoring and Alerting: Track message lag, consumer health, and throughput.
- Data Retention Policies: Balance storage costs and recovery needs.
Additional Example: Using RabbitMQ for Real-Time Chat
- Use RabbitMQ exchanges with topic routing keys representing chat rooms.
- Consumers bind queues to exchanges with routing keys for selective message delivery.
- Implement consumer acknowledgments and message TTL for reliability.
sequenceDiagram
participant User as User Client
participant Exchange as RabbitMQ Exchange
participant Queue as RabbitMQ Queue
participant Consumer as Chat Service
User->>Exchange: Publish message with routing key (chat.room.123)
Exchange->>Queue: Route message based on binding
Consumer->>Queue: Consume message
Consumer->>User: Deliver message
Summary
Building a scalable messaging architecture for social media requires combining messaging patterns like publish-subscribe, partitioned queues, and event sourcing. Leveraging robust message brokers such as Kafka or RabbitMQ, along with best practices like partitioning by conversation ID and implementing dead letter queues, ensures high availability, fault tolerance, and low latency. This architecture supports millions of concurrent users while maintaining message order and durability.
By integrating monitoring, rate limiting, and failure handling, technical leads and senior engineers can design messaging systems that scale gracefully and provide a seamless user experience.
11.3 Disaster Recovery Implementation in a Healthcare System
Designing a disaster recovery (DR) plan for a healthcare system is a critical task due to the sensitive nature of patient data, regulatory compliance requirements (such as HIPAA), and the need for uninterrupted availability of healthcare services. This section explores a comprehensive approach to implementing DR in healthcare, weaving best practices and examples with mind maps to clarify complex concepts.
Key Objectives in Healthcare Disaster Recovery
- Data Integrity and Confidentiality: Ensuring patient data is accurate and secure.
- Minimal Downtime: Healthcare systems must be available 24/7; downtime can risk patient safety.
- Regulatory Compliance: Adhering to standards like HIPAA, GDPR.
- Rapid Recovery: Quick restoration of services and data after an incident.
Mind Map: Disaster Recovery Components in Healthcare Systems
Data Backup Strategies
Healthcare data is voluminous and sensitive. A layered backup strategy is essential.
Example:
- Full Backups: Weekly full backups stored in encrypted offsite cloud storage.
- Incremental Backups: Nightly incremental backups to reduce storage and speed.
- Immutable Storage: Use of Write Once Read Many (WORM) storage to prevent tampering.
Best Practice: Automate backup verification to ensure data integrity.
Recovery Objectives: RPO and RTO
- RPO (Recovery Point Objective): Maximum acceptable data loss measured in time.
- RTO (Recovery Time Objective): Maximum acceptable downtime.
Example:
- For Electronic Health Records (EHR), RPO might be 15 minutes, RTO under 1 hour.
Mind Map: Recovery Objectives
Failover Mechanisms
Failover ensures system availability by switching to a standby system when the primary fails.
Active-Passive Failover:
- Primary system handles all traffic.
- Secondary system remains on standby.
- Example: A hospital’s patient management system uses an active database cluster in the primary data center and a passive replica in a geographically distant site.
Active-Active Failover:
- Multiple systems actively handle traffic.
- Provides load balancing and redundancy.
- Example: Telemedicine platform with active-active clusters across regions to ensure zero downtime.
Best Practice: Regularly test failover to ensure seamless switching.
Testing and Drills
Regular testing validates the DR plan’s effectiveness.
Example:
- Quarterly DR drills simulate data center outages.
- Use of chaos engineering tools to randomly inject failures in non-production environments.
Mind Map: Testing and Drills
Security Considerations
Security must be integrated into DR to protect sensitive healthcare data.
Example:
- Data encrypted at rest and in transit during backups and replication.
- Multi-factor authentication for DR environment access.
Best Practice: Maintain audit logs for all DR-related activities to support compliance.
Compliance and Audit
Healthcare systems must comply with regulations like HIPAA.
Example:
- Automated audit logging during DR operations.
- Regular compliance reviews and updates to DR policies.
Practical Example: Disaster Recovery Plan for a Healthcare System
Scenario: A regional hospital network with multiple clinics and a centralized EHR system.
- Backup: Nightly incremental backups and weekly full backups stored encrypted in a cloud provider’s geographically separate region.
- Failover: Active-passive failover between primary data center and cloud DR site.
- RPO/RTO: RPO of 15 minutes, RTO of 30 minutes.
- Testing: Monthly DR drills involving failover to cloud site.
- Security: End-to-end encryption, strict access controls, and audit logging.
Outcome: When a ransomware attack disables the primary data center, the hospital fails over to the cloud DR site within 20 minutes, with no patient data loss and minimal service disruption.
Summary
Implementing disaster recovery in healthcare systems requires a balanced approach that addresses data integrity, availability, security, and compliance. By leveraging layered backups, clear recovery objectives, robust failover mechanisms, regular testing, and stringent security controls, healthcare providers can ensure continuous patient care even in the face of disasters.
For further reading, consider exploring NIST SP 800-34 Rev.1 for contingency planning and HIPAA Security Rule guidelines.
11.4 Autoscaling and Caching in a SaaS Analytics Platform
Designing a SaaS analytics platform that can handle unpredictable workloads while maintaining low latency and high availability is a complex challenge. Autoscaling and caching are two critical system design patterns that, when combined effectively, enable the platform to scale elastically and deliver fast responses to users.
Autoscaling in SaaS Analytics Platforms
Autoscaling dynamically adjusts the number of running instances or resources based on current demand, ensuring optimal resource utilization and cost efficiency.
Key Autoscaling Strategies:
- Horizontal Autoscaling: Adding or removing instances (e.g., containers, VMs) based on metrics like CPU usage, request rate, or custom business metrics.
- Vertical Autoscaling: Increasing or decreasing resource capacity (CPU, memory) of existing instances.
- Predictive Autoscaling: Using historical data and machine learning to anticipate load spikes and scale proactively.
- Queue-Based Autoscaling: Scaling based on the length of processing queues or backlog.
Example: Horizontal Autoscaling with Kubernetes
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: analytics-worker-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: analytics-worker
minReplicas: 3
maxReplicas: 30
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
This HPA configuration scales the analytics worker pods between 3 and 30 replicas, targeting 70% average CPU utilization.
Caching Strategies in SaaS Analytics Platforms
Caching reduces latency and backend load by storing frequently accessed data closer to the application or user.
Common Caching Patterns:
- Cache Aside: Application checks cache first; if a miss, fetches from DB and populates cache.
- Read-Through: Cache automatically loads data on a miss.
- Write-Through: Writes go through cache and persist to DB synchronously.
- Write-Back: Writes are cached and asynchronously persisted later.
Cache Layers:
- In-Memory Cache: Fast, ephemeral cache (e.g., Redis, Memcached) for hot data.
- CDN Caching: Edge caching for static assets and pre-aggregated reports.
- Application-Level Cache: Local caches within application instances for ultra-low latency.
Example: Cache Aside Pattern for Query Results
import redis
cache = redis.Redis(host='redis-cache', port=6379)
def get_analytics_report(user_id, query_params):
cache_key = f"report:{user_id}:{hash(frozenset(query_params.items()))}"
cached_report = cache.get(cache_key)
if cached_report:
return deserialize(cached_report)
# Cache miss: fetch from DB
report = fetch_report_from_db(user_id, query_params)
cache.set(cache_key, serialize(report), ex=3600) # Cache for 1 hour
return report
Integrating Autoscaling and Caching: Mind Map
Practical Example: Autoscaling and Caching in Action
Imagine a SaaS analytics platform where users run complex queries generating reports. During peak hours, query volume spikes unpredictably.
-
Autoscaling: The platform uses Kubernetes HPA to scale analytics worker pods based on CPU and request latency metrics. When CPU utilization exceeds 70%, new pods spin up automatically.
-
Caching: To reduce repeated heavy computations, query results are cached in Redis using the cache-aside pattern with a 1-hour TTL. This reduces backend load and improves response times.
-
Combined Effect: When a new pod is added, it connects to the shared Redis cache, ensuring cached data is reused across instances. Autoscaling ensures enough compute capacity, while caching reduces redundant work.
Best Practices Summary
- Monitor multiple metrics: Combine CPU, memory, request latency, and queue length for autoscaling triggers.
- Implement cache invalidation: Use TTLs and event-driven invalidation to keep cache fresh.
- Design for cold starts: Use warm-up strategies or predictive autoscaling to avoid latency spikes.
- Use distributed caches: Ensure cache is shared across scaled instances to maximize hit rates.
- Test autoscaling under load: Simulate traffic spikes to validate scaling policies.
By thoughtfully combining autoscaling and caching, SaaS analytics platforms can achieve the elasticity and responsiveness required to serve diverse and demanding workloads efficiently.
11.5 Lessons Learned and Common Pitfalls in Large-Scale System Design
Designing large-scale systems is a complex endeavor that requires balancing multiple competing factors such as scalability, availability, consistency, and maintainability. Over years of experience, several lessons have emerged that can help technical leads and senior engineers avoid common pitfalls and build robust, scalable architectures.
Key Lessons Learned
Prioritize Simplicity Over Premature Optimization
- Lesson: Complex designs often introduce hidden failure modes and increase maintenance overhead.
- Example: A team initially implemented a multi-master database replication with complex conflict resolution. The system suffered frequent data inconsistencies. Simplifying to a single-master with asynchronous replicas improved reliability.
Design for Failure from Day One
- Lesson: Assume components will fail; build fault tolerance and graceful degradation.
- Example: Netflix’s Chaos Monkey is a famous tool to inject failures to validate system resilience.
Understand Your Consistency and Availability Trade-offs
- Lesson: CAP theorem constraints mean you cannot have perfect consistency, availability, and partition tolerance simultaneously.
- Example: A social media feed system chose eventual consistency to maintain availability during network partitions, accepting slight delays in data propagation.
Avoid Single Points of Failure (SPOF)
- Lesson: SPOFs can bring down entire systems; redundancy and failover mechanisms are essential.
- Example: An e-commerce platform initially had a single load balancer; it became a bottleneck and SPOF. Introducing multiple load balancers with DNS failover improved uptime.
Monitor Early and Continuously
- Lesson: Without observability, diagnosing issues in complex systems is near impossible.
- Example: A SaaS provider integrated centralized logging and metrics from day one, enabling rapid detection and resolution of performance regressions.
Automate Deployment and Recovery Processes
- Lesson: Manual interventions slow down recovery and increase human error.
- Example: Using Infrastructure as Code (IaC) and automated rollback strategies reduced downtime during deployments.
Plan for Data Growth and Scaling Bottlenecks
- Lesson: Systems that work well at small scale may fail catastrophically at large scale.
- Example: A messaging system initially used a single database shard; as user base grew, it faced write contention. Sharding and partitioning strategies resolved the bottleneck.
Embrace Incremental and Iterative Design
- Lesson: Big-bang designs rarely succeed; incremental improvements allow learning and adaptation.
- Example: A video streaming service rolled out caching layers progressively, measuring impact and tuning configurations.
Common Pitfalls and How to Avoid Them
Detailed Examples of Pitfalls
Over-Engineering Example
A startup designed a microservices architecture with dozens of services before validating product-market fit. The complexity slowed development and introduced integration bugs. Simplifying to a monolith initially allowed faster iteration and more stable releases.
Ignoring Failure Scenarios Example
An online payment system did not implement circuit breakers on downstream payment gateways. When the gateway became slow, requests piled up causing thread exhaustion and system-wide outages. Adding circuit breakers and bulkheads isolated failures.
Poor Capacity Planning Example
A social networking app underestimated peak traffic during events. Their database connections maxed out, causing timeouts and user complaints. Implementing connection pooling and horizontal scaling mitigated the issue.
Inadequate Monitoring Example
A cloud service provider lacked centralized logging. When a critical bug caused data loss, the team struggled to identify root cause. Introducing centralized observability tools improved incident response times.
Tight Coupling Example
A monolithic application tightly coupled UI and backend logic. Scaling the backend independently was impossible, leading to resource wastage. Refactoring into loosely coupled services enabled independent scaling.
Neglecting Security Example
A public API lacked rate limiting, leading to DDoS attacks that degraded service availability. Implementing throttling and API gateways restored stability.
Data Consistency Mismanagement Example
A collaborative document editing app used eventual consistency without proper conflict resolution, resulting in lost user changes. Introducing operational transformation algorithms improved consistency.
Manual Processes Example
A company deployed updates manually across multiple data centers, causing configuration drift and inconsistent versions. Automating deployments with CI/CD pipelines ensured uniformity and faster rollbacks.
Summary Mind Map
Final Recommendations
- Start simple and evolve: Build minimal viable architecture and iterate.
- Automate everything: From testing to deployment and recovery.
- Invest in observability: Metrics, logs, and tracing are your eyes and ears.
- Test failure scenarios: Use chaos engineering to validate resilience.
- Educate your team: Share lessons learned and encourage best practices.
By internalizing these lessons and avoiding common pitfalls, teams can design large-scale systems that are not only scalable and highly available but also maintainable and secure.
12. Future Trends and Emerging Patterns
12.1 Serverless Architectures and Their Impact on Scalability
Serverless architecture represents a paradigm shift in how applications are designed, deployed, and scaled. By abstracting away server management, it allows developers to focus purely on business logic while the cloud provider handles infrastructure concerns such as provisioning, scaling, and maintenance.
What is Serverless Architecture?
Serverless computing is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. The term “serverless” is a bit of a misnomer because servers are still involved, but the key point is that developers do not have to manage or provision them.
Key Characteristics of Serverless:
- Event-driven: Functions are triggered by events such as HTTP requests, database changes, or message queue events.
- Ephemeral: Functions are stateless and short-lived.
- Auto-scaling: The platform automatically scales the number of function instances based on demand.
- Pay-per-use: Billing is based on actual usage (e.g., number of executions, execution time).
Mind Map: Serverless Architecture Overview
Impact on Scalability
Serverless architectures inherently provide fine-grained scalability. Each function invocation is independent and can scale horizontally without manual intervention. This model suits unpredictable or spiky workloads exceptionally well.
How Serverless Enhances Scalability:
- Automatic Horizontal Scaling: The platform spins up multiple instances of functions in response to incoming events.
- No Capacity Planning: Developers do not need to estimate or provision capacity ahead of time.
- Granular Scaling: Functions scale individually, allowing parts of the system to scale based on their own demand.
Example:
Consider an image processing service that resizes images uploaded by users. Using serverless functions, each image upload triggers a function that processes the image. If 10,000 images are uploaded simultaneously, the platform automatically runs 10,000 function instances in parallel without any manual scaling.
Mind Map: Serverless Scalability Benefits
Best Practices for Designing Scalable Serverless Applications
- Design Stateless Functions: Ensure functions do not rely on local state to allow easy scaling.
- Use Managed Services for State: Offload state management to databases, caches, or object storage.
- Optimize Cold Starts: Keep functions lightweight, use provisioned concurrency if supported.
- Implement Idempotency: Functions may be retried; ensure safe repeated executions.
- Monitor and Set Concurrency Limits: Avoid throttling and understand platform limits.
Example: Serverless Order Processing System
Scenario: An e-commerce platform uses serverless functions to handle order processing.
- Event Source: HTTP API Gateway receives order requests.
- Function 1: Validates order details.
- Function 2: Processes payment asynchronously via event queue.
- Function 3: Updates inventory and sends confirmation email.
Scalability Impact:
- Each function scales independently based on workload.
- Payment processing can scale separately, handling spikes during sales.
- No server provisioning needed even during peak traffic.
Challenges and Considerations
- Cold Start Latency: Initial invocation can be slower; mitigated by provisioned concurrency or keeping functions warm.
- Execution Time Limits: Serverless functions often have max execution durations (e.g., 15 minutes).
- Vendor Lock-in: Heavy reliance on proprietary services can limit portability.
- Debugging and Monitoring: Distributed nature requires robust observability tooling.
Summary
Serverless architectures dramatically simplify scalability by offloading infrastructure management to cloud providers. By leveraging event-driven, stateless functions, applications can elastically scale to meet demand without upfront capacity planning. However, understanding the trade-offs and designing with best practices is critical to harness the full potential of serverless for highly available and scalable applications.
12.2 AI-Driven System Optimization and Self-Healing Patterns
As modern systems grow increasingly complex and dynamic, traditional manual tuning and reactive maintenance approaches become insufficient. AI-driven system optimization and self-healing patterns leverage machine learning (ML) and artificial intelligence (AI) techniques to proactively monitor, analyze, and adjust system behavior in real-time, improving reliability, performance, and availability.
What is AI-Driven System Optimization?
AI-driven system optimization refers to the use of AI/ML algorithms to automatically analyze system metrics, predict potential issues, and optimize configurations or resource allocations without human intervention.
What are Self-Healing Systems?
Self-healing systems detect anomalies or failures and automatically take corrective actions to restore normal operation, minimizing downtime and manual intervention.
Mind Map: AI-Driven System Optimization and Self-Healing Patterns
Core Components and Workflow
-
Data Collection & Monitoring:
- Continuous gathering of telemetry data such as resource usage, request latencies, error rates, and system logs.
-
Anomaly Detection:
- AI models analyze data streams to detect deviations from normal behavior.
- Example: Using unsupervised learning (e.g., Isolation Forest, Autoencoders) to spot unusual CPU spikes.
-
Predictive Analytics:
- Forecast future system states or failures based on historical trends.
- Example: Predicting disk failures or memory leaks before they impact availability.
-
Decision Making & Optimization:
- Reinforcement learning or rule-based AI selects optimal actions such as scaling, load balancing, or configuration changes.
-
Self-Healing Execution:
- Automated remediation steps like restarting failed services, rerouting traffic, or activating circuit breakers.
-
Feedback Loop:
- System continuously evaluates the impact of actions and retrains models to improve accuracy.
Example 1: AI-Driven Autoscaling in Kubernetes
Scenario: A microservices-based application experiences unpredictable traffic spikes.
Implementation:
- Collect pod-level CPU, memory, and request latency metrics.
- Train an ML model to predict traffic surges 5 minutes in advance.
- Use predictions to proactively scale pods horizontally before load increases.
- If a pod crashes, self-healing controllers automatically restart it.
Benefits:
- Reduced latency during spikes.
- Lower risk of resource exhaustion.
- Minimized manual intervention.
Example 2: Self-Healing Database Cluster
Scenario: A distributed database cluster occasionally suffers from node failures causing degraded performance.
Implementation:
- Monitor node health and query latency.
- Use anomaly detection to identify slow queries or failing nodes.
- Automatically trigger failover to healthy replicas.
- Restart or isolate problematic nodes.
- Log actions and outcomes for continuous learning.
Benefits:
- Improved uptime and data availability.
- Faster recovery from failures.
Mind Map: AI Techniques Applied
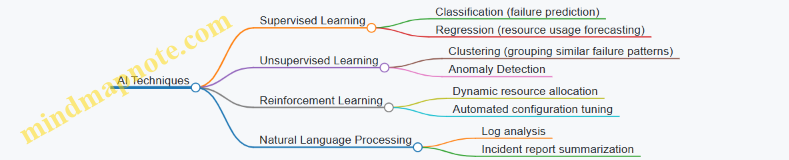
Best Practices
- Data Quality: Ensure high-quality, representative telemetry data for training AI models.
- Explainability: Use interpretable models or provide explanations for AI-driven decisions to build trust.
- Fail-Safe Mechanisms: Always maintain manual override capabilities to prevent unintended disruptions.
- Incremental Rollouts: Gradually deploy AI-driven optimizations to monitor impact and avoid cascading failures.
- Continuous Learning: Regularly retrain models with new data to adapt to evolving system behavior.
Summary
AI-driven system optimization and self-healing patterns represent a paradigm shift in designing resilient, scalable systems. By embedding intelligence into monitoring and control loops, systems can proactively adapt to changing conditions, reduce downtime, and optimize resource usage — all critical for meeting modern SLAs and user expectations.
12.3 Edge Computing for Low Latency and High Availability
Introduction
Edge computing is an architectural paradigm that brings computation and data storage closer to the sources of data, such as IoT devices, mobile devices, or local edge servers. By processing data near its origin, edge computing reduces latency, conserves bandwidth, and enhances system availability. This section explores how edge computing patterns can be leveraged to build low latency and highly available applications.
Why Edge Computing?
- Latency Reduction: Processing data locally avoids round-trip delays to centralized cloud data centers.
- Bandwidth Optimization: Only relevant or aggregated data is sent upstream, reducing network load.
- Resilience and Availability: Local processing enables continued operation even when connectivity to the cloud is intermittent or lost.
Core Concepts and Patterns in Edge Computing
Mind Map: Edge Computing Core Concepts
Edge Computing Architectural Patterns
-
Local Data Processing Pattern
- Process data at the edge node before sending to the cloud.
- Example: A smart factory sensor node aggregates temperature readings locally and only sends alerts or summaries upstream.
-
Edge Caching Pattern
- Cache frequently accessed data at edge nodes to reduce latency.
- Example: Content Delivery Networks (CDNs) cache video content at edge servers close to users.
-
Edge Aggregation Pattern
- Aggregate data from multiple edge devices before forwarding.
- Example: A gateway collects sensor data from multiple IoT devices, performs filtering, and sends aggregated data to the cloud.
-
Offline-First Pattern
- Design edge applications to operate fully or partially offline and sync with the cloud when connectivity is restored.
- Example: Mobile POS systems that continue transactions offline and sync sales data later.
-
Hierarchical Edge Pattern
- Multi-tier edge nodes with different processing capabilities, e.g., device edge, local edge server, regional edge data center.
- Example: Autonomous vehicles process sensor data locally, send aggregated data to roadside edge servers, which then forward to central cloud.
Example: Smart Traffic Management System
Scenario: A city implements a smart traffic management system to optimize traffic flow and reduce congestion.
- Edge Devices: Cameras and sensors at intersections detect vehicle counts and speeds.
- Local Edge Servers: Process sensor data in real-time to adjust traffic light timings locally.
- Regional Edge Data Centers: Aggregate data from multiple intersections to analyze traffic patterns.
- Cloud Backend: Performs long-term analytics and machine learning model training.
Benefits:
- Real-time traffic light adjustments reduce wait times (low latency).
- Local edge servers continue functioning even if connectivity to cloud is lost (high availability).
Mind Map: Edge Computing in Smart Traffic Management
Best Practices for Implementing Edge Computing
- Design for Intermittent Connectivity: Use offline-first and eventual consistency models.
- Data Prioritization: Process critical data locally; defer non-urgent data transmission.
- Security at the Edge: Encrypt data, use secure hardware modules, and implement authentication.
- Monitoring and Observability: Collect telemetry from edge nodes for health and performance monitoring.
- Automated Updates: Implement secure and reliable mechanisms to update edge software remotely.
Additional Example: Video Streaming with Edge Caching
- Problem: Delivering high-quality video streams with minimal buffering.
- Solution: Use edge caching servers located close to users to store popular content.
- Outcome: Reduced latency, improved user experience, and decreased backbone network traffic.
Summary
Edge computing is a powerful approach to achieve low latency and high availability by decentralizing computation and storage closer to data sources. By adopting edge computing patterns such as local processing, caching, aggregation, and hierarchical edge tiers, architects can build resilient, scalable systems that perform well under varying network conditions.
12.4 Quantum Computing and Its Potential Influence on System Design
Quantum computing represents a paradigm shift in computation, leveraging principles of quantum mechanics such as superposition, entanglement, and quantum interference to solve problems that are intractable for classical computers. While still in its nascent stages, quantum computing has the potential to profoundly influence system design, especially in areas demanding massive parallelism, complex optimization, and cryptographic security.
Understanding Quantum Computing Basics
- Qubits: Unlike classical bits, qubits can represent 0, 1, or both simultaneously (superposition).
- Entanglement: Qubits can be correlated in ways that classical bits cannot, enabling complex state relationships.
- Quantum Gates: Operations that manipulate qubits, analogous to logic gates in classical computing.
Mind Map: Quantum Computing Core Concepts
Potential Influences on System Design
-
Algorithmic Acceleration
- Quantum algorithms like Shor’s (factoring) and Grover’s (search) can drastically reduce computational complexity.
- Example: Cryptographic systems relying on RSA may require redesign to quantum-resistant algorithms.
-
Hybrid Classical-Quantum Architectures
- Systems will likely integrate classical and quantum processors, requiring new orchestration and communication patterns.
- Example: A cloud service offering quantum acceleration for specific workloads (e.g., optimization).
-
Data Security and Cryptography
- Quantum computing threatens current encryption methods, pushing system architects to adopt post-quantum cryptography.
- Example: Designing key management systems that support quantum-safe algorithms.
-
New Scalability Models
- Quantum processors may handle specific tasks exponentially faster, shifting bottlenecks to data I/O and classical integration.
- Example: Systems designed with modular quantum co-processors for specialized tasks.
-
Fault Tolerance and Error Correction
- Quantum systems are highly error-prone; system design must incorporate quantum error correction and fault-tolerant protocols.
- Example: Architecting middleware that abstracts quantum error correction from application logic.
Mind Map: Quantum Computing Impact on System Design
Example: Designing a Hybrid Quantum-Classical Financial Risk Analysis System
Scenario: A financial institution wants to leverage quantum computing to accelerate portfolio optimization, a computationally intensive task.
System Design Considerations:
- Hybrid Architecture: Classical servers handle data ingestion, preprocessing, and post-processing; quantum processors perform the core optimization.
- Communication Layer: A high-throughput, low-latency messaging system connects classical and quantum components.
- Fault Tolerance: Middleware manages retries and error correction when quantum computations fail or decohere.
- Security: Data is encrypted using quantum-resistant algorithms during transmission and storage.
Workflow:
- Classical system collects and cleans financial data.
- Data is encoded into quantum states and sent to the quantum processor.
- Quantum processor runs optimization algorithms (e.g., Quantum Approximate Optimization Algorithm).
- Results are returned to the classical system for validation and integration.
Mind Map: Hybrid Quantum-Classical System Design Example
Best Practices for Integrating Quantum Computing into System Design
- Start Small with Hybrid Models: Begin by offloading specific tasks to quantum processors rather than full system redesign.
- Design for Modularity: Keep quantum components loosely coupled to classical systems to allow independent evolution.
- Plan for Security Evolution: Incorporate post-quantum cryptographic algorithms early to future-proof systems.
- Invest in Observability: Quantum computations are probabilistic; build monitoring and logging to understand quantum-classical interactions.
- Collaborate with Quantum Experts: Quantum computing is a specialized domain; cross-disciplinary collaboration is essential.
Summary
Quantum computing is poised to revolutionize system design by introducing new computational capabilities and challenges. Senior engineers and technical leads must stay informed about quantum principles, anticipate architectural shifts, and prepare their systems for integration with quantum technologies. While widespread quantum adoption is still emerging, early experimentation and hybrid designs will provide competitive advantages and future-proof architectures.
12.5 Preparing for the Next Generation of Scalable and Resilient Systems
As system architects and senior engineers, preparing for the next generation of scalable and resilient systems requires a forward-looking mindset that embraces emerging technologies, evolving design paradigms, and adaptive operational strategies. This section explores key areas to focus on, supported by mind maps and practical examples to help you visualize and implement these concepts effectively.
Key Focus Areas for Next-Gen Systems
Embracing Emerging Technologies
Serverless and Function-as-a-Service (FaaS)
- Why: Eliminates infrastructure management, enabling automatic scaling and pay-per-use billing.
- Example: Migrating a batch image processing pipeline to AWS Lambda functions triggered by S3 uploads, automatically scaling with demand and reducing operational overhead.
Edge Computing
- Why: Reduces latency and bandwidth usage by processing data closer to the source.
- Example: A global IoT monitoring system that processes sensor data locally on edge nodes for real-time anomaly detection, forwarding only critical events to central cloud services.
AI & ML Integration
- Why: Enables predictive autoscaling, anomaly detection, and intelligent routing.
- Example: Using ML models to predict traffic spikes in an e-commerce platform and proactively scale resources before demand surges.
Quantum Computing (Emerging)
- Why: Potential to solve complex optimization and cryptographic problems faster.
- Example: Exploring quantum-safe encryption algorithms to future-proof secure communications in distributed systems.
Advanced Architectural Paradigms
- Event-Driven Architectures: Enhance decoupling and scalability by using asynchronous communication patterns.
- Service Mesh: Provides observability, security, and traffic management for microservices at scale.
- Self-Healing Systems: Automatically detect and recover from failures to maintain availability.
Example: Implementing Istio service mesh in a Kubernetes cluster to enable fine-grained traffic routing, fault injection for testing resilience, and automatic retries.
Operational Excellence and Automation
- Observability & Telemetry: Collect comprehensive metrics, logs, and traces to gain deep system insights.
- Chaos Engineering: Regularly inject failures to validate system robustness.
- Automated Recovery: Use runbooks and automation tools to reduce mean time to recovery (MTTR).
- Predictive Scaling: Leverage AI to forecast demand and adjust resources proactively.
Example: A SaaS provider integrates Prometheus and Jaeger for observability, coupled with a chaos engineering platform like Gremlin to simulate network failures, ensuring systems gracefully degrade and recover.
Security & Compliance as Foundational Pillars
- Zero Trust Security: Never trust, always verify; enforce strict identity and access controls.
- Adaptive Security: Dynamically adjust security policies based on context and threat intelligence.
- Privacy-by-Design: Embed privacy considerations into system design from inception.
- Regulatory Automation: Automate compliance checks and reporting to keep pace with evolving regulations.
Example: Deploying an API gateway with integrated OAuth2 and dynamic rate limiting, combined with automated compliance scanning tools to ensure GDPR adherence.
Integrated Example: Designing a Next-Gen Global Video Streaming Platform
- Scenario: The platform uses microservices deployed globally with edge nodes for low-latency streaming.
- Autoscaling: ML models predict peak viewing times, scaling encoding and delivery services.
- Resilience: Circuit breakers prevent cascading failures; chaos engineering validates fault tolerance.
- Security: Zero trust policies protect content and user data.
- Observability: Centralized telemetry enables rapid incident response.
Summary
Preparing for the next generation of scalable and resilient systems means embracing a holistic approach that combines emerging technologies, advanced architectural patterns, operational automation, and robust security. By visualizing these concepts through mind maps and grounding them in practical examples, technical leads and senior engineers can architect systems that not only meet today’s demands but are also future-proofed for evolving challenges.
13. Conclusion and Best Practice Summary
13.1 Recap of Key Patterns and Their Practical Applications
In this section, we consolidate the advanced system design patterns covered throughout the blog, emphasizing their practical applications in building highly available and scalable systems. To aid comprehension, we include mind maps and concrete examples illustrating how these patterns interrelate and can be applied effectively.
Mind Map: Overview of Key Patterns
Pattern Recaps with Practical Examples
Fault Tolerance & Redundancy
-
Circuit Breaker: Prevents cascading failures by stopping calls to failing services.
- Example: In a microservices-based e-commerce platform, if the payment service is down, the circuit breaker trips to avoid overwhelming it and allows fallback to a cached payment status or a retry queue.
-
Bulkhead: Isolates failures by partitioning resources.
- Example: Separate thread pools for user authentication and order processing ensure that a spike in login requests does not degrade order processing.
-
Active-Active vs Active-Passive: Ensures availability through redundancy.
- Example: A globally distributed database cluster uses active-active replication to serve reads and writes from multiple regions, reducing latency and improving fault tolerance.
Load Balancing
-
Client-Side Load Balancing: Clients choose service instances.
- Example: Netflix Ribbon allows clients to pick healthy instances, improving response times.
-
Server-Side Load Balancing: Centralized load balancer distributes traffic.
- Example: AWS Elastic Load Balancer distributes incoming HTTP requests across EC2 instances.
-
DNS Load Balancing: Distributes traffic at the DNS level.
- Example: Route 53 directs users to the nearest healthy region.
Data Replication & Consistency
-
Synchronous Replication: Ensures strong consistency but higher latency.
- Example: Financial transactions replicated synchronously between primary and backup databases to avoid data loss.
-
Asynchronous Replication: Improves performance with eventual consistency.
- Example: Social media posts replicated asynchronously to reduce write latency.
-
Eventual Consistency: Acceptable in scenarios like user profile updates.
Caching Strategies
-
Cache Aside: Application manages cache population.
- Example: An online catalog service loads product data from DB into Redis on cache miss.
-
Read-Through: Cache automatically loads data on miss.
- Example: Using a caching library that fetches data transparently from DB.
-
Write-Through: Writes go through cache to DB.
- Example: Inventory updates immediately reflected in cache and DB.
Messaging & Event-Driven Architectures
-
Message Queues: Decouple producers and consumers.
- Example: Order service publishes order events to a queue consumed by billing and shipping services asynchronously.
-
Publish-Subscribe: Broadcast events to multiple subscribers.
- Example: Notification service subscribes to user activity events to send emails and push notifications.
-
Event Sourcing & CQRS: Separate read/write models for scalability.
- Example: Banking system stores all transactions as events and builds account balances on demand.
Autoscaling & Elasticity
-
Horizontal Pod Autoscaling: Automatically scales pods based on CPU or custom metrics.
- Example: Video transcoding service scales out during peak upload hours.
-
Predictive Autoscaling: Uses ML to forecast demand.
- Example: E-commerce platform predicts traffic spikes during sales and pre-scales resources.
-
Queue-Based Autoscaling: Scales consumers based on queue length.
- Example: Email sending service adds workers as message backlog grows.
Disaster Recovery
-
Multi-Region Failover: Switch traffic to healthy region on failure.
- Example: Banking app fails over to secondary region with near-zero downtime.
-
Chaos Engineering: Inject faults to test resilience.
- Example: Netflix’s Chaos Monkey randomly terminates instances to validate recovery processes.
Security Patterns
-
Rate Limiting & Throttling: Protects against abuse.
- Example: API gateway limits requests per user to prevent DDoS.
-
Circuit Breakers for Security: Temporarily block suspicious traffic.
- Example: Automatically block IPs with repeated failed login attempts.
-
OAuth & API Gateway: Centralized authentication and authorization.
- Example: Microservices behind an API gateway validate OAuth tokens before processing requests.
Monitoring & Observability
-
Metrics, Logs, Traces: Comprehensive visibility.
- Example: Prometheus collects metrics, Grafana visualizes them, Jaeger traces distributed requests.
-
Health Checks: Ensure service readiness.
- Example: Kubernetes readiness probes prevent routing traffic to unhealthy pods.
-
Alerting: Actionable notifications.
- Example: PagerDuty alerts on high error rates enable rapid incident response.
Integrated Example: E-Commerce Platform
This recap underscores how combining these patterns thoughtfully leads to robust, scalable, and highly available systems. Understanding their trade-offs and real-world applications empowers technical leads and senior engineers to architect solutions that meet demanding SLAs and evolving business needs.
13.2 Integrating Multiple Patterns for Holistic System Design
Designing highly available and scalable systems requires more than just applying isolated patterns; it demands a thoughtful integration of multiple design patterns to address diverse challenges cohesively. This section explores how to combine patterns effectively, illustrated with mind maps and practical examples.
Why Integrate Multiple Patterns?
- Complexity of Modern Systems: Single patterns rarely solve all issues; combining them addresses availability, scalability, fault tolerance, and performance simultaneously.
- Trade-off Management: Integration helps balance trade-offs like consistency vs availability or latency vs throughput.
- Resilience and Flexibility: Layered patterns provide defense-in-depth, reducing risk of cascading failures.
Mind Map: Core Patterns Integration for High Availability & Scalability
Example Scenario: E-Commerce Platform
Imagine designing an e-commerce platform that must handle high traffic spikes during sales, maintain data consistency for orders, and ensure zero downtime.
Step 1: Fault Isolation and Resilience
- Use Bulkhead Pattern to isolate payment, inventory, and user services so failure in one doesn’t cascade.
- Implement Circuit Breakers on external payment gateway calls to prevent system overload.
Step 2: Load Distribution
- Deploy Server-Side Load Balancers with health checks to distribute incoming requests across multiple instances.
- Use Client-Side Load Balancing in microservices to balance inter-service calls efficiently.
Step 3: Data Consistency and Performance
- Apply Master-Slave Replication for the product catalog to ensure read scalability.
- Use Cache Aside Pattern with Redis for frequently accessed product details.
Step 4: Messaging and Event-Driven Processing
- Employ Message Queues to decouple order processing from payment confirmation.
- Use Event Sourcing to maintain an immutable log of order events for audit and recovery.
Step 5: Autoscaling
- Configure Horizontal Pod Autoscaling in Kubernetes based on CPU and queue length metrics.
- Integrate Predictive Autoscaling using historical traffic data to prepare for sales events.
Step 6: Disaster Recovery
- Set up Multi-Region Active-Active Deployment with data replication.
- Regularly run Chaos Engineering experiments to validate failover mechanisms.
Step 7: Security and Throttling
- Implement Rate Limiting at the API Gateway to prevent abuse.
- Use Circuit Breakers to mitigate DDoS attacks by cutting off unhealthy downstream services.
Step 8: Observability
- Centralize Metrics, Logs, and Traces using Prometheus, ELK stack, and Jaeger.
- Define health checks and readiness probes for all services.
Mind Map: Integrated Patterns in E-Commerce Platform
Best Practices for Integrating Patterns
- Start with Clear Requirements: Understand availability, latency, consistency, and security needs.
- Layer Patterns Thoughtfully: Combine patterns at different layers (network, application, data).
- Automate and Monitor: Use automation for deployment and monitoring to detect integration issues early.
- Test Extensively: Employ chaos engineering and load testing to validate pattern integration.
- Document Interactions: Maintain clear documentation of how patterns interact and their failure modes.
Summary
Integrating multiple system design patterns is essential for building robust, scalable, and highly available applications. By combining fault tolerance, load balancing, data replication, caching, messaging, autoscaling, disaster recovery, security, and observability patterns, engineers can create resilient systems that gracefully handle failures and scale dynamically. The holistic approach, supported by clear architecture diagrams and practical examples, empowers technical leads and senior engineers to design systems that meet demanding SLAs and evolving business needs.
13.3 Checklist for Designing High Availability and Scalable Systems
Designing systems that are both highly available and scalable requires a comprehensive approach that touches on architecture, infrastructure, development practices, and operational readiness. Below is a detailed checklist to guide senior engineers and technical leads through the critical considerations, complemented by mind maps and practical examples.
High Availability & Scalability Design Checklist
Detailed Checklist Items with Examples
Architecture
- Redundancy: Ensure no single point of failure by implementing active-active or active-passive redundancy.
- Example: Deploying multiple instances of a payment processing service across availability zones with active-active load balancing.
- Load Balancing: Use appropriate load balancing strategies to distribute traffic efficiently.
- Example: Combining DNS-based global load balancing with local server-side round-robin balancing.
- Data Replication: Choose replication strategy based on consistency and latency needs.
- Example: Using asynchronous replication for a global user profile database to reduce write latency.
Fault Tolerance
- Circuit Breaker: Prevent cascading failures by stopping calls to failing services.
- Example: A microservice implementing a circuit breaker to fallback to cached data when a downstream service is down.
- Bulkhead: Isolate components to contain failures.
- Example: Partitioning thread pools per external API to avoid resource exhaustion.
- Graceful Degradation: Design systems to maintain partial functionality during failures.
- Example: An e-commerce site disabling recommendations but allowing checkout during a recommendation engine outage.
Scalability
- Horizontal Scaling: Add more instances rather than beefing up existing ones.
- Example: Kubernetes pods autoscaling based on CPU and request latency.
- Vertical Scaling: Increase resources of existing nodes when horizontal scaling is limited.
- Example: Upgrading database server memory to handle increased query load temporarily.
- Autoscaling: Implement reactive and predictive autoscaling.
- Example: Using queue length metrics to trigger scaling of worker services.
Data Management
- Caching: Use appropriate caching patterns to reduce latency and load.
- Example: Cache Aside pattern for product catalog data in an online store.
- Consistency Models: Decide between strong and eventual consistency based on business needs.
- Example: Eventual consistency for user activity feeds to maximize availability.
Resilience Testing
- Chaos Engineering: Regularly inject failures to validate system robustness.
- Example: Using Chaos Monkey to randomly terminate instances in production.
- Failure Injection: Simulate network latency, service crashes, and resource exhaustion.
Monitoring & Alerting
- Health Checks: Implement readiness and liveness probes.
- Example: Kubernetes readiness probes to prevent routing traffic to unhealthy pods.
- Metrics, Logs, Traces: Collect and correlate for full observability.
- Example: Centralized ELK stack with Prometheus and Jaeger integration.
- Alerting: Define actionable alerts with proper thresholds.
Security
- Rate Limiting & Throttling: Protect services from abuse and overload.
- Example: API Gateway enforcing per-user rate limits.
- Secrets Management: Securely store and rotate credentials.
- Example: Using HashiCorp Vault or cloud provider secret managers.
Disaster Recovery
- Recovery Objectives: Define RPO (Recovery Point Objective) and RTO (Recovery Time Objective).
- Multi-Region Failover: Plan and test failover strategies.
- Example: Active-passive failover for critical databases across regions.
- Backup & Restore: Regular automated backups with tested restore procedures.
Mind Map: Autoscaling Considerations
Example: Applying the Checklist to a Video Streaming Platform
- Redundancy: Deploy transcoding services in multiple availability zones using active-active setup.
- Load Balancing: Use global DNS load balancing combined with local NGINX reverse proxies.
- Data Replication: Asynchronous replication for user watch history to optimize write latency.
- Fault Tolerance: Circuit breakers around third-party CDN APIs.
- Autoscaling: Queue length based autoscaling for video processing workers.
- Caching: Multi-level caching for video metadata.
- Monitoring: End-to-end tracing of video upload to playback.
- Security: Rate limiting on upload APIs to prevent abuse.
- Disaster Recovery: Nightly backups and multi-region failover tested quarterly.
This checklist, combined with continuous validation through testing and monitoring, will help ensure your systems achieve the desired levels of availability and scalability while maintaining operational excellence.
13.4 Resources for Continued Learning and Community Engagement
As senior software engineers and technical leads, continuous learning and active community engagement are vital to staying ahead in designing highly available and scalable systems. This section provides curated resources, mind maps, and practical examples to deepen your expertise and foster collaboration.
Books and Publications
- Designing Data-Intensive Applications by Martin Kleppmann — A foundational book covering system design patterns, data replication, consistency, and scalability.
- Site Reliability Engineering by Google — Insights into building and operating large-scale, highly available systems.
- Release It! by Michael T. Nygard — Practical patterns for building resilient software.
- The Art of Scalability by Martin L. Abbott and Michael T. Fisher — Comprehensive coverage of scalability strategies.
Online Courses and Tutorials
- Coursera: Cloud Computing Specialization — Covers cloud architecture, scalability, and fault tolerance.
- Udemy: Microservices Architecture and Implementation on .NET Core — Practical microservices design with resilience patterns.
- Pluralsight: Advanced System Design — Deep dives into distributed systems and scalability.
Community Forums and Discussion Groups
- Stack Overflow — Engage with specific system design questions.
- Reddit r/sysadmin and r/devops — Discussions on availability, scalability, and infrastructure.
- LinkedIn Groups: Software Architecture & Design — Professional networking and knowledge sharing.
- Discord & Slack Channels — Many tech communities host channels dedicated to system design and architecture.
Conferences and Meetups
- QCon — Focused on software architecture and system design.
- AWS re:Invent — Cloud scalability and availability best practices.
- KubeCon + CloudNativeCon — Kubernetes and cloud-native ecosystem.
- Local Meetups — Search Meetup.com for system architecture and cloud engineering groups.
Open Source Projects and Hands-On Labs
- Envoy Proxy — Learn about advanced load balancing and fault tolerance.
- Istio Service Mesh — Explore resilience patterns in microservices.
- Chaos Monkey by Netflix — Practice chaos engineering to improve system resilience.
- Kubernetes — Hands-on experience with autoscaling and self-healing.
Mind Maps for Structured Learning
Mind Map 1: High Availability Design Patterns
Mind Map 2: Scalability Strategies
Mind Map 3: Observability and Monitoring
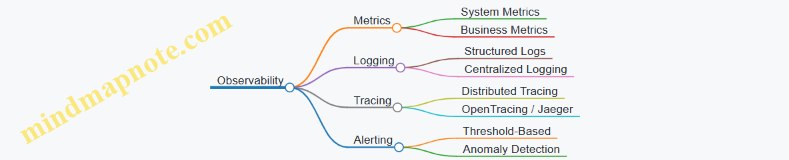
Practical Example: Using Mind Maps for Team Workshops
Scenario: You are leading a design workshop to improve the availability of a microservices platform.
Approach:
- Present the “High Availability Design Patterns” mind map to the team.
- Use it as a checklist to identify current gaps (e.g., missing circuit breakers).
- Assign sub-teams to explore and prototype solutions for each pattern.
- Iterate and integrate findings into the architecture roadmap.
This structured approach promotes shared understanding and actionable outcomes.
Additional Tips for Continued Learning
- Document Learnings: Maintain a shared knowledge base or wiki for your team.
- Pair Programming: Collaborate on implementing new patterns.
- Contribute to Open Source: Gain real-world experience and community feedback.
- Write and Share: Blogging or presenting at meetups solidifies your understanding.
By leveraging these resources and structured learning tools like mind maps, senior engineers and technical leads can continuously refine their skills and lead their teams toward building robust, scalable, and highly available systems.
13.5 Final Thoughts: Balancing Innovation with Reliability
In the rapidly evolving landscape of software engineering, striking the right balance between innovation and reliability is paramount for building systems that not only push technological boundaries but also maintain unwavering availability and performance. As senior engineers and technical leads, embracing this balance ensures your applications delight users while standing resilient against failures.
The Innovation-Reliability Spectrum
Innovation drives new features, improved user experiences, and competitive advantage. Reliability ensures these innovations are delivered consistently and safely. Leaning too far into innovation without sufficient reliability can lead to unstable systems, while overemphasizing reliability may stifle creativity and slow down delivery.
Mind Map: Balancing Innovation and Reliability
Practical Examples
Example 1: Canary Releases to Safely Innovate
A global SaaS provider wants to introduce a new recommendation engine. Instead of a full rollout, they deploy the feature to 5% of users initially (canary release). This approach allows the team to monitor system behavior and user impact closely, rolling back quickly if issues arise.
- Innovation Aspect: Deploying new functionality rapidly to a subset.
- Reliability Aspect: Minimizing blast radius and enabling quick rollback.
Example 2: Feature Flags for Controlled Innovation
An e-commerce platform integrates a new payment gateway behind a feature flag. This allows the team to enable or disable the gateway dynamically without redeploying, facilitating A/B testing and gradual exposure.
- Innovation Aspect: Flexibility to experiment and gather feedback.
- Reliability Aspect: Immediate disablement in case of failures.
Example 3: Observability-Driven Development
A fintech application invests heavily in detailed metrics, distributed tracing, and centralized logging before launching a new microservice. This observability foundation enables rapid detection and diagnosis of anomalies post-launch.
- Innovation Aspect: Confidently deploying new services.
- Reliability Aspect: Proactive monitoring to maintain uptime.
Mind Map: Strategies to Achieve Balance
Key Takeaways
- Embrace Controlled Experimentation: Use feature flags and incremental rollouts to innovate safely.
- Invest in Observability: Comprehensive monitoring and tracing empower teams to detect and resolve issues swiftly.
- Automate Testing and Validation: Continuous testing pipelines reduce the risk of regressions.
- Prepare for Failure: Design systems with fault tolerance and disaster recovery baked in.
- Learn from Incidents: Conduct blameless postmortems to improve both innovation processes and reliability.
Balancing innovation with reliability is not a one-time effort but a continuous journey. By integrating these principles and patterns into your system design and development workflows, you can deliver cutting-edge applications that users trust and rely on, even as you push the envelope of what’s possible.