Enterprise Software Architecture Patterns and High Performance Backend Engineering
1. Introduction to Enterprise Software Architecture
1.1 Understanding Enterprise Software Systems: Scope and Challenges
Enterprise software systems are complex, large-scale applications designed to support and automate business processes across an entire organization or multiple organizations. These systems are critical for operational efficiency, decision-making, and competitive advantage.
Scope of Enterprise Software Systems
Enterprise software typically encompasses a wide range of functionalities and integrates multiple subsystems. The scope includes:
- Business Process Automation: Automating workflows such as order processing, inventory management, and HR operations.
- Data Management: Handling large volumes of structured and unstructured data across departments.
- Integration: Connecting with external systems, legacy applications, and third-party services.
- User Management: Supporting diverse user roles with varying access levels.
- Scalability: Serving thousands or millions of users concurrently.
Challenges in Enterprise Software Systems
Enterprise systems face unique challenges due to their scale, complexity, and criticality:
- Complexity and Size: Managing thousands of modules, components, and services.
- Integration Complexity: Ensuring seamless communication between heterogeneous systems.
- Performance and Scalability: Maintaining responsiveness under heavy load.
- Security: Protecting sensitive business data and ensuring compliance.
- Maintainability: Facilitating ongoing updates and evolution without downtime.
- Data Consistency: Balancing consistency, availability, and partition tolerance in distributed environments.
Mind Map: Scope and Challenges of Enterprise Software Systems
Example: Enterprise Resource Planning (ERP) System
An ERP system integrates core business processes such as finance, procurement, manufacturing, and supply chain. Consider a multinational manufacturing company using an ERP:
- Scope: The system manages purchase orders, inventory levels, employee payroll, and compliance reporting.
- Challenges: It must integrate with legacy manufacturing execution systems, handle thousands of concurrent users worldwide, ensure data consistency across regions, and comply with international regulations.
Example: Online Banking Platform
An online banking platform serves millions of customers with features like account management, transactions, loans, and fraud detection.
- Scope: Real-time transaction processing, multi-channel access (web, mobile), and integration with credit bureaus.
- Challenges: High availability, stringent security requirements, rapid response times, and regulatory compliance.
Summary
Understanding the scope and challenges of enterprise software systems is foundational for designing architectures that are scalable, maintainable, and performant. Recognizing these aspects early helps technical leads and senior engineers make informed decisions about patterns, technologies, and practices to adopt.
1.2 Key Principles of Enterprise Architecture
Enterprise Architecture (EA) serves as the blueprint for aligning business strategy with IT infrastructure and software systems. Understanding its key principles is essential for senior software engineers and technical leads aiming to design scalable, maintainable, and high-performance enterprise systems.
Core Principles of Enterprise Architecture
Below is a mind map illustrating the foundational principles:
Alignment: Business and IT
Enterprise Architecture must ensure that IT systems directly support business goals. For example, a retail company aiming to expand globally needs an architecture that supports multi-region deployments and localization.
Example:
A logistics company restructures its backend to support real-time shipment tracking aligned with customer satisfaction goals. The architecture integrates GPS data ingestion services with customer notification systems, demonstrating alignment.
Standardization: Reducing Complexity
Using standardized technologies and design patterns reduces complexity and improves maintainability.
Example:
An enterprise adopts RESTful APIs across all services instead of mixing REST, SOAP, and proprietary protocols. This standardization simplifies integration and onboarding of new developers.
Modularity: Building with Decoupled Components
Modularity allows independent development, testing, and deployment, which improves agility and fault isolation.
Example:
A banking system separates its payment processing, user authentication, and reporting into distinct microservices. Each can be scaled or updated without impacting others.
Scalability: Handling Growth Efficiently
Designing for scalability ensures the system can handle increased load without degradation.
Example:
An e-commerce platform uses a load balancer with stateless backend services and a distributed cache to handle flash sales with millions of users.
Security: Protecting Data and Access
Security must be integrated at every architectural layer.
Example:
A healthcare application implements role-based access control (RBAC) and encrypts sensitive patient data both at rest and in transit.
Interoperability: Seamless Integration
Systems must communicate effectively, often through APIs or messaging systems.
Example:
A supply chain system integrates with multiple third-party vendors via standardized REST APIs and message queues to synchronize inventory data.
Agility: Embracing Change
The architecture should support rapid changes and continuous delivery.
Example:
A SaaS provider uses container orchestration (e.g., Kubernetes) to deploy updates frequently with minimal downtime.
Governance: Ensuring Compliance and Quality
Governance enforces policies, standards, and compliance requirements.
Example:
An enterprise implements automated code quality checks and security scans in their CI/CD pipeline to enforce governance policies.
Mind Map: Principles with Examples
Summary
Mastering these key principles enables technical leads and senior engineers to architect enterprise systems that are robust, performant, and aligned with business needs. Each principle interlocks with others, creating a cohesive framework that guides design decisions and engineering practices.
1.3 Overview of Common Architecture Patterns in Enterprise Systems
Enterprise software systems are complex and require well-defined architecture patterns to ensure scalability, maintainability, and performance. Understanding the common architecture patterns helps senior engineers and technical leads make informed decisions when designing backend systems.
What Are Architecture Patterns?
Architecture patterns are reusable solutions to common problems in software architecture. They provide a blueprint for organizing system components and their interactions.
Common Architecture Patterns in Enterprise Systems
Below is a mind map summarizing the most prevalent architecture patterns:
Layered Architecture
Description: A traditional and widely used pattern that organizes code into layers, each with a specific responsibility.
Example:
- Presentation Layer: REST API controllers
- Business Logic Layer: Services implementing business rules
- Data Access Layer: Repositories interacting with databases
Best Practice: Keep layers loosely coupled and communicate through well-defined interfaces.
Example Code Snippet:
// Service Layer Example
public class OrderService {
private final OrderRepository orderRepository;
public OrderService(OrderRepository repo) {
this.orderRepository = repo;
}
public void placeOrder(Order order) {
// Business logic
orderRepository.save(order);
}
}
Microservices Architecture
Description: Decomposes an application into small, independently deployable services, each responsible for a specific business capability.
Example: An e-commerce system with separate services for inventory, orders, payments, and shipping.
Best Practice: Define clear service boundaries using domain-driven design principles.
Example Mind Map:
Example: Using asynchronous messaging with RabbitMQ for order processing:
# Pseudocode for publishing an order event
order_event = {"orderId": 123, "status": "PLACED"}
rabbitmq_channel.basic_publish(exchange='orders', routing_key='order.placed', body=json.dumps(order_event))
Event-Driven Architecture
Description: Systems communicate through events, enabling loose coupling and asynchronous processing.
Example: An order service emits an “OrderPlaced” event, which triggers inventory and billing services.
Mind Map:
Best Practice: Design events as immutable facts and use event sourcing where applicable.
Example:
// Emitting an event in Node.js
const event = { type: 'OrderPlaced', data: { orderId: 123, items: [...] } };
eventBus.emit('OrderPlaced', event);
Service-Oriented Architecture (SOA)
Description: Similar to microservices but often involves larger, more coarse-grained services and an Enterprise Service Bus (ESB) for communication.
Example: A banking system where services like account management, loan processing, and customer service communicate via ESB.
Best Practice: Use SOA when integration of heterogeneous systems is a priority.
Domain-Driven Design (DDD)
Description: Focuses on modeling software to match complex business domains.
Example: Defining aggregates like Customer, Order, and Product with clear boundaries.
Mind Map:
Example:
public class Order : AggregateRoot {
private List<OrderItem> items;
public void AddItem(Product product, int quantity) {
// Business rule enforcement
items.Add(new OrderItem(product, quantity));
}
}
CQRS (Command Query Responsibility Segregation)
Description: Separates the read and write models to optimize performance and scalability.
Example: Write model handles commands like “CreateOrder”; read model optimized for queries like “GetOrderDetails”.
Best Practice: Use CQRS with event sourcing for complex domains requiring auditability.
Summary
Each architecture pattern serves different enterprise needs. Often, hybrid approaches combining multiple patterns yield the best results. For example, microservices can be built using DDD principles and communicate via event-driven mechanisms.
Understanding these patterns and their trade-offs is critical for designing high-performance, maintainable enterprise backend systems.
1.4 Importance of Scalability, Maintainability, and Performance
In enterprise software architecture, three pillars often define the success and longevity of a backend system: Scalability, Maintainability, and Performance. Understanding their importance and how they interplay is critical for Senior Software Engineers and Technical Leads aiming to build robust, efficient, and adaptable systems.
Scalability
Scalability is the system’s ability to handle increased load without sacrificing functionality or performance.
- Vertical Scaling (Scaling Up): Increasing resources on a single node (CPU, RAM).
- Horizontal Scaling (Scaling Out): Adding more nodes to distribute load.
Mind Map: Scalability
Example:
A retail e-commerce platform experiences a surge in user traffic during holiday sales. Vertical scaling might temporarily improve performance by upgrading the database server’s hardware. However, to handle sustained high traffic, horizontal scaling by adding multiple application servers behind a load balancer ensures availability and fault tolerance.
Maintainability
Maintainability refers to how easily a system can be modified to fix defects, improve performance, or adapt to a changing environment.
Key factors influencing maintainability:
- Modularity: Separation of concerns through layers or services.
- Code Quality: Readability, documentation, and standards.
- Testability: Automated tests for regression prevention.
- Clear Architecture: Well-defined interfaces and contracts.
Mind Map: Maintainability
Example:
Consider a legacy monolithic backend with tightly coupled modules. Introducing a layered architecture with clear boundaries between presentation, business logic, and data access layers improves maintainability. For instance, refactoring the payment processing logic into a separate microservice allows independent updates and faster bug fixes without impacting the entire system.
Performance
Performance is about how fast and efficiently a system responds to user requests and processes data.
Key performance metrics include:
- Latency: Time taken to respond to a request.
- Throughput: Number of requests processed per unit time.
- Resource Utilization: CPU, memory, and network usage.
Mind Map: Performance
Example:
A financial trading platform requires ultra-low latency to process transactions in milliseconds. Implementing in-memory caching for frequently accessed data and asynchronous processing for non-critical tasks reduces response time. Profiling tools identify CPU hotspots, enabling targeted optimizations.
Interrelation and Trade-offs
These three pillars often influence each other:
- Improving scalability (e.g., adding more nodes) might increase system complexity, impacting maintainability.
- Aggressive performance optimizations (e.g., complex caching) can make code harder to maintain.
- Highly maintainable modular systems may introduce slight performance overhead due to abstraction layers.
Mind Map: Interrelation
Practical Integrated Example
Imagine designing a backend for a ride-sharing enterprise system:
- Scalability: Use microservices to horizontally scale components like driver matching and payment processing independently.
- Maintainability: Adopt Domain-Driven Design to keep services modular and aligned with business domains.
- Performance: Implement asynchronous event-driven communication to reduce latency and improve throughput.
This integrated approach ensures the system can grow with user demand, adapt to evolving business needs, and maintain responsive performance.
Summary
| Pillar | Importance | Best Practices | Example Use Case |
|---|---|---|---|
| Scalability | Supports growth and handles peak loads | Horizontal scaling, load balancing | E-commerce during holiday sales |
| Maintainability | Enables easy updates, bug fixes, and feature additions | Modular design, code quality, automated testing | Refactoring monolith to microservices |
| Performance | Ensures fast response times and efficient resource use | Caching, profiling, async processing | Financial trading platform with low latency |
Understanding and balancing these pillars is essential for building enterprise backend systems that are robust, adaptable, and performant.
1.5 Case Study: Architecture Evolution in a Large-Scale Enterprise Application
In this section, we explore the architectural evolution of a large-scale enterprise application — AcmeCorp’s Order Management System (OMS) — which transformed from a monolithic design to a modern, scalable, and high-performance backend. This case study highlights challenges, decisions, and best practices encountered during the journey.
Background
AcmeCorp’s OMS initially started as a monolithic Java EE application handling order intake, inventory management, billing, and reporting. As the company grew, the system faced performance bottlenecks, deployment complexity, and slowed feature delivery.
Initial Architecture Overview
- Single codebase: All modules tightly coupled.
- Shared database: One relational database schema.
- Synchronous calls: Internal method calls within the monolith.
Challenges Faced
- Scalability issues: Peak loads caused slowdowns, especially during order processing.
- Deployment bottlenecks: Even small changes required full redeployments.
- Limited fault isolation: Failures in one module impacted the entire system.
- Slow development cycles: Teams blocked by dependencies.
Architectural Evolution Goals
- Improve scalability and fault tolerance.
- Enable independent deployments.
- Facilitate faster development and testing.
- Maintain data consistency and integrity.
Step 1: Modularization within the Monolith
Approach: Introduce clear module boundaries and layered architecture.
Best Practices:
- Define explicit interfaces between modules.
- Use Dependency Injection to manage dependencies.
- Separate read and write models where possible.
Example:
- Extracted Inventory logic into a separate package with well-defined APIs.
Step 2: Introducing Microservices for Critical Domains
Approach: Identify bounded contexts and extract microservices for Order and Inventory modules.
Best Practices:
- Use Domain-Driven Design (DDD) to define bounded contexts.
- Implement API Gateway to route requests.
- Use separate databases per microservice to enforce data ownership.
Example:
- Order Service exposes REST endpoints for order creation and status.
- Inventory Service asynchronously updates stock levels.
Step 3: Event-Driven Communication
Approach: Replace synchronous REST calls between services with asynchronous events.
Best Practices:
- Use event brokers like Apache Kafka or RabbitMQ.
- Design immutable event schemas.
- Handle eventual consistency with compensating transactions.
Example:
- When an order is created, Order Service publishes an
OrderCreatedEvent. - Inventory Service listens and updates stock asynchronously.
Step 4: Performance Optimization and Scalability
Approach: Implement caching, database sharding, and horizontal scaling.
Best Practices:
- Use Redis for caching frequently accessed data (e.g., product catalog).
- Partition databases by customer region to reduce latency.
- Deploy services in Kubernetes clusters with autoscaling.
Example:
- Cached inventory availability to reduce database hits during order validation.
- Scaled Order Service pods based on CPU and request latency metrics.
Step 5: Continuous Deployment and Monitoring
Approach: Automate deployment pipelines and implement observability.
Best Practices:
- Use CI/CD pipelines with automated tests and canary releases.
- Implement distributed tracing (e.g., OpenTelemetry) to track requests across services.
- Set up dashboards and alerts for latency, error rates, and throughput.
Example:
- Deployed new Order Service versions with zero downtime using blue-green deployments.
- Traced order processing end-to-end to identify bottlenecks.
Summary Mindmap of Evolution
Key Takeaways
- Incremental evolution: Gradually refactor rather than rewrite.
- Domain-driven design: Crucial for defining service boundaries.
- Asynchronous communication: Improves resilience and scalability.
- Observability: Essential for maintaining performance in distributed systems.
- Automation: Enables rapid, safe deployments.
This case study illustrates how thoughtful architectural evolution, guided by best practices and real-world constraints, can transform a legacy enterprise system into a high-performance, scalable backend aligned with modern engineering standards.
2. Layered Architecture Pattern
2.1 Fundamentals of Layered Architecture
Layered Architecture is one of the most widely adopted architectural patterns in enterprise software development. It organizes the system into distinct layers, each with specific responsibilities, promoting separation of concerns, maintainability, and scalability.
What is Layered Architecture?
Layered Architecture divides an application into logical layers stacked vertically. Each layer communicates only with the layer directly below or above it, creating a clear structure that simplifies development and testing.
Typical layers include:
- Presentation Layer: Handles user interface and user experience.
- Application Layer (or Service Layer): Coordinates application activities and business logic.
- Domain Layer (or Business Layer): Contains core business rules and domain logic.
- Infrastructure Layer: Manages technical concerns like data access, messaging, and external system integration.
Benefits of Layered Architecture
- Separation of Concerns: Each layer has a focused responsibility.
- Maintainability: Changes in one layer have minimal impact on others.
- Testability: Layers can be tested independently.
- Reusability: Layers can be reused across different applications.
- Scalability: Layers can be scaled independently if designed properly.
Mind Map: Core Concepts of Layered Architecture
Communication Flow in Layered Architecture
Each layer communicates only with its adjacent layers, typically downward for service requests and upward for responses or data.
Example: Simple E-Commerce Application
Let’s illustrate a layered architecture with a simplified e-commerce backend.
Layers and Responsibilities:
- Presentation Layer: REST API controllers handling HTTP requests.
- Application Layer: Services orchestrating order placement.
- Domain Layer: Business logic for order validation and pricing.
- Infrastructure Layer: Database repositories and external payment gateway integration.
Code Snippet: Order Placement Flow (Simplified)
// Presentation Layer
@RestController
public class OrderController {
private final OrderService orderService;
public OrderController(OrderService orderService) {
this.orderService = orderService;
}
@PostMapping("/orders")
public ResponseEntity<String> placeOrder(@RequestBody OrderRequest request) {
orderService.placeOrder(request);
return ResponseEntity.ok("Order placed successfully");
}
}
// Application Layer
@Service
public class OrderService {
private final OrderDomainService domainService;
public OrderService(OrderDomainService domainService) {
this.domainService = domainService;
}
public void placeOrder(OrderRequest request) {
domainService.validateAndProcessOrder(request);
}
}
// Domain Layer
@Service
public class OrderDomainService {
private final OrderRepository orderRepository;
private final PaymentGateway paymentGateway;
public OrderDomainService(OrderRepository orderRepository, PaymentGateway paymentGateway) {
this.orderRepository = orderRepository;
this.paymentGateway = paymentGateway;
}
public void validateAndProcessOrder(OrderRequest request) {
// Business validation logic
if (request.getItems().isEmpty()) {
throw new IllegalArgumentException("Order must contain items");
}
// Process payment
paymentGateway.charge(request.getPaymentDetails());
// Save order
orderRepository.save(request.toOrderEntity());
}
}
// Infrastructure Layer
@Repository
public class OrderRepository {
// Database access code here
public void save(Order order) {
// Persist order to DB
}
}
@Component
public class PaymentGateway {
public void charge(PaymentDetails paymentDetails) {
// Integrate with external payment service
}
}
Best Practices for Layered Architecture
- Keep Layers Independent: Avoid tight coupling by using interfaces and dependency injection.
- Define Clear Layer Boundaries: Do not allow layers to skip intermediate layers.
- Avoid Business Logic in Presentation or Infrastructure Layers: Keep domain logic centralized.
- Use DTOs (Data Transfer Objects): To transfer data between layers and avoid leaking internal models.
- Handle Cross-Cutting Concerns Appropriately: Use aspects or middleware for logging, security, and transactions.
Mind Map: Best Practices
Common Pitfalls
- Over-Layering: Too many layers can add unnecessary complexity and performance overhead.
- Layer Leakage: When layers bypass others, breaking encapsulation.
- Mixing Responsibilities: Putting business logic in the presentation or infrastructure layers.
Summary
Layered Architecture provides a solid foundation for building enterprise applications by promoting modularity, maintainability, and clear separation of concerns. Understanding its fundamentals and applying best practices ensures scalable and high-quality backend systems.
2.2 Best Practices for Layer Separation and Dependency Management
In enterprise software architecture, the Layered Architecture pattern is one of the most fundamental and widely adopted approaches. Proper layer separation and dependency management are critical to building maintainable, scalable, and testable systems. This section explores best practices for achieving clean separation of concerns and managing dependencies effectively.
Why Layer Separation Matters
- Maintainability: Changes in one layer should not ripple unnecessarily into others.
- Testability: Isolated layers allow for focused unit and integration testing.
- Reusability: Layers can be reused or replaced independently.
- Team Collaboration: Different teams can own different layers without conflict.
Core Principles of Layer Separation
- Single Responsibility per Layer: Each layer should have a distinct responsibility.
- Strict Dependency Direction: Higher layers depend on lower layers, never vice versa.
- Interface-Based Contracts: Communication between layers should be through well-defined interfaces.
- Encapsulation: Internal implementation details of a layer should be hidden.
Typical Layers in Enterprise Backend Systems
- Presentation Layer: Handles user interface, API endpoints, or external communication.
- Application Layer: Coordinates application activities, orchestrates business logic.
- Domain Layer: Contains business rules, domain entities, and domain services.
- Infrastructure Layer: Deals with technical concerns like database access, messaging, and external services.
Mind Map: Layer Separation Overview
Best Practices for Dependency Management
-
Depend on Abstractions, Not on Concrete Implementations
- Use interfaces or abstract classes to define contracts.
- Example: The Application Layer depends on
IRepository<T>rather than a concreteSqlRepository.
-
Use Dependency Injection (DI)
- Inject dependencies rather than instantiating them inside classes.
- Promotes loose coupling and easier testing.
-
Avoid Circular Dependencies
- Circular references between layers or modules create tight coupling and maintenance headaches.
- Use architectural validation tools or static analysis to detect cycles.
-
Enforce Layer Boundaries with Code Reviews and Tooling
- Use tools like SonarQube, ArchUnit (Java), or custom linters to enforce dependency rules.
-
Keep Infrastructure Dependencies at the Outermost Layer
- Domain and Application layers should not depend on infrastructure details.
- Infrastructure implements interfaces defined in the Domain or Application layers.
Mind Map: Dependency Management Best Practices
Example: Layer Separation and Dependency Management in a Simple Order Processing System
Scenario: An enterprise backend processes customer orders. The system has four layers: Presentation (API), Application (Order Service), Domain (Order Aggregate), and Infrastructure (Database).
Step 1: Define Domain Layer Interface
// Domain Layer
public interface IOrderRepository
{
Order GetOrderById(Guid orderId);
void Save(Order order);
}
public class Order
{
public Guid Id { get; private set; }
public List<OrderItem> Items { get; private set; }
// Business logic methods
}
Step 2: Implement Infrastructure Layer
// Infrastructure Layer
public class SqlOrderRepository : IOrderRepository
{
private readonly DbContext _context;
public SqlOrderRepository(DbContext context)
{
_context = context;
}
public Order GetOrderById(Guid orderId)
{
// Fetch order from database
}
public void Save(Order order)
{
// Persist order to database
}
}
Step 3: Application Layer Uses Abstraction
// Application Layer
public class OrderService
{
private readonly IOrderRepository _orderRepository;
public OrderService(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
public void ProcessOrder(Guid orderId)
{
var order = _orderRepository.GetOrderById(orderId);
// Apply business rules
_orderRepository.Save(order);
}
}
Step 4: Presentation Layer Calls Application Layer
// Presentation Layer (API Controller)
[ApiController]
[Route("api/orders")]
public class OrdersController : ControllerBase
{
private readonly OrderService _orderService;
public OrdersController(OrderService orderService)
{
_orderService = orderService;
}
[HttpPost("{id}/process")]
public IActionResult ProcessOrder(Guid id)
{
_orderService.ProcessOrder(id);
return Ok();
}
}
Step 5: Dependency Injection Configuration
// Composition Root
services.AddScoped<IOrderRepository, SqlOrderRepository>();
services.AddScoped<OrderService>();
Summary
- Separate concerns clearly into distinct layers.
- Depend on abstractions, not concrete implementations.
- Use dependency injection to manage dependencies and improve testability.
- Avoid circular dependencies to maintain clean architecture.
- Enforce boundaries through tooling and code reviews.
By following these best practices, senior software engineers and technical leads can design enterprise backends that are robust, maintainable, and scalable.
2.3 Implementing Layered Architecture with Real-World Examples
Layered architecture is one of the most widely adopted architectural patterns in enterprise software development. It organizes the system into distinct layers, each with specific responsibilities, promoting separation of concerns, maintainability, and scalability.
Overview of Layered Architecture
Typically, a layered architecture consists of the following layers:
- Presentation Layer: Handles user interface and user experience.
- Application Layer (Service Layer): Coordinates application activities and business logic orchestration.
- Domain Layer (Business Logic Layer): Contains core business rules and domain entities.
- Data Access Layer: Manages persistence and retrieval of data.
Mind Map: Core Layers and Responsibilities
Best Practices in Implementation
- Strict Layer Boundaries: Each layer should only communicate with the adjacent layer to avoid tight coupling.
- Dependency Direction: Dependencies should point inward, meaning outer layers depend on inner layers but not vice versa.
- Use Interfaces and Abstractions: Define contracts between layers to enhance testability and flexibility.
- Handle Cross-Cutting Concerns Appropriately: Use aspects or middleware for logging, security, and transaction management.
Real-World Example: E-Commerce Order Processing System
Let’s implement a simplified order processing system using layered architecture.
Presentation Layer
- REST API endpoints for order submission and status queries.
Application Layer
- Services coordinating order validation, payment processing, and notification.
Domain Layer
- Business rules such as order validation, discount calculation, and inventory checks.
Data Access Layer
- Repository pattern to interact with the database.
Code Snippet: Domain Entity (Order) in Domain Layer (Java)
public class Order {
private String orderId;
private List<OrderItem> items;
private OrderStatus status;
public boolean validate() {
// Business rule: order must have at least one item
return items != null && !items.isEmpty();
}
public void applyDiscount(Discount discount) {
// Apply discount logic
}
// Getters and setters omitted for brevity
}
Code Snippet: Service Layer (Application Layer)
public class OrderService {
private OrderRepository orderRepository;
private PaymentGateway paymentGateway;
public void placeOrder(Order order) {
if (!order.validate()) {
throw new IllegalArgumentException("Invalid order");
}
// Process payment
paymentGateway.charge(order);
// Save order
orderRepository.save(order);
// Notify user (could be an event or direct call)
}
}
Code Snippet: Data Access Layer
public interface OrderRepository {
void save(Order order);
Order findById(String orderId);
}
public class OrderRepositoryImpl implements OrderRepository {
// Assume use of JPA/Hibernate
@PersistenceContext
private EntityManager entityManager;
@Override
public void save(Order order) {
entityManager.persist(order);
}
@Override
public Order findById(String orderId) {
return entityManager.find(Order.class, orderId);
}
}
Mind Map: Order Processing Flow Across Layers
Example: Handling Cross-Cutting Concerns with Middleware
Instead of embedding logging or security checks inside each layer, use middleware or aspects.
Logging Aspect Example (Spring AOP)
@Aspect
@Component
public class LoggingAspect {
@Before("execution(* com.example.orderservice.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
System.out.println("Entering method: " + joinPoint.getSignature().getName());
}
}
Performance Considerations
- Avoid excessive calls between layers; batch operations when possible.
- Cache frequently accessed data in the Data Access Layer.
- Keep Presentation Layer thin to reduce latency.
Summary
Implementing layered architecture with clear separation and adherence to best practices leads to maintainable, scalable, and testable enterprise applications. The example of an order processing system demonstrates how each layer plays a distinct role, collaborating to deliver robust functionality.
This approach can be adapted and extended to complex enterprise systems, integrating additional layers or patterns such as caching layers, integration layers, or service layers as needed.
2.4 Handling Cross-Cutting Concerns: Logging, Security, and Transactions
Cross-cutting concerns are aspects of a program that affect other concerns. In enterprise layered architecture, these concerns typically span multiple layers and modules, making their management critical for maintainability, security, and performance.
In this section, we will explore best practices for handling three major cross-cutting concerns: Logging, Security, and Transactions. Each topic will include mind maps and practical examples to illustrate how to integrate these concerns effectively.
Logging
Logging is essential for monitoring, debugging, and auditing enterprise applications. Proper logging helps diagnose issues quickly and provides insights into system behavior.
Mind Map: Logging in Layered Architecture
Example: Implementing Structured Logging with Correlation IDs (Java + Spring Boot)
// Filter to add Correlation ID to MDC (Mapped Diagnostic Context)
@Component
public class CorrelationIdFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String correlationId = request.getHeader("X-Correlation-ID");
if (correlationId == null) {
correlationId = UUID.randomUUID().toString();
}
MDC.put("correlationId", correlationId);
response.addHeader("X-Correlation-ID", correlationId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.remove("correlationId");
}
}
}
// Logger usage in service
@Slf4j
@Service
public class OrderService {
public void processOrder(Order order) {
log.info("Processing order with ID: {}", order.getId());
// business logic
}
}
This approach ensures every log entry contains a correlation ID, enabling tracing of requests across layers and services.
Security
Security is a paramount cross-cutting concern that must be integrated at every layer to protect enterprise applications from threats.
Mind Map: Security Concerns and Patterns
Example: Securing a REST API with JWT (Node.js + Express)
const jwt = require('jsonwebtoken');
const express = require('express');
const app = express();
// Middleware to verify JWT
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, process.env.ACCESS_TOKEN_SECRET, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
// Protected route example
app.get('/api/orders', authenticateToken, (req, res) => {
// Only authenticated users can access
res.json({ orders: [/* ... */] });
});
This pattern ensures that only users with valid tokens can access protected endpoints.
Transactions
Transactions ensure data consistency and integrity, especially important in enterprise systems where multiple operations must succeed or fail as a unit.
Mind Map: Transaction Management
Example: Declarative Transaction Management with Spring Boot
@Service
public class PaymentService {
@Autowired
private PaymentRepository paymentRepository;
@Transactional
public void processPayment(Payment payment) {
paymentRepository.save(payment);
// Additional business logic
// If any exception occurs, transaction rolls back automatically
}
}
Example: Saga Pattern for Distributed Transactions (Conceptual)
This asynchronous approach avoids locking resources across services and improves scalability.
Summary
Effectively handling cross-cutting concerns like logging, security, and transactions is vital for building robust, maintainable, and high-performance enterprise applications. Leveraging best practices, appropriate tools, and architectural patterns ensures these concerns are managed consistently across layers.
References & Further Reading
- “Enterprise Integration Patterns” by Gregor Hohpe and Bobby Woolf
- Spring Framework Documentation: https://spring.io/projects/spring-framework
- OWASP Top Ten Security Risks: https://owasp.org/www-project-top-ten/
- Martin Fowler on Saga Pattern: https://martinfowler.com/articles/saga.html
2.5 Performance Considerations and Optimization Strategies
In layered architecture, performance can sometimes be impacted by the overhead of multiple layers communicating with each other. Understanding and optimizing these interactions is critical to building high-performance enterprise systems.
Key Performance Considerations in Layered Architecture
- Layer Communication Overhead: Each call between layers adds latency.
- Data Transformation Costs: Data often needs to be transformed or mapped when crossing layers.
- Redundant Processing: Avoid duplicated logic or repeated data fetching across layers.
- Resource Utilization: Efficient use of CPU, memory, and I/O at each layer.
- Concurrency and Threading: Proper management to prevent bottlenecks.
- Caching Strategies: Reducing repeated expensive operations.
Mind Map: Performance Factors in Layered Architecture
Optimization Strategies
Minimize Layer Crossings
Example: Instead of having the UI layer call the service layer, which then calls the data access layer multiple times, batch requests or combine operations to reduce the number of calls.
// Inefficient: multiple calls across layers
List<Order> orders = orderService.getOrdersByCustomer(customerId);
for(Order order : orders) {
Customer cust = customerService.getCustomer(order.getCustomerId());
// ...
}
// Optimized: fetch all needed data in one service call
List<OrderWithCustomer> ordersWithCustomers = orderService.getOrdersWithCustomers(customerId);
Use Asynchronous Processing Where Possible
Offload long-running or I/O-bound operations asynchronously to prevent blocking layers.
Example: Using CompletableFuture in Java to fetch data from multiple services concurrently.
CompletableFuture<Order> orderFuture = CompletableFuture.supplyAsync(() -> orderService.getOrder(orderId));
CompletableFuture<Customer> customerFuture = CompletableFuture.supplyAsync(() -> customerService.getCustomer(customerId));
CompletableFuture.allOf(orderFuture, customerFuture).join();
// Process results after both complete
Optimize Data Transformation
Use efficient mapping libraries (e.g., MapStruct) or manual mapping to reduce overhead.
Example: Avoid reflection-based mappers in hot paths.
Implement Caching at Appropriate Layers
- Cache frequently accessed data in the service or data access layer.
- Use distributed caches (e.g., Redis) for shared data.
Example: Caching product catalog data to avoid repeated database hits.
@Cacheable("productCatalog")
public List<Product> getProductCatalog() {
return productRepository.findAll();
}
Avoid Redundant Processing
Centralize business logic to avoid duplication.
Example: Validate input once in the service layer rather than in both UI and data layers.
Optimize Database Access
- Use pagination and filtering to limit data volume.
- Employ prepared statements and connection pooling.
Example: Fetch only required columns instead of SELECT *.
Mind Map: Optimization Strategies
Real-World Example: Optimizing a Customer Order System
Scenario: A layered architecture system where the UI calls the service layer, which calls the data access layer multiple times per user request.
Problem: High latency due to multiple synchronous calls and redundant data fetching.
Optimization Steps:
- Batch Data Fetching: Modify service layer to fetch all required customer and order data in a single query.
- Asynchronous Calls: Use async calls for non-dependent data fetching.
- Caching: Cache customer profile data that rarely changes.
- Data Mapping: Use MapStruct for fast DTO to entity conversions.
Outcome: Reduced average response time from 800ms to 250ms, improved throughput by 3x.
Summary
Performance in layered architecture depends on minimizing unnecessary overhead between layers, efficient data handling, and smart use of caching and concurrency. By applying these optimization strategies, senior engineers and technical leads can ensure their enterprise systems remain responsive and scalable under load.
3. Microservices Architecture
3.1 Microservices: Concepts and Benefits for Enterprise Systems
Microservices architecture has emerged as a dominant approach for building scalable, maintainable, and flexible enterprise systems. Unlike traditional monolithic architectures, microservices decompose an application into a suite of small, independently deployable services, each running in its own process and communicating via lightweight mechanisms, often HTTP APIs or messaging queues.
Core Concepts of Microservices
- Service Independence: Each microservice is autonomous, owning its own data and logic.
- Single Responsibility: Services are designed around business capabilities.
- Decentralized Data Management: Each service manages its own database or data source.
- Inter-Service Communication: Services communicate through well-defined APIs or asynchronous messaging.
- Continuous Delivery: Independent deployment enables rapid iteration and scaling.
Mind Map: Microservices Core Concepts
Benefits of Microservices for Enterprise Systems
-
Scalability: Services can be scaled independently based on demand, optimizing resource usage.
-
Flexibility in Technology Stack: Teams can choose the best technology suited for each service without affecting the entire system.
-
Improved Fault Isolation: Failure in one service does not necessarily bring down the entire system.
-
Faster Time to Market: Smaller codebases and independent teams enable quicker development cycles.
-
Easier Maintenance and Updates: Smaller, focused services reduce complexity and improve maintainability.
-
Organizational Alignment: Teams can be aligned around business capabilities, improving ownership and accountability.
Mind Map: Benefits of Microservices
Example: Online Retail Enterprise
Consider an online retail enterprise transitioning from a monolithic system to microservices. The monolith handles user management, product catalog, order processing, payment, and shipping in a single codebase.
Microservices decomposition:
- User Service: Manages user profiles, authentication, and authorization.
- Catalog Service: Handles product listings, categories, and inventory.
- Order Service: Processes customer orders and order status.
- Payment Service: Handles payment processing and transactions.
- Shipping Service: Manages shipment tracking and logistics.
Each service owns its database and exposes RESTful APIs. For example, the Order Service communicates asynchronously with the Payment Service via a message queue to process payments, improving resilience and decoupling.
Benefits realized:
- The Payment Service can be scaled independently during peak sale events.
- Teams can deploy updates to the Catalog Service without impacting order processing.
- Fault in the Shipping Service does not affect user login or order placement.
Best Practices Embedded in Microservices Concepts
- Design around business capabilities: Avoid technical decomposition; focus on domains.
- Use asynchronous communication where possible: Improves resilience and scalability.
- Automate deployment pipelines: Supports independent service delivery.
- Implement centralized logging and monitoring: To maintain observability across distributed services.
- Define clear API contracts: Ensures loose coupling and easier integration.
Microservices architecture, when applied thoughtfully, empowers enterprises to build backend systems that are robust, scalable, and aligned with evolving business needs. The modular nature of microservices also facilitates adopting new technologies and responding rapidly to market changes, making it a compelling choice for modern enterprise software engineering.
3.2 Designing Microservices: Bounded Contexts and Domain-Driven Design
Designing microservices effectively requires a deep understanding of the domain and a clear boundary definition between services. Domain-Driven Design (DDD) provides a powerful methodology to identify and define these boundaries through the concept of Bounded Contexts. This section explores how to leverage DDD principles to design microservices that are cohesive, loosely coupled, and aligned with business capabilities.
What is a Bounded Context?
A Bounded Context is a logical boundary within which a particular domain model applies consistently. It encapsulates a specific part of the business domain, ensuring that the language, rules, and data models inside it are coherent and isolated from other contexts.
- Each bounded context can be implemented as an independent microservice.
- It helps avoid ambiguity and complexity by separating different models that might have conflicting meanings.
Why Use Bounded Contexts in Microservices?
- Clear Ownership: Each microservice owns its domain model and logic.
- Independent Evolution: Services can evolve independently without breaking others.
- Scalability: Enables scaling of specific business capabilities.
- Team Alignment: Teams can be organized around bounded contexts for better collaboration.
Mind Map: Core Concepts of Bounded Contexts in Microservices
Domain-Driven Design Strategic Patterns for Microservices
DDD provides several strategic patterns to manage relationships between bounded contexts:
- Context Map: Visualizes relationships between bounded contexts.
- Shared Kernel: Shared subset of the domain model between contexts.
- Customer-Supplier: One context (supplier) provides functionality that another (customer) depends on.
- Anti-Corruption Layer (ACL): Protects a bounded context from external models by translating between models.
Example: Designing an E-Commerce System with Bounded Contexts
Imagine an e-commerce platform with the following business capabilities:
- Catalog Management
- Order Processing
- Customer Management
- Payment Processing
Each of these can be modeled as a bounded context and implemented as a microservice.
Step 1: Identify Bounded Contexts
- Catalog Context: Manages product listings, categories, and inventory.
- Order Context: Handles order lifecycle, status, and fulfillment.
- Customer Context: Manages customer profiles, preferences, and authentication.
- Payment Context: Processes payments, refunds, and transactions.
Step 2: Define Ubiquitous Language per Context
- In Catalog Context, “Product” means the item for sale.
- In Order Context, “Product” might refer to a snapshot of the product at order time.
Step 3: Context Mapping Example
- Catalog Context
- Order Context
- Customer-Supplier relationship with Catalog Context
- Uses Anti-Corruption Layer to translate product data
- Customer Context
- Payment Context
Step 4: Microservice API Boundaries
- Catalog Service exposes APIs for product search and inventory queries.
- Order Service exposes APIs for order creation and status updates.
Mind Map: Example E-Commerce Microservice Design
Best Practices When Designing Microservices with Bounded Contexts
- Align Microservices with Business Capabilities: Each microservice should represent a meaningful business domain.
- Keep Context Boundaries Explicit: Avoid overlapping responsibilities.
- Use Ubiquitous Language: Ensure consistent terminology within each microservice.
- Isolate Data Ownership: Each microservice owns its data to prevent tight coupling.
- Implement ACLs for Integration: Use Anti-Corruption Layers to translate between different models when integrating services.
- Design for Failure: Assume services can fail and design communication accordingly (e.g., asynchronous messaging).
Example Code Snippet: Defining an Aggregate in Order Microservice (Java)
// Order Aggregate Root
public class Order {
private String orderId;
private List<OrderItem> items;
private OrderStatus status;
public Order(String orderId) {
this.orderId = orderId;
this.items = new ArrayList<>();
this.status = OrderStatus.CREATED;
}
public void addItem(ProductSnapshot product, int quantity) {
items.add(new OrderItem(product, quantity));
}
public void confirm() {
if (items.isEmpty()) {
throw new IllegalStateException("Order must have at least one item");
}
this.status = OrderStatus.CONFIRMED;
}
// Other domain behaviors...
}
// Value Object representing product data at order time
public class ProductSnapshot {
private String productId;
private String name;
private BigDecimal price;
public ProductSnapshot(String productId, String name, BigDecimal price) {
this.productId = productId;
this.name = name;
this.price = price;
}
}
This example shows how the Order microservice uses a snapshot of product data to avoid direct dependency on the Catalog service’s domain model.
Summary
Designing microservices around bounded contexts using Domain-Driven Design helps create clear, maintainable, and scalable backend systems. By defining explicit boundaries, aligning services with business domains, and using patterns like Anti-Corruption Layers, teams can build robust microservice architectures that evolve gracefully with business needs.
3.3 Best Practices for Service Communication and Data Management
In microservices architecture, effective service communication and robust data management are pivotal to building scalable, maintainable, and high-performance enterprise systems. This section explores best practices, supported by clear examples and mind maps to help you visualize and implement these concepts.
Service Communication Best Practices
- Choose the Right Communication Style
- Synchronous Communication: Typically HTTP/REST or gRPC; suitable for request-response scenarios.
- Asynchronous Communication: Messaging queues, event-driven patterns; ideal for decoupling and resilience.
Example:
A payment microservice calls an inventory microservice synchronously to check stock availability before confirming an order. However, order confirmation events are published asynchronously to downstream services like notification and analytics.
- Use API Gateways and Service Meshes
- API Gateways centralize cross-cutting concerns like authentication, rate limiting, and routing.
- Service Meshes (e.g., Istio, Linkerd) manage service-to-service communication, providing observability, retries, and circuit breaking.
Example:
An API Gateway routes client requests to appropriate microservices, while the service mesh handles retries and load balancing transparently between services.
- Implement Idempotency and Retry Policies
- Ensure that repeated requests (due to retries) do not cause inconsistent states.
- Use unique request IDs and idempotent operations.
Example:
A payment service processes a transaction request. If the client retries due to a timeout, the service checks the request ID to avoid duplicate charges.
- Design for Fault Tolerance
- Use circuit breakers to prevent cascading failures.
- Implement timeouts and fallbacks.
Example:
If the inventory service is down, the order service falls back to a cached stock level or returns a friendly error message.
- Version Your APIs
- Maintain backward compatibility.
- Use URL versioning or headers.
Example:
The user profile service exposes /api/v1/users and /api/v2/users endpoints to support clients with different capabilities.
Mind Map: Service Communication Best Practices
Data Management Best Practices
- Database per Service Pattern
- Each microservice owns its database to ensure loose coupling.
Example:
The order service uses a relational database, while the product catalog service uses a document database optimized for flexible schemas.
- Eventual Consistency and Saga Pattern
- Use sagas to manage distributed transactions across services.
- Embrace eventual consistency rather than distributed ACID transactions.
Example:
An order placement saga coordinates between payment, inventory, and shipping services using compensating transactions if any step fails.
- Data Replication and CQRS
- Separate read and write models to optimize performance.
- Use event sourcing to replicate state changes.
Example:
The inventory service writes updates to its database but publishes events to update a read-optimized cache for fast queries.
- Data Schema Evolution and Compatibility
- Use schema registries and backward-compatible changes.
Example:
Kafka topics use Avro schemas managed by a schema registry to ensure producers and consumers remain compatible.
- Secure Data Access and Encryption
- Enforce strict access controls.
- Encrypt sensitive data at rest and in transit.
Example:
The customer service encrypts personal data fields in its database and uses TLS for all inter-service communication.
Mind Map: Data Management Best Practices
Integrated Example: Order Processing Microservices
Scenario:
- The
Order Servicereceives an order request. - It synchronously calls the
Inventory Serviceto verify stock. - If stock is available, it publishes an
OrderCreatedevent asynchronously. - The
Payment Servicelistens forOrderCreatedevents and processes payment. - The
Shipping Servicelistens forPaymentConfirmedevents to initiate shipment.
Key Practices Applied:
- Synchronous call for immediate stock validation.
- Asynchronous event-driven communication for decoupling.
- Saga pattern to handle distributed transaction failures.
- API Gateway routes external requests.
- Each service owns its database.
- Circuit breakers and retries implemented.
This approach balances consistency, performance, and resilience.
By following these best practices, senior engineers and technical leads can design microservices that communicate efficiently and manage data reliably, enabling enterprise systems to scale and perform under demanding workloads.
3.4 Example: Building a High-Performance Microservice with Asynchronous Messaging
In this section, we will explore how to build a high-performance microservice leveraging asynchronous messaging. Asynchronous communication decouples services, improves scalability, and enhances fault tolerance — all critical qualities for enterprise-grade backend systems.
Why Asynchronous Messaging?
- Decoupling: Services communicate without waiting for immediate responses.
- Scalability: Message queues buffer load spikes, allowing consumers to process at their own pace.
- Fault Tolerance: Messages can be retried or persisted, reducing data loss.
- Responsiveness: Frontend or upstream services remain responsive, improving user experience.
Core Components of the Example Microservice
Mind Map: High-Performance Microservice with Asynchronous Messaging
Step 1: Define the Use Case
Let’s consider a User Notification Service that sends notifications (email, SMS, push) asynchronously when triggered by other services.
- Trigger: Order Service emits an event
OrderPlaced. - Notification Service: Listens for
OrderPlacedevents and sends notifications.
Step 2: Choose the Messaging Infrastructure
For this example, we’ll use RabbitMQ as the message broker.
- Supports reliable messaging with acknowledgments.
- Supports queues, exchanges, and routing keys.
Step 3: Implement the Message Producer (Order Service)
// Pseudocode for publishing an event to RabbitMQ
public class OrderService {
private final RabbitTemplate rabbitTemplate;
public void placeOrder(Order order) {
// Business logic to place order
saveOrder(order);
// Publish event asynchronously
OrderPlacedEvent event = new OrderPlacedEvent(order.getId(), order.getUserId());
rabbitTemplate.convertAndSend("order.exchange", "order.placed", event);
}
}
Best Practice: Use a dedicated exchange and routing keys to organize event flows.
Step 4: Implement the Message Consumer (Notification Service)
// Pseudocode for consuming messages asynchronously
@Component
public class NotificationListener {
@RabbitListener(queues = "notification.queue")
public void handleOrderPlaced(OrderPlacedEvent event) {
// Process notification asynchronously
sendNotification(event.getUserId(), "Your order has been placed successfully.");
}
private void sendNotification(String userId, String message) {
// Implementation to send email/SMS/push
}
}
Best Practice: Keep message handlers idempotent to handle retries safely.
Step 5: Performance Optimization Techniques
Mind Map: Performance Optimization in Asynchronous Microservices
Step 6: Error Handling and Reliability
- Dead Letter Queues (DLQ): Messages that fail processing multiple times are routed to DLQ for manual inspection.
- Retries: Implement exponential backoff retries for transient failures.
- Idempotency: Ensure that processing the same message multiple times does not cause inconsistent state.
// Example of idempotency check
public void handleOrderPlaced(OrderPlacedEvent event) {
if (notificationAlreadySent(event.getOrderId())) {
return; // Skip duplicate processing
}
sendNotification(event.getUserId(), "Your order has been placed.");
markNotificationSent(event.getOrderId());
}
Step 7: Monitoring and Observability
- Collect metrics on message throughput, processing latency, and error rates.
- Use distributed tracing (e.g., OpenTelemetry) to trace message flows across services.
- Log message metadata for troubleshooting.
Mind Map: Observability in Asynchronous Microservices
Summary
Building a high-performance microservice with asynchronous messaging involves:
- Designing clear message contracts and event schemas.
- Using a robust message broker like RabbitMQ or Kafka.
- Ensuring consumers are idempotent and resilient.
- Optimizing throughput with batching and parallelism.
- Implementing comprehensive error handling.
- Monitoring system health with metrics and tracing.
This approach enables scalable, maintainable, and responsive enterprise backend systems.
For further reading, consider exploring:
- RabbitMQ Tutorials
- Kafka Documentation
- Domain-Driven Design and Event-Driven Architecture
- OpenTelemetry for Distributed Tracing
3.5 Challenges and Solutions: Service Discovery, Load Balancing, and Fault Tolerance
In microservices architecture, managing the dynamic nature of services is critical to maintaining a resilient, scalable, and high-performance system. This section explores the key challenges related to service discovery, load balancing, and fault tolerance, and provides practical solutions with examples.
Service Discovery
Challenge: In a microservices environment, services are often ephemeral and can scale up or down dynamically. Hardcoding service locations (IP addresses or hostnames) is impractical and brittle.
Solution: Implement a dynamic service discovery mechanism that allows services to register themselves and discover others at runtime.
Mind Map: Service Discovery
Example: Using Netflix Eureka for Client-Side Discovery
// Service registration example (Spring Boot application)
@EnableEurekaClient
@SpringBootApplication
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}
// Service discovery example
@RestController
public class OrderController {
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/user-info")
public String getUserInfo() {
List<ServiceInstance> instances = discoveryClient.getInstances("user-service");
ServiceInstance instance = instances.get(0); // Simple load balancing
String baseUrl = instance.getUri().toString();
// Call user-service using baseUrl
return "User info from " + baseUrl;
}
}
Load Balancing
Challenge: Efficiently distributing requests across multiple service instances to maximize throughput, minimize latency, and avoid overloading any single instance.
Solution: Use load balancing strategies either on the client side or server side.
Mind Map: Load Balancing
Example: Client-Side Load Balancing with Spring Cloud Ribbon
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
// Usage
@Autowired
private RestTemplate restTemplate;
public String callUserService() {
// 'user-service' is the service ID registered in Eureka
return restTemplate.getForObject("http://user-service/users/123", String.class);
}
Fault Tolerance
Challenge: Microservices are distributed and prone to partial failures — network issues, service crashes, or slow responses can cascade and degrade the entire system.
Solution: Implement fault tolerance patterns such as circuit breakers, retries, bulkheads, and fallback mechanisms.
Mind Map: Fault Tolerance
Example: Circuit Breaker with Resilience4j
@Service
public class PaymentService {
@CircuitBreaker(name = "paymentService", fallbackMethod = "fallbackPayment")
public String processPayment(String orderId) {
// Simulate remote call
if (new Random().nextInt(10) < 7) {
throw new RuntimeException("Payment gateway timeout");
}
return "Payment processed for order " + orderId;
}
public String fallbackPayment(String orderId, Throwable t) {
return "Payment service is currently unavailable. Please try again later for order " + orderId;
}
}
Summary
| Challenge | Solution Approach | Tools / Examples |
|---|---|---|
| Service Discovery | Dynamic registry & client/server discovery | Eureka, Consul, DNS |
| Load Balancing | Client-side or server-side balancing | Ribbon, NGINX, HAProxy |
| Fault Tolerance | Circuit breakers, retries, bulkheads | Resilience4j, Hystrix |
By integrating these patterns and tools, technical leads and senior engineers can design microservices systems that are resilient, scalable, and performant, even under heavy load and failure conditions.
4. Event-Driven Architecture
4.1 Principles of Event-Driven Architecture in Enterprise Systems
Event-Driven Architecture (EDA) is a powerful architectural paradigm widely adopted in enterprise systems to build scalable, loosely coupled, and highly responsive applications. At its core, EDA revolves around the production, detection, consumption, and reaction to events — discrete pieces of information that represent a change in state or an occurrence within a system.
What is Event-Driven Architecture?
EDA is an architectural style where components communicate primarily through the generation and handling of events. Instead of direct request-response interactions, components emit events asynchronously, enabling other components to react independently.
Core Principles of Event-Driven Architecture
Mind Map: Principles of Event-Driven Architecture
Detailed Explanation of Key Principles
Asynchronous Communication
In EDA, event producers emit events without waiting for consumers to process them. This non-blocking behavior improves system responsiveness and throughput.
Example: A user places an order on an e-commerce site. The order service emits an OrderPlaced event. Inventory, billing, and shipping services consume this event independently to update stock, charge the customer, and prepare shipment.
Loose Coupling
Producers and consumers do not need to know about each other’s implementation or location. They only agree on the event contract (schema).
Example: The inventory service does not need to know who placed the order, only that an OrderPlaced event has occurred.
Event Channels / Brokers
Events are transmitted via channels such as message brokers (Kafka, RabbitMQ) or event buses. These intermediaries provide buffering, routing, and delivery guarantees.
Example: Using Apache Kafka as a durable event log that multiple consumers can subscribe to.
Event Schema and Versioning
Events must have well-defined schemas to ensure compatibility. As systems evolve, schemas may change, so versioning strategies (e.g., backward compatibility, schema registries) are essential.
Example: Using Avro schemas with a schema registry to manage event versions.
Reliability and Durability
Events should not be lost even in case of failures. Persistent queues and acknowledgement protocols ensure reliable delivery.
Example: A message broker persists events to disk until consumers confirm processing.
Idempotency
Since events might be delivered multiple times, consumers should handle duplicates gracefully.
Example: The billing service checks if an invoice for an order already exists before creating a new one.
Event Ordering
Some business processes require events to be processed in order. Partitioning events by keys and using ordered queues help maintain this.
Example: All events related to a single customer are routed to the same partition to preserve order.
Example: Event-Driven Order Processing System
Mind Map: Event-Driven Order Processing
Flow:
- User places an order →
OrderPlacedevent emitted. - Inventory service reduces stock and emits
InventoryUpdated. - Billing service processes payment and emits
PaymentProcessed. - Shipping service prepares shipment and emits
ShipmentCreated. - Notification service sends confirmation.
This decoupled flow allows each service to scale independently and handle failures gracefully.
Summary
Event-Driven Architecture empowers enterprise systems to be more scalable, resilient, and maintainable by embracing asynchronous, loosely coupled communication through events. Understanding and applying its core principles — asynchronous communication, loose coupling, event schema management, reliability, idempotency, and ordering — is essential for building high-performance backend systems.
Further Reading & Tools
- Apache Kafka: https://kafka.apache.org/
- Event Sourcing Patterns: https://martinfowler.com/eaaDev/EventSourcing.html
- Schema Registry: https://docs.confluent.io/platform/current/schema-registry/index.html
- Designing Event-Driven Systems by Ben Stopford
4.2 Designing Event Streams and Event Sourcing Patterns
Introduction
Event Streams and Event Sourcing are foundational concepts in event-driven architecture that enable systems to capture all changes as a sequence of immutable events. This approach provides a reliable audit trail, supports temporal queries, and facilitates high scalability and resilience.
What is an Event Stream?
An event stream is an ordered, append-only sequence of events that represent state changes in a system. Each event is a record of something that happened at a particular point in time.
Key Characteristics:
- Immutable: Events cannot be changed once written.
- Ordered: Events are stored in the order they occurred.
- Append-only: New events are added to the end of the stream.
What is Event Sourcing?
Event Sourcing is a pattern where state changes are captured as a sequence of events rather than storing just the current state. The current state can be reconstructed by replaying these events.
Mind Map: Core Concepts of Event Streams and Event Sourcing
Designing Event Streams
When designing event streams, consider the following best practices:
-
Define Clear Event Boundaries:
- Events should represent meaningful domain changes.
- Example:
OrderPlaced,PaymentReceived,OrderShipped.
-
Use Strongly Typed Events:
- Define event schemas with explicit fields.
- Use versioning to handle schema evolution.
-
Partition Event Streams by Aggregate:
- Each aggregate instance (e.g., an order) has its own event stream.
-
Include Metadata:
- Timestamp, event ID, correlation ID, causation ID.
-
Ensure Idempotency:
- Events should be processed in a way that repeated handling does not cause inconsistent state.
Mind Map: Designing Event Streams
Event Sourcing Pattern Example
Scenario: Order Management System
Instead of storing the current order state, we store all events related to the order:
OrderCreated{ orderId, customerId, createdAt }ItemAdded{ orderId, productId, quantity }ItemRemoved{ orderId, productId }OrderConfirmed{ orderId, confirmedAt }
Reconstructing State: To get the current state of an order, replay all events for that order in sequence.
class Order:
def __init__(self, order_id):
self.order_id = order_id
self.items = {}
self.confirmed = False
def apply(self, event):
if event['type'] == 'OrderCreated':
self.order_id = event['orderId']
elif event['type'] == 'ItemAdded':
self.items[event['productId']] = self.items.get(event['productId'], 0) + event['quantity']
elif event['type'] == 'ItemRemoved':
if event['productId'] in self.items:
del self.items[event['productId']]
elif event['type'] == 'OrderConfirmed':
self.confirmed = True
# Rebuild order from events
order_events = [
{'type': 'OrderCreated', 'orderId': '123'},
{'type': 'ItemAdded', 'orderId': '123', 'productId': 'A1', 'quantity': 2},
{'type': 'ItemAdded', 'orderId': '123', 'productId': 'B2', 'quantity': 1},
{'type': 'OrderConfirmed', 'orderId': '123'}
]
order = Order('123')
for event in order_events:
order.apply(event)
print(order.items) # Output: {'A1': 2, 'B2': 1}
print(order.confirmed) # Output: True
Best Practices for Event Sourcing
-
Snapshotting: To improve performance, periodically save snapshots of the aggregate state to avoid replaying the entire event history.
-
Event Versioning: Use backward-compatible changes and maintain multiple event versions if necessary.
-
Event Store Selection: Choose an event store that supports append-only writes, efficient reads, and event querying (e.g., Apache Kafka, EventStoreDB).
-
Handling Eventual Consistency: Design consumers to handle eventual consistency and out-of-order events gracefully.
Mind Map: Event Sourcing Best Practices
Real-World Example: Event Sourcing in a Payment System
Events:
PaymentInitiatedPaymentAuthorizedPaymentCapturedPaymentFailed
Each event captures a state transition. The payment aggregate replays these events to determine the current status.
{
"type": "PaymentAuthorized",
"paymentId": "pay_456",
"authorizedAmount": 100.00,
"currency": "USD",
"timestamp": "2024-06-01T12:00:00Z"
}
This approach allows auditability, rollback, and temporal queries (e.g., “What was the payment status at a given time?”).
Summary
Designing event streams and applying event sourcing patterns empower enterprise systems with auditability, scalability, and flexibility. By carefully defining event boundaries, schemas, and leveraging snapshots and versioning, engineers can build robust backends that handle complex business logic and high throughput effectively.
4.3 Practical Example: Implementing Event-Driven Order Processing System
In this section, we will walk through a practical example of implementing an event-driven order processing system, a common use case in enterprise applications such as e-commerce platforms, supply chain management, and financial services.
Overview
An event-driven architecture (EDA) decouples components by communicating through events, enabling asynchronous processing, scalability, and resilience. In an order processing system, events represent changes or actions such as order creation, payment confirmation, inventory update, and shipment.
Key Components of the System
Event Flow
OrderCreated
-> PaymentProcessed
-> InventoryReserved
-> OrderShipped
-> NotificationSent
Step-by-Step Implementation
Order Service: Publishing OrderCreated Event
// Pseudocode example using a message broker (e.g., Kafka, RabbitMQ)
public class OrderService {
private EventPublisher eventPublisher;
public void createOrder(Order order) {
// Validate order
validateOrder(order);
// Persist order to DB
orderRepository.save(order);
// Publish event
OrderCreatedEvent event = new OrderCreatedEvent(order.getId(), order.getCustomerId(), order.getItems());
eventPublisher.publish("OrderCreated", event);
}
}
Payment Service: Consuming OrderCreated and Publishing PaymentProcessed
public class PaymentService {
private EventPublisher eventPublisher;
@EventListener(topic = "OrderCreated")
public void onOrderCreated(OrderCreatedEvent event) {
// Process payment
boolean paymentSuccess = paymentGateway.charge(event.getCustomerId(), event.getAmount());
if (paymentSuccess) {
PaymentProcessedEvent paymentEvent = new PaymentProcessedEvent(event.getOrderId(), true);
eventPublisher.publish("PaymentProcessed", paymentEvent);
} else {
// Handle payment failure
}
}
}
Inventory Service: Reserving Inventory
public class InventoryService {
private EventPublisher eventPublisher;
@EventListener(topic = "PaymentProcessed")
public void onPaymentProcessed(PaymentProcessedEvent event) {
if (event.isSuccessful()) {
boolean reserved = inventoryManager.reserveItems(event.getOrderId());
if (reserved) {
InventoryReservedEvent reservedEvent = new InventoryReservedEvent(event.getOrderId());
eventPublisher.publish("InventoryReserved", reservedEvent);
} else {
// Handle inventory shortage
}
}
}
}
Shipping Service: Scheduling Shipment
public class ShippingService {
private EventPublisher eventPublisher;
@EventListener(topic = "InventoryReserved")
public void onInventoryReserved(InventoryReservedEvent event) {
shipmentScheduler.scheduleShipment(event.getOrderId());
OrderShippedEvent shippedEvent = new OrderShippedEvent(event.getOrderId());
eventPublisher.publish("OrderShipped", shippedEvent);
}
}
Notification Service: Informing Customers
public class NotificationService {
@EventListener(topic = "OrderShipped")
public void onOrderShipped(OrderShippedEvent event) {
notificationSender.sendOrderShippedNotification(event.getOrderId());
}
}
Best Practices Embedded in This Example
- Loose Coupling: Each service only knows about the events it consumes or produces, enabling independent development and deployment.
- Asynchronous Communication: Using events allows the system to handle spikes in load gracefully.
- Idempotency: Event handlers should be idempotent to handle duplicate events safely.
- Event Schema Versioning: Define clear event schemas and version them to support backward compatibility.
- Error Handling: Implement dead-letter queues or retry mechanisms for failed event processing.
Additional Mind Map: Best Practices for Event-Driven Systems
Summary
This practical example demonstrates how an event-driven architecture can be applied to an order processing system to achieve scalability, resilience, and maintainability. By leveraging asynchronous events, each component focuses on its domain responsibility while collaborating through well-defined event contracts.
This approach is highly extensible: new services like analytics, fraud detection, or customer loyalty can be added by subscribing to existing events without impacting the core order flow.
4.4 Best Practices for Event Schema Evolution and Versioning
In event-driven architectures, event schemas define the structure of the data passed between services. As systems evolve, these schemas inevitably change. Managing schema evolution and versioning effectively is critical to maintaining backward and forward compatibility, ensuring system resilience, and avoiding data loss or processing errors.
Why Schema Evolution and Versioning Matter
- Backward Compatibility: New consumers can read old events.
- Forward Compatibility: Old consumers can safely ignore new fields.
- Data Integrity: Prevents data corruption or loss during schema changes.
- System Stability: Avoids runtime failures due to unexpected schema changes.
Key Principles for Event Schema Evolution
- Additive Changes Only: Add new optional fields instead of removing or renaming existing ones.
- Avoid Breaking Changes: Do not change data types or mandatory fields without versioning.
- Use Default Values: For new fields to maintain compatibility.
- Deprecate Carefully: Mark fields as deprecated but keep them until all consumers migrate.
Mind Map: Event Schema Evolution Strategies
Versioning Approaches
Schema Version Field
Embed a version field inside the event payload.
{
"eventType": "OrderCreated",
"version": 2,
"orderId": "12345",
"customerId": "67890",
"discountCode": "SPRINGSALE" // new optional field added in v2
}
Best Practices:
- Consumers switch logic based on version.
- Older versions remain supported until deprecated.
Topic or Stream Versioning
Publish different versions of events to separate Kafka topics or message queues.
Example:
order-created-v1order-created-v2
Best Practices:
- Clear separation of event versions.
- Easier consumer migration.
Event Type Versioning
Use different event type names for versions.
Example:
OrderCreatedV1OrderCreatedV2
Best Practices:
- Explicit versioning in event names.
- Consumers subscribe selectively.
Mind Map: Versioning Approaches
Example: Evolving an OrderCreated Event Schema
Initial Schema (v1):
{
"eventType": "OrderCreated",
"version": 1,
"orderId": "12345",
"customerId": "67890",
"orderTotal": 100.00
}
Evolved Schema (v2): Added optional discountCode and changed orderTotal to string to support currency formatting.
{
"eventType": "OrderCreated",
"version": 2,
"orderId": "12345",
"customerId": "67890",
"orderTotal": "100.00 USD",
"discountCode": "SPRINGSALE" // optional
}
Handling in Consumers:
if event['version'] == 1:
# process with numeric orderTotal
total = float(event['orderTotal'])
elif event['version'] == 2:
# parse string orderTotal
total = parse_currency(event['orderTotal'])
discount = event.get('discountCode', None)
Tools and Formats Supporting Schema Evolution
| Tool/Format | Description | Evolution Support |
|---|---|---|
| Apache Avro | Compact binary serialization format | Supports schema evolution with backward and forward compatibility via schema registry |
| Protocol Buffers (Protobuf) | Google’s language-neutral serialization | Supports optional fields and default values for evolution |
| JSON Schema | Schema definition for JSON data | Supports versioning but less strict enforcement |
Mind Map: Tools Supporting Schema Evolution
Best Practices Summary
- Always design events with evolution in mind.
- Use additive changes and avoid breaking changes.
- Embed version information or use topic/event type versioning.
- Employ schema registries to centrally manage and validate schemas.
- Communicate schema changes clearly to all teams.
- Test consumers against multiple schema versions.
Additional Example: Using Avro Schema Registry
Registering a new schema version:
{
"type": "record",
"name": "OrderCreated",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerId", "type": "string"},
{"name": "orderTotal", "type": "double"},
{"name": "discountCode", "type": ["null", "string"], "default": null}
]
}
The schema registry ensures compatibility with previous versions before accepting the new schema.
By following these best practices and leveraging appropriate tools, technical leads and senior engineers can ensure their event-driven systems remain robust, adaptable, and performant as they evolve over time.
4.5 Performance Tuning: Event Queues, Brokers, and Throughput Optimization
Event-driven architectures rely heavily on event queues and brokers to decouple components and enable asynchronous communication. However, to achieve high performance and scalability, careful tuning and optimization of these components is essential. In this section, we’ll explore key strategies, best practices, and examples to optimize event queues, brokers, and maximize throughput.
Understanding the Components
Optimizing Event Queues
Event queues act as buffers between producers and consumers. Their configuration directly affects latency, throughput, and reliability.
- Buffer Size: Larger buffers can hold more events, reducing the chance of producer blocking but increasing memory usage.
- Persistence: Durable queues write events to disk, ensuring reliability but potentially adding latency.
- Acknowledgements: Configuring acknowledgement modes (e.g., auto-ack vs manual ack) impacts throughput and message loss risk.
Example:
In RabbitMQ, setting prefetch_count controls how many messages a consumer can process concurrently. Increasing this can improve throughput but risks overwhelming the consumer.
# Python pika example: setting prefetch_count
channel.basic_qos(prefetch_count=50)
Broker Selection and Configuration
Choosing the right broker and tuning its parameters is critical.
- Broker Type: Kafka excels at high-throughput, partitioned logs; RabbitMQ is great for complex routing.
- Partitioning: Splitting topics into partitions allows parallel processing and load distribution.
- Replication: Ensures fault tolerance but can affect write latency.
Example:
Kafka’s partition count should be aligned with the number of consumer instances for optimal parallelism.
# Create Kafka topic with 12 partitions
kafka-topics.sh --create --topic orders --partitions 12 --replication-factor 3 --bootstrap-server localhost:9092
Throughput Optimization Techniques
a) Batch Processing
Processing events in batches reduces overhead per message.
Example:
Kafka consumers can be configured to fetch batches of messages before processing.
// Kafka consumer poll with batch
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
process(record);
}
b) Compression
Compressing messages reduces network bandwidth and storage.
Example:
Kafka supports compression codecs like gzip, snappy, and lz4.
compression.type=lz4
c) Consumer Parallelism
Increasing the number of consumers or threads can improve throughput but requires careful partition management.
d) Backpressure Handling
Implement mechanisms to prevent consumers from being overwhelmed, such as rate limiting or dynamic scaling.
Monitoring and Metrics
Track key metrics to identify bottlenecks:
- Queue length and lag
- Consumer processing time
- Broker CPU and memory usage
- Network throughput
Example:
Using Kafka’s kafka-consumer-groups.sh to monitor consumer lag:
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group order-service --describe
Real-World Example: Optimizing an Order Processing Pipeline
Scenario: An e-commerce platform uses Kafka to process order events. Initially, the system experiences high latency and consumer lag during peak hours.
Steps Taken:
- Increased Kafka topic partitions from 6 to 24 to allow more consumer parallelism.
- Enabled LZ4 compression to reduce network load.
- Tuned consumer batch size and poll interval for efficient processing.
- Configured consumers with manual commit and adjusted
max.poll.recordsto 500. - Implemented monitoring dashboards to track lag and throughput.
Outcome:
- Throughput increased by 3x.
- Consumer lag reduced by 80%.
- System scaled smoothly during traffic spikes.
Summary Mind Map
Key Takeaways
- Tune queue buffer sizes and acknowledgement modes to balance throughput and reliability.
- Select brokers and configure partitions to maximize parallelism.
- Use batch processing and compression to optimize network and processing efficiency.
- Monitor system metrics continuously to detect and resolve bottlenecks.
- Real-world tuning is iterative and requires close collaboration between developers and operations.
By applying these performance tuning strategies, enterprise event-driven systems can achieve high throughput, low latency, and robust scalability.
5. Domain-Driven Design (DDD) in Enterprise Architecture
5.1 Core Concepts of Domain-Driven Design (DDD)
Domain-Driven Design (DDD) is a software design approach focused on modeling software to match a complex domain’s business logic and rules. It emphasizes collaboration between technical teams and domain experts to create a shared understanding and a rich domain model that drives the software architecture.
Why Domain-Driven Design?
- Aligns software design closely with business needs.
- Helps manage complexity by breaking down large domains into smaller, understandable parts.
- Encourages continuous collaboration between developers and domain experts.
Key Concepts of DDD:
Mind Map: Core Concepts of Domain-Driven Design
Domain
The domain is the sphere of knowledge and activity around which the application logic revolves. It represents the business problem space.
- Core Domain: The most critical part of the business where competitive advantage lies.
- Subdomains: Divisions of the domain, each with specific responsibilities.
- Supporting Subdomain: Supports the core domain but is not central.
- Generic Subdomain: Generic problems that can be solved with off-the-shelf solutions.
Example: In an e-commerce platform:
- Core Domain: Order Management
- Supporting Subdomain: Customer Support
- Generic Subdomain: Payment Processing
Ubiquitous Language
A common language shared by developers and domain experts to ensure clear communication.
Example: Instead of using technical terms like “transaction” or “process”, the team agrees to use “Order Placement” and “Order Fulfillment” to describe business processes.
Bounded Context
A boundary within which a particular model is defined and applicable. Different contexts can have different models even if they use the same terms.
Mind Map: Bounded Context
Example: In the same e-commerce system:
- The Inventory context manages stock levels.
- The Order context manages order lifecycle.
Both contexts might use the term “Product” but with different attributes and behaviors.
Entities
Objects that have a distinct identity that runs through time and different states.
Example:
An Order entity has an order ID that uniquely identifies it, regardless of changes to its status or contents.
public class Order {
private final String orderId; // Identity
private List<OrderItem> items;
private OrderStatus status;
// Constructor, getters, business methods
}
Value Objects
Objects that describe some characteristics or attributes but have no conceptual identity.
Example:
An Address value object:
public class Address {
private final String street;
private final String city;
private final String zipCode;
// Equals and hashCode based on all fields
}
Value objects are immutable and interchangeable if their attributes are the same.
Aggregates
A cluster of domain objects that can be treated as a single unit. An aggregate has a root entity (Aggregate Root) that controls access to the aggregate.
Example:
An Order aggregate root controls OrderItem entities:
public class Order {
private final String orderId;
private List<OrderItem> items;
public void addItem(Product product, int quantity) {
// business logic
}
}
Clients interact only with the aggregate root to ensure consistency.
Repositories
Mechanisms for encapsulating storage, retrieval, and search behavior which emulate a collection of aggregates.
Example:
public interface OrderRepository {
Order findById(String orderId);
void save(Order order);
}
Services
Operations or domain logic that don’t naturally fit within an entity or value object.
Example:
A PaymentService that handles payment processing outside of the Order aggregate.
Domain Events
Events that signify something important happened in the domain.
Example:
OrderPlaced event published when an order is successfully placed.
public class OrderPlaced {
private final String orderId;
private final LocalDateTime timestamp;
// Constructor, getters
}
Factories
Factories are responsible for creating complex aggregates or entities.
Example:
An OrderFactory that creates a new order with default settings and validations.
Summary Example: Modeling a Simple Order Domain
Mind Map: Simple Order Domain Model
This model helps developers and domain experts collaborate effectively and ensures the software reflects the true business domain.
By mastering these core concepts, senior engineers and technical leads can design backend systems that are maintainable, scalable, and aligned with business goals, setting a solid foundation for advanced DDD practices.
5.2 Strategic Design: Context Mapping and Aggregates
Strategic Design is a cornerstone of Domain-Driven Design (DDD) that helps teams manage complexity by defining clear boundaries and relationships within the domain. Two critical concepts in strategic design are Context Mapping and Aggregates. This section dives deep into these concepts, illustrating best practices with examples and mind maps to help senior software engineers and technical leads apply them effectively in enterprise systems.
What is Context Mapping?
Context Mapping is the practice of defining and visualizing the relationships and boundaries between different Bounded Contexts within a large domain. A Bounded Context encapsulates a specific model and its logic, ensuring that terms and rules are consistent within that boundary but may differ across others.
Why Context Mapping Matters
- Clarifies team responsibilities and ownership.
- Prevents model confusion and ambiguity.
- Enables integration strategies between contexts.
Common Context Relationships
- Shared Kernel: Shared subset of the domain model between contexts.
- Customer-Supplier: One context (supplier) provides services or data to another (customer).
- Conformist: One context must conform to the model of another without negotiation.
- Anti-Corruption Layer (ACL): A protective layer to translate between models.
- Open Host Service: A published interface for other contexts.
Mind Map: Context Mapping Overview
Example: E-Commerce Platform Context Map
Imagine an enterprise e-commerce system with these bounded contexts:
- Ordering Context: Handles order placement and processing.
- Inventory Context: Manages stock levels and warehouse data.
- Billing Context: Responsible for payment processing and invoicing.
- Customer Context: Manages customer profiles and preferences.
Context Relationships:
- Ordering (Customer) depends on Inventory (Supplier) for stock availability.
- Billing (Customer) depends on Ordering (Supplier) for order details.
- Ordering and Billing share a Shared Kernel for common order identifiers.
- Customer context uses an Anti-Corruption Layer to integrate with legacy CRM systems.
What are Aggregates?
An Aggregate is a cluster of domain objects that can be treated as a single unit for data changes. It enforces consistency boundaries and transactional integrity.
Key Characteristics of Aggregates
- Has a single Aggregate Root that acts as the entry point.
- Internal entities and value objects are only accessible through the root.
- Ensures invariants and business rules within the aggregate.
- Defines transactional boundaries.
Why Aggregates are Important
- Simplifies complex domain models.
- Controls data consistency and concurrency.
- Facilitates clear API design for domain operations.
Mind Map: Aggregate Structure
Example: Order Aggregate in Ordering Context
Consider the Order Aggregate in the Ordering Context:
- Aggregate Root:
Order - Entities:
OrderLineItem(each representing a product and quantity) - Value Objects:
Money(price),Address(shipping info)
Business Rules enforced by Aggregate Root:
- Total order amount must be correctly calculated.
- OrderLineItems cannot have zero or negative quantity.
- Order status transitions must follow a defined lifecycle.
public class Order {
private List<OrderLineItem> _lineItems = new List<OrderLineItem>();
public Guid Id { get; private set; }
public OrderStatus Status { get; private set; }
public void AddLineItem(Product product, int quantity, Money price) {
if (quantity <= 0) throw new ArgumentException("Quantity must be positive");
var lineItem = new OrderLineItem(product.Id, quantity, price);
_lineItems.Add(lineItem);
RecalculateTotal();
}
private void RecalculateTotal() {
// Calculate total order amount
}
public void ChangeStatus(OrderStatus newStatus) {
// Validate status transition
Status = newStatus;
}
}
public class OrderLineItem {
public Guid ProductId { get; private set; }
public int Quantity { get; private set; }
public Money Price { get; private set; }
public OrderLineItem(Guid productId, int quantity, Money price) {
ProductId = productId;
Quantity = quantity;
Price = price;
}
}
Best Practices for Designing Aggregates
- Keep aggregates small to reduce locking and improve performance.
- Model transactional consistency within a single aggregate only.
- Use domain events to communicate changes across aggregates.
- Avoid direct references between aggregates; use IDs instead.
Mind Map: Best Practices for Aggregates
Summary
Strategic design with Context Mapping and Aggregates helps senior engineers and technical leads manage complexity in enterprise systems by establishing clear boundaries and transactional integrity. Context maps visualize how different parts of the system interact and integrate, while aggregates encapsulate domain logic and consistency within those boundaries.
By applying these concepts with practical examples and mind maps, teams can build maintainable, scalable, and high-performance backend systems aligned with business goals.
5.3 Integrating Domain-Driven Design (DDD) with Architecture Patterns
Integrating Domain-Driven Design (DDD) with established architecture patterns is a powerful approach to building maintainable, scalable, and business-aligned enterprise systems. This section explores how DDD concepts can be harmoniously combined with common architecture patterns such as Layered Architecture, Microservices, and Event-Driven Architecture, supported by practical examples and mind maps.
Understanding the Integration
DDD emphasizes modeling software around the core business domain, focusing on the ubiquitous language, bounded contexts, and aggregates. Architecture patterns provide structural blueprints for organizing code and components. Integrating these ensures that the system’s technical structure reflects the business domain boundaries and behaviors.
Mind Map: Core Integration Concepts
Layered Architecture + DDD
How to Integrate:
- Presentation Layer: Handles UI or API endpoints, translating user interactions into domain commands.
- Application Layer: Coordinates tasks, delegates to domain layer, handles transactions.
- Domain Layer: Contains domain models (entities, value objects, aggregates) and domain services.
- Infrastructure Layer: Deals with persistence, messaging, external services.
Example:
Imagine an order management system.
- The Domain Layer defines an
Orderaggregate with business rules. - The Application Layer exposes services like
PlaceOrderServicethat orchestrate domain operations. - The Infrastructure Layer implements repositories for persisting orders.
This separation ensures domain logic is isolated and reusable.
Mind Map: Layered Architecture with DDD
Microservices Architecture + DDD
How to Integrate:
- Each Microservice corresponds to a Bounded Context from DDD.
- Microservices encapsulate domain models and business logic relevant to their bounded context.
- Communication between microservices happens via APIs or asynchronous messaging.
Example:
In an e-commerce platform:
- The Inventory Service microservice manages stock levels and corresponds to the Inventory bounded context.
- The Order Service microservice manages orders and payments.
This clear separation reduces coupling and allows independent scaling.
Mind Map: Microservices and Bounded Contexts
Event-Driven Architecture + DDD
How to Integrate:
- Use domain events to represent significant state changes within aggregates.
- Publish domain events asynchronously to other bounded contexts or services.
- Event sourcing can be applied to persist state changes as a sequence of events.
Example:
In an order processing system:
- When an order is placed, the
OrderPlaceddomain event is published. - The Inventory service listens for
OrderPlacedevents to update stock. - The Billing service listens to charge the customer.
This decouples services and improves responsiveness.
Mind Map: Event-Driven DDD Integration
Practical Example: Combining DDD with Microservices and Event-Driven Architecture
Scenario: Building a high-performance e-commerce backend.
- Bounded Contexts: Order, Inventory, Payment.
- Each bounded context is implemented as a microservice.
- When an order is placed, the Order Service emits an
OrderPlacedevent. - Inventory Service subscribes to this event and updates stock asynchronously.
- Payment Service listens for the event to process payment.
Code Snippet (simplified):
// Domain Event in Order Service
public class OrderPlaced {
private final String orderId;
private final List<OrderItem> items;
public OrderPlaced(String orderId, List<OrderItem> items) {
this.orderId = orderId;
this.items = items;
}
// getters
}
// Publishing event after placing order
orderRepository.save(order);
eventBus.publish(new OrderPlaced(order.getId(), order.getItems()));
Benefits:
- Clear domain boundaries.
- Services independently deployable and scalable.
- Asynchronous communication reduces coupling and latency.
Best Practices Summary
- Align bounded contexts with architectural boundaries (layers, services).
- Keep domain logic centralized within the domain layer or microservice.
- Use domain events to communicate between bounded contexts asynchronously.
- Avoid anemic domain models by embedding business rules within aggregates.
- Use context maps to document relationships and integration points.
By integrating DDD with architecture patterns, senior engineers and technical leads can build enterprise systems that are both technically robust and deeply aligned with business needs, ensuring maintainability and high performance over time.
5.4 Example: Modeling Complex Business Domains with DDD
Domain-Driven Design (DDD) is a powerful approach to tackling complexity in enterprise software by aligning the software model closely with the business domain. In this section, we will walk through an example of modeling a complex business domain using DDD principles, illustrating how to break down the domain into bounded contexts, define aggregates, entities, value objects, and domain events.
Business Scenario: Online Marketplace
Imagine we are building an online marketplace platform where multiple vendors sell products to customers. The platform handles product catalogs, orders, payments, and reviews. This domain is complex because it involves multiple subdomains with distinct responsibilities and business rules.
Step 1: Identify Bounded Contexts
Bounded contexts help us partition the domain into manageable parts where a particular model applies consistently.
- Catalog Context: Manages product information, categories, and inventory.
- Ordering Context: Handles order placement, payment processing, and order status.
- Review Context: Manages customer and vendor reviews.
- Shipping Context: Manages shipment and tracking details.
Each bounded context has its own ubiquitous language and models.
Step 2: Define Aggregates and Entities
Within each bounded context, we identify aggregates — clusters of domain objects that are treated as a single unit for data changes.
Catalog Context Aggregates
- Product Aggregate
- Entity: Product (with unique ProductId)
- Value Objects: Price, Dimensions
- Related Entities: Category
Ordering Context Aggregates
- Order Aggregate
- Entity: Order (OrderId)
- Entities: OrderItem
- Value Objects: ShippingAddress, PaymentDetails
Review Context Aggregates
- Review Aggregate
- Entity: Review (ReviewId)
- Value Objects: Rating, Comment
Step 3: Example: Product Aggregate Implementation (Simplified)
// Value Object: Price
public class Price {
public decimal Amount { get; private set; }
public string Currency { get; private set; }
public Price(decimal amount, string currency) {
if(amount < 0) throw new ArgumentException("Price cannot be negative");
Amount = amount;
Currency = currency;
}
}
// Entity: Product
public class Product {
public Guid ProductId { get; private set; }
public string Name { get; private set; }
public Price ProductPrice { get; private set; }
public string Description { get; private set; }
public Product(Guid productId, string name, Price price, string description) {
ProductId = productId;
Name = name;
ProductPrice = price;
Description = description;
}
public void UpdatePrice(Price newPrice) {
ProductPrice = newPrice;
}
}
This example shows how the Product entity encapsulates its state and behavior, and uses a value object for price to ensure immutability and validation.
Step 4: Domain Events Example
Domain events capture things that happen in the domain that other parts of the system might be interested in.
public class OrderPlaced : IDomainEvent {
public Guid OrderId { get; }
public DateTime OccurredOn { get; } = DateTime.UtcNow;
public OrderPlaced(Guid orderId) {
OrderId = orderId;
}
}
When an order is placed in the Ordering context, this event can trigger inventory updates in the Catalog context or shipment scheduling in the Shipping context.
Step 5: Context Mapping and Integration
To integrate bounded contexts, we define relationships such as:
- Ordering depends on Catalog to validate product availability.
- Shipping depends on Ordering for shipment details.
- Review is a separate context with its own model.
Integration can be done via REST APIs, messaging, or shared kernel patterns depending on coupling requirements.
Summary of Best Practices Demonstrated
- Bounded Contexts: Keep models focused and consistent.
- Aggregates: Define transactional boundaries and encapsulate invariants.
- Entities and Value Objects: Differentiate mutable entities from immutable value objects.
- Domain Events: Decouple subsystems and enable asynchronous workflows.
- Context Mapping: Clarify relationships and integration approaches.
By applying these DDD modeling techniques, technical leads and senior engineers can build maintainable, scalable, and expressive enterprise systems that reflect complex business realities clearly and effectively.
5.5 Best Practices for Collaboration Between Domain Experts and Engineers
Effective collaboration between domain experts and engineers is critical to the success of Domain-Driven Design (DDD) and enterprise software projects. This section explores best practices that foster communication, shared understanding, and productive teamwork, illustrated with practical examples and mind maps.
Establish a Ubiquitous Language
A ubiquitous language is a shared vocabulary developed collaboratively by domain experts and engineers. It ensures that everyone uses the same terms with the same meaning, reducing misunderstandings.
- Practice: Hold regular workshops where domain experts explain business concepts and engineers translate them into technical terms.
- Example: In a healthcare application, instead of ambiguous terms like “patient record,” the team agrees on precise terms like “Electronic Health Record (EHR)” and “Encounter.”
Use Domain Storytelling
Domain storytelling is a collaborative technique where domain experts narrate business processes while engineers map them visually. This helps uncover hidden requirements and clarifies workflows.
- Practice: Conduct domain storytelling sessions with whiteboards or digital tools.
- Example: For an order fulfillment system, domain experts describe the order lifecycle while engineers diagram actors, commands, and events.
Create Context Maps Together
Context maps visualize bounded contexts and their relationships. Jointly creating these maps helps align domain boundaries and integration points.
- Practice: Collaborate on context mapping sessions early and revisit regularly.
- Example: In a banking system, teams map contexts like “Account Management,” “Loan Processing,” and “Fraud Detection,” defining integration styles (e.g., shared kernel, anti-corruption layer).
Encourage Pairing and Cross-Functional Teams
Pairing domain experts with engineers or forming cross-functional teams promotes continuous knowledge exchange and faster feedback.
- Practice: Schedule pairing sessions during design phases or critical feature development.
- Example: A domain expert pairs with a backend engineer to design the payment processing aggregate, ensuring domain rules are correctly implemented.
Maintain Living Documentation
Keep documentation up to date with evolving domain knowledge and codebase changes. Use collaborative tools accessible to both domain experts and engineers.
- Practice: Use wikis, shared repositories, or tools like Confluence with version control.
- Example: Document aggregate roots, domain events, and business rules with examples and link to code implementations.
Foster a Culture of Open Communication and Respect
Encourage an environment where domain experts and engineers feel comfortable asking questions and challenging assumptions.
- Practice: Promote psychological safety, active listening, and empathy.
- Example: During retrospectives, both sides share what worked and what could improve in collaboration.
Summary Example: Collaborative Workflow for a New Feature
- Kickoff Workshop: Domain experts explain the business need using domain storytelling.
- Ubiquitous Language Session: Team agrees on terminology.
- Context Mapping: Identify bounded contexts involved.
- Pairing: Domain expert pairs with engineer to design aggregates and domain events.
- Documentation: Update living docs with models and rules.
- Review & Feedback: Continuous communication during implementation.
By integrating these best practices, technical leads and senior engineers can bridge the gap between business knowledge and technical implementation, resulting in robust, maintainable, and aligned enterprise software systems.
6. API-First Design and Backend Engineering
6.1 API-First Approach: Benefits and Principles
The API-First approach is a design methodology that prioritizes the design and development of APIs before implementing the underlying backend services. This approach ensures that APIs are treated as first-class products, enabling better collaboration, scalability, and maintainability in enterprise backend engineering.
Benefits of API-First Approach
- Improved Collaboration: Enables frontend, backend, and third-party teams to work in parallel by agreeing on API contracts early.
- Consistency and Standardization: Promotes uniform API design across services, improving developer experience and reducing integration errors.
- Faster Time-to-Market: Early API design allows mock implementations and parallel development, accelerating delivery.
- Better Documentation: API contracts serve as living documentation, reducing ambiguity.
- Scalability and Flexibility: Decouples frontend and backend, allowing independent scaling and technology choices.
- Easier Testing and Validation: APIs can be tested independently with mock servers before backend implementation.
Core Principles of API-First Design
- Design Before Code: Define API specifications (e.g., OpenAPI/Swagger) before writing backend logic.
- Consumer-Centric: Design APIs with the end consumer in mind, focusing on usability and clarity.
- Contract-Driven Development: Use API contracts as the source of truth for development and testing.
- Versioning and Backward Compatibility: Plan for API evolution without breaking existing clients.
- Security by Design: Incorporate authentication, authorization, and data validation early.
- Reusability and Modularity: Design APIs to be reusable across different clients and services.
Mind Map: Benefits of API-First Approach
Mind Map: Principles of API-First Design
Example: Defining an API Contract with OpenAPI
openapi: 3.0.3
info:
title: Order Management API
version: 1.0.0
paths:
/orders:
get:
summary: Retrieve a list of orders
responses:
'200':
description: A JSON array of order objects
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Order'
/orders/{orderId}:
get:
summary: Get a specific order by ID
parameters:
- in: path
name: orderId
required: true
schema:
type: string
responses:
'200':
description: Order details
content:
application/json:
schema:
$ref: '#/components/schemas/Order'
components:
schemas:
Order:
type: object
properties:
id:
type: string
customerId:
type: string
status:
type: string
enum: [pending, processing, shipped, delivered]
totalAmount:
type: number
format: float
required:
- id
- customerId
- status
- totalAmount
This contract can be shared with frontend teams and used to generate mock servers, client SDKs, and automated tests before backend implementation.
Example: Mock Server Usage
Using tools like Prism or Swagger UI, teams can spin up a mock server based on the OpenAPI spec above, enabling frontend developers to begin integration early.
Best Practices Embedded in API-First Approach
- Use Standard Specification Formats: OpenAPI or AsyncAPI for event-driven APIs.
- Automate Documentation Generation: Keep docs in sync with API contracts.
- Incorporate API Gateways Early: For routing, security, and rate limiting.
- Implement Continuous Contract Testing: To catch breaking changes early.
- Design for Idempotency and Error Handling: Clear status codes and error messages.
Summary
The API-First approach empowers enterprise backend engineering by fostering collaboration, ensuring consistency, and accelerating development cycles. By designing APIs as first-class products with clear contracts, teams can build scalable, maintainable, and high-performance backend systems that meet evolving business needs.
6.2 Designing RESTful and GraphQL APIs for Enterprise Backends
Designing APIs for enterprise backends requires a balance between scalability, maintainability, security, and performance. RESTful and GraphQL APIs are two dominant paradigms that serve different needs but can also complement each other in complex enterprise environments.
Understanding RESTful APIs
REST (Representational State Transfer) is an architectural style that uses standard HTTP methods and status codes to create scalable and stateless APIs.
Key principles:
- Resources are identified by URIs
- Use HTTP methods (GET, POST, PUT, DELETE, PATCH)
- Stateless communication
- Use of standard HTTP status codes
- Support for multiple representations (JSON, XML, etc.)
Mind Map: RESTful API Design Principles
Example: RESTful API Endpoint Design for a Customer Management System
| HTTP Method | Endpoint | Description |
|---|---|---|
| GET | /api/customers | Retrieve list of customers |
| GET | /api/customers/{id} | Retrieve a single customer |
| POST | /api/customers | Create a new customer |
| PUT | /api/customers/{id} | Update an existing customer |
| DELETE | /api/customers/{id} | Delete a customer |
Example Request:
GET /api/customers/123 HTTP/1.1
Host: example.com
Accept: application/json
Example Response:
{
"id": 123,
"name": "Jane Doe",
"email": "[email protected]",
"status": "active"
}
Understanding GraphQL APIs
GraphQL is a query language and runtime for APIs that allows clients to request exactly the data they need, reducing over-fetching and under-fetching.
Key features:
- Single endpoint for all queries and mutations
- Clients specify the shape of the response
- Strongly typed schema
- Real-time data with subscriptions
Mind Map: GraphQL API Design Concepts
Example: GraphQL Schema for Customer Management
type Customer {
id: ID!
name: String!
email: String!
status: String!
}
type Query {
customers(status: String, limit: Int): [Customer]
customer(id: ID!): Customer
}
type Mutation {
createCustomer(name: String!, email: String!): Customer
updateCustomer(id: ID!, name: String, email: String, status: String): Customer
deleteCustomer(id: ID!): Boolean
}
Example Query:
query {
customer(id: "123") {
id
name
email
}
}
Example Response:
{
"data": {
"customer": {
"id": "123",
"name": "Jane Doe",
"email": "[email protected]"
}
}
}
Best Practices for Designing RESTful and GraphQL APIs in Enterprise Backends
RESTful API Best Practices
- Consistent Resource Naming: Use plural nouns (e.g., /customers) and hierarchical URIs.
- Use HTTP Status Codes Properly: Communicate success and error states clearly.
- Support Filtering, Sorting, and Pagination: To handle large datasets efficiently.
- Version Your API: Via URI (e.g., /v1/customers) or headers to maintain backward compatibility.
- Statelessness: Avoid server-side sessions to improve scalability.
- Use HATEOAS (Hypermedia as the Engine of Application State): To provide discoverability.
GraphQL API Best Practices
- Design a Clear and Strongly Typed Schema: Reflect business domain accurately.
- Limit Query Complexity: To prevent expensive queries affecting performance.
- Use Batching and Caching: Tools like DataLoader to optimize resolver calls.
- Implement Authorization at Resolver Level: Fine-grained access control.
- Provide Descriptive Error Messages: For easier debugging.
- Monitor Query Performance: Use tracing and logging.
When to Use REST vs GraphQL
| Aspect | REST | GraphQL |
|---|---|---|
| Endpoint | Multiple endpoints per resource | Single endpoint |
| Data Fetching | Fixed data per endpoint | Client specifies data shape |
| Over-fetching | Common issue | Avoided |
| Under-fetching | Common issue | Avoided |
| Caching | Easier with HTTP caching | More complex, requires custom solutions |
| Learning Curve | Lower | Higher |
| Tooling & Ecosystem | Mature and widely supported | Growing rapidly |
Integrated Example: Combining REST and GraphQL
In large enterprise systems, it is common to use REST for simple, stable endpoints and GraphQL for complex, client-driven data requirements.
Example:
- Use REST for authentication, file uploads, and simple CRUD operations.
- Use GraphQL for complex queries involving multiple related entities.
Summary
Designing APIs for enterprise backends requires understanding the strengths and trade-offs of RESTful and GraphQL approaches. By following best practices and leveraging examples like the customer management system, technical leads can architect APIs that are scalable, maintainable, and performant.
6.3 Example: Building a High-Performance API Gateway
An API Gateway acts as a single entry point for client requests, routing them to appropriate backend services, handling cross-cutting concerns such as authentication, rate limiting, caching, and logging. Building a high-performance API Gateway is critical in enterprise systems to ensure scalability, reliability, and maintainability.
Mind Map: Key Responsibilities of an API Gateway
Step 1: Defining the Requirements
- Support multiple backend microservices
- Handle high throughput with low latency
- Provide authentication and authorization
- Enable rate limiting per client
- Support caching for frequently requested data
- Provide detailed logging and metrics
Step 2: Choosing the Technology Stack
- Language: Node.js (for asynchronous I/O) or Go (for performance)
- Framework: Express.js or Fastify (Node.js), or custom HTTP server in Go
- API Gateway Tools: Kong, Ambassador, or custom-built
- Caching: Redis or in-memory cache
- Authentication: JWT tokens with OAuth2 flow
Step 3: Example Implementation in Node.js with Express and Redis Caching
const express = require('express');
const jwt = require('jsonwebtoken');
const redis = require('redis');
const axios = require('axios');
const app = express();
const redisClient = redis.createClient();
// Middleware: Authentication
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, process.env.JWT_SECRET, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
// Middleware: Rate Limiting (simple example)
const rateLimitMap = new Map();
const RATE_LIMIT = 100; // requests
const WINDOW_SIZE = 60 * 1000; // 1 minute
function rateLimiter(req, res, next) {
const userIP = req.ip;
const currentTime = Date.now();
if (!rateLimitMap.has(userIP)) {
rateLimitMap.set(userIP, { count: 1, startTime: currentTime });
return next();
}
const userData = rateLimitMap.get(userIP);
if (currentTime - userData.startTime < WINDOW_SIZE) {
if (userData.count >= RATE_LIMIT) {
return res.status(429).send('Too many requests');
} else {
userData.count++;
return next();
}
} else {
rateLimitMap.set(userIP, { count: 1, startTime: currentTime });
return next();
}
}
// Middleware: Caching
async function cache(req, res, next) {
const key = req.originalUrl;
redisClient.get(key, (err, data) => {
if (err) throw err;
if (data != null) {
res.send(JSON.parse(data));
} else {
res.sendResponse = res.send;
res.send = (body) => {
redisClient.setex(key, 60, JSON.stringify(body)); // cache for 60 seconds
res.sendResponse(body);
};
next();
}
});
}
// Route: Proxy to backend service
app.get('/api/users/:id', authenticateToken, rateLimiter, cache, async (req, res) => {
try {
const userId = req.params.id;
const response = await axios.get(`http://users-service/api/users/${userId}`);
res.json(response.data);
} catch (error) {
res.status(500).send('Backend service error');
}
});
app.listen(3000, () => {
console.log('API Gateway running on port 3000');
});
Explanation & Best Practices:
- Authentication Middleware: Verifies JWT tokens to secure API access.
- Rate Limiting: Protects backend services from abuse; here a simple in-memory approach is shown, but Redis or dedicated rate limiting services are recommended for distributed systems.
- Caching: Uses Redis to cache responses and reduce backend load, improving response time.
- Request Proxying: The gateway forwards requests to backend microservices transparently.
Mind Map: Performance Optimization Techniques for API Gateway
Additional Example: Using NGINX as a High-Performance API Gateway
http {
upstream users_service {
server users-service-1:8080;
server users-service-2:8080;
}
server {
listen 80;
location /api/users/ {
proxy_pass http://users_service;
proxy_set_header Authorization $http_authorization;
proxy_cache my_cache;
proxy_cache_valid 200 60s;
limit_req zone=one burst=5 nodelay;
}
}
limit_req_zone $binary_remote_addr zone=one:10m rate=10r/s;
proxy_cache_path /tmp/nginx_cache levels=1:2 keys_zone=my_cache:10m max_size=1g inactive=60m use_temp_path=off;
}
- This config enables load balancing, caching, and rate limiting at the gateway level.
Summary
Building a high-performance API Gateway involves combining routing, security, caching, rate limiting, and monitoring into a cohesive system. Leveraging asynchronous programming, in-memory or distributed caching, and robust authentication mechanisms ensures the gateway can handle enterprise-scale traffic with low latency and high reliability. Whether building custom solutions or using mature tools like Kong or NGINX, understanding these core concepts and patterns is essential for senior engineers and technical leads.
6.4 Best Practices for API Versioning, Security, and Rate Limiting
Introduction
In enterprise backend engineering, APIs serve as critical interfaces between clients and services. Ensuring APIs are versioned properly, secured effectively, and protected from abuse through rate limiting is essential for maintaining stability, security, and scalability.
This section explores best practices for API versioning, security, and rate limiting, supported by mind maps and practical examples.
API Versioning Best Practices
API versioning enables you to evolve your API without breaking existing clients. Here are key strategies:
- URI Versioning: Embed version in the URL path.
- Header Versioning: Use custom headers to specify version.
- Query Parameter Versioning: Pass version as a query parameter.
- Content Negotiation: Use Accept headers to specify version.
Mind Map: API Versioning Strategies
Example: URI Versioning in Express.js
const express = require('express');
const app = express();
// v1 endpoint
app.get('/api/v1/users', (req, res) => {
res.json({ version: 'v1', users: ['Alice', 'Bob'] });
});
// v2 endpoint with additional fields
app.get('/api/v2/users', (req, res) => {
res.json({ version: 'v2', users: [{ name: 'Alice', age: 30 }, { name: 'Bob', age: 25 }] });
});
app.listen(3000, () => console.log('API running on port 3000'));
API Security Best Practices
Securing APIs is paramount to protect sensitive data and prevent unauthorized access.
- Authentication: Verify identity (e.g., OAuth2, JWT).
- Authorization: Enforce access control (e.g., RBAC, ABAC).
- Input Validation: Prevent injection and malformed data.
- Encryption: Use HTTPS/TLS for data in transit.
- Logging and Monitoring: Detect suspicious activity.
Mind Map: API Security Layers
Example: Securing a Microservice with OAuth2 and JWT
const jwt = require('jsonwebtoken');
const express = require('express');
const app = express();
const SECRET = 'your_jwt_secret';
// Middleware to verify JWT token
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, SECRET, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
app.get('/api/v1/secure-data', authenticateToken, (req, res) => {
res.json({ message: 'This is secured data', user: req.user });
});
app.listen(3000, () => console.log('Secure API running on port 3000'));
API Rate Limiting Best Practices
Rate limiting protects APIs from abuse and ensures fair usage.
- Fixed Window: Limits requests per fixed time window.
- Sliding Log: Tracks timestamps of requests.
- Token Bucket: Allows bursts up to a limit.
- Leaky Bucket: Smooths out bursts.
Mind Map: Rate Limiting Algorithms
Example: Implementing Rate Limiting with Express and express-rate-limit
const rateLimit = require('express-rate-limit');
const express = require('express');
const app = express();
const limiter = rateLimit({
windowMs: 15 * 60 * 1000, // 15 minutes
max: 100, // limit each IP to 100 requests per windowMs
message: 'Too many requests from this IP, please try again later.'
});
// Apply to all requests
app.use(limiter);
app.get('/api/v1/resource', (req, res) => {
res.json({ data: 'Some data' });
});
app.listen(3000, () => console.log('API with rate limiting running on port 3000'));
Summary Mind Map
Conclusion
Applying robust API versioning, security, and rate limiting practices ensures your enterprise backend remains reliable, secure, and scalable. Using clear versioning strategies avoids breaking changes, security layers protect sensitive data, and rate limiting safeguards against abuse.
These best practices, combined with real-world examples, empower senior engineers and technical leads to design and maintain high-performance APIs that meet enterprise demands.
6.5 Performance Optimization: Caching, Pagination, and Throttling
Optimizing backend performance is crucial for enterprise systems that handle large volumes of data and high traffic. In this section, we explore three key techniques: caching, pagination, and throttling. Each technique helps improve responsiveness, reduce load, and maintain system stability.
Caching
Caching stores frequently accessed data temporarily to reduce latency and database load.
Types of Caching
- In-Memory Caching: Fastest, stores data in RAM (e.g., Redis, Memcached).
- Distributed Caching: Shared cache across multiple servers.
- HTTP Caching: Browser or CDN caches responses.
Best Practices
- Cache data that is expensive to compute or fetch.
- Set appropriate expiration (TTL) to avoid stale data.
- Use cache invalidation strategies (write-through, write-back, cache-aside).
- Monitor cache hit/miss ratios.
Example: Implementing Cache-Aside Pattern with Redis (Node.js)
const redis = require('redis');
const client = redis.createClient();
async function getUser(userId) {
const cacheKey = `user:${userId}`;
const cachedUser = await client.get(cacheKey);
if (cachedUser) {
console.log('Cache hit');
return JSON.parse(cachedUser);
}
console.log('Cache miss');
const userFromDb = await database.getUserById(userId); // Assume this is a DB call
await client.set(cacheKey, JSON.stringify(userFromDb), 'EX', 3600); // Cache for 1 hour
return userFromDb;
}
Pagination
Pagination limits the amount of data returned in a single request, improving response time and reducing memory usage.
Pagination Strategies
- Offset-based Pagination: Uses offset and limit parameters.
- Cursor-based Pagination: Uses a cursor (e.g., unique ID) for better performance on large datasets.
Best Practices
- Prefer cursor-based pagination for large or frequently changing datasets.
- Provide metadata (total count, next cursor) in API responses.
- Avoid deep offset pagination to prevent performance degradation.
Example: Cursor-Based Pagination in SQL
SELECT * FROM orders
WHERE order_id > :last_seen_id
ORDER BY order_id ASC
LIMIT 20;
Example: REST API Response with Pagination Metadata
{
"data": [ /* array of items */ ],
"pagination": {
"nextCursor": "abc123",
"limit": 20
}
}
Throttling
Throttling controls the rate of incoming requests to prevent system overload and ensure fair resource usage.
Types of Rate Limiting
- Fixed Window: Limits requests per fixed time window.
- Sliding Log: Tracks timestamps of requests for a sliding window.
- Token Bucket: Allows bursts but limits average rate.
Best Practices
- Implement throttling at API gateway or load balancer.
- Return meaningful HTTP status codes (e.g., 429 Too Many Requests).
- Provide clients with retry-after headers.
- Differentiate limits by user roles or endpoints.
Example: Express.js Middleware for Fixed Window Rate Limiting
const rateLimit = require('express-rate-limit');
const limiter = rateLimit({
windowMs: 60 * 1000, // 1 minute
max: 100, // limit each IP to 100 requests per windowMs
message: 'Too many requests, please try again later.',
headers: true
});
app.use('/api/', limiter);
Mind Maps
Caching Mind Map
Pagination Mind Map
Throttling Mind Map
Summary
Caching, pagination, and throttling are foundational techniques to optimize backend performance in enterprise applications. By caching frequently accessed data, limiting data payloads with pagination, and controlling request rates through throttling, systems can achieve better scalability, responsiveness, and reliability.
Implementing these techniques thoughtfully with proper monitoring and tuning ensures a high-performance backend that meets enterprise demands.
7. Data Management Patterns for High Performance
7.1 Choosing the Right Database: SQL vs NoSQL in Enterprise Systems
Selecting the appropriate database technology is a critical decision in enterprise backend engineering. It directly impacts scalability, performance, maintainability, and the ability to meet business requirements. This section explores the fundamental differences between SQL and NoSQL databases, their strengths and weaknesses, and practical guidelines to choose the right fit for your enterprise system.
Understanding SQL and NoSQL Databases
-
SQL Databases (Relational Databases): Use structured schemas, tables with rows and columns, and support ACID (Atomicity, Consistency, Isolation, Durability) transactions. Examples include PostgreSQL, MySQL, Oracle DB, and Microsoft SQL Server.
-
NoSQL Databases (Non-Relational Databases): Designed for flexible schemas, horizontal scalability, and high throughput. They come in various types: document stores, key-value stores, wide-column stores, and graph databases. Examples include MongoDB, Cassandra, Redis, and Neo4j.
Mind Map: Key Characteristics of SQL vs NoSQL
When to Choose SQL Databases
-
Strong Consistency and ACID Compliance Required: Financial systems, inventory management, and applications where transactional integrity is paramount.
-
Complex Queries and Relationships: When your data model involves complex joins, foreign keys, and relational integrity.
-
Mature Tooling and Ecosystem: Enterprise-grade reporting, analytics, and tooling support.
-
Fixed Schema and Data Structure: When the data model is well-defined and unlikely to change frequently.
Example:
A banking application that processes transactions must ensure that debits and credits are consistent and atomic. Using PostgreSQL ensures ACID compliance, preventing anomalies like double spending.
When to Choose NoSQL Databases
-
High Scalability and Availability: Systems that require horizontal scaling across distributed nodes, such as social media platforms or IoT data ingestion.
-
Flexible or Evolving Schema: Rapidly changing data models or semi-structured data like JSON documents.
-
High Throughput and Low Latency Needs: Real-time analytics, caching layers, or session stores.
-
Specialized Data Models: Graph databases for relationship-heavy data or wide-column stores for time-series data.
Example:
An e-commerce platform capturing user clickstreams and product catalogs with varying attributes benefits from MongoDB’s flexible document model and horizontal scaling.
Mind Map: Decision Factors for Database Selection
Hybrid Approaches: Polyglot Persistence
Modern enterprise systems often combine SQL and NoSQL databases to leverage their respective strengths. This approach is called polyglot persistence.
Example:
- Use PostgreSQL for transactional data (orders, payments).
- Use Cassandra or MongoDB for storing user activity logs or product catalogs.
- Use Redis as an in-memory cache for session management.
This strategy allows optimizing each component for its workload and performance requirements.
Practical Example: Choosing a Database for an Enterprise Order Management System
| Requirement | Recommended Database | Reasoning |
|---|---|---|
| Transactional integrity | SQL (PostgreSQL) | Ensures ACID compliance for order processing and payments |
| Product catalog with variable data | NoSQL (MongoDB) | Flexible schema supports diverse product attributes |
| User session caching | NoSQL (Redis) | In-memory key-value store for ultra-low latency |
Best Practices for Database Selection
-
Analyze Data Access Patterns: Understand read/write ratios, query complexity, and latency requirements.
-
Evaluate Consistency Needs: Choose SQL for strict consistency; NoSQL for eventual consistency where acceptable.
-
Consider Scalability Plans: Anticipate growth and select databases that scale accordingly.
-
Prototype and Benchmark: Build small proof-of-concept implementations to measure performance and operational complexity.
-
Plan for Data Migration and Integration: Ensure smooth interoperability between different database systems if using polyglot persistence.
Summary
Choosing between SQL and NoSQL databases is not a binary decision but a nuanced evaluation of business needs, data models, and system requirements. Understanding their trade-offs and leveraging hybrid architectures can empower senior engineers and technical leads to build scalable, maintainable, and high-performance enterprise backend systems.
7.2 Data Partitioning and Sharding Strategies
Data partitioning and sharding are critical techniques for scaling enterprise backend systems that handle large volumes of data and high throughput. They help distribute data across multiple storage nodes or databases, improving performance, availability, and manageability.
What is Data Partitioning?
Data partitioning is the process of dividing a large dataset into smaller, more manageable pieces called partitions. Each partition can be stored and managed separately, often on different servers or storage devices.
What is Sharding?
Sharding is a specific type of horizontal partitioning where data is split across multiple database instances (shards). Each shard holds a subset of the total data, and collectively they form the complete dataset.
Why Partition or Shard Data?
- Scalability: Distribute load across multiple servers.
- Performance: Reduce query latency by limiting the data scanned.
- Availability: Fault isolation; failure in one shard doesn’t affect others.
- Manageability: Easier backups and maintenance on smaller datasets.
Common Partitioning Strategies
Example: Range Partitioning in an Order Management System
Suppose we have an orders table with millions of records. We can partition orders by order_date:
| Partition Name | Date Range |
|---|---|
| orders_q1 | 2024-01-01 to 2024-03-31 |
| orders_q2 | 2024-04-01 to 2024-06-30 |
| orders_q3 | 2024-07-01 to 2024-09-30 |
| orders_q4 | 2024-10-01 to 2024-12-31 |
Benefits: Queries for recent orders only scan relevant partitions, improving performance.
Best Practice: Monitor partition sizes to avoid hotspots and rebalance if necessary.
Sharding Strategies
Example: Hash-Based Sharding for User Data
Imagine a social media platform with millions of users. To distribute user data evenly:
# Python example for shard selection
NUM_SHARDS = 8
def get_shard(user_id):
return hash(user_id) % NUM_SHARDS
user_id = 123456
shard = get_shard(user_id)
print(f"User {user_id} data is stored in shard {shard}")
Advantages: Even data distribution prevents hotspots.
Considerations: Range queries on user_id are inefficient because data is spread.
Best Practices for Partitioning and Sharding
- Choose the right shard key: It should evenly distribute data and align with query patterns.
- Avoid hotspots: Monitor and rebalance shards or partitions as data grows.
- Plan for re-sharding: Design systems to support adding/removing shards with minimal downtime.
- Use consistent hashing: To minimize data movement when scaling shards.
- Implement cross-shard queries carefully: Use aggregation services or middleware to handle joins.
Real-World Example: Twitter’s Sharding Approach
Twitter uses user_id hashing to shard tweets across multiple databases. This enables horizontal scaling and reduces latency. They also use caching layers and asynchronous processing to handle high write volumes.
Summary
Data partitioning and sharding are foundational for building scalable, high-performance enterprise backends. By understanding different strategies and applying best practices, technical leads can design systems that handle growth gracefully while maintaining responsiveness and reliability.
7.3 Example: Implementing a Scalable Data Access Layer
In enterprise backend systems, the Data Access Layer (DAL) serves as the critical bridge between the application logic and the underlying data stores. Designing a scalable DAL is essential to ensure that your system can handle increased load, maintain low latency, and provide consistent data access.
Key Objectives for a Scalable Data Access Layer
- Abstraction: Decouple business logic from data storage details.
- Performance: Minimize latency and optimize throughput.
- Scalability: Support horizontal scaling and distributed data sources.
- Maintainability: Easy to extend and modify without impacting other layers.
- Resilience: Handle failures gracefully and support retries or fallbacks.
Mind Map: Scalable Data Access Layer Design
Step 1: Choose the Right Abstraction Pattern
Repository Pattern is widely used to abstract the data access logic. It provides a collection-like interface for accessing domain objects.
Example:
public interface UserRepository {
User findById(String id);
List<User> findAll();
void save(User user);
void delete(String id);
}
public class UserRepositoryImpl implements UserRepository {
private final DataSource dataSource;
public UserRepositoryImpl(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public User findById(String id) {
// Implementation with optimized SQL query
}
// Other methods ...
}
This abstraction allows you to swap the underlying data store or optimize queries without changing the business logic.
Step 2: Implement Connection Pooling and Query Optimization
Connection pooling reduces the overhead of establishing database connections repeatedly.
Example: Using HikariCP in Java:
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/enterprise_db");
config.setUsername("user");
config.setPassword("password");
config.setMaximumPoolSize(20);
HikariDataSource dataSource = new HikariDataSource(config);
Query optimization involves:
- Using prepared statements
- Indexing frequently queried columns
- Avoiding N+1 query problems
Step 3: Add a Caching Layer
Caching frequently accessed data reduces database load and improves response times.
Example: Using Redis as a cache for user profiles:
public User getUserById(String id) {
String cacheKey = "user:" + id;
User cachedUser = redisClient.get(cacheKey);
if (cachedUser != null) {
return cachedUser;
}
User user = userRepository.findById(id);
if (user != null) {
redisClient.set(cacheKey, user, Duration.ofMinutes(10));
}
return user;
}
Step 4: Support Scalability with Read Replicas and Sharding
- Read Replicas: Route read queries to replicas to distribute load.
- Sharding: Partition data horizontally across multiple databases.
Mind Map: Scaling Strategies
Example: Routing reads to replicas (pseudo-code):
public User findById(String id, boolean readFromReplica) {
DataSource ds = readFromReplica ? replicaDataSource : primaryDataSource;
// Execute query on selected data source
}
Step 5: Implement Resilience Patterns
Use retry policies and circuit breakers to handle transient failures.
Example: Using Resilience4j for retries:
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.build();
Retry retry = Retry.of("userService", config);
Supplier<User> userSupplier = Retry.decorateSupplier(retry, () -> userRepository.findById(id));
User user = Try.ofSupplier(userSupplier)
.recover(throwable -> fallbackUser())
.get();
Step 6: Monitoring and Metrics
Track query latency, error rates, and cache hit ratios to identify bottlenecks.
Example: Using Micrometer metrics:
Timer.Sample sample = Timer.start(meterRegistry);
User user = userRepository.findById(id);
sample.stop(Timer.builder("db.query.time")
.tag("operation", "findById")
.register(meterRegistry));
Summary
Implementing a scalable Data Access Layer involves combining abstraction patterns, performance optimizations, caching, scaling strategies, resilience mechanisms, and monitoring. By following these best practices and iteratively refining your DAL, you ensure your enterprise backend can handle growth while maintaining responsiveness and reliability.
7.4 Best Practices for Caching and Data Replication
Caching and data replication are critical techniques to enhance the performance, scalability, and availability of enterprise backend systems. When applied correctly, they reduce latency, decrease load on primary data stores, and improve fault tolerance.
Why Caching and Data Replication Matter
- Caching stores frequently accessed data closer to the application or user, reducing expensive database calls.
- Data Replication involves copying data across multiple nodes or data centers to improve availability and fault tolerance.
Mind Map: Overview of Caching Best Practices
Mind Map: Data Replication Strategies
Best Practices for Caching
Choose the Right Cache Location
- Client-Side Caching: Useful for static assets and reducing network calls.
- Server-Side Caching: Ideal for database query results or computed data.
- CDN: Best for static content delivery at the edge.
Implement Effective Cache Invalidation
- Use TTL (Time-to-Live) to automatically expire stale data.
- Employ event-driven invalidation when underlying data changes.
- Example: In an e-commerce app, invalidate product detail cache after an update.
Select Appropriate Cache Granularity
- Cache at the object level for fine-grained control.
- Cache entire pages or query results for faster retrieval but higher invalidation complexity.
Use Suitable Eviction Policies
- LRU is commonly used to evict least recently accessed items.
- LFU can be beneficial when access frequency matters.
Monitor Cache Hit/Miss Ratios
- Regularly analyze cache metrics to tune TTL and eviction policies.
Avoid Cache Stampede
- Use techniques like request coalescing or locking to prevent multiple requests from overwhelming the backend when cache expires.
Best Practices for Data Replication
Select the Right Replication Type
- Master-Slave: Simple and widely used; slaves handle reads, master handles writes.
- Master-Master: Allows writes on multiple nodes; requires conflict resolution.
Choose Between Synchronous and Asynchronous Replication
- Synchronous: Ensures strong consistency but adds latency.
- Asynchronous: Improves performance but risks data lag.
Design for Conflict Resolution
- Use application logic or database features to handle conflicts in multi-master setups.
Plan for Network Partitions and Failover
- Implement automatic failover and leader election to maintain availability.
Use Replication for Geo-Distribution
- Place replicas closer to users to reduce latency.
Example 1: Caching with Redis in a Product Catalog Service
import redis
import json
cache = redis.Redis(host='localhost', port=6379, db=0)
PRODUCT_CACHE_TTL = 300 # seconds
def get_product(product_id):
cache_key = f"product:{product_id}"
cached = cache.get(cache_key)
if cached:
print("Cache hit")
return json.loads(cached)
else:
print("Cache miss")
product = query_database(product_id) # Simulated DB call
cache.setex(cache_key, PRODUCT_CACHE_TTL, json.dumps(product))
return product
# Simulated database query
def query_database(product_id):
# Imagine this is a costly DB operation
return {"id": product_id, "name": "Widget", "price": 19.99}
Explanation:
- The product data is cached with a TTL of 5 minutes.
- On cache miss, data is fetched from the database and cached.
- This reduces database load and improves response times.
Example 2: Master-Slave Replication Setup in PostgreSQL
# On master server (primary):
# Enable WAL archiving and replication settings in postgresql.conf
wal_level = replica
max_wal_senders = 5
# On slave server (standby):
# Use pg_basebackup to clone master data
pg_basebackup -h master_host -D /var/lib/postgresql/data -U replicator -P
# Create recovery.conf with:
standby_mode = 'on'
primary_conninfo = 'host=master_host port=5432 user=replicator password=secret'
trigger_file = '/tmp/failover.trigger'
Explanation:
- The slave continuously receives WAL logs from the master.
- Reads can be offloaded to the slave, improving scalability.
- In case of master failure, failover can be triggered.
Additional Tips
- Combine Caching and Replication: Use caching on top of replicated databases to maximize performance.
- Cache Aside Pattern: Application checks cache first, then database, and updates cache on writes.
- Monitor Replication Lag: Use tools to track replication delay and alert on anomalies.
Summary
Caching and data replication are foundational for building high-performance, resilient enterprise backends. By carefully selecting strategies and following best practices, engineers can significantly improve system responsiveness and availability while managing complexity effectively.
7.5 Handling Consistency and Availability in Distributed Data Stores
In distributed data stores, achieving the right balance between consistency and availability is one of the most critical challenges. This section explores the fundamental concepts, trade-offs, and best practices to handle consistency and availability effectively, ensuring your enterprise backend remains robust and performant.
Understanding the CAP Theorem
The CAP theorem states that in a distributed system, you can only guarantee two out of the following three properties simultaneously:
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a (non-error) response, without guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite arbitrary message loss or failure of part of the system.
Since network partitions are inevitable, distributed systems must choose between consistency and availability during partitions.
Mind Map: CAP Theorem Overview
Consistency Models in Distributed Systems
- Strong Consistency: Guarantees that all nodes see the same data at the same time.
- Eventual Consistency: Guarantees that if no new updates are made, all nodes will eventually converge to the same state.
- Causal Consistency: Ensures that causally related operations are seen by all nodes in the same order.
- Read-your-writes Consistency: Guarantees that a client always reads its own writes.
Mind Map: Consistency Models
Availability Considerations
- Systems prioritizing availability respond to all requests even during network partitions.
- May serve stale or inconsistent data temporarily.
- Important for user-facing applications requiring low latency and high uptime.
Example Scenario: Shopping Cart Service
Imagine a shopping cart service in an e-commerce platform distributed across multiple data centers.
-
Strong Consistency Approach: Using a distributed consensus protocol (e.g., Paxos, Raft) ensures all updates to the cart are immediately visible everywhere. However, this can increase latency and reduce availability during network issues.
-
Eventual Consistency Approach: Updates to the cart are propagated asynchronously. Users might see slightly stale data but the system remains highly available and responsive.
Techniques to Handle Consistency and Availability
-
Quorum-Based Replication: Reads and writes require a majority of nodes to respond, balancing consistency and availability.
-
Conflict Resolution Strategies: Use vector clocks, timestamps, or application-level reconciliation to resolve conflicts in eventually consistent systems.
-
Multi-Version Concurrency Control (MVCC): Maintains multiple versions of data to allow concurrent reads and writes.
-
Read and Write Preferences: Configure nodes to prefer local reads for availability or global reads for consistency.
Mind Map: Techniques for Consistency and Availability
Practical Example: Implementing Quorum Reads and Writes in Cassandra
Cassandra allows tuning consistency levels per operation:
- Write Consistency Levels: ONE, QUORUM, ALL
- Read Consistency Levels: ONE, QUORUM, ALL
Example:
// Writing with QUORUM consistency
session.execute("INSERT INTO users (id, name) VALUES (?, ?)".bind(userId, userName).setConsistencyLevel(ConsistencyLevel.QUORUM));
// Reading with QUORUM consistency
ResultSet rs = session.execute("SELECT * FROM users WHERE id = ?".bind(userId).setConsistencyLevel(ConsistencyLevel.QUORUM));
This ensures that a majority of replicas acknowledge writes and reads, balancing consistency and availability.
Best Practices
- Understand Your Business Requirements: Choose consistency or availability based on application needs.
- Use Tunable Consistency: Systems like Cassandra and Riak allow adjusting consistency levels dynamically.
- Implement Conflict Resolution: Design your application to handle conflicts gracefully.
- Monitor and Test Under Network Partitions: Simulate failures to observe system behavior.
- Document Consistency Guarantees: Clearly communicate to consumers what consistency guarantees exist.
Summary
Handling consistency and availability in distributed data stores requires careful design and trade-offs. By understanding the CAP theorem, consistency models, and leveraging techniques like quorum replication and conflict resolution, engineers can build resilient and performant enterprise backends.
For further reading, consider exploring:
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Cassandra and Riak official documentation on consistency
- Research papers on distributed consensus algorithms like Paxos and Raft
8. Performance Engineering and Optimization Techniques
8.1 Profiling and Benchmarking Backend Systems
Profiling and benchmarking are critical activities in backend engineering to ensure that your system meets performance expectations and scales effectively under load. This section covers the fundamentals, best practices, and practical examples to help senior software engineers and technical leads master these techniques.
What is Profiling?
Profiling is the process of measuring the runtime behavior of your application to identify bottlenecks, inefficient code paths, and resource usage patterns.
- CPU usage
- Memory consumption
- I/O operations
- Thread contention
What is Benchmarking?
Benchmarking involves running a set of tests under controlled conditions to measure the performance of your backend system or components, often comparing different implementations or configurations.
- Latency
- Throughput
- Error rates
- Resource utilization
Why Profiling and Benchmarking Matter
- Identify bottlenecks early: Pinpoint slow code or inefficient algorithms.
- Validate optimizations: Measure impact of code changes.
- Capacity planning: Understand limits under load.
- Improve user experience: Reduce latency and increase throughput.
Mind Map: Profiling and Benchmarking Overview
Profiling Techniques and Tools
| Technique | Description | Example Tools |
|---|---|---|
| CPU Profiling | Measures CPU time spent per function or thread | Java Flight Recorder, perf, VisualVM |
| Memory Profiling | Tracks memory allocation and leaks | YourKit, Valgrind, JProfiler |
| Thread Profiling | Detects thread contention and deadlocks | Thread Dump Analyzer, VisualVM |
| I/O Profiling | Monitors disk and network I/O | iostat, strace, Wireshark |
Example: CPU Profiling with Java Flight Recorder
java -XX:StartFlightRecording=duration=60s,filename=recording.jfr -jar backend-app.jar
Analyze the recording with Java Mission Control to identify hotspots.
Benchmarking Approaches
- Microbenchmarking: Tests small units of code (e.g., a single function).
- Component Benchmarking: Tests a subsystem (e.g., database access layer).
- End-to-End Benchmarking: Tests the entire backend system under simulated load.
Mind Map: Benchmarking Types and Goals
Example: Benchmarking a REST API with Apache JMeter
- Define test plan with multiple threads simulating concurrent users.
- Configure HTTP requests to API endpoints.
- Run tests with increasing load.
- Collect metrics: response time, throughput, error rate.
Sample JMeter results might show:
| Concurrent Users | Avg Response Time (ms) | Throughput (requests/sec) | Error Rate (%) |
|---|---|---|---|
| 10 | 120 | 80 | 0 |
| 50 | 300 | 200 | 1 |
| 100 | 700 | 250 | 5 |
Best Practices for Profiling and Benchmarking
- Profile in environments as close to production as possible.
- Use representative workloads and data.
- Automate benchmarking to run regularly (e.g., in CI pipelines).
- Combine profiling with monitoring to get a holistic view.
- Interpret results carefully; consider external factors like network variability.
Integrated Example: Profiling and Benchmarking a High-Load Transaction System
Scenario: A payment processing backend experiences latency spikes under heavy load.
Steps:
- Profiling: Use CPU and thread profilers to identify contention on database connection pools.
- Benchmarking: Simulate transaction load with a tool like Gatling.
- Optimization: Increase connection pool size, optimize queries.
- Re-profile and benchmark: Confirm improvements with reduced latency and higher throughput.
Summary
Profiling and benchmarking are indispensable tools for senior engineers and technical leads aiming to build high-performance backend systems. By systematically measuring and analyzing your system’s behavior, you can make informed decisions to optimize performance, scalability, and reliability.
Further Reading and Tools
- Java Flight Recorder and Mission Control
- Apache JMeter
- Gatling Load Testing
- perf Linux Profiler
- VisualVM
8.2 Identifying and Eliminating Bottlenecks
In high-performance backend engineering, bottlenecks are the primary barriers that prevent your system from achieving optimal throughput and low latency. Identifying and eliminating these bottlenecks is crucial for maintaining system responsiveness and scalability.
What is a Bottleneck?
A bottleneck is any point in the system where the flow of data or processing slows down, limiting overall system performance. It can be caused by hardware limitations, inefficient code, database constraints, network latency, or resource contention.
Step 1: Identifying Bottlenecks
Mind Map: Identifying Bottlenecks
Explanation:
- Monitoring & Metrics: Use tools like Prometheus, Grafana, or Datadog to track resource utilization and latency metrics.
- Profiling Tools: CPU and memory profilers (e.g., VisualVM, YourKit, or built-in language profilers) help pinpoint inefficient code paths.
- Logs & Traces: Distributed tracing tools like Jaeger or Zipkin help visualize request flows and identify slow services.
- Load Testing: Simulate high load scenarios to observe where the system starts to degrade.
- User Feedback: Real-world user reports can highlight performance pain points.
Step 2: Common Bottleneck Types and Examples
Mind Map: Common Bottlenecks
Example 1: CPU-bound Bottleneck
A backend service performing complex data transformations on incoming requests experiences high CPU usage, causing increased response times.
Solution: Optimize algorithms, use parallel processing, or offload heavy computations to asynchronous jobs.
Example 2: I/O-bound Bottleneck
A microservice waits excessively for database responses due to unoptimized queries.
Solution: Analyze slow queries, add indexes, use caching layers, or implement read replicas.
Step 3: Eliminating Bottlenecks
Mind Map: Eliminating Bottlenecks
Example 3: Using Caching to Eliminate Bottlenecks
A product catalog service experiences slow response times due to frequent database reads.
Solution: Implement Redis caching for frequently accessed product data, reducing database load and improving response times.
Example 4: Asynchronous Processing
A payment processing service is slowed down by synchronous calls to external payment gateways.
Solution: Use message queues (e.g., RabbitMQ, Kafka) to handle payment requests asynchronously, improving throughput and user experience.
Step 4: Practical Example - Profiling and Fixing a Bottleneck
Scenario: A REST API endpoint for fetching user profiles is slow under load.
Process:
- Monitor: Using Grafana dashboards, notice high CPU and latency spikes during peak traffic.
- Profile: CPU profiling reveals a nested loop causing quadratic time complexity.
- Optimize: Refactor the code to use hash maps for lookups, reducing complexity to linear.
- Test: Load testing shows a 50% reduction in response time.
Summary
Identifying and eliminating bottlenecks requires a systematic approach combining monitoring, profiling, and iterative optimization. By understanding the types of bottlenecks and applying best practices such as caching, asynchronous processing, and database tuning, backend engineers can significantly improve system performance.
References & Tools
- Monitoring: Prometheus, Grafana, Datadog
- Profiling: VisualVM, YourKit, Py-Spy
- Tracing: Jaeger, Zipkin
- Load Testing: JMeter, Locust
- Caching: Redis, Memcached
- Message Queues: RabbitMQ, Apache Kafka
This section equips senior engineers and technical leads with actionable insights and examples to tackle performance bottlenecks effectively.
8.3 Example: Optimizing a High-Load Transaction Processing System
Optimizing a high-load transaction processing system is a critical task for backend engineers working in enterprise environments. Such systems often handle thousands to millions of transactions per second, requiring careful design and tuning to maintain performance, reliability, and consistency.
Understanding the System Context
Before optimization, it’s essential to understand the system’s architecture, bottlenecks, and transaction characteristics.
Mind Map: Understanding High-Load Transaction Processing System
Step 1: Profiling and Identifying Bottlenecks
Use profiling tools (e.g., Java Flight Recorder, Perf, or APM tools like New Relic) to find hotspots.
- CPU-bound operations
- I/O waits (database, network)
- Lock contention
- Garbage collection pauses
Example: Profiling reveals that 60% of time is spent waiting on database writes.
Step 2: Database Optimization
Databases are often the bottleneck in transaction systems.
- Use Connection Pooling: Efficiently reuse DB connections.
- Batch Writes: Group multiple transactions to reduce overhead.
- Indexing: Add indexes on frequently queried columns.
- Partitioning/Sharding: Split data to distribute load.
- Use Optimistic Locking: Reduce locking overhead.
Mind Map: Database Optimization Strategies
Example: Implementing batch inserts reduced DB write time by 40%.
Step 3: Caching Layer Implementation
Introduce caching to reduce database load.
- Use in-memory caches (Redis, Memcached) for frequently accessed data.
- Cache transaction results or intermediate computations.
- Implement cache invalidation strategies carefully to maintain consistency.
Mind Map: Caching Strategies
Example: Caching user session data reduced DB reads by 70%, improving response times.
Step 4: Asynchronous Processing and Queuing
Offload non-critical or heavy operations asynchronously.
- Use message queues (Kafka, RabbitMQ) to decouple components.
- Implement worker pools to process queued transactions.
- Use event-driven design to trigger downstream processes.
Mind Map: Asynchronous Processing
Example: Moving invoice generation to an async queue reduced API latency by 30%.
Step 5: Concurrency and Threading Model
Optimize how the system handles concurrent transactions.
- Use non-blocking I/O where possible.
- Avoid synchronized blocks that cause thread contention.
- Use thread pools sized according to CPU cores and workload.
Example: Switching from a fixed thread pool of 50 to a dynamic pool based on CPU cores improved throughput by 25%.
Step 6: Load Balancing and Horizontal Scaling
Distribute load across multiple instances.
- Use load balancers (HAProxy, NGINX) to distribute requests.
- Scale horizontally by adding more backend instances.
- Ensure statelessness or use sticky sessions if necessary.
Mind Map: Scaling Strategies
Example: Adding 3 more backend nodes and configuring round-robin load balancing doubled throughput.
Step 7: Monitoring and Continuous Improvement
- Set up dashboards for key metrics (TPS, latency, error rates).
- Use alerts to detect performance degradation.
- Continuously profile and optimize based on data.
Summary Table of Optimization Steps with Examples
| Step | Technique | Example Outcome |
|---|---|---|
| Profiling | Identify DB write bottleneck | 60% time spent on DB writes |
| Database Optimization | Batch writes, indexing | 40% reduction in DB write time |
| Caching | Redis caching for sessions | 70% reduction in DB reads |
| Asynchronous Processing | Queue invoice generation | 30% API latency reduction |
| Concurrency Optimization | Dynamic thread pools | 25% throughput improvement |
| Load Balancing & Scaling | Add backend instances | 2x throughput increase |
Code Snippet Example: Batch Insert in Java (Using JDBC)
public void batchInsertTransactions(List<Transaction> transactions) throws SQLException {
String sql = "INSERT INTO transactions (id, amount, status) VALUES (?, ?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
conn.setAutoCommit(false);
for (Transaction tx : transactions) {
ps.setString(1, tx.getId());
ps.setBigDecimal(2, tx.getAmount());
ps.setString(3, tx.getStatus());
ps.addBatch();
}
ps.executeBatch();
conn.commit();
} catch (SQLException e) {
// handle exception
throw e;
}
}
Final Thoughts
Optimizing a high-load transaction processing system requires a holistic approach that spans database tuning, caching, asynchronous processing, concurrency management, and scaling. By systematically profiling and applying best practices with real-world examples, technical leads can significantly improve system throughput and latency while maintaining reliability and consistency.
8.4 Best Practices for Resource Management and Threading Models
Efficient resource management and optimal threading models are critical to achieving high performance and scalability in enterprise backend systems. Poor handling of threads and resources can lead to contention, deadlocks, resource starvation, and degraded system throughput.
Key Concepts in Resource Management and Threading
- Thread Lifecycle: Creation, execution, waiting, and termination.
- Thread Pools: Reusing threads to reduce overhead.
- Synchronization: Managing access to shared resources.
- Concurrency vs Parallelism: Logical vs physical simultaneous execution.
- Resource Contention: When multiple threads compete for limited resources.
Best Practices Overview
Use Thread Pools to Manage Threads Efficiently
Creating and destroying threads is expensive. Thread pools allow reuse of threads, reducing overhead and improving throughput.
Example: Java’s ExecutorService
ExecutorService threadPool = Executors.newFixedThreadPool(10);
for (int i = 0; i < 100; i++) {
threadPool.submit(() -> {
// Simulate task
System.out.println("Processing task by " + Thread.currentThread().getName());
});
}
threadPool.shutdown();
Best Practices:
- Choose pool size based on CPU cores and blocking nature of tasks.
- Use bounded queues to avoid resource exhaustion.
- Monitor thread pool metrics (active threads, queue size).
Adopt Asynchronous and Reactive Programming Models
Reactive models (e.g., Reactor, RxJava) and async programming reduce thread blocking by using event-driven, non-blocking I/O.
Example: Using CompletableFuture in Java
CompletableFuture.supplyAsync(() -> {
// Simulate I/O bound task
return fetchDataFromService();
}).thenAccept(data -> {
System.out.println("Received data: " + data);
});
Benefits:
- Improves resource utilization.
- Scales better under high concurrency.
Minimize Lock Contention and Use Fine-Grained Synchronization
Overusing locks or using coarse-grained locks causes thread contention and reduces throughput.
Mind Map:
Example: Using java.util.concurrent.atomic.AtomicInteger
AtomicInteger counter = new AtomicInteger(0);
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
counter.incrementAndGet();
}
};
// Run tasks concurrently without explicit locks
Avoid Deadlocks by Careful Lock Ordering and Timeout
Deadlocks occur when threads wait indefinitely for locks held by each other.
Best Practices:
- Always acquire multiple locks in a consistent global order.
- Use tryLock with timeout to detect potential deadlocks.
Example:
Lock lockA = new ReentrantLock();
Lock lockB = new ReentrantLock();
boolean acquireLocks() throws InterruptedException {
while (true) {
boolean gotLockA = lockA.tryLock(50, TimeUnit.MILLISECONDS);
boolean gotLockB = lockB.tryLock(50, TimeUnit.MILLISECONDS);
if (gotLockA && gotLockB) {
return true;
}
if (gotLockA) lockA.unlock();
if (gotLockB) lockB.unlock();
// Retry after some delay
Thread.sleep(10);
}
}
Tune Thread Count According to Workload Type
- CPU-bound tasks: Number of threads ≈ number of CPU cores.
- I/O-bound tasks: Number of threads > number of CPU cores (to compensate for waiting).
Example:
int cpuCores = Runtime.getRuntime().availableProcessors();
int ioBoundThreadCount = cpuCores * 2; // heuristic for I/O bound
ExecutorService ioThreadPool = Executors.newFixedThreadPool(ioBoundThreadCount);
Use Work Stealing to Balance Load Among Threads
Work stealing allows idle threads to ‘steal’ tasks from busy threads’ queues, improving CPU utilization.
Example: Java’s ForkJoinPool uses work stealing internally.
ForkJoinPool pool = new ForkJoinPool();
pool.submit(() -> {
// Parallel recursive task
});
Monitor and Profile Thread Usage and Resource Consumption
Use tools like:
- Java VisualVM, JConsole
- Thread dumps
- Application Performance Monitoring (APM) tools
Example: Detect thread leaks by monitoring thread count over time.
Summary Mind Map
Mastering resource management and threading models is essential for building robust, scalable, and high-performance enterprise backend systems. Applying these best practices with thoughtful design and continuous monitoring will help technical leads and senior engineers deliver resilient software architectures.
8.5 Load Testing and Capacity Planning for Enterprise Backends
Load testing and capacity planning are critical activities to ensure that enterprise backend systems can handle expected and unexpected traffic volumes without degradation of performance or availability. This section covers best practices, methodologies, and real-world examples to equip senior software engineers and technical leads with actionable insights.
What is Load Testing?
Load testing simulates real-world user traffic to evaluate system behavior under expected load conditions. It helps identify bottlenecks, resource constraints, and performance limits.
What is Capacity Planning?
Capacity planning involves forecasting future system resource requirements based on load testing data, business growth, and traffic trends to ensure the backend infrastructure scales appropriately.
Mind Map: Load Testing Fundamentals
Mind Map: Capacity Planning Workflow
Best Practices for Load Testing
- Define Clear Objectives: Understand what you want to achieve (e.g., max concurrent users, response time thresholds).
- Simulate Realistic User Behavior: Use realistic scenarios including think times, varied request types, and data.
- Incremental Load Increase: Gradually increase load to observe system behavior at different levels.
- Monitor System Metrics: Track CPU, memory, disk I/O, network, and application-specific metrics.
- Test in Production-Like Environments: Ensure environment parity to get accurate results.
- Analyze and Document Results: Identify bottlenecks and create actionable reports.
Example: Load Testing a REST API with Locust
from locust import HttpUser, TaskSet, task, between
class UserBehavior(TaskSet):
@task(3)
def get_items(self):
self.client.get("/api/items")
@task(1)
def create_item(self):
self.client.post("/api/items", json={"name": "test", "price": 10})
class WebsiteUser(HttpUser):
tasks = [UserBehavior]
wait_time = between(1, 5)
- This script simulates users performing GET and POST requests with weighted probabilities.
- Run with increasing user count to observe response times and error rates.
Capacity Planning Example: Forecasting for a SaaS Backend
- Current Metrics: 1000 concurrent users, average CPU utilization 60%, response time 200ms.
- Business Growth: Expecting 50% user growth in next 6 months.
- Forecast: 1500 concurrent users.
Steps:
- Analyze load test results at 1500 users.
- Identify if CPU or memory becomes a bottleneck.
- Plan infrastructure scaling (e.g., add 2 more backend instances).
- Budget for additional cloud resources.
Mind Map: Common Load Testing Scenarios
Tips for Effective Load Testing and Capacity Planning
- Automate Load Tests: Integrate with CI/CD pipelines for continuous validation.
- Use Realistic Data: Avoid synthetic data that doesn’t reflect production.
- Collaborate with Stakeholders: Align load targets with business expectations.
- Plan for Failures: Include chaos testing to understand system resilience.
- Iterate Frequently: Load testing is not one-off; repeat as system evolves.
Summary
Load testing and capacity planning are indispensable for building resilient, high-performance enterprise backends. By combining systematic testing, realistic simulations, and data-driven forecasting, engineering teams can proactively address performance challenges and scale infrastructure efficiently.
Further Reading and Tools
- Tools: Apache JMeter, Gatling, Locust, k6
- Books: “The Art of Capacity Planning” by John Allspaw
- Articles: Martin Fowler’s “Load Testing Patterns”
9. Security Patterns in Enterprise Backend Systems
9.1 Common Security Threats and Mitigation Strategies
Enterprise backend systems face a wide range of security threats that can compromise data integrity, availability, and confidentiality. Understanding these threats and implementing effective mitigation strategies is crucial for senior software engineers and technical leads responsible for designing and maintaining secure, high-performance backend systems.
Common Security Threats
Below is a mind map illustrating the major categories of security threats commonly encountered in enterprise backend systems:
Detailed Explanation and Examples
Injection Attacks
Injection attacks occur when untrusted data is sent to an interpreter as part of a command or query. The attacker’s hostile data can trick the interpreter into executing unintended commands.
Example: SQL Injection
// Vulnerable code snippet
String query = "SELECT * FROM users WHERE username = '" + username + "' AND password = '" + password + "'";
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery(query);
If username or password contains malicious SQL, attackers can bypass authentication or extract sensitive data.
Mitigation: Use parameterized queries or prepared statements.
String query = "SELECT * FROM users WHERE username = ? AND password = ?";
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, username);
pstmt.setString(2, password);
ResultSet rs = pstmt.executeQuery();
Authentication and Authorization Flaws
Weak authentication mechanisms or improper authorization checks can allow attackers to impersonate users or escalate privileges.
Example: Broken Authentication
- Using predictable session IDs
- Not invalidating sessions after logout
Mitigation:
- Implement multi-factor authentication (MFA)
- Use secure, random session tokens
- Enforce session expiration and logout
Cross-Site Scripting (XSS)
XSS attacks inject malicious scripts into web pages viewed by other users.
Example: Stored XSS where user input is stored and later rendered without sanitization.
Mitigation:
- Encode output based on context (HTML, JavaScript, URL)
- Use Content Security Policy (CSP)
Cross-Site Request Forgery (CSRF)
CSRF tricks authenticated users into submitting requests they did not intend.
Mitigation:
- Use anti-CSRF tokens
- Verify the Origin and Referer headers
Insecure Deserialization
Deserialization of untrusted data can lead to remote code execution or privilege escalation.
Mitigation:
- Avoid deserializing data from untrusted sources
- Use safe serialization formats (e.g., JSON instead of binary)
- Implement integrity checks
Security Misconfiguration
Default configurations, unnecessary features, or incomplete hardening can expose vulnerabilities.
Mitigation:
- Regularly audit configurations
- Disable unused services
- Apply principle of least privilege
Sensitive Data Exposure
Failure to protect sensitive data can lead to leaks.
Mitigation:
- Encrypt data at rest and in transit
- Use strong key management
- Avoid logging sensitive information
Denial of Service (DoS) / Distributed DoS (DDoS)
Attackers overwhelm systems to degrade or deny service.
Mitigation:
- Rate limiting
- Web Application Firewalls (WAF)
- Auto-scaling and traffic filtering
Insufficient Logging and Monitoring
Lack of proper logging can delay detection and response to attacks.
Mitigation:
- Implement centralized logging
- Monitor for anomalous behaviors
- Set up alerts for suspicious activities
Broken Access Control
Improper enforcement of access controls can allow unauthorized actions.
Mitigation:
- Enforce access control checks on server side
- Use role-based access control (RBAC) or attribute-based access control (ABAC)
Integrated Example: Mitigating Multiple Threats in a REST API
Consider a REST API endpoint that updates user profiles:
@PUT
@Path("/users/{id}")
public Response updateUser(@PathParam("id") String userId, UserProfile profile, @Context SecurityContext securityContext) {
String currentUserId = securityContext.getUserPrincipal().getName();
if (!currentUserId.equals(userId)) {
return Response.status(Response.Status.FORBIDDEN).build(); // Broken Access Control mitigation
}
// Validate and sanitize input to prevent injection and XSS
String sanitizedEmail = sanitize(profile.getEmail());
// Update user profile in database using prepared statements
userRepository.updateUserEmail(userId, sanitizedEmail);
return Response.ok().build();
}
This example demonstrates:
- Authorization check to prevent unauthorized access
- Input sanitization to prevent injection and XSS
- Use of secure database operations
Summary Mind Map: Threats and Mitigations
By systematically understanding these threats and applying layered mitigation strategies, senior engineers and technical leads can architect backend systems that are resilient, secure, and performant in demanding enterprise environments.
9.2 Implementing Authentication and Authorization Patterns
In enterprise backend systems, securing access to resources is paramount. Authentication and authorization are two fundamental security mechanisms that ensure only legitimate users and services can access protected data and operations.
Authentication vs Authorization
- Authentication: Verifying the identity of a user or service.
- Authorization: Determining what an authenticated user or service is allowed to do.
Common Authentication Patterns
Authentication Patterns Mind Map
Common Authorization Patterns
Authorization Patterns Mind Map
Best Practices for Authentication
- Use Strong Password Policies
- Enforce complexity, expiration, and reuse policies.
- Implement Multi-Factor Authentication (MFA)
- Adds an extra security layer.
- Use Token-Based Authentication (JWT/OAuth 2.0)
- Stateless, scalable, and widely supported.
- Secure Token Storage and Transmission
- Use HTTPS, HttpOnly and Secure cookies.
- Implement Session Management
- Expire sessions and tokens appropriately.
Example: Implementing JWT Authentication in a Node.js Backend
const express = require('express');
const jwt = require('jsonwebtoken');
const bodyParser = require('body-parser');
const app = express();
app.use(bodyParser.json());
const SECRET_KEY = 'your-secure-secret';
// Mock user database
const users = [{ id: 1, username: 'alice', password: 'password123' }];
// Login endpoint - authenticates user and returns JWT
app.post('/login', (req, res) => {
const { username, password } = req.body;
const user = users.find(u => u.username === username && u.password === password);
if (!user) {
return res.status(401).json({ message: 'Invalid credentials' });
}
const token = jwt.sign({ userId: user.id, username: user.username }, SECRET_KEY, { expiresIn: '1h' });
res.json({ token });
});
// Middleware to verify JWT
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, SECRET_KEY, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
// Protected route
app.get('/profile', authenticateToken, (req, res) => {
res.json({ message: `Welcome ${req.user.username}! This is your profile.` });
});
app.listen(3000, () => console.log('Server running on port 3000'));
Best Practices for Authorization
- Use Principle of Least Privilege
- Users/services get only permissions they need.
- Prefer Role-Based Access Control (RBAC) for Simplicity
- Assign users to roles with defined permissions.
- Use Attribute-Based Access Control (ABAC) for Fine-Grained Control
- Policies based on user, resource, environment attributes.
- Centralize Authorization Logic
- Avoid scattering access checks throughout code.
- Audit and Log Authorization Decisions
- For compliance and troubleshooting.
Example: Role-Based Access Control (RBAC) Implementation in Express.js
const rolesPermissions = {
admin: ['read:any_profile', 'write:any_profile'],
user: ['read:own_profile', 'write:own_profile']
};
// Middleware to check permissions
function authorize(permission) {
return (req, res, next) => {
const userRole = req.user.role; // Assume role is set in JWT or user session
const permissions = rolesPermissions[userRole] || [];
if (permissions.includes(permission)) {
next();
} else {
res.status(403).json({ message: 'Forbidden: insufficient permissions' });
}
};
}
// Example protected route
app.get('/admin/dashboard', authenticateToken, authorize('read:any_profile'), (req, res) => {
res.json({ message: 'Welcome to admin dashboard' });
});
Combining Authentication and Authorization
Combined Security Flow Mind Map
Summary
Implementing robust authentication and authorization patterns is critical for enterprise backend security. Leveraging token-based authentication like JWT combined with RBAC or ABAC authorization models provides scalable, maintainable, and secure access control. Always integrate best practices such as the principle of least privilege, session management, and auditing to build resilient backend systems.
9.3 Example: Securing Microservices with OAuth2 and JWT
Securing microservices is a critical aspect of enterprise backend engineering. OAuth2 combined with JWT (JSON Web Tokens) provides a robust, scalable, and stateless mechanism for authentication and authorization across distributed services.
Overview of OAuth2 and JWT in Microservices
- OAuth2 is an authorization framework that enables applications to obtain limited access to user accounts on an HTTP service.
- JWT is a compact, URL-safe token format that encodes claims and is digitally signed, allowing stateless authentication.
Together, OAuth2 handles the authorization flows, while JWTs carry the user identity and permissions securely between microservices.
Mind Map: Securing Microservices with OAuth2 and JWT
Step-by-Step Example: Implementing OAuth2 and JWT in a Microservices Environment
Components Setup
- Authorization Server: Responsible for authenticating users and issuing JWT access tokens.
- Resource Server (Microservice): Validates JWT tokens and enforces access control.
- Client Application: Requests tokens and accesses microservices.
Authorization Server Issues JWT Access Tokens
- Upon successful user authentication, the authorization server issues a JWT signed with a private key.
- The JWT contains claims such as the user ID (
sub), issuer (iss), expiration (exp), and scopes/roles.
Client Sends JWT with Requests
-
The client includes the JWT in the
Authorizationheader as a Bearer token:Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9...
Microservice Validates JWT
- The microservice verifies the JWT signature using the public key.
- It checks claims like expiration and scopes to authorize the request.
Access is Granted or Denied
- If validation passes, the microservice processes the request.
- Otherwise, it returns an HTTP 401 Unauthorized or 403 Forbidden.
Code Example: Simple JWT Validation in a Node.js Microservice
const express = require('express');
const jwt = require('jsonwebtoken');
const jwksClient = require('jwks-rsa');
const app = express();
// JWKS client to fetch public keys from Authorization Server
const client = jwksClient({
jwksUri: 'https://auth-server.example.com/.well-known/jwks.json'
});
function getKey(header, callback) {
client.getSigningKey(header.kid, function(err, key) {
if (err) {
callback(err, null);
} else {
const signingKey = key.getPublicKey();
callback(null, signingKey);
}
});
}
// Middleware to validate JWT
function checkJwt(req, res, next) {
const authHeader = req.headers.authorization;
if (!authHeader || !authHeader.startsWith('Bearer ')) {
return res.status(401).send('Missing or invalid Authorization header');
}
const token = authHeader.split(' ')[1];
jwt.verify(token, getKey, {
algorithms: ['RS256'],
issuer: 'https://auth-server.example.com/',
audience: 'microservice-api'
}, (err, decoded) => {
if (err) {
return res.status(401).send('Invalid token');
}
// Attach user info to request
req.user = decoded;
next();
});
}
app.use(checkJwt);
app.get('/data', (req, res) => {
// Access control based on scopes
if (!req.user.scope || !req.user.scope.includes('read:data')) {
return res.status(403).send('Insufficient scope');
}
res.json({ message: 'Secure data accessed', user: req.user.sub });
});
app.listen(3000, () => console.log('Microservice running on port 3000'));
Best Practices Embedded in the Example
- Use RS256 asymmetric signing: Allows microservices to verify tokens without sharing private keys.
- Validate issuer and audience: Ensures tokens are from trusted sources and intended for the microservice.
- Check scopes/roles: Enforces fine-grained access control.
- Use HTTPS: Protects tokens in transit (assumed in example).
- Stateless validation: No need for centralized session storage, improving scalability.
Additional Mind Map: OAuth2 Grant Types and Use Cases
Summary
By combining OAuth2 for authorization flows and JWT for token representation, microservices can securely authenticate requests in a scalable and stateless manner. This approach supports distributed systems well, enabling technical leads and senior engineers to build performant and secure enterprise backends.
For further reading, consider exploring:
- The OAuth2 RFC 6749 specification
- JWT RFC 7519 specification
- OpenID Connect for identity layer on top of OAuth2
- Libraries such as
passport.js,spring-security-oauth2, orkeycloakfor real-world implementations
9.4 Best Practices for Data Encryption and Secure Communication
Ensuring data encryption and secure communication is a cornerstone of protecting enterprise backend systems from unauthorized access, data breaches, and tampering. This section explores best practices, practical examples, and conceptual mind maps to help senior software engineers and technical leads implement robust encryption strategies effectively.
Why Encryption and Secure Communication Matter
- Protect sensitive data at rest and in transit
- Comply with regulatory requirements (e.g., GDPR, HIPAA, PCI-DSS)
- Prevent man-in-the-middle (MITM) attacks and eavesdropping
- Maintain data integrity and confidentiality
Mind Map: Core Concepts of Data Encryption and Secure Communication
Encrypting Data at Rest
Best Practices:
- Use strong symmetric encryption algorithms like AES-256 for encrypting databases, file systems, and backups.
- Leverage built-in encryption features of databases (e.g., Transparent Data Encryption in SQL Server, Oracle TDE).
- Encrypt sensitive configuration files and secrets using vault solutions (HashiCorp Vault, AWS KMS, Azure Key Vault).
- Implement strict access controls to encrypted data.
Example:
// Example: Encrypting sensitive data before storing in a database using AES
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import javax.crypto.spec.GCMParameterSpec;
public class AESEncryption {
private static final String AES = "AES";
private static final String AES_GCM_NO_PADDING = "AES/GCM/NoPadding";
private static final int TAG_LENGTH_BIT = 128;
private static final int IV_LENGTH_BYTE = 12;
public static byte[] encrypt(byte[] plaintext, SecretKey key, byte[] iv) throws Exception {
Cipher cipher = Cipher.getInstance(AES_GCM_NO_PADDING);
GCMParameterSpec spec = new GCMParameterSpec(TAG_LENGTH_BIT, iv);
cipher.init(Cipher.ENCRYPT_MODE, key, spec);
return cipher.doFinal(plaintext);
}
public static void main(String[] args) throws Exception {
KeyGenerator keyGen = KeyGenerator.getInstance(AES);
keyGen.init(256);
SecretKey key = keyGen.generateKey();
byte[] iv = new byte[IV_LENGTH_BYTE]; // SecureRandom should fill this
String sensitiveData = "UserPassword123!";
byte[] encrypted = encrypt(sensitiveData.getBytes(), key, iv);
System.out.println("Encrypted data: " + javax.xml.bind.DatatypeConverter.printHexBinary(encrypted));
}
}
Encrypting Data in Transit
Best Practices:
- Always use TLS 1.2 or higher for all communication channels (HTTP, gRPC, WebSocket).
- Enforce HTTPS by redirecting HTTP traffic and using HSTS headers.
- Use mutual TLS (mTLS) for service-to-service authentication in microservices.
- Validate certificates properly and avoid disabling hostname verification.
- Enable Perfect Forward Secrecy (PFS) by selecting appropriate cipher suites.
Example:
# Example: NGINX configuration enforcing TLS 1.3 and strong cipher suites
server {
listen 443 ssl http2;
server_name example.com;
ssl_certificate /etc/ssl/certs/example.crt;
ssl_certificate_key /etc/ssl/private/example.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers 'ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384';
ssl_prefer_server_ciphers on;
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always;
location / {
proxy_pass http://backend_service;
}
}
Key Management Best Practices
- Use dedicated Key Management Systems (KMS) like AWS KMS, Azure Key Vault, or HashiCorp Vault.
- Never hardcode encryption keys or secrets in source code.
- Implement automated key rotation policies to reduce exposure risk.
- Protect keys with hardware security modules (HSM) when possible.
- Audit and monitor key usage.
Mind Map: Key Management Lifecycle
Secure Communication Protocols and Patterns
- Use HTTPS for all web-based communication.
- Employ SSH for secure remote access and file transfers.
- Use VPNs or private networks for internal communication when possible.
- Implement OAuth2 and JWT for secure API authentication and authorization.
- Use message-level encryption in asynchronous messaging systems (e.g., encrypt payloads in Kafka or RabbitMQ).
Example:
// Example JWT payload with encrypted sensitive claim
{
"sub": "1234567890",
"name": "John Doe",
"email": "[email protected]",
"encrypted_ssn": "U2FsdGVkX1+5fZ2a..." // Encrypted Social Security Number
}
Performance Considerations
- Encryption adds CPU overhead; balance security and performance by choosing efficient algorithms.
- Use hardware acceleration (AES-NI) when available.
- Cache TLS sessions to reduce handshake overhead.
- Offload encryption/decryption to dedicated services or proxies if needed.
Summary
Implementing data encryption and secure communication requires a holistic approach covering encryption algorithms, key management, secure protocols, and performance optimization. By following these best practices and leveraging modern tools and frameworks, enterprise backend systems can achieve robust security without sacrificing performance.
References & Further Reading
- OWASP Cryptographic Storage Cheat Sheet
- NIST Special Publication 800-57: Key Management
- TLS Best Practices
- HashiCorp Vault Documentation
- JWT.io Introduction
9.5 Performance Impact of Security Measures and Optimization Tips
Enterprise backend systems must balance robust security with high performance. Security measures such as encryption, authentication, and authorization introduce computational overhead, latency, and resource consumption. Understanding these impacts and applying optimization techniques is critical for maintaining system responsiveness and scalability.
Performance Impacts of Common Security Measures
-
Encryption and Decryption Overhead
- TLS/SSL Handshake delays
- CPU cycles for symmetric and asymmetric cryptography
- Impact on data-at-rest encryption (disk I/O and CPU)
-
Authentication and Authorization Latency
- Token validation (e.g., JWT signature verification)
- External identity provider calls (OAuth2, SAML)
- Role-based access control (RBAC) checks
-
Input Validation and Sanitization
- Additional processing before business logic
- Potential for increased request processing time
-
Audit Logging and Monitoring
- I/O overhead for writing logs
- Network overhead if logs are centralized
Mind Map: Performance Impact Areas of Security Measures
Example: TLS Overhead in a High-Traffic API
Consider an API gateway handling 10,000 requests per second with TLS enabled. The TLS handshake, especially with asymmetric cryptography, can add 50-200ms latency per new connection.
Optimization: Enable TLS session reuse and keep-alive connections to amortize handshake costs over multiple requests.
// Example: Enabling HTTP/2 and TLS session reuse in Java Spring Boot
@Bean
public TomcatServletWebServerFactory servletContainer() {
TomcatServletWebServerFactory tomcat = new TomcatServletWebServerFactory();
tomcat.addConnectorCustomizers(connector -> {
connector.setProperty("sslSessionCacheSize", "1000");
connector.setProperty("sslSessionTimeout", "300");
connector.setProperty("protocols", "TLSv1.2,TLSv1.3");
});
return tomcat;
}
Optimization Tips for Security Without Sacrificing Performance
-
Use Hardware Acceleration for Cryptography
- Leverage CPU instructions like AES-NI
- Use dedicated HSMs (Hardware Security Modules) or cloud KMS services
-
Implement Token Caching and Validation Optimization
- Cache JWT validation results for short durations
- Use lightweight tokens with minimal claims
-
Asynchronous and Batched Security Operations
- Offload heavy tasks like audit logging to asynchronous queues
- Batch authorization checks where possible
-
Adopt Efficient Algorithms and Protocols
- Prefer elliptic curve cryptography (ECDSA) over RSA for signatures
- Use HTTP/2 or HTTP/3 to reduce connection overhead
-
Minimize External Calls in Security Flows
- Cache identity provider metadata
- Use local token introspection instead of remote calls
-
Optimize Input Validation
- Use compiled regex or parser generators
- Validate early and reject invalid requests quickly
-
Leverage API Gateways and Edge Security
- Terminate TLS and perform authentication at the edge
- Reduce load on backend services
Mind Map: Security Performance Optimization Strategies
Example: Asynchronous Audit Logging Implementation
import threading
import queue
import time
# Queue to hold audit log entries
audit_log_queue = queue.Queue()
# Worker thread to process logs asynchronously
def audit_log_worker():
while True:
log_entry = audit_log_queue.get()
if log_entry is None:
break
# Simulate I/O operation
time.sleep(0.01) # Write to log storage
print(f"Logged: {log_entry}")
audit_log_queue.task_done()
# Start worker thread
threading.Thread(target=audit_log_worker, daemon=True).start()
# Function to add audit logs asynchronously
def log_audit_event(event):
audit_log_queue.put(event)
# Usage example
log_audit_event("User 123 logged in")
log_audit_event("User 123 accessed resource XYZ")
This approach prevents audit logging from blocking the main request thread, improving throughput.
Summary
Security is non-negotiable in enterprise backends but can introduce performance overhead. By understanding the impact areas and applying targeted optimizations—such as hardware acceleration, caching, asynchronous processing, and efficient algorithms—technical leads can design systems that are both secure and performant.
Continuous profiling and monitoring of security components are essential to identify bottlenecks and validate optimization effectiveness.
10. Observability and Monitoring for Enterprise Backends
10.1 Importance of Observability in High Performance Systems
Observability is a critical aspect of designing, operating, and maintaining high performance backend systems in enterprise environments. It refers to the ability to understand the internal state of a system based on the data it produces, such as logs, metrics, and traces. Without proper observability, diagnosing issues, optimizing performance, and ensuring reliability become guesswork, which can lead to costly downtime and degraded user experience.
Why Observability Matters in High Performance Systems
- Proactive Issue Detection: Early identification of anomalies before they escalate into failures.
- Root Cause Analysis: Quickly pinpointing the source of problems in complex distributed systems.
- Performance Optimization: Understanding bottlenecks and resource utilization to improve throughput and latency.
- Capacity Planning: Data-driven decisions on scaling infrastructure to meet demand.
- Reliability and SLA Compliance: Ensuring systems meet defined service level agreements through continuous monitoring.
Core Pillars of Observability
Example: Observability in a High-Performance Order Processing System
Imagine an enterprise e-commerce backend handling thousands of orders per minute. Observability enables the engineering team to:
- Track order processing latency: Metrics show a spike in processing time.
- Analyze logs: Identify error messages related to inventory service timeouts.
- Trace requests: Pinpoint that a downstream microservice is causing delays.
This combined insight allows the team to quickly isolate and fix the bottleneck, minimizing customer impact.
Mind Map: Benefits of Observability in High Performance Systems
Best Practices for Implementing Observability
- Instrument your code: Embed logging, metrics, and tracing hooks at critical points.
- Use standardized formats: For logs (e.g., JSON), metrics (e.g., Prometheus exposition format), and trace context (e.g., W3C Trace Context).
- Centralize data collection: Employ tools like ELK stack, Prometheus, Jaeger, or commercial observability platforms.
- Correlate data sources: Link logs, metrics, and traces via unique identifiers (e.g., request IDs).
- Automate alerting: Define thresholds and anomaly detection to notify teams proactively.
Example: Correlating Logs, Metrics, and Traces
By correlating these data points, engineers can confidently identify that the inventory service latency spike caused order processing delays.
Summary
Observability is indispensable for high performance enterprise backend systems. It empowers technical leads and senior engineers to maintain system health, optimize performance, and deliver reliable services. Investing in comprehensive observability strategies pays off by reducing downtime, accelerating troubleshooting, and enabling data-driven operational decisions.
10.2 Designing Effective Logging, Metrics, and Tracing
In modern enterprise backend systems, observability is a cornerstone for maintaining high performance, reliability, and rapid troubleshooting. Designing effective logging, metrics, and tracing strategies enables technical leads and senior engineers to gain deep insights into system behavior, identify bottlenecks, and proactively address issues.
Overview
- Logging: Captures discrete events and contextual information.
- Metrics: Quantitative measurements over time, often aggregated.
- Tracing: Tracks the flow of requests across distributed components.
Each plays a complementary role in observability and should be designed cohesively.
Mind Map: Observability Components
Designing Effective Logging
Best Practices:
- Use structured logging (e.g., JSON) to enable easier parsing and querying.
- Include contextual metadata such as request IDs, user IDs, and service names.
- Define and consistently use log levels:
- DEBUG: Detailed troubleshooting info
- INFO: High-level system events
- WARN: Unexpected but recoverable issues
- ERROR: Failures requiring attention
- Avoid logging sensitive data to comply with security and privacy policies.
- Implement correlation IDs to trace logs across distributed services.
Example:
{
"timestamp": "2024-06-01T12:34:56.789Z",
"level": "ERROR",
"service": "order-service",
"traceId": "abcd1234efgh5678",
"spanId": "span1234",
"message": "Failed to process order",
"orderId": "order789",
"error": {
"type": "ValidationError",
"message": "Invalid payment method"
}
}
Designing Effective Metrics
Metric Types:
- Counters: Monotonically increasing values (e.g., number of requests).
- Gauges: Values that can go up or down (e.g., current memory usage).
- Histograms/Summaries: Distribution of values (e.g., request latency).
Best Practices:
- Use meaningful labels/tags to slice and dice metrics (e.g., endpoint, status code).
- Define SLIs (Service Level Indicators) aligned with business goals.
- Use aggregation windows appropriate for alerting and capacity planning.
- Avoid high-cardinality labels that can overwhelm metric stores.
Example:
# HELP http_requests_total The total number of HTTP requests
# TYPE http_requests_total counter
http_requests_total{method="POST",endpoint="/api/orders",status="200"} 1024
# HELP http_request_duration_seconds Histogram of request durations
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.1"} 240
http_request_duration_seconds_bucket{le="0.5"} 900
http_request_duration_seconds_bucket{le="1"} 1020
http_request_duration_seconds_sum 350
http_request_duration_seconds_count 1024
Designing Effective Tracing
Core Concepts:
- Trace: Represents an end-to-end request journey.
- Span: A unit of work within a trace, e.g., a function call or remote request.
- Context Propagation: Passing trace and span IDs through service boundaries.
Best Practices:
- Use distributed tracing frameworks like OpenTelemetry.
- Implement sampling to reduce overhead but maintain visibility.
- Capture span attributes such as service name, operation, error status.
- Correlate traces with logs and metrics using trace IDs.
Example:
{
"traceId": "abcd1234efgh5678",
"spans": [
{
"spanId": "span1",
"parentSpanId": null,
"name": "HTTP GET /api/orders",
"startTime": "2024-06-01T12:34:56.000Z",
"endTime": "2024-06-01T12:34:56.100Z",
"attributes": {
"http.status_code": 200,
"service.name": "api-gateway"
}
},
{
"spanId": "span2",
"parentSpanId": "span1",
"name": "DB Query: SELECT * FROM orders",
"startTime": "2024-06-01T12:34:56.020Z",
"endTime": "2024-06-01T12:34:56.070Z",
"attributes": {
"db.system": "postgresql",
"db.statement": "SELECT * FROM orders WHERE id=123"
}
}
]
}
Integrated Example: Correlating Logs, Metrics, and Traces
Imagine a user places an order through a microservices-based e-commerce platform:
- Trace: A trace is created when the API gateway receives the request, propagating trace IDs through order, payment, and inventory services.
- Logs: Each service logs events with the trace ID and span ID, e.g., “Order validated”, “Payment authorized”, “Inventory reserved”.
- Metrics: Metrics track request counts, error rates, and latency per service.
This integrated observability allows engineers to:
- Quickly identify which service or span caused latency.
- Correlate errors in logs with spikes in error metrics.
- Visualize the full request journey in tracing dashboards.
Summary
| Aspect | Key Design Considerations | Example Tools/Technologies |
|---|---|---|
| Logging | Structured logs, contextual metadata, log levels | ELK Stack, Fluentd, Logstash |
| Metrics | Counters/gauges/histograms, labels, aggregation | Prometheus, Grafana |
| Tracing | Distributed tracing, spans, context propagation, sampling | OpenTelemetry, Jaeger, Zipkin |
By thoughtfully designing logging, metrics, and tracing, senior engineers and technical leads can build highly observable enterprise backends that simplify debugging, improve reliability, and optimize performance.
10.3 Example: Implementing Distributed Tracing in a Microservices Architecture
Distributed tracing is essential for understanding the flow of requests across multiple microservices, diagnosing latency issues, and improving overall system observability. In this section, we will explore how to implement distributed tracing in a microservices architecture with practical examples and mind maps to clarify concepts.
What is Distributed Tracing?
Distributed tracing tracks a request as it travels through various services, capturing timing and metadata at each step. This helps engineers visualize the entire request lifecycle and identify bottlenecks or failures.
Key Concepts in Distributed Tracing
Mind Map: Distributed Tracing Core Concepts
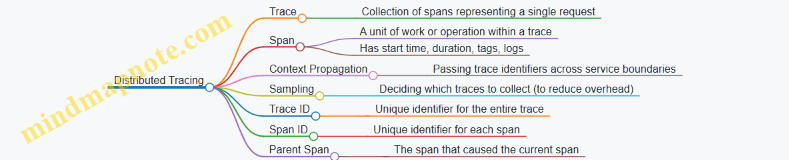
Tools and Frameworks
- OpenTelemetry: Vendor-neutral instrumentation framework
- Jaeger: Open-source distributed tracing system
- Zipkin: Another popular tracing system
- Spring Cloud Sleuth: For Java Spring microservices
Step-by-Step Implementation Example
Scenario:
An e-commerce platform with three microservices:
- API Gateway - Receives client requests
- Order Service - Processes orders
- Inventory Service - Manages stock levels
We want to trace a request from the API Gateway through Order Service to Inventory Service.
Step 1: Instrument Services with OpenTelemetry SDK
- Add OpenTelemetry SDK dependencies to each microservice.
- Configure exporters (e.g., Jaeger) to send trace data.
Step 2: Propagate Trace Context
- Use HTTP headers (e.g.,
traceparentandtracestate) to propagate trace context between services. - Ensure each service extracts incoming trace context and creates child spans.
Step 3: Create Spans for Key Operations
- In API Gateway: Create a root span for the incoming HTTP request.
- In Order Service: Create spans for order validation, payment processing.
- In Inventory Service: Create spans for stock reservation.
Code Snippet (Node.js with OpenTelemetry):
const { NodeTracerProvider } = require('@opentelemetry/sdk-trace-node');
const { registerInstrumentations } = require('@opentelemetry/instrumentation');
const { HttpInstrumentation } = require('@opentelemetry/instrumentation-http');
const { JaegerExporter } = require('@opentelemetry/exporter-jaeger');
const { SimpleSpanProcessor } = require('@opentelemetry/sdk-trace-base');
// Initialize tracer provider
const provider = new NodeTracerProvider();
// Configure Jaeger exporter
const exporter = new JaegerExporter({
endpoint: 'http://localhost:14268/api/traces',
});
provider.addSpanProcessor(new SimpleSpanProcessor(exporter));
provider.register();
// Register HTTP instrumentation to auto-instrument HTTP calls
registerInstrumentations({
instrumentations: [new HttpInstrumentation()],
});
const tracer = provider.getTracer('api-gateway');
// Example: Creating a root span for incoming request
function handleRequest(req, res) {
const span = tracer.startSpan('handleRequest');
// Simulate downstream call
callOrderService().then(() => {
span.end();
res.send('Order processed');
});
}
Step 4: Visualize Traces
- Run Jaeger UI (
http://localhost:16686) to view traces. - Search for traces by trace ID, operation name, or duration.
Mind Map: Distributed Tracing Implementation Workflow
Best Practices
- Consistent Context Propagation: Ensure all services propagate trace context correctly to maintain trace continuity.
- Sampling Strategy: Use adaptive sampling to balance between overhead and data granularity.
- Tagging and Logging: Add meaningful tags and logs to spans to enrich trace data.
- Instrumentation Automation: Use auto-instrumentation libraries where possible to reduce manual effort.
Additional Example: Propagating Trace Context in HTTP Headers
GET /order HTTP/1.1
Host: orderservice.example.com
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
tracestate: congo=t61rcWkgMzE
Each service reads these headers to continue the trace.
Summary
Implementing distributed tracing in microservices requires:
- Instrumenting each service to create and propagate spans
- Using a tracing backend like Jaeger for visualization
- Following best practices for context propagation and sampling
This approach enables technical leads and senior engineers to gain deep insights into system behavior, quickly troubleshoot issues, and optimize performance across complex enterprise backends.
10.4 Best Practices for Alerting and Incident Response
Effective alerting and incident response are critical components of maintaining high availability and performance in enterprise backend systems. This section explores best practices that technical leads and senior engineers can implement to ensure timely detection, diagnosis, and resolution of issues.
Key Principles of Alerting and Incident Response
- Relevance: Alerts should be meaningful and actionable to avoid alert fatigue.
- Timeliness: Alerts must be delivered promptly to enable quick response.
- Clarity: Alerts should provide clear context and guidance.
- Prioritization: Differentiate alerts by severity to focus on critical issues first.
- Automation: Automate incident detection and response workflows where possible.
Mind Map: Core Components of Alerting and Incident Response
Best Practices for Alerting
Define Clear Alerting Thresholds
- Use historical data and performance baselines to set realistic thresholds.
- Example: Trigger CPU usage alert only if usage exceeds 85% for 5 consecutive minutes.
Use Multi-Dimensional Alerting
- Combine multiple metrics or signals to reduce false positives.
- Example: Alert only if both error rate and latency spike simultaneously.
Categorize Alerts by Severity
- Define severity levels such as Critical, Warning, and Info.
- Example: Critical alert for service downtime; Warning for degraded performance.
Provide Contextual Information
- Include relevant logs, recent deployments, and affected services in alerts.
- Example: “Service X latency increased by 40% after deployment Y.”
Implement Alert Deduplication and Suppression
- Avoid alert storms by grouping related alerts and suppressing duplicates.
Regularly Review and Tune Alerts
- Continuously analyze alert effectiveness and adjust thresholds or rules.
Example: Defining an Effective Alert in Prometheus Alertmanager
groups:
- name: backend_alerts
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.05
for: 10m
labels:
severity: critical
annotations:
summary: "High HTTP 5xx error rate detected"
description: "More than 5% of requests are failing with 5xx errors for over 10 minutes."
This alert triggers only if the error rate exceeds 5% for 10 minutes, reducing noise from transient spikes.
Best Practices for Incident Response
Establish Clear On-Call and Escalation Policies
- Define who is responsible for responding to alerts and escalation paths.
Use Runbooks for Common Incidents
- Document step-by-step procedures to diagnose and resolve frequent issues.
Enable Collaboration Through ChatOps
- Integrate alerting tools with chat platforms (e.g., Slack, Microsoft Teams) for real-time communication.
Prioritize Incident Triage
- Quickly assess impact and scope to allocate resources effectively.
Maintain an Incident Timeline
- Record key events, actions taken, and decisions made during the incident.
Conduct Postmortems
- Analyze root causes, document lessons learned, and implement preventive measures.
Mind Map: Incident Response Workflow
Example: Incident Response Using PagerDuty and Slack Integration
- Alert Triggered: Prometheus Alertmanager sends alert to PagerDuty.
- PagerDuty Notification: On-call engineer receives SMS, email, and mobile push notification.
- Incident Created: PagerDuty automatically opens an incident and posts a message to a dedicated Slack channel.
- Collaboration: Engineers discuss the issue in Slack, share logs, and coordinate fixes.
- Resolution: Once fixed, the incident is resolved in PagerDuty, and a postmortem is scheduled.
Additional Tips
- Avoid Alert Fatigue: Limit non-actionable alerts and use machine learning to detect anomalies intelligently.
- Test Your Alerting Pipeline: Regularly simulate incidents to verify alert delivery and response readiness.
- Leverage Metrics and Traces: Combine monitoring data for faster root cause analysis.
Summary
Implementing robust alerting and incident response practices ensures enterprise backend systems remain reliable and performant. By combining clear, actionable alerts with structured incident workflows and collaborative tools, technical leads can empower their teams to detect and resolve issues swiftly, minimizing downtime and impact on users.
10.5 Leveraging AI and Machine Learning for Predictive Monitoring
In modern enterprise backend systems, observability and monitoring are crucial for maintaining high availability, performance, and reliability. Traditional monitoring approaches often rely on threshold-based alerts and reactive incident management. However, with the increasing complexity and scale of backend systems, these methods can lead to alert fatigue and delayed responses.
Leveraging Artificial Intelligence (AI) and Machine Learning (ML) for predictive monitoring enables proactive detection of anomalies, capacity planning, and automated remediation, significantly improving system resilience and operational efficiency.
What is Predictive Monitoring?
Predictive monitoring uses AI/ML algorithms to analyze historical and real-time telemetry data (logs, metrics, traces) to predict potential system failures, performance degradations, or security incidents before they occur.
Benefits of AI/ML-Driven Predictive Monitoring
- Early Anomaly Detection: Identifies subtle deviations from normal behavior that traditional threshold-based systems may miss.
- Reduced Alert Fatigue: Filters out noise by correlating events and prioritizing alerts based on predicted impact.
- Capacity Forecasting: Predicts resource exhaustion and scaling needs.
- Automated Root Cause Analysis: Helps pinpoint the underlying causes of issues faster.
Core Components of AI/ML Predictive Monitoring
Common AI/ML Techniques in Predictive Monitoring
- Anomaly Detection: Detects unusual patterns in data.
- Example: Using Isolation Forest or Autoencoders to detect CPU usage spikes.
- Time Series Forecasting: Predicts future metric values.
- Example: Using ARIMA or LSTM models to forecast memory consumption.
- Clustering: Groups similar events or behaviors.
- Example: K-Means clustering to group similar error logs.
- Classification: Categorizes incidents or alerts.
- Example: Classifying alerts as critical, warning, or info based on historical outcomes.
Example: Implementing Predictive Monitoring with ML for Latency Anomalies
Scenario: A backend service experiences intermittent latency spikes impacting user experience. The goal is to predict these spikes before they occur.
Step 1: Data Collection
- Collect latency metrics at 1-minute intervals.
- Gather related system metrics (CPU, memory, network I/O).
Step 2: Data Preprocessing
- Clean missing data points.
- Normalize metrics.
- Extract features like moving averages, rate of change.
Step 3: Model Selection
- Use an LSTM (Long Short-Term Memory) neural network for time series anomaly detection.
Step 4: Training & Validation
- Train the model on historical latency data labeled with normal and spike periods.
Step 5: Deployment & Prediction
- Deploy the model in the monitoring pipeline.
- Predict latency anomalies 5 minutes in advance.
Step 6: Alerting & Remediation
- Trigger alerts with predicted anomaly confidence.
- Integrate with auto-scaling or traffic routing mechanisms.
Mind Map: Predictive Monitoring Workflow Example
Best Practices for AI/ML Predictive Monitoring
- Start Small: Begin with a single critical metric or service.
- Use Domain Knowledge: Incorporate expert insights to improve feature engineering.
- Continuously Retrain Models: Adapt to evolving system behavior.
- Combine Multiple Data Sources: Correlate logs, metrics, and traces for richer context.
- Human-in-the-Loop: Allow engineers to validate and refine predictions.
- Integrate with Existing Tools: Use platforms like Prometheus, Grafana, or ELK stack alongside AI models.
Tools and Frameworks
- Open Source: TensorFlow, PyTorch, Prophet (for forecasting), ELK Stack, Prometheus
- Commercial: Datadog AI, New Relic Applied Intelligence, Splunk ITSI
Summary
Leveraging AI and ML for predictive monitoring transforms backend observability from reactive to proactive. By intelligently analyzing telemetry data, technical leads and senior engineers can anticipate issues, optimize resource utilization, and improve system reliability—key factors for high performance enterprise backend engineering.
11. Continuous Integration and Deployment (CI/CD) for Enterprise Backends
11.1 CI/CD Principles and Benefits for Enterprise Software
Continuous Integration and Continuous Deployment (CI/CD) are foundational practices in modern enterprise software engineering, enabling teams to deliver high-quality software rapidly and reliably. This section explores the core principles of CI/CD, its benefits specifically tailored for enterprise environments, and practical examples to illustrate these concepts.
What is CI/CD?
- Continuous Integration (CI): The practice of automatically integrating code changes from multiple contributors into a shared repository several times a day. Each integration is verified by automated builds and tests to detect integration errors early.
- Continuous Deployment (CD): The practice of automatically deploying every change that passes the automated tests to production or staging environments, ensuring rapid delivery of new features and fixes.
Core Principles of CI/CD
Benefits of CI/CD in Enterprise Software
- Faster Time to Market: Automating integration and deployment pipelines reduces manual errors and accelerates release cycles.
- Improved Code Quality: Automated testing and static analysis catch defects early, reducing bugs in production.
- Reduced Integration Risk: Frequent integration minimizes the “integration hell” problem common in large teams.
- Enhanced Collaboration: Developers can work in parallel with confidence that their changes will integrate smoothly.
- Scalability: Pipelines can be scaled to handle multiple services and teams in large enterprise environments.
- Consistent Environments: Automated deployments ensure that staging, testing, and production environments remain consistent.
- Rapid Feedback Loops: Immediate feedback on code quality and deployment status helps teams react quickly.
Example: Implementing a Simple CI Pipeline with GitHub Actions
name: CI Pipeline
on:
push:
branches:
- main
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
- name: Build with Gradle
run: ./gradlew build
- name: Run Tests
run: ./gradlew test
This pipeline triggers on every push to the main branch, checks out the code, sets up Java, builds the project, and runs tests automatically.
Example: Continuous Deployment with Canary Releases
Scenario: An enterprise backend service deploys a new version to 5% of users. Monitoring tools track error rates and latency. If metrics remain stable, traffic is gradually shifted to the new version. If problems arise, the deployment is rolled back immediately.
Best Practices for Enterprise CI/CD
- Automate Everything: From code integration to deployment and monitoring.
- Maintain a Single Source of Truth: Use version control systems like Git.
- Implement Comprehensive Testing: Unit, integration, and end-to-end tests.
- Use Feature Flags: To control feature rollout without redeploying.
- Secure Pipelines: Protect secrets and enforce access controls.
- Monitor Pipeline Health: Track build times, failure rates, and deployment success.
Summary
CI/CD transforms enterprise software delivery by embedding automation, quality, and rapid feedback into the development lifecycle. By embracing these principles, technical leads can foster a culture of continuous improvement, reduce risks, and deliver high-performance backend systems that meet evolving business needs.
11.2 Designing Pipelines for High Performance Backend Systems
Designing CI/CD pipelines for high performance backend systems requires careful consideration of automation, speed, reliability, and scalability. The goal is to enable rapid, safe, and repeatable deployments while minimizing downtime and performance regressions.
Key Principles of High Performance CI/CD Pipelines
- Automation: Automate build, test, and deployment steps to reduce manual errors and speed up delivery.
- Parallelism: Run tasks in parallel where possible to reduce overall pipeline duration.
- Incremental Builds: Use caching and incremental compilation to avoid rebuilding unchanged components.
- Early Feedback: Incorporate fast unit and integration tests early to catch issues quickly.
- Scalability: Ensure the pipeline can handle multiple concurrent builds and deployments.
- Rollback and Recovery: Design rollback mechanisms to quickly revert faulty deployments.
Mind Map: Components of a High Performance CI/CD Pipeline
Example Pipeline Design for a Microservices Backend
Scenario: A microservices-based backend system with multiple services written in Java and Node.js, deployed on Kubernetes.
-
Source Control & Trigger: Pipeline triggers on pull request creation and merge to
mainbranch. -
Build Stage:
- Use Docker layer caching to speed up container image builds.
- Build Java services with Maven incremental builds.
- Use
npm ciwith caching for Node.js services.
-
Test Stage:
- Run unit tests in parallel across services.
- Execute integration tests against a shared test environment.
- Run static code analysis and security scans.
-
Performance Testing:
- Run lightweight load tests on critical endpoints.
-
Deployment Stage:
- Deploy to staging environment automatically.
- On approval, deploy to production using blue-green deployment.
- Monitor key metrics and roll back if anomalies detected.
-
Notifications:
- Slack notifications for build status.
- Dashboard for deployment health.
Mind Map: Parallelization Strategies in Pipeline
Best Practices with Examples
-
Use Caching to Speed Up Builds:
- Example: Cache Maven
.m2repository and Docker layers to avoid downloading dependencies repeatedly.
- Example: Cache Maven
-
Fail Fast Strategy:
- Run fast unit tests before slower integration or performance tests to avoid wasting resources.
-
Incremental Deployment:
- Deploy only changed microservices rather than the entire backend.
-
Canary Releases:
- Deploy new version to a small subset of users and monitor before full rollout.
-
Automated Rollbacks:
- Example: If error rate exceeds threshold post-deployment, automatically revert to previous stable version.
Example: Jenkinsfile Snippet for Parallel Build and Test
pipeline {
agent any
stages {
stage('Build') {
parallel {
stage('Build Service A') {
steps {
sh 'mvn -f service-a/pom.xml clean package'
}
}
stage('Build Service B') {
steps {
sh 'npm ci --prefix service-b'
sh 'npm run build --prefix service-b'
}
}
}
}
stage('Test') {
parallel {
stage('Unit Tests') {
steps {
sh './run-unit-tests.sh'
}
}
stage('Integration Tests') {
steps {
sh './run-integration-tests.sh'
}
}
}
}
}
post {
failure {
mail to: '[email protected]', subject: "Build Failed: ${env.JOB_NAME}", body: "Please check the build logs."
}
}
}
Summary
Designing pipelines for high performance backend systems involves leveraging automation, parallelism, caching, and robust deployment strategies. By integrating these best practices with real-world examples, technical leads can build pipelines that accelerate delivery without compromising reliability or performance.
11.3 Example: Automating Deployment of a Microservices-Based Application
Automating the deployment of a microservices-based application is critical to ensure consistency, speed, and reliability in delivering new features and fixes. This section walks through a detailed example of setting up a CI/CD pipeline for a microservices architecture, highlighting best practices and practical tips.
Overview of the Deployment Automation Process
Step 1: Source Code Management and Branching Strategy
- Use Git repositories with feature branching.
- Protect main branches (e.g.,
mainormaster) with pull request reviews. - Example:
- Developers create feature branches.
- Pull requests trigger automated builds and tests.
# Example git commands
git checkout -b feature/payment-service-enhancement
# After development
git push origin feature/payment-service-enhancement
Step 2: Building Microservices
- Each microservice has its own build pipeline.
- Use containerization (e.g., Docker) to package services.
- Example Dockerfile snippet for a Node.js microservice:
FROM node:16-alpine
WORKDIR /app
COPY package*.json ./
RUN npm install --production
COPY . .
CMD ["node", "server.js"]
- Build pipeline example (using GitHub Actions):
name: Build and Push Service A
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker image
run: |
docker build -t myorg/service-a:${{ github.sha }} .
- name: Push to Registry
run: |
echo ${{ secrets.DOCKER_PASSWORD }} | docker login -u ${{ secrets.DOCKER_USERNAME }} --password-stdin
docker push myorg/service-a:${{ github.sha }}
Step 3: Automated Testing
- Unit tests, integration tests, and contract tests should run automatically.
- Example: Using Jest for unit tests in a Node.js microservice.
{
"scripts": {
"test": "jest"
}
}
- Include tests in the CI pipeline before deployment.
Step 4: Deployment Orchestration
- Use Kubernetes or similar orchestration platforms.
- Deployment manifests or Helm charts define service deployment.
Example Helm values snippet for service A:
replicaCount: 3
image:
repository: myorg/service-a
tag: "{{ .Chart.AppVersion }}"
service:
type: ClusterIP
port: 8080
- Automate deployment with tools like Argo CD or Flux for GitOps.
Step 5: Canary Releases and Rollbacks
- Gradually shift traffic to new versions to minimize risk.
- Example: Using Istio for traffic splitting.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: service-a
spec:
hosts:
- service-a
http:
- route:
- destination:
host: service-a
subset: v1
weight: 90
- destination:
host: service-a
subset: v2
weight: 10
- Rollback by redirecting 100% traffic back to stable version.
Step 6: Monitoring and Alerts
- Integrate monitoring (Prometheus, Grafana) and logging (ELK stack).
- Set alerts for deployment failures or performance degradation.
Full Mind Map for Automating Deployment
Summary
Automating deployment for microservices involves orchestrating multiple steps—from source control and building container images to testing, deploying, and monitoring. Leveraging containerization, orchestration platforms, and modern CI/CD tools enables teams to deliver high-quality software rapidly and reliably. Incorporating strategies like canary releases and automated rollbacks further enhances system resilience and user experience.
11.4 Best Practices for Rollbacks, Canary Releases, and Blue-Green Deployments
In enterprise backend engineering, deploying new versions of software safely and efficiently is crucial to maintaining high availability and performance. This section covers best practices for three key deployment strategies: Rollbacks, Canary Releases, and Blue-Green Deployments. Each approach helps minimize downtime and reduce risk when releasing changes.
Rollbacks
Definition: A rollback is the process of reverting a system to a previous stable version after detecting issues in a new release.
Best Practices:
- Automate Rollbacks: Use deployment pipelines that support automatic rollback on failure detection.
- Maintain Versioned Artifacts: Always keep previous stable builds accessible for quick redeployment.
- Database Rollbacks: Plan for database schema changes carefully; use backward-compatible migrations or versioned schemas.
- Monitor Closely: Implement real-time monitoring to detect failures early and trigger rollbacks.
Example: Imagine deploying a new API version that causes increased error rates. Automated monitoring detects the spike and triggers a rollback to the last stable container image, restoring service within minutes.
Canary Releases
Definition: Canary releases involve rolling out a new version to a small subset of users or servers before full deployment.
Best Practices:
- Gradual Traffic Shift: Start with a small percentage (e.g., 5%) and increase gradually based on health metrics.
- Automated Metrics Analysis: Use automated systems to compare error rates, latency, and resource usage between canary and stable versions.
- Isolate Canary Environment: Use feature flags or separate deployment units to isolate canary traffic.
- Rollback Ready: Have automated rollback triggers if canary metrics degrade.
Example: A payment processing service deploys a new version to 5% of its servers. Metrics show no increase in error rates after 30 minutes, so traffic is incrementally increased to 50%, then 100%. If errors spike, rollback is triggered immediately.
Blue-Green Deployments
Definition: Blue-Green deployment maintains two identical production environments (Blue and Green). One serves live traffic while the other is updated.
Best Practices:
- Environment Parity: Ensure both environments are identical in configuration and capacity.
- Switch Traffic Atomically: Use load balancers or DNS to switch traffic instantly from Blue to Green.
- Test in Green Before Switch: Fully test the new version in the inactive environment before switching.
- Rollback by Switching Back: If issues arise, switch traffic back to the previous environment.
Example: An enterprise CRM system runs on the Blue environment. The Green environment is updated with a new release and tested thoroughly. Once verified, traffic is switched to Green. If a critical bug is found, traffic switches back to Blue immediately.
Mind Maps
Deployment Strategies Overview
Rollback Process
Canary Release Flow
Blue-Green Deployment Steps
Integrated Example: E-Commerce Backend Deployment
Consider an e-commerce platform deploying a new checkout service version.
- Blue-Green Deployment: The new version is deployed to the Green environment and tested with synthetic transactions.
- Canary Release: Traffic is switched to Green for 10% of users, monitoring payment success rates and latency.
- Monitoring: Automated dashboards track errors and performance.
- Rollback: If errors exceed threshold, traffic switches back to Blue automatically.
- Full Rollout: If stable, traffic is gradually increased to 100%.
This combined approach ensures minimal disruption and rapid recovery.
Summary
- Automate rollback procedures and keep previous versions ready.
- Use canary releases to minimize risk by gradual exposure.
- Employ blue-green deployments for near-zero downtime and quick rollback.
- Leverage monitoring and automation to detect issues and trigger responses.
By integrating these deployment strategies with robust monitoring and automation, technical leads can ensure high availability and performance in enterprise backend systems.
11.5 Performance Considerations in Deployment Automation
Deployment automation is a cornerstone of modern enterprise backend engineering, enabling rapid, reliable, and repeatable software releases. However, automating deployments without considering performance can lead to bottlenecks, increased downtime, and inefficient resource utilization. This section explores key performance considerations when designing and implementing deployment automation pipelines, supplemented with practical examples and mind maps to visualize concepts.
Key Performance Considerations in Deployment Automation
- Pipeline Execution Time: Minimizing the total time taken from code commit to production deployment.
- Resource Utilization: Efficient use of compute, network, and storage resources during builds and deployments.
- Parallelism and Concurrency: Running independent tasks simultaneously to reduce overall pipeline duration.
- Incremental and Partial Deployments: Deploying only changed components to reduce deployment scope and time.
- Rollback Speed: Ensuring quick rollback mechanisms to minimize downtime in case of failures.
- Monitoring and Feedback Loops: Real-time insights to detect and resolve performance bottlenecks promptly.
Mind Map: Performance Factors in Deployment Automation
Pipeline Execution Time Optimization
Best Practice: Break down the deployment pipeline into smaller stages that can be executed independently and in parallel where possible.
Example:
A microservices backend project uses a CI/CD pipeline with the following stages:
- Build all microservices
- Run unit tests
- Run integration tests
- Deploy to staging
- Run smoke tests
- Deploy to production
By parallelizing the build and unit test stages for each microservice, the team reduced pipeline execution time from 30 minutes to 12 minutes.
# Simplified CI pipeline snippet for parallel builds
jobs:
build-service-a:
runs-on: ubuntu-latest
steps:
- run: ./build.sh service-a
build-service-b:
runs-on: ubuntu-latest
steps:
- run: ./build.sh service-b
test-service-a:
needs: build-service-a
steps:
- run: ./test.sh service-a
test-service-b:
needs: build-service-b
steps:
- run: ./test.sh service-b
Efficient Resource Utilization
Best Practice: Use containerization and cloud-native orchestration to dynamically allocate resources based on workload demands.
Example:
Using Kubernetes, the deployment pipeline spins up ephemeral pods for build and test jobs. Resource requests and limits are configured to prevent over-provisioning and ensure fair resource sharing.
apiVersion: batch/v1
kind: Job
metadata:
name: build-job
spec:
template:
spec:
containers:
- name: builder
image: build-image:latest
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
restartPolicy: Never
Parallelism and Concurrency
Best Practice: Identify independent tasks and run them concurrently to maximize throughput.
Example:
In a backend system with multiple independent modules, tests are grouped by module and executed in parallel test runners, reducing test phase duration significantly.
Mind Map: Parallelism in Deployment Pipelines
Incremental and Partial Deployments
Best Practice: Deploy only components that have changed instead of the entire system.
Example:
A backend platform uses Git commit analysis and artifact hashing to detect which microservices have changed. Only those services are rebuilt and redeployed, reducing deployment time from 20 minutes to 5 minutes.
Rollback Speed
Best Practice: Use deployment strategies like blue-green or canary deployments that enable near-instant rollback without downtime.
Example:
A blue-green deployment setup maintains two identical production environments. New releases are deployed to the inactive environment, tested, and then traffic is switched over. If issues arise, switching back is immediate.
flowchart LR
A[Current Production] -->|Traffic| B[Users]
C[New Release] --> D[Idle Environment]
D -->|Test & Verify| E[Ready for Switch]
E -->|Switch Traffic| B
E -->|Rollback| A
Monitoring and Feedback Loops
Best Practice: Integrate real-time monitoring and alerting into the deployment pipeline to detect performance degradation or failures early.
Example:
The deployment pipeline pushes metrics to Prometheus and triggers alerts via PagerDuty if deployment time exceeds thresholds or if health checks fail post-deployment.
Summary
Performance considerations in deployment automation are crucial for maintaining agility and reliability in enterprise backend systems. By optimizing pipeline execution time, efficiently utilizing resources, leveraging parallelism, adopting incremental deployments, ensuring fast rollbacks, and integrating robust monitoring, teams can achieve high-performance deployment automation that supports rapid innovation without sacrificing stability.
12. Case Studies and Real-World Applications
12.1 Case Study: Scalable E-Commerce Backend Architecture
Overview
In this case study, we explore the design and implementation of a scalable backend architecture for a modern e-commerce platform. The platform must handle millions of users, support high transaction volumes, and provide a seamless shopping experience with low latency.
Key Requirements
- High availability: 24/7 uptime with minimal downtime.
- Scalability: Ability to handle traffic spikes during sales or holidays.
- Performance: Fast response times for browsing, searching, and checkout.
- Data consistency: Accurate inventory and order processing.
- Security: Protect customer data and payment information.
Architecture Overview Mind Map
Architectural Pattern: Microservices
To achieve scalability and maintainability, the backend is decomposed into microservices, each responsible for a specific domain:
- User Service: Handles authentication (OAuth2), user profiles, and sessions.
- Product Service: Manages product data, inventory, and search indexing.
- Cart Service: Maintains user carts, supports add/remove items.
- Order Service: Processes orders, payment confirmation, and status updates.
- Payment Service: Integrates with external payment gateways.
Each service communicates asynchronously using an event-driven approach with message queues (e.g., Kafka or RabbitMQ) to decouple services and improve resilience.
Example: Product Service - Inventory Update Flow
User places an order -> Order Service validates order -> Order Service publishes "OrderPlaced" event -> Product Service listens to "OrderPlaced" event -> Product Service updates inventory atomically -> Product Service publishes "InventoryUpdated" event -> Notification Service sends confirmation to user
This asynchronous event-driven flow ensures eventual consistency and allows independent scaling of services.
Data Storage Strategy
- Product and Inventory: Stored in a NoSQL database (e.g., MongoDB) for flexible schema and fast reads.
- Orders: Stored in a relational database (e.g., PostgreSQL) to ensure ACID properties.
- Caching: Redis is used to cache frequently accessed data such as product details and user sessions.
Performance Optimization Techniques
- API Gateway: Centralized entry point with request routing, authentication, and rate limiting.
- Load Balancing: Distributes incoming traffic across multiple service instances.
- Database Sharding: Horizontal partitioning of order data to distribute load.
- Asynchronous Processing: Heavy tasks (e.g., sending emails) are handled asynchronously.
Mind Map: Performance Optimization
Security Best Practices
- Use HTTPS for all communications.
- Implement OAuth2 for secure authentication.
- Encrypt sensitive data at rest and in transit.
- Apply role-based access control (RBAC) within services.
- Regularly audit logs and monitor for suspicious activities.
Example Code Snippet: Securing a Microservice Endpoint (Node.js/Express)
const express = require('express');
const jwt = require('jsonwebtoken');
const app = express();
// Middleware to verify JWT token
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, process.env.ACCESS_TOKEN_SECRET, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
app.get('/api/products', authenticateToken, (req, res) => {
// Fetch and return products
res.json({ products: [] });
});
app.listen(3000);
Monitoring and Observability
- Use centralized logging (e.g., ELK stack) to aggregate logs from all services.
- Implement distributed tracing (e.g., OpenTelemetry) to track requests across microservices.
- Set up metrics dashboards (e.g., Prometheus + Grafana) to monitor system health and performance.
Summary
This case study demonstrates how combining microservices, event-driven architecture, and best practices in security, data management, and performance engineering can build a robust, scalable e-commerce backend. The modular design allows independent scaling and deployment, while asynchronous communication ensures resilience and responsiveness.
Further Reading
- “Building Microservices” by Sam Newman
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Official documentation for Kafka, Redis, and OAuth2
By integrating these patterns and practices, senior engineers and technical leads can architect enterprise-grade e-commerce backends that meet demanding business and technical requirements.
12.2 Case Study: Financial Services Platform with Event-Driven Design
Introduction
In this case study, we explore how a financial services platform leveraged an event-driven architecture (EDA) to achieve high scalability, resilience, and real-time processing capabilities. The platform supports critical operations such as transaction processing, fraud detection, account management, and regulatory reporting.
Background and Challenges
- Legacy monolithic system struggled with scaling during peak trading hours.
- Difficulty in integrating new features without downtime.
- Real-time fraud detection required immediate reaction to suspicious events.
- Regulatory compliance demanded accurate audit trails and event histories.
Why Event-Driven Architecture?
Event-driven design enables asynchronous communication between decoupled components, allowing the system to react to business events in near real-time.
Key benefits:
- Loose coupling for easier maintenance and feature addition.
- Scalability by distributing event processing across multiple consumers.
- Improved fault tolerance through event replay and durable event storage.
High-Level Architecture Mind Map
Core Components and Their Roles
Event Producers
- Transaction Service: Emits events like
TransactionInitiated,TransactionCompleted, andTransactionFailed. - Account Management Service: Emits events such as
AccountCreated,AccountUpdated, andAccountClosed. - Fraud Detection Service: Emits alerts like
FraudSuspicionRaised.
Event Broker
- Utilizes Apache Kafka for high-throughput, durable event streaming.
- Ensures ordered event delivery and supports partitioning for scalability.
Event Consumers
- Audit Logging Service: Listens to all events to maintain an immutable audit trail.
- Notification Service: Sends real-time alerts to customers based on event triggers.
- Regulatory Reporting Service: Aggregates events for compliance reporting.
- Real-time Analytics Engine: Processes event streams to detect anomalies and trends.
Event Flow Example: Transaction Processing
- User initiates a transaction.
- Transaction Service validates and emits
TransactionInitiatedevent. - Fraud Detection Service consumes the event, analyzes risk, and if suspicious, emits
FraudSuspicionRaised. - If no fraud, Transaction Service completes the transaction and emits
TransactionCompleted. - Audit Logging Service records all events.
- Notification Service sends confirmation to the user.
- Regulatory Reporting Service updates compliance records.
Example Code Snippet: Emitting an Event (Node.js with Kafka)
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'transaction-service',
brokers: ['kafka-broker1:9092', 'kafka-broker2:9092']
});
const producer = kafka.producer();
async function emitTransactionInitiated(transaction) {
await producer.connect();
await producer.send({
topic: 'transactions',
messages: [
{
key: transaction.id,
value: JSON.stringify({
eventType: 'TransactionInitiated',
data: transaction,
timestamp: new Date().toISOString()
})
}
]
});
await producer.disconnect();
}
// Usage
const transaction = { id: 'txn123', amount: 1000, currency: 'USD', accountId: 'acc456' };
emitTransactionInitiated(transaction);
Best Practices Applied
- Event Schema Design: Used versioned JSON schemas to ensure backward compatibility.
- Idempotency: Consumers designed to handle duplicate events gracefully.
- Event Sourcing: Stored all state changes as events to enable auditability and state reconstruction.
- Monitoring: Implemented metrics on event lag, processing time, and error rates.
- Security: Enforced encryption on event data in transit and at rest.
Performance and Scalability Considerations
- Partitioned Kafka topics by account ID to distribute load evenly.
- Employed consumer groups for parallel processing.
- Used asynchronous processing to avoid blocking critical paths.
- Applied backpressure handling to prevent event broker overload.
Mind Map: Event-Driven Fraud Detection Workflow
Lessons Learned
- Transitioning from a monolith to EDA required cultural and organizational changes.
- Comprehensive testing strategies, including contract testing, were critical.
- Observability tools were essential to trace event flows and diagnose issues.
- Eventual consistency models required careful design of user experience and data views.
Conclusion
This financial services platform successfully leveraged event-driven architecture to meet demanding requirements for scalability, responsiveness, and compliance. By decoupling components and embracing asynchronous event flows, the platform achieved a flexible and maintainable backend capable of evolving with business needs.
12.3 Case Study: High Throughput API Gateway for SaaS Products
Introduction
In modern SaaS architectures, the API Gateway plays a pivotal role as the single entry point for all client requests. It manages authentication, routing, rate limiting, caching, and more, all while maintaining high throughput and low latency. This case study explores the design and implementation of a high-performance API Gateway tailored for a SaaS product serving millions of users.
Objectives and Challenges
- Handle millions of requests per minute with minimal latency
- Support multi-tenant architecture ensuring tenant isolation
- Provide robust security including authentication and authorization
- Enable scalable routing to microservices
- Implement rate limiting and throttling per tenant and user
- Support API versioning and dynamic configuration without downtime
Architectural Overview
Key Components and Patterns
| Component | Description | Example Implementation |
|---|---|---|
| Authentication | OAuth2 with JWT tokens for stateless, scalable auth | Using oauth2-proxy and JWT validation |
| Routing | Dynamic routing based on tenant and API version | Envoy proxy with custom routing rules |
| Rate Limiting | Token bucket algorithm per tenant/user | Redis-backed rate limiter |
| Caching | Response caching for idempotent GET requests | In-memory cache with TTL (e.g., Redis, Memcached) |
| Load Balancing | Round-robin or least connections to backend microservices | Envoy or NGINX load balancing |
| Monitoring | Metrics collection and distributed tracing | Prometheus + Jaeger integration |
Example: Implementing Rate Limiting with Redis
import time
import redis
class RateLimiter:
def __init__(self, redis_client, max_requests, window_seconds):
self.redis = redis_client
self.max_requests = max_requests
self.window = window_seconds
def is_allowed(self, key):
current_time = int(time.time())
window_key = f"rate_limit:{key}:{current_time // self.window}"
count = self.redis.get(window_key)
if count and int(count) >= self.max_requests:
return False
pipe = self.redis.pipeline()
pipe.incr(window_key, 1)
pipe.expire(window_key, self.window)
pipe.execute()
return True
# Usage
redis_client = redis.Redis(host='localhost', port=6379)
rate_limiter = RateLimiter(redis_client, max_requests=1000, window_seconds=60)
user_key = "tenant123:user456"
if rate_limiter.is_allowed(user_key):
print("Request allowed")
else:
print("Rate limit exceeded")
This example uses a sliding window rate limiter implemented with Redis. It ensures each tenant/user cannot exceed 1000 requests per minute.
Example: Dynamic Routing Configuration with Envoy
static_resources:
listeners:
- name: listener_0
address:
socket_address:
address: 0.0.0.0
port_value: 8080
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: tenant1_service
domains: ["tenant1.example.com"]
routes:
- match: { prefix: "/v1/" }
route: { cluster: tenant1_service_v1 }
- match: { prefix: "/v2/" }
route: { cluster: tenant1_service_v2 }
http_filters:
- name: envoy.filters.http.router
clusters:
- name: tenant1_service_v1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: tenant1_service_v1
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: tenant1-service-v1.internal
port_value: 8081
- name: tenant1_service_v2
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: tenant1_service_v2
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: tenant1-service-v2.internal
port_value: 8082
This Envoy config routes requests based on tenant domain and API version prefix, enabling zero-downtime API version rollouts.
Performance Optimization Techniques
- Connection Pooling: Reuse backend connections to reduce latency.
- Asynchronous Processing: Use non-blocking IO for handling requests.
- Caching: Cache frequent GET responses and authentication tokens.
- Load Shedding: Reject or queue requests under extreme load to maintain stability.
- Circuit Breakers: Prevent cascading failures by isolating failing services.
Monitoring and Observability
Using tools like Prometheus for metrics, Jaeger for tracing, and ELK stack for logs, the API Gateway team can proactively detect and resolve performance issues.
Summary
This case study demonstrated how to design and implement a high throughput API Gateway for SaaS products by combining architectural patterns, best practices, and practical examples. Key takeaways include:
- Leveraging dynamic routing and multi-tenancy support
- Implementing rate limiting and security at the gateway layer
- Using caching and load balancing to optimize performance
- Employing observability tools for monitoring and troubleshooting
By following these principles, technical leads and senior engineers can build scalable, secure, and performant API gateways that serve as the backbone of modern SaaS platforms.
12.4 Lessons Learned and Best Practices from Industry Leaders
Enterprise software architecture and high-performance backend engineering are complex domains where experience from industry leaders provides invaluable insights. This section distills key lessons learned and best practices, supported by real-world examples and mind maps to help senior engineers and technical leads apply these principles effectively.
Embrace Modularity and Loose Coupling
Lesson: Industry leaders emphasize modular design to improve maintainability, scalability, and team autonomy.
Best Practice: Design services and components with well-defined interfaces and minimal dependencies.
Example: Netflix’s microservices architecture allows independent deployment and scaling of components like user management, recommendations, and streaming.
Prioritize Observability from Day One
Lesson: Companies like Uber and LinkedIn have shown that observability is critical for diagnosing issues and optimizing performance in complex systems.
Best Practice: Implement structured logging, distributed tracing, and metrics collection as integral parts of the architecture.
Example: Uber’s Jaeger tracing system enables pinpointing latency bottlenecks across microservices.
Design for Failure and Resilience
Lesson: Amazon’s “Chaos Monkey” practice highlights the importance of designing systems that expect and gracefully handle failures.
Best Practice: Use circuit breakers, retries with exponential backoff, and fallback mechanisms.
Example: Netflix’s Hystrix library implements circuit breakers to prevent cascading failures.
Optimize Data Management with Scalability in Mind
Lesson: Google’s Spanner and Facebook’s Cassandra demonstrate that choosing the right data architecture is key to balancing consistency, availability, and partition tolerance.
Best Practice: Use polyglot persistence, sharding, and caching appropriately.
Example: Facebook uses Cassandra for write-heavy workloads with eventual consistency, while using MySQL for relational data.
Automate CI/CD and Embrace DevOps Culture
Lesson: Etsy and Google have shown that continuous integration and deployment pipelines reduce time to market and improve software quality.
Best Practice: Automate testing, deployment, and rollback processes; foster collaboration between development and operations teams.
Example: Google’s Borg system automates deployment at massive scale with built-in health checks and rollbacks.
Focus on API Design and Backward Compatibility
Lesson: Twitter and Stripe stress the importance of stable, well-documented APIs to enable ecosystem growth and internal team productivity.
Best Practice: Version APIs carefully, use semantic versioning, and provide clear deprecation paths.
Example: Stripe maintains backward compatibility for years to avoid breaking client integrations.
Invest in Performance Profiling and Load Testing
Lesson: LinkedIn and Pinterest leverage extensive profiling and load testing to identify bottlenecks before production issues arise.
Best Practice: Use profiling tools to analyze CPU, memory, and I/O; simulate realistic traffic patterns.
Example: LinkedIn’s use of Apache JMeter for load testing their backend services ensures reliability during peak usage.
Summary Table of Lessons and Examples
| Lesson | Industry Leader | Example Tool/Practice |
|---|---|---|
| Modularity & Loose Coupling | Netflix | Microservices, DDD |
| Observability | Uber | Jaeger, ELK Stack |
| Resilience & Failure Handling | Netflix | Hystrix |
| Data Management | Facebook, Google | Cassandra, Spanner |
| CI/CD & DevOps | Google, Etsy | Borg, Jenkins, Spinnaker |
| API Design | Stripe, Twitter | Semantic Versioning, Docs |
| Performance Engineering | JMeter, Profiling Tools |
By integrating these lessons and best practices, senior engineers and technical leads can architect enterprise backends that are scalable, resilient, maintainable, and performant—meeting the demanding needs of modern business applications.
12.5 Future Trends in Enterprise Architecture and Backend Engineering
As enterprise software systems evolve, so do the architectural paradigms and backend engineering practices that power them. Staying ahead of these trends is crucial for senior software engineers and technical leads aiming to build scalable, maintainable, and high-performance systems.
Increasing Adoption of AI-Driven Architecture
Artificial Intelligence (AI) and Machine Learning (ML) are no longer just application features but are becoming integral to architecture decisions and backend operations.
- AI-assisted design: Automated architecture validation and optimization using AI tools.
- Predictive scaling: ML models predict load and trigger autoscaling proactively.
- Self-healing systems: AI-driven anomaly detection and automatic remediation.
Example: Netflix uses AI to predict traffic spikes and optimize resource allocation dynamically, reducing latency and cost.
Serverless and Function-as-a-Service (FaaS) Expansion
Serverless architectures continue to gain traction for their scalability and cost-efficiency.
- Event-driven backend: Functions triggered by events enable granular scaling.
- Reduced operational overhead: No server management, focusing on code.
- Challenges: Cold start latency, debugging complexity.
Example: An e-commerce platform uses AWS Lambda functions for payment processing and inventory updates, scaling automatically during flash sales.
Edge Computing Integration
Bringing computation closer to data sources reduces latency and bandwidth usage.
- Hybrid architecture: Combining cloud and edge nodes for optimized performance.
- Use cases: IoT, real-time analytics, AR/VR applications.
Example: A logistics company processes sensor data at edge gateways to provide near real-time tracking without relying solely on cloud roundtrips.
Enhanced Observability with AI and Automation
Observability is evolving from reactive monitoring to proactive system intelligence.
- AI-powered anomaly detection: Identifies subtle performance degradations.
- Automated root cause analysis: Speeds up incident resolution.
- Self-optimizing systems: Feedback loops adjust configurations automatically.
Example: Google’s Site Reliability Engineering (SRE) teams leverage AI tools to detect and resolve incidents before customers notice.
Evolution of API Architectures: GraphQL and Beyond
APIs are becoming more flexible and efficient.
- GraphQL adoption: Enables clients to request exactly the data they need.
- API composition: Aggregating multiple microservices behind unified APIs.
- API mesh: Managing API traffic with observability, security, and routing.
Example: A SaaS provider uses GraphQL to reduce over-fetching and improve frontend performance across multiple client platforms.
Increased Focus on Data Mesh and Decentralized Data Ownership
Data architectures are shifting from centralized lakes to domain-oriented decentralized models.
- Data as a product: Domains own and serve their data.
- Self-serve data infrastructure: Teams can publish and consume data independently.
Example: A multinational bank implements a data mesh to empower regional teams with autonomy while maintaining governance.
Quantum Computing Exploration
Though nascent, quantum computing promises to revolutionize backend processing for specific workloads.
- Hybrid classical-quantum architectures: Offloading specialized tasks.
- Potential use cases: Cryptography, optimization problems, complex simulations.
Example: Research teams at enterprises experiment with quantum algorithms for portfolio optimization in finance.
Sustainability and Green Software Engineering
Environmental impact is becoming a key consideration in architecture and backend design.
- Energy-efficient algorithms and infrastructure choices.
- Carbon-aware scheduling: Running workloads when renewable energy is abundant.
Example: A cloud provider offers carbon footprint dashboards and incentives for green computing practices.
Mind Map: Future Trends Overview
Mind Map: AI-Driven Backend Engineering Details
Summary
The future of enterprise software architecture and backend engineering is shaped by the convergence of AI, serverless paradigms, edge computing, and evolving data strategies. Technical leads should embrace these trends by fostering continuous learning, experimenting with new technologies, and designing systems that are resilient, scalable, and sustainable.
Call to Action
- Start small by integrating AI-powered monitoring tools.
- Experiment with serverless functions for non-critical workloads.
- Explore edge computing use cases relevant to your domain.
- Advocate for sustainable engineering practices within your teams.
By proactively adopting these future trends, you position your enterprise systems for long-term success and innovation.
13. Conclusion and Next Steps
13.1 Recap of Key Patterns and Practices
In this section, we revisit the essential enterprise software architecture patterns and high-performance backend engineering practices covered throughout this blog. The goal is to consolidate your understanding and provide a quick reference to apply these concepts effectively.
Mind Map: Overview of Enterprise Architecture Patterns
Layered Architecture Recap
- Best Practice: Maintain strict separation between presentation, business logic, and data access layers to improve maintainability.
- Example: In a retail enterprise app, the UI layer handles user input, the service layer processes orders, and the repository layer manages database interactions.
- Performance Tip: Minimize synchronous calls across layers to reduce latency.
Microservices Recap
- Best Practice: Define services around business capabilities using Domain-Driven Design’s bounded contexts.
- Example: An e-commerce platform splits inventory, payment, and shipping into separate microservices communicating asynchronously via message queues.
- Performance Tip: Use asynchronous messaging (e.g., Kafka, RabbitMQ) to decouple services and improve throughput.
Event-Driven Architecture Recap
- Best Practice: Use event sourcing to capture state changes as immutable events, enabling auditability and replay.
- Example: An order processing system emits events like
OrderCreated,PaymentProcessed, andOrderShippedto update downstream systems. - Performance Tip: Optimize event brokers and partition event streams to handle high throughput.
Domain-Driven Design (DDD) Recap
- Best Practice: Collaborate closely with domain experts to model complex business logic accurately.
- Example: In a banking system, define aggregates like
AccountandTransactionencapsulating business rules. - Performance Tip: Keep aggregates small to avoid contention and improve concurrency.
API-First Design Recap
- Best Practice: Design APIs before implementation to ensure consistency and consumer-first thinking.
- Example: Use OpenAPI specifications to define REST endpoints for a customer management system.
- Performance Tip: Implement caching headers and pagination to reduce load and improve response times.
Data Management Recap
- Best Practice: Choose the right database technology based on use case (e.g., relational for transactions, NoSQL for flexible schemas).
- Example: Use Cassandra for time-series data storage in an IoT platform, while using PostgreSQL for user data.
- Performance Tip: Apply data sharding and caching layers (e.g., Redis) to scale read/write operations.
Performance Engineering Recap
- Best Practice: Continuously profile and benchmark backend components to identify bottlenecks.
- Example: Use tools like JProfiler or Perf to analyze CPU and memory usage in a payment processing backend.
- Performance Tip: Optimize thread pools and database connection pools to handle concurrent loads efficiently.
Security Patterns Recap
- Best Practice: Implement robust authentication and authorization mechanisms, leveraging standards like OAuth2 and JWT.
- Example: Secure microservices by validating JWT tokens issued by a centralized identity provider.
- Performance Tip: Balance security checks with caching token validations to minimize overhead.
Observability Recap
- Best Practice: Instrument services with structured logging, metrics, and distributed tracing for end-to-end visibility.
- Example: Use OpenTelemetry to trace requests across microservices and identify latency hotspots.
- Performance Tip: Aggregate logs and metrics asynchronously to avoid impacting service responsiveness.
CI/CD Recap
- Best Practice: Automate build, test, and deployment pipelines to enable rapid and reliable releases.
- Example: Implement blue-green deployments to minimize downtime during backend updates.
- Performance Tip: Integrate performance tests into CI pipelines to catch regressions early.
Summary
By combining these architecture patterns and engineering practices, senior software engineers and technical leads can design enterprise backend systems that are scalable, maintainable, secure, and performant. The examples provided throughout this blog serve as practical guides to applying these concepts in real-world scenarios.
Remember, the key to success lies in understanding your domain deeply, choosing appropriate patterns thoughtfully, and continuously measuring and optimizing your systems.
13.2 Building Your Own High Performance Enterprise Backend
Building a high performance enterprise backend requires a thoughtful combination of architecture patterns, best practices, and engineering disciplines. This section guides you through the essential steps, considerations, and examples to design and implement a backend system that is scalable, maintainable, and performant.
Step 1: Define Clear Requirements and Non-Functional Goals
Before diving into code or architecture, clarify the functional requirements and especially the non-functional requirements such as:
- Scalability (horizontal/vertical)
- Latency targets
- Throughput expectations
- Availability and fault tolerance
- Security and compliance
Example: For an e-commerce platform, you might require the backend to handle 10,000 concurrent users with sub-200ms API response times during peak traffic.
Step 2: Choose the Right Architecture Pattern
Selecting an architecture pattern that aligns with your requirements is critical.
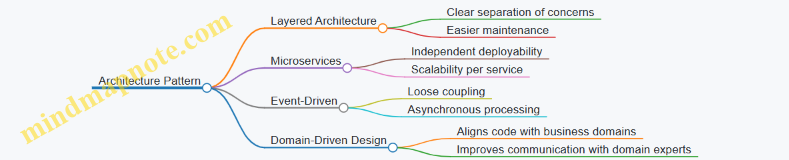
Example: For a complex domain with multiple bounded contexts, a microservices architecture combined with Domain-Driven Design (DDD) is often effective.
Step 3: Design Your Data Management Strategy
Data is the backbone of enterprise systems. Consider:
- Database selection (SQL, NoSQL, NewSQL)
- Data partitioning and sharding
- Caching layers
- Consistency and availability trade-offs
Example: Use Redis as a caching layer to reduce read latency for frequently accessed product catalog data.
Step 4: Implement API-First Design
Design APIs before implementation to ensure clear contracts and better collaboration.
- Use OpenAPI/Swagger for REST APIs
- Consider GraphQL for flexible querying
- Define versioning strategy upfront
Example: Define a RESTful API for user management with endpoints like /users, /users/{id}, supporting pagination and filtering.
Step 5: Optimize for Performance from the Start
Incorporate performance considerations early:
- Use asynchronous processing where possible
- Employ connection pooling
- Optimize database queries with indexes and query plans
- Implement batching and throttling
Example: In a payment processing microservice, use message queues (e.g., Kafka) to asynchronously handle transaction validation, improving throughput.
Step 6: Ensure Security and Compliance
Security must be integral:
- Use OAuth2 and JWT for authentication and authorization
- Encrypt sensitive data at rest and in transit
- Validate inputs to prevent injection attacks
Example: Secure APIs with JWT tokens and implement rate limiting to prevent abuse.
Step 7: Build Observability and Monitoring
Make your backend observable to detect and resolve issues quickly:
- Structured logging
- Metrics collection (Prometheus, Grafana)
- Distributed tracing (OpenTelemetry)
Example: Implement distributed tracing to track a user request flowing through multiple microservices.
Step 8: Automate CI/CD Pipelines
Automate testing, building, and deployment to ensure reliability and speed:
- Unit, integration, and load testing
- Canary and blue-green deployments
- Rollback mechanisms
Example: Use Jenkins or GitHub Actions to run tests and deploy microservices to Kubernetes clusters automatically.
Step 9: Continuously Profile and Optimize
Regularly profile your backend to identify bottlenecks:
- Use profilers (e.g., YourKit, JProfiler)
- Analyze database slow queries
- Monitor thread and resource usage
Example: After deployment, identify a slow API endpoint caused by an unindexed database column and add the necessary index.
Summary Mind Map
Final Example: Building a Simple High-Performance Order Service
Scenario: An order service in a retail system that must handle high throughput with low latency.
- Architecture: Microservice with event-driven communication
- Data: PostgreSQL for transactional data, Redis for caching recent orders
- API: RESTful API with OpenAPI spec
- Performance: Asynchronous order validation via Kafka
- Security: OAuth2 for API access
- Observability: Centralized logging and distributed tracing
Code snippet (simplified Node.js/Express):
const express = require('express');
const { Kafka } = require('kafkajs');
const redis = require('redis');
const app = express();
app.use(express.json());
const kafka = new Kafka({ clientId: 'order-service', brokers: ['kafka:9092'] });
const producer = kafka.producer();
const redisClient = redis.createClient();
app.post('/orders', async (req, res) => {
const order = req.body;
// Save order to DB (pseudo-code)
await saveOrderToDB(order);
// Cache order
await redisClient.set(`order:${order.id}`, JSON.stringify(order));
// Send event for async processing
await producer.send({
topic: 'order-validation',
messages: [{ value: JSON.stringify(order) }],
});
res.status(201).send({ message: 'Order received', orderId: order.id });
});
app.listen(3000, () => console.log('Order service running on port 3000'));
This example demonstrates asynchronous processing, caching, and a clean API interface, foundational for a high performance backend.
By following these steps and continuously iterating based on real-world feedback and metrics, you can build enterprise backend systems that meet demanding performance and scalability requirements while remaining maintainable and secure.
13.3 Recommended Tools and Frameworks
In the realm of enterprise software architecture and high-performance backend engineering, selecting the right tools and frameworks is crucial for building scalable, maintainable, and efficient systems. Below, we explore a curated list of recommended tools and frameworks organized by categories, along with mind maps to visualize their relationships and practical examples demonstrating their usage.
Backend Frameworks
- Spring Boot (Java): Widely used for building microservices and enterprise applications with extensive ecosystem support.
- Express.js (Node.js): Minimalist framework for building fast and scalable APIs.
- ASP.NET Core (C#): Cross-platform, high-performance framework for building modern backend services.
- Django (Python): Batteries-included framework for rapid development with ORM and admin interface.
Example:
// Spring Boot REST Controller Example
@RestController
@RequestMapping("/api/products")
public class ProductController {
@GetMapping("/{id}")
public ResponseEntity<Product> getProduct(@PathVariable Long id) {
Product product = productService.findById(id);
return ResponseEntity.ok(product);
}
}
API Design & Management
- Swagger / OpenAPI: For API documentation and design-first development.
- GraphQL (Apollo Server, Graphene): Flexible query language for APIs.
- Kong / Apigee / AWS API Gateway: API gateways for routing, security, and rate limiting.
Example:
# OpenAPI snippet for a GET /users endpoint
paths:
/users:
get:
summary: Get list of users
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/User'
Messaging & Event Streaming
- Apache Kafka: Distributed event streaming platform.
- RabbitMQ: Robust message broker supporting multiple protocols.
- AWS SNS/SQS: Managed pub/sub and queue services.
Example:
// Kafka Producer example in Java
Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("orders", "order123", "Order Created");
producer.send(record);
producer.close();
Databases & Data Stores
- Relational Databases: PostgreSQL, MySQL, Oracle
- NoSQL Databases: MongoDB, Cassandra, Redis
- NewSQL: CockroachDB, Google Spanner
Example:
# MongoDB query example using PyMongo
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
db = client['enterprise_db']
users = db.users.find({'status': 'active'})
for user in users:
print(user)
Containerization & Orchestration
- Docker: Containerization platform.
- Kubernetes: Container orchestration for scaling and management.
- Helm: Kubernetes package manager.
Example:
# Kubernetes Deployment snippet
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-service
spec:
replicas: 3
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend-container
image: myorg/backend:latest
ports:
- containerPort: 8080
Monitoring & Observability
- Prometheus: Metrics collection and alerting.
- Grafana: Visualization dashboard.
- Jaeger / Zipkin: Distributed tracing.
- ELK Stack (Elasticsearch, Logstash, Kibana): Centralized logging.
Example:
# Prometheus scrape config snippet
scrape_configs:
- job_name: 'backend-service'
static_configs:
- targets: ['backend-service:8080']
CI/CD Tools
- Jenkins: Popular automation server.
- GitLab CI/CD: Integrated pipelines with GitLab.
- CircleCI / Travis CI: Cloud-based CI/CD services.
- ArgoCD: GitOps continuous delivery for Kubernetes.
Example:
# GitLab CI pipeline snippet
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- ./gradlew build
test_job:
stage: test
script:
- ./gradlew test
deploy_job:
stage: deploy
script:
- kubectl apply -f deployment.yaml
Mind Maps
Mind Map 1: Enterprise Backend Tooling Overview
Mind Map 2: Messaging & Event Streaming Ecosystem
Mind Map 3: Observability Stack
Summary
Choosing the right combination of tools and frameworks depends on your enterprise architecture goals, team expertise, and system requirements. The above recommendations provide a strong foundation for building high-performance, scalable, and maintainable backend systems. Leveraging these tools effectively, combined with best practices and architectural patterns, empowers technical leads and senior engineers to deliver robust enterprise solutions.
13.4 Continuing Education and Community Resources
As senior software engineers and technical leads, staying current with evolving enterprise software architecture patterns and high-performance backend engineering techniques is crucial. Continuous learning not only sharpens your skills but also empowers you to lead your teams effectively and innovate in complex enterprise environments.
Online Learning Platforms and Courses
- Coursera: Offers courses from top universities on software architecture, microservices, and backend engineering.
- Example: “Microservices Specialization” by University of Colorado
- Pluralsight: Deep dives into architecture patterns, performance tuning, and cloud-native backend development.
- Example: “Enterprise Architecture Fundamentals”
- Udemy: Practical courses with hands-on labs.
- Example: “Backend Development with Node.js and Microservices”
Books and Publications
- “Patterns of Enterprise Application Architecture” by Martin Fowler
- “Domain-Driven Design” by Eric Evans
- “Building Microservices” by Sam Newman
- “Designing Data-Intensive Applications” by Martin Kleppmann
Conferences and Workshops
- QCon: Enterprise software architecture and backend engineering tracks.
- O’Reilly Software Architecture Conference
- Devoxx, GOTO Conferences: Focus on microservices, cloud, and performance engineering.
Community Forums and Discussion Groups
- Stack Overflow: For problem-solving and peer support.
- Reddit r/softwarearchitecture, r/microservices
- LinkedIn Groups: Enterprise Architecture, Backend Engineering
- Dev.to and Medium: Articles and discussions by industry experts
Open Source Projects and GitHub Repositories
Engaging with open source projects helps you learn real-world applications of architecture patterns and performance optimizations.
- Example: Spring Cloud for microservices
- Example: Apache Kafka for event-driven architecture
Mind Maps for Learning Paths
Mind Map: Enterprise Software Architecture Learning Path
Mind Map: Backend Performance Optimization
Mind Map: Microservices Best Practices
Example: Leveraging Community Resources for Skill Growth
Scenario: You want to improve your expertise in event-driven architecture.
- Start with an online course on Coursera or Pluralsight focused on event-driven systems.
- Read Martin Kleppmann’s “Designing Data-Intensive Applications” to understand event sourcing and stream processing.
- Join Reddit’s r/microservices and participate in discussions about event-driven patterns.
- Explore Apache Kafka’s GitHub repo and contribute to documentation or small bug fixes.
- Attend a webinar or conference session on event-driven architecture.
- Use profiling tools to analyze your event-driven application’s performance.
Summary
Continuing education and active participation in community resources are vital for mastering enterprise software architecture and backend engineering. By combining structured learning, community engagement, and hands-on experimentation, you can stay ahead in this fast-evolving field and drive impactful technical leadership.
13.5 Final Thoughts and Encouragement for Technical Leads
As a Technical Lead in enterprise software engineering, you stand at the crossroads of technology, architecture, and team leadership. The journey through mastering enterprise software architecture patterns and high-performance backend engineering is ongoing and filled with challenges—but also immense opportunities to drive impactful change.
Embrace Continuous Learning and Adaptability
The technology landscape evolves rapidly. Staying current with emerging architecture patterns, backend technologies, and performance optimization techniques is essential. Encourage your team to adopt a growth mindset and foster a culture of continuous learning.
Example:
- Organize regular knowledge-sharing sessions where team members present new tools or patterns they’ve explored.
- Experiment with new technologies in small, low-risk projects before full adoption.
Lead by Example with Best Practices
Your leadership sets the tone for code quality, architectural discipline, and performance consciousness.
Example:
- When reviewing code, highlight not only correctness but also architectural alignment and performance implications.
- Advocate for automated testing, CI/CD pipelines, and observability as non-negotiable elements.
Foster Collaboration Between Domains
Enterprise systems are complex and cross-functional. Bridging communication between domain experts, architects, developers, and operations is critical.
Example:
- Use Domain-Driven Design (DDD) workshops to align technical and business teams on ubiquitous language and bounded contexts.
- Encourage cross-team design reviews to uncover hidden dependencies and performance bottlenecks early.
Prioritize Scalability and Performance Early
Incorporate performance considerations from the design phase rather than as an afterthought.
Example:
- Use asynchronous processing and event-driven patterns to decouple components and improve throughput.
- Design APIs with pagination, caching, and rate limiting to handle load gracefully.
Mind Map: Key Focus Areas for Technical Leads
Mind Map: Balancing Technical and Leadership Responsibilities
Encouragement: Your Impact is Multiplicative
Remember, your decisions ripple through the entire organization. By championing robust architecture and high-performance engineering, you empower your team to build reliable, scalable, and maintainable systems that drive business success.
Example:
- Introducing an event-driven architecture pattern reduced system latency by 40% and improved developer productivity by enabling independent service deployments.
Final Quote to Inspire
“Good architecture enables teams to innovate rapidly and deliver value consistently. As a Technical Lead, your vision and guidance are the keystones of that architecture. Lead boldly, learn continuously, and inspire relentlessly.”
By integrating these principles and mindset into your leadership approach, you will not only build high-performance backend systems but also cultivate a thriving engineering culture that adapts and excels in the face of evolving enterprise challenges.