High Concurrency Microservices Design with Event Driven Architecture and Observability
1. Introduction to High Concurrency in Microservices
1.1 Understanding High Concurrency: Concepts and Challenges
High concurrency refers to the ability of a system to handle a large number of simultaneous operations or requests efficiently without degradation in performance or reliability. In microservices architecture, achieving high concurrency is critical for building scalable, responsive, and resilient applications that serve many users or process many events in parallel.
Key Concepts of High Concurrency
-
Concurrency vs Parallelism:
- Concurrency is about managing multiple tasks at the same time, potentially by interleaving execution.
- Parallelism is about executing multiple tasks simultaneously, often leveraging multiple CPU cores.
-
Throughput: Number of requests or events processed per unit time.
-
Latency: Time taken to process a single request or event.
-
Scalability: Ability to maintain performance as load increases.
-
Resource Contention: When multiple tasks compete for limited resources like CPU, memory, or network.
-
Synchronization and Coordination: Managing access to shared resources to avoid race conditions or deadlocks.
Challenges in High Concurrency Systems
-
Race Conditions: When two or more operations access shared data and try to change it simultaneously.
-
Deadlocks: Circular waiting where two or more processes are waiting indefinitely for resources held by each other.
-
Thundering Herd Problem: Many processes waking up simultaneously to perform the same task, overwhelming the system.
-
Load Spikes and Bursts: Sudden surges in traffic that can overwhelm services.
-
Backpressure Handling: Preventing system overload by controlling the flow of incoming requests.
-
Data Consistency: Maintaining accurate and consistent data across distributed services.
-
Fault Tolerance: Ensuring system continues to operate despite failures.
Mind Map: Core Concepts of High Concurrency
Mind Map: Challenges in High Concurrency Systems
Example 1: Race Condition in a Shared Counter
Imagine a microservice that increments a shared counter stored in a database to track the number of orders placed. Two concurrent requests read the current value as 100, both increment it to 101, and write back 101. The counter should have been 102, but due to concurrent writes, it remains 101.
Solution: Use atomic operations or distributed locks to ensure increments are serialized.
Example 2: Thundering Herd Problem
A cache expires and many microservices simultaneously try to refresh the data by querying the database, causing a spike in load.
Solution: Implement request coalescing or use a locking mechanism so only one service refreshes the cache while others wait.
Example 3: Handling Load Spikes with Backpressure
During a flash sale, an order processing microservice receives thousands of requests per second. Without control, the service becomes overwhelmed and crashes.
Solution: Use message queues with rate limiting and backpressure strategies to buffer requests and process them at a sustainable rate.
Summary
Understanding the fundamental concepts and challenges of high concurrency is the foundation for designing robust microservices. Recognizing common pitfalls like race conditions, deadlocks, and load spikes enables engineers to apply appropriate design patterns and technologies to build scalable, resilient systems.
1.2 Why Microservices for High Concurrency Systems?
High concurrency systems demand architectures that can efficiently handle a massive number of simultaneous operations without bottlenecks or failures. Microservices architecture naturally aligns with these requirements by breaking down complex applications into smaller, independently deployable services that can scale and evolve autonomously.
Key Reasons Microservices Suit High Concurrency Systems
- Scalability: Each microservice can be scaled independently based on its load, allowing targeted resource allocation.
- Isolation and Fault Tolerance: Failures in one service don’t cascade, improving overall system resilience.
- Technology Diversity: Teams can choose the best technology stack per service, optimizing performance.
- Faster Development and Deployment: Smaller codebases enable quicker iterations and deployments.
- Optimized Resource Utilization: Services can be deployed on different hardware or cloud instances tailored to their workload.
Mind Map: Benefits of Microservices for High Concurrency
Example: Scaling an Online Video Streaming Platform
Imagine a video streaming platform with multiple microservices: User Management, Video Encoding, Content Delivery, and Recommendation Engine.
- During peak hours, the Content Delivery microservice experiences high concurrency due to many users streaming simultaneously.
- Instead of scaling the entire monolithic application, only the Content Delivery microservice is horizontally scaled across multiple instances.
- Meanwhile, the Recommendation Engine, which is less impacted by concurrency spikes, remains at its normal scale, saving resources.
This targeted scaling reduces costs and improves performance.
Mind Map: Microservices Scaling Example
Additional Best Practices Embedded in Microservices for High Concurrency
- Load Balancing: Distribute incoming requests evenly across service instances.
- Statelessness: Design services to be stateless where possible, simplifying scaling.
- Asynchronous Communication: Use event-driven messaging to decouple services and smooth out traffic spikes.
- Backpressure Handling: Implement mechanisms to prevent service overload.
Example: Stateless Order Processing Service
An order processing microservice handles thousands of concurrent orders. By keeping the service stateless and storing session data in a distributed cache, the service can spin up multiple instances without session affinity issues, enabling seamless scaling.
Mind Map: Best Practices for High Concurrency Microservices
Summary
Microservices architecture empowers high concurrency systems by enabling independent scaling, fault isolation, and flexible technology choices. Coupled with best practices like statelessness and asynchronous communication, microservices provide a robust foundation to meet demanding concurrency requirements efficiently.
1.3 Overview of Event Driven Architecture in Concurrency
Event Driven Architecture (EDA) is a design paradigm where services communicate through the production, detection, and reaction to events. In high concurrency microservices systems, EDA plays a pivotal role by enabling asynchronous, loosely coupled, and scalable interactions between services.
What is Event Driven Architecture?
At its core, EDA centers around events — discrete pieces of information that represent a change in state or an occurrence within a system. Instead of synchronous request-response calls, microservices emit events to notify other services about changes, enabling them to react independently and concurrently.
Why EDA is Suited for High Concurrency?
- Asynchronous Communication: Services don’t wait for immediate responses, allowing many operations to proceed in parallel.
- Loose Coupling: Services only need to know about event formats, not the internal workings of other services.
- Scalability: Event brokers can buffer and distribute events to multiple consumers, handling spikes in load gracefully.
- Resilience: Failures in one service do not block others; events can be retried or compensated.
Core Components of EDA in Concurrency
Event Flow in a High Concurrency Microservices System
Example: E-Commerce Order Processing
Imagine an e-commerce platform where thousands of users place orders concurrently. Using EDA:
- Order Service emits an
OrderPlacedevent when a new order is created. - Inventory Service listens for
OrderPlacedevents to reserve stock asynchronously. - Payment Service processes payments triggered by the same event.
- Notification Service sends confirmation emails once payment is successful.
This asynchronous event flow allows all services to process orders concurrently without blocking each other.
Best Practice: Designing Events for Concurrency
- Use Immutable Event Payloads: Events should represent facts that never change.
- Design Idempotent Consumers: Services should handle duplicate events gracefully.
- Partition Events by Key: To enable parallel processing without conflicts.
- Avoid Synchronous Dependencies: Keep event handlers independent to maximize concurrency.
Summary
Event Driven Architecture provides a robust foundation for building high concurrency microservices by enabling asynchronous, scalable, and loosely coupled communication. By carefully designing event flows and handlers, systems can efficiently handle massive concurrent workloads with resilience and flexibility.
1.4 Importance of Observability in High Concurrency Environments
In high concurrency microservices environments, where thousands or even millions of events and requests flow through distributed systems simultaneously, observability becomes a critical pillar for maintaining system health, performance, and reliability. Without proper observability, detecting, diagnosing, and resolving issues can become nearly impossible due to the complexity and asynchronous nature of event-driven architectures.
Why Observability Matters in High Concurrency Systems
- Complex Interactions: High concurrency environments involve multiple services interacting asynchronously, often with eventual consistency. Observability helps track these interactions end-to-end.
- Performance Bottlenecks: Identifying where latency or resource contention occurs requires detailed metrics and tracing.
- Failure Detection: Failures may cascade or be transient; observability enables early detection and root cause analysis.
- Capacity Planning: Understanding load patterns and resource utilization helps scale systems efficiently.
- Continuous Improvement: Observability data feeds feedback loops for optimizing system design and deployment.
Core Pillars of Observability in High Concurrency Microservices
Mind Map: Observability Challenges in High Concurrency Systems
Example: Observability in a High Concurrency Order Processing Microservice
Imagine an order processing microservice that handles thousands of orders per second, communicating with inventory, payment, and shipping services asynchronously via events.
- Metrics: Track orders received, processed, failed, and average processing time.
- Logs: Include structured logs with order IDs, event types, and timestamps.
- Traces: Use distributed tracing to follow an order event from receipt through inventory check, payment authorization, and shipping initiation.
This observability setup allows engineers to quickly identify if orders are stuck in a particular stage, if payment authorization is slowing down, or if inventory updates are failing.
Best Practices for Observability in High Concurrency Environments
-
Use Correlation IDs: Propagate unique identifiers through all events and service calls to correlate logs, metrics, and traces.
-
Instrument Asynchronous Boundaries: Ensure tracing spans cover asynchronous event producers and consumers.
-
Aggregate Metrics at Multiple Levels: Collect metrics per service, per endpoint, and per event type.
-
Implement Sampling Wisely: To handle high data volume, use adaptive sampling for traces and logs without losing critical information.
-
Centralize Observability Data: Use platforms like Prometheus, Grafana, ELK stack, or OpenTelemetry collectors to unify data.
Mind Map: Observability Best Practices
Summary
Observability is indispensable in high concurrency microservices because it provides the visibility needed to understand complex, asynchronous workflows and rapidly respond to issues. By combining metrics, logs, and traces with best practices like correlation IDs and centralized data platforms, engineering teams can maintain reliability and performance even under massive concurrent loads.
1.5 Real-World Use Case: High Traffic E-Commerce Platform
In this section, we explore a practical example of designing a high concurrency microservices system using event driven architecture and observability, centered around a high traffic e-commerce platform. This example will illustrate how to handle massive simultaneous user interactions such as browsing, ordering, payment processing, and inventory management.
Overview of the E-Commerce Platform
The platform supports:
- Millions of daily active users
- Thousands of concurrent orders per second
- Real-time inventory updates
- Payment processing with external gateways
- Personalized recommendations and notifications
The core challenge is to maintain responsiveness, data consistency, and fault tolerance under high concurrency.
Mind Map: High-Level Components and Event Flows
Example: Event Schema for OrderPlaced Event
{
"eventType": "OrderPlaced",
"eventId": "uuid-1234",
"timestamp": "2024-06-01T12:34:56Z",
"payload": {
"orderId": "order-5678",
"userId": "user-abc",
"items": [
{"productId": "prod-111", "quantity": 2},
{"productId": "prod-222", "quantity": 1}
],
"totalAmount": 150.00,
"currency": "USD"
}
}
This event is published by the Order Service to the event broker and consumed by Inventory and Payment Services.
Mind Map: Handling High Concurrency Challenges
Example: Implementing a Simple Saga for Order Fulfillment
This pattern ensures eventual consistency and fault tolerance.
Observability Example
- Metrics: Track order processing latency, event queue lag, payment success rate.
- Logs: Correlate logs using
eventIdandorderIdfor tracing issues. - Tracing: Use distributed tracing tools (e.g., OpenTelemetry) to visualize event propagation from Order Service through Inventory and Payment Services.
Code Snippet: Publishing an Event (Node.js Example)
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ clientId: 'order-service', brokers: ['kafka:9092'] });
const producer = kafka.producer();
async function publishOrderPlaced(order) {
await producer.connect();
const event = {
eventType: 'OrderPlaced',
eventId: generateUUID(),
timestamp: new Date().toISOString(),
payload: order
};
await producer.send({
topic: 'orders',
messages: [{ value: JSON.stringify(event) }]
});
await producer.disconnect();
}
function generateUUID() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
const r = Math.random() * 16 | 0, v = c === 'x' ? r : (r & 0x3 | 0x8);
return v.toString(16);
});
}
Summary
This real-world use case demonstrates how a high concurrency e-commerce platform leverages event driven architecture to decouple services, handle asynchronous workflows, and maintain scalability. Observability is integrated throughout to ensure visibility into complex event flows and to quickly detect and resolve issues. The use of patterns like Saga and idempotent event handling ensures data consistency and resilience under heavy load.
2. Core Principles of Event Driven Architecture (EDA)
2.1 Event-Driven vs Request-Driven Architectures: Key Differences
In modern microservices design, understanding the distinction between event-driven and request-driven architectures is fundamental to building scalable, resilient, and maintainable systems. This section explores their core differences, advantages, trade-offs, and practical examples.
What is Request-Driven Architecture?
Request-driven architecture, often called synchronous or RESTful architecture, is based on direct communication between services where a client sends a request and waits for a response.
- Characteristics:
- Synchronous communication
- Tight coupling between client and server
- Immediate response expected
- Typically uses HTTP/REST or gRPC protocols
Example:
A client service calls an Order Service API to place an order and waits for confirmation before proceeding.
Client -> Order Service: PlaceOrder(request)
Order Service -> Client: OrderConfirmation(response)
What is Event-Driven Architecture (EDA)?
Event-driven architecture is based on asynchronous communication where services produce and consume events without waiting for immediate responses.
- Characteristics:
- Asynchronous communication
- Loose coupling between producers and consumers
- Eventual consistency
- Uses message brokers like Kafka, RabbitMQ, or cloud event buses
Example:
An Order Service publishes an OrderPlaced event. Inventory and Billing services consume this event independently to update stock and process payment.
Order Service -> Event Broker: Publish(OrderPlaced)
Inventory Service <- Event Broker: Consume(OrderPlaced)
Billing Service <- Event Broker: Consume(OrderPlaced)
Mind Map: Key Differences Between Request-Driven and Event-Driven Architectures
Advantages and Trade-offs
| Aspect | Request-Driven Architecture | Event-Driven Architecture |
|---|---|---|
| Coupling | Tighter coupling; services depend on each other | Looser coupling; services independent |
| Communication | Synchronous, blocking | Asynchronous, non-blocking |
| Scalability | Limited by synchronous calls | Highly scalable through decoupling |
| Complexity | Simpler to implement and reason about | More complex due to asynchronous flows |
| Failure Handling | Immediate error propagation | Requires eventual consistency and retries |
| Use Case Suitability | Real-time queries, CRUD | Event sourcing, audit logs, high concurrency tasks |
Practical Example: Order Processing
Request-Driven:
A client calls the Order Service API to place an order. The Order Service synchronously calls Inventory and Payment services to reserve stock and charge payment before responding.
Client -> Order Service: PlaceOrder
Order Service -> Inventory Service: ReserveStock
Inventory Service -> Order Service: StockReserved
Order Service -> Payment Service: ChargePayment
Payment Service -> Order Service: PaymentConfirmed
Order Service -> Client: OrderConfirmed
Drawbacks: If Inventory or Payment service is slow or down, the entire request blocks or fails.
Event-Driven:
The Order Service publishes an OrderPlaced event. Inventory and Payment services consume the event asynchronously and process their parts independently.
Client -> Order Service: PlaceOrder
Order Service -> Event Broker: Publish(OrderPlaced)
Inventory Service <- Event Broker: Consume(OrderPlaced)
Payment Service <- Event Broker: Consume(OrderPlaced)
Benefits: Services can scale independently; failures in one service do not block others; system can handle high concurrency gracefully.
Mind Map: When to Use Which Architecture
Summary
Request-driven architectures are straightforward and suitable for synchronous, low-latency operations but can struggle under high concurrency and tight coupling. Event-driven architectures embrace asynchronous communication, enabling scalability and resilience at the cost of increased complexity and eventual consistency.
Understanding these differences helps senior backend engineers design microservices that meet performance, scalability, and maintainability goals effectively.
2.2 Event Types: Commands, Events, and Queries Explained
In an event-driven microservices architecture, understanding the different types of messages exchanged between services is fundamental. These messages typically fall into three categories: Commands, Events, and Queries. Each serves a distinct purpose and follows different design principles. This section will explain these types in detail, supported by mind maps and practical examples.
Overview Mind Map
Commands
Definition: A command is a directive sent to a microservice to perform a specific action. It represents an intention to change the state of the system.
Characteristics:
- Imperative: “Do this”.
- Sent to a specific service or component.
- Usually results in side effects (state changes).
- May or may not return a response.
- Typically synchronous but can be asynchronous.
Example Mind Map:
Example in Code (Pseudo-code):
// Command: CreateOrder
class CreateOrderCommand {
String orderId;
String userId;
List<Item> items;
}
// Handling the command
void handle(CreateOrderCommand cmd) {
// Validate order
// Persist order
// Publish OrderCreated event
}
Best Practice:
- Commands should be idempotent where possible to handle retries gracefully.
- Use clear naming conventions (e.g., verbs like Create, Update, Delete).
Events
Definition: An event is a notification that something has happened in the system. It is a fact, not a directive.
Characteristics:
- Declarative: “This happened”.
- Published to multiple subscribers.
- Immutable and append-only.
- Used for asynchronous communication.
- Drives eventual consistency.
Example Mind Map:
Example in Code (Pseudo-code):
{
"eventType": "OrderCreated",
"orderId": "12345",
"timestamp": "2024-06-01T12:00:00Z",
"details": {
"userId": "user789",
"items": ["item1", "item2"]
}
}
Best Practice:
- Design event schemas carefully to be backward and forward compatible.
- Include metadata such as timestamps, correlation IDs, and versioning.
- Ensure events are idempotent on the consumer side.
Queries
Definition: A query is a request for information from a microservice. It does not change the system state.
Characteristics:
- Declarative: “Give me this data”.
- Usually synchronous.
- Should be side-effect free.
- Can be optimized for read performance (CQRS pattern).
Example Mind Map:
Example in Code (Pseudo-code):
GET /orders/12345 HTTP/1.1
Host: orders.example.com
Response:
{
"orderId": "12345",
"status": "Processing",
"items": ["item1", "item2"]
}
Best Practice:
- Separate query models from command models (CQRS).
- Use caching where appropriate to improve performance.
Integrated Example: Order Management Flow
Summary Table
| Message Type | Purpose | Direction | Side Effects | Typical Usage Example |
|---|---|---|---|---|
| Command | Request action | Client -> Service | Yes | CreateOrder, CancelBooking |
| Event | Notify that something happened | Service -> Multiple subscribers | No (immutable) | OrderCreated, PaymentProcessed |
| Query | Request data retrieval | Client -> Service | No | GetOrderDetails, ListUsers |
By clearly distinguishing between commands, events, and queries, microservices can communicate effectively, maintain loose coupling, and scale efficiently under high concurrency scenarios.
2.3 Designing Event Schemas for Scalability and Flexibility
Designing event schemas is a foundational step in building scalable and flexible event-driven microservices. The schema defines the structure and semantics of the events exchanged between services, impacting compatibility, extensibility, and performance.
Key Principles for Designing Event Schemas
- Schema Evolution: Design schemas that can evolve without breaking consumers.
- Versioning: Use versioning strategies that support backward and forward compatibility.
- Minimalism: Include only necessary data to reduce payload size and improve throughput.
- Contextual Clarity: Events should be self-describing and convey clear intent.
- Idempotency Support: Include identifiers or metadata to help consumers handle duplicate events safely.
Mind Map: Core Considerations in Event Schema Design
Schema Evolution Strategies
- Additive Changes: Adding new optional fields is safe and non-breaking.
- Deprecation: Mark fields as deprecated but keep them until all consumers migrate.
- Field Removal: Remove fields only after confirming no consumers rely on them.
- Data Type Changes: Avoid changing data types; if necessary, use new fields.
Example: JSON Event Schema for a User Registration Event
{
"eventId": "uuid-1234-5678",
"eventType": "UserRegistered",
"timestamp": "2024-06-01T12:34:56Z",
"payload": {
"userId": "user-789",
"email": "[email protected]",
"registrationSource": "web",
"referralCode": null
},
"version": "1.0"
}
- Extensibility: If a new field like
phoneNumberis needed, add it as an optional field without breaking existing consumers. - Metadata:
eventIdandtimestamphelp with idempotency and ordering.
Mind Map: Versioning Approaches
Best Practice Example: Using Avro with Schema Registry
Apache Avro combined with a Schema Registry (e.g., Confluent Schema Registry) enables:
- Strongly Typed Schemas: Enforces data types and structure.
- Schema Evolution: Supports backward and forward compatibility.
- Centralized Management: Consumers and producers validate against a shared schema.
Example Avro schema snippet for a PaymentProcessed event:
{
"namespace": "com.example.events",
"type": "record",
"name": "PaymentProcessed",
"fields": [
{"name": "paymentId", "type": "string"},
{"name": "orderId", "type": "string"},
{"name": "amount", "type": "double"},
{"name": "currency", "type": "string", "default": "USD"},
{"name": "timestamp", "type": "long"}
]
}
Example: Handling Schema Evolution in Code (Java with Avro)
// Old schema consumer
PaymentProcessedV1 event = deserialize(payload, PaymentProcessedV1.class);
// New schema producer adds 'currency' field with default
PaymentProcessedV2 eventV2 = new PaymentProcessedV2();
eventV2.setPaymentId("p123");
eventV2.setOrderId("o456");
eventV2.setAmount(100.0);
eventV2.setCurrency("EUR");
eventV2.setTimestamp(System.currentTimeMillis());
// Consumers using V1 schema can still deserialize V2 events due to default value
Mind Map: Metadata Fields to Include in Events
Summary
Designing event schemas with scalability and flexibility in mind requires careful planning around schema structure, versioning, metadata, and evolution strategies. Leveraging schema registries and typed schemas like Avro or Protobuf enhances compatibility and maintainability. Including rich metadata supports observability and troubleshooting in high concurrency environments.
By following these best practices and examples, teams can build resilient event-driven microservices that gracefully evolve and scale.
2.4 Event Brokers and Messaging Systems: Kafka, RabbitMQ, and More
In an event-driven microservices architecture, event brokers and messaging systems play a pivotal role in enabling asynchronous communication, decoupling services, and supporting high concurrency. Choosing the right event broker depends on your system’s requirements such as throughput, latency, message durability, ordering guarantees, and operational complexity.
What is an Event Broker?
An event broker is a middleware component that receives, stores, and forwards events/messages between producers (publishers) and consumers (subscribers). It abstracts the communication layer and provides features like message persistence, delivery guarantees, and scalability.
Popular Event Brokers and Messaging Systems
| Broker | Type | Strengths | Use Cases |
|---|---|---|---|
| Apache Kafka | Distributed Log | High throughput, partitioning, durability | Real-time analytics, event sourcing |
| RabbitMQ | Message Queue (AMQP) | Flexible routing, rich protocol support | Task queues, RPC, complex routing |
| Amazon SQS | Managed Queue Service | Fully managed, scalable, serverless | Cloud-native decoupling, simple queues |
| NATS | Lightweight Messaging | Low latency, simple, cloud native | IoT, microservices communication |
| Apache Pulsar | Distributed Log | Multi-tenancy, geo-replication | Large scale event streaming |
Mind Map: Key Features of Event Brokers
Apache Kafka
Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant, and scalable event processing. It stores streams of records in categories called topics.
Key Concepts:
- Topic: Logical channel for messages.
- Partition: Subdivision of a topic enabling parallelism.
- Producer: Publishes messages to topics.
- Consumer: Reads messages from topics.
- Broker: Kafka server node.
Example: Publishing and Consuming Events with Kafka (Java)
// Producer example
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("orders", "order123", "Order Created");
producer.send(record);
producer.close();
// Consumer example
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "localhost:9092");
consumerProps.put("group.id", "order-service-group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList("orders"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> rec : records) {
System.out.printf("Received order event: key=%s, value=%s, offset=%d\n", rec.key(), rec.value(), rec.offset());
}
}
Best Practice: Use partitions to parallelize event consumption and achieve high concurrency. Ensure your event handlers are idempotent to handle possible duplicate deliveries.
RabbitMQ
RabbitMQ is a message broker implementing the AMQP protocol, known for flexible routing and rich messaging patterns.
Key Concepts:
- Exchange: Routes messages to queues.
- Queue: Stores messages until consumed.
- Binding: Defines routing rules between exchange and queue.
- Producer: Sends messages to exchanges.
- Consumer: Receives messages from queues.
Example: Simple Publish/Subscribe with RabbitMQ (Python)
import pika
# Producer
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
message = 'Order Created'
channel.basic_publish(exchange='logs', routing_key='', body=message)
print(" [x] Sent %r" % message)
connection.close()
# Consumer
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
Best Practice: Use exchanges and bindings to implement complex routing scenarios such as topic-based or header-based routing, enabling flexible event distribution.
Comparison Mind Map: Kafka vs RabbitMQ
Other Notable Messaging Systems
- Amazon SQS: Fully managed, serverless queue service, ideal for cloud-native apps needing simple decoupling.
- NATS: Lightweight, low-latency messaging system, great for microservices and IoT.
- Apache Pulsar: Combines messaging and streaming with multi-tenancy and geo-replication.
Choosing the Right Broker
- For high throughput and event streaming, prefer Kafka or Pulsar.
- For complex routing and protocol support, RabbitMQ is a strong candidate.
- For cloud-native and managed services, Amazon SQS or cloud equivalents.
- For low-latency lightweight messaging, consider NATS.
Summary
Event brokers are the backbone of event-driven microservices. Understanding their characteristics and trade-offs is crucial for designing scalable, resilient, and maintainable systems. By leveraging brokers like Kafka and RabbitMQ with best practices such as partitioning, idempotent consumers, and flexible routing, you can build robust high concurrency microservices architectures.
2.5 Best Practice: Designing Idempotent Event Handlers with Examples
Introduction
In event-driven microservices, idempotency is a critical property for event handlers to ensure that processing the same event multiple times does not lead to inconsistent system states or duplicate side effects. This is especially important in distributed systems where events can be delivered more than once due to retries, network issues, or broker semantics.
What is Idempotency?
Idempotency means that an operation can be performed multiple times without changing the result beyond the initial application. For event handlers, this means that processing the same event repeatedly should have the same effect as processing it once.
Why Idempotent Event Handlers?
- Avoid duplicate side effects: Prevents creating duplicate orders, payments, or notifications.
- Handle retries gracefully: Brokers or clients may retry events on failure.
- Ensure data consistency: Critical for maintaining correct state across microservices.
Common Challenges
- Events may arrive out of order.
- Duplicate events due to network retries.
- Partial failures during event processing.
Mind Map: Key Concepts in Designing Idempotent Event Handlers
Strategies for Idempotency
Use Unique Event Identifiers
Every event should have a globally unique identifier (UUID, ULID, or a composite key) that the event handler can use to detect duplicates.
Maintain a Deduplication Store
Keep a persistent store (e.g., Redis, database table) to record processed event IDs. Before processing, check if the event ID exists.
Design Idempotent Side Effects
Ensure that external calls (e.g., sending emails, updating inventory) are idempotent or can be safely retried without adverse effects.
Use Transactional Boundaries
Wrap event processing and deduplication record insertion in a single transaction to avoid race conditions.
Handle Event Versioning and Ordering
Include version numbers or timestamps to handle out-of-order events and apply only the latest state.
Example 1: Idempotent Order Created Event Handler (Pseudo-code)
class OrderCreatedHandler:
def __init__(self, dedup_store, order_repo):
self.dedup_store = dedup_store # e.g., Redis
self.order_repo = order_repo # Database repository
def handle(self, event):
event_id = event['id']
# Check if event already processed
if self.dedup_store.exists(event_id):
print(f"Event {event_id} already processed. Skipping.")
return
# Process the event
order_data = event['data']
self.order_repo.create_order(order_data)
# Mark event as processed atomically
self.dedup_store.add(event_id)
print(f"Processed event {event_id} successfully.")
Explanation:
- The handler checks if the event ID exists in the deduplication store.
- If yes, it skips processing.
- Otherwise, it creates the order and marks the event as processed.
Example 2: Idempotent Payment Processed Handler with Transaction
@Transactional
public void handlePaymentProcessed(Event event) {
String eventId = event.getId();
if (dedupRepository.exists(eventId)) {
log.info("Duplicate event detected: {}", eventId);
return;
}
Payment payment = event.getPaymentDetails();
paymentRepository.save(payment);
dedupRepository.save(new ProcessedEvent(eventId));
}
Explanation:
- Uses a transactional boundary to save payment and mark event processed atomically.
- Prevents race conditions where event might be processed twice concurrently.
Mind Map: Idempotency Implementation Workflow
Additional Best Practices
- Use Event Versioning: Include a version or sequence number in events to handle updates and prevent stale data application.
- Design Side Effects to be Idempotent: For example, sending emails with unique message IDs or updating counters using upserts.
- Leverage Exactly-Once Processing Features: Some messaging systems (e.g., Kafka with transactional producers) can help but do not replace idempotency.
- Monitor for Duplicate Events: Use observability tools to detect abnormal duplicate processing.
Summary
Designing idempotent event handlers is essential for building reliable, consistent, and scalable event-driven microservices. By combining unique event identifiers, deduplication stores, transactional processing, and idempotent side effects, you can ensure your system gracefully handles retries and duplicates without compromising data integrity.
References
- Martin Kleppmann, “Designing Data-Intensive Applications”
- Microsoft Docs, “Idempotent Messaging Patterns”
- Kafka Documentation, “Exactly Once Semantics”
This section equips you with practical strategies and examples to implement idempotent event handlers effectively in your microservices ecosystem.
3. Designing Microservices for High Concurrency
3.1 Service Decomposition Strategies for Concurrency Optimization
Designing microservices for high concurrency begins with effective service decomposition. Proper decomposition allows services to scale independently, reduce contention, and optimize resource utilization under load. In this section, we’ll explore key strategies for decomposing services with concurrency in mind, supported by mind maps and practical examples.
Why Service Decomposition Matters for Concurrency
- Isolated Workloads: Smaller, focused services reduce contention and allow parallel processing.
- Independent Scaling: Services can be scaled based on their specific load characteristics.
- Fault Isolation: Failures in one service don’t cascade, improving overall system resilience.
- Optimized Resource Usage: Tailor resource allocation to service needs, avoiding bottlenecks.
Common Decomposition Strategies
Domain-Driven Design (DDD) Based Decomposition
DDD encourages decomposing services around bounded contexts which encapsulate a specific domain model. This naturally aligns with concurrency optimization by isolating domain logic and data.
-
Example: In an e-commerce system, separate services for
Order Management,Inventory, andPaymenteach own their domain logic and data. -
Concurrency Benefit: Each service can process events and requests independently, reducing cross-service contention.
Functional Decomposition
Decompose services by business capabilities or CRUD operations.
-
Example: A
User Servicehandles user registration and profile updates, while aNotification Servicemanages sending emails and SMS. -
Concurrency Benefit: Functional separation allows services to scale based on specific workload patterns.
Event-Driven Decomposition
Decompose services based on event ownership and event flows.
-
Example: A
Shipping Servicelistens toOrderPlacedevents and triggers shipment processing. -
Concurrency Benefit: Services react asynchronously to events, enabling parallel processing and reducing synchronous bottlenecks.
Data-Centric Decomposition
Each service owns its own database or data partition to avoid contention.
-
Example:
Customer Servicehas its own database separate fromOrder Service. -
Concurrency Benefit: Eliminates database-level locks across services, enabling independent scaling and faster transactions.
Resource-Based Decomposition
Design services around RESTful resources or APIs.
-
Example: Separate microservices for
/products,/orders, and/users. -
Concurrency Benefit: Enables fine-grained scaling and caching strategies per resource.
Practical Example: Decomposing an Online Marketplace
Suppose you are designing a high concurrency online marketplace. Here’s how you might decompose:
| Service Name | Responsibility | Concurrency Optimization Benefit |
|---|---|---|
| User Service | User registration, authentication | Independent scaling during peak login periods |
| Product Catalog | Managing product listings | Read-heavy service optimized with caching |
| Order Service | Order placement and tracking | Isolated transactional boundaries reduce contention |
| Inventory Service | Stock management | Event-driven updates enable async concurrency |
| Payment Service | Payment processing | Scales independently to handle payment spikes |
| Notification Service | Sending emails, SMS | Async event consumers reduce blocking on main flows |
Each service owns its own database and communicates asynchronously via events (e.g., OrderPlaced, PaymentCompleted). This decomposition supports concurrent processing by isolating workloads and enabling independent scaling.
Best Practices for Service Decomposition to Optimize Concurrency
- Keep services small and focused: Smaller services reduce contention and simplify scaling.
- Design for asynchronous communication: Use events to decouple services and enable parallel processing.
- Avoid shared databases: Each service should own its data to prevent cross-service locking.
- Identify hotspots early: Profile workloads to find concurrency bottlenecks and decompose accordingly.
- Use domain knowledge: Align services with bounded contexts to maintain clear ownership and reduce coupling.
By carefully decomposing microservices with concurrency in mind, you lay the foundation for a scalable, resilient, and performant system capable of handling high loads efficiently.
3.2 Stateless vs Stateful Services: Trade-offs and Patterns
Designing microservices for high concurrency requires a clear understanding of the fundamental distinction between stateless and stateful services. Each approach comes with its own trade-offs, influencing scalability, complexity, fault tolerance, and performance.
What Are Stateless Services?
Stateless services do not store any client session or state information between requests. Each request is treated independently, and the service relies on external systems (like databases or caches) to retrieve or persist any required state.
Example: A microservice that processes user login requests by validating credentials against a database without storing session info locally.
What Are Stateful Services?
Stateful services maintain state information across multiple requests. This state can be in-memory or persisted locally within the service instance.
Example: A shopping cart service that keeps track of items added by a user in memory during their session.
Trade-offs Between Stateless and Stateful Services
| Aspect | Stateless Services | Stateful Services |
|---|---|---|
| Scalability | Highly scalable; easy to horizontally scale | More complex to scale; state synchronization needed |
| Fault Tolerance | Easier to recover; any instance can handle requests | Harder to recover; state loss possible on failure |
| Complexity | Simpler design; no state management required | More complex; requires state replication or persistence |
| Performance | Potential latency due to external state calls | Faster access to local state; reduced external calls |
| Consistency | Easier to maintain consistency | Risk of state divergence; requires synchronization |
Mind Map: Stateless vs Stateful Services
Patterns for Stateless Services
- Externalize State: Store session or user data in external stores like Redis, databases, or distributed caches.
- Idempotent Operations: Design APIs to be idempotent to handle retries without side effects.
- Load Balancing: Use load balancers to distribute requests evenly since any instance can handle any request.
Example:
# Stateless example: User authentication microservice
from flask import Flask, request, jsonify
app = Flask(__name__)
users_db = {"alice": "password123", "bob": "mypassword"}
@app.route('/login', methods=['POST'])
def login():
data = request.json
username = data.get('username')
password = data.get('password')
if users_db.get(username) == password:
# No session stored locally
return jsonify({"message": "Login successful"}), 200
else:
return jsonify({"message": "Invalid credentials"}), 401
if __name__ == '__main__':
app.run()
Patterns for Stateful Services
- Sticky Sessions: Route requests from the same client to the same service instance.
- State Replication: Use replication or consensus algorithms (e.g., Raft) to synchronize state.
- Event Sourcing: Persist state changes as events to rebuild state after failures.
Example:
# Stateful example: Simple in-memory shopping cart microservice
from flask import Flask, request, jsonify
app = Flask(__name__)
# In-memory state per instance
shopping_carts = {}
@app.route('/cart/<user_id>/add', methods=['POST'])
def add_item(user_id):
item = request.json.get('item')
if user_id not in shopping_carts:
shopping_carts[user_id] = []
shopping_carts[user_id].append(item)
return jsonify({"cart": shopping_carts[user_id]}), 200
@app.route('/cart/<user_id>', methods=['GET'])
def get_cart(user_id):
return jsonify({"cart": shopping_carts.get(user_id, [])}), 200
if __name__ == '__main__':
app.run()
Note: This example is simple and does not handle persistence or replication, which are critical for production.
When to Choose Stateless vs Stateful?
-
Stateless:
- Systems requiring massive horizontal scaling.
- Services where state can be externalized easily.
- When fault tolerance and simplicity are priorities.
-
Stateful:
- Services with complex stateful workflows.
- When latency is critical and local state access improves performance.
- When state changes need to be tightly coupled with service logic.
Mind Map: Choosing Between Stateless and Stateful
Summary
Understanding the trade-offs between stateless and stateful microservices is essential for designing systems that handle high concurrency effectively. Stateless services offer simplicity and scalability, while stateful services provide performance and richer user experiences at the cost of complexity. Often, a hybrid approach is used, combining stateless frontends with stateful backend components, orchestrated via event-driven patterns to maintain consistency and resilience.
3.3 Implementing Backpressure and Load Shedding Mechanisms
In high concurrency microservices, managing load effectively is critical to maintaining system stability and responsiveness. When the system is overwhelmed by requests or events, uncontrolled load can lead to cascading failures, increased latency, and degraded user experience. Two essential techniques to handle such scenarios are Backpressure and Load Shedding.
What is Backpressure?
Backpressure is a mechanism that allows a system to signal its inability to process incoming requests or events at the current rate, prompting upstream components to slow down or pause sending data. This helps prevent resource exhaustion and keeps the system operating within safe limits.
What is Load Shedding?
Load shedding is the practice of intentionally dropping or rejecting some requests or events when the system is under extreme load, to preserve overall system health and ensure that critical requests are still processed.
Mind Map: Backpressure and Load Shedding Overview
Why Implement Backpressure and Load Shedding in Microservices?
- Microservices often communicate asynchronously via events or messages.
- High concurrency can cause message queues and services to become overwhelmed.
- Without control, queues grow indefinitely, leading to memory exhaustion and crashes.
- Backpressure helps slow down event producers.
- Load shedding ensures the system stays responsive by dropping non-critical or excess events.
Practical Example: Backpressure in a Kafka Consumer Microservice
Imagine a microservice consuming events from a Kafka topic. If the consumer cannot keep up with the producer’s event rate, the consumer’s internal queue will grow, increasing memory usage and latency.
Implementing Backpressure:
- Use a bounded queue for incoming events.
- When the queue is full, signal the producer to slow down or pause.
- In Kafka, this can be done by controlling the consumer poll rate or using Kafka’s flow control features.
// Example using Reactor Kafka with backpressure
Flux<ReceiverRecord<String, String>> kafkaFlux = kafkaReceiver.receive()
.onBackpressureBuffer(1000, dropped -> {
System.out.println("Dropped event due to backpressure: " + dropped);
}, BackpressureOverflowStrategy.DROP_OLDEST);
kafkaFlux.subscribe(record -> {
processEvent(record);
record.receiverOffset().acknowledge();
});
In this example:
onBackpressureBufferlimits the buffer size to 1000.- When the buffer is full, oldest events are dropped (load shedding).
- This prevents unbounded memory growth.
Practical Example: Load Shedding in HTTP API Gateway
An API Gateway handling incoming requests to backend microservices can implement load shedding by rejecting requests when backend services are overloaded.
Implementation:
- Monitor backend service health and request queue lengths.
- When thresholds are exceeded, respond with HTTP 429 (Too Many Requests).
- Optionally, prioritize requests (e.g., authenticated users vs anonymous).
from flask import Flask, request, jsonify
app = Flask(__name__)
MAX_CONCURRENT_REQUESTS = 100
current_requests = 0
@app.before_request
def check_load():
global current_requests
if current_requests >= MAX_CONCURRENT_REQUESTS:
return jsonify({'error': 'Too many requests, please try again later.'}), 429
current_requests += 1
@app.after_request
def after_request(response):
global current_requests
current_requests -= 1
return response
@app.route('/process')
def process():
# Simulate processing
return jsonify({'status': 'processed'})
if __name__ == '__main__':
app.run()
This example:
- Tracks the number of concurrent requests.
- Rejects new requests with 429 if the limit is reached.
- Simple form of load shedding to protect backend microservices.
Mind Map: Implementing Backpressure
Mind Map: Implementing Load Shedding
Best Practices
- Combine Backpressure and Load Shedding: Use backpressure to slow down load early, and load shedding as a last resort.
- Graceful Degradation: Prioritize critical requests and shed less important ones.
- Monitoring: Continuously monitor queue sizes, latencies, and error rates to tune thresholds.
- Idempotency: Ensure that dropped or retried events do not cause inconsistent state.
- Timeouts: Use timeouts to avoid waiting indefinitely on slow downstream services.
Summary
Backpressure and load shedding are vital tools in designing resilient high concurrency microservices. Backpressure helps maintain system stability by signaling upstream components to slow down, while load shedding protects the system by dropping excess load when overwhelmed. Implementing these mechanisms thoughtfully, combined with monitoring and prioritization, ensures your microservices can handle bursts of traffic gracefully without crashing or degrading user experience.
3.4 Example: Building a Concurrent Order Processing Microservice
In this section, we’ll build a simplified yet practical example of a concurrent order processing microservice designed to handle high throughput and concurrency using event-driven principles. We’ll explore the architecture, concurrency control, and best practices with illustrative mind maps and code snippets.
Overview
The order processing microservice is responsible for receiving orders, validating them, reserving inventory, processing payments, and confirming the order. To handle high concurrency, the service must process multiple orders simultaneously without conflicts or bottlenecks.
Mind Map: High-Level Components and Flow
Step 1: Defining the OrderReceived Event Schema
{
"eventType": "OrderReceived",
"orderId": "string",
"customerId": "string",
"items": [
{ "productId": "string", "quantity": "number" }
],
"timestamp": "ISO8601 string"
}
This event is published when a new order is received.
Step 2: Event-Driven Processing Flow
- Receive Order API call
- Validate order data
- Publish OrderReceived event
- On OrderReceived event
- Validate inventory availability
- Publish InventoryReserved or InventoryFailed event
- On InventoryReserved event
- Initiate payment processing
- Publish PaymentProcessed or PaymentFailed event
- On PaymentProcessed event
- Update order status to Confirmed
- Publish OrderConfirmed event
- On any failure event
- Trigger compensating actions (e.g., release inventory)
- Update order status to Failed
Step 3: Handling Concurrency with Idempotency and Optimistic Locking
-
Idempotent Event Handlers: Each event handler checks if the event was already processed to avoid duplicate processing.
-
Optimistic Locking: When updating order state in the database, use version numbers or timestamps to prevent race conditions.
Example pseudocode for idempotent handler:
processed_events = set()
def handle_order_received(event):
if event['eventId'] in processed_events:
return # Already processed
# Process event
processed_events.add(event['eventId'])
# Business logic here
Step 4: Example Code Snippet - Publishing an Event (Node.js with Kafka)
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ clientId: 'order-service', brokers: ['kafka:9092'] });
const producer = kafka.producer();
async function publishOrderReceived(order) {
await producer.connect();
await producer.send({
topic: 'order-events',
messages: [
{
key: order.orderId,
value: JSON.stringify({
eventType: 'OrderReceived',
orderId: order.orderId,
customerId: order.customerId,
items: order.items,
timestamp: new Date().toISOString()
})
}
]
});
await producer.disconnect();
}
Step 5: Mind Map - Concurrency Control Techniques
Step 6: Example - Optimistic Locking Update (Pseudo SQL)
UPDATE orders
SET status = 'Confirmed', version = version + 1
WHERE order_id = :orderId AND version = :currentVersion;
If the update affects zero rows, it means a concurrent update happened, and the operation should be retried or aborted.
Step 7: Best Practice - Using Circuit Breakers
To prevent cascading failures when inventory or payment services are down, implement circuit breakers that:
- Monitor failure rates
- Temporarily stop calls to failing services
- Provide fallback responses or queue requests
Example libraries: Netflix Hystrix (Java), Polly (.NET), or custom implementations.
Summary
This example demonstrates how to design a concurrent order processing microservice using event-driven architecture:
- Decouple components via events
- Use idempotent handlers to avoid duplicate processing
- Apply optimistic locking to handle concurrent state updates
- Employ circuit breakers to improve resilience
By following these practices, the microservice can handle high concurrency reliably and scalably.
3.5 Best Practice: Using Circuit Breakers and Bulkheads to Improve Resilience
In high concurrency microservices environments, resilience is paramount to ensure system stability and availability. Two critical design patterns to achieve this are Circuit Breakers and Bulkheads. These patterns help isolate failures, prevent cascading issues, and maintain service responsiveness under load.
What is a Circuit Breaker?
A Circuit Breaker is a design pattern that detects failures and prevents an application from trying to perform an action that’s likely to fail. It acts like an electrical circuit breaker, stopping the flow of requests to a failing service to allow it to recover.
Key Benefits:
- Prevents cascading failures
- Improves system stability
- Enables graceful degradation
States of a Circuit Breaker:
- Closed: Requests flow normally.
- Open: Requests are blocked to the failing service.
- Half-Open: Allows limited requests to test if the service has recovered.
What is a Bulkhead?
Bulkheads are inspired by ship compartments that prevent flooding from sinking the entire ship. In microservices, bulkheads isolate resources such as thread pools or connection pools so that failure in one component does not exhaust resources for others.
Key Benefits:
- Limits failure impact to isolated components
- Improves fault tolerance
- Controls resource usage under high load
Mind Map: Circuit Breaker Pattern
Mind Map: Bulkhead Pattern
Example 1: Implementing Circuit Breaker with Resilience4j (Java)
import io.github.resilience4j.circuitbreaker.CircuitBreaker;
import io.github.resilience4j.circuitbreaker.CircuitBreakerConfig;
import io.github.resilience4j.circuitbreaker.CircuitBreakerRegistry;
import java.time.Duration;
import java.util.function.Supplier;
public class OrderService {
private CircuitBreaker circuitBreaker;
public OrderService() {
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // Open circuit if 50% failures
.waitDurationInOpenState(Duration.ofSeconds(10)) // Wait 10 seconds before retry
.slidingWindowSize(10) // Number of calls to evaluate
.build();
circuitBreaker = CircuitBreakerRegistry.of(config).circuitBreaker("orderServiceCB");
}
public String processOrder() {
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, this::callRemoteInventoryService);
try {
return decoratedSupplier.get();
} catch (Exception e) {
return fallback();
}
}
private String callRemoteInventoryService() {
// Simulate remote call that may fail
if (Math.random() < 0.6) {
throw new RuntimeException("Inventory service unavailable");
}
return "Order processed successfully";
}
private String fallback() {
return "Fallback: Please try again later";
}
}
Explanation: This example configures a circuit breaker that opens when 50% of the last 10 calls fail, waits 10 seconds before trying again, and provides a fallback response when the circuit is open.
Example 2: Using Bulkhead Pattern with Resilience4j Semaphore Bulkhead
import io.github.resilience4j.bulkhead.SemaphoreBulkhead;
import io.github.resilience4j.bulkhead.SemaphoreBulkheadConfig;
import io.github.resilience4j.bulkhead.SemaphoreBulkheadRegistry;
import java.time.Duration;
import java.util.concurrent.Callable;
public class PaymentService {
private SemaphoreBulkhead bulkhead;
public PaymentService() {
SemaphoreBulkheadConfig config = SemaphoreBulkheadConfig.custom()
.maxConcurrentCalls(5) // Limit to 5 concurrent calls
.maxWaitDuration(Duration.ofMillis(500)) // Wait max 500ms to acquire permission
.build();
bulkhead = SemaphoreBulkheadRegistry.of(config).bulkhead("paymentBulkhead");
}
public String processPayment() throws Exception {
Callable<String> decoratedCallable = SemaphoreBulkhead
.decorateCallable(bulkhead, this::callExternalPaymentGateway);
try {
return decoratedCallable.call();
} catch (Exception e) {
return fallback();
}
}
private String callExternalPaymentGateway() throws InterruptedException {
// Simulate payment processing delay
Thread.sleep(1000);
return "Payment successful";
}
private String fallback() {
return "Payment service busy, please try again later";
}
}
Explanation: This example limits the number of concurrent payment processing calls to 5. If the limit is exceeded, calls wait up to 500ms before failing fast and returning a fallback.
Integrating Circuit Breakers and Bulkheads
Combining these two patterns provides robust protection:
- Use Circuit Breakers to detect and isolate failing downstream services.
- Use Bulkheads to isolate resource usage and prevent one failing or slow component from exhausting system resources.
Mind Map: Combined Resilience Strategy
Summary
- Circuit Breakers prevent cascading failures by stopping calls to unhealthy services.
- Bulkheads isolate resources to contain failures and control concurrency.
- Both patterns are essential in high concurrency microservices to maintain availability and responsiveness.
- Use libraries like Resilience4j for easy implementation.
- Always provide meaningful fallbacks to improve user experience during failures.
By thoughtfully applying circuit breakers and bulkheads, backend engineers can design microservices that gracefully handle failures and scale effectively under high concurrency loads.
4. Event-Driven Communication Patterns for Scalability
4.1 Publish-Subscribe Pattern: Design and Implementation
Overview
The Publish-Subscribe (Pub/Sub) pattern is a messaging paradigm where senders (publishers) emit messages (events) without knowledge of the receivers (subscribers). Subscribers express interest in specific event types and receive only those events. This decouples the components, enabling scalable, flexible, and highly concurrent microservices.
Why Use Pub/Sub in High Concurrency Microservices?
- Loose Coupling: Publishers and subscribers operate independently, allowing services to evolve without tight dependencies.
- Scalability: Multiple subscribers can process events concurrently, distributing load.
- Asynchronous Communication: Enables non-blocking workflows, improving throughput.
- Event Broadcasting: One event can trigger multiple reactions across services.
Core Components of Pub/Sub
Design Considerations
- Event Topics or Channels: Define logical channels to categorize events (e.g.,
order.created,payment.completed). - Event Schema: Standardize event payloads for interoperability.
- Message Broker Selection: Choose based on throughput, durability, latency (e.g., Apache Kafka, RabbitMQ, AWS SNS).
- Subscriber Management: Handle dynamic subscriptions, scaling, and failure recovery.
- Delivery Semantics: Decide between at-most-once, at-least-once, or exactly-once delivery.
- Ordering Guarantees: Determine if event order matters and how to enforce it.
Example: Implementing a Simple Pub/Sub with Kafka
Scenario
An e-commerce system where the Order Service publishes order.created events, and multiple services like Inventory Service and Notification Service subscribe to these events.
Step 1: Define the Event Schema (JSON)
{
"eventType": "order.created",
"orderId": "12345",
"customerId": "67890",
"items": [
{"productId": "abc", "quantity": 2},
{"productId": "def", "quantity": 1}
],
"timestamp": "2024-06-01T12:34:56Z"
}
Step 2: Publisher Code Snippet (Java with Kafka Producer)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
String topic = "order-events";
String key = "order-12345";
String value = "{...json event payload...}";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.println("Event published to topic " + metadata.topic() + " partition " + metadata.partition());
}
});
producer.close();
Step 3: Subscriber Code Snippet (Java with Kafka Consumer)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "inventory-service-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-events"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received event: " + record.value());
// Process event, e.g., update inventory
}
}
Best Practices with Examples
Idempotent Event Handlers
Ensure subscribers can safely process the same event multiple times without side effects.
Example: Use unique event IDs and check if the event was already processed before applying changes.
Handling Event Ordering
If order matters, use partitioning keys (e.g., orderId) so all related events go to the same partition and are processed sequentially.
Dead Letter Queues (DLQ)
For events that fail processing repeatedly, route them to a DLQ for manual inspection or retry.
Monitoring Event Flow
Instrument publishers and subscribers with metrics (event rates, processing latency, error counts) for observability.
Mind Map: Pub/Sub Best Practices
Summary
The Publish-Subscribe pattern is foundational for building scalable and concurrent microservices. By decoupling event producers and consumers, it enables asynchronous workflows and flexible system evolution. Proper design around event schemas, delivery guarantees, and observability ensures robust implementations that handle high concurrency gracefully.
4.2 Event Sourcing and CQRS for High Throughput Systems
In high concurrency microservices, managing data consistency, scalability, and performance is paramount. Event Sourcing combined with Command Query Responsibility Segregation (CQRS) offers a powerful architectural pattern to address these challenges effectively.
What is Event Sourcing?
Event Sourcing is a pattern where state changes are stored as a sequence of immutable events rather than just storing the current state. Instead of persisting the latest snapshot, every change to the application state is captured as an event.
Key Benefits:
- Complete audit trail of all changes
- Ability to reconstruct state at any point in time
- Easier to implement temporal queries and debugging
What is CQRS?
CQRS stands for Command Query Responsibility Segregation. It separates the write model (commands) from the read model (queries). This separation allows optimizing each side independently for scalability and performance.
Key Benefits:
- Optimized read and write paths
- Simplifies complex domain logic on the write side
- Enables different data models for reading and writing
How Event Sourcing and CQRS Work Together
Event Sourcing naturally complements CQRS by using events as the source of truth for the write model, while the read model is built by projecting these events into query-optimized views.
Mind Map: Event Sourcing and CQRS Overview
Example Scenario: Online Shopping Cart
Let’s consider an online shopping cart microservice designed with Event Sourcing and CQRS.
Command Side (Write Model)
- Receives commands like
AddItem,RemoveItem,Checkout. - Validates the commands (e.g., check inventory availability).
- Emits events such as
ItemAdded,ItemRemoved,CartCheckedOut.
Event Store
- Stores all emitted events in an append-only log.
Query Side (Read Model)
- Listens to events and updates a read-optimized database (e.g., a denormalized view).
- Supports queries like “Get current cart contents” or “Get cart total price”.
Code Example: Simplified Event Sourcing in Node.js
// Event definitions
class ItemAdded {
constructor(itemId, quantity) {
this.type = 'ItemAdded';
this.itemId = itemId;
this.quantity = quantity;
this.timestamp = new Date();
}
}
// Event Store (in-memory for simplicity)
const eventStore = [];
// Aggregate root: ShoppingCart
class ShoppingCart {
constructor() {
this.items = {};
}
apply(event) {
switch (event.type) {
case 'ItemAdded':
this.items[event.itemId] = (this.items[event.itemId] || 0) + event.quantity;
break;
// handle other event types...
}
}
loadFromHistory(events) {
events.forEach(event => this.apply(event));
}
addItem(itemId, quantity) {
const event = new ItemAdded(itemId, quantity);
eventStore.push(event);
this.apply(event);
}
}
// Usage
const cart = new ShoppingCart();
cart.loadFromHistory(eventStore); // rebuild state from events
cart.addItem('item-123', 2);
console.log(cart.items); // { 'item-123': 2 }
Mind Map: Event Sourcing Flow
Handling High Throughput with Event Sourcing and CQRS
- Write Scalability: Since commands result in appending events, the event store can be optimized for high write throughput (e.g., Kafka, EventStoreDB).
- Read Scalability: Read models can be scaled horizontally and optimized for specific query patterns.
- Asynchronous Processing: Read models update asynchronously, allowing the system to handle bursts of traffic efficiently.
Best Practices
- Design Idempotent Event Handlers: Ensure that replaying events or processing duplicates does not corrupt state.
- Use Snapshots: For aggregates with long event histories, periodically store snapshots to speed up state reconstruction.
- Separate Event Schema from Business Logic: Keep event definitions stable and backward compatible.
- Implement Event Versioning: To handle schema evolution gracefully.
Summary
Event Sourcing combined with CQRS provides a robust foundation for building high throughput, scalable microservices. By treating events as the source of truth and separating read/write concerns, systems can achieve better performance, auditability, and flexibility — essential for high concurrency environments.
4.3 Asynchronous Messaging and Eventual Consistency Explained
In high concurrency microservices architectures, asynchronous messaging is a foundational pattern that enables services to communicate without blocking each other, thus improving scalability and resilience. Coupled with this is the concept of eventual consistency, which allows distributed systems to remain responsive and available even when immediate consistency is not feasible.
What is Asynchronous Messaging?
Asynchronous messaging means that the sender and receiver of a message do not need to interact with the message queue or broker at the same time. The sender publishes a message and continues its work immediately, while the receiver processes the message at its own pace.
Key Benefits:
- Decouples services, enabling independent scaling
- Improves fault tolerance by buffering messages
- Enables load leveling and backpressure handling
Example:
Imagine an e-commerce platform where the Order Service publishes an OrderCreated event to a message broker like Kafka. The Inventory Service and Billing Service consume this event asynchronously to update stock and charge the customer respectively. The Order Service does not wait for these services to complete, thus remaining responsive.
What is Eventual Consistency?
Eventual consistency is a consistency model used in distributed systems where updates to data will propagate to all nodes eventually, but not necessarily immediately. This contrasts with strong consistency, where all nodes see the same data at the same time.
Why Eventual Consistency?
- Enables high availability and partition tolerance (CAP theorem)
- Allows systems to continue operating under network partitions or failures
- Fits naturally with asynchronous event-driven communication
Example:
In the previous example, the Inventory Service might take a few seconds to update stock after receiving the OrderCreated event. During this time, the system is temporarily inconsistent but will converge to a consistent state eventually.
Mind Map: Asynchronous Messaging and Eventual Consistency
Practical Example: Implementing Asynchronous Messaging with Eventual Consistency
Consider a simplified Order and Inventory microservices setup:
- Order Service publishes an
OrderPlacedevent asynchronously. - Inventory Service listens for
OrderPlacedevents and updates stock. - If the inventory update fails, the service retries or triggers a compensating action.
// Pseudocode for Order Service publishing event
class OrderService {
void placeOrder(Order order) {
saveOrderToDb(order);
eventBus.publish(new OrderPlacedEvent(order.getId()));
}
}
// Inventory Service consuming event asynchronously
class InventoryService {
void onOrderPlaced(OrderPlacedEvent event) {
try {
updateInventory(event.getOrderId());
} catch (Exception e) {
retryOrCompensate(event);
}
}
}
Idempotency is crucial here to handle duplicate events gracefully. For example, the Inventory Service should check if stock has already been updated for a given order before applying changes.
Best Practices
- Design for Idempotency: Ensure event handlers can safely process the same event multiple times.
- Use Dead Letter Queues: Capture failed messages for manual or automated reprocessing.
- Implement Retries with Backoff: Avoid overwhelming services during transient failures.
- Monitor Event Processing: Use observability tools to track lag, errors, and throughput.
Summary
Asynchronous messaging paired with eventual consistency enables microservices to handle high concurrency by decoupling service interactions and tolerating temporary inconsistencies. While this introduces complexity, following best practices such as idempotency, retries, and observability ensures robust and scalable systems.
4.4 Example: Implementing Event Sourcing in a Payment Microservice
Event Sourcing is a powerful pattern for building scalable, resilient microservices, especially in high concurrency environments like payment processing. Instead of storing just the current state, event sourcing persists all changes as a sequence of immutable events. This allows reconstruction of state at any point and provides a reliable audit trail.
Mind Map: Key Concepts of Event Sourcing in Payment Microservice
Step 1: Define the Domain Events
In a payment microservice, domain events represent meaningful state changes. Here are some typical events:
// Example in Java
public interface PaymentEvent {}
public class PaymentInitiated implements PaymentEvent {
public final String paymentId;
public final double amount;
public final String currency;
public final String userId;
public PaymentInitiated(String paymentId, double amount, String currency, String userId) {
this.paymentId = paymentId;
this.amount = amount;
this.currency = currency;
this.userId = userId;
}
}
public class PaymentAuthorized implements PaymentEvent {
public final String paymentId;
public final String authorizationCode;
public PaymentAuthorized(String paymentId, String authorizationCode) {
this.paymentId = paymentId;
this.authorizationCode = authorizationCode;
}
}
// Additional events: PaymentCaptured, PaymentFailed, PaymentRefunded
Step 2: Implement the Payment Aggregate
The aggregate is responsible for applying events and maintaining current state by replaying events.
public class Payment {
private String paymentId;
private double amount;
private String currency;
private String userId;
private String status; // e.g., INITIATED, AUTHORIZED, CAPTURED, FAILED
// Apply events to mutate state
public void apply(PaymentEvent event) {
if (event instanceof PaymentInitiated) {
PaymentInitiated e = (PaymentInitiated) event;
this.paymentId = e.paymentId;
this.amount = e.amount;
this.currency = e.currency;
this.userId = e.userId;
this.status = "INITIATED";
} else if (event instanceof PaymentAuthorized) {
this.status = "AUTHORIZED";
} else if (event instanceof PaymentCaptured) {
this.status = "CAPTURED";
} else if (event instanceof PaymentFailed) {
this.status = "FAILED";
} else if (event instanceof PaymentRefunded) {
this.status = "REFUNDED";
}
}
// Rehydrate from event history
public static Payment fromEvents(List<PaymentEvent> events) {
Payment payment = new Payment();
for (PaymentEvent event : events) {
payment.apply(event);
}
return payment;
}
}
Step 3: Command Handling and Event Generation
Commands are requests to perform actions. The aggregate validates commands and emits events.
public class PaymentService {
private final EventStore eventStore; // Interface to persist events
public void initiatePayment(String paymentId, double amount, String currency, String userId) {
List<PaymentEvent> history = eventStore.loadEvents(paymentId);
Payment payment = Payment.fromEvents(history);
if (payment.status != null) {
throw new IllegalStateException("Payment already exists");
}
PaymentInitiated event = new PaymentInitiated(paymentId, amount, currency, userId);
eventStore.appendEvent(paymentId, event);
}
public void authorizePayment(String paymentId, String authorizationCode) {
List<PaymentEvent> history = eventStore.loadEvents(paymentId);
Payment payment = Payment.fromEvents(history);
if (!"INITIATED".equals(payment.status)) {
throw new IllegalStateException("Payment not in initiated state");
}
PaymentAuthorized event = new PaymentAuthorized(paymentId, authorizationCode);
eventStore.appendEvent(paymentId, event);
}
// Additional command handlers for capture, refund, fail
}
Step 4: Event Store Implementation
An event store is an append-only log that persists events. For example, Apache Kafka or a dedicated event store like EventStoreDB can be used.
public interface EventStore {
List<PaymentEvent> loadEvents(String aggregateId);
void appendEvent(String aggregateId, PaymentEvent event);
}
Example using an in-memory event store for simplicity:
public class InMemoryEventStore implements EventStore {
private final Map<String, List<PaymentEvent>> store = new ConcurrentHashMap<>();
@Override
public List<PaymentEvent> loadEvents(String aggregateId) {
return store.getOrDefault(aggregateId, new ArrayList<>());
}
@Override
public void appendEvent(String aggregateId, PaymentEvent event) {
store.computeIfAbsent(aggregateId, k -> new ArrayList<>()).add(event);
}
}
Step 5: Projections for Querying
Since event sourcing stores events, projections are used to build queryable views.
Example: PaymentStatusProjection maintains the latest status for each payment.
public class PaymentStatusProjection {
private final Map<String, String> paymentStatuses = new ConcurrentHashMap<>();
public void onEvent(PaymentEvent event) {
if (event instanceof PaymentInitiated) {
paymentStatuses.put(((PaymentInitiated) event).paymentId, "INITIATED");
} else if (event instanceof PaymentAuthorized) {
paymentStatuses.put(((PaymentAuthorized) event).paymentId, "AUTHORIZED");
} else if (event instanceof PaymentCaptured) {
paymentStatuses.put(((PaymentCaptured) event).paymentId, "CAPTURED");
} else if (event instanceof PaymentFailed) {
paymentStatuses.put(((PaymentFailed) event).paymentId, "FAILED");
} else if (event instanceof PaymentRefunded) {
paymentStatuses.put(((PaymentRefunded) event).paymentId, "REFUNDED");
}
}
public String getStatus(String paymentId) {
return paymentStatuses.get(paymentId);
}
}
Step 6: Handling Concurrency and Idempotency
- Concurrency: Use optimistic concurrency control by storing event version numbers and rejecting conflicting writes.
- Idempotency: Ensure command handlers can safely retry without producing duplicate events.
Example snippet for optimistic concurrency:
public void appendEvent(String aggregateId, PaymentEvent event, int expectedVersion) {
List<PaymentEvent> events = store.getOrDefault(aggregateId, new ArrayList<>());
int currentVersion = events.size();
if (currentVersion != expectedVersion) {
throw new ConcurrentModificationException("Version conflict detected");
}
events.add(event);
store.put(aggregateId, events);
}
Summary
This example demonstrated how to implement event sourcing in a payment microservice:
- Define domain events representing state changes.
- Use an aggregate to apply events and rehydrate state.
- Handle commands to validate and generate new events.
- Persist events in an append-only event store.
- Build projections for efficient querying.
- Manage concurrency and idempotency for robustness.
By adopting event sourcing, the payment microservice gains auditability, scalability, and resilience, crucial for high concurrency systems.
Additional Resources
- Martin Fowler on Event Sourcing
- Event Sourcing with Kafka
- Axon Framework Example
4.5 Best Practice: Handling Event Ordering and Duplicate Events
In event-driven microservices, ensuring correct event ordering and handling duplicate events are critical challenges that directly impact system consistency, reliability, and user experience. This section explores best practices to address these challenges with clear examples and mind maps to visualize the concepts.
Understanding the Challenges
- Event Ordering: Events may arrive out of order due to network delays, retries, or asynchronous processing.
- Duplicate Events: Events can be delivered multiple times because of retries, network glitches, or broker behavior.
Both issues can cause incorrect state transitions, data inconsistencies, or unintended side effects if not properly handled.
Mind Map: Key Concepts in Event Ordering and Deduplication
Best Practices
Use Sequence Numbers or Versioning
Assign a monotonically increasing sequence number or version to each event related to an entity or aggregate. This allows consumers to:
- Detect out-of-order events.
- Apply events only if they are newer than the current state.
Example:
{
"orderId": "12345",
"eventType": "OrderUpdated",
"sequenceNumber": 5,
"payload": { "status": "shipped" }
}
The consumer tracks the last applied sequence number per order and ignores events with lower or equal sequence numbers.
Partition Events by Entity Key
Use consistent partitioning (e.g., Kafka partitions keyed by entity ID) to ensure all events for a particular entity are processed in order by the same consumer instance.
This reduces cross-partition ordering issues.
Implement Idempotent Event Handlers
Design event handlers so that processing the same event multiple times does not change the outcome beyond the first application.
Example:
processed_event_ids = set()
def handle_event(event):
if event.id in processed_event_ids:
return # Duplicate detected, ignore
# Process event
processed_event_ids.add(event.id)
In production, use persistent stores (like Redis or a database) to track processed event IDs.
Use Deduplication Stores or Caches
Maintain a store of recently processed event IDs with TTL (time-to-live) to detect and discard duplicates.
This is especially useful in at-least-once delivery systems.
Leverage Broker Features
Some message brokers provide features like exactly-once semantics or deduplication (e.g., Kafka’s idempotent producers and transactional APIs).
Use these features to reduce duplicates at the source.
Handle Out-of-Order Events Gracefully
If strict ordering is impossible, design your system to tolerate eventual consistency and reconcile state later.
Use compensating events or snapshots to restore consistency.
Example: Handling Event Ordering and Duplicates in an Inventory Microservice
Scenario: An inventory service receives InventoryReserved and InventoryReleased events for product stock management.
Problem: Events may arrive out of order or be duplicated due to retries.
Solution:
- Each event carries a
sequenceNumberper product. - The service stores the last applied sequence number per product.
- Events with sequence numbers <= last applied are ignored.
- Event handlers are idempotent; repeated processing of the same event ID has no side effects.
Pseudocode:
class InventoryService:
def __init__(self):
self.last_sequence_numbers = {} # product_id -> sequence_number
self.processed_event_ids = set()
def handle_event(self, event):
product_id = event.payload['productId']
seq_num = event.sequenceNumber
# Check ordering
last_seq = self.last_sequence_numbers.get(product_id, 0)
if seq_num <= last_seq:
print(f"Ignoring out-of-order event {event.id} for product {product_id}")
return
# Check duplicates
if event.id in self.processed_event_ids:
print(f"Ignoring duplicate event {event.id}")
return
# Process event
self.apply_event(event)
# Update state
self.last_sequence_numbers[product_id] = seq_num
self.processed_event_ids.add(event.id)
def apply_event(self, event):
# Business logic to update inventory
pass
Mind Map: Event Ordering and Deduplication Workflow
Summary
Handling event ordering and duplicates is essential for building robust, high concurrency microservices with event-driven architecture. By combining sequence numbers, idempotent handlers, partitioning strategies, and leveraging broker capabilities, you can ensure data consistency and system reliability even under heavy load and network uncertainties.
These best practices, paired with observability and monitoring, help detect and resolve ordering or duplication issues early, maintaining a seamless user experience.
5. Data Management and Consistency in Event Driven Microservices
5.1 Managing Distributed Data with Eventual Consistency
In a microservices architecture, especially one designed for high concurrency and event-driven communication, managing distributed data consistently is a major challenge. Unlike monolithic systems where a single database can enforce strong consistency, distributed systems often embrace eventual consistency to achieve scalability, availability, and fault tolerance.
What is Eventual Consistency?
Eventual consistency is a consistency model used in distributed computing to achieve high availability. It guarantees that, given enough time without new updates, all replicas of data will converge to the same value.
- Strong consistency: All nodes see the same data at the same time.
- Eventual consistency: Nodes may temporarily have different data, but will converge eventually.
Why Eventual Consistency in Microservices?
- Scalability: Allows services to operate independently without waiting for synchronous locks.
- Availability: Systems remain responsive even if some nodes are temporarily unreachable.
- Performance: Reduces latency by avoiding distributed transactions.
Mind Map: Key Concepts of Eventual Consistency
Managing Distributed Data: Best Practices
Design for Idempotency
Ensure that event handlers and commands can be retried safely without causing inconsistent states.
Example:
// Example of idempotent event handler in Java
public void handleOrderCreatedEvent(OrderCreatedEvent event) {
if (orderRepository.exists(event.getOrderId())) {
// Already processed
return;
}
// Process order creation
orderRepository.save(event.getOrder());
}
Use Event Sourcing
Store state changes as a sequence of events rather than overwriting the current state.
Example:
- UserAccountCreated
- UserEmailUpdated
- UserPasswordChanged
Replaying these events reconstructs the current state.
Implement Conflict Resolution Strategies
- Last Write Wins (LWW): The latest timestamped event overwrites previous data.
- Custom Merging: Domain-specific logic to merge conflicting updates.
Embrace Asynchronous Communication
Use message brokers to decouple services and allow eventual propagation of updates.
Example Scenario: Inventory and Order Microservices
Two microservices:
- Order Service: Receives orders.
- Inventory Service: Manages stock levels.
Problem: When an order is placed, inventory must be updated. Strong consistency would require a distributed transaction, which hurts scalability.
Solution: Use eventual consistency with events.
- Order Service emits an
OrderPlacedevent. - Inventory Service consumes the event asynchronously and updates stock.
- If stock is insufficient, Inventory Service emits an
InventoryShortageevent. - Order Service listens and triggers compensating actions (e.g., cancel order).
flowchart LR
A[Order Service] -->|OrderPlaced Event| B(Inventory Service)
B -->|InventoryShortage Event| A
This pattern allows both services to operate independently and scale, accepting temporary inconsistencies.
Mind Map: Eventual Consistency Workflow in Microservices
Monitoring and Observability Tips
- Track event lag times to detect delays in eventual consistency.
- Use distributed tracing to follow event flows across services.
- Monitor conflict rates and compensating transaction occurrences.
Summary
Managing distributed data with eventual consistency is essential for scalable, high concurrency microservices. By designing idempotent handlers, leveraging event sourcing, and embracing asynchronous communication, systems can maintain data integrity without sacrificing performance.
Understanding and implementing these patterns with observability in mind ensures robust and maintainable microservices ecosystems.
5.2 Saga Pattern for Distributed Transactions: Concepts and Examples
Introduction
In microservices architectures, managing distributed transactions across multiple services is challenging due to the lack of a single ACID transaction boundary. The Saga pattern offers a way to maintain data consistency by breaking a large transaction into a series of smaller, manageable local transactions coordinated through events or commands.
What is the Saga Pattern?
A Saga is a sequence of local transactions where each transaction updates data within a single service and publishes an event or triggers the next transaction in the saga. If one transaction fails, compensating transactions are executed to undo the changes made by preceding transactions, ensuring eventual consistency.
Types of Saga Coordination
- Choreography-based Saga: Each service produces and listens to events and decides when to act and what to do next.
- Orchestration-based Saga: A centralized orchestrator directs the saga by invoking local transactions and triggering compensations when necessary.
Mind Map: Saga Pattern Overview
How Saga Works: Step-by-Step Example
Imagine an e-commerce order processing system with three microservices:
- Order Service: Creates and manages orders
- Payment Service: Handles payment processing
- Inventory Service: Manages stock levels
Scenario: Place an order, charge payment, and reserve inventory.
Saga Steps:
- Order Service creates an order and emits
OrderCreatedevent. - Payment Service listens to
OrderCreated, processes payment, and emitsPaymentProcessedevent. - Inventory Service listens to
PaymentProcessed, reserves inventory, and emitsInventoryReservedevent. - Order Service listens to
InventoryReservedand marks the order as completed.
If any step fails (e.g., payment fails), compensating transactions are triggered:
- If payment fails, Order Service cancels the order.
- If inventory reservation fails, Payment Service issues a refund.
Mind Map: Order Processing Saga
Code Example: Orchestration-Based Saga (Simplified Pseudocode)
// Saga Orchestrator
public class OrderSagaOrchestrator {
public void handleOrderCreated(Order order) {
try {
paymentService.processPayment(order);
inventoryService.reserveInventory(order);
orderService.completeOrder(order);
} catch (PaymentException e) {
orderService.cancelOrder(order);
} catch (InventoryException e) {
paymentService.refundPayment(order);
orderService.cancelOrder(order);
}
}
}
Code Example: Choreography-Based Saga (Event-Driven)
// Order Service
public void createOrder(Order order) {
saveOrder(order);
eventBus.publish(new OrderCreatedEvent(order.getId()));
}
// Payment Service
@EventListener
public void onOrderCreated(OrderCreatedEvent event) {
try {
processPayment(event.getOrderId());
eventBus.publish(new PaymentProcessedEvent(event.getOrderId()));
} catch (Exception e) {
eventBus.publish(new PaymentFailedEvent(event.getOrderId()));
}
}
// Inventory Service
@EventListener
public void onPaymentProcessed(PaymentProcessedEvent event) {
try {
reserveInventory(event.getOrderId());
eventBus.publish(new InventoryReservedEvent(event.getOrderId()));
} catch (Exception e) {
eventBus.publish(new InventoryFailedEvent(event.getOrderId()));
}
}
// Order Service listens for compensation events
@EventListener
public void onPaymentFailed(PaymentFailedEvent event) {
cancelOrder(event.getOrderId());
}
@EventListener
public void onInventoryFailed(InventoryFailedEvent event) {
refundPayment(event.getOrderId());
cancelOrder(event.getOrderId());
}
Best Practices for Implementing Saga Pattern
- Design clear compensating transactions: Each local transaction must have a reliable undo operation.
- Idempotency: Ensure all transactions and compensations are idempotent to handle retries safely.
- Event versioning: Manage schema changes carefully to avoid breaking event consumers.
- Timeouts and retries: Implement timeouts and retry policies for robustness.
- Monitoring and observability: Track saga progress and failures using distributed tracing and logs.
Mind Map: Saga Best Practices
Summary
The Saga pattern is a powerful approach to manage distributed transactions in microservices by leveraging local transactions and compensations coordinated either via orchestration or choreography. Proper design, idempotency, and observability are key to building reliable, scalable, and maintainable high concurrency systems using this pattern.
5.3 Designing Compensating Actions for Failure Recovery
In distributed microservices architectures, especially those employing event-driven designs, failures are inevitable. Unlike monolithic systems, where transactions can be rolled back atomically, distributed systems require a different approach to maintain data consistency and system reliability. This is where compensating actions come into play.
What are Compensating Actions?
Compensating actions are operations that semantically undo the effects of a previously completed action when a failure occurs later in a distributed transaction or saga. Instead of rolling back a transaction, you perform a compensating transaction that reverses or mitigates the impact of the original operation.
Why Use Compensating Actions?
- No Distributed ACID Transactions: Distributed systems often avoid two-phase commits due to performance and scalability concerns.
- Eventual Consistency: Systems accept temporary inconsistencies and resolve them over time.
- Failure Recovery: Enables graceful handling of partial failures in long-running business processes.
Key Principles for Designing Compensating Actions
- Idempotency: Compensating actions should be idempotent to handle retries safely.
- Business Semantics: The compensation must make sense in the business context (e.g., refunding a payment).
- Ordering: Compensations must be executed in the reverse order of the original actions.
- Isolation: Ensure compensations do not interfere with unrelated operations.
Mind Map: Designing Compensating Actions
Example Scenario: Order and Payment Microservices
Imagine a simplified e-commerce flow:
- Order Service: Creates an order and reserves inventory.
- Payment Service: Charges the customer.
- Shipping Service: Ships the order.
If the payment fails after the order is created and inventory reserved, the system must compensate by releasing the reserved inventory.
Step-by-Step Compensation Design
| Step | Action | Compensating Action |
|---|---|---|
| 1 | Reserve Inventory | Release Inventory Reservation |
| 2 | Charge Payment | Refund Payment |
| 3 | Ship Order | Initiate Return or Cancel Shipment |
In this example, if payment fails, the compensating action is to release the inventory reservation.
Code Example: Idempotent Compensating Action in Inventory Service (Node.js/Express)
// Inventory Service - Compensate reservation
app.post('/inventory/release', async (req, res) => {
const { reservationId } = req.body;
// Idempotency check: Has this reservation already been released?
const existing = await db.findReleaseByReservationId(reservationId);
if (existing) {
return res.status(200).send({ message: 'Reservation already released' });
}
// Release inventory
await db.releaseInventory(reservationId);
// Record the release to prevent duplicate compensation
await db.recordRelease(reservationId);
res.status(200).send({ message: 'Inventory released successfully' });
});
Mind Map: Idempotent Compensating Action Implementation
Handling Complex Failure Scenarios
- Partial Failures: If compensation itself fails, implement retry mechanisms with exponential backoff.
- Timeouts: Define timeouts for compensations to avoid indefinite retries.
- Monitoring: Use observability tools to track compensation success/failure.
Example: Saga Orchestration with Compensating Actions
sequenceDiagram
participant Order as Order Service
participant Payment as Payment Service
participant Inventory as Inventory Service
Order->>Inventory: Reserve Inventory
Inventory-->>Order: Reservation Confirmed
Order->>Payment: Charge Payment
Payment-->>Order: Payment Failed
Order->>Inventory: Release Inventory (Compensation)
Inventory-->>Order: Inventory Released
Best Practices Summary
- Design compensating actions as first-class citizens when modeling your business processes.
- Ensure compensations are idempotent and safe to retry.
- Use saga orchestration or choreography to manage compensation flows.
- Test compensations thoroughly under failure conditions.
- Monitor compensations in production to detect issues early.
By carefully designing compensating actions, you can build resilient, fault-tolerant microservices that gracefully handle failures without sacrificing scalability or performance.
5.4 Example: Implementing a Saga for Inventory and Order Coordination
In a microservices architecture, coordinating distributed transactions across multiple services can be challenging, especially when aiming for eventual consistency. The Saga pattern offers a robust solution by breaking down a transaction into a sequence of local transactions, each with its own compensating action in case of failure.
This section walks through a practical example of implementing a Saga to coordinate between an Order Service and an Inventory Service.
Scenario Overview
- Order Service: Responsible for creating and managing customer orders.
- Inventory Service: Manages stock levels for products.
Goal: When a customer places an order, the system should:
- Reserve inventory for the ordered items.
- Confirm the order if inventory reservation succeeds.
- If inventory reservation fails, cancel the order.
If any step fails, the Saga ensures compensating actions are triggered to maintain consistency.
Saga Workflow Mind Map
Implementation Details
Defining Events
The Saga relies on events to communicate state changes between services asynchronously.
| Event Name | Description | Payload Example |
|---|---|---|
OrderCreated | Order has been created | { orderId, items, status: 'Pending' } |
InventoryReserved | Inventory successfully reserved | { orderId, items } |
InventoryReservationFailed | Inventory reservation failed | { orderId, reason } |
OrderConfirmed | Order confirmed | { orderId, status: 'Confirmed' } |
OrderCancelled | Order cancelled | { orderId, reason } |
Order Service Pseudocode
class OrderService:
def create_order(self, order_data):
order = self._save_order(order_data, status='Pending')
self._publish_event('OrderCreated', order)
def on_inventory_reserved(self, event):
order = self._get_order(event.orderId)
try:
order.status = 'Confirmed'
self._update_order(order)
self._publish_event('OrderConfirmed', order)
except Exception as e:
self._publish_event('OrderCancelled', {'orderId': order.id, 'reason': str(e)})
def on_inventory_reservation_failed(self, event):
order = self._get_order(event.orderId)
order.status = 'Cancelled'
self._update_order(order)
self._publish_event('OrderCancelled', {'orderId': order.id, 'reason': event.reason})
Inventory Service Pseudocode
class InventoryService:
def on_order_created(self, event):
try:
self._reserve_stock(event.items)
self._publish_event('InventoryReserved', {'orderId': event.orderId, 'items': event.items})
except OutOfStockError as e:
self._publish_event('InventoryReservationFailed', {'orderId': event.orderId, 'reason': str(e)})
Mind Map: Compensating Transactions
Best Practices Illustrated
- Idempotency: Each event handler should be idempotent to safely handle retries without side effects.
- Event Ordering: Use event versioning or sequence numbers to ensure correct processing order.
- Timeouts: Implement timeouts and retries for long-running transactions.
- Observability: Emit logs and traces for each step to facilitate debugging.
Extended Example: Using a Saga Orchestrator
Instead of relying solely on event chaining, a Saga orchestrator service can coordinate the workflow explicitly.
class SagaOrchestrator:
def handle_order_created(self, event):
success = inventory_service.reserve_stock(event.orderId, event.items)
if success:
order_service.confirm_order(event.orderId)
else:
order_service.cancel_order(event.orderId, reason='Inventory reservation failed')
This approach centralizes Saga logic and can simplify complex workflows.
Summary
Implementing a Saga for inventory and order coordination ensures data consistency across distributed services without locking resources globally. By designing clear event contracts, compensating transactions, and leveraging asynchronous messaging, you can build resilient, scalable microservices that handle high concurrency gracefully.
5.5 Best Practice: Using Change Data Capture (CDC) for Event Generation
Change Data Capture (CDC) is a powerful technique to capture and propagate data changes from your databases to downstream systems, such as microservices, in near real-time. Leveraging CDC for event generation in event-driven microservices architectures ensures data consistency, reduces coupling, and improves scalability.
What is Change Data Capture (CDC)?
CDC is a pattern that detects and captures changes (inserts, updates, deletes) in a database and streams these changes as events to other systems. This enables microservices to react to data changes asynchronously without polling or tight coupling.
Why Use CDC for Event Generation?
- Decoupling: Microservices do not need to directly query or update each other’s databases.
- Real-time Eventing: Changes are captured and propagated immediately.
- Data Consistency: Events reflect actual committed database changes.
- Reduced Complexity: Avoids manual event generation logic in application code.
CDC Workflow Mind Map
Common CDC Tools and Technologies
| Tool | Description | Supported Databases |
|---|---|---|
| Debezium | Open-source CDC platform built on Kafka Connect | MySQL, PostgreSQL, MongoDB, SQL Server, Oracle |
| Maxwell’s Daemon | Lightweight CDC tool that streams MySQL binlog | MySQL |
| AWS DMS | Managed CDC service on AWS | Multiple AWS-supported DBs |
Example: Using Debezium to Capture MySQL Changes and Publish to Kafka
Step 1: Setup Debezium Connector
Configure Debezium to monitor your MySQL database’s binlog and publish change events to Kafka topics.
{
"name": "mysql-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql-host",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "orders_db",
"table.include.list": "orders_db.orders",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.orders"
}
}
Step 2: Event Generation
When a new order is inserted or updated in the orders table, Debezium captures this change and publishes a corresponding event to the Kafka topic dbserver1.orders_db.orders.
Step 3: Microservice Consumes Events
Your order processing microservice subscribes to the Kafka topic and reacts to these events asynchronously.
public void onOrderChange(ConsumerRecord<String, String> record) {
// Deserialize event
OrderEvent event = deserialize(record.value());
// Process event
if (event.getOperation().equals("c")) { // 'c' for create
processNewOrder(event.getOrderData());
} else if (event.getOperation().equals("u")) { // 'u' for update
updateOrder(event.getOrderData());
}
}
CDC Implementation Mind Map
Best Practices for Using CDC in Event Generation
-
Design Clear Event Schemas: Include metadata such as operation type, timestamps, and before/after states to enable consumers to handle events correctly.
-
Ensure Idempotency: Since events can be delivered multiple times, design consumers to handle duplicate events gracefully.
-
Monitor CDC Pipelines: Use observability tools to track CDC lag, failures, and throughput.
-
Handle Schema Evolution: Use schema registries (e.g., Confluent Schema Registry) to manage changes in event schemas.
-
Secure Data Streams: Encrypt data in transit and authenticate CDC connectors and consumers.
Example: Handling Idempotency in Event Consumers
public void processNewOrder(OrderData order) {
if (orderRepository.existsById(order.getId())) {
// Duplicate event, ignore
return;
}
orderRepository.save(order);
}
Summary
Using CDC for event generation in high concurrency microservices architectures enables real-time, consistent, and loosely coupled communication between services. By capturing database changes directly and streaming them as events, CDC reduces complexity and improves scalability. Integrating CDC with robust event brokers and observability practices ensures a resilient and maintainable system.
References & Further Reading
- Debezium Documentation
- Event Sourcing and CQRS with CDC
- Designing Idempotent Event Handlers
- Kafka Connect CDC Source Connectors
6. Ensuring Performance and Scalability under High Load
6.1 Load Testing Strategies for Event Driven Microservices
Load testing is a critical step in validating that your event driven microservices can handle high concurrency and peak loads without degradation or failure. Unlike traditional request-response systems, event driven architectures introduce asynchronous flows and decoupled components, which require specialized load testing strategies.
Key Objectives of Load Testing in Event Driven Microservices
- Validate throughput: Ensure the system can process the expected volume of events per second.
- Measure latency: Track end-to-end processing delays from event production to consumption.
- Detect bottlenecks: Identify slow components such as event brokers, consumers, or databases.
- Test resilience: Observe behavior under load spikes, failures, and backpressure.
- Verify scalability: Confirm horizontal scaling strategies effectively increase capacity.
Mind Map: Load Testing Focus Areas
Synthetic Event Generation
To simulate load, create synthetic event producers that mimic real-world event patterns. This can be done by:
- Writing custom scripts or microservices that publish events at configurable rates.
- Using load testing tools integrated with event brokers (e.g., Kafka Producer API).
- Replaying historical production event logs to simulate realistic traffic.
Example: Using a Python Kafka producer to generate 1000 events per second with randomized payloads.
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
topic = 'order-events'
def generate_order_event():
return {
'order_id': random.randint(1000, 9999),
'status': 'created',
'timestamp': time.time()
}
rate_per_sec = 1000
interval = 1.0 / rate_per_sec
while True:
event = generate_order_event()
producer.send(topic, event)
time.sleep(interval)
Load Injection Points
Load can be injected at different points:
- At the event broker: Push events directly to the broker to test ingestion capacity.
- At the microservice consumers: Simulate downstream processing load by invoking consumer endpoints or triggering event handlers.
- At downstream systems: Test database or cache performance under event-driven load.
Best Practice: Start by load testing the event broker independently, then progressively include microservices and downstream components.
Load Patterns
- Steady Load: Maintain a constant event rate to observe system behavior under normal conditions.
- Spike Testing: Introduce sudden bursts of events to test system elasticity and backpressure handling.
- Soak Testing: Run prolonged load tests to detect memory leaks, resource exhaustion, or degradation over time.
Mind Map: Load Patterns and Their Purpose
Metrics to Monitor During Load Testing
- Throughput: Number of events processed per second.
- Latency: Time from event production to final processing.
- Error Rates: Failed event processing or dropped messages.
- Resource Utilization: CPU, memory, disk I/O, network bandwidth.
- Queue Lengths: Size of event queues or topics to detect bottlenecks.
Example: Using Prometheus metrics exported by microservices and Kafka brokers to track these metrics in Grafana dashboards.
Tools and Frameworks
- Apache JMeter: Can be extended with plugins or scripts to produce events to brokers.
- Gatling: Useful for HTTP-based microservices; can be adapted for event producers.
- K6: Modern load testing tool with scripting for custom event generation.
- Custom Scripts: Often necessary for fine-grained control over event payloads and timing.
Example Scenario: Load Testing an Order Processing Microservice
Setup:
- Kafka as the event broker.
- Order microservice consumes ‘order-created’ events.
- Downstream inventory and payment services.
Steps:
- Use a custom Kafka producer script to generate 5000 ‘order-created’ events per second.
- Monitor Kafka broker throughput and consumer lag.
- Observe microservice CPU and memory usage.
- Track end-to-end latency from event publish to order confirmation.
- Introduce a spike of 10,000 events per second for 1 minute to test resilience.
- Analyze logs and metrics for errors or slowdowns.
Outcome:
- Identify if consumers keep up or lag behind.
- Detect if backpressure mechanisms trigger.
- Adjust consumer parallelism or broker partitions accordingly.
Summary
Load testing event driven microservices requires a holistic approach that covers event generation, injection points, realistic load patterns, and comprehensive metrics monitoring. By combining synthetic event producers, targeted load injection, and observability tools, engineers can ensure their microservices architecture meets high concurrency demands reliably and efficiently.
6.2 Horizontal Scaling of Microservices and Event Brokers
Horizontal scaling is a fundamental technique to handle high concurrency by adding more instances of microservices or event brokers rather than increasing the capacity of a single instance (vertical scaling). This approach improves fault tolerance, availability, and throughput.
Why Horizontal Scaling?
- Elasticity: Dynamically add or remove instances based on load.
- Fault Isolation: Failure in one instance doesn’t bring down the entire system.
- Improved Throughput: Distribute workload across multiple nodes.
Horizontal Scaling of Microservices
Microservices are designed to be stateless or manage state externally, making them ideal candidates for horizontal scaling.
Key Strategies:
- Statelessness: Ensure services do not store session or user-specific data locally.
- Load Balancing: Use load balancers (e.g., NGINX, HAProxy, or cloud provider solutions) to distribute incoming requests evenly.
- Service Discovery: Dynamic discovery of service instances (e.g., Consul, Eureka) to route traffic correctly.
- Container Orchestration: Use Kubernetes or Docker Swarm to manage scaling automatically.
Example: Scaling a User Authentication Service
# Kubernetes Horizontal Pod Autoscaler example
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: auth-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: auth-service
minReplicas: 3
maxReplicas: 15
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
This configuration automatically scales the auth-service pods between 3 and 15 based on CPU utilization.
Horizontal Scaling of Event Brokers
Event brokers are the backbone of event driven architectures, and scaling them horizontally is critical to handle high event throughput.
Popular Event Brokers Supporting Horizontal Scaling:
- Apache Kafka: Partitioned topics allow parallel consumption.
- RabbitMQ: Clustering and federation for distributing load.
- Amazon Kinesis: Shard-based scaling.
Key Concepts:
- Partitioning: Splitting topics/queues into partitions or shards.
- Replication: Duplicating partitions across nodes for fault tolerance.
- Consumer Groups: Multiple consumers read from partitions in parallel.
Example: Kafka Horizontal Scaling
Practical Example:
- Topic
ordersinitially has 3 partitions. - To handle increased load, increase partitions to 12.
- Add 4 Kafka brokers to distribute partitions.
- Consumers in a group scale from 3 to 12 to match partitions.
This setup allows 12 parallel event streams, improving throughput.
Mind Map: Horizontal Scaling Overview
Best Practices for Horizontal Scaling
- Design for Statelessness: Avoid local state; use external stores like Redis or databases.
- Automate Scaling: Use orchestration tools and autoscalers.
- Monitor Load and Performance: Use metrics to trigger scaling events.
- Partition Thoughtfully: Choose partition keys that evenly distribute load.
- Graceful Shutdown: Ensure instances can drain in-flight requests/events before termination.
Summary
Horizontal scaling of microservices and event brokers is essential to support high concurrency workloads. By leveraging stateless service design, load balancing, container orchestration, and partitioned event brokers like Kafka, systems can elastically grow to meet demand while maintaining resilience and performance.
6.3 Optimizing Event Processing Pipelines with Parallelism
In high concurrency microservices architectures, event processing pipelines often become bottlenecks if not designed to leverage parallelism effectively. Optimizing these pipelines ensures that events are processed quickly, reliably, and at scale, enabling your system to handle peak loads without degradation.
Why Parallelism Matters in Event Processing
- Throughput: Parallel processing increases the number of events handled per unit time.
- Latency Reduction: Concurrent handling reduces wait times for individual events.
- Resource Utilization: Efficiently uses CPU cores and distributed resources.
- Fault Isolation: Failures in one parallel path don’t block others.
Key Concepts in Parallel Event Processing
Parallelism Techniques Explained
-
Partitioning and Sharding
- Split event streams based on keys (e.g., userId, orderId).
- Events with the same key go to the same partition to preserve order.
- Example: Kafka partitions events by key, allowing multiple consumers to process partitions in parallel.
-
Consumer Groups
- Multiple consumers subscribe to the same topic.
- Kafka assigns partitions to consumers, enabling parallel consumption.
-
Thread Pools and Async Processing
- Within a microservice, use thread pools or async frameworks (e.g., Java’s CompletableFuture, Node.js async/await) to process multiple events concurrently.
-
Pipeline Parallelism
- Break event processing into stages (e.g., validation, enrichment, persistence).
- Each stage can be processed in parallel or distributed across services.
Mind Map: Parallelism Techniques in Event Pipelines
Example: Parallel Processing with Kafka Consumer Groups
// Java example using KafkaConsumer with multiple threads
public class ParallelKafkaConsumer {
private final KafkaConsumer<String, String> consumer;
private final ExecutorService executor;
public ParallelKafkaConsumer(Properties props, int threadCount) {
this.consumer = new KafkaConsumer<>(props);
this.executor = Executors.newFixedThreadPool(threadCount);
}
public void startConsuming(String topic) {
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
executor.submit(() -> processEvent(record));
}
}
}
private void processEvent(ConsumerRecord<String, String> record) {
// Event processing logic here
System.out.println("Processing event: " + record.value());
}
}
This example demonstrates how to consume Kafka events and process them concurrently using a thread pool. Each event is submitted as a separate task, enabling parallelism.
Example: Async Event Processing in Node.js
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ clientId: 'my-app', brokers: ['kafka:9092'] });
const consumer = kafka.consumer({ groupId: 'event-group' });
async function run() {
await consumer.connect();
await consumer.subscribe({ topic: 'events', fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
processEvent(message.value.toString());
},
});
}
async function processEvent(event) {
// Simulate async processing
await new Promise(resolve => setTimeout(resolve, 100));
console.log(`Processed event: ${event}`);
}
run().catch(console.error);
This Node.js example uses KafkaJS to consume messages asynchronously, processing multiple events in parallel as Kafka distributes partitions among consumers.
Best Practices for Parallel Event Processing
- Preserve Ordering When Needed: Use partition keys to ensure events that require ordering are processed sequentially.
- Idempotent Handlers: Design event handlers to be idempotent to safely retry or process events out of order.
- Monitor Thread/Consumer Utilization: Avoid thread starvation or consumer lag by tuning thread pools and consumer counts.
- Backpressure Handling: Implement mechanisms to slow down producers or buffer events if consumers are overwhelmed.
- State Management: For stateful processing, consider using state stores or external databases designed for concurrency.
Mind Map: Best Practices for Parallelism
Summary
Optimizing event processing pipelines with parallelism is essential for building scalable, high concurrency microservices. By leveraging partitioning, consumer groups, asynchronous processing, and pipeline stages, you can maximize throughput and minimize latency. Coupled with best practices like preserving ordering and designing idempotent handlers, your event-driven system will be robust and performant under heavy load.
6.4 Example: Scaling Kafka Consumers for Peak Traffic
Scaling Kafka consumers effectively is critical to maintaining high throughput and low latency in event-driven microservices, especially under peak traffic conditions. This section walks through practical strategies and examples to scale Kafka consumers, ensuring your system remains performant and resilient.
Understanding Kafka Consumer Scaling
Kafka consumers can be scaled horizontally by adding more consumer instances to a consumer group. Kafka partitions the topic, and each partition is consumed by only one consumer instance within the same group, enabling parallel processing.
Key Concepts
- Partitions: Kafka topics are divided into partitions to allow parallel consumption.
- Consumer Group: A set of consumers sharing the same group ID; partitions are assigned to consumers in the group.
- Offset: Position of the consumer in the partition; used for tracking consumption progress.
Step 1: Assess Current Throughput and Partition Count
Before scaling, evaluate the current throughput and number of partitions.
kafka-topics.sh --describe --topic your-topic --bootstrap-server kafka-broker:9092
Example output:
Topic: your-topic PartitionCount: 6 ReplicationFactor: 3 Configs: ...
More partitions allow more parallelism but come with trade-offs in complexity.
Step 2: Increase Partitions (If Needed)
If your topic has fewer partitions than the number of consumers you want to run, increase partitions:
kafka-topics.sh --alter --topic your-topic --partitions 12 --bootstrap-server kafka-broker:9092
Note: Increasing partitions can affect message ordering guarantees.
Step 3: Scale Consumer Instances Horizontally
Deploy additional consumer instances with the same group ID. Kafka will rebalance partitions across consumers.
Example: Using Spring Boot Kafka consumer configuration snippet:
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(6); // Number of threads consuming in parallel
return factory;
}
This example sets concurrency to 6, meaning 6 threads will consume partitions in parallel within a single consumer instance.
Step 4: Optimize Consumer Configuration
Tune consumer properties for peak performance:
| Property | Recommended Setting | Description |
|---|---|---|
max.poll.records | 500-1000 | Number of records fetched per poll |
fetch.min.bytes | 1MB or higher | Minimum bytes to fetch per request |
fetch.max.wait.ms | 50-100 ms | Max wait time for fetching data |
session.timeout.ms | 10000 ms | Consumer group session timeout |
heartbeat.interval.ms | 3000 ms | Interval for sending heartbeat to broker |
Example consumer config snippet:
max.poll.records=1000
fetch.min.bytes=1048576
fetch.max.wait.ms=100
session.timeout.ms=10000
heartbeat.interval.ms=3000
Step 5: Monitor Consumer Lag and Throughput
Use Kafka monitoring tools or Prometheus exporters to track consumer lag and throughput.
Example Prometheus query for consumer lag:
kafka_consumergroup_lag{consumergroup="order-service-group"}
Step 6: Handle Rebalancing Efficiently
Rebalancing can cause consumer downtime. To minimize impact:
- Use sticky partition assignment to reduce partition movement.
- Increase session.timeout.ms to avoid premature rebalances.
- Implement pause/resume in consumers to control processing during rebalance.
Example: Enabling sticky assignor in consumer config:
partition.assignment.strategy=org.apache.kafka.clients.consumer.StickyAssignor
Step 7: Example Scenario - Scaling an Order Processing Microservice
Context: An order processing microservice consumes order events from Kafka. During peak sales, traffic spikes 5x.
Initial Setup:
- Topic partitions: 6
- Consumer instances: 2
- Consumer concurrency: 3 (total 6 threads)
Scaling Steps:
- Increase partitions to 12 to allow more parallelism.
- Deploy 4 consumer instances, each with concurrency 3 (total 12 threads).
- Tune consumer configs for higher throughput.
- Monitor lag and adjust as needed.
Code snippet for consumer concurrency:
factory.setConcurrency(3);
Result: The system handles peak traffic with reduced lag and improved throughput.
Summary Mind Map
By following these steps and best practices, you can effectively scale Kafka consumers to handle peak traffic in your event-driven microservices, ensuring high concurrency, low latency, and system resilience.
6.5 Best Practice: Using Rate Limiting and Throttling to Protect Services
In high concurrency microservices architectures, protecting your services from overload is critical to maintaining system stability, responsiveness, and overall user experience. Rate limiting and throttling are essential techniques to control the flow of requests and events, preventing resource exhaustion and cascading failures.
What Are Rate Limiting and Throttling?
- Rate Limiting: A strategy to limit the number of requests a client or service can make within a specified time window.
- Throttling: Temporarily restricting or delaying requests when a system is under heavy load to prevent overload.
Both techniques help maintain service availability and prevent abuse or accidental spikes.
Why Use Rate Limiting and Throttling in Event Driven Microservices?
- Protect downstream services and databases from being overwhelmed by sudden bursts.
- Ensure fair usage among clients or internal services.
- Maintain predictable performance and latency.
- Prevent cascading failures in distributed systems.
Mind Map: Concepts and Components of Rate Limiting and Throttling
Common Rate Limiting Algorithms
| Algorithm | Description | Use Case Example |
|---|---|---|
| Fixed Window | Limits requests in fixed time intervals (e.g., 100 requests per minute). | Simple APIs with predictable traffic. |
| Sliding Window | More precise, counts requests in a rolling window to avoid spikes at edges. | Real-time APIs needing smooth limits. |
| Token Bucket | Tokens are added at a fixed rate; requests consume tokens. | Bursty traffic with smoothing needed. |
| Leaky Bucket | Requests are processed at a fixed rate, excess are queued or dropped. | Streaming or event processing systems. |
Example: Implementing Rate Limiting with Token Bucket in a Node.js Microservice
const rateLimit = require('express-rate-limit');
// Token Bucket style rate limiter: 10 requests per 10 seconds
const limiter = rateLimit({
windowMs: 10 * 1000, // 10 seconds
max: 10, // limit each IP to 10 requests per windowMs
message: 'Too many requests, please try again later.',
standardHeaders: true, // Return rate limit info in the `RateLimit-*` headers
legacyHeaders: false,
});
const express = require('express');
const app = express();
app.use('/api/', limiter);
app.get('/api/orders', (req, res) => {
res.send('Order list');
});
app.listen(3000, () => {
console.log('Server running on port 3000');
});
This example protects the /api/orders endpoint by limiting each client IP to 10 requests every 10 seconds.
Throttling Example: Delaying Event Processing in Kafka Consumer
In event-driven microservices, throttling can be applied when consuming events from brokers like Kafka to avoid overwhelming downstream services.
public class ThrottledConsumer {
private final int maxEventsPerSecond = 100;
private long lastCheckTime = System.currentTimeMillis();
private int eventCount = 0;
public void consume(Event event) throws InterruptedException {
long now = System.currentTimeMillis();
if (now - lastCheckTime > 1000) {
eventCount = 0;
lastCheckTime = now;
}
if (eventCount >= maxEventsPerSecond) {
// Throttle: sleep to delay processing
Thread.sleep(1000 - (now - lastCheckTime));
eventCount = 0;
lastCheckTime = System.currentTimeMillis();
}
processEvent(event);
eventCount++;
}
private void processEvent(Event event) {
// Business logic here
}
}
This simple throttling logic ensures no more than 100 events are processed per second.
Integrating Rate Limiting at Different Layers
Handling Rate Limit Exceedance Gracefully
- Return HTTP 429 (Too Many Requests) with Retry-After header.
- Provide meaningful error messages to clients.
- Implement exponential backoff on client side.
- Use circuit breakers to isolate overloaded services.
Observability for Rate Limiting and Throttling
- Track number of requests rejected due to limits.
- Monitor latency and error rates during throttling.
- Alert on unusual spikes in throttled requests.
Summary
Rate limiting and throttling are vital best practices to protect microservices in high concurrency environments. By carefully selecting algorithms, integrating controls at appropriate layers, and monitoring their effects, you can ensure your system remains resilient, fair, and performant under load.
7. Observability in High Concurrency Microservices
7.1 Fundamentals of Observability: Metrics, Logs, and Traces
Observability is a critical aspect of designing and operating high concurrency microservices, especially when leveraging event driven architecture. It enables engineers to understand system behavior, diagnose issues quickly, and optimize performance effectively. Observability is primarily achieved through three pillars: Metrics, Logs, and Traces. Each provides a different perspective on the system’s internal state and interactions.
What is Observability?
Observability is the ability to infer the internal state of a system based on the data it produces externally. In microservices, especially those handling high concurrency and asynchronous events, observability helps to answer questions like:
- How is my system performing under load?
- Where are the bottlenecks or failures occurring?
- How do requests flow through distributed components?
The Three Pillars of Observability
Metrics
Metrics are numerical measurements collected over time that provide quantitative insights into system performance and health.
- Characteristics: Aggregated, numeric, time-series data.
- Examples: CPU usage, request rate, error rate, latency percentiles.
Example:
# Prometheus metric example for HTTP request latency
http_request_duration_seconds_bucket{le="0.1",method="POST",endpoint="/order"} 2400
http_request_duration_seconds_bucket{le="0.5",method="POST",endpoint="/order"} 5300
http_request_duration_seconds_bucket{le="1",method="POST",endpoint="/order"} 7000
Best Practice: Use meaningful labels (e.g., service name, endpoint, status code) to slice and dice metrics.
Logs
Logs are timestamped, unstructured or semi-structured text records that capture discrete events or messages emitted by the system.
- Characteristics: Detailed, event-driven, human-readable.
- Examples: Error messages, warnings, info about state changes.
Example:
{
"timestamp": "2024-06-01T12:34:56Z",
"level": "ERROR",
"service": "payment-service",
"message": "Payment processing failed",
"orderId": "12345",
"errorCode": "INSUFFICIENT_FUNDS"
}
Best Practice: Structure logs in JSON format for easier parsing and querying.
Traces
Traces represent the journey of a single request or event as it propagates through multiple services, capturing timing and causal relationships.
- Characteristics: Distributed, causal, time-correlated.
- Examples: Span start/end times, parent-child relationships, metadata.
Example:
TraceID: 4bf92f3577b34da6a3ce929d0e0e4736
Span 1: API Gateway received request (start: 12:00:00, duration: 10ms)
Span 2: Auth Service validated token (start: 12:00:01, duration: 5ms)
Span 3: Order Service processed order (start: 12:00:06, duration: 50ms)
Best Practice: Use distributed tracing tools like OpenTelemetry, Jaeger, or Zipkin to visualize and analyze traces.
Mind Map: Overview of Observability Pillars
Why All Three Pillars Are Needed Together
| Pillar | Strengths | Limitations | Complementary Role |
|---|---|---|---|
| Metrics | Quick overview, trend analysis | Lack of context/detail | Alerts and dashboards |
| Logs | Detailed event info, debugging | Hard to aggregate at scale | Deep dive into specific incidents |
| Traces | Visualize request flow, latency | Can be complex to instrument | Understand cross-service interactions |
Together, they provide a comprehensive view that enables rapid detection, diagnosis, and resolution of issues in high concurrency microservices.
Example Scenario: Observability in a High Concurrency Order Processing Microservice
Imagine a microservice handling thousands of concurrent order requests.
- Metrics: Track request throughput, error rates, and average processing latency.
- Logs: Capture errors like payment failures or inventory shortages with order IDs.
- Traces: Follow a single order request from API gateway through payment, inventory, and notification services.
This combined observability approach helps engineers pinpoint if a latency spike is due to payment service slowness or a downstream notification bottleneck.
Summary
- Observability is essential for understanding and maintaining high concurrency microservices.
- Metrics provide quantitative performance data.
- Logs offer detailed event context.
- Traces reveal the flow and timing of distributed requests.
- Using all three pillars in concert enables robust monitoring, troubleshooting, and optimization.
Further Reading & Tools
- OpenTelemetry - Standard for metrics, logs, and traces instrumentation.
- Prometheus - Popular metrics collection and alerting system.
- ELK Stack (Elasticsearch, Logstash, Kibana) - Log aggregation and analysis.
- Jaeger - Distributed tracing system.
7.2 Instrumenting Event Driven Systems for Visibility
Instrumenting event driven systems is critical to gain deep visibility into asynchronous workflows, event flows, and microservice interactions. Proper instrumentation enables effective monitoring, debugging, and performance optimization in high concurrency environments.
Why Instrumentation Matters in Event Driven Systems
- Asynchronous Complexity: Events flow across multiple services and queues, making synchronous debugging impossible.
- Distributed Nature: Microservices run on different hosts or containers, requiring centralized visibility.
- High Throughput: Large volumes of events demand efficient and scalable instrumentation.
Key Goals of Instrumentation
- Capture event metadata (timestamps, IDs, types).
- Track event lifecycle (production, consumption, processing time).
- Correlate events across services to reconstruct workflows.
- Measure performance metrics (latency, throughput, error rates).
- Detect anomalies and bottlenecks early.
Mind Map: Instrumentation Components in Event Driven Systems
Best Practices for Instrumentation
- Propagate Correlation IDs Across Events and Services
- Assign a unique correlation ID when an event is created.
- Pass this ID through all subsequent events and service calls.
- Example:
// Java example using MDC for correlation ID propagation
import org.slf4j.MDC;
public void produceEvent(Event event) {
String correlationId = UUID.randomUUID().toString();
MDC.put("correlationId", correlationId);
event.setCorrelationId(correlationId);
eventPublisher.publish(event);
MDC.clear();
}
-
Instrument Event Producers to Log Event Emission
- Log event type, timestamp, and correlation ID.
- Emit metrics for event counts.
-
Instrument Event Brokers to Monitor Queue Metrics
- Track queue length, consumer lag, and throughput.
- Example: Using Kafka’s JMX metrics to monitor consumer lag.
-
Instrument Event Consumers to Log Receipt and Processing
- Log event receipt time, processing start/end.
- Capture errors and retries.
-
Use Distributed Tracing to Visualize Event Flows
- Integrate OpenTelemetry or Zipkin.
- Trace spans should cover event production, broker transit, and consumption.
Example: Instrumenting a Kafka-Based Event Driven System
Event Producer Instrumentation (Node.js)
const { Kafka } = require('kafkajs');
const { v4: uuidv4 } = require('uuid');
const kafka = new Kafka({ clientId: 'order-service', brokers: ['kafka:9092'] });
const producer = kafka.producer();
async function produceOrderCreatedEvent(order) {
const correlationId = uuidv4();
const event = {
type: 'OrderCreated',
timestamp: new Date().toISOString(),
correlationId: correlationId,
payload: order
};
console.log(`Producing event with correlationId: ${correlationId}`);
await producer.send({
topic: 'orders',
messages: [{ key: order.id, value: JSON.stringify(event) }]
});
}
Event Consumer Instrumentation (Node.js)
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ clientId: 'inventory-service', brokers: ['kafka:9092'] });
const consumer = kafka.consumer({ groupId: 'inventory-group' });
async function run() {
await consumer.connect();
await consumer.subscribe({ topic: 'orders', fromBeginning: false });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
const event = JSON.parse(message.value.toString());
const correlationId = event.correlationId;
console.log(`Received event with correlationId: ${correlationId}`);
const start = Date.now();
// Process event
await processOrder(event.payload);
const duration = Date.now() - start;
console.log(`Processed event ${event.type} in ${duration}ms`);
}
});
}
run().catch(console.error);
Mind Map: Correlation ID Propagation Flow
Tools and Libraries for Instrumentation
| Category | Tools / Libraries | Description |
|---|---|---|
| Metrics Collection | Prometheus, StatsD | Collect and aggregate metrics |
| Distributed Tracing | OpenTelemetry, Jaeger, Zipkin | Trace asynchronous flows |
| Logging Aggregation | ELK Stack (Elasticsearch, Logstash, Kibana), Fluentd | Centralized log management |
| Correlation ID Support | Sleuth (Spring), OpenTelemetry SDKs | Automatic correlation ID propagation |
Summary
Instrumenting event driven systems for visibility requires a holistic approach covering producers, brokers, consumers, and observability tools. Propagating correlation IDs, capturing detailed event metadata, and integrating distributed tracing are foundational best practices. These enable engineers to monitor, debug, and optimize high concurrency microservices effectively.
7.3 Distributed Tracing in Asynchronous Event Flows
Distributed tracing is a critical observability technique that helps engineers understand the flow of requests and events across multiple microservices, especially in asynchronous, event-driven architectures where traditional request-response tracing falls short. In high concurrency microservices environments, tracing asynchronous event flows enables root cause analysis, performance optimization, and system reliability improvements.
Why Distributed Tracing Matters in Asynchronous Event Flows
- Visibility across service boundaries: Events often trigger downstream services asynchronously, making it difficult to track the full lifecycle of a transaction.
- Latency measurement: Understand where time is spent across event processing pipelines.
- Error propagation: Detect where failures or bottlenecks occur in event chains.
- Correlation of events: Link related events and commands across services.
Challenges Unique to Asynchronous Event Tracing
- Lack of a single request context due to asynchronous decoupling.
- Event propagation across multiple brokers or queues.
- Potential out-of-order event processing.
- Multiple retries and idempotency complicate trace interpretation.
Core Concepts for Distributed Tracing in Event-Driven Systems
Mind Map: Distributed Tracing in Asynchronous Event Flows
Best Practice: Propagating Trace Context Through Events
To maintain trace continuity, trace context (trace ID, span ID, baggage) must be propagated within event metadata or headers.
Example: Injecting Trace Context in Kafka Producer (Java with OpenTelemetry)
// Pseudo-code snippet
ProducerRecord<String, String> record = new ProducerRecord<>("orders", orderId, orderJson);
// Inject trace context into Kafka headers
OpenTelemetry.getPropagators().getTextMapPropagator().inject(
Context.current(),
record.headers(),
(headers, key, value) -> headers.add(key, value.getBytes(StandardCharsets.UTF_8))
);
producer.send(record);
Example: Extracting Trace Context in Kafka Consumer
ConsumerRecord<String, String> record = ...;
Context extractedContext = OpenTelemetry.getPropagators().getTextMapPropagator().extract(
Context.current(),
record.headers(),
(headers, key) -> {
Header header = headers.lastHeader(key);
return header == null ? null : new String(header.value(), StandardCharsets.UTF_8);
}
);
// Start a new span as a child of extractedContext
Span span = tracer.spanBuilder("processOrderEvent").setParent(extractedContext).startSpan();
try (Scope scope = span.makeCurrent()) {
// Process event
} finally {
span.end();
}
Visualizing Asynchronous Event Traces
Distributed tracing tools visualize spans as timelines showing the causal relationships between events and services.
Mind Map: Trace Visualization Components
Example: In Jaeger UI, a trace might show:
- Span 1: API Gateway receives client request
- Span 2: Event published to Kafka with trace context
- Span 3: Order Service consumes event and processes order
- Span 4: Inventory Service updates stock asynchronously
This visualization helps identify delays or errors in any step.
Example Scenario: Tracing an Order Fulfillment Event Flow
- Client places order via API Gateway
- Trace span starts at API Gateway.
- API Gateway publishes “OrderCreated” event to Kafka
- Trace context injected into event headers.
- Order Service consumes “OrderCreated” event
- Extracts trace context, starts child span.
- Order Service publishes “InventoryReserved” event
- Continues trace context propagation.
- Inventory Service consumes “InventoryReserved” event
- Extracts context, processes reservation.
Each step creates spans linked by trace context, enabling end-to-end visibility.
Tips for Effective Distributed Tracing in Event-Driven Microservices
- Standardize trace context propagation across all event producers and consumers.
- Instrument all critical event handlers to capture spans.
- Add meaningful attributes and logs to spans for richer context.
- Handle retries and duplicates carefully to avoid trace pollution.
- Use sampling wisely to balance overhead and trace coverage.
Summary
Distributed tracing in asynchronous event flows is essential for understanding and debugging complex microservices interactions under high concurrency. By propagating trace context through event metadata, instrumenting producers and consumers, and leveraging visualization tools, engineers gain deep insights into system behavior, enabling faster troubleshooting and performance tuning.
7.4 Example: Implementing OpenTelemetry in a Microservices Ecosystem
OpenTelemetry is an open-source observability framework for cloud-native software, providing standardized APIs and SDKs to collect metrics, logs, and traces. In a high concurrency microservices ecosystem, OpenTelemetry helps gain deep visibility into asynchronous event flows, enabling effective monitoring and troubleshooting.
Why OpenTelemetry?
- Vendor-neutral and supports multiple backends
- Unified instrumentation for metrics, traces, and logs
- Supports distributed tracing essential for microservices
- Rich ecosystem with integrations for popular frameworks and languages
Step-by-Step Implementation Guide
Instrumenting Microservices
Each microservice needs to be instrumented to capture telemetry data. This typically involves:
- Adding OpenTelemetry SDK dependencies
- Initializing tracer and meter providers
- Instrumenting incoming and outgoing requests
- Capturing custom events and metrics
Example: Instrumenting a Node.js Microservice with OpenTelemetry
const { NodeTracerProvider } = require('@opentelemetry/sdk-trace-node');
const { registerInstrumentations } = require('@opentelemetry/instrumentation');
const { HttpInstrumentation } = require('@opentelemetry/instrumentation-http');
const { ExpressInstrumentation } = require('@opentelemetry/instrumentation-express');
const { SimpleSpanProcessor } = require('@opentelemetry/sdk-trace-base');
const { ConsoleSpanExporter } = require('@opentelemetry/sdk-trace-base');
const provider = new NodeTracerProvider();
provider.addSpanProcessor(new SimpleSpanProcessor(new ConsoleSpanExporter()));
provider.register();
registerInstrumentations({
instrumentations: [
new HttpInstrumentation(),
new ExpressInstrumentation(),
],
});
// Your express app code here
This setup automatically traces HTTP requests and Express middleware.
Propagating Context Across Services
To maintain trace continuity across asynchronous event-driven calls, context propagation is essential.
- Use OpenTelemetry context propagation APIs
- Inject trace context into event messages (e.g., Kafka headers)
- Extract trace context on the consumer side
Example: Injecting and Extracting Trace Context in Kafka Messages (Java)
// Producer side
TextMapSetter<ProducerRecord<String, String>> setter = (carrier, key, value) -> {
carrier.headers().add(key, value.getBytes(StandardCharsets.UTF_8));
};
tracer.getTextMapPropagator().inject(Context.current(), record, setter);
// Consumer side
TextMapGetter<ConsumerRecord<String, String>> getter = new TextMapGetter<>() {
@Override
public Iterable<String> keys(ConsumerRecord<String, String> carrier) {
return StreamSupport.stream(carrier.headers().spliterator(), false)
.map(Header::key).collect(Collectors.toList());
}
@Override
public String get(ConsumerRecord<String, String> carrier, String key) {
Header header = carrier.headers().lastHeader(key);
if (header != null) {
return new String(header.value(), StandardCharsets.UTF_8);
}
return null;
}
};
Context extractedContext = tracer.getTextMapPropagator().extract(Context.current(), record, getter);
Exporting Telemetry Data
Choose an exporter to send telemetry data to your backend (e.g., Jaeger, Zipkin, Prometheus).
Example configuration for exporting traces to Jaeger (Node.js):
const { JaegerExporter } = require('@opentelemetry/exporter-jaeger');
const exporter = new JaegerExporter({
endpoint: 'http://localhost:14268/api/traces',
});
provider.addSpanProcessor(new SimpleSpanProcessor(exporter));
Visualizing and Analyzing Traces
Use observability backends like Jaeger or Zipkin to visualize distributed traces, identify bottlenecks, and understand event flows.
Mind Map: OpenTelemetry Implementation Workflow
Mind Map: Context Propagation in Event Driven Microservices
Real-World Example: Tracing an Order Processing Flow
Imagine a microservices ecosystem handling order processing with these services:
- API Gateway
- Order Service
- Inventory Service
- Payment Service
- Notification Service
Each service is instrumented with OpenTelemetry. When a customer places an order:
- API Gateway receives the request and starts a root span.
- It calls Order Service, propagating the trace context.
- Order Service emits an event to Inventory Service via Kafka, injecting trace context into message headers.
- Inventory Service extracts context, processes stock reservation, and emits an event to Payment Service.
- Payment Service processes payment and emits an event to Notification Service.
- Notification Service sends confirmation to the customer.
This trace can be visualized end-to-end, showing latencies and errors per service.
Summary
Implementing OpenTelemetry in a high concurrency microservices ecosystem enables:
- End-to-end distributed tracing
- Context propagation across asynchronous events
- Unified metrics and logs collection
- Better observability leading to faster debugging and performance tuning
By following the instrumentation, context propagation, exporting, and visualization steps, engineering teams can build robust observability pipelines tailored for event-driven architectures.
7.5 Best Practice: Correlating Logs and Traces for Root Cause Analysis
In high concurrency microservices environments, especially those leveraging event-driven architecture, diagnosing issues can be challenging due to the asynchronous and distributed nature of the system. Correlating logs and traces effectively is essential for root cause analysis (RCA), enabling engineers to pinpoint failures, performance bottlenecks, or unexpected behaviors quickly.
Why Correlate Logs and Traces?
- Distributed Context: Microservices often span multiple processes, hosts, and networks.
- Asynchronous Flows: Events and messages may trigger downstream processing asynchronously.
- Volume of Data: High concurrency generates massive logs and trace data.
- Complex Dependencies: Services interact in complex chains and parallel flows.
Correlating logs and traces provides a unified view of the request or event journey across services.
Core Concepts
- Trace ID: A unique identifier attached to a request or event that flows through multiple services.
- Span ID: Represents a single unit of work within a trace (e.g., a function call, database query).
- Log Context: Embedding trace and span IDs within log entries to link logs to traces.
Mind Map: Correlating Logs and Traces
Example: Propagating Trace Context and Correlating Logs in a Node.js Microservice
const { trace, context } = require('@opentelemetry/api');
const logger = require('./logger'); // Assume logger supports structured logging
function processOrder(order) {
const tracer = trace.getTracer('order-service');
tracer.startActiveSpan('processOrder', span => {
// Add trace context to logs
logger.info('Starting order processing', {
traceId: span.spanContext().traceId,
spanId: span.spanContext().spanId,
orderId: order.id
});
// Simulate processing
try {
// ... business logic
logger.info('Order processed successfully', {
traceId: span.spanContext().traceId,
spanId: span.spanContext().spanId,
orderId: order.id
});
} catch (error) {
logger.error('Order processing failed', {
traceId: span.spanContext().traceId,
spanId: span.spanContext().spanId,
orderId: order.id,
error: error.message
});
span.recordException(error);
span.setStatus({ code: 2, message: error.message });
} finally {
span.end();
}
});
}
In this example:
- The OpenTelemetry tracer creates a span for the order processing.
- Logs are enriched with
traceIdandspanIdfor correlation. - Errors are recorded in both logs and traces.
Structured Logging Example (JSON log entry)
{
"timestamp": "2024-06-01T12:00:00Z",
"level": "info",
"message": "Starting order processing",
"traceId": "4bf92f3577b34da6a3ce929d0e0e4736",
"spanId": "00f067aa0ba902b7",
"orderId": "12345",
"service": "order-service"
}
This structured log can be queried by traceId to find all logs related to a specific trace.
Visualizing Correlated Data
- Use distributed tracing tools like Jaeger, Zipkin, or AWS X-Ray to visualize trace spans.
- Use log aggregation tools like ELK Stack (Elasticsearch, Logstash, Kibana) or Grafana Loki to search logs by trace ID.
Example workflow:
- Identify a failed trace in Jaeger.
- Extract the trace ID.
- Query logs in Kibana filtering by the trace ID.
- Analyze logs and spans together to find root cause.
Best Practices Summary
- Consistent Trace Context Propagation: Ensure all services propagate trace IDs and span IDs through headers or message metadata.
- Structured Logging: Use JSON or other structured formats to embed trace context.
- Instrumentation: Prefer automatic instrumentation with OpenTelemetry or similar frameworks.
- Centralized Storage: Aggregate logs and traces in centralized platforms for unified querying.
- Correlate with Metrics: Combine logs and traces with metrics to get a holistic observability picture.
Additional Mind Map: Root Cause Analysis Workflow
By embedding trace context into logs and leveraging distributed tracing tools, senior backend engineers can dramatically reduce the time to identify and resolve issues in high concurrency microservices environments. This practice is critical for maintaining reliability and performance in complex event-driven systems.
8. Monitoring and Alerting Strategies
8.1 Defining Key Performance Indicators (KPIs) for Concurrency
In high concurrency microservices environments, KPIs are essential to measure system performance, identify bottlenecks, and ensure that services meet their scalability and reliability goals. Defining the right KPIs helps engineering teams monitor, optimize, and troubleshoot their systems effectively.
Why KPIs Matter in High Concurrency Systems
- Quantify performance under load: Understand how your microservices behave when handling thousands or millions of concurrent requests.
- Detect bottlenecks early: Identify slow components or resource constraints before they impact users.
- Guide scaling decisions: Inform when and how to scale services or infrastructure.
- Improve reliability: Track error rates and system health to maintain SLAs.
Core KPI Categories for High Concurrency Microservices
Detailed KPIs Explained with Examples
Throughput
- Definition: Number of requests or events processed per unit time (e.g., requests per second).
- Why it matters: Measures the capacity of your microservice to handle concurrent workload.
- Example: A payment processing microservice handles 10,000 transactions per second during peak hours.
Latency / Response Time
- Definition: Time taken to process a request or event from receipt to completion.
- Why it matters: High latency can degrade user experience and indicate contention or resource exhaustion.
- Example: Average response time of an order fulfillment service should remain under 200ms even under high concurrency.
Error Rate
- Definition: Percentage of failed requests or events relative to total processed.
- Why it matters: High error rates under load indicate instability or bugs.
- Example: If error rate spikes above 1% during traffic surges, investigate circuit breakers or database contention.
Retry Rate
- Definition: Frequency of retries triggered due to transient failures.
- Why it matters: Excessive retries can overload systems and increase latency.
- Example: Monitoring retry rate on event handlers to detect downstream service slowness.
Resource Utilization
- CPU Usage: High CPU usage may indicate inefficient processing or need for scaling.
- Memory Usage: Memory leaks or spikes can cause crashes under concurrency.
- Network I/O: Saturation can cause delays in event delivery.
Concurrent Requests / Active Sessions
- Definition: Number of simultaneous requests being processed.
- Why it matters: Helps understand real-time load and capacity limits.
- Example: A microservice handling 5,000 concurrent websocket connections.
Queue Length and Backpressure Events
- Definition: Number of events waiting in queues or times backpressure was applied.
- Why it matters: Indicates overload and helps trigger scaling or load shedding.
- Example: Kafka consumer lag growing beyond threshold signals consumer bottleneck.
SLA Compliance
- Definition: Percentage of requests meeting defined service level objectives (e.g., 99.9% under 300ms).
- Why it matters: Ensures business requirements and user expectations are met.
Example: Defining KPIs for a High Concurrency Order Processing Microservice
| KPI | Target Value | Measurement Method | Notes |
|---|---|---|---|
| Throughput | 15,000 orders/sec | Metrics from API gateway or message broker | Peak load during flash sales |
| Average Latency | < 150 ms | Distributed tracing and logs | Includes DB and external API calls |
| Error Rate | < 0.5% | Error logs and monitoring tools | Includes validation and processing errors |
| Retry Rate | < 2% | Application logs | Retries due to transient DB timeouts |
| CPU Usage | < 80% | Infrastructure monitoring | Avoid CPU saturation |
| Memory Usage | < 70% | Infrastructure monitoring | Prevent memory leaks |
| Concurrent Requests | Up to 10,000 | Real-time metrics | Measures active processing load |
| Queue Length | < 500 | Message broker monitoring | Indicates consumer lag |
| SLA Compliance | 99.95% requests < 200ms | SLA monitoring dashboard | Critical for customer satisfaction |
Mind Map: KPI Relationships and Monitoring Focus
Best Practices for KPI Definition
- Align KPIs with business goals: Ensure metrics reflect what matters to end-users and stakeholders.
- Use a combination of metrics: Single KPIs rarely tell the full story; combine throughput, latency, and error rates.
- Set realistic targets: Base targets on historical data and capacity planning.
- Continuously review and refine: KPIs should evolve with system changes and scaling.
- Automate monitoring and alerting: Use tools like Prometheus, Grafana, and OpenTelemetry to track KPIs in real-time.
By carefully defining and monitoring KPIs tailored to your high concurrency microservices, you gain actionable insights that drive performance optimization, reliability, and scalability.
8.2 Setting Up Real-Time Dashboards with Prometheus and Grafana
In high concurrency microservices environments, real-time monitoring is critical to ensure system health, performance, and quick detection of anomalies. Prometheus and Grafana are two of the most popular open-source tools used to build powerful, customizable real-time dashboards.
Why Prometheus and Grafana?
- Prometheus is a time-series database and monitoring system designed for reliability and scalability. It scrapes metrics from instrumented services and stores them efficiently.
- Grafana is a visualization tool that connects to Prometheus (and other data sources) to create rich, interactive dashboards.
Together, they provide a robust observability stack for microservices.
Step-by-Step Guide to Setting Up Real-Time Dashboards
Instrument Your Microservices
- Use client libraries (Go, Java, Python, etc.) to expose metrics in Prometheus format.
- Common metrics include request counts, latencies, error rates, and resource usage.
Example: Exposing HTTP request metrics in a Node.js microservice using prom-client:
const client = require('prom-client');
const express = require('express');
const app = express();
const httpRequestDurationMicroseconds = new client.Histogram({
name: 'http_request_duration_ms',
help: 'Duration of HTTP requests in ms',
labelNames: ['method', 'route', 'code'],
buckets: [50, 100, 200, 300, 400, 500, 1000]
});
app.use((req, res, next) => {
const end = httpRequestDurationMicroseconds.startTimer();
res.on('finish', () => {
end({ method: req.method, route: req.route ? req.route.path : req.path, code: res.statusCode });
});
next();
});
app.get('/metrics', (req, res) => {
res.set('Content-Type', client.register.contentType);
res.end(client.register.metrics());
});
app.listen(3000);
Configure Prometheus to Scrape Metrics
- Define scrape targets in
prometheus.yml:
scrape_configs:
- job_name: 'order-service'
static_configs:
- targets: ['order-service:3000']
- job_name: 'payment-service'
static_configs:
- targets: ['payment-service:3000']
- Start Prometheus with this config.
Install and Configure Grafana
- Install Grafana and add Prometheus as a data source.
- Configure the Prometheus URL (e.g.,
http://localhost:9090).
Build Dashboards
- Create panels for key metrics:
- Request rate (per second)
- Error rate
- Latency percentiles (p50, p95, p99)
- Resource usage (CPU, memory)
Mind Map: Setting Up Real-Time Dashboards
Example Grafana Dashboard Panel Queries
- Request Rate:
sum(rate(http_requests_total[1m])) by (job) - Error Rate:
sum(rate(http_requests_total{status=~"5.."}[1m])) by (job) - Latency (95th percentile):
histogram_quantile(0.95, sum(rate(http_request_duration_ms_bucket[5m])) by (le, job))
Best Practices
- Labeling: Use consistent labels (e.g.,
job,instance,route) to filter and aggregate metrics effectively. - Dashboard Organization: Group related metrics logically; use templating variables for dynamic filtering.
- Alerting: Configure Grafana alerts on critical metrics to get notified of anomalies.
- Performance: Avoid overly complex PromQL queries that can degrade Prometheus performance.
Summary
Setting up real-time dashboards with Prometheus and Grafana empowers backend engineers to monitor high concurrency microservices effectively. By instrumenting services, configuring Prometheus scrapes, and building insightful Grafana dashboards, teams gain visibility into system behavior, enabling proactive troubleshooting and performance tuning.
8.3 Alerting on Anomalies and Latency Spikes in Event Processing
In high concurrency microservices architectures, especially those leveraging event-driven patterns, timely detection of anomalies and latency spikes is critical to maintaining system reliability and performance. Alerting mechanisms enable engineering teams to respond proactively before issues escalate into outages or degraded user experiences.
Why Alert on Anomalies and Latency Spikes?
- Early Detection: Identify abnormal behavior or performance degradation early.
- Prevent Cascading Failures: Latency spikes in one microservice can propagate delays downstream.
- Maintain SLAs: Ensure service level agreements are met by monitoring event processing times.
- Optimize Resource Usage: Detect bottlenecks and inefficient resource consumption.
Key Concepts for Alerting in Event Processing
- Anomaly Detection: Identifying deviations from normal patterns in metrics such as event throughput, error rates, or processing latency.
- Latency Spikes: Sudden increases in the time taken to process events, which can indicate backpressure or resource exhaustion.
- Threshold-Based Alerts: Predefined static thresholds triggering alerts when exceeded.
- Dynamic/Adaptive Alerts: Use statistical or ML models to detect anomalies beyond static thresholds.
Mind Map: Alerting Components in Event Driven Microservices
Example: Setting Up Threshold-Based Alerts with Prometheus & Grafana
Suppose you have a microservice consuming events from Kafka and you want to alert when the average event processing latency exceeds 500ms over 5 minutes.
Prometheus Query:
avg_over_time(event_processing_latency_seconds[5m]) > 0.5
Alert Rule YAML:
- alert: HighEventProcessingLatency
expr: avg_over_time(event_processing_latency_seconds[5m]) > 0.5
for: 2m
labels:
severity: warning
annotations:
summary: "Event processing latency is high"
description: "The average event processing latency has exceeded 500ms for more than 2 minutes."
Grafana Alert:
- Create a dashboard panel visualizing
event_processing_latency_seconds. - Configure alerting with the above threshold.
- Set notification channels (Slack, email).
Mind Map: Anomaly Detection Workflow
Example: Using Machine Learning for Anomaly Detection
You can integrate anomaly detection libraries (e.g., Facebook’s Prophet, Twitter’s AnomalyDetection, or custom ML models) to analyze event processing latency time series.
Python Example Using Twitter’s AnomalyDetection:
import pandas as pd
from AnomalyDetection import AnomalyDetection
# Sample latency data
latency_data = pd.DataFrame({
'timestamp': pd.date_range(start='2024-01-01', periods=100, freq='T'),
'latency_ms': [100 + (x\%10)*10 for x in range(100)]
})
# Introduce anomaly
latency_data.loc[50:55, 'latency_ms'] = 1000
# Run anomaly detection
results = AnomalyDetection.detect_ts(latency_data, max_anoms=0.1, direction='pos')
print(results['anoms'])
This output can feed into alerting pipelines to notify teams when anomalies are detected.
Best Practices for Alerting on Latency and Anomalies
- Combine Multiple Metrics: Use latency, throughput, error rates, and consumer lag together for comprehensive alerting.
- Avoid Alert Fatigue: Tune thresholds and use anomaly detection to reduce false positives.
- Implement Multi-Level Alerts: Warning, critical, and info levels help prioritize responses.
- Correlate Alerts: Link latency spikes with error rate increases or queue backlogs.
- Use Distributed Tracing: Helps pinpoint root causes of latency spikes across microservices.
Example: Correlating Latency Spike with Consumer Lag
Imagine a Kafka consumer microservice where a latency spike coincides with increased consumer lag.
Prometheus Queries:
- Consumer Lag:
kafka_consumer_lag{consumer_group="order_processor"}
- Event Processing Latency:
histogram_quantile(0.95, sum(rate(event_processing_latency_seconds_bucket[5m])) by (le))
Alert Logic:
- Alert if 95th percentile latency > 500ms AND consumer lag > 1000 messages.
This combined alert indicates the consumer is falling behind, causing latency spikes.
Summary
Alerting on anomalies and latency spikes in event processing is essential for maintaining the health and performance of high concurrency microservices. By leveraging threshold-based alerts, anomaly detection techniques, and correlating multiple metrics, engineering teams can detect issues early and respond effectively.
Integrating these alerts with robust notification and incident management systems ensures rapid mitigation and continuous improvement.
8.4 Example: Creating SLA-Based Alerts for Critical Microservices
Service Level Agreements (SLAs) define the expected performance and availability targets for critical microservices. Creating SLA-based alerts ensures that any deviation from these targets triggers timely notifications, enabling rapid response to potential issues.
Step 1: Define SLA Metrics
Common SLA metrics for microservices include:
- Availability: Percentage of uptime (e.g., 99.9% uptime)
- Latency: Response time thresholds (e.g., 95th percentile latency < 200ms)
- Error Rate: Percentage of failed requests (e.g., error rate < 0.1%)
Step 2: Instrument Microservices to Collect Metrics
Use monitoring tools like Prometheus to collect these metrics. Example Prometheus metrics:
# HTTP request duration histogram
http_request_duration_seconds_bucket{service="order-service",le="0.1"} 240
http_request_duration_seconds_bucket{service="order-service",le="0.2"} 450
# HTTP request total counter
http_requests_total{service="order-service",status="500"} 5
http_requests_total{service="order-service",status="200"} 995
Step 3: Define Alerting Rules Based on SLA Thresholds
Example Prometheus alert rules:
groups:
- name: SLAAlerts
rules:
- alert: HighErrorRate
expr: sum(rate(http_requests_total{service="order-service",status=~"5.."}[5m])) / sum(rate(http_requests_total{service="order-service"}[5m])) > 0.001
for: 5m
labels:
severity: critical
annotations:
summary: "High error rate detected in order-service"
description: "Error rate has exceeded 0.1% over the last 5 minutes."
- alert: HighLatency
expr: histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{service="order-service"}[5m])) by (le)) > 0.2
for: 5m
labels:
severity: warning
annotations:
summary: "High latency detected in order-service"
description: "95th percentile latency has exceeded 200ms over the last 5 minutes."
- alert: LowAvailability
expr: (1 - (sum(rate(http_requests_total{service="order-service",status=~"5.."}[5m])) / sum(rate(http_requests_total{service="order-service"}[5m])))) < 0.999
for: 10m
labels:
severity: critical
annotations:
summary: "Availability below SLA for order-service"
description: "Availability has dropped below 99.9% in the last 10 minutes."
Step 4: Configure Alertmanager for Notification Routing
Example Alertmanager configuration snippet:
route:
receiver: 'on-call-team'
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: 'on-call-team'
email_configs:
- to: '[email protected]'
from: '[email protected]'
smarthost: 'smtp.example.com:587'
auth_username: '[email protected]'
auth_password: 'password'
Mind Map: SLA-Based Alerting Workflow
Mind Map: Example Alert Rule Logic
Real-World Example Scenario
Imagine an Order Processing Microservice responsible for handling customer orders. The SLA states:
- Availability >= 99.9%
- 95th percentile latency < 200ms
- Error rate < 0.1%
When the error rate spikes due to a database connectivity issue, the HighErrorRate alert fires, notifying the on-call engineer via email and Slack. The engineer investigates the logs and metrics (enabled by observability), identifies the root cause, and resolves the issue before SLA violations impact customers.
Summary
Creating SLA-based alerts involves:
- Clearly defining SLA metrics relevant to your critical microservices
- Instrumenting services to collect accurate metrics
- Writing precise alerting rules that reflect SLA thresholds
- Configuring notification channels to ensure timely response
- Leveraging observability tools to diagnose and resolve issues quickly
This proactive approach helps maintain service reliability and customer satisfaction in high concurrency microservices environments.
8.5 Best Practice: Using Synthetic Monitoring for End-to-End Validation
Synthetic monitoring is a proactive approach to observability where automated scripts simulate user interactions or system workflows to continuously validate the health, performance, and correctness of microservices in a high concurrency environment. This technique is especially valuable in event driven architectures where asynchronous communication and eventual consistency can make real-time issue detection challenging.
Why Synthetic Monitoring?
- Proactive Detection: Identify issues before real users are impacted.
- End-to-End Validation: Test entire workflows across multiple microservices.
- Performance Benchmarking: Measure latency and throughput under controlled conditions.
- Regression Testing: Ensure new deployments do not break existing flows.
Key Components of Synthetic Monitoring in Microservices
Designing Synthetic Tests for Event Driven Microservices
-
Identify Critical User Journeys or Business Transactions
- Example: Order placement → Payment processing → Inventory update → Shipping notification.
-
Simulate Event Emission and Consumption
- Publish events mimicking real user actions.
- Verify downstream services consume and process events correctly.
-
Validate Data Consistency and State Changes
- Query microservices or databases to confirm expected state transitions.
-
Measure Latency and Throughput Across the Workflow
-
Incorporate Retry and Backoff Logic to Mimic Realistic Conditions
Example: Synthetic Monitoring Script for an Order Processing Workflow
// Using k6 for synthetic API testing
import http from 'k6/http';
import { check, sleep } from 'k6';
export default function () {
// Step 1: Place Order
let orderRes = http.post('https://api.example.com/orders', JSON.stringify({
userId: 'user123',
items: [{ productId: 'prod456', quantity: 2 }]
}), { headers: { 'Content-Type': 'application/json' } });
check(orderRes, { 'order placed successfully': (r) => r.status === 201 });
let orderId = orderRes.json('orderId');
// Step 2: Poll for Payment Completion Event
let paymentStatus = 'pending';
for (let i = 0; i < 10; i++) {
let paymentRes = http.get(`https://api.example.com/payments/status/${orderId}`);
if (paymentRes.status === 200 && paymentRes.json('status') === 'completed') {
paymentStatus = 'completed';
break;
}
sleep(2); // wait before retry
}
check(paymentStatus, { 'payment completed': (status) => status === 'completed' });
// Step 3: Verify Inventory Update
let inventoryRes = http.get('https://api.example.com/inventory/prod456');
check(inventoryRes, { 'inventory updated': (r) => r.json('availableQuantity') < 100 });
// Step 4: Confirm Shipping Notification Event
let shippingRes = http.get(`https://api.example.com/shipping/status/${orderId}`);
check(shippingRes, { 'shipping notified': (r) => r.status === 200 && r.json('status') === 'notified' });
}
Integrating Synthetic Monitoring with Observability
Best Practices Summary
- Automate synthetic tests to run frequently and consistently.
- Cover critical business workflows end-to-end, not just isolated APIs.
- Simulate realistic event sequences including retries and failures.
- Correlate synthetic monitoring data with logs, metrics, and traces for comprehensive insights.
- Use synthetic monitoring results to drive continuous improvement and resilience.
Additional Example: Postman Collection for Event Driven Microservice Validation
- Create a Postman collection that:
- Sends events to event brokers via API gateways.
- Polls microservices for expected state changes.
- Validates response payloads and status codes.
- Can be integrated with Newman CLI for automated CI runs.
By embedding synthetic monitoring into your high concurrency microservices ecosystem, you gain a powerful tool to validate system behavior proactively, ensuring reliability and performance even under heavy load and complex asynchronous event flows.
9. Debugging and Troubleshooting High Concurrency Issues
9.1 Common Concurrency Pitfalls in Event Driven Microservices
Concurrency in event-driven microservices introduces unique challenges that can lead to subtle bugs, degraded performance, and system instability. Understanding these pitfalls is crucial for senior backend engineers aiming to build robust, scalable systems.
Mind Map: Common Concurrency Pitfalls
Detailed Explanation and Examples
Race Conditions
When multiple microservices or instances process events that update shared resources concurrently without proper synchronization, race conditions occur.
Example: Imagine an e-commerce inventory service where two order microservices simultaneously receive events to decrement the stock of the same product.
// Pseudocode illustrating race condition
int stock = inventoryService.getStock(productId);
if (stock > 0) {
inventoryService.decrementStock(productId);
}
If both services read the stock as 1 simultaneously, both will decrement, resulting in negative stock.
Best Practice: Use atomic operations or distributed locks, or design the system to avoid shared mutable state by leveraging event sourcing.
Deadlocks
Deadlocks happen when two or more services wait indefinitely for each other to release resources.
Example: In a distributed saga coordinating payment and inventory update, if payment service waits for inventory confirmation while inventory waits for payment confirmation, a circular wait occurs.
graph LR
PaymentService -->|Waits for| InventoryService
InventoryService -->|Waits for| PaymentService
Best Practice: Design sagas with clear timeout policies and avoid circular dependencies.
Event Ordering Issues
Event-driven systems often process events asynchronously, which can cause events to be handled out of order.
Example: A payment event arrives before the order creation event, causing the payment service to fail because the order context does not exist yet.
Best Practice: Use event versioning, sequence numbers, or design services to handle out-of-order events gracefully (e.g., buffering or compensating actions).
Duplicate Event Handling
Event brokers often guarantee at-least-once delivery, meaning events can be delivered multiple times.
Example: An invoice microservice receives the same payment event twice, generating duplicate invoices.
Best Practice: Implement idempotent event handlers by using unique event IDs and checking if an event was already processed.
Resource Starvation
When consumers or threads are blocked waiting for slow downstream services, other events may starve and not get processed timely.
Example: A microservice waiting for a database lock causes its event consumer threads to block, reducing throughput.
Best Practice: Use asynchronous processing, timeouts, and circuit breakers to prevent blocking.
Backpressure Mismanagement
Without proper backpressure, event producers can overwhelm consumers or brokers, causing queue overflows and increased latency.
Example: Kafka topic partitions fill up because consumers cannot keep pace with producers, leading to message loss or delays.
Best Practice: Implement flow control mechanisms, rate limiting, and monitor queue sizes.
Inconsistent State due to Eventual Consistency
Microservices often rely on eventual consistency, which means temporary data inconsistencies are expected.
Example: User profile updates in the authentication service take time to propagate to the recommendation service, causing stale recommendations.
Best Practice: Communicate consistency expectations clearly and design UI/UX to handle eventual consistency gracefully.
Lack of Idempotency
Processing the same event multiple times without idempotency can cause unintended side effects.
Example: A payment service charges a customer twice due to reprocessing a payment event.
Best Practice: Ensure event handlers are idempotent by storing processed event IDs and avoiding side effects on repeated processing.
Improper Timeout and Retry Handling
Retries without backoff or limits can cause cascading failures or resource exhaustion.
Example: A microservice retries failed event handling immediately and indefinitely, causing high CPU usage.
Best Practice: Use exponential backoff, jitter, and circuit breakers to manage retries effectively.
Summary
Concurrency pitfalls in event-driven microservices often stem from asynchronous processing, distributed state, and eventual consistency. Awareness and proactive design around these issues—such as idempotency, ordering guarantees, and proper resource management—are essential for building resilient, high-concurrency systems.
Additional Mind Map: Mitigation Strategies
9.2 Techniques for Debugging Asynchronous Event Flows
Debugging asynchronous event flows in microservices can be challenging due to the decoupled nature of components, non-linear execution, and potential message delays or losses. This section explores effective techniques to identify, trace, and resolve issues in asynchronous event-driven systems.
Understanding the Complexity of Asynchronous Event Flows
- Events are produced and consumed independently.
- Event ordering may not be guaranteed.
- Failures can be transient or permanent.
- Multiple services may be involved in processing a single business transaction.
Mind Map: Key Challenges in Debugging Asynchronous Event Flows
Technique 1: Distributed Tracing with Context Propagation
Description: Use distributed tracing tools (e.g., OpenTelemetry, Jaeger) to track event flows across microservices. Propagate trace context (trace ID, span ID) through event metadata.
Example:
- When Service A emits an event, it attaches a trace ID.
- Service B, upon consuming the event, continues the trace by creating a child span.
- This allows visualization of the entire event journey, including delays and failures.
{
"event": {
"id": "evt-123",
"traceId": "abcd-ef01-2345",
"payload": { "orderId": "order-789" }
}
}
Best Practice: Always include trace context in event headers or metadata.
Technique 2: Structured and Correlated Logging
Description: Logs should be structured (JSON format) and include correlation IDs (e.g., trace ID, event ID) to link logs across services.
Example:
{
"timestamp": "2024-06-01T12:00:00Z",
"level": "INFO",
"service": "OrderService",
"traceId": "abcd-ef01-2345",
"eventId": "evt-123",
"message": "Received order creation event"
}
Best Practice: Use centralized log aggregation (e.g., ELK stack) to search and correlate logs.
Technique 3: Event Replay and Dead Letter Queues (DLQ)
Description: Use DLQs to capture failed events for later inspection and replay events to reproduce issues.
Example:
- An event fails processing in Service C and is routed to a DLQ.
- Developers inspect the DLQ, fix the root cause, and replay the event.
Best Practice: Implement tooling to automate event replay with trace context.
Technique 4: Visualizing Event Flows with Event Flow Diagrams
Description: Create diagrams that map event producers, consumers, and event brokers to understand flow and dependencies.
Example: Use tools like Mermaid.js to render event flow diagrams in documentation.
Technique 5: Implementing Timeouts and Retries with Backoff
Description: Detect and debug issues caused by delayed or lost events by monitoring retry patterns and timeouts.
Example:
- Service D retries event processing with exponential backoff.
- Logs show repeated failures followed by success, indicating transient issues.
Best Practice: Instrument retry metrics and alert on excessive retries.
Technique 6: Using Synthetic Events for Testing and Debugging
Description: Inject synthetic or test events into the system to validate event flow and identify bottlenecks.
Example:
- Inject a test “OrderCreated” event to verify downstream services process it correctly.
Best Practice: Automate synthetic event injection in staging environments.
Mind Map: Debugging Workflow for Asynchronous Event Flows
Summary
Debugging asynchronous event flows requires a combination of observability tools, structured logging, tracing, and systematic workflows. By propagating context, correlating logs, and leveraging event replay mechanisms, engineers can effectively diagnose and resolve issues in complex event-driven microservices.
References and Tools
- OpenTelemetry: https://opentelemetry.io/
- Jaeger Tracing: https://www.jaegertracing.io/
- ELK Stack: https://www.elastic.co/elk-stack
- Kafka Dead Letter Queues: https://www.confluent.io/blog/kafka-dead-letter-queues/
- Mermaid.js for diagrams: https://mermaid-js.github.io/mermaid/#/
9.3 Using Observability Data to Diagnose Performance Bottlenecks
In high concurrency microservices environments, performance bottlenecks can severely impact system throughput, latency, and user experience. Observability data — including metrics, logs, and traces — provides the critical insights needed to identify, analyze, and resolve these bottlenecks effectively.
Key Observability Data Types for Diagnosing Bottlenecks
- Metrics: Quantitative data such as request rates, error rates, CPU/memory usage, queue lengths, and latency percentiles.
- Logs: Detailed event records that provide context about service behavior and errors.
- Traces: Distributed traces that capture the flow of requests across microservices, highlighting latency and failures at each hop.
Mind Map: Observability Data Sources for Bottleneck Diagnosis
Step-by-Step Approach to Diagnose Performance Bottlenecks
-
Identify Symptoms via Metrics:
- Look for spikes in latency (p95/p99) or error rates.
- Monitor resource saturation (CPU, memory, network I/O).
- Check message queue lengths or consumer lag in event brokers.
-
Correlate with Logs:
- Search logs around the time of observed anomalies.
- Identify error patterns, timeouts, or retries.
-
Trace the Request Path:
- Use distributed tracing to pinpoint slow or failing spans.
- Identify services or operations causing delays.
-
Analyze Service Dependencies:
- Determine if downstream services or databases are bottlenecks.
- Verify if network latency or serialization overhead contributes.
-
Validate with Load Testing:
- Reproduce bottlenecks under controlled load.
- Confirm hypotheses and test fixes.
Mind Map: Diagnosing Bottlenecks Workflow
Example: Diagnosing a Slow Order Processing Microservice
Scenario: Users report slow order confirmation times during peak hours.
Step 1: Metrics Analysis
- Observed p99 latency for the
OrderServiceincreased from 200ms to 2s. - CPU usage on
OrderServicepods is at 90%. - Kafka consumer lag for the order event topic is growing.
Step 2: Logs Inspection
- Logs show repeated retries connecting to the
InventoryService. - Warning logs indicate timeouts after 1 second.
Step 3: Distributed Tracing
- Traces reveal that the
InventoryServicecall spans are taking 1.5s. - The
OrderServicewaits synchronously for inventory confirmation.
Step 4: Dependency Check
InventoryServicedatabase shows high query latency due to locking.
Step 5: Load Testing & Fix
- Load tests confirm contention on inventory DB.
- Fix implemented: introduce caching and asynchronous inventory confirmation with compensating transactions.
Mind Map: Example Diagnosis of Order Processing Bottleneck
Best Practices for Using Observability Data
- Instrument Early and Consistently: Embed metrics, logs, and tracing from the start.
- Use Correlation IDs: Enable linking logs and traces for the same request.
- Set Baselines and Alerts: Define normal performance thresholds to detect anomalies quickly.
- Automate Analysis: Use tools that can automatically detect patterns and anomalies.
- Iterate and Improve: Continuously refine instrumentation and diagnosis processes.
By leveraging observability data effectively, engineers can quickly pinpoint and resolve performance bottlenecks in high concurrency microservices, ensuring system reliability and optimal user experience.
9.4 Example: Troubleshooting a Deadlock in a Distributed Saga
In distributed systems, especially those implementing the Saga pattern for managing distributed transactions, deadlocks can occur due to resource contention or circular wait conditions. Troubleshooting such deadlocks requires a clear understanding of the saga flow, resource locking, and event dependencies.
What is a Deadlock in a Distributed Saga?
A deadlock happens when two or more services in a saga wait indefinitely for each other to release resources or complete actions, causing the entire transaction to stall.
Common Causes of Deadlocks in Distributed Sagas
- Circular dependencies between saga steps.
- Improper locking or resource management.
- Long-running compensating transactions blocking progress.
- Concurrent saga instances competing for the same resources.
Mind Map: Troubleshooting Deadlock in Distributed Saga
Step-by-Step Example: Troubleshooting a Deadlock
Scenario:
A distributed saga coordinates an order fulfillment process involving two microservices: Inventory Service and Payment Service. Both services lock resources during their steps. Occasionally, the saga gets stuck, indicating a deadlock.
Step 1: Identify Symptoms
- Saga status remains “In Progress” beyond expected time.
- Logs show Inventory Service waiting for Payment Service to release a lock.
- Payment Service is simultaneously waiting for Inventory Service.
Step 2: Analyze Saga Execution Flow
- Inventory Service locks inventory records.
- Payment Service locks payment transaction.
- Both services wait for the other to complete before proceeding.
Step 3: Use Observability Tools
- Distributed tracing reveals circular wait:
- Trace shows Inventory Service emits event “InventoryReserved” but waits for “PaymentConfirmed”.
- Payment Service emits “PaymentAuthorized” but waits for “InventoryConfirmed”.
- Logs show lock acquisition timestamps and waiting periods.
Step 4: Detect Resource Contention
- Database monitoring shows row-level locks held by both services.
- No timeout configured on lock acquisition.
Step 5: Apply Resolution Strategies
- Implement lock timeouts to avoid indefinite waits.
- Introduce retry with exponential backoff.
- Refactor saga to reorder steps to prevent circular waits.
Step 6: Preventive Best Practices
- Avoid locking multiple resources simultaneously.
- Use event-driven compensations rather than locks where possible.
- Monitor saga execution times and alert on anomalies.
Code Snippet: Detecting and Logging Deadlock Conditions
// Pseudocode for lock acquisition with timeout
boolean acquireLockWithTimeout(Resource resource, Duration timeout) {
Instant start = Instant.now();
while (Duration.between(start, Instant.now()).compareTo(timeout) < 0) {
if (resource.tryLock()) {
return true;
}
Thread.sleep(100); // wait before retry
}
log.warn("Failed to acquire lock on resource {} within timeout", resource.getId());
return false;
}
Summary
Troubleshooting deadlocks in distributed sagas requires a combination of understanding the saga orchestration, leveraging observability tools like distributed tracing and logs, and applying best practices such as lock timeouts and careful saga design. By following a systematic approach, engineers can identify deadlocks quickly and implement solutions to maintain high concurrency and system reliability.
9.5 Best Practice: Implementing Chaos Engineering to Identify Weaknesses
Chaos Engineering is a proactive discipline used to improve system resilience by intentionally injecting faults and observing how the system behaves under stress. In high concurrency, event-driven microservices, chaos engineering helps uncover hidden weaknesses that traditional testing might miss.
Why Chaos Engineering?
- Uncover Hidden Failures: Real-world failures are often unpredictable; chaos engineering simulates these conditions.
- Validate Resilience Patterns: Test circuit breakers, bulkheads, retries, and fallback mechanisms under real load.
- Improve Observability: Forces teams to enhance monitoring and alerting to detect injected faults quickly.
- Build Confidence: Ensures systems can gracefully handle failures without impacting users.
Key Principles of Chaos Engineering
- Start with a steady state: Define normal system behavior using metrics.
- Hypothesize about potential failures and their impact.
- Introduce controlled experiments that simulate failures.
- Measure the system’s response and learn from results.
Mind Map: Chaos Engineering Workflow

Common Chaos Experiments for Event-Driven Microservices
| Experiment Type | Description | Example Scenario |
|---|---|---|
| Network Latency Injection | Introduce artificial delays between services | Delay event delivery between producer and consumer |
| Pod/Instance Kill | Randomly terminate microservice instances | Kill order processing service pod during peak load |
| Message Loss | Drop or duplicate messages in event broker | Simulate dropped payment confirmation events |
| Resource Exhaustion | Limit CPU, memory to simulate resource constraints | Throttle CPU on inventory service to test backpressure |
| Dependency Failure | Make downstream services unavailable | Simulate database outage for user profile service |
Example: Injecting Network Latency in Kafka Consumers
# Using tc (traffic control) to add 200ms latency on Kafka consumer pod
kubectl exec -it kafka-consumer-pod -- tc qdisc add dev eth0 root netem delay 200ms
Observation: Monitor if consumer lag increases, if retries or timeouts occur, and if fallback mechanisms trigger.
Learning: If lag spikes cause downstream services to fail, consider implementing buffering or scaling consumers.
Mind Map: Observability Enhancements for Chaos Experiments
Best Practices for Running Chaos Experiments
- Start Small: Begin with low blast radius experiments in staging or canary environments.
- Automate Experiments: Use tools like Chaos Mesh, Gremlin, or LitmusChaos for repeatability.
- Collaborate: Involve developers, SREs, and QA teams to interpret results and plan mitigations.
- Document Learnings: Maintain a knowledge base of failures and fixes.
- Integrate with CI/CD: Run chaos tests as part of deployment pipelines to catch regressions early.
Example: Using Chaos Mesh to Kill a Microservice Pod
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: kill-order-service
namespace: production
spec:
action: pod-kill
mode: one
selector:
namespaces:
- production
labelSelectors:
"app": "order-service"
duration: "30s"
scheduler:
cron: "@every 10m"
This experiment kills one instance of the order-service every 10 minutes for 30 seconds, simulating unexpected crashes.
Expected Outcome: The system should reroute traffic, retry events, or spin up new pods without user impact.
Summary
Implementing chaos engineering in high concurrency, event-driven microservices is essential to uncover subtle failure modes and improve system robustness. By combining fault injection with strong observability and iterative learning, teams can build resilient systems that maintain availability and performance even under adverse conditions.
10. Security Considerations in Event Driven High Concurrency Systems
10.1 Securing Event Brokers and Message Channels
Securing event brokers and message channels is a critical aspect of building a robust, reliable, and trustworthy event-driven microservices architecture, especially under high concurrency scenarios. Event brokers act as the backbone for communication between microservices, and any security lapse can lead to data leaks, unauthorized access, or message tampering.
Why Security Matters in Event Brokers
- Event brokers handle sensitive data flowing between services.
- They are often exposed to multiple services, increasing attack surface.
- Unauthorized access can lead to message interception, injection, or replay attacks.
- Ensuring confidentiality, integrity, and availability is essential.
Key Security Goals for Event Brokers
- Authentication: Verify the identity of producers and consumers.
- Authorization: Control access to topics, queues, or channels.
- Encryption: Protect data in transit and at rest.
- Integrity: Ensure messages are not tampered with.
- Auditability: Maintain logs for security events and access.
Mind Map: Securing Event Brokers and Message Channels
Authentication Methods
-
TLS Client Certificates
- Mutual TLS (mTLS) ensures both client and broker authenticate each other.
- Example: Kafka supports mTLS to authenticate producers and consumers.
-
SASL Mechanisms
- SASL/PLAIN, SASL/SCRAM, SASL/GSSAPI (Kerberos) are common.
- Example: RabbitMQ supports SASL for user authentication.
-
OAuth 2.0 / JWT Tokens
- Used for token-based authentication, especially in cloud environments.
- Example: AWS SNS/SQS supports IAM roles and policies.
Authorization Strategies
- Role-Based Access Control (RBAC): Assign roles to users/services with specific permissions.
- Access Control Lists (ACLs): Define explicit allow/deny rules on topics or queues.
- Attribute-Based Access Control (ABAC): More dynamic, based on attributes like IP, time, or service metadata.
Example:
Kafka ACL to allow a user to produce to a topic:
bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 \
--add --allow-principal User:alice --operation Write --topic orders
Encryption
- TLS for Data in Transit: Encrypts messages between clients and brokers.
- Encryption at Rest: Broker storage encrypted to protect persisted messages.
- Key Management: Use secure vaults or KMS (Key Management Services) for encryption keys.
Example: Enabling TLS in RabbitMQ involves configuring certificates and enabling SSL listeners.
Ensuring Message Integrity
- Use message signing or HMAC to detect tampering.
- Brokers like Kafka can use checksums to verify message integrity.
Example: Kafka automatically calculates CRC32 checksums for messages.
Auditability and Monitoring
- Enable detailed access and event logs on brokers.
- Use monitoring tools to detect unusual access patterns.
Example: Kafka’s audit logs can be integrated with ELK stack for real-time analysis.
Broker Hardening Best Practices
- Network Segmentation: Isolate brokers in private subnets.
- Firewall Rules: Restrict access to broker ports only to trusted services.
- Configuration: Disable unused protocols, enforce strong cipher suites.
Practical Example: Securing Kafka Broker
# server.properties snippet
listeners=SSL://:9093
ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
ssl.keystore.password=your_keystore_password
ssl.key.password=your_key_password
ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
ssl.truststore.password=your_truststore_password
security.inter.broker.protocol=SSL
ssl.client.auth=required
# Enable SASL/SCRAM
sasl.enabled.mechanisms=SCRAM-SHA-256
listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="broker" password="broker-password";
- This config enables mutual TLS and SASL/SCRAM authentication.
- ACLs can be added to restrict topic access.
Summary
Securing event brokers and message channels requires a multi-layered approach combining authentication, authorization, encryption, integrity checks, and auditability. By following best practices and leveraging broker-specific security features, you can protect your event-driven microservices from common security threats while maintaining high concurrency and performance.
References
- Apache Kafka Security Documentation: https://kafka.apache.org/documentation/#security
- RabbitMQ Security Guide: https://www.rabbitmq.com/security.html
- OWASP Messaging Security Cheat Sheet: https://cheatsheetseries.owasp.org/cheatsheets/Messaging_Security_Cheat_Sheet.html
10.2 Authentication and Authorization in Microservices Communication
In a microservices architecture, especially one designed for high concurrency and event-driven communication, securing inter-service communication is critical. Authentication and authorization ensure that only legitimate services and users can access resources and perform actions, protecting the system from unauthorized access, data breaches, and malicious activities.
Understanding Authentication vs Authorization
- Authentication: Verifying the identity of a service or user.
- Authorization: Determining whether the authenticated entity has permission to perform a specific action or access a resource.
Challenges in Microservices Communication Security
- Multiple services communicating asynchronously.
- Dynamic service instances and scaling.
- Token propagation across service calls.
- Managing credentials and secrets securely.
Common Authentication and Authorization Strategies
Mind Map: Authentication and Authorization Strategies in Microservices
Token-Based Authentication with JWT
JWTs are widely used for stateless authentication in microservices. They carry claims about the user or service and are signed to ensure integrity.
Example: JWT Authentication Flow
- User logs in and obtains a JWT from the Authentication Service.
- The user includes the JWT in the Authorization header (
Bearer <token>) when calling a microservice. - Each microservice validates the JWT signature and extracts claims.
- Authorization decisions are made based on claims (e.g., roles, scopes).
// Example JWT Payload
{
"sub": "user123",
"roles": ["order:read", "order:write"],
"iat": 1686000000,
"exp": 1686003600
}
Best Practice: Validate JWTs Locally
- Avoid calling the auth server on every request.
- Use public keys or shared secrets to verify signatures.
Mutual TLS (mTLS) for Service-to-Service Authentication
mTLS provides strong authentication by requiring both client and server to present certificates during the TLS handshake.
Mind Map: mTLS Workflow
Example: Enabling mTLS in Kubernetes
- Use a service mesh like Istio or Linkerd that automates mTLS.
- Certificates are issued and rotated automatically.
# Example Istio PeerAuthentication to enforce mTLS
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: default
spec:
mtls:
mode: STRICT
Authorization Using RBAC and ABAC
- RBAC: Assign permissions based on roles.
- ABAC: Use attributes (user, resource, environment) to make fine-grained decisions.
Example: RBAC Policy in a Microservice
{
"role": "order_manager",
"permissions": ["create_order", "update_order", "view_order"]
}
Example: ABAC Policy Using Claims
- Allow access if
departmentclaim equalssalesandresource.ownerequals user ID.
Propagating Identity and Permissions in Event-Driven Communication
In event-driven systems, requests are often asynchronous, making it challenging to propagate authentication and authorization context.
Best Practice: Include Security Context in Event Metadata
- Attach JWT or minimal claims in event headers.
- Services validate the token or claims before processing.
Example: Event Metadata with JWT
{
"eventType": "OrderCreated",
"payload": { "orderId": "1234" },
"metadata": {
"authorization": "Bearer eyJhbGciOi..."
}
}
Example: Implementing Token-Based Auth in a Node.js Microservice
const express = require('express');
const jwt = require('jsonwebtoken');
const app = express();
const PUBLIC_KEY = `-----BEGIN PUBLIC KEY-----\n...\n-----END PUBLIC KEY-----`;
// Middleware to authenticate JWT
function authenticateToken(req, res, next) {
const authHeader = req.headers['authorization'];
const token = authHeader && authHeader.split(' ')[1];
if (!token) return res.sendStatus(401);
jwt.verify(token, PUBLIC_KEY, { algorithms: ['RS256'] }, (err, user) => {
if (err) return res.sendStatus(403);
req.user = user;
next();
});
}
// Middleware for authorization
function authorizeRole(role) {
return (req, res, next) => {
if (req.user.roles && req.user.roles.includes(role)) {
next();
} else {
res.sendStatus(403);
}
};
}
app.get('/orders', authenticateToken, authorizeRole('order:read'), (req, res) => {
res.json({ orders: [] });
});
app.listen(3000, () => console.log('Order service running'));
Summary
- Use JWTs for stateless authentication and embed authorization claims.
- Employ mTLS for strong service-to-service authentication.
- Implement RBAC or ABAC for flexible authorization policies.
- Propagate security context in event metadata for asynchronous flows.
- Validate tokens locally to reduce latency and dependency.
By integrating these authentication and authorization strategies, microservices can securely handle high concurrency communication while maintaining robust access control.
10.3 Protecting Against Replay Attacks and Event Tampering
In event-driven microservices architectures, ensuring the integrity and authenticity of events is critical, especially under high concurrency where events are processed asynchronously and potentially by multiple consumers. Replay attacks and event tampering can lead to duplicated processing, inconsistent state, or even security breaches.
Understanding Replay Attacks and Event Tampering
- Replay Attack: An attacker or malfunctioning system resends a previously captured event to the system, causing repeated processing.
- Event Tampering: Unauthorized modification of event data during transit or storage, leading to corrupted or maliciously altered information.
Both can cause serious issues such as double spending in financial systems, duplicated orders, or corrupted data states.
Mind Map: Key Concepts in Protecting Events
Best Practices with Examples
Use Unique Event Identifiers and Idempotency Keys
Each event should carry a globally unique identifier (UUID) or an idempotency key. Consumers can use this key to detect and discard duplicate events.
Example:
{
"eventId": "123e4567-e89b-12d3-a456-426614174000",
"type": "OrderPlaced",
"payload": { "orderId": "ORD-1001", "amount": 250 },
"timestamp": "2024-06-01T12:00:00Z"
}
When the consumer receives an event, it checks if eventId has already been processed. If yes, it ignores the event, preventing replay.
Include Timestamps and Expiry Logic
Events should include a timestamp, and consumers should reject events older than a certain threshold.
Example:
from datetime import datetime, timedelta
MAX_EVENT_AGE = timedelta(minutes=5)
def is_event_fresh(event_timestamp):
event_time = datetime.fromisoformat(event_timestamp.replace('Z', '+00:00'))
return datetime.utcnow() - event_time < MAX_EVENT_AGE
# Usage
if not is_event_fresh(event['timestamp']):
print("Discarding stale event")
This prevents attackers or bugs from replaying old events indefinitely.
Digital Signatures and Message Authentication Codes (MACs)
Sign events cryptographically to ensure authenticity and integrity.
Example: Using HMAC with SHA-256:
import hmac
import hashlib
SECRET_KEY = b'supersecretkey'
def sign_event(event_payload):
message = event_payload.encode('utf-8')
signature = hmac.new(SECRET_KEY, message, hashlib.sha256).hexdigest()
return signature
# On consumer side, verify signature before processing
This ensures that any tampering with the event payload invalidates the signature.
Secure Transport Channels
Always use TLS encryption for event transmission between microservices and event brokers.
Example: Configuring Kafka with SSL:
security.protocol=SSL
ssl.keystore.location=/var/private/ssl/kafka.keystore.jks
ssl.keystore.password=changeit
ssl.key.password=changeit
ssl.truststore.location=/var/private/ssl/kafka.truststore.jks
ssl.truststore.password=changeit
This prevents man-in-the-middle attacks that could tamper or replay events.
Immutable Event Storage and Append-Only Logs
Store events in append-only logs (e.g., Kafka topics, event stores) to prevent unauthorized modification.
Example: Using Kafka’s log compaction and retention policies to maintain immutable event history.
Implement Replay Detection in Consumers
Consumers maintain a cache or database of processed event IDs with TTL (time-to-live) to detect duplicates.
Example: Redis-based deduplication
import redis
r = redis.Redis()
def is_duplicate(event_id):
if r.exists(event_id):
return True
else:
r.set(event_id, 'processed', ex=3600) # Keep record for 1 hour
return False
# Usage
if is_duplicate(event['eventId']):
print("Duplicate event detected")
else:
process_event(event)
Sequence Numbers and Ordering Guarantees
Use sequence numbers per event stream to detect missing or replayed events.
Example:
{
"eventId": "evt-1001",
"sequenceNumber": 42,
"type": "PaymentProcessed",
"payload": { ... }
}
Consumer verifies that sequence numbers increase monotonically and flags out-of-order or repeated events.
Mind Map: Replay Attack Prevention Workflow
Summary
Protecting against replay attacks and event tampering is a multi-layered effort involving:
- Designing events with unique identifiers and timestamps
- Cryptographically signing events
- Securing transport channels
- Maintaining idempotent and stateful consumers
- Implementing replay detection caches
- Monitoring and alerting on suspicious activity
By integrating these practices, microservices can maintain data integrity and security even under high concurrency and asynchronous event processing.
10.4 Example: Implementing Token-Based Security in Event Messages
Introduction
In event-driven microservices architectures, securing event messages is critical to prevent unauthorized access, tampering, and replay attacks. Token-based security is a common approach to authenticate and authorize event producers and consumers. This section demonstrates how to implement token-based security in event messages with practical examples and mind maps to clarify concepts.
Why Token-Based Security for Event Messages?
- Authentication: Verifies the identity of the event sender.
- Authorization: Ensures the sender has permission to publish or consume certain events.
- Integrity: Confirms the event message has not been altered.
- Replay Protection: Prevents attackers from resending old messages.
Mind Map: Token-Based Security in Event Messages
Step 1: Choosing the Token Format
JSON Web Tokens (JWT) are widely used because they are compact, self-contained, and can carry claims (metadata). They can be signed (JWS) or encrypted (JWE).
Example JWT payload for an event message:
{
"iss": "order-service",
"sub": "event-publisher",
"aud": "inventory-service",
"iat": 1686000000,
"exp": 1686003600,
"event": "OrderCreated",
"roles": ["publisher"]
}
iss: Issuer of the tokensub: Subject (entity sending the event)aud: Audience (intended recipient service)iat: Issued at timestampexp: Expiration timestampevent: Event typeroles: Permissions or roles
Step 2: Token Generation (Event Publisher Side)
import jwt
import time
SECRET_KEY = 'your-very-secure-secret'
def generate_event_token(event_type, issuer, subject, audience, roles):
current_time = int(time.time())
payload = {
'iss': issuer,
'sub': subject,
'aud': audience,
'iat': current_time,
'exp': current_time + 3600, # 1 hour expiration
'event': event_type,
'roles': roles
}
token = jwt.encode(payload, SECRET_KEY, algorithm='HS256')
return token
# Example usage
jwt_token = generate_event_token(
event_type='OrderCreated',
issuer='order-service',
subject='event-publisher',
audience='inventory-service',
roles=['publisher']
)
print(jwt_token)
Step 3: Attaching Token to Event Message
When publishing an event, include the token in the message metadata or headers depending on the messaging system.
Example with Kafka (using headers):
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
event_payload = b'{"orderId": "12345", "status": "created"}'
producer.send(
'order-events',
value=event_payload,
headers=[('authorization', jwt_token.encode())]
)
producer.flush()
Step 4: Token Validation (Event Consumer Side)
def validate_event_token(token, expected_audience):
try:
decoded = jwt.decode(token, SECRET_KEY, algorithms=['HS256'], audience=expected_audience)
# Additional checks: roles, event type, expiration
if 'publisher' not in decoded.get('roles', []):
raise Exception('Unauthorized role')
return decoded
except jwt.ExpiredSignatureError:
raise Exception('Token expired')
except jwt.InvalidTokenError as e:
raise Exception(f'Invalid token: {str(e)}')
# Example usage
try:
token_from_event = jwt_token # Extracted from event headers
claims = validate_event_token(token_from_event, expected_audience='inventory-service')
print('Token valid:', claims)
except Exception as e:
print('Token validation failed:', e)
Step 5: Replay Protection
- Use the
iat(issued at) andexp(expiration) claims to limit token validity. - Optionally, include a unique nonce or event ID and maintain a cache of processed tokens/events to detect duplicates.
Example nonce inclusion:
{
"jti": "unique-event-id-12345"
}
In consumer:
- Check if
jtiwas processed before. - If yes, discard the event to prevent replay.
Mind Map: Token Validation Workflow
Summary
Implementing token-based security in event messages involves:
- Generating signed tokens (e.g., JWT) with relevant claims.
- Attaching tokens securely to event messages.
- Validating tokens on the consumer side to authenticate and authorize.
- Employing replay protection mechanisms.
This approach enhances the security posture of event-driven microservices, especially under high concurrency where many services communicate asynchronously.
References & Tools
- JWT.io - JWT debugging and libraries
- PyJWT Documentation
- OAuth 2.0 and JWT
- Kafka Headers documentation
By following these steps and best practices, senior backend engineers can confidently secure event messages in their high concurrency microservices architectures.
10.5 Best Practice: Auditing and Compliance in Event Driven Architectures
In event driven architectures (EDA), auditing and compliance are critical to ensure traceability, accountability, and adherence to regulatory requirements. Unlike traditional request-response systems, EDA introduces asynchronous flows and distributed components, which complicate audit trails. This section covers best practices to implement robust auditing and compliance mechanisms in event driven microservices, supported by practical examples and mind maps.
Why Auditing and Compliance Matter in EDA
- Traceability: Track the lifecycle of events across services to understand system behavior.
- Accountability: Identify who or what triggered specific events.
- Regulatory Compliance: Meet standards such as GDPR, HIPAA, PCI-DSS requiring data access logs and change histories.
- Security: Detect unauthorized access or tampering with event data.
Key Components of Auditing in EDA
Best Practices
-
Implement Immutable, Structured Event Logs
- Use append-only storage (e.g., Kafka topics with retention policies, or write-ahead logs).
- Store events in a structured format like JSON or Avro with clear schemas.
- Example: Using Apache Kafka with a dedicated audit topic where all events are replicated for audit purposes.
-
Enrich Events with Comprehensive Metadata
- Include timestamps, unique event IDs (UUIDs), source service identifiers, user IDs, and correlation IDs.
- Example: An order event containing
eventId,timestamp,originService,userId, andcorrelationIdfields.
-
Use Distributed Tracing to Correlate Events Across Services
- Implement OpenTelemetry or Zipkin to propagate trace and span IDs.
- Enables reconstructing event flow end-to-end for audits.
-
Secure Event Channels and Storage
- Encrypt event data at rest and in transit.
- Authenticate and authorize producers and consumers.
- Example: Using TLS for Kafka communication and RBAC for topic access.
-
Define and Enforce Data Retention and Archival Policies
- Retain audit logs for the minimum period required by regulations.
- Archive older logs to immutable storage (e.g., WORM storage).
-
Automate Compliance Monitoring and Alerting
- Use SIEM tools to analyze audit logs for suspicious activity.
- Set alerts for policy violations or unexpected event patterns.
-
Implement Tamper-Evident Mechanisms
- Use cryptographic hashes or blockchain-inspired append-only ledgers to detect modifications.
Example: Auditing an Order Microservice Event Flow
{
"eventId": "123e4567-e89b-12d3-a456-426614174000",
"eventType": "OrderCreated",
"timestamp": "2024-06-01T12:34:56.789Z",
"originService": "OrderService",
"userId": "user-98765",
"correlationId": "trace-abc123",
"payload": {
"orderId": "order-54321",
"items": [
{"productId": "prod-111", "quantity": 2},
{"productId": "prod-222", "quantity": 1}
],
"totalAmount": 150.75
}
}
- This event is logged immutably in Kafka.
- The
correlationIdlinks this event to subsequent events likePaymentProcessedandOrderShipped. - Access to the audit topic is restricted via RBAC.
- Logs are retained for 1 year and archived thereafter.
Mind Map: Audit Event Lifecycle
Additional Tips
- Version your event schemas to maintain compatibility and auditability over time.
- Log both successful and failed event processing attempts to capture complete audit trails.
- Integrate audit logs with centralized logging and monitoring platforms for easier compliance reporting.
By following these practices, teams can build event driven microservices that not only scale under high concurrency but also maintain rigorous auditing and compliance standards essential for enterprise-grade applications.
11. Case Studies and Real-World Implementations
11.1 Case Study: High Concurrency Ticket Booking System
Overview
In this case study, we explore the design and implementation of a high concurrency ticket booking system using Event Driven Architecture (EDA) and observability best practices. Ticket booking platforms often face intense traffic spikes during popular event launches, requiring a system that can handle thousands of concurrent requests with low latency and high reliability.
System Requirements
- Handle thousands of concurrent booking requests per second
- Prevent overbooking and ensure data consistency
- Provide real-time updates on seat availability
- Maintain high availability and fault tolerance
- Enable detailed observability for monitoring and troubleshooting
Architecture Mind Map
Key Components and Their Roles
-
API Gateway: Acts as the entry point, handling authentication, rate limiting, and routing to microservices.
-
Booking Microservice: Handles user booking requests, initiates seat reservation events, and processes payments.
-
Inventory Microservice: Maintains the current state of seat availability using event sourcing to ensure consistency.
-
Event Broker (Kafka): Facilitates asynchronous communication between microservices, enabling decoupling and scalability.
-
Notification Microservice: Sends booking confirmations and alerts to users.
-
Observability Stack: Collects metrics, logs, and traces to monitor system health and diagnose issues.
Event Flow Example
User books a ticket -> API Gateway -> Booking Microservice
Booking Microservice publishes seat-reservation event -> Inventory Microservice
Inventory Microservice validates and updates seat availability -> publishes seat-reserved event
Booking Microservice listens for seat-reserved event -> processes payment
Payment success -> publishes payment-success event
Notification Microservice listens -> sends confirmation to user
Best Practice: Idempotent Event Handlers
To handle retries and duplicate events, event handlers are designed to be idempotent.
Example:
processed_events = set()
def handle_seat_reservation(event):
if event.id in processed_events:
return # Ignore duplicate
# Process reservation
reserve_seat(event.seat_id)
processed_events.add(event.id)
Handling Overbooking with Saga Pattern
The Saga pattern coordinates distributed transactions across microservices.
Mind Map:
Example:
# Pseudo-code for saga orchestration
try:
reserve_seat(seat_id)
process_payment(user_id, amount)
confirm_booking()
except PaymentFailed:
release_seat(seat_id)
notify_user('Payment failed')
except SeatUnavailable:
notify_user('Seat not available')
Observability Implementation
- Metrics: Track request rates, success/failure counts, latency per microservice.
- Distributed Tracing: Use OpenTelemetry to trace requests across services asynchronously.
- Logging: Centralized logs with correlation IDs to link events.
Example:
# Prometheus metrics example for Booking Microservice
booking_requests_total{status="success"}
booking_requests_total{status="failure"}
booking_request_latency_seconds
Trace Example:
TraceID: 1234
Span1: API Gateway -> Booking Microservice
Span2: Booking Microservice -> Inventory Microservice
Span3: Inventory Microservice -> Kafka
Span4: Notification Microservice
Load Testing and Scaling
- Use tools like Locust or JMeter to simulate high concurrency booking requests.
- Scale microservices horizontally based on CPU and memory usage.
- Partition Kafka topics by event type and key (e.g., event ID) for parallel processing.
Summary
This case study demonstrates how an event driven microservices architecture, combined with patterns like Saga and best practices in observability, can effectively handle high concurrency scenarios such as ticket booking. The asynchronous event flow enables scalability and resilience, while observability ensures system health and rapid troubleshooting.
References
- Event Sourcing and CQRS
- Saga Pattern
- OpenTelemetry
- Apache Kafka
- Prometheus Monitoring
11.2 Case Study: Real-Time Analytics Pipeline with Event Driven Microservices
Overview
In this case study, we explore the design and implementation of a real-time analytics pipeline built using event driven microservices. The system ingests high volumes of streaming data, processes it concurrently, and delivers near-instant insights to end users. This architecture demonstrates best practices for handling high concurrency, event-driven communication, and observability.
System Requirements
- Ingest streaming data from multiple sources (e.g., user activity, IoT sensors, logs)
- Process data in real-time to generate analytics metrics and alerts
- Scale horizontally to handle spikes in data volume
- Ensure fault tolerance and data consistency
- Provide observability for monitoring and troubleshooting
High-Level Architecture Mind Map
Detailed Components
Data Ingestion
- Event Broker: Apache Kafka is used for its high throughput and partitioning capabilities.
- Producers: Multiple microservices and SDKs publish events asynchronously.
Example: Kafka Producer in Java
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("user-events", "user123", "{\"action\":\"click\"}");
producer.send(record);
producer.close();
Stream Processing Microservices
- Consume events from Kafka topics.
- Perform filtering, transformation, and aggregation.
- Publish processed events to downstream topics.
Example: Filtering and Aggregation in Kafka Streams (Java)
KStream<String, String> source = builder.stream("user-events");
KStream<String, String> filtered = source.filter((key, value) -> value.contains("click"));
KTable<String, Long> counts = filtered.groupByKey()
.count(Materialized.as("click-counts-store"));
counts.toStream().to("click-counts");
Storage
- Aggregated metrics are stored in a time-series database for fast querying.
- Raw events can be archived in a data warehouse for batch analytics.
Serving Layer
- API Gateway exposes REST endpoints for dashboards and alerting systems.
- Dashboards visualize real-time metrics.
Observability
- Metrics collected via Prometheus exporters.
- Distributed tracing implemented with OpenTelemetry.
- Centralized logging with ELK stack.
Mind Map: Event Flow
Best Practices Illustrated
| Practice | Description | Example |
|---|---|---|
| Idempotent Event Handlers | Ensure event processors can safely retry without side effects | Stream processors use unique event keys and state stores to avoid double counting |
| Backpressure Handling | Use Kafka consumer lag monitoring and adjust processing rate | Autoscaling stream processors based on lag metrics |
| Observability Integration | Instrument microservices with metrics, logs, and traces | OpenTelemetry traces span ingestion to serving layers |
| Saga Pattern for Data Consistency | Coordinate multi-step processing with compensating actions | If aggregation fails, trigger compensating event to rollback partial state |
Example: Observability Trace (OpenTelemetry)
{
"traceId": "4bf92f3577b34da6a3ce929d0e0e4736",
"spans": [
{
"spanId": "00f067aa0ba902b7",
"name": "Kafka Consume",
"startTime": "2024-06-01T12:00:00Z",
"endTime": "2024-06-01T12:00:01Z"
},
{
"spanId": "b9c7c989f97918e1",
"name": "Filter & Aggregate",
"startTime": "2024-06-01T12:00:01Z",
"endTime": "2024-06-01T12:00:02Z",
"parentSpanId": "00f067aa0ba902b7"
},
{
"spanId": "c1a1f7b1e5d9f3a2",
"name": "Write to Time-Series DB",
"startTime": "2024-06-01T12:00:02Z",
"endTime": "2024-06-01T12:00:03Z",
"parentSpanId": "b9c7c989f97918e1"
}
]
}
Summary
This case study demonstrates how an event driven microservices architecture can efficiently handle high concurrency for real-time analytics. By leveraging Kafka for event streaming, scalable stream processing microservices, and robust observability tooling, the system achieves low latency, fault tolerance, and operational transparency. The examples and mind maps provide concrete guidance for implementing similar pipelines in your own projects.
11.3 Lessons Learned from Scaling a Financial Trading Platform
Scaling a financial trading platform to handle high concurrency and ensure low latency is a complex challenge. This section explores key lessons learned from real-world experiences, emphasizing event driven architecture (EDA) and observability practices that proved critical.
Key Challenges Faced
- Extreme Low Latency Requirements: Trades must be executed within milliseconds.
- High Throughput: Thousands of orders per second during market peaks.
- Data Consistency: Maintaining accurate order books and balances.
- Fault Tolerance: Ensuring no single point of failure.
- Regulatory Compliance: Auditing and traceability.
Lesson 1: Embrace Event-Driven Architecture for Decoupling and Scalability
Mind Map:
Example:
The platform used Kafka topics to decouple order intake, risk checks, and trade execution. Each microservice consumed relevant events asynchronously, allowing independent scaling and fault isolation.
Lesson 2: Implement Idempotent Event Handlers to Avoid Duplicate Processing
Mind Map:
Example:
Order execution microservice stored processed event IDs in a Redis cache. If a duplicate order event arrived (due to retries), it was ignored, preventing double trades.
Lesson 3: Use Saga Pattern for Distributed Transaction Management
Mind Map:
Example:
A trade involved reserving funds, updating order books, and notifying clearing systems. The saga coordinated these steps via events, and if any step failed, compensating events rolled back prior actions.
Lesson 4: Prioritize Observability to Detect and Diagnose Issues Quickly
Mind Map:
Example:
Using OpenTelemetry, the team implemented distributed tracing that linked order submission events through risk checks to trade execution. When latency spikes occurred, traces helped identify bottlenecks in the risk service.
Lesson 5: Design for Backpressure and Load Shedding
Mind Map:
Example:
During market surges, the platform applied backpressure by slowing order intake when downstream services were overwhelmed. Non-critical analytics events were shed temporarily to preserve core trading functionality.
Lesson 6: Ensure Security and Compliance in Event Flows
Mind Map:
Example:
All events were signed and encrypted before publishing to Kafka. Services verified signatures to prevent tampering. Audit logs stored immutable event histories for regulatory compliance.
Summary Table of Lessons
| Lesson | Description | Example |
|---|---|---|
| 1 | Use EDA for decoupling and scalability | Kafka topics for order processing |
| 2 | Idempotent event handlers prevent duplicates | Redis cache for processed event IDs |
| 3 | Saga pattern manages distributed transactions | Coordinated trade steps with compensations |
| 4 | Observability enables quick issue detection | OpenTelemetry tracing of event flows |
| 5 | Backpressure and load shedding protect system | Slowing order intake during surges |
| 6 | Security and compliance in event messaging | Event signing and audit logs |
Final Thoughts
Scaling a financial trading platform requires a holistic approach combining architectural patterns, robust event handling, and comprehensive observability. The lessons learned highlight the importance of designing for failure, monitoring deeply, and securing every event. These principles empower teams to build resilient, high concurrency microservices capable of thriving under intense market conditions.
11.4 Example Code Walkthrough: Event Driven Order Fulfillment
In this section, we’ll walk through a practical example of an event-driven order fulfillment microservice system designed to handle high concurrency. We’ll cover the architecture, event flow, code snippets, and best practices integrated into the design.
Overview
The order fulfillment system consists of several microservices collaborating asynchronously through events:
- Order Service: Receives and validates orders.
- Inventory Service: Checks and reserves stock.
- Payment Service: Processes payments.
- Shipping Service: Arranges shipment.
Each service publishes and subscribes to domain events, enabling loose coupling and scalability.
Mind Map: Event Driven Order Fulfillment Flow
Event Flow Explanation
- OrderPlaced Command: Client submits an order.
- OrderValidated Event: Order Service validates and emits this event.
- InventoryReserved / InventoryFailed Event: Inventory Service attempts to reserve stock.
- PaymentProcessed / PaymentFailed Event: Payment Service processes payment.
- ShipmentCreated Event: Shipping Service creates shipment.
- Order Completed: Order Service marks order as completed.
Failures trigger compensating transactions handled by a Saga orchestrator.
Code Snippets
Order Service - Publishing OrderValidated Event
# order_service.py
import json
from messaging import EventPublisher
class OrderService:
def __init__(self):
self.publisher = EventPublisher(topic='order-events')
def place_order(self, order_data):
# Validate order
if not self._validate(order_data):
raise ValueError("Invalid order data")
event = {
'event_type': 'OrderValidated',
'order_id': order_data['order_id'],
'customer_id': order_data['customer_id'],
'items': order_data['items']
}
self.publisher.publish(json.dumps(event))
def _validate(self, order_data):
# Simplified validation logic
return 'order_id' in order_data and 'items' in order_data and len(order_data['items']) > 0
Inventory Service - Handling OrderValidated and Publishing InventoryReserved
# inventory_service.py
import json
from messaging import EventSubscriber, EventPublisher
class InventoryService:
def __init__(self):
self.subscriber = EventSubscriber(topic='order-events', group='inventory-service')
self.publisher = EventPublisher(topic='inventory-events')
def start(self):
self.subscriber.subscribe(self.handle_order_validated)
def handle_order_validated(self, message):
event = json.loads(message)
if event['event_type'] != 'OrderValidated':
return
order_id = event['order_id']
items = event['items']
if self._reserve_inventory(items):
inventory_event = {
'event_type': 'InventoryReserved',
'order_id': order_id
}
else:
inventory_event = {
'event_type': 'InventoryFailed',
'order_id': order_id
}
self.publisher.publish(json.dumps(inventory_event))
def _reserve_inventory(self, items):
# Example: Check stock and reserve
# For demo, assume always successful
return True
Payment Service - Processing InventoryReserved Event
# payment_service.py
import json
from messaging import EventSubscriber, EventPublisher
class PaymentService:
def __init__(self):
self.subscriber = EventSubscriber(topic='inventory-events', group='payment-service')
self.publisher = EventPublisher(topic='payment-events')
def start(self):
self.subscriber.subscribe(self.handle_inventory_reserved)
def handle_inventory_reserved(self, message):
event = json.loads(message)
if event['event_type'] != 'InventoryReserved':
return
order_id = event['order_id']
if self._process_payment(order_id):
payment_event = {
'event_type': 'PaymentProcessed',
'order_id': order_id
}
else:
payment_event = {
'event_type': 'PaymentFailed',
'order_id': order_id
}
self.publisher.publish(json.dumps(payment_event))
def _process_payment(self, order_id):
# Simulate payment processing
return True
Shipping Service - Creating Shipment on PaymentProcessed
# shipping_service.py
import json
from messaging import EventSubscriber, EventPublisher
class ShippingService:
def __init__(self):
self.subscriber = EventSubscriber(topic='payment-events', group='shipping-service')
self.publisher = EventPublisher(topic='shipping-events')
def start(self):
self.subscriber.subscribe(self.handle_payment_processed)
def handle_payment_processed(self, message):
event = json.loads(message)
if event['event_type'] != 'PaymentProcessed':
return
order_id = event['order_id']
shipment_id = self._create_shipment(order_id)
shipment_event = {
'event_type': 'ShipmentCreated',
'order_id': order_id,
'shipment_id': shipment_id
}
self.publisher.publish(json.dumps(shipment_event))
def _create_shipment(self, order_id):
# Simulate shipment creation
return f"SHIP-{order_id}"
Order Service - Finalizing Order on ShipmentCreated
# order_service.py (continued)
class OrderService:
# ... existing methods ...
def start(self):
subscriber = EventSubscriber(topic='shipping-events', group='order-service')
subscriber.subscribe(self.handle_shipment_created)
def handle_shipment_created(self, message):
event = json.loads(message)
if event['event_type'] != 'ShipmentCreated':
return
order_id = event['order_id']
self._update_order_status(order_id, 'COMPLETED')
def _update_order_status(self, order_id, status):
print(f"Order {order_id} status updated to {status}")
Best Practices Demonstrated
- Idempotency: Each event handler should be idempotent to handle duplicate events gracefully.
- Loose Coupling: Services communicate asynchronously via events, reducing dependencies.
- Error Handling: While not fully shown, compensating transactions (Sagas) would handle failures.
- Scalability: Services can be scaled independently based on load.
- Observability: Each service can emit logs and metrics around event processing.
Mind Map: Best Practices in Code
Summary
This example demonstrates how an event-driven microservices architecture can effectively handle high concurrency order fulfillment. By decoupling services and using asynchronous event flows, the system achieves scalability, resilience, and maintainability. Integrating best practices such as idempotency and observability ensures robustness in production environments.
11.5 Best Practice: Continuous Improvement through Observability Feedback Loops
Continuous improvement is essential in managing high concurrency microservices, especially when leveraging event driven architecture (EDA). Observability feedback loops enable teams to detect, analyze, and act on system behavior in real-time, fostering a culture of proactive optimization and resilience.
What is an Observability Feedback Loop?
An observability feedback loop is a cyclical process where data collected from metrics, logs, and traces informs decisions that improve system performance, reliability, and scalability. This loop helps identify bottlenecks, failures, or inefficiencies and guides iterative enhancements.
Key Components of Observability Feedback Loops
Step-by-Step Example: Improving Order Processing Latency
-
Data Collection:
- Collect latency metrics from the order processing microservice using Prometheus.
- Capture distributed traces with OpenTelemetry to understand event flow delays.
-
Analysis:
- Detect latency spikes during peak hours.
- Trace analysis reveals a bottleneck in the event handler responsible for payment validation.
-
Action:
- Optimize the payment validation logic by caching frequent queries.
- Increase consumer instances to parallelize event processing.
-
Validation:
- Monitor latency metrics post-deployment.
- Confirm latency reduction and improved throughput.
-
Continuous Cycle:
- Set up automated alerts for latency anomalies.
- Schedule regular reviews of observability data to identify new improvement areas.
Mind Map: Observability Feedback Loop in Event Driven Microservices
Practical Tips for Implementing Feedback Loops
-
Automate Data Collection: Use tools like Prometheus, Grafana, ELK Stack, and Jaeger to gather and visualize observability data continuously.
-
Define Clear KPIs: Establish measurable indicators such as request latency, event processing rate, and error percentage.
-
Integrate Alerting: Configure alerts on threshold breaches to enable rapid response.
-
Enable Cross-Team Collaboration: Share observability insights across development, operations, and QA teams.
-
Leverage Machine Learning: Use anomaly detection algorithms to identify subtle issues before they impact users.
-
Document Learnings: Maintain a knowledge base of incidents, root causes, and resolutions to accelerate future troubleshooting.
Example: Automating Feedback Loop with Kubernetes and Prometheus
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: order-processing-alerts
spec:
groups:
- name: order-processing.rules
rules:
- alert: HighOrderProcessingLatency
expr: histogram_quantile(0.95, sum(rate(order_processing_latency_seconds_bucket[5m])) by (le)) > 1
for: 2m
labels:
severity: warning
annotations:
summary: "High 95th percentile latency in order processing"
description: "Latency has exceeded 1 second for over 2 minutes. Investigate event handler performance."
This alert triggers a notification, prompting the team to analyze and optimize the event handler, closing the feedback loop.
Summary
Observability feedback loops are vital for maintaining and improving high concurrency microservices built on event driven architecture. By continuously collecting and analyzing observability data, teams can make informed decisions, rapidly address issues, and iteratively enhance system performance and reliability.
Embracing these loops fosters a proactive culture where microservices evolve to meet growing demands efficiently and resiliently.
12. Future Trends and Emerging Technologies
12.1 Advances in Event Streaming Platforms and Protocols
Event streaming platforms and protocols have evolved rapidly to meet the demands of modern high concurrency microservices architectures. These advances enable systems to handle massive event throughput, provide low-latency processing, and ensure reliability and scalability. In this section, we explore the latest developments, highlight key features, and provide practical examples to help you leverage these technologies effectively.
Key Advances in Event Streaming Platforms
- Scalability and Throughput Enhancements
- Improved Protocols for Event Delivery
- Native Support for Exactly-Once Semantics
- Cloud-Native and Serverless Integrations
- Enhanced Security Features
- Multi-Tenancy and Isolation
Mind Map: Advances in Event Streaming Platforms
Popular Event Streaming Platforms and Their Advances
Apache Kafka
- KRaft Mode (Kafka Raft Metadata Mode): Removes dependency on ZooKeeper, simplifying cluster management and improving scalability.
- Tiered Storage: Enables offloading older data to cheaper storage, reducing costs and improving performance.
- Kafka Streams Enhancements: Improved APIs for stateful stream processing with better fault tolerance.
- Exactly-Once Semantics: Transactional APIs ensure no data duplication or loss.
Example: Implementing a transactional producer in Kafka to guarantee exactly-once delivery:
Producer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord<>("orders", "order123", "created"));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.abortTransaction();
}
Apache Pulsar
- Multi-Tenancy: Built-in support for namespaces and tenant isolation.
- Geo-Replication: Efficient cross-region replication with configurable consistency.
- Function as a Service (FaaS): Pulsar Functions allow lightweight stream processing.
- Protocol Support: Supports native Pulsar protocol, Kafka protocol, and MQTT.
Example: Using Pulsar Functions to enrich events on the fly:
from pulsar import Function
class EnrichFunction(Function):
def process(self, input, context):
input['enriched'] = True
return input
NATS JetStream
- Lightweight and High Performance: Designed for ultra-low latency messaging.
- At-Least-Once and Exactly-Once Delivery: Supports durable streams and message acknowledgments.
- Simplified Protocol: Uses a simple, text-based protocol with client libraries in many languages.
Example: Publishing a message with JetStream in Go:
js, _ := nc.JetStream()
js.Publish("orders", []byte("order_created"))
Emerging Protocols and Standards
- gRPC Streaming: Enables efficient bi-directional streaming with HTTP/2, reducing overhead and improving latency.
- HTTP/3 and QUIC: Promises faster connection establishment and improved multiplexing for event delivery.
- MQTT 5.0: Adds features like shared subscriptions, message expiry, and enhanced authentication, making it suitable for IoT event streaming.
Mind Map: Protocol Advances
Practical Example: Migrating from HTTP Polling to Event Streaming with Kafka
Scenario: A legacy order management system uses HTTP polling to check for new orders, causing high latency and load.
Solution: Replace polling with Kafka event streaming.
- Orders microservice publishes
OrderCreatedevents to Kafka. - Downstream services subscribe to the topic and react asynchronously.
- Observability tools monitor event lag and throughput.
Code Snippet: Publishing an event in Node.js using KafkaJS:
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ clientId: 'orders-service', brokers: ['broker1:9092'] });
const producer = kafka.producer();
async function publishOrderCreated(order) {
await producer.connect();
await producer.send({
topic: 'OrderCreated',
messages: [{ key: order.id, value: JSON.stringify(order) }],
});
await producer.disconnect();
}
Summary
Advances in event streaming platforms and protocols empower microservices architectures to handle high concurrency workloads efficiently. By adopting modern features like exactly-once semantics, multi-tenancy, and cloud-native integrations, backend engineers can build resilient, scalable, and observable systems. Understanding these advances and applying best practices with concrete examples ensures your microservices remain performant and maintainable in demanding environments.
12.2 Serverless Architectures for High Concurrency Microservices
Serverless architectures have revolutionized how we build and scale microservices, especially under high concurrency scenarios. By abstracting away infrastructure management, serverless platforms allow developers to focus on business logic while automatically handling scaling, fault tolerance, and resource allocation.
Why Serverless for High Concurrency?
- Automatic Scaling: Serverless functions scale instantly and elastically with incoming requests, making them ideal for unpredictable or spiky workloads.
- Cost Efficiency: Pay only for actual usage, which is beneficial when concurrency fluctuates.
- Reduced Operational Overhead: No need to manage servers, clusters, or capacity planning.
- Event-Driven Nature: Serverless platforms naturally align with event-driven architectures, triggering functions on events such as HTTP requests, message queue events, or database changes.
Key Concepts in Serverless Microservices for High Concurrency
Example: Building a Serverless Order Processing Microservice
Imagine an e-commerce platform that needs to handle thousands of concurrent orders during a flash sale. Using AWS Lambda (or any FaaS platform), we can design a serverless microservice to process orders asynchronously.
Architecture Overview:
- API Gateway: Receives order requests.
- Lambda Function: Validates and processes orders.
- Event Queue (SQS): Decouples order intake from processing.
- DynamoDB: Stores order state.
- Event Bridge: Emits events for downstream services (inventory, payment).
Code Snippet (Node.js Lambda Handler):
exports.handler = async (event) => {
const order = JSON.parse(event.body);
// Basic validation
if (!order.id || !order.items) {
return { statusCode: 400, body: 'Invalid order data' };
}
// Enqueue order for processing
await enqueueOrder(order);
return { statusCode: 202, body: 'Order accepted' };
};
async function enqueueOrder(order) {
// Example: send message to SQS queue
const AWS = require('aws-sdk');
const sqs = new AWS.SQS();
const params = {
QueueUrl: process.env.ORDER_QUEUE_URL,
MessageBody: JSON.stringify(order)
};
await sqs.sendMessage(params).promise();
}
Best Practice: Use queues to buffer spikes in concurrency and decouple ingestion from processing.
Handling Concurrency Limits and Cold Starts
Serverless platforms impose concurrency limits per account or function. To handle this:
- Request Queuing: Use message queues to smooth bursts.
- Provisioned Concurrency: Pre-warm functions to reduce cold start latency.
- Function Splitting: Break large functions into smaller, single-responsibility units.
Mind Map: Managing Serverless Concurrency
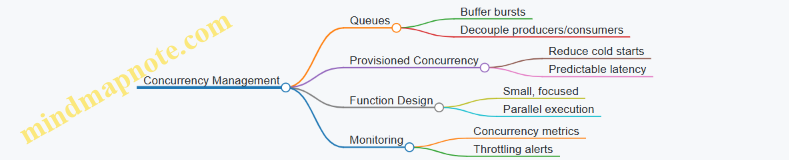
Observability in Serverless Microservices
Observability is critical to understand behavior under high concurrency:
- Distributed Tracing: Track requests across async boundaries.
- Structured Logging: Correlate logs with request IDs.
- Metrics: Monitor invocation counts, durations, errors, throttles.
Example: Using AWS X-Ray to trace Lambda executions and visualize latency hotspots.
Additional Example: Event-Driven Image Processing Pipeline
- Trigger: Upload to S3 bucket triggers Lambda.
- Lambda: Processes image (resize, watermark).
- Output: Stores processed image in another bucket.
This pattern scales automatically with upload concurrency.
Summary Best Practices
- Design functions to be stateless and idempotent.
- Use event queues to handle bursts and decouple services.
- Monitor concurrency metrics and set alerts.
- Mitigate cold starts with provisioned concurrency or keep-alive pings.
- Leverage native event triggers for seamless integration.
- Implement tracing and logging for observability.
Serverless architectures offer a powerful model for building high concurrency microservices that are scalable, cost-effective, and maintainable.
12.3 AI and Machine Learning for Predictive Observability
In modern high concurrency microservices environments, observability is critical not only for reactive troubleshooting but increasingly for proactive, predictive insights. AI and Machine Learning (ML) techniques empower engineers to anticipate system failures, performance degradations, and anomalies before they impact users. This section explores how AI/ML can be integrated into observability pipelines to enhance predictive capabilities.
Why Predictive Observability?
Traditional observability focuses on collecting metrics, logs, and traces to understand system behavior after an event occurs. Predictive observability leverages AI/ML models to analyze historical and real-time data to forecast potential issues, enabling preemptive remediation.
Benefits:
- Early detection of anomalies and performance degradation
- Reduced downtime and improved SLA adherence
- Automated root cause analysis assistance
- Optimized resource allocation based on predicted load
Key AI/ML Techniques in Predictive Observability
- Anomaly Detection: Identifying unusual patterns in metrics or logs that deviate from normal behavior.
- Time Series Forecasting: Predicting future values of system metrics (e.g., CPU usage, request latency).
- Classification and Clustering: Grouping similar events or errors to identify recurring issues.
- Root Cause Analysis Automation: Using ML to correlate events and trace data to pinpoint failure origins.
Mind Map: AI/ML Techniques for Predictive Observability
Example: Implementing Anomaly Detection on Latency Metrics
Consider a microservice emitting latency metrics every second. We want to detect anomalies indicating potential performance issues.
Step 1: Data Collection
- Collect latency metrics via Prometheus.
- Export data to an ML pipeline.
Step 2: Model Selection
- Use an unsupervised model like Isolation Forest or an LSTM autoencoder.
Step 3: Training and Inference
- Train model on historical latency data representing normal behavior.
- Run inference on real-time data to flag anomalies.
Code Snippet (Python, using scikit-learn Isolation Forest):
from sklearn.ensemble import IsolationForest
import numpy as np
# Simulated latency data (ms)
latency_data = np.array([100, 105, 98, 102, 500, 110, 108]).reshape(-1, 1)
model = IsolationForest(contamination=0.1)
model.fit(latency_data[:-1]) # Train on normal data
anomaly_score = model.decision_function(latency_data[-1].reshape(1, -1))
prediction = model.predict(latency_data[-1].reshape(1, -1))
if prediction == -1:
print("Anomaly detected in latency")
else:
print("Latency normal")
Mind Map: Predictive Observability Workflow
Example: Time Series Forecasting for Resource Scaling
Predicting CPU utilization to proactively scale microservices.
Approach: Use Facebook’s Prophet library for forecasting.
Code Snippet:
from prophet import Prophet
import pandas as pd
# Sample data frame with timestamps and CPU usage
cpu_data = pd.DataFrame({
'ds': pd.date_range(start='2024-01-01', periods=100, freq='H'),
'y': [50 + 10 * (i \% 24 == 12) + (i \% 5) for i in range(100)] # synthetic pattern
})
model = Prophet()
model.fit(cpu_data)
future = model.make_future_dataframe(periods=24, freq='H')
prediction = model.predict(future)
print(prediction[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail())
This forecast can trigger autoscaling before CPU usage spikes.
Integrating AI/ML with Observability Tools
- OpenTelemetry: Instrument microservices to collect rich telemetry data.
- Prometheus + Grafana: Use Prometheus for metrics storage and Grafana for visualization.
- ML Pipelines: Stream telemetry data to ML platforms (e.g., TensorFlow Extended, Kubeflow).
- Alerting: Integrate ML anomaly detection outputs with alerting systems like Alertmanager.
Best Practices
- Continuously retrain models with fresh data to adapt to evolving system behavior.
- Combine multiple ML techniques for robust detection (ensemble methods).
- Use explainable AI methods to interpret model decisions and build trust.
- Maintain a human-in-the-loop process for validating alerts and refining models.
Summary
AI and ML offer powerful tools to elevate observability from reactive monitoring to proactive, predictive insights. By applying anomaly detection, forecasting, and root cause analysis automation, teams can maintain high concurrency microservices with improved reliability and performance.
Further Reading
- “Machine Learning for System Health Monitoring” by Google Cloud
- “Anomaly Detection for Monitoring” - AWS Whitepaper
- OpenTelemetry ML Integration Guides
- Facebook Prophet Documentation
12.4 Example: Integrating AI-Based Anomaly Detection in Monitoring
In modern high concurrency microservices architectures, observability is critical to maintaining system health and performance. Integrating AI-based anomaly detection into monitoring pipelines can proactively identify unusual patterns, performance degradations, or failures before they escalate.
Why AI-Based Anomaly Detection?
- Traditional threshold-based alerts often generate noise or miss subtle anomalies.
- AI models can learn normal system behavior and detect deviations dynamically.
- Helps reduce alert fatigue and improves incident response time.
Overview of Integration Steps
Step 1: Data Collection
Collecting rich observability data is the foundation. This includes:
- Metrics: CPU, memory, request latency, error rates.
- Logs: Structured logs with context about events.
- Traces: Distributed tracing data showing request flows.
Example: Using Prometheus to scrape metrics and OpenTelemetry for traces.
Step 2: Data Preprocessing
Raw data must be cleaned and transformed:
- Normalize metrics to a common scale.
- Extract features such as rolling averages, percentiles, or error counts.
- Aggregate logs by time windows.
Example: Calculating a moving average of request latency over 1-minute intervals.
Step 3: Model Selection
Common AI approaches:
- Supervised Learning: Requires labeled anomaly data (rare in production).
- Unsupervised Learning: Detects anomalies without labels (e.g., Isolation Forest, Autoencoders).
- Hybrid: Combines both for better accuracy.
Example: Using an Isolation Forest to detect outlier latency spikes.
Step 4: Model Training
Train the model on historical data representing normal behavior.
- Use sliding windows to capture temporal patterns.
- Continuously update the model with new data to adapt to changes.
Example: Training an autoencoder on 30 days of latency and error rate metrics.
Step 5: Deployment and Real-Time Inference
Deploy the trained model as a microservice or embed within the monitoring pipeline.
- Perform inference on streaming data.
- Flag anomalies with confidence scores.
Example: Kafka streams feeding metrics into a Python microservice running the anomaly detection model.
Step 6: Alerting and Incident Management
Integrate anomaly detection outputs with alerting systems:
- Set confidence thresholds to reduce false positives.
- Route alerts to Slack, PagerDuty, or other incident tools.
Example: An alert triggers when anomaly confidence exceeds 0.8, notifying the on-call engineer.
Step 7: Feedback Loop and Continuous Improvement
- Engineers validate flagged anomalies.
- Feedback is used to retrain and improve the model.
Example: Labeling false positives to refine the model’s sensitivity.
Practical Example: Detecting Latency Anomalies in a Payment Microservice
import numpy as np
from sklearn.ensemble import IsolationForest
# Sample latency data (ms) collected every minute
latency_data = np.array([100, 105, 98, 102, 500, 110, 108, 115, 120, 600])
# Reshape for model input
latency_data = latency_data.reshape(-1, 1)
# Train Isolation Forest on normal data (excluding obvious anomalies)
model = IsolationForest(contamination=0.2, random_state=42)
model.fit(latency_data[:-2])
# Predict anomalies
preds = model.predict(latency_data)
for i, pred in enumerate(preds):
status = 'Anomaly' if pred == -1 else 'Normal'
print(f"Minute {i+1}: Latency={latency_data[i][0]}ms - {status}")
Output:
Minute 1: Latency=100ms - Normal
Minute 2: Latency=105ms - Normal
Minute 3: Latency=98ms - Normal
Minute 4: Latency=102ms - Normal
Minute 5: Latency=500ms - Anomaly
Minute 6: Latency=110ms - Normal
Minute 7: Latency=108ms - Normal
Minute 8: Latency=115ms - Normal
Minute 9: Latency=120ms - Normal
Minute 10: Latency=600ms - Anomaly
This simple example demonstrates how an AI model can automatically detect unusual latency spikes.
Mind Map: AI-Based Anomaly Detection Workflow
Summary
Integrating AI-based anomaly detection into your high concurrency microservices monitoring stack enables proactive identification of issues that traditional methods might miss. By leveraging rich observability data, selecting appropriate models, and establishing feedback loops, engineering teams can enhance system reliability and reduce downtime.
Further Reading & Tools
- OpenTelemetry for observability data collection
- Prometheus for metrics scraping
- Scikit-learn Isolation Forest
- Grafana Machine Learning Plugins
- Anomaly Detection with Autoencoders
12.5 Best Practice: Preparing for Quantum-Safe Event Security
As quantum computing advances, traditional cryptographic algorithms that secure event-driven microservices may become vulnerable. Preparing your event-driven architecture for quantum-safe security is essential to future-proof your systems against emerging threats.
Why Quantum-Safe Security Matters for Event-Driven Microservices
- Quantum Threats: Quantum computers can break widely used asymmetric encryption schemes like RSA and ECC, which underpin TLS, digital signatures, and message authentication.
- Event Integrity & Confidentiality: Events often carry sensitive data and commands; compromised cryptography can lead to data breaches, unauthorized actions, and system manipulation.
- Long-Term Security: Events stored in event sourcing or logs may be decrypted retroactively if quantum attacks become feasible.
Mind Map: Quantum-Safe Event Security Overview
Post-Quantum Cryptography (PQC) Algorithms for Event Security
| Algorithm Type | Description | Use Case in Microservices |
|---|---|---|
| Lattice-based | Based on hard lattice problems; efficient | Key exchange, digital signatures |
| Hash-based | Uses hash functions for signatures | Event signing, integrity verification |
| Code-based | Based on error-correcting codes | Encryption, key exchange |
| Multivariate | Polynomial equations over finite fields | Digital signatures |
Example: Hybrid Cryptography for Event Message Signing
To maintain compatibility and gradually transition to quantum-safe algorithms, use hybrid signatures combining classical and post-quantum algorithms.
# Pseudocode for hybrid signing of an event message
def sign_event(event_payload, classical_private_key, pqc_private_key):
classical_signature = classical_sign(event_payload, classical_private_key)
pqc_signature = pqc_sign(event_payload, pqc_private_key)
return {
"payload": event_payload,
"signatures": {
"classical": classical_signature,
"post_quantum": pqc_signature
}
}
# Verification would require both signatures to be validated
This approach ensures security against classical and emerging quantum threats.
Mind Map: Steps to Prepare Event-Driven Systems for Quantum-Safe Security
Practical Considerations
- Performance Impact: PQC algorithms may have larger key sizes and slower operations; benchmark and optimize accordingly.
- Backward Compatibility: Hybrid approaches allow gradual migration without breaking existing clients.
- Key Management: Update key generation, rotation, and storage to support new key types.
- Event Broker Support: Ensure messaging infrastructure supports larger payloads and new cryptographic metadata.
Example: Integrating Post-Quantum TLS in Microservices Communication
Many event brokers use TLS for transport security. Transitioning to quantum-safe TLS involves using PQC-enabled TLS libraries.
# Example using OpenSSL with PQC support (hypothetical)
openssl s_client -connect broker.example.com:443 -cipher pqc_cipher_suite
In your microservice client configuration:
transport:
tls:
enabled: true
cipherSuites:
- pqc_cipher_suite
certFile: pqc_cert.pem
keyFile: pqc_key.pem
This ensures event messages are encrypted with quantum-resistant algorithms during transit.
Summary
Preparing for quantum-safe event security involves:
- Understanding quantum threats to cryptography
- Adopting post-quantum cryptographic algorithms
- Implementing hybrid cryptography for smooth migration
- Upgrading key management and event broker configurations
- Continuously monitoring cryptographic advancements
By proactively integrating quantum-safe measures, your high concurrency event-driven microservices will remain secure and resilient in the quantum era.
13. Summary and Best Practices Recap
13.1 Key Takeaways for Designing High Concurrency Microservices
Designing microservices to handle high concurrency effectively requires a holistic approach that balances architecture, scalability, resilience, and observability. Below are the essential takeaways, illustrated with mind maps and practical examples to solidify understanding.
Embrace Event Driven Architecture (EDA) for Loose Coupling and Scalability
- Use asynchronous event communication to decouple services, enabling independent scaling and failure isolation.
- Design idempotent event handlers to safely process repeated events.
Example:
A payment microservice emits a PaymentProcessed event after successful payment. The order service listens to this event to update order status asynchronously, preventing blocking and enabling both services to scale independently.
Decompose Services Strategically for Concurrency
- Split services by bounded contexts or business capabilities to reduce contention.
- Prefer stateless services where possible to simplify scaling.
- Use stateful services cautiously with proper concurrency control.
Example:
An order processing system separates inventory management, payment processing, and shipping into distinct microservices, each scaling based on its load profile.
Implement Robust Communication Patterns
- Use publish-subscribe for event dissemination to multiple consumers.
- Apply event sourcing and CQRS to optimize read/write workloads.
- Handle eventual consistency with sagas and compensating transactions.
Example:
A booking microservice uses sagas to coordinate seat reservation and payment. If payment fails, the saga triggers a compensating action to release the reserved seat.
Design for Resilience and Backpressure
- Incorporate circuit breakers and bulkheads to isolate failures.
- Implement backpressure and load shedding to protect services under heavy load.
Example:
During traffic spikes, an API gateway applies rate limiting and sheds non-critical requests to maintain overall system stability.
Prioritize Observability for Proactive Monitoring and Troubleshooting
- Instrument metrics, logs, and distributed traces across services.
- Correlate events and traces to understand asynchronous flows.
- Use real-time dashboards and alerts to detect anomalies early.
Example:
Using OpenTelemetry, a microservices ecosystem collects traces that link an event published by the inventory service to downstream order and notification services, enabling root cause analysis of latency spikes.
Optimize Data Consistency and Transaction Management
- Accept eventual consistency where strict consistency is not critical.
- Use sagas for managing distributed transactions.
- Employ Change Data Capture (CDC) to generate reliable events from database changes.
Example:
An inventory service uses CDC to publish events when stock levels change, ensuring other services receive timely updates without direct coupling.
Scale Horizontally and Test Under Load
- Design services to scale horizontally by adding instances.
- Scale event brokers (e.g., Kafka partitions) to handle peak throughput.
- Perform load and chaos testing to validate system behavior under stress.
Example:
Kafka consumers are scaled out with multiple partitions to handle thousands of concurrent events per second, validated through load testing.
Summary Table of Key Practices
| Practice Area | Key Takeaway | Example Scenario |
|---|---|---|
| Event Driven Architecture | Asynchronous, idempotent event processing | PaymentProcessed event triggers order update |
| Service Decomposition | Bounded contexts, stateless preferred | Separate inventory, payment, shipping services |
| Communication Patterns | Pub-sub, event sourcing, sagas for consistency | Saga coordinates booking and payment |
| Resilience & Load | Circuit breakers, backpressure, load shedding | API gateway rate limiting during spikes |
| Observability | Metrics, logs, distributed tracing, alerts | OpenTelemetry traces link event flows |
| Data Consistency | Eventual consistency, sagas, CDC | Inventory CDC publishes stock changes |
| Scalability & Testing | Horizontal scaling, broker partitioning, chaos testing | Scaling Kafka consumers for peak traffic |
By integrating these principles and practices, senior backend engineers can design microservices architectures that reliably handle high concurrency workloads with robustness, scalability, and observability.
13.2 Checklist for Implementing Event Driven Architecture
Implementing an Event Driven Architecture (EDA) effectively requires careful planning and adherence to best practices. This checklist will guide you through the essential steps and considerations, ensuring your microservices are scalable, resilient, and maintainable.
Define Clear Event Boundaries
- Identify domain events that represent meaningful state changes.
- Ensure events are coarse-grained enough to encapsulate business intent but fine-grained enough to avoid unnecessary coupling.
Example:
In an e-commerce system, instead of emitting a generic OrderUpdated event, define specific events like OrderPlaced, OrderCancelled, and OrderShipped.
Design Idempotent Event Handlers
- Ensure event consumers can safely process the same event multiple times without side effects.
- Use unique event IDs and store processed event IDs to prevent duplicate processing.
Example:
A payment microservice processes PaymentCompleted events. It checks if the event ID has been processed before updating the ledger to avoid double charging.
Choose the Right Messaging Infrastructure
- Select an event broker that fits your throughput, latency, and durability needs (e.g., Kafka, RabbitMQ, AWS SNS/SQS).
- Consider partitioning, replication, and retention policies.
Example:
Kafka is chosen for a high-throughput analytics pipeline due to its partitioning and retention capabilities.
Define Event Schemas and Versioning
- Use schema registries (e.g., Avro, Protobuf) to enforce event structure.
- Plan for backward and forward compatibility.
Example:
A user profile service uses Avro schemas stored in Confluent Schema Registry to evolve user update events without breaking consumers.
Implement Reliable Event Delivery
- Use at-least-once or exactly-once delivery semantics as per use case.
- Handle retries with exponential backoff.
Example:
An order fulfillment service retries failed event deliveries and routes unprocessable events to a dead letter queue for manual inspection.
Ensure Event Ordering Where Necessary
- Identify events that require strict ordering.
- Use partition keys or sequence numbers to maintain order.
Example:
In a banking system, transactions for the same account are partitioned by account ID to preserve order.
Design for Eventual Consistency
- Accept that data may be temporarily inconsistent across services.
- Use compensating transactions or sagas for distributed workflows.
Example:
An inventory service updates stock asynchronously after order placement, with compensating actions if stock update fails.
Instrument Events for Observability
- Include metadata such as timestamps, correlation IDs, and causation IDs.
- Enable tracing across event flows.
Example:
Each event carries a correlation ID that links it to the originating user request, enabling end-to-end tracing.
Secure Event Communication
- Encrypt messages in transit and at rest.
- Authenticate and authorize event producers and consumers.
Example:
Use TLS for Kafka communication and OAuth tokens for producer/consumer authentication.
Plan for Scalability and Load Management
- Implement backpressure and load shedding.
- Scale consumers horizontally.
Example:
Kafka consumers autoscale based on lag metrics to handle traffic spikes gracefully.
Test Event Driven Flows Thoroughly
- Use contract testing for event schemas.
- Simulate failure scenarios and retries.
Example:
Run integration tests that simulate network failures and verify event replay and recovery.
Summary Mind Map
By following this checklist, you can systematically design and implement an Event Driven Architecture that supports high concurrency, resilience, and observability in your microservices ecosystem.
13.3 Observability Best Practices for Ongoing Success
Observability is a cornerstone for maintaining, scaling, and evolving high concurrency microservices built on event driven architecture. It empowers engineers to gain deep insights into system behavior, detect anomalies early, and troubleshoot issues efficiently. Below are best practices, supported by mind maps and examples, to ensure your observability strategy drives ongoing success.
Embrace the Three Pillars of Observability
Observability is built on three foundational pillars: Metrics, Logs, and Traces. Each provides a unique lens into your system’s health and behavior.
Example:
- Metrics: Track event processing rate (events/sec) and consumer lag in Kafka.
- Logs: Include structured logs with event IDs and correlation IDs.
- Traces: Use distributed tracing to follow an event from producer to multiple consumers.
Instrumentation with Context Propagation
Ensure all microservices propagate context (e.g., trace IDs, correlation IDs) through event metadata to maintain traceability across asynchronous boundaries.
Example:
When publishing an event, attach a trace-id header. Consumers extract this header to continue the trace, enabling a full picture of event flow.
Define and Monitor Key Performance Indicators (KPIs)
Select KPIs that reflect system health and user experience. Common KPIs include:
- Event throughput
- Processing latency
- Error rates
- Consumer lag
- Resource utilization
Example: Set up Prometheus alerts for consumer lag exceeding a threshold, indicating potential backpressure or processing delays.
Correlate Logs, Metrics, and Traces
Integrate observability data into a unified platform to enable seamless navigation between logs, metrics, and traces.
Example: An alert on increased latency triggers investigation. From the dashboard, you jump to the trace showing a slow event handler, then view logs for that trace ID to identify the root cause.
Implement Health Checks and Heartbeats
Regularly emit health signals from microservices and event brokers to detect failures proactively.
Example: A microservice emits a heartbeat event every 30 seconds. If the monitoring system detects missing heartbeats for 2 intervals, it triggers an alert.
Use Sampling and Aggregation Wisely
High concurrency systems generate massive observability data. Use sampling and aggregation to balance detail and cost.
Example: Trace 10% of all events but 100% of error events to ensure visibility into failures without overwhelming storage.
Automate Anomaly Detection and Alerting
Leverage machine learning or rule-based systems to detect unusual patterns in metrics and logs.
Example: Configure alerts for sudden spikes in dead-letter queue size, indicating event processing failures requiring immediate attention.
Continuously Review and Evolve Observability Strategy
Observability is not a set-and-forget task. Regularly review instrumentation, dashboards, and alerts to adapt to system changes.
Example: After a production incident, the team adds new metrics to track a previously unmonitored event processing stage, preventing recurrence.
Summary
By implementing these observability best practices, your high concurrency microservices will be equipped to handle complexity with transparency and agility. The combination of comprehensive instrumentation, intelligent alerting, and continuous refinement forms the backbone of operational excellence in event driven architectures.
Additional Resources
- OpenTelemetry Documentation
- Prometheus Monitoring Best Practices
- Distributed Tracing with Jaeger
- Observability Engineering Book by Charity Majors
13.4 Final Example: End-to-End High Concurrency Microservices Blueprint
In this section, we will walk through a comprehensive example that ties together all the concepts discussed throughout this blog: designing an end-to-end high concurrency microservices system using event-driven architecture (EDA) and observability best practices.
Scenario: High Concurrency Online Food Delivery Platform
Imagine a food delivery platform where thousands of users place orders simultaneously, restaurants update menu availability in real-time, and delivery partners update their locations continuously. The system must handle high concurrency, ensure data consistency, and provide observability to detect and troubleshoot issues quickly.
System Components Overview
Step 1: Service Decomposition & Responsibilities
- Order Service: Handles order creation, updates, and status tracking.
- Restaurant Service: Manages restaurant menus, availability, and order acceptance.
- Delivery Service: Tracks delivery partner locations and order delivery status.
- Notification Service: Sends real-time notifications to users and partners.
Each service is designed to be stateless where possible, with state persisted in dedicated databases.
Step 2: Event-Driven Communication
All services communicate asynchronously via events published to Kafka topics.
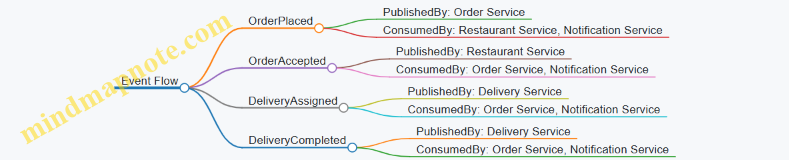
Example: When a user places an order, the Order Service publishes an OrderPlaced event. The Restaurant Service consumes this event to check availability and accept or reject the order.
Step 3: Handling High Concurrency
- Kafka Partitioning: Topics are partitioned by order ID or restaurant ID to allow parallel processing.
- Idempotent Event Handlers: Each service ensures event handlers are idempotent to handle retries and duplicates gracefully.
- Backpressure: Services monitor consumer lag and apply backpressure or load shedding if overwhelmed.
# Example: Idempotent event handler snippet in Python
processed_event_ids = set()
def handle_order_placed(event):
if event.id in processed_event_ids:
return # Duplicate event, ignore
# Process event
processed_event_ids.add(event.id)
# ... business logic ...
Step 4: Distributed Transactions with Saga Pattern
To maintain consistency across services, the system uses the Saga pattern.
Example Saga Flow:
- Order Service creates order and publishes
OrderPlaced. - Restaurant Service accepts order and publishes
OrderAccepted. - Delivery Service assigns delivery and publishes
DeliveryAssigned. - If any step fails, compensating events like
OrderCancelledare published.
sequenceDiagram
OrderService->>RestaurantService: OrderPlaced Event
RestaurantService-->>OrderService: OrderAccepted Event
OrderService->>DeliveryService: Assign Delivery
DeliveryService-->>OrderService: DeliveryAssigned Event
Note over OrderService,DeliveryService: On failure
DeliveryService->>OrderService: DeliveryFailed Event
OrderService->>RestaurantService: OrderCancelled Event
Step 5: Observability Integration
- Metrics: Each service exposes Prometheus metrics, e.g., event processing rate, consumer lag.
- Logs: Structured logs include correlation IDs to trace events across services.
- Tracing: Distributed tracing with OpenTelemetry captures event flows.
# Example Prometheus metric for consumer lag
kafka_consumer_lag{service="OrderService",topic="OrderPlaced"} 5
// Example structured log snippet
{
"timestamp": "2024-06-01T12:00:00Z",
"service": "OrderService",
"event_id": "evt-12345",
"correlation_id": "corr-67890",
"message": "Processed OrderPlaced event",
"level": "INFO"
}
Step 6: Monitoring & Alerting
- Dashboards visualize throughput, latency, error rates.
- Alerts trigger on consumer lag thresholds or error spikes.
Step 7: Putting It All Together — Mind Map of the Blueprint
Summary
This blueprint demonstrates how to design a scalable, resilient, and observable high concurrency microservices system using event-driven architecture. By decomposing services, leveraging asynchronous event flows, applying the Saga pattern for consistency, and integrating robust observability, engineers can build systems that handle massive concurrent loads while maintaining reliability and operational insight.
This example can be adapted and extended to various domains requiring high concurrency and real-time responsiveness.
13.5 Resources and Further Reading
To deepen your understanding of high concurrency microservices design with event driven architecture and observability, here is a curated list of resources, including books, articles, tools, and community links. Additionally, mind maps are provided to visually organize key concepts and their relationships.
Books
-
“Designing Data-Intensive Applications” by Martin Kleppmann
- A foundational book covering distributed systems, event sourcing, and data consistency.
- Link
-
“Microservices Patterns” by Chris Richardson
- Covers microservice design patterns including sagas, event-driven architecture, and observability.
- Link
-
“Building Event-Driven Microservices” by Adam Bellemare
- Focuses on event-driven design principles and practical implementations.
Articles & Tutorials
-
Martin Fowler’s Article on Event Sourcing
- Explains event sourcing fundamentals with examples.
- Link
-
The Reactive Manifesto
- Principles for building responsive, resilient, elastic, and message-driven systems.
- Link
-
Observability Engineering at Uber
- Deep dive into Uber’s approach to observability in high-scale microservices.
- Link
Tools and Frameworks
-
Apache Kafka
- Distributed event streaming platform widely used for event-driven microservices.
- Link
-
OpenTelemetry
- Open-source observability framework for metrics, logs, and traces.
- Link
-
Prometheus & Grafana
- Monitoring and visualization tools commonly used for microservices observability.
- Prometheus, Grafana
-
Jaeger
- Distributed tracing system for monitoring and troubleshooting microservices.
- Link
Community and Courses
-
Microservices Community on GitHub
- Open source projects and discussions around microservices architecture.
- Link
-
Event-Driven Architecture Meetup Groups
- Join local or virtual meetups focused on event-driven systems.
- Search on Meetup.com
-
Coursera: Cloud Native Development with Microservices
- Course covering microservices, event-driven architecture, and cloud native patterns.
- Link
Mind Maps
Mind Map 1: High Concurrency Microservices Design
Mind Map 2: Event Driven Architecture Components
Mind Map 3: Observability in Microservices
Example: Using OpenTelemetry for Observability
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor, ConsoleSpanExporter
# Setup tracer
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
# Export spans to console (for demo)
span_processor = BatchSpanProcessor(ConsoleSpanExporter())
trace.get_tracer_provider().add_span_processor(span_processor)
# Example traced function
with tracer.start_as_current_span("process_order") as span:
# Simulate processing
print("Processing order with high concurrency")
This example demonstrates how to instrument a microservice function to generate trace data, which can be collected and visualized to understand system behavior under load.
Example: Simple Event Handler Idempotency
processed_event_ids = set()
def handle_event(event):
if event.id in processed_event_ids:
print("Duplicate event ignored")
return
# Process event
print(f"Processing event {event.id}")
processed_event_ids.add(event.id)
This snippet shows a basic approach to ensuring idempotency in event handlers, a best practice critical to reliable event-driven microservices.
By leveraging these resources, mind maps, and examples, senior and backend engineers can build robust, scalable, and observable high concurrency microservices architectures using event driven principles.