Scalable MLOps Systems Design and Automated Model Lifecycle Management in Production
1. Introduction to Scalable MLOps Systems
1.1 Understanding MLOps: Definition and Importance
What is MLOps?
MLOps, short for Machine Learning Operations, is a set of practices that combines Machine Learning (ML), DevOps, and Data Engineering to automate and streamline the entire ML lifecycle—from data preparation and model training to deployment and monitoring in production environments.
It aims to bridge the gap between data science teams who build models and engineering teams who deploy and maintain them, ensuring reliable, scalable, and repeatable ML workflows.
Why is MLOps Important?
- Accelerates Model Deployment: Automates repetitive tasks, reducing time-to-market for ML models.
- Ensures Model Reliability: Continuous testing and monitoring detect issues early.
- Facilitates Collaboration: Aligns data scientists, engineers, and business stakeholders.
- Supports Scalability: Enables handling of large-scale data and models efficiently.
- Maintains Compliance: Tracks model versions and data lineage for auditing.
Mind Map: Core Concepts of MLOps
Example: MLOps in Action at a Retail Company
Scenario: A retail company wants to deploy a demand forecasting model to optimize inventory.
-
Without MLOps: Data scientists build models locally and hand off code to engineers. Deployment is manual, leading to delays and errors. Monitoring is minimal, so model performance degrades unnoticed.
-
With MLOps: The company implements an automated pipeline where data ingestion, model training, validation, and deployment are orchestrated. Model performance is continuously monitored, and alerts trigger retraining when accuracy drops.
This results in faster deployment cycles, improved forecast accuracy, and reduced stockouts.
Mind Map: Benefits of Implementing MLOps
Key Takeaway
MLOps is essential for operationalizing machine learning at scale. It transforms ML from an experimental phase into a robust, production-ready process that delivers continuous business value.
By understanding and adopting MLOps principles, organizations can overcome common pitfalls such as deployment bottlenecks, model decay, and lack of reproducibility.
1.2 Key Challenges in Scaling MLOps Systems
Scaling MLOps systems from small prototypes to robust, production-grade pipelines introduces a unique set of challenges. These challenges span technical, organizational, and operational domains, requiring thoughtful design and best practices to overcome. In this section, we explore the primary obstacles encountered when scaling MLOps systems, supported by mind maps and practical examples.
Data Management Complexity
As datasets grow in volume, variety, and velocity, managing data pipelines becomes increasingly difficult. Challenges include ensuring data quality, handling data drift, and maintaining consistent feature engineering across environments.
Example: A retail company initially used batch data ingestion for training models on weekly sales data. As they scaled to include real-time inventory updates and customer behavior, their existing pipelines struggled with latency and data consistency. Implementing a feature store with streaming ingestion (e.g., Feast) helped them maintain consistent features and reduce data drift.
Model Training and Experimentation at Scale
Scaling training pipelines involves managing compute resources efficiently, automating hyperparameter tuning, and tracking numerous experiments without losing reproducibility.
Example: An AI platform team used manual scripts for training and tuning models, which became unmanageable as the number of experiments grew. By adopting MLflow for experiment tracking and Kubernetes for distributed training, they automated resource scaling and improved reproducibility.
Deployment and Serving Complexity
Deploying models at scale requires handling diverse deployment patterns, ensuring low latency, and managing multiple versions concurrently.
Example: A financial services company deployed fraud detection models with strict latency requirements. Initially, their monolithic deployment caused bottlenecks. Transitioning to microservices with autoscaling and canary deployments using KFServing enabled smoother rollouts and better fault tolerance.
Monitoring and Maintenance
Continuous monitoring of model performance, detecting data and concept drift, and automating alerts are critical but challenging at scale.
Example: An online advertising platform faced sudden drops in model accuracy after campaign changes. By integrating Prometheus and Grafana dashboards with automated drift detection, they quickly identified issues and triggered retraining workflows.
Collaboration and Governance
Scaling MLOps involves multiple teams (data scientists, engineers, operations) and requires clear governance, version control, and compliance adherence.
Example: A healthcare AI startup struggled with compliance and auditability as their team grew. Implementing role-based access control, detailed model cards, and automated audit logs ensured regulatory compliance and smoother collaboration.
Summary Table of Key Challenges
| Challenge Area | Description | Example Solution |
|---|---|---|
| Data Management | Handling data quality, volume, velocity, and drift | Feature stores, streaming ingestion |
| Model Training | Efficient resource use, experiment tracking | MLflow, distributed training on Kubernetes |
| Deployment | Managing latency, scaling, versioning | Microservices, KFServing, canary releases |
| Monitoring | Continuous performance tracking and alerting | Prometheus, Grafana, drift detection |
| Collaboration & Governance | Multi-team coordination, compliance, version control | RBAC, audit logs, documentation |
By understanding these challenges and applying best practices with concrete tools and frameworks, MLOps engineers can design scalable, maintainable, and robust systems that support continuous delivery of high-quality machine learning models.
1.3 Overview of Model Lifecycle Management
Model Lifecycle Management (MLM) refers to the systematic process of managing machine learning models from their initial development through deployment, monitoring, and eventual retirement. Effective MLM ensures models remain accurate, reliable, and aligned with business goals throughout their operational life.
Key Stages of Model Lifecycle Management
Detailed Explanation of Each Stage with Examples
1. Development:
This initial phase involves gathering and preparing data, engineering features, training models, and tracking experiments.
Example: A retail company collects transaction data and uses feature engineering to create customer purchase frequency features. They train multiple models and use MLflow to track experiments and hyperparameters.
2. Validation:
Before deployment, models must be rigorously evaluated for accuracy, fairness, and interpretability.
Example: Using tools like Fairlearn, the team assesses if the model exhibits bias against any customer segment. They also generate SHAP explanations to understand feature importance.
3. Deployment:
Models are packaged and deployed to production environments using strategies that minimize downtime and risk.
Example: Deploying a fraud detection model using a blue-green deployment on Kubernetes, ensuring zero downtime and easy rollback if issues arise.
4. Monitoring:
Continuous monitoring of model predictions and input data is essential to detect performance degradation or data drift.
Example: Implementing Prometheus metrics to track prediction latency and accuracy, and setting up alerts for data distribution shifts.
5. Maintenance:
Models require periodic retraining with new data, version control, and rollback capabilities.
Example: Scheduling automated retraining pipelines with Apache Airflow that trigger when data drift is detected, and storing model versions in a registry like MLflow Model Registry.
6. Retirement:
When models become obsolete or replaced, they should be properly decommissioned and archived.
Example: Archiving an old recommendation model after migrating users to a new version, while maintaining logs for audit purposes.
Mind Map: Model Lifecycle Management with Best Practices
Summary
Model Lifecycle Management is a continuous, iterative process that integrates best practices and automation at every stage to ensure machine learning models deliver sustained value in production. By adopting structured lifecycle management, teams can reduce risks, improve model quality, and accelerate time-to-market.
1.4 Real-world Example: Scaling MLOps at a Large E-commerce Platform
Scaling MLOps in a large e-commerce platform involves addressing unique challenges such as high data velocity, diverse model requirements, and the need for rapid deployment to support dynamic business needs. This section explores a comprehensive example of how a leading e-commerce company successfully scaled its MLOps systems to handle millions of users and thousands of models, ensuring reliability, efficiency, and automation throughout the model lifecycle.
Context and Challenges
- Business Needs: Personalized recommendations, fraud detection, dynamic pricing, inventory forecasting.
- Data Volume: Petabytes of user interaction data generated daily.
- Model Diversity: Multiple teams building models for different purposes.
- Deployment Frequency: Models updated daily or weekly to adapt to market changes.
Mind Map: Key Components in Scaling MLOps for E-commerce
Implementation Highlights with Examples
1. Data Management and Feature Engineering
-
The platform implemented a centralized feature store using Feast to ensure consistent feature computation and reuse across teams.
-
Example: Real-time user clickstream data is ingested via Kafka streams into a data lake, then features like “time since last purchase” are computed and served in real-time for recommendation models.
# Example: Defining a feature in Feast
from feast import Feature, Entity, FeatureView, ValueType
user = Entity(name="user_id", value_type=ValueType.INT64, description="User ID")
purchase_count = Feature(name="purchase_count", dtype=ValueType.INT64, description="Number of purchases")
user_features_view = FeatureView(
name="user_features",
entities=[user],
features=[purchase_count],
batch_source=batch_source,
online=True
)
2. Automated Model Training and Experimentation
-
The company used MLflow to track experiments, enabling reproducibility and easy comparison of model versions.
-
Hyperparameter tuning was automated using Optuna integrated within the training pipeline.
-
Example: A training pipeline triggered daily retrained a fraud detection model using the latest data, with MLflow logging metrics and parameters.
import mlflow
import optuna
def objective(trial):
param = {
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3)
}
with mlflow.start_run():
model = train_model(param)
accuracy = evaluate_model(model)
mlflow.log_params(param)
mlflow.log_metric('accuracy', accuracy)
return accuracy
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
3. Model Validation and Deployment
-
Before deployment, models undergo automated validation pipelines that check for performance regression, fairness, and explainability.
-
Deployment uses Kubernetes with blue/green deployment strategies to minimize downtime and risk.
-
Example: Canary deployment gradually shifts traffic to the new recommendation model while monitoring key metrics.
apiVersion: apps/v1
kind: Deployment
metadata:
name: recommendation-model-canary
spec:
replicas: 2
selector:
matchLabels:
app: recommendation-model
template:
metadata:
labels:
app: recommendation-model
version: canary
spec:
containers:
- name: model-server
image: recommendation-model:v2
4. Monitoring and Observability
-
Prometheus and Grafana dashboards monitor model latency, throughput, and data drift.
-
Alerts are configured to notify engineers when model performance drops below thresholds.
-
Example: Drift detection triggers retraining workflows automatically.
alert: ModelPerformanceDegradation
expr: model_accuracy < 0.85
for: 5m
labels:
severity: critical
annotations:
summary: "Model accuracy dropped below threshold"
description: "The recommendation model accuracy has fallen below 85%."
5. Automation and Orchestration
-
Apache Airflow orchestrates the entire pipeline from data ingestion, feature computation, model training, validation, deployment, and monitoring.
-
Example DAG snippet for daily retraining:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def train_model_task():
# code to trigger training pipeline
pass
def validate_model_task():
# code to validate model
pass
def deploy_model_task():
# code to deploy model
pass
def monitor_model_task():
# code to monitor model
pass
def retrain_dag():
dag = DAG('daily_retrain', start_date=datetime(2023,1,1), schedule_interval='@daily')
train = PythonOperator(task_id='train_model', python_callable=train_model_task, dag=dag)
validate = PythonOperator(task_id='validate_model', python_callable=validate_model_task, dag=dag)
deploy = PythonOperator(task_id='deploy_model', python_callable=deploy_model_task, dag=dag)
monitor = PythonOperator(task_id='monitor_model', python_callable=monitor_model_task, dag=dag)
train >> validate >> deploy >> monitor
return dag
retrain_dag()
Summary
This real-world example demonstrates how a large e-commerce platform successfully scaled its MLOps systems by:
- Implementing centralized, real-time feature stores.
- Automating experiment tracking and hyperparameter tuning.
- Enforcing rigorous validation and safe deployment strategies.
- Establishing comprehensive monitoring and alerting.
- Orchestrating workflows end-to-end with automation tools.
By integrating these best practices with robust tooling and automation, the platform achieved scalable, reliable, and efficient model lifecycle management in production.
2. Designing Scalable MLOps Architectures
2.1 Core Components of a Scalable MLOps System
Designing a scalable MLOps system requires a clear understanding of its fundamental components. Each component plays a critical role in ensuring the system can handle increasing workloads, maintain reliability, and support continuous integration and deployment of machine learning models.
Overview of Core Components
Below is a mind map illustrating the primary components of a scalable MLOps system:
Data Management
Description: The foundation of any ML system is reliable data. Scalable MLOps systems must handle large volumes of data from diverse sources with automated ingestion, validation, and feature engineering.
Example:
- Using Apache Kafka for real-time data ingestion pipelines that scale horizontally.
- Implementing Feast as a feature store to serve consistent features at scale for both training and inference.
Model Development
Description: This includes experiment tracking, automated training pipelines, and hyperparameter tuning to accelerate model iteration.
Example:
- MLflow for experiment tracking and reproducibility.
- TFX (TensorFlow Extended) pipelines automate data validation, training, and evaluation.
- Hyperparameter tuning using Kubernetes-based Katib for scalable search.
Model Validation & Testing
Description: Automated validation ensures models meet performance, fairness, and explainability criteria before deployment.
Example:
- Using Seldon Core’s pre-deployment validation hooks to run bias detection tests.
- Integrating SHAP for explainability reports as part of the validation pipeline.
Model Deployment
Description: Scalable deployment involves containerizing models, orchestrating them with tools like Kubernetes, and enabling multi-model serving.
Example:
- Docker containers package models.
- KFServing manages scalable, serverless model endpoints.
- Canary deployments enable safe rollouts.
Monitoring & Observability
Description: Continuous monitoring of model performance and system health is critical to detect issues like data drift or model degradation.
Example:
- Prometheus collects metrics on latency and error rates.
- Grafana dashboards visualize model performance trends.
- Alertmanager triggers notifications on anomalies.
Model Lifecycle Management
Description: Managing model versions, registries, and automating rollbacks ensures smooth transitions between model updates.
Example:
- MLflow Model Registry tracks model versions and stages.
- Automated pipelines promote models from staging to production.
- Rollback triggered automatically on monitoring alerts.
Security & Compliance
Description: Protecting data and models with access controls, encryption, and audit logging is essential for compliance.
Example:
- Implementing Role-Based Access Control (RBAC) in Kubernetes clusters.
- Encrypting data at rest and in transit.
- Maintaining audit logs for model access and changes.
Infrastructure & Scalability
Description: Leveraging cloud-native technologies and autoscaling mechanisms enables the system to handle variable workloads efficiently.
Example:
- Using Kubernetes Horizontal Pod Autoscaler (HPA) to scale model serving pods.
- Employing serverless functions for lightweight preprocessing tasks.
Summary
A scalable MLOps system is an ecosystem of interconnected components working seamlessly to manage data, develop and validate models, deploy them reliably, monitor their performance, and maintain security and compliance. By adopting best practices and leveraging modern tools, teams can build robust systems that grow with their business needs.
2.2 Microservices vs Monolithic Architectures in MLOps
In the realm of MLOps, the choice between microservices and monolithic architectures plays a crucial role in determining the scalability, maintainability, and deployment agility of machine learning systems. This section explores both architectural styles, their pros and cons, and practical examples to help you decide which approach fits your MLOps needs.
What is a Monolithic Architecture?
A monolithic architecture is a single unified system where all components — data ingestion, feature engineering, model training, validation, deployment, and monitoring — are tightly integrated and run as one application.
Characteristics:
- Single codebase
- Shared resources and libraries
- Simple deployment pipeline
Advantages:
- Easier to develop initially
- Simple to test and debug
- Lower latency due to internal calls
Disadvantages:
- Difficult to scale individual components independently
- Changes in one part can affect the entire system
- Slower release cycles due to tight coupling
Example: Imagine a startup building an end-to-end ML pipeline in one Python Flask app that handles data preprocessing, model training, and serving. While simple at first, as the system grows, it becomes harder to maintain and scale.
What is a Microservices Architecture?
Microservices architecture decomposes the ML system into loosely coupled, independently deployable services. Each service handles a specific responsibility such as data ingestion, feature store management, model training, or model serving.
Characteristics:
- Multiple small services communicating over APIs
- Independent deployment and scaling
- Technology heterogeneity allowed
Advantages:
- Scalability: scale only the bottleneck components
- Flexibility: update or rewrite services without impacting others
- Fault isolation: failure in one service doesn’t bring down the entire system
Disadvantages:
- Increased complexity in communication and orchestration
- Requires robust monitoring and logging
- Potential latency overhead due to network calls
Example: A large enterprise uses a microservices MLOps platform where Kafka streams ingest data, a separate feature store service manages features, a training service runs on Kubernetes, and model serving is handled by a dedicated REST API service. This setup allows independent scaling and faster iteration.
Mind Map: Comparing Monolithic and Microservices Architectures in MLOps
Best Practices for Choosing Between Microservices and Monolithic in MLOps
- Start simple: Begin with a monolithic approach if your team is small or the project scope is limited.
- Modularize early: Even in monolithic apps, design modular components to ease future migration.
- Scale components: Identify bottlenecks and consider microservices for those parts.
- Use orchestration tools: Kubernetes, Docker Compose, or service meshes can help manage microservices complexity.
- Automate CI/CD: Independent pipelines for each microservice accelerate deployment.
Practical Example: Transitioning from Monolithic to Microservices
Scenario: A company initially built a monolithic ML platform where data preprocessing, model training, and serving were all in one app. As user demand grew, the model serving API became a bottleneck.
Solution: They extracted the model serving logic into a separate microservice deployed on Kubernetes with autoscaling enabled. This allowed the serving layer to scale independently, reducing latency and improving uptime.
Outcome:
- Deployment frequency increased
- Reduced downtime during updates
- Easier to onboard new engineers to specific services
Summary Table
| Aspect | Monolithic Architecture | Microservices Architecture |
|---|---|---|
| Development Speed | Faster for small projects | Slower initial setup |
| Scalability | Limited to scaling whole app | Fine-grained scaling per service |
| Deployment | Single deployment pipeline | Multiple independent pipelines |
| Fault Isolation | Low, one failure can affect entire app | High, isolated failures |
| Complexity | Lower | Higher due to distributed nature |
| Technology Flexibility | Limited to single stack | High, can mix languages and frameworks |
By understanding these architectural paradigms and their trade-offs, MLOps engineers can design systems that balance complexity, scalability, and maintainability tailored to their organization’s needs.
2.3 Leveraging Cloud-Native Technologies for Scalability
Cloud-native technologies have revolutionized how MLOps systems are designed, enabling scalable, resilient, and flexible machine learning pipelines. By embracing cloud-native principles—such as containerization, microservices, and dynamic orchestration—ML engineers and AI platform engineers can build systems that automatically scale with demand, reduce operational overhead, and accelerate deployment cycles.
Why Cloud-Native for MLOps?
- Elastic scalability: Automatically adjust resources based on workload.
- Resilience: Self-healing and fault tolerance.
- Portability: Run workloads consistently across environments.
- Automation: Simplified CI/CD and lifecycle management.
Core Cloud-Native Technologies in MLOps
Containerization: Docker and OCI Images
Containers package ML models and dependencies into immutable, portable units. This ensures consistency from development to production.
Example:
- Package a TensorFlow model with its runtime and dependencies into a Docker image.
- Push the image to a container registry (e.g., Docker Hub, AWS ECR).
- Deploy the container in any Kubernetes cluster without environment mismatch.
# Dockerfile example for a simple model server
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . ./
CMD ["python", "serve_model.py"]
Orchestration: Kubernetes and Kubeflow
Kubernetes automates deployment, scaling, and management of containerized applications. Kubeflow extends Kubernetes specifically for ML workflows.
Best Practices:
- Use Kubernetes namespaces to isolate environments (dev, test, prod).
- Define resource requests and limits for pods to optimize cluster utilization.
- Employ Horizontal Pod Autoscaler (HPA) to scale model serving pods based on CPU or custom metrics.
Example:
- Deploy a Kubeflow pipeline that automates data preprocessing, training, and deployment.
- Use Kubernetes Custom Resource Definitions (CRDs) to manage ML-specific resources like TFJobs or PyTorchJobs.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: model-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: model-server
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
Service Mesh: Istio for Traffic Management and Security
Service meshes provide fine-grained control over service-to-service communication, enabling advanced routing, retries, and observability.
Example:
- Use Istio to implement canary deployments for new model versions by routing a small percentage of traffic to the new model.
- Enforce mutual TLS between services to secure data in transit.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: model-serving
spec:
hosts:
- model.example.com
http:
- route:
- destination:
host: model-v1
weight: 90
- destination:
host: model-v2
weight: 10
Serverless Architectures for Event-Driven Scalability
Serverless platforms automatically scale compute resources in response to events, reducing management overhead.
Example:
- Use AWS Lambda to trigger model inference on demand, e.g., when a new data file arrives in S3.
- Combine with API Gateway to expose a scalable REST API for model predictions.
import boto3
def lambda_handler(event, context):
# Load model from S3 or cache
# Perform inference
# Return prediction
pass
Storage Solutions for Scalable Data and Model Management
Cloud-native object storage (e.g., AWS S3, Google Cloud Storage) offers scalable, durable storage for datasets and model artifacts.
Example:
- Store training datasets in S3 buckets with lifecycle policies to archive older data.
- Use model registries integrated with object storage to version and track models.
Monitoring and Observability
Use Prometheus and Grafana to collect and visualize metrics from ML pipelines and model serving endpoints.
Example:
- Monitor request latency and error rates of model serving pods.
- Set up alerts for model performance degradation or infrastructure issues.
# Prometheus scrape config example
scrape_configs:
- job_name: 'model-server'
static_configs:
- targets: ['model-server.default.svc.cluster.local:8080']
Summary Mindmap
By integrating these cloud-native technologies, MLOps systems can achieve the scalability, reliability, and automation necessary for robust production deployments. The examples provided demonstrate practical implementations that readers can adapt to their own environments.
2.4 Case Study: Building a Scalable MLOps Pipeline with Kubernetes and Kubeflow
In this case study, we explore how to design and implement a scalable MLOps pipeline leveraging Kubernetes and Kubeflow. This approach enables automation, scalability, and reproducibility for machine learning workflows in production environments.
Overview
Kubernetes provides a robust container orchestration platform that can manage compute resources efficiently, while Kubeflow is an open-source MLOps toolkit built on top of Kubernetes, designed to simplify the deployment, orchestration, and management of ML workflows.
Key Benefits:
- Scalability via Kubernetes’ native autoscaling
- Reproducibility and portability of ML pipelines
- Integration of experiment tracking, training, and deployment
Mind Map: High-Level Architecture
Step 1: Setting Up the Kubernetes Cluster
- Use a managed Kubernetes service (e.g., GKE, EKS, AKS) for ease of management.
- Configure node pools with autoscaling to handle variable workloads.
- Set up persistent storage for datasets and model artifacts.
Example:
# Create a GKE cluster with autoscaling enabled
gcloud container clusters create mlops-cluster \
--num-nodes=3 \
--enable-autoscaling --min-nodes=3 --max-nodes=10 \
--zone=us-central1-a
Step 2: Deploying Kubeflow
- Deploy Kubeflow using the official manifests or the Kubeflow Operator.
- Ensure all components like Pipelines, Katib, KFServing, and Metadata are installed.
Example:
# Deploy Kubeflow using kfctl
kfctl apply -V -f https://raw.githubusercontent.com/kubeflow/manifests/v1.4.0/kfdef/kfctl_gcp_iap.yaml
Step 3: Building the Pipeline
- Define the ML pipeline using Kubeflow Pipelines DSL (Python).
- Components include data preprocessing, model training, hyperparameter tuning, evaluation, and deployment.
Example:
import kfp
from kfp import dsl
@dsl.pipeline(
name='Sample Scalable Pipeline',
description='An example pipeline with preprocessing, training, and deployment'
)
def scalable_pipeline():
preprocess = dsl.ContainerOp(
name='Preprocess Data',
image='gcr.io/my-project/preprocess:latest',
arguments=['--input', '/data/raw', '--output', '/data/processed']
)
train = dsl.ContainerOp(
name='Train Model',
image='gcr.io/my-project/train:latest',
arguments=['--data', preprocess.output]
)
deploy = dsl.ContainerOp(
name='Deploy Model',
image='gcr.io/my-project/deploy:latest',
arguments=['--model', train.output]
)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(scalable_pipeline, 'scalable_pipeline.yaml')
Step 4: Hyperparameter Tuning with Katib
- Integrate Katib to automate hyperparameter search.
- Define experiment YAML specifying parameters, objective metrics, and trial templates.
Example:
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
name: random-example
spec:
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy
algorithm:
algorithmName: random
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.1"
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: learning_rate
description: Learning rate for training
reference: learning_rate
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: training-container
image: gcr.io/my-project/train:latest
command:
- --learning_rate
- {{trialParameters.learning_rate}}
restartPolicy: Never
Step 5: Model Serving with KFServing
- Deploy trained models as scalable, serverless endpoints.
- KFServing supports autoscaling, canary rollouts, and multi-framework models.
Example:
apiVersion: serving.kubeflow.org/v1beta1
kind: InferenceService
metadata:
name: sklearn-iris
spec:
predictor:
sklearn:
storageUri: "gs://my-bucket/models/sklearn-iris/"
resources:
requests:
cpu: 100m
memory: 256Mi
Mind Map: Pipeline Workflow
Best Practices Illustrated
- Containerization: Each pipeline step is encapsulated in a container image, ensuring environment consistency.
- Version Control: Pipeline definitions and container images are versioned and stored in Git and container registries.
- Resource Efficiency: Kubernetes autoscaling optimizes resource usage based on workload demand.
- Experiment Tracking: Katib automates hyperparameter tuning, improving model performance systematically.
- Serverless Serving: KFServing provides scalable, low-latency inference endpoints with minimal operational overhead.
Summary
This case study demonstrated how Kubernetes and Kubeflow can be combined to build a scalable, automated MLOps pipeline. By leveraging container orchestration, pipeline automation, hyperparameter tuning, and serverless model serving, organizations can accelerate ML production workflows while maintaining robustness and scalability.
3. Data Management and Feature Engineering at Scale
3.1 Best Practices for Scalable Data Ingestion and Storage
In scalable MLOps systems, efficient and reliable data ingestion and storage are foundational to ensure smooth downstream model training and serving. This section covers best practices, patterns, and examples to help you design scalable data pipelines that can handle large volumes, variety, and velocity of data.
Key Principles for Scalable Data Ingestion and Storage
- Reliability: Ensure data is ingested without loss or duplication.
- Scalability: Support growing data volumes and velocity.
- Flexibility: Handle diverse data types and sources.
- Latency: Balance between batch and real-time ingestion based on use case.
- Cost-effectiveness: Optimize storage and compute costs.
Mind Map: Scalable Data Ingestion and Storage Best Practices
Best Practices Explained with Examples
Choose the Right Ingestion Pattern
-
Batch ingestion is suitable for scenarios where data freshness is not critical, such as daily sales reports or historical data backfills.
Example: Use Apache Airflow to orchestrate ETL jobs that extract data from databases, transform it, and load it into a data lake like AWS S3.
-
Stream ingestion is ideal for real-time or near-real-time use cases like fraud detection or user activity tracking.
Example: Use Apache Kafka to capture clickstream data and process it in real-time with Apache Flink or Spark Streaming.
-
Hybrid ingestion combines batch and streaming to balance latency and throughput, often implemented via Lambda architecture.
Use Scalable Storage Solutions
-
Data Lakes provide cost-effective storage for raw and semi-structured data. They support schema-on-read, allowing flexible exploration.
Example: Store raw JSON logs in AWS S3 buckets partitioned by date for efficient querying.
-
Data Warehouses are optimized for structured data and fast analytical queries.
Example: Load curated, cleaned data into Google BigQuery for BI dashboards.
-
Feature Stores centralize feature definitions and storage, enabling consistency between training and serving.
Example: Feast allows you to register features from batch and streaming sources, serving them via low-latency APIs.
Implement Data Partitioning and Compression
-
Partition data by time (e.g., date, hour) or key (e.g., user ID) to improve query performance and parallelism.
-
Use compression formats like Parquet or ORC to reduce storage costs and speed up data scans.
Example: Store Parquet files partitioned by event_date in S3, enabling Athena queries to scan only relevant partitions.
Ensure Data Quality and Governance
-
Validate data at ingestion using schema checks and anomaly detection.
-
Maintain metadata catalogs for discoverability and lineage.
-
Enforce access controls to secure sensitive data.
Example: Use Apache Deequ for automated data quality checks and AWS Glue Data Catalog for metadata management.
Automate and Monitor Data Pipelines
-
Use workflow orchestrators like Airflow or Prefect to automate ingestion pipelines.
-
Implement monitoring and alerting on ingestion failures, delays, and data quality issues.
Example: Set up Airflow DAGs with SLA alerts and integrate with Prometheus/Grafana for pipeline health dashboards.
Summary
Designing scalable data ingestion and storage pipelines requires a thoughtful combination of architecture patterns, tools, and best practices. By selecting appropriate ingestion modes, leveraging scalable storage solutions, and enforcing data quality and governance, you can build robust pipelines that support your MLOps workflows effectively.
Additional Resources
- Apache Kafka Documentation
- Feast Feature Store
- AWS Data Lake Architecture
- Apache Airflow
- Apache Deequ
3.2 Automated Feature Engineering Pipelines
Automated feature engineering pipelines are essential for scaling machine learning workflows and ensuring consistency, reproducibility, and efficiency in production environments. By automating feature extraction, transformation, and selection, teams can reduce manual effort, minimize errors, and accelerate model development.
Why Automate Feature Engineering?
- Consistency: Ensures features are generated uniformly across training and serving.
- Reproducibility: Enables exact recreation of features for debugging and audits.
- Scalability: Handles large datasets and complex transformations efficiently.
- Rapid Iteration: Facilitates quick experimentation with new features.
Key Components of Automated Feature Engineering Pipelines
Example: Building an Automated Feature Engineering Pipeline with Apache Spark and Feast
Scenario: A retail company wants to automate feature engineering for a customer churn prediction model using transactional and demographic data.
Step 1: Data Ingestion
- Use Spark to batch ingest customer transactions and demographics from a data lake.
Step 2: Feature Extraction & Transformation
- Extract features like total spend, average transaction value, days since last purchase.
- Transform categorical variables (e.g., customer segment) using one-hot encoding.
Step 3: Feature Storage
- Register features in Feast, a feature store that supports online and offline access.
Step 4: Serving Features
- During model training, retrieve historical features from Feast offline store.
- For real-time predictions, serve features from Feast online store.
Code Snippet:
from feast import FeatureStore
# Initialize feature store
fs = FeatureStore(repo_path="./feature_repo")
# Retrieve features for training
training_data = fs.get_historical_features(
entity_df=customer_df,
features=["customer_total_spend", "avg_transaction_value", "customer_segment_encoded"]
).to_df()
# Use training_data for model training
Mind Map: Feature Engineering Pipeline with Feast
Best Practices for Automated Feature Engineering Pipelines
- Modularize Transformations: Break feature logic into reusable, testable components.
- Version Control: Track feature definitions and transformations using Git or feature store versioning.
- Data Validation: Integrate checks to detect anomalies or schema changes early.
- Monitoring: Continuously monitor feature distributions and data quality in production.
- Documentation: Maintain clear documentation of feature definitions and lineage.
Additional Example: Using TFX (TensorFlow Extended) for Automated Feature Engineering
TFX provides components like Transform to define feature engineering pipelines that run consistently during training and serving.
Example:
import tensorflow_transform as tft
def preprocessing_fn(inputs):
# Scale numeric feature
scaled_age = tft.scale_to_z_score(inputs['age'])
# Bucketize continuous feature
bucketized_income = tft.bucketize(inputs['income'], num_buckets=5)
# One-hot encode categorical feature
gender_one_hot = tft.compute_and_apply_vocabulary(inputs['gender'])
return {
'scaled_age': scaled_age,
'bucketized_income': bucketized_income,
'gender_one_hot': gender_one_hot
}
This function is then used in a TFX pipeline to ensure transformations are applied identically during training and inference.
Summary
Automated feature engineering pipelines are a cornerstone of scalable MLOps systems. Leveraging tools like Feast and TFX, combined with best practices such as modularization, validation, and monitoring, enables teams to build robust, efficient, and maintainable pipelines that accelerate model development and deployment.
3.3 Ensuring Data Quality and Consistency in Production
Ensuring data quality and consistency in production environments is critical for reliable and trustworthy machine learning models. Poor data quality can lead to degraded model performance, unexpected behavior, and ultimately, loss of business value. This section explores best practices, techniques, and tools to maintain high data quality and consistency throughout the production lifecycle.
Why Data Quality and Consistency Matter
- Model Accuracy: Garbage in, garbage out — models trained or served on low-quality data produce unreliable predictions.
- Trust and Compliance: High-quality data ensures compliance with regulations and builds stakeholder trust.
- Operational Stability: Consistent data prevents pipeline failures and reduces debugging overhead.
Key Dimensions of Data Quality
Best Practices for Ensuring Data Quality and Consistency
-
Schema Enforcement and Validation
- Use schema registries (e.g., Apache Avro, JSON Schema) to enforce data formats.
- Validate incoming data against schemas before processing.
-
Automated Data Quality Checks
- Implement checks for missing values, outliers, and distribution shifts.
- Use tools like Great Expectations or Deequ to codify and automate these checks.
-
Data Profiling and Monitoring
- Continuously profile data to detect anomalies.
- Monitor key statistics (mean, variance, cardinality) over time.
-
Data Versioning and Lineage
- Track data versions to reproduce model training and diagnose issues.
- Maintain lineage to understand data transformations and sources.
-
Handling Missing and Corrupt Data
- Define strategies for imputing or discarding missing values.
- Detect and quarantine corrupt or malformed records.
-
Consistency Across Environments
- Ensure training, validation, and production data pipelines use the same preprocessing logic.
- Use feature stores to centralize feature definitions and transformations.
-
Alerting and Incident Response
- Set up alerts for data quality degradation.
- Define processes for rapid investigation and remediation.
Mind Map: Data Quality Assurance Workflow
Example: Implementing Data Quality Checks with Great Expectations
import great_expectations as ge
def validate_data(df):
# Convert pandas DataFrame to GE DataFrame
ge_df = ge.from_pandas(df)
# Define expectations
ge_df.expect_column_values_to_not_be_null('user_id')
ge_df.expect_column_values_to_be_in_type_list('transaction_amount', ['float', 'int'])
ge_df.expect_column_values_to_be_between('transaction_amount', min_value=0)
ge_df.expect_column_values_to_match_regex('email', r"[^@\s]+@[^@\s]+\.[^@\s]+")
# Validate and get results
results = ge_df.validate()
if not results['success']:
raise ValueError("Data validation failed")
return True
This example shows how to codify data quality rules and automatically validate incoming data before it proceeds further in the pipeline.
Example: Monitoring Data Drift with Statistical Tests
Data drift can silently degrade model performance. Monitoring distribution changes helps catch issues early.
from scipy.stats import ks_2samp
def detect_drift(reference_data, production_data, column):
stat, p_value = ks_2samp(reference_data[column], production_data[column])
if p_value < 0.05:
print(f"Drift detected in column {column} (p={p_value:.4f})")
return True
else:
print(f"No significant drift in column {column}")
return False
This Kolmogorov-Smirnov test compares distributions of a feature between reference and production datasets.
Real-World Example: Feature Store Consistency with Feast
Using a feature store like Feast helps ensure consistent feature definitions and data quality across training and serving.
- Centralized Feature Definitions: All teams use the same feature code, reducing discrepancies.
- Online and Offline Stores: Synchronize batch and real-time feature data.
- Data Validation: Feast can integrate with data quality tools to validate features before serving.
Summary
Ensuring data quality and consistency in production requires a combination of automated validation, continuous monitoring, and robust tooling. By implementing schema enforcement, automated checks, data versioning, and leveraging feature stores, teams can build resilient MLOps pipelines that maintain trustworthiness and performance over time.
3.4 Example: Implementing Feature Stores with Feast for Real-time Serving
Feature stores have become a critical component in scalable MLOps architectures, enabling consistent, reliable, and low-latency access to features for both training and real-time inference. In this section, we’ll explore how to implement a feature store using Feast (Feature Store), an open-source feature store that simplifies feature management and serving.
What is Feast?
Feast is a feature store designed to bridge the gap between data engineering and machine learning. It provides a unified platform to ingest, store, and serve features for both batch and real-time use cases.
- Key capabilities:
- Centralized feature repository
- Consistent feature definitions for training and serving
- Real-time and batch feature retrieval
- Integration with popular data sources and ML platforms
Mind Map: Core Components of Feast
Step-by-Step Example: Building a Real-time Feature Store with Feast
Step 1: Define Entities
Entities represent the primary keys for your features, such as customer_id or device_id.
from feast import Entity
customer = Entity(name="customer_id", value_type=ValueType.INT64, description="Customer ID")
Step 2: Define Feature Views
Feature Views group features that share the same entity and data source.
from feast import Feature, FeatureView, FileSource
from feast.types import Int64, Float
# Define offline data source
customer_transactions = FileSource(
path="data/customer_transactions.parquet",
event_timestamp_column="event_timestamp"
)
# Define feature view
customer_transaction_fv = FeatureView(
name="customer_transactions",
entities=["customer_id"],
ttl=Duration(seconds=86400 * 7), # 7 days TTL
features=[
Feature(name="total_transactions", dtype=Int64),
Feature(name="avg_transaction_value", dtype=Float),
],
online=True,
batch_source=customer_transactions
)
Step 3: Register Features and Entities
from feast import FeatureStore
fs = FeatureStore(repo_path=".")
fs.apply([customer, customer_transaction_fv])
Step 4: Ingest Data
Batch ingest historical data:
fs.materialize(start_date=datetime(2023, 1, 1), end_date=datetime(2023, 1, 31))
For streaming ingestion, Feast supports integration with Kafka or other streaming platforms.
Step 5: Retrieve Features for Real-time Serving
entity_rows = [{"customer_id": 1234}]
features = fs.get_online_features(
feature_refs=[
"customer_transactions:total_transactions",
"customer_transactions:avg_transaction_value"
],
entity_rows=entity_rows
).to_dict()
print(features)
This will return the latest feature values for the specified customer in real-time with low latency.
Mind Map: Real-time Feature Serving Workflow with Feast
Best Practices for Using Feast in Production
- Consistent Feature Definitions: Define features once and reuse for training and serving to avoid training-serving skew.
- Feature TTL: Set appropriate TTL (time-to-live) to ensure freshness and manage storage.
- Monitoring: Track feature freshness and online store health.
- Data Quality Checks: Validate incoming data before ingestion.
- Version Control: Use Feast’s repository structure to version feature definitions.
Example Use Case: Fraud Detection System
- Entities:
user_id,transaction_id - Features: Number of transactions in last hour, average transaction amount, number of declined transactions
- Workflow:
- Ingest transaction data in real-time via streaming.
- Materialize features to online store.
- Retrieve features at inference time for fraud prediction.
This setup ensures the fraud detection model always uses the latest transactional features with minimal latency.
Summary
Implementing a feature store with Feast enables scalable, consistent, and low-latency feature management critical for production ML systems. By following the steps above and adhering to best practices, ML engineers can streamline feature engineering workflows and improve model reliability in real-time serving scenarios.
4. Automated Model Training and Experimentation
4.1 Designing Automated Training Pipelines
Automated training pipelines are the backbone of scalable MLOps systems. They enable continuous, repeatable, and efficient model training that can adapt to new data and evolving requirements without manual intervention. Designing such pipelines requires careful consideration of modularity, scalability, reproducibility, and integration with other MLOps components.
Key Objectives of Automated Training Pipelines
- Automation: Minimize manual steps to reduce human error and speed up iteration.
- Reproducibility: Ensure that training can be repeated with the exact same results.
- Scalability: Support large datasets and complex models efficiently.
- Modularity: Enable easy updates and maintenance by separating pipeline stages.
- Integration: Seamlessly connect with data ingestion, validation, deployment, and monitoring systems.
Mind Map: Components of an Automated Training Pipeline
Step-by-Step Breakdown with Examples
-
Data Ingestion & Validation
- Automate fetching data from sources like data lakes or streaming platforms.
- Example: Use Apache Beam or Spark jobs triggered by Airflow DAGs to ingest and validate data.
- Best Practice: Implement schema validation using tools like
Great Expectationsto catch data quality issues early.
-
Feature Engineering
- Automate transformations and feature extraction.
- Example: Use Feast feature store to serve consistent features during training and inference.
- Best Practice: Keep feature engineering code modular and version-controlled.
-
Model Training
- Automate training jobs with parameterization.
- Example: Use Kubeflow Pipelines to define training steps that run on scalable Kubernetes clusters.
- Best Practice: Incorporate hyperparameter tuning frameworks like Optuna or Katib for automated optimization.
-
Model Evaluation
- Automatically evaluate models on validation datasets.
- Example: Integrate MLflow to log metrics and compare experiments.
- Best Practice: Define clear evaluation criteria and thresholds for promotion.
-
Model Registration
- Automatically register the best-performing model.
- Example: Use MLflow Model Registry or Sagemaker Model Registry.
- Best Practice: Include metadata such as training data versions, parameters, and evaluation metrics.
-
Pipeline Orchestration
- Use workflow orchestrators to automate and schedule the entire pipeline.
- Example: Airflow DAGs or Kubeflow Pipelines with retry and alerting mechanisms.
Mind Map: Automation Tools & Frameworks
Example: Simple Automated Training Pipeline Using Kubeflow Pipelines
import kfp
from kfp import dsl
def data_preprocessing_op():
return dsl.ContainerOp(
name='Data Preprocessing',
image='python:3.8',
command=['python', 'preprocess.py'],
file_outputs={'processed_data': '/output/data.csv'}
)
def train_model_op(processed_data):
return dsl.ContainerOp(
name='Train Model',
image='tensorflow/tensorflow:2.4.1',
command=['python', 'train.py', '--data', processed_data],
file_outputs={'model': '/output/model.h5'}
)
def evaluate_model_op(model):
return dsl.ContainerOp(
name='Evaluate Model',
image='python:3.8',
command=['python', 'evaluate.py', '--model', model],
file_outputs={'metrics': '/output/metrics.json'}
)
@dsl.pipeline(
name='Automated Training Pipeline',
description='An example pipeline that automates training steps.'
)
def training_pipeline():
preprocess = data_preprocessing_op()
train = train_model_op(preprocess.output)
evaluate = evaluate_model_op(train.output)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(training_pipeline, 'training_pipeline.yaml')
This pipeline automates preprocessing, training, and evaluation steps, each running in isolated containers. It can be scheduled and monitored via Kubeflow UI.
Best Practices Summary
- Modularize pipeline steps to enable independent updates and debugging.
- Use containerization to ensure environment consistency.
- Track experiments and metadata for reproducibility and auditability.
- Integrate validation and monitoring early to catch issues promptly.
- Leverage orchestration tools to automate scheduling, retries, and notifications.
Automated training pipelines are essential for maintaining agility and robustness in production ML systems. By combining modular design, automation tools, and best practices, teams can accelerate model development and deployment while ensuring quality and scalability.
4.2 Hyperparameter Tuning and Experiment Tracking Best Practices
Hyperparameter tuning and experiment tracking are critical components in building robust and performant machine learning models. Efficient tuning helps optimize model performance, while systematic experiment tracking ensures reproducibility, transparency, and collaboration.
Hyperparameter Tuning Best Practices
Understand Your Hyperparameters
- Categorize hyperparameters:
- Model architecture (e.g., number of layers, units per layer)
- Optimization (e.g., learning rate, batch size)
- Regularization (e.g., dropout rate, weight decay)
Choose the Right Tuning Strategy
- Grid Search: Exhaustive search over a manually specified subset of hyperparameters.
- Random Search: Samples hyperparameters randomly; often more efficient than grid search.
- Bayesian Optimization: Uses probabilistic models to select promising hyperparameters.
- Hyperband and Successive Halving: Early stopping methods to allocate resources efficiently.
Automate Hyperparameter Search
- Use tools like Optuna, Ray Tune, or Keras Tuner to automate and scale tuning.
Parallelize Experiments
- Run multiple tuning trials concurrently on distributed infrastructure to reduce turnaround time.
Monitor and Log Results
- Track hyperparameter values, metrics, and system resource usage.
Use Early Stopping
- Stop poorly performing trials early to save compute resources.
Set Realistic Search Spaces
- Define reasonable ranges and distributions for hyperparameters to avoid wasting resources.
Experiment Tracking Best Practices
Use a Centralized Tracking System
- Tools like MLflow, Weights & Biases (W&B), Neptune.ai, or Comet.ml enable centralized logging.
Log All Relevant Information
- Hyperparameters
- Training and validation metrics
- Model artifacts (e.g., serialized models)
- Data versions
- Code versions (commit hashes)
- Environment details (library versions, hardware)
Organize Experiments Hierarchically
- Group experiments by project, model type, or dataset.
Enable Collaboration
- Share experiment results and visualizations with team members.
Automate Tracking in Pipelines
- Integrate tracking calls into training scripts and CI/CD pipelines.
Visualize and Compare Experiments
- Use dashboards to compare metrics across runs and identify best models.
Reproducibility
- Ensure experiments can be reproduced by capturing code, data, and environment.
Mind Maps
Mind Map: Hyperparameter Tuning Strategies
Mind Map: Experiment Tracking Components
Examples
Example 1: Hyperparameter Tuning with Optuna
import optuna
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
# Objective function to optimize
def objective(trial):
iris = load_iris()
X, y = iris.data, iris.target
# Suggest hyperparameters
C = trial.suggest_loguniform('C', 1e-3, 1e3)
gamma = trial.suggest_loguniform('gamma', 1e-4, 1e-1)
clf = SVC(C=C, gamma=gamma)
score = cross_val_score(clf, X, y, cv=3).mean()
return score
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print('Best hyperparameters:', study.best_params)
This example demonstrates automated hyperparameter tuning using Optuna’s Bayesian optimization.
Example 2: Experiment Tracking with MLflow
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
with mlflow.start_run():
# Set hyperparameters
n_estimators = 100
max_depth = 3
# Train model
clf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
clf.fit(X_train, y_train)
# Predict and evaluate
preds = clf.predict(X_test)
acc = accuracy_score(y_test, preds)
# Log parameters and metrics
mlflow.log_param('n_estimators', n_estimators)
mlflow.log_param('max_depth', max_depth)
mlflow.log_metric('accuracy', acc)
# Log model
mlflow.sklearn.log_model(clf, 'random_forest_model')
print(f'Model accuracy: {acc}')
This example shows how to log hyperparameters, metrics, and model artifacts using MLflow for experiment tracking.
Summary
- Choose hyperparameter tuning strategies based on your problem and resources.
- Automate and parallelize tuning to accelerate experimentation.
- Use centralized experiment tracking tools to log all relevant data.
- Ensure reproducibility and collaboration through systematic tracking.
- Visualize and compare experiments to identify the best performing models.
By following these best practices, machine learning engineers and AI platform engineers can build scalable, reproducible, and efficient model development workflows.
4.3 Integrating Continuous Training with CI/CD Workflows
Continuous Integration and Continuous Deployment (CI/CD) workflows have revolutionized software engineering by enabling rapid, reliable, and repeatable delivery of code. In MLOps, integrating continuous training into CI/CD pipelines ensures that machine learning models remain up-to-date, performant, and aligned with evolving data distributions and business requirements.
Why Integrate Continuous Training into CI/CD?
- Automated Model Updates: Automatically retrain models when new data arrives or when performance degrades.
- Reduced Manual Intervention: Minimize human error and speed up the model refresh cycle.
- Consistent Quality: Enforce validation and testing steps before deployment.
- Traceability: Maintain a clear audit trail of model versions and training runs.
Key Components of Continuous Training in CI/CD
Designing a Continuous Training Pipeline
-
Triggering Mechanism:
- Data-driven triggers such as arrival of new data batches or detection of data drift.
- Scheduled retraining (e.g., nightly or weekly).
-
Automated Training:
- Use pipeline orchestration tools (e.g., Apache Airflow, Kubeflow Pipelines) to automate preprocessing, training, and evaluation.
-
Validation and Testing:
- Implement automated validation gates to ensure models meet performance thresholds.
-
Model Registration and Versioning:
- Store trained models in a model registry (e.g., MLflow Model Registry) with metadata.
-
Deployment Automation:
- Integrate with CI/CD tools (e.g., Jenkins, GitLab CI/CD) to deploy validated models.
-
Monitoring and Feedback:
- Continuously monitor model performance and trigger retraining if necessary.
Example: Continuous Training with GitLab CI/CD and MLflow
Scenario: An e-commerce company wants to retrain its recommendation model weekly using new user interaction data.
Pipeline Steps:
-
Step 1: Data Ingestion Trigger
- A scheduled GitLab CI pipeline triggers every Sunday at midnight.
-
Step 2: Training Job
- The pipeline runs a Python script that:
- Loads latest data from a data lake.
- Preprocesses data.
- Trains the recommendation model.
- Logs parameters, metrics, and artifacts to MLflow.
- The pipeline runs a Python script that:
-
Step 3: Validation
- The script evaluates model performance against baseline metrics.
- If performance is below threshold, the pipeline fails and alerts the team.
-
Step 4: Model Registration
- If validation passes, the model is registered in MLflow Model Registry with a new version.
-
Step 5: Deployment
- A downstream job deploys the new model to staging environment for further testing.
-
Step 6: Production Rollout
- After manual or automated approval, the model is deployed to production.
GitLab CI YAML snippet:
stages:
- train
- validate
- deploy
train_model:
stage: train
script:
- python train.py --data-path s3://data-lake/user-interactions/ --mlflow-uri http://mlflow-server
artifacts:
paths:
- model/
validate_model:
stage: validate
script:
- python validate.py --model-path model/ --threshold 0.85
when: on_success
deploy_model:
stage: deploy
script:
- python deploy.py --model-path model/ --env staging
when: manual
Mind Map: CI/CD Workflow for Continuous Training
Best Practices
- Modular Pipelines: Design reusable and modular pipeline components.
- Automated Testing: Include unit tests for data transformations and model code.
- Use Feature Stores: Ensure consistent feature computation between training and serving.
- Rollback Mechanisms: Implement automated rollback if new models degrade performance.
- Security: Secure credentials and access to data and model registries.
- Documentation: Maintain clear documentation of pipeline steps and triggers.
Summary
Integrating continuous training into CI/CD workflows enables teams to maintain high-quality, up-to-date models with minimal manual effort. By automating triggers, training, validation, registration, deployment, and monitoring, organizations can accelerate their ML lifecycle and respond quickly to changing data and business needs.
4.4 Practical Example: Using MLflow and TFX for Experiment Management
In this section, we will explore how to effectively manage machine learning experiments using MLflow and TensorFlow Extended (TFX). These tools help automate tracking, reproducibility, and lifecycle management of experiments, which are critical for scalable MLOps.
Why Experiment Management?
Experiment management enables ML teams to:
- Track different model versions and parameters
- Compare model performance metrics
- Reproduce results easily
- Collaborate efficiently across teams
Overview of MLflow and TFX
| Tool | Purpose | Key Features |
|---|---|---|
| MLflow | Open-source platform for managing ML lifecycle | Experiment tracking, model registry, deployment |
| TFX | End-to-end platform for deploying production ML pipelines | Pipeline orchestration, data validation, model analysis |
Mind Map: Experiment Management with MLflow and TFX
Step-by-Step Example: Managing Experiments with MLflow and TFX
Setting up MLflow Tracking Server
import mlflow
from mlflow import log_metric, log_param, log_artifact
# Set tracking URI (local or remote server)
mlflow.set_tracking_uri("http://localhost:5000")
# Start a new experiment run
with mlflow.start_run(run_name="tfx_experiment_1"):
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("batch_size", 32)
# Simulate training metrics
mlflow.log_metric("accuracy", 0.92)
mlflow.log_metric("loss", 0.15)
# Log model artifact (e.g., saved model directory)
mlflow.log_artifact("./model")
print("Experiment logged successfully!")
Building a Simple TFX Pipeline with MLflow Integration
from tfx.orchestration import pipeline
from tfx.components import ExampleGen, Trainer, Evaluator, Pusher
from tfx.orchestration.local.local_dag_runner import LocalDagRunner
import mlflow
# Define pipeline components
example_gen = ExampleGen(input_base="./data")
trainer = Trainer(
module_file="trainer.py",
examples=example_gen.outputs['examples'],
train_args={'num_steps': 1000},
eval_args={'num_steps': 500}
)
evaluator = Evaluator(examples=example_gen.outputs['examples'], model=trainer.outputs['model'])
pusher = Pusher(model=trainer.outputs['model'], push_destination="./serving_model")
# Define the pipeline
tfx_pipeline = pipeline.Pipeline(
pipeline_name="tfx_mlflow_pipeline",
pipeline_root="./pipeline_root",
components=[example_gen, trainer, evaluator, pusher],
enable_cache=True
)
# Run the pipeline locally
LocalDagRunner().run(tfx_pipeline)
# After training, log model and metrics to MLflow
with mlflow.start_run(run_name="tfx_pipeline_run"):
mlflow.log_param("num_steps", 1000)
mlflow.log_metric("eval_accuracy", 0.93)
mlflow.log_artifact("./serving_model")
print("TFX pipeline run logged to MLflow.")
Tracking Experiments and Comparing Results
- Use MLflow UI (
mlflow ui) to visualize runs, compare metrics, and select the best performing model. - Register models in MLflow Model Registry to manage model lifecycle stages (Staging, Production).
Best Practices
- Automate experiment logging: Integrate MLflow logging calls directly inside TFX Trainer component’s training code.
- Use metadata store: TFX’s metadata store tracks pipeline executions and artifacts, enabling reproducibility.
- Version control your pipeline code: Keep TFX pipeline definitions and MLflow configurations in Git.
- Use MLflow Model Registry: Promote models through stages to enforce quality gates before production deployment.
Additional Mind Map: Integrating MLflow into TFX Trainer
Summary
By combining TFX’s robust pipeline orchestration with MLflow’s flexible experiment tracking and model registry, teams can build scalable, automated, and reproducible experiment management systems. This integration supports continuous training, evaluation, and deployment workflows essential for production-grade MLOps.
References & Resources
- MLflow Documentation
- TensorFlow Extended (TFX) Guide
- TFX and MLflow Integration Example
- MLflow Model Registry
5. Model Validation and Testing Strategies
5.1 Automated Model Validation Techniques
Automated model validation is a critical step in the MLOps pipeline to ensure that models meet predefined quality and performance standards before deployment. It helps detect issues early, maintain reliability, and reduce manual overhead.
Why Automated Model Validation?
- Consistency: Removes human bias and variability.
- Speed: Enables rapid feedback loops.
- Scalability: Supports frequent retraining and deployment.
- Early Detection: Identifies performance degradation or data issues.
Key Techniques in Automated Model Validation
Performance Metrics Validation
Automated evaluation of model predictions against ground truth labels using appropriate metrics.
Example:
from sklearn.metrics import accuracy_score, f1_score
def validate_classification_model(y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
if acc < 0.85 or f1 < 0.80:
raise ValueError(f"Model performance below threshold: Accuracy={acc}, F1={f1}")
return True
This function can be integrated into CI/CD pipelines to automatically reject models that do not meet performance criteria.
Data Validation
Ensures input data conforms to expected schema and quality standards.
Example: Using great_expectations to validate data schema and distributions.
import great_expectations as ge
def validate_data(dataframe):
df = ge.from_pandas(dataframe)
# Expect columns
df.expect_column_to_exist('age')
df.expect_column_values_to_not_be_null('age')
# Expect age to be within realistic range
df.expect_column_values_to_be_between('age', min_value=0, max_value=120)
results = df.validate()
if not results['success']:
raise ValueError("Data validation failed")
return True
Drift Detection
Detects if the data or model behavior has changed significantly from training.
Example: Using Kolmogorov-Smirnov test for data drift detection.
from scipy.stats import ks_2samp
def detect_data_drift(train_data, current_data, feature):
stat, p_value = ks_2samp(train_data[feature], current_data[feature])
if p_value < 0.05:
print(f"Drift detected in feature {feature} (p={p_value})")
return True
return False
Explainability Checks
Validate that feature importance or SHAP values remain consistent to detect unexpected model behavior.
Example:
import shap
def check_shap_consistency(model, X_train, X_new):
explainer = shap.TreeExplainer(model)
shap_values_train = explainer.shap_values(X_train)
shap_values_new = explainer.shap_values(X_new)
# Compare mean absolute SHAP values
mean_train = np.mean(np.abs(shap_values_train), axis=0)
mean_new = np.mean(np.abs(shap_values_new), axis=0)
diff = np.abs(mean_train - mean_new)
if np.any(diff > 0.1):
raise Warning("Significant change in feature importance detected")
return True
Fairness and Bias Detection
Automated checks to ensure model predictions are fair across demographic groups.
Example: Using aif360 to check demographic parity.
from aif360.metrics import BinaryLabelDatasetMetric
def check_fairness(dataset):
metric = BinaryLabelDatasetMetric(dataset, privileged_groups=[{'gender': 1}], unprivileged_groups=[{'gender': 0}])
disparity = metric.disparate_impact()
if disparity < 0.8 or disparity > 1.25:
raise Warning(f"Fairness check failed: Disparate Impact = {disparity}")
return True
Automated Testing of Model Code
Unit and integration tests ensure that model code behaves as expected.
Example:
import unittest
class TestModelFunctions(unittest.TestCase):
def test_prediction_shape(self):
preds = model.predict(X_test)
self.assertEqual(preds.shape[0], X_test.shape[0])
def test_no_nan_predictions(self):
preds = model.predict(X_test)
self.assertFalse(np.isnan(preds).any())
if __name__ == '__main__':
unittest.main()
Integrating Automated Validation into Pipelines
Summary
Automated model validation techniques encompass a broad range of checks including performance, data quality, drift, explainability, fairness, and code correctness. By integrating these techniques into your MLOps pipelines, you can ensure robust, reliable, and fair models in production with minimal manual intervention.
5.2 Performance Monitoring and Drift Detection
Performance monitoring and drift detection are critical components in maintaining the reliability and accuracy of machine learning models once deployed in production. Continuous monitoring ensures that models perform as expected over time, while drift detection helps identify when the underlying data or model behavior changes, potentially degrading performance.
Why Performance Monitoring and Drift Detection Matter
- Model degradation over time: Models trained on historical data may become less accurate as real-world data evolves.
- Data distribution changes: Incoming data might shift due to seasonality, user behavior changes, or external factors.
- Concept drift: The relationship between input features and target variables can change, requiring model updates.
- Regulatory compliance: Monitoring helps ensure models meet fairness, bias, and reliability standards continuously.
Key Metrics for Performance Monitoring
- Accuracy, Precision, Recall, F1-Score: For classification models, track these to measure predictive quality.
- Mean Squared Error (MSE), Mean Absolute Error (MAE): For regression models.
- ROC-AUC: To evaluate classification threshold performance.
- Latency and Throughput: Operational metrics to ensure service-level objectives.
- Prediction Distribution: Monitor changes in predicted class probabilities or values.
Drift Types and Detection Techniques
Mind Map: Types of Drift
Practical Example: Implementing Drift Detection with Python
import numpy as np
from scipy.stats import ks_2samp
# Historical (reference) data distribution
reference_data = np.random.normal(loc=0, scale=1, size=1000)
# Incoming batch data
new_data = np.random.normal(loc=0.2, scale=1.1, size=1000)
# Perform Kolmogorov-Smirnov test to detect data drift
statistic, p_value = ks_2samp(reference_data, new_data)
print(f"KS Statistic: {statistic:.4f}, p-value: {p_value:.4f}")
if p_value < 0.05:
print("Data drift detected: distributions differ significantly.")
else:
print("No significant data drift detected.")
This example uses the Kolmogorov-Smirnov test to compare the distribution of a feature in the reference dataset versus the new incoming data batch. A low p-value indicates a significant difference, signaling potential drift.
Monitoring Model Performance Over Time
Mind Map: Monitoring Pipeline
Example: Using MLflow and Prometheus for Monitoring
- MLflow: Track model versions and performance metrics.
- Prometheus: Collect real-time metrics such as latency, error rates.
# Example Prometheus alert rule for model error rate
groups:
- name: mlops_alerts
rules:
- alert: HighModelErrorRate
expr: rate(model_prediction_errors[5m]) > 0.05
for: 10m
labels:
severity: critical
annotations:
summary: "High error rate detected in model predictions"
description: "Model error rate has exceeded 5% for more than 10 minutes."
This alert can trigger automated workflows to pause deployments or notify engineers.
Best Practices
- Automate monitoring and alerting: Use pipelines that automatically collect and analyze metrics.
- Establish baseline metrics: Define normal ranges for performance and data distributions.
- Use multiple drift detection methods: Combine statistical tests with performance monitoring.
- Incorporate explainability: Understand which features contribute to drift or performance degradation.
- Integrate with CI/CD: Automate retraining or rollback based on drift alerts.
Summary
Performance monitoring and drift detection form the backbone of robust production MLOps systems. By continuously tracking model quality and data consistency, teams can proactively maintain and improve models, ensuring reliable AI services at scale.
5.3 Incorporating Explainability and Fairness Checks
In modern MLOps pipelines, ensuring that models are not only accurate but also explainable and fair is critical for building trust and meeting regulatory requirements. This section dives into best practices, methodologies, and practical examples to incorporate explainability and fairness checks seamlessly into your production workflows.
Why Explainability and Fairness Matter
- Explainability helps stakeholders understand model decisions, enabling debugging, trust-building, and regulatory compliance.
- Fairness ensures models do not propagate or amplify biases, promoting ethical AI use.
Key Concepts
Mind Map: Explainability and Fairness in MLOps
Explainability Techniques and Examples
-
SHAP (SHapley Additive exPlanations)
- Provides local explanations by attributing each feature’s contribution to a single prediction.
- Example: For a credit scoring model, SHAP can highlight that “income” had the largest positive impact on a loan approval decision.
-
LIME (Local Interpretable Model-agnostic Explanations)
- Generates interpretable local surrogate models to explain individual predictions.
- Example: Explaining why a particular image was classified as “cat” by perturbing pixels and observing prediction changes.
-
Partial Dependence Plots (PDP)
- Visualize the marginal effect of a feature on the predicted outcome.
- Example: Showing how increasing “age” affects the predicted risk score in a healthcare model.
Fairness Checks and Examples
-
Bias Detection Metrics
- Statistical Parity Difference: Measures difference in positive outcome rates between groups.
- Example: Checking if male and female applicants have similar loan approval rates.
-
Mitigation Strategies
- Pre-processing: Rebalancing training data to reduce bias.
- In-processing: Adding fairness constraints during model training.
- Post-processing: Adjusting model outputs to equalize fairness metrics.
-
Practical Example: Using IBM AI Fairness 360 Toolkit
- Detect bias in dataset.
- Apply reweighing pre-processing.
- Retrain and validate fairness improvements.
Integrating Explainability and Fairness into MLOps Pipelines
Mind Map: Integration Workflow
Example: Automated Explainability and Fairness Check in CI/CD Pipeline
-
Step 1: After model training, run a validation job that:
- Computes SHAP values for a validation dataset.
- Calculates fairness metrics (e.g., demographic parity).
-
Step 2: Generate a report summarizing:
- Top features influencing predictions.
- Any fairness metric violations.
-
Step 3: If fairness thresholds are not met, fail the pipeline and notify the team.
-
Step 4: Upon passing, deploy the model with embedded explainability endpoints.
Summary
Incorporating explainability and fairness checks is essential for responsible AI. By using tools like SHAP, LIME, and fairness toolkits, and integrating these checks into automated MLOps pipelines, teams can ensure models remain transparent, trustworthy, and equitable throughout their lifecycle.
5.4 Example: Implementing Validation Gates with Seldon Core
In production MLOps pipelines, validation gates are critical checkpoints that ensure only models meeting predefined quality criteria are promoted or served. Seldon Core, an open-source platform for deploying machine learning models on Kubernetes, provides powerful tools to implement such validation gates effectively.
What Are Validation Gates?
Validation gates are automated decision points in the model deployment pipeline that verify model quality, performance, fairness, and compliance before allowing the model to proceed to the next stage (e.g., deployment or promotion).
Key validation criteria include:
- Model accuracy and performance metrics
- Data drift and concept drift detection
- Fairness and bias checks
- Explainability and interpretability
Why Use Seldon Core for Validation Gates?
- Extensible Inference Graphs: Seldon Core allows chaining multiple components (transformers, predictors, routers, and analyzers) in an inference graph.
- Custom Metrics and Analytics: Integrate custom metrics collection and validation logic.
- Integration with Kubernetes: Enables scalable and robust deployment.
- Support for A/B Testing and Canary Deployments: Facilitates gradual rollout with validation.
Step-by-Step Example: Building a Validation Gate in Seldon Core
Define the Model and Validation Components
- Model Predictor: The core ML model serving predictions.
- Validator Component: A custom microservice or component that evaluates predictions against validation criteria.
Create a Custom Validator
Implement a Python Flask app or FastAPI service that:
- Receives prediction outputs and input features.
- Computes validation metrics (e.g., accuracy, confidence thresholds).
- Returns a pass/fail signal or enriched metadata.
Example Validator (Python Flask):
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/validate', methods=['POST'])
def validate():
data = request.json
predictions = data.get('predictions')
labels = data.get('labels') # if available
# Simple validation: check if confidence > 0.8
confidences = [pred['score'] for pred in predictions]
if all(c > 0.8 for c in confidences):
return jsonify({'validation_passed': True})
else:
return jsonify({'validation_passed': False})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Define the Seldon Deployment with Validation Gate
Use the SeldonDeployment CRD to define an inference graph where the validator acts as a transformer or router that gates the flow.
Example YAML snippet:
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: model-with-validation
spec:
predictors:
- name: default
replicas: 1
graph:
name: validator
implementation: CUSTOM
endpoint:
type: REST
children:
- name: model-predictor
implementation: SKLEARN_SERVER
modelUri: gs://my-model-bucket/sklearn-model
componentSpecs:
- spec:
containers:
- name: validator
image: myregistry/validator:latest
- name: model-predictor
image: seldonio/sklearnserver:0.6
env:
- name: MODEL_URI
value: gs://my-model-bucket/sklearn-model
In this setup, the validator component intercepts requests, performs validation, and only forwards to the model predictor if validation passes.
Implementing Validation Logic in the Inference Graph
You can implement the validation gate as a router that decides whether to forward the request to the model or reject it based on validation results.
Router Mind Map:
Monitoring and Alerting
Integrate Seldon Core’s metrics with Prometheus and Grafana to monitor validation gate pass/fail rates.
Metrics to track:
- Validation pass rate
- Latency introduced by validation
- Number of rejected requests
Example Prometheus query:
sum(rate(seldon_validator_passed_total[5m])) / sum(rate(seldon_validator_total[5m]))
Mind Map: Validation Gate Workflow in Seldon Core
Best Practices for Validation Gates with Seldon Core
- Keep validation logic lightweight to avoid adding excessive latency.
- Use asynchronous validation for non-critical checks to improve throughput.
- Leverage Seldon’s A/B testing to compare models with and without validation gates.
- Automate rollback if validation failures exceed thresholds.
- Integrate with CI/CD pipelines to trigger validation on new model versions.
Summary
Implementing validation gates with Seldon Core enables robust automated quality control in production ML pipelines. By combining custom validation microservices with Seldon’s flexible inference graphs, teams can enforce strict model quality standards, reduce risk, and maintain trust in deployed models.
This example demonstrated how to build a simple confidence-based validation gate, integrate it into a Seldon deployment, and monitor its performance effectively.
6. Scalable Model Deployment and Serving
6.1 Deployment Patterns: Batch, Online, and Streaming
In production MLOps systems, choosing the right deployment pattern is critical to meet latency, throughput, and scalability requirements. The three primary deployment patterns are Batch, Online (Real-time), and Streaming. Each pattern serves different use cases and comes with its own architectural considerations and best practices.
Overview of Deployment Patterns
Batch Deployment
Definition: Batch deployment involves running model inference on large datasets at scheduled intervals. This pattern is suitable when predictions do not need to be instantaneous.
Best Practices:
- Schedule batch jobs during off-peak hours to optimize resource usage.
- Use distributed processing frameworks like Apache Spark for scalability.
- Store batch outputs in data warehouses or feature stores for downstream consumption.
Example: An e-commerce company runs a nightly batch job to score all users for product recommendations. The job reads user interaction data from a data lake, applies the recommendation model, and writes scores to a database for the website to consume the next day.
Code snippet (PySpark example):
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('BatchInference').getOrCreate()
# Load user data
user_df = spark.read.parquet('s3://data-lake/user_interactions/')
# Load model (e.g., a serialized sklearn model)
import joblib
model = joblib.load('/models/recommendation_model.pkl')
# Define UDF for prediction
from pyspark.sql.functions import udf
from pyspark.sql.types import FloatType
def predict_udf(features):
return float(model.predict([features])[0])
predict = udf(predict_udf, FloatType())
# Apply model
predictions = user_df.withColumn('score', predict(user_df['features']))
# Save predictions
predictions.write.mode('overwrite').parquet('s3://predictions/recommendations/')
Online Deployment
Definition: Online deployment serves model predictions in real-time, responding to individual requests with low latency.
Best Practices:
- Containerize models for portability and scalability.
- Use REST or gRPC APIs for serving.
- Implement autoscaling to handle variable traffic.
- Monitor latency and error rates closely.
Example: A fraud detection system exposes a REST API endpoint that receives transaction details and returns a fraud risk score within milliseconds.
Example architecture:
Code snippet (FastAPI example):
from fastapi import FastAPI
import joblib
import numpy as np
app = FastAPI()
model = joblib.load('/models/fraud_detection.pkl')
@app.post('/predict')
def predict(transaction: dict):
features = np.array(transaction['features']).reshape(1, -1)
score = model.predict_proba(features)[0][1]
return {'fraud_score': score}
Streaming Deployment
Definition: Streaming deployment processes data continuously as it arrives, enabling near real-time predictions on event streams.
Best Practices:
- Use event-driven architectures with message brokers like Kafka.
- Employ stream processing frameworks (e.g., Apache Flink) for low-latency inference.
- Design for fault tolerance and exactly-once processing semantics.
Example: A sensor monitoring system ingests IoT device data via Kafka, applies an anomaly detection model in real-time, and triggers alerts when anomalies are detected.
Example architecture:
Code snippet (Kafka + Python example):
from kafka import KafkaConsumer, KafkaProducer
import joblib
import json
consumer = KafkaConsumer('sensor-data', bootstrap_servers='localhost:9092')
producer = KafkaProducer(bootstrap_servers='localhost:9092')
model = joblib.load('/models/anomaly_detector.pkl')
for message in consumer:
data = json.loads(message.value)
features = data['features']
prediction = model.predict([features])[0]
if prediction == 1: # anomaly detected
alert = {'sensor_id': data['sensor_id'], 'alert': 'anomaly_detected'}
producer.send('alerts', json.dumps(alert).encode('utf-8'))
Summary Table
| Deployment Pattern | Latency | Throughput | Use Cases | Technologies |
|---|---|---|---|---|
| Batch | High (minutes to hours) | High | Monthly reports, bulk scoring | Apache Spark, Airflow, AWS Batch |
| Online | Low (milliseconds) | Medium | Fraud detection, recommendations | REST/gRPC APIs, KFServing, Seldon Core |
| Streaming | Near real-time (seconds) | High | IoT monitoring, social media analysis | Kafka, Flink, Kinesis |
By understanding these deployment patterns and their trade-offs, ML engineers and AI platform engineers can design scalable, efficient, and maintainable production systems tailored to their business needs.
6.2 Containerization and Orchestration for Model Serving
Containerization and orchestration are foundational technologies that enable scalable, reliable, and efficient deployment of machine learning models in production environments. This section delves into best practices, tools, and examples to help Machine Learning Engineers and AI Platform Engineers design robust model serving systems.
What is Containerization?
Containerization packages an application and its dependencies into a lightweight, portable unit called a container. This ensures consistency across different environments, from development to production.
Key benefits:
- Environment consistency
- Isolation of dependencies
- Portability across platforms
- Faster startup times compared to virtual machines
What is Orchestration?
Orchestration automates the deployment, scaling, and management of containerized applications. It handles tasks like load balancing, service discovery, rolling updates, and fault tolerance.
Popular orchestration platforms:
- Kubernetes
- Docker Swarm
- Apache Mesos
Mind Map: Containerization and Orchestration Overview
Containerization Best Practices for Model Serving
-
Use minimal base images:
- Example: Use
python:3.9-sliminstead of fullpython:3.9to reduce image size.
- Example: Use
-
Package only necessary dependencies:
- Avoid installing unused libraries to keep containers lightweight.
-
Multi-stage builds:
- Separate build environment from runtime environment to optimize image size.
-
Version control your Dockerfiles:
- Track changes and ensure reproducibility.
-
Security considerations:
- Run containers as non-root users.
- Regularly update base images to patch vulnerabilities.
Example: Dockerfile for a TensorFlow Model Serving Container
# Stage 1: Build stage
FROM python:3.9-slim AS builder
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . ./
# Stage 2: Runtime stage
FROM python:3.9-slim
WORKDIR /app
COPY --from=builder /app /app
EXPOSE 8501
CMD ["python", "serve_model.py"]
Explanation:
- The first stage installs dependencies.
- The second stage copies the built app and runs the model serving script.
Orchestration Best Practices for Model Serving
-
Use Kubernetes Deployments:
- Manage stateless model serving pods with rolling updates and rollbacks.
-
Leverage Services for Load Balancing:
- Expose model endpoints via Kubernetes Services for stable networking.
-
Autoscaling:
- Use Horizontal Pod Autoscaler (HPA) to scale pods based on CPU, memory, or custom metrics.
-
ConfigMaps and Secrets:
- Store configuration and sensitive data securely.
-
Health Checks:
- Implement readiness and liveness probes to ensure pod health.
-
Resource Requests and Limits:
- Define CPU and memory requirements to optimize scheduling.
Mind Map: Kubernetes Components for Model Serving
Example: Kubernetes Deployment YAML for Model Serving
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-serving-deployment
spec:
replicas: 3
selector:
matchLabels:
app: model-serving
template:
metadata:
labels:
app: model-serving
spec:
containers:
- name: model-server
image: myregistry/model-serving:latest
ports:
- containerPort: 8501
resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "1"
memory: "1Gi"
readinessProbe:
httpGet:
path: /health
port: 8501
initialDelaySeconds: 10
periodSeconds: 5
livenessProbe:
httpGet:
path: /health
port: 8501
initialDelaySeconds: 15
periodSeconds: 20
apiVersion: v1
kind: Service
metadata:
name: model-serving-service
spec:
selector:
app: model-serving
ports:
- protocol: TCP
port: 80
targetPort: 8501
type: LoadBalancer
Explanation:
- Deploys 3 replicas of the model server.
- Defines resource requests and limits.
- Adds readiness and liveness probes.
- Exposes the service via a LoadBalancer.
Real-World Example: Deploying a Scikit-learn Model with Docker and Kubernetes
Step 1: Containerize the model using a Dockerfile:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . ./
EXPOSE 5000
CMD ["python", "app.py"]
Step 2: Push the image to a container registry (e.g., Docker Hub).
Step 3: Create Kubernetes deployment and service YAML files as shown above.
Step 4: Deploy to Kubernetes cluster:
kubectl apply -f deployment.yaml
kubectl apply -f service.yaml
Step 5: Access the model endpoint via the external IP provided by the LoadBalancer.
Summary
| Aspect | Best Practices & Examples |
|---|---|
| Containerization | Minimal base images, multi-stage builds, security practices |
| Orchestration | Kubernetes deployments, services, autoscaling, health checks |
| Tools | Docker, Kubernetes, Helm, Kubeflow Serving |
| Example Technologies | TensorFlow Serving, Seldon Core, KFServing |
Additional Resources
- Docker Official Documentation
- Kubernetes Official Documentation
- Kubeflow Serving
- Seldon Core
By mastering containerization and orchestration, ML engineers can deploy models that scale seamlessly, maintain high availability, and simplify operational overhead, which are critical for successful production MLOps systems.
6.3 Load Balancing and Autoscaling Models in Production
In production environments, serving machine learning models efficiently and reliably requires robust load balancing and autoscaling strategies. These ensure that your models can handle varying traffic loads, maintain low latency, and optimize resource usage.
Why Load Balancing and Autoscaling Matter
- Load Balancing distributes incoming inference requests across multiple model instances to prevent any single instance from becoming a bottleneck.
- Autoscaling dynamically adjusts the number of model serving instances based on real-time demand, ensuring cost efficiency and availability.
Key Concepts Mind Map
Load Balancing Strategies
-
Round Robin: Requests are distributed evenly in a circular order. Simple but may not consider instance load.
-
Least Connections: Directs traffic to the instance with the fewest active connections, balancing load more intelligently.
-
IP Hash: Routes requests based on client IP, useful for session persistence.
-
Weighted Load Balancing: Assigns weights to instances based on capacity or priority.
-
Health Checks: Regularly verify instance health to avoid routing traffic to unhealthy pods.
Autoscaling Approaches
-
Horizontal Pod Autoscaling (HPA): Automatically increases or decreases the number of pods based on CPU utilization or custom metrics.
-
Vertical Scaling: Adjusts resource limits (CPU/memory) of existing pods but can cause downtime.
-
Predictive Autoscaling: Uses historical traffic data and ML models to anticipate load spikes and scale proactively.
Example: Autoscaling a TensorFlow Model Serving Deployment on Kubernetes
apiVersion: apps/v1
kind: Deployment
metadata:
name: tf-model-deployment
spec:
replicas: 2
selector:
matchLabels:
app: tf-model
template:
metadata:
labels:
app: tf-model
spec:
containers:
- name: tensorflow-serving
image: tensorflow/serving:latest
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 1
memory: 2Gi
ports:
- containerPort: 8500
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: tf-model-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tf-model-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
This example sets up a TensorFlow Serving deployment with autoscaling based on CPU utilization. When CPU usage exceeds 60%, Kubernetes will scale up to a maximum of 10 replicas.
Example: Load Balancing with Istio Service Mesh
Istio provides advanced load balancing capabilities for microservices, including ML model serving.
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: tf-model-destination
spec:
host: tf-model-service
trafficPolicy:
loadBalancer:
simple: LEAST_CONN
This configures Istio to use the least connections load balancing strategy for the TensorFlow model service.
Best Practices
- Combine Load Balancing and Autoscaling: Use load balancers to distribute traffic evenly and autoscaling to adjust capacity dynamically.
- Use Custom Metrics for Autoscaling: Beyond CPU, monitor request latency, queue length, or error rates to trigger scaling.
- Implement Health Checks: Ensure only healthy model instances receive traffic.
- Optimize Cold Starts: Use warm-up strategies or keep a minimum number of replicas running.
- Monitor Continuously: Use tools like Prometheus and Grafana to track autoscaling and load balancing effectiveness.
Summary Mind Map
By implementing robust load balancing and autoscaling strategies, you can ensure your machine learning models serve predictions reliably and cost-effectively, even under fluctuating production workloads.
6.4 Case Study: Deploying Multi-Model Endpoints with KFServing
Introduction
Deploying multiple machine learning models behind a single endpoint is a common requirement in production environments. This approach simplifies client interactions, reduces infrastructure overhead, and enables seamless A/B testing or model versioning. KFServing (now part of KServe) is a Kubernetes-native platform designed to simplify serverless model deployment and management, supporting multi-model serving with ease.
What is KFServing?
KFServing is an open-source project that provides a standardized, Kubernetes-native way to deploy and serve ML models. It supports multiple frameworks (TensorFlow, PyTorch, XGBoost, SKLearn, ONNX, etc.) and offers features like autoscaling, canary rollout, and multi-model serving.
Why Multi-Model Endpoints?
- Unified Access: Single API endpoint for multiple models.
- Resource Efficiency: Share infrastructure resources.
- Simplified Management: Centralized monitoring and logging.
- Use Cases: Model ensembles, A/B testing, multi-tenant serving.
Mind Map: Multi-Model Endpoint Deployment with KFServing
Step-by-Step Example: Deploying Two Models with KFServing
Scenario
Deploy two models — a TensorFlow image classifier and a Scikit-learn fraud detection model — behind a single KFServing InferenceService with multi-model support.
Prepare Models
- TensorFlow model saved in
gs://my-bucket/models/tf-image-classifier/ - Scikit-learn model saved in
gs://my-bucket/models/sklearn-fraud-detector/
Define the InferenceService YAML
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: multi-model-endpoint
spec:
predictor:
multiModel:
modelFormat:
name: tensorflow
storageUri: gs://my-bucket/models/
container:
image: kserve/tensorflowserver:latest
protocols:
- v1
- v2
models:
- name: tf-image-classifier
path: tf-image-classifier
framework: tensorflow
- name: sklearn-fraud-detector
path: sklearn-fraud-detector
framework: sklearn
Deploy on Kubernetes
kubectl apply -f multi-model-inferenceservice.yaml
Test the Endpoint
- The endpoint will route requests based on the
model_nameheader or URL path.
Example curl request to TensorFlow model:
curl -v -H "model_name: tf-image-classifier" \
-H "Content-Type: application/json" \
-d '{"instances": [[1.0, 2.0, 5.0]]}' \
http://multi-model-endpoint.default.example.com/v1/models/tf-image-classifier:predict
Example curl request to Scikit-learn model:
curl -v -H "model_name: sklearn-fraud-detector" \
-H "Content-Type: application/json" \
-d '{"data": [[0.1, 0.2, 0.3]]}' \
http://multi-model-endpoint.default.example.com/v1/models/sklearn-fraud-detector:predict
Mind Map: Request Routing in Multi-Model Endpoints
Best Practices for Multi-Model Endpoints with KFServing
- Model Versioning: Use clear versioning in model paths to enable rollback and A/B testing.
- Resource Allocation: Assign resource requests and limits per model to avoid noisy neighbor issues.
- Health Checks: Implement liveness and readiness probes for each model.
- Monitoring: Integrate Prometheus/Grafana for per-model metrics.
- Security: Use network policies and authentication to secure endpoints.
- Automation: Integrate deployment with CI/CD pipelines for continuous delivery.
Additional Example: Canary Rollout with Multi-Model Endpoint
You can deploy a new version of a model alongside the current one and gradually shift traffic using KFServing’s canary rollout feature.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: multi-model-canary
spec:
predictor:
multiModel:
models:
- name: fraud-detector-v1
path: fraud-detector/v1
framework: sklearn
- name: fraud-detector-v2
path: fraud-detector/v2
framework: sklearn
canaryTrafficPercent: 20
This routes 80% of traffic to v1 and 20% to v2, enabling safe testing in production.
Summary
Deploying multi-model endpoints with KFServing enables efficient, scalable, and manageable production ML systems. By leveraging Kubernetes-native features, autoscaling, and flexible routing, teams can serve multiple models seamlessly behind a unified API, simplifying client integration and operational overhead.
References
- KFServing Official Documentation
- Kubernetes InferenceService API
- Multi-Model Serving Guide
- Example GitHub Repo
7. Automated Model Lifecycle Management
7.1 Defining Model Versioning and Registry Best Practices
Model versioning and registry are foundational pillars for managing machine learning models effectively in production environments. Proper versioning ensures traceability, reproducibility, and smooth collaboration, while a robust model registry acts as a centralized repository to track, manage, and govern models throughout their lifecycle.
Why Model Versioning and Registry Matter
- Traceability: Know exactly which model version was deployed and under what conditions.
- Reproducibility: Re-run experiments or production pipelines with the exact model version.
- Collaboration: Multiple teams can work on different versions without conflicts.
- Governance & Compliance: Audit trails for regulatory requirements.
Best Practices for Model Versioning
Semantic Versioning
Use semantic versioning (e.g., v1.0.0) to communicate the nature of changes:
- Major: Breaking changes or architecture updates.
- Minor: New features or improvements.
- Patch: Bug fixes or minor tweaks.
Immutable Model Artifacts
Store model artifacts as immutable files (e.g., in object storage) to prevent accidental overwrites.
Include Metadata
Attach metadata such as training data version, hyperparameters, evaluation metrics, and environment details.
Link Code and Data Versions
Tie model versions to specific code commits and dataset versions for full reproducibility.
Automate Versioning
Use CI/CD pipelines to automatically increment versions upon successful training and validation.
Best Practices for Model Registry
Centralized Repository
Use a dedicated model registry tool (e.g., MLflow Model Registry, Sagemaker Model Registry) to store and manage models.
Model Stage Management
Define stages such as Staging, Production, Archived to manage model lifecycle states.
Access Control
Implement role-based access control (RBAC) to restrict who can register, promote, or archive models.
Model Lineage Tracking
Track lineage to understand dependencies between models, datasets, and code.
Integration with CI/CD
Enable automated deployment pipelines triggered by model stage transitions.
Mind Map: Model Versioning Best Practices
Mind Map: Model Registry Best Practices
Example 1: Using MLflow Model Registry for Versioning and Staging
import mlflow
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Register a new model version
model_uri = "runs:/1234567890abcdef/model"
model_name = "CustomerChurnModel"
model_version = client.create_model_version(
name=model_name,
source=model_uri,
run_id="1234567890abcdef"
)
# Transition model to staging
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Staging"
)
# Later, promote to production
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production"
)
Explanation:
- The example demonstrates registering a model version in MLflow.
- The model is first moved to
Stagingfor testing, then promoted toProduction. - MLflow automatically tracks version numbers.
Example 2: Automating Versioning with CI/CD
A typical GitHub Actions snippet to increment model version on successful training:
name: Model Training Pipeline
on:
push:
branches:
- main
jobs:
train-model:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Train Model
run: |
python train.py --output model.pkl
- name: Increment Version
run: |
# Assume version stored in VERSION file
version=$(cat VERSION)
IFS='.' read -r major minor patch <<< "$version"
patch=$((patch + 1))
echo "$major.$minor.$patch" > VERSION
- name: Commit and Push Version
run: |
git config user.name "github-actions"
git config user.email "[email protected]"
git add VERSION
git commit -m "Increment model version"
git push
Explanation:
- After training completes, the patch version is incremented.
- The updated version is committed back to the repository.
- This ensures every model build is uniquely versioned.
Summary
| Aspect | Best Practice Summary | Example Tool/Technique |
|---|---|---|
| Model Versioning | Semantic versioning, immutable artifacts, metadata | MLflow, Git tags, CI/CD scripts |
| Model Registry | Centralized repo, stages, access control, lineage | MLflow Model Registry, Sagemaker |
| Automation | CI/CD pipelines for version increment and deployment | GitHub Actions, Jenkins |
By following these best practices and leveraging automated tools, teams can maintain robust control over their models, enabling scalable, reliable, and compliant MLOps systems.
7.2 Automating Model Promotion and Rollback Procedures
Automating model promotion and rollback is a critical aspect of maintaining reliability and agility in production MLOps systems. It ensures that only validated, high-quality models serve end-users, while enabling rapid recovery if issues arise.
Why Automate Model Promotion and Rollback?
- Reduce manual errors: Automation minimizes human mistakes during deployment.
- Speed up release cycles: Enables continuous delivery of improved models.
- Ensure compliance: Enforce validation gates and governance automatically.
- Improve reliability: Quickly revert to stable versions when failures occur.
Core Concepts
- Model Promotion: The process of moving a model from a staging or testing environment into production after passing validation checks.
- Model Rollback: Reverting to a previous stable model version when the current production model underperforms or causes issues.
Mind Map: Automating Model Promotion and Rollback
Best Practices for Automating Promotion
- Define Clear Validation Criteria: Establish quantitative thresholds for model accuracy, precision, recall, or business KPIs.
- Use Automated Testing Pipelines: Integrate unit tests, integration tests, and model validation tests in CI/CD.
- Implement Approval Gates: Combine automated checks with optional human approvals for sensitive deployments.
- Adopt Deployment Strategies: Use canary or blue-green deployments to reduce risk.
Example: Automated Promotion Pipeline Using MLflow and Jenkins
- Step 1: Model training completes and logs metrics to MLflow.
- Step 2: Jenkins pipeline triggers validation job that checks if metrics meet thresholds.
- Step 3: If validation passes, Jenkins deploys the model to a staging environment.
- Step 4: Automated integration tests run against staging.
- Step 5: Upon success, Jenkins promotes the model to production via Kubernetes deployment.
# Jenkinsfile snippet
pipeline {
stages {
stage('Validate Model') {
steps {
script {
def metrics = sh(script: 'mlflow metrics get --run-id $RUN_ID', returnStdout: true)
if (!metrics.contains('accuracy:0.9')) {
error('Model accuracy below threshold')
}
}
}
}
stage('Deploy to Staging') {
steps {
sh 'kubectl apply -f staging-deployment.yaml'
}
}
stage('Integration Tests') {
steps {
sh './run_integration_tests.sh'
}
}
stage('Promote to Production') {
steps {
sh 'kubectl apply -f production-deployment.yaml'
}
}
}
}
Best Practices for Automating Rollback
- Continuous Monitoring: Monitor model performance and system health in real-time.
- Define Rollback Triggers: Set thresholds for metrics that trigger rollback automatically.
- Maintain Model Versioning: Keep previous stable model versions readily deployable.
- Automate Rollback Execution: Use scripts or orchestration tools to revert deployments.
- Alert Stakeholders: Notify teams immediately upon rollback.
Example: Automated Rollback with Seldon Core and Prometheus
- Step 1: Prometheus monitors model latency and accuracy metrics.
- Step 2: Alertmanager triggers a webhook when latency exceeds threshold.
- Step 3: A Kubernetes operator listens to alerts and triggers rollback by redeploying the last stable model version.
- Step 4: Slack notifications are sent to the MLOps team.
# Prometheus alert rule
- alert: HighModelLatency
expr: seldon_model_latency_seconds > 1.0
for: 5m
labels:
severity: critical
annotations:
summary: "Model latency is too high"
description: "Model latency has exceeded 1 second for more than 5 minutes."
# Rollback script snippet
kubectl rollout undo deployment/model-deployment -n production
curl -X POST -H 'Content-type: application/json' --data '{"text":"Rollback executed due to high latency"}' https://hooks.slack.com/services/XXX/YYY/ZZZ
Integrating Promotion and Rollback in a Unified Workflow
Summary
Automating model promotion and rollback procedures is essential for scalable and reliable MLOps. By combining validation gates, deployment automation, continuous monitoring, and alerting, teams can confidently deliver high-quality models and quickly recover from issues. Leveraging tools like MLflow, Jenkins, Seldon Core, Prometheus, and Kubernetes enables building robust automated pipelines that reduce downtime and improve trust in AI systems.
7.3 Lifecycle Automation Using Pipelines and Workflow Orchestration
Automating the model lifecycle is crucial for maintaining efficiency, reproducibility, and scalability in production MLOps systems. Workflow orchestration tools and pipelines enable teams to define, schedule, and monitor complex sequences of tasks that constitute the model lifecycle — from data ingestion and preprocessing to training, validation, deployment, and monitoring.
Why Automate Model Lifecycle?
- Consistency: Ensures that every step in the lifecycle executes in a controlled, repeatable manner.
- Scalability: Handles increasing workloads and multiple models without manual intervention.
- Traceability: Tracks each stage for auditing and debugging.
- Rapid Iteration: Enables continuous integration and continuous delivery (CI/CD) of models.
Key Components of Lifecycle Automation Pipelines
Popular Workflow Orchestration Tools
| Tool | Description | Use Case Example |
|---|---|---|
| Apache Airflow | Python-based, highly extensible workflow scheduler | Scheduling ETL and training jobs in batch mode |
| Kubeflow Pipelines | Kubernetes-native, designed for ML workflows | End-to-end ML pipeline orchestration on K8s |
| MLflow | Experiment tracking with simple pipeline capabilities | Tracking experiments and packaging models |
| Argo Workflows | Kubernetes-native, container-based workflow engine | Complex DAGs for model retraining and deployment |
Example: Automating Model Lifecycle with Apache Airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def data_ingestion():
print("Ingesting data from source...")
def preprocess_data():
print("Preprocessing data...")
def train_model():
print("Training model...")
def validate_model():
print("Validating model performance...")
def deploy_model():
print("Deploying model to production...")
with DAG('ml_model_lifecycle', start_date=datetime(2024, 1, 1), schedule_interval='@daily') as dag:
t1 = PythonOperator(task_id='data_ingestion', python_callable=data_ingestion)
t2 = PythonOperator(task_id='preprocess_data', python_callable=preprocess_data)
t3 = PythonOperator(task_id='train_model', python_callable=train_model)
t4 = PythonOperator(task_id='validate_model', python_callable=validate_model)
t5 = PythonOperator(task_id='deploy_model', python_callable=deploy_model)
t1 >> t2 >> t3 >> t4 >> t5
This simple DAG defines a sequential pipeline automating key lifecycle stages. In production, each function would contain robust logic, error handling, and integration with data stores and model registries.
Example: Kubeflow Pipelines for End-to-End Automation
Kubeflow Pipelines allow defining reusable components and assembling them into complex workflows.
import kfp
from kfp import dsl
@dsl.component
def ingest_op():
print('Data ingestion step')
@dsl.component
def train_op():
print('Model training step')
@dsl.component
def deploy_op():
print('Model deployment step')
@dsl.pipeline(name='ml-lifecycle-pipeline')
def ml_pipeline():
ingest = ingest_op()
train = train_op()
deploy = deploy_op()
train.after(ingest)
deploy.after(train)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(ml_pipeline, 'ml_pipeline.yaml')
Kubeflow Pipelines supports parameterization, parallelism, and integration with Kubernetes resources, making it ideal for scalable MLOps.
Best Practices for Pipeline and Workflow Automation
- Modularize Components: Build reusable, testable components for each lifecycle step.
- Parameterize Pipelines: Allow dynamic inputs for flexibility and experimentation.
- Implement Idempotency: Ensure tasks can safely rerun without side effects.
- Integrate with Model Registry: Automate model versioning and metadata tracking.
- Use Monitoring and Alerts: Detect failures and performance degradation early.
- Secure Secrets and Credentials: Use vaults or environment variables to protect sensitive data.
Mind Map: Best Practices for Lifecycle Automation
Summary
Automating the model lifecycle using pipelines and workflow orchestration is indispensable for scalable, reliable MLOps. By leveraging tools like Apache Airflow, Kubeflow Pipelines, and MLflow, teams can build robust workflows that accelerate model development, deployment, and maintenance while ensuring governance and traceability.
Incorporating best practices such as modular design, parameterization, and monitoring further enhances pipeline robustness and adaptability to evolving production needs.
7.4 Example: End-to-End Model Lifecycle with Airflow and MLflow
In this section, we will explore a practical example of implementing an end-to-end automated model lifecycle management system using Apache Airflow for orchestration and MLflow for experiment tracking, model registry, and deployment. This example demonstrates how to automate the entire lifecycle from data ingestion, model training, validation, registration, and deployment, ensuring reproducibility, scalability, and maintainability.
Overview Mind Map
Step 1: Data Ingestion and Preprocessing
We start by creating an Airflow DAG task that extracts raw data, performs necessary transformations, and loads it into a feature store or training dataset.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def extract_transform_load(**kwargs):
# Example: Load raw data, clean, and save processed data
import pandas as pd
raw_data = pd.read_csv('/path/to/raw/data.csv')
processed_data = raw_data.dropna() # simple cleaning
processed_data.to_csv('/path/to/processed/data.csv', index=False)
with DAG('ml_lifecycle_dag', start_date=datetime(2024, 1, 1), schedule_interval='@daily') as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load
)
Step 2: Model Training and Experiment Tracking with MLflow
Next, we define a training function that logs parameters, metrics, and the model itself to MLflow.
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
def train_model(**kwargs):
data = pd.read_csv('/path/to/processed/data.csv')
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run():
n_estimators = 100
max_depth = 5
clf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
acc = accuracy_score(y_test, preds)
mlflow.log_param('n_estimators', n_estimators)
mlflow.log_param('max_depth', max_depth)
mlflow.log_metric('accuracy', acc)
mlflow.sklearn.log_model(clf, 'model')
print(f'Model trained with accuracy: {acc}')
with DAG('ml_lifecycle_dag', start_date=datetime(2024, 1, 1), schedule_interval='@daily', catchup=False) as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load
)
train_task = PythonOperator(
task_id='train_model',
python_callable=train_model
)
etl_task >> train_task
Step 3: Model Validation and Conditional Registration
After training, validate the model performance and register it in MLflow Model Registry if it meets the criteria.
from mlflow.tracking import MlflowClient
def validate_and_register(**kwargs):
client = MlflowClient()
experiment = client.get_experiment_by_name('Default')
runs = client.search_runs(experiment_ids=[experiment.experiment_id], order_by=['attributes.start_time DESC'], max_results=1)
latest_run = runs[0]
accuracy = latest_run.data.metrics.get('accuracy')
threshold = 0.8
if accuracy and accuracy >= threshold:
model_uri = f"runs:/{latest_run.info.run_id}/model"
model_name = 'RandomForestClassifier'
# Register model
result = mlflow.register_model(model_uri, model_name)
print(f'Model registered with version: {result.version}')
else:
print(f'Model accuracy {accuracy} below threshold {threshold}, skipping registration.')
with DAG('ml_lifecycle_dag', start_date=datetime(2024, 1, 1), schedule_interval='@daily', catchup=False) as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load
)
train_task = PythonOperator(
task_id='train_model',
python_callable=train_model
)
validate_register_task = PythonOperator(
task_id='validate_and_register',
python_callable=validate_and_register
)
etl_task >> train_task >> validate_register_task
Step 4: Model Deployment Automation
Deploy the registered model to a serving environment automatically using MLflow’s deployment tools or custom scripts.
def deploy_model(**kwargs):
client = MlflowClient()
model_name = 'RandomForestClassifier'
latest_versions = client.get_latest_versions(name=model_name, stages=['None'])
if latest_versions:
model_version = latest_versions[0].version
# Transition model to 'Production' stage
client.transition_model_version_stage(
name=model_name,
version=model_version,
stage='Production'
)
print(f'Model version {model_version} transitioned to Production')
# Example: Trigger deployment script or API call here
else:
print('No new model versions to deploy.')
with DAG('ml_lifecycle_dag', start_date=datetime(2024, 1, 1), schedule_interval='@daily', catchup=False) as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load
)
train_task = PythonOperator(
task_id='train_model',
python_callable=train_model
)
validate_register_task = PythonOperator(
task_id='validate_and_register',
python_callable=validate_and_register
)
deploy_task = PythonOperator(
task_id='deploy_model',
python_callable=deploy_model
)
etl_task >> train_task >> validate_register_task >> deploy_task
Step 5: Monitoring and Retraining
Set up Airflow to monitor model performance metrics and trigger retraining if performance degrades.
def monitor_model(**kwargs):
# Placeholder: Implement monitoring logic, e.g., check recent prediction accuracy or data drift
# If performance < threshold, trigger retraining
performance_degraded = False # Example condition
if performance_degraded:
print('Performance degraded, triggering retraining')
# Trigger retraining DAG or task
else:
print('Model performance is stable')
monitor_task = PythonOperator(
task_id='monitor_model',
python_callable=monitor_model,
dag=dag
)
# Optionally, set dependencies to include monitoring
# deploy_task >> monitor_task
Summary Mind Map
Key Best Practices Highlighted
- Modular DAG design: Each step is a separate Airflow task for clear separation of concerns.
- Experiment tracking: Use MLflow to log parameters, metrics, and artifacts for reproducibility.
- Conditional model registration: Only register models that meet performance thresholds.
- Model versioning and stage transitions: Manage model lifecycle states (e.g., None → Production).
- Automation of deployment: Integrate deployment steps into the pipeline to reduce manual intervention.
- Monitoring and retraining: Continuously monitor model health and automate retraining triggers.
This example can be extended with more sophisticated data validation, feature engineering, hyperparameter tuning, and deployment strategies depending on your production environment and business needs.
8. Monitoring and Observability in Production MLOps
8.1 Metrics to Monitor for Model and System Health
Monitoring metrics is critical to maintaining reliable, performant, and trustworthy machine learning systems in production. These metrics help detect issues early, ensure models continue to deliver value, and maintain system stability.
Key Categories of Metrics
Model Performance Metrics
These metrics evaluate how well the model is performing on live data compared to expectations or baseline.
-
Example: For a fraud detection model, monitoring precision and recall helps balance false positives and false negatives. Sudden drops in recall might indicate the model is missing new fraud patterns.
-
Mind Map:
Data Quality Metrics
Monitoring data quality ensures the input to your model remains consistent and reliable.
-
Example: A sudden increase in missing values or a shift in feature distribution (data drift) can degrade model performance. For instance, a recommendation system might see a new user demographic causing feature distribution changes.
-
Mind Map:
- Practical Implementation: Use statistical tests like Kolmogorov-Smirnov or Population Stability Index (PSI) to detect drift.
System Health Metrics
These metrics focus on the infrastructure and serving environment to ensure the model is available and responsive.
-
Latency: Time taken to get a prediction. High latency can degrade user experience.
-
Throughput: Number of requests served per second.
-
Error Rate: Percentage of failed prediction requests.
-
Resource Utilization: CPU, memory, and GPU usage to detect bottlenecks.
-
Example: If latency spikes during peak hours, autoscaling policies might need adjustment.
-
Mind Map:
Business Metrics
Ultimately, model success is measured by its impact on business goals.
-
Example: An increase in conversion rate after deploying a personalized marketing model.
-
Mind Map:
Integrated Example: Monitoring a Customer Churn Prediction Model
-
Model Performance: Track recall to catch true churners.
-
Data Quality: Monitor feature distributions like customer tenure or usage patterns for drift.
-
System Health: Monitor API latency and error rates to ensure smooth predictions.
-
Business: Monitor churn rate and retention improvements.
Best Practices
- Automate metric collection and alerting using tools like Prometheus, Grafana, or custom dashboards.
- Set thresholds and anomaly detection to trigger alerts.
- Correlate model metrics with business KPIs to prioritize issues.
- Regularly review and update monitored metrics as models and business needs evolve.
Summary Mind Map
By continuously monitoring these metrics, AI Platform Engineers and Machine Learning Engineers can proactively maintain model quality and system reliability, ensuring scalable and robust MLOps production environments.
8.2 Logging and Tracing for Debugging and Auditing
Effective logging and tracing are critical components in scalable MLOps systems to ensure smooth debugging, auditing, and operational transparency. This section explores best practices, tools, and examples to implement robust logging and tracing mechanisms.
Why Logging and Tracing Matter in MLOps
- Debugging: Quickly identify and resolve issues in data pipelines, model training, and serving.
- Auditing: Maintain records for compliance, reproducibility, and accountability.
- Performance Monitoring: Understand bottlenecks and optimize system efficiency.
Key Concepts
- Logging: Recording discrete events or messages generated by components.
- Tracing: Capturing the flow of requests or operations across distributed components.
Mind Map: Core Components of Logging and Tracing in MLOps
Best Practices for Logging in MLOps
-
Use Structured Logging:
- Prefer JSON or other structured formats over plain text.
- Example:
{ "timestamp": "2024-06-01T12:00:00Z", "level": "ERROR", "component": "ModelTraining", "message": "Training failed due to missing feature data", "feature": "user_age", "run_id": "abc123" } -
Define Log Levels Clearly:
- DEBUG: Detailed information for troubleshooting.
- INFO: General operational events.
- WARN: Potential issues.
- ERROR: Failures requiring immediate attention.
-
Centralize Logs:
- Use log aggregation tools (e.g., ELK stack) to collect logs from multiple services.
-
Include Contextual Metadata:
- Add identifiers like model version, pipeline run ID, user ID, timestamps.
-
Implement Log Rotation and Retention:
- Manage storage costs and comply with data retention policies.
Best Practices for Tracing in MLOps
-
Adopt Distributed Tracing:
- Trace requests as they propagate through microservices, data pipelines, and model serving layers.
-
Propagate Trace Context:
- Pass trace and span IDs through HTTP headers or messaging metadata.
-
Use Open Standards:
- OpenTelemetry is a popular standard for instrumentation.
-
Visualize Traces:
- Use tools like Jaeger or Zipkin to analyze latency and pinpoint failures.
-
Correlate Logs and Traces:
- Link logs with trace IDs for comprehensive debugging.
Mind Map: Logging and Tracing Workflow Example
Example: Implementing Logging and Tracing in a Python MLOps Pipeline
import logging
import time
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor, ConsoleSpanExporter
# Setup logging
logging.basicConfig(
format='%(asctime)s %(levelname)s %(name)s %(message)s',
level=logging.INFO
)
logger = logging.getLogger("mlops_pipeline")
# Setup tracing
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
span_processor = BatchSpanProcessor(ConsoleSpanExporter())
trace.get_tracer_provider().add_span_processor(span_processor)
def train_model(data):
with tracer.start_as_current_span("train_model") as span:
logger.info(f"Starting training with data size: {len(data)}")
try:
# Simulate training
time.sleep(2)
if len(data) == 0:
raise ValueError("Empty training data")
accuracy = 0.95 # Dummy accuracy
logger.info(f"Training completed with accuracy: {accuracy}")
span.set_attribute("accuracy", accuracy)
except Exception as e:
logger.error(f"Training failed: {e}")
span.record_exception(e)
raise
# Example usage
train_model([1, 2, 3, 4, 5])
Auditing Use Case: Tracking Model Predictions
-
Log each prediction request with:
- Model version
- Input features
- Prediction output
- Request timestamp
- User or request ID
-
Trace the request through preprocessing, model inference, and postprocessing.
Example log entry:
{
"timestamp": "2024-06-01T12:30:00Z",
"level": "INFO",
"component": "ModelServing",
"model_version": "v1.2.3",
"request_id": "req789",
"input_features": {"age": 35, "income": 70000},
"prediction": "approved",
"latency_ms": 45
}
Summary
- Implement structured, centralized logging with rich contextual metadata.
- Use distributed tracing to follow requests end-to-end across services.
- Leverage open-source tools like OpenTelemetry, Jaeger, and ELK stack.
- Correlate logs and traces for efficient debugging and auditing.
- Automate log retention and access controls to support compliance.
By integrating these logging and tracing practices, MLOps engineers can build transparent, reliable, and maintainable production ML systems.
8.3 Alerting and Incident Response Automation
In production MLOps systems, timely alerting and efficient incident response are critical to maintaining model reliability, minimizing downtime, and ensuring data integrity. Automated alerting systems help detect anomalies, performance degradation, or failures early, while incident response automation streamlines troubleshooting and remediation.
Key Concepts in Alerting and Incident Response Automation
- Alerting: The process of notifying the relevant stakeholders or systems when a predefined threshold or anomaly is detected.
- Incident Response: The coordinated approach to investigate, mitigate, and resolve issues impacting the system.
- Automation: Using tools and workflows to reduce manual intervention, accelerate response times, and enforce consistency.
Mind Map: Core Components of Alerting and Incident Response Automation
Best Practices for Alerting
-
Define Meaningful Alerts: Avoid alert fatigue by setting alerts only for actionable events. For example, alert on model accuracy dropping below a critical threshold rather than minor fluctuations.
-
Use Multi-Level Alerts: Differentiate between warnings and critical alerts to prioritize responses.
-
Incorporate Anomaly Detection: Use statistical or ML-based anomaly detection to catch subtle issues.
-
Integrate with Communication Tools: Ensure alerts reach the right teams promptly via preferred channels.
-
Test Alerts Regularly: Simulate incidents to verify alert delivery and response workflows.
Example: Setting Up Alerting with Prometheus and Alertmanager
-
Scenario: Monitor model latency and trigger alerts if the 95th percentile latency exceeds 200ms for more than 5 minutes.
-
Prometheus Rule:
groups:
- name: ml_model_latency.rules
rules:
- alert: HighModelLatency
expr: histogram_quantile(0.95, rate(model_request_latency_seconds_bucket[5m])) > 0.2
for: 5m
labels:
severity: critical
annotations:
summary: "Model latency is high"
description: "The 95th percentile latency has exceeded 200ms for over 5 minutes."
- Alertmanager Configuration:
Configure routing to send critical alerts to PagerDuty and warnings to Slack.
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'slack-notifications'
routes:
- match:
severity: critical
receiver: 'pagerduty'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#mlops-alerts'
send_resolved: true
- name: 'pagerduty'
pagerduty_configs:
- service_key: '<PAGERDUTY_SERVICE_KEY>'
send_resolved: true
Incident Response Automation
Automating incident response reduces mean time to resolution (MTTR) and ensures consistent handling of issues.
Mind Map: Incident Response Automation Workflow
Example: Automated Incident Response with PagerDuty and AWS Lambda
-
Scenario: Upon receiving a critical alert indicating model degradation, automatically trigger a Lambda function to rollback to the previous stable model version.
-
Workflow:
- Prometheus Alertmanager sends alert to PagerDuty.
- PagerDuty triggers an AWS Lambda function via webhook.
- Lambda function calls the MLOps platform API to rollback the model.
- Lambda sends confirmation back to PagerDuty.
- PagerDuty notifies the on-call engineer and updates the incident status.
-
Sample Lambda Pseudocode:
import requests
def lambda_handler(event, context):
# Extract alert info
alert = event['alert']
if alert['status'] == 'firing' and alert['labels']['alertname'] == 'ModelDegradation':
# Call MLOps API to rollback
response = requests.post(
'https://mlops-platform/api/models/rollback',
json={'model_name': alert['labels']['model_name'], 'version': 'previous'})
if response.status_code == 200:
return {'status': 'rollback_successful'}
else:
return {'status': 'rollback_failed', 'details': response.text}
return {'status': 'no_action'}
Summary
Automated alerting and incident response are foundational to reliable, scalable MLOps systems. By combining well-defined alert rules, multi-channel notifications, and automated remediation workflows, teams can rapidly detect and resolve production issues, minimizing impact on business outcomes.
Additional Resources
- Prometheus Alertmanager Documentation
- PagerDuty Automation Guide
- AWS Lambda Webhook Integrations
- Runbook Automation Best Practices
8.4 Practical Example: Implementing Observability with Prometheus and Grafana
Observability is a cornerstone of reliable and scalable MLOps systems. It enables teams to monitor model performance, infrastructure health, and quickly diagnose issues in production. In this section, we will walk through a practical example of implementing observability using Prometheus for metrics collection and Grafana for visualization.
Why Prometheus and Grafana?
- Prometheus is an open-source monitoring system that collects and stores metrics as time series data.
- Grafana is a powerful visualization tool that integrates seamlessly with Prometheus to create rich dashboards.
Together, they provide a robust observability stack for MLOps pipelines.
Step 1: Instrumenting Your ML System for Metrics Collection
To monitor your ML models and infrastructure, you need to expose relevant metrics. These can include:
- Model inference latency
- Request throughput
- Error rates
- Resource utilization (CPU, memory, GPU)
- Data drift indicators
Example: Instrumenting a Python Model Server with Prometheus Client
from prometheus_client import start_http_server, Summary, Counter
import random
import time
# Create metrics to track
REQUEST_TIME = Summary('inference_latency_seconds', 'Time spent processing inference')
REQUEST_COUNT = Counter('inference_requests_total', 'Total number of inference requests')
@REQUEST_TIME.time()
def process_request():
# Simulate inference latency
time.sleep(random.uniform(0.1, 0.5))
REQUEST_COUNT.inc()
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000)
while True:
process_request()
This example starts a Prometheus metrics server on port 8000 exposing two metrics: inference latency and request count.
Step 2: Configuring Prometheus to Scrape Metrics
Prometheus needs to be configured to scrape the metrics endpoint exposed by your ML service.
Example: prometheus.yml configuration snippet
scrape_configs:
- job_name: 'ml-model-server'
static_configs:
- targets: ['localhost:8000']
This tells Prometheus to scrape the metrics exposed on port 8000.
Step 3: Setting Up Grafana Dashboards
Once Prometheus is collecting metrics, Grafana can visualize them.
Example: Key Grafana Panels for MLOps Observability
- Inference Latency (Histogram/Line Chart)
- Request Rate (Counter over time)
- Error Rate (Percentage of failed requests)
- CPU and Memory Usage (from node exporters or cloud metrics)
Mind Map: Observability Stack Components
Step 4: Defining Alerts for Proactive Monitoring
Prometheus Alertmanager can be configured to send alerts based on metric thresholds.
Example: Alert Rule for High Inference Latency
groups:
- name: ml_model_alerts
rules:
- alert: HighInferenceLatency
expr: inference_latency_seconds_sum / inference_latency_seconds_count > 0.4
for: 5m
labels:
severity: warning
annotations:
summary: "Inference latency is above 400ms"
description: "The average inference latency has exceeded 400ms for more than 5 minutes."
This alert triggers if the average inference latency exceeds 400ms for 5 minutes.
Step 5: Integrating Observability into MLOps Pipelines
- Continuous Monitoring: Integrate metric collection into all stages of the pipeline (training, validation, deployment).
- Drift Detection: Monitor data distribution metrics and alert on drift.
- Resource Monitoring: Track GPU/CPU usage to optimize costs.
Mind Map: Observability Workflow in MLOps
Summary
Implementing observability with Prometheus and Grafana empowers MLOps teams to maintain robust, scalable, and reliable ML systems in production. By instrumenting your services, configuring metric scraping, building insightful dashboards, and setting up alerts, you create a feedback loop essential for continuous improvement and rapid incident response.
Additional Resources
- Prometheus Documentation
- Grafana Documentation
- Prometheus Python Client
- MLOps Observability Best Practices
This practical example serves as a foundation. You can extend it by integrating logs, traces, and advanced anomaly detection to achieve full-stack observability in your MLOps environment.
9. Security and Compliance in Scalable MLOps Systems
9.1 Securing Data Pipelines and Model Artifacts
Securing data pipelines and model artifacts is a critical aspect of building trustworthy and compliant MLOps systems. Data pipelines often handle sensitive information, and model artifacts represent intellectual property and can influence business decisions. Ensuring their security protects against data breaches, tampering, and unauthorized access.
Key Security Considerations in Data Pipelines
- Data Confidentiality: Prevent unauthorized access to sensitive data during ingestion, processing, and storage.
- Data Integrity: Ensure data is not altered or corrupted during transit or storage.
- Authentication & Authorization: Control who and what systems can access data and pipeline components.
- Auditability: Maintain logs and records of data access and pipeline operations for compliance and forensic analysis.
- Encryption: Use encryption at rest and in transit to protect data.
Securing Model Artifacts
- Version Control with Access Controls: Store model artifacts in secure registries with role-based access.
- Artifact Integrity: Use checksums or hashes to detect tampering.
- Secure Storage: Encrypt model files and restrict access.
- Provenance Tracking: Maintain metadata about model lineage and training data.
Mind Map: Securing Data Pipelines
Mind Map: Securing Model Artifacts
Best Practices with Examples
Encrypt Data in Transit and at Rest
Example: Use TLS for all data transfers between pipeline components. For instance, when ingesting data from a source to a data lake, enable HTTPS endpoints and encrypt data stored in cloud buckets using server-side encryption (SSE).
# AWS S3 bucket policy snippet enforcing encryption
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnforceEncryption",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::your-bucket-name/*",
"Condition": {
"StringNotEquals": {
"s3:x-amz-server-side-encryption": "AES256"
}
}
}
]
}
Implement Role-Based Access Control (RBAC) for Pipelines and Artifacts
Example: In Kubernetes-based pipelines, use RBAC policies to restrict who can deploy or modify pipeline components.
# Kubernetes RBAC example granting read-only access to pipeline namespace
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: ml-pipeline
name: pipeline-reader
rules:
- apiGroups: [""]
resources: ["pods", "services", "configmaps"]
verbs: ["get", "list", "watch"]
Use Model Registries with Access Controls
Example: MLflow Model Registry allows setting permissions on who can register, transition, or delete models.
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Register a model
model_uri = "runs:/1234567890abcdef/model"
model_name = "fraud-detection-model"
client.create_registered_model(model_name)
client.create_model_version(model_name, model_uri, run_id="1234567890abcdef")
# Set permissions (example, depends on deployment)
# Use your MLflow server's access control mechanisms
Validate Data Integrity with Checksums
Example: When ingesting files, compute SHA-256 hash and verify it after transfer.
import hashlib
def compute_sha256(file_path):
sha256_hash = hashlib.sha256()
with open(file_path,"rb") as f:
for byte_block in iter(lambda: f.read(4096),b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
# Usage
original_hash = compute_sha256('data_source.csv')
# After transfer
received_hash = compute_sha256('data_destination.csv')
assert original_hash == received_hash, "Data integrity check failed!"
Audit Logging and Monitoring
Example: Use centralized logging (e.g., ELK stack) to track pipeline operations and access to model artifacts.
# Example: Log pipeline execution events
kubectl logs ml-pipeline-run-12345 > pipeline_run_12345.log
# Configure alerts for unauthorized access attempts
Summary
Securing data pipelines and model artifacts requires a multi-layered approach combining encryption, access controls, integrity verification, and auditing. By following these best practices and leveraging tools like MLflow, Kubernetes RBAC, and encrypted cloud storage, MLOps engineers can build resilient and compliant production systems.
Additional Resources
- OWASP Secure Data Pipeline Guidelines
- MLflow Model Registry Documentation
- Kubernetes RBAC Documentation
- AWS S3 Encryption Best Practices
9.2 Access Control and Identity Management
Access control and identity management are foundational pillars for securing scalable MLOps systems. They ensure that only authorized users and services can access sensitive data, models, and infrastructure components, thereby reducing the risk of data breaches, unauthorized model manipulation, and compliance violations.
Key Concepts in Access Control and Identity Management
- Authentication: Verifying the identity of a user or service.
- Authorization: Granting or denying access rights to resources based on authenticated identity.
- Role-Based Access Control (RBAC): Assigning permissions to roles rather than individuals.
- Attribute-Based Access Control (ABAC): Access decisions based on attributes of users, resources, and environment.
- Identity Federation: Allowing users to authenticate across multiple systems using a single identity.
- Audit Logging: Recording access and actions for compliance and troubleshooting.
Mind Map: Core Components of Access Control and Identity Management
Best Practices for Access Control in MLOps
-
Implement Principle of Least Privilege: Grant users and services only the minimum permissions necessary to perform their tasks.
-
Use Role-Based Access Control (RBAC): Define clear roles such as Data Scientist, ML Engineer, DevOps, and assign permissions accordingly.
-
Enable Multi-Factor Authentication (MFA): Protect sensitive systems and dashboards with MFA to reduce risk of compromised credentials.
-
Secure Service-to-Service Communication: Use service accounts with scoped permissions and short-lived tokens.
-
Centralize Identity Management: Integrate with enterprise identity providers (e.g., LDAP, Active Directory, or cloud IAM) for unified access control.
-
Audit and Monitor Access: Continuously log and review access patterns to detect unauthorized activities.
Example 1: Implementing RBAC in Kubernetes for MLOps Pipelines
Kubernetes is widely used for orchestrating scalable MLOps pipelines. RBAC in Kubernetes controls access to cluster resources.
-
Scenario: Data scientists need read access to model training logs but no permission to modify deployments.
-
Steps:
- Define Roles with specific permissions.
- Bind users or groups to these roles.
# Role granting read access to pods and logs
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: ml-pipeline
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "watch", "list"]
# RoleBinding to assign role to data scientists group
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods-binding
namespace: ml-pipeline
subjects:
- kind: Group
name: data-scientists
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
This setup ensures data scientists can monitor logs without risking changes to deployments.
Mind Map: RBAC Implementation Workflow
Example 2: Identity Federation with OAuth2 and OpenID Connect (OIDC)
In large organizations, federated identity allows seamless access across multiple MLOps tools (e.g., MLflow, Kubeflow, Jenkins).
-
Scenario: Enable single sign-on (SSO) for ML engineers accessing Kubeflow and MLflow UI.
-
Approach: Use an identity provider (IdP) like Okta or Azure AD supporting OAuth2/OIDC.
-
Flow:
- User attempts to access Kubeflow UI.
- Redirected to IdP login page.
- Upon successful authentication, IdP issues a JWT token.
- Kubeflow verifies token and grants access based on claims.
-
Benefits:
- Centralized user management.
- Simplified credential handling.
- Improved security with MFA support.
Mind Map: Identity Federation Flow
Example 3: Securing Model Registry Access with Cloud IAM
Cloud platforms like AWS, GCP, and Azure provide IAM services to control access to model registries.
-
Scenario: Restrict model registry write access to ML engineers and read access to data scientists.
-
AWS Example: Using AWS IAM policies attached to user groups.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:DescribeModelPackage",
"sagemaker:ListModelPackages"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateModelPackage",
"sagemaker:UpdateModelPackage"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:PrincipalTag/Role": "ML_Engineer"
}
}
}
]
}
This policy allows all users to list and describe model packages but restricts creation and updates to users tagged as ML Engineers.
Summary
Access control and identity management are critical to protect scalable MLOps systems. By combining strong authentication, granular authorization (RBAC/ABAC), identity federation, and continuous auditing, organizations can secure their ML workflows effectively.
Integrating these practices with real-world tools like Kubernetes RBAC, OAuth2/OIDC, and cloud IAM services ensures robust security while maintaining usability and scalability.
Further Reading & Tools
- Kubernetes RBAC Documentation: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
- OAuth 2.0 and OpenID Connect: https://oauth.net/2/
- AWS IAM Best Practices: https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
- Kubeflow Authentication: https://www.kubeflow.org/docs/components/multi-tenancy/authentication/
- MLflow Authentication and Authorization: https://mlflow.org/docs/latest/security.html
9.3 Compliance with Data Privacy Regulations (GDPR, HIPAA)
Ensuring compliance with data privacy regulations is a critical aspect of designing and operating scalable MLOps systems. Regulations such as the General Data Protection Regulation (GDPR) in the EU and the Health Insurance Portability and Accountability Act (HIPAA) in the US impose strict requirements on how personal and sensitive data is collected, processed, stored, and shared. Failure to comply can lead to severe legal penalties, loss of customer trust, and operational disruptions.
Key Principles of GDPR and HIPAA Relevant to MLOps
- Data Minimization: Only collect and process data necessary for the model’s purpose.
- Purpose Limitation: Use data only for the specified, legitimate purposes.
- Data Subject Rights: Enable data subjects to access, correct, or delete their data.
- Data Security: Implement technical and organizational measures to protect data.
- Breach Notification: Procedures to detect, report, and investigate data breaches.
- Accountability and Documentation: Maintain records of data processing activities.
Mind Map: GDPR Compliance in MLOps
Mind Map: HIPAA Compliance in MLOps
Best Practices for Compliance in MLOps Pipelines
-
Data Anonymization and Pseudonymization
- Example: Before training a model on healthcare data, replace patient identifiers with pseudonyms or hash values to prevent direct identification.
- Tools: Use libraries like
ARXorFakerfor synthetic data generation and anonymization.
-
Consent Management and Data Subject Rights Automation
- Example: Implement automated workflows that track user consent status and automatically exclude data from training if consent is withdrawn.
- Use case: A financial institution uses a consent management platform integrated with their MLOps pipeline to ensure only authorized data is processed.
-
Secure Data Storage and Access Controls
- Example: Store datasets and model artifacts in encrypted storage buckets with role-based access control (RBAC).
- Cloud providers like AWS S3 with encryption and IAM policies or GCP Cloud Storage with IAM roles can be leveraged.
-
Auditability and Documentation
- Example: Maintain detailed logs of data processing steps, model training runs, and deployment activities to demonstrate compliance during audits.
- Tools: Use MLflow or custom logging integrated with centralized logging systems like ELK stack.
-
Data Breach Detection and Incident Response
- Example: Set up monitoring to detect unusual access patterns or data exfiltration attempts.
- Automate alerting and incident response workflows using tools like PagerDuty or AWS GuardDuty.
Example Scenario: GDPR-Compliant Customer Churn Prediction Model
- Context: A telecom company builds a churn prediction model using customer data.
- Compliance Steps:
- Collect explicit consent from customers before using their data.
- Anonymize personally identifiable information (PII) such as names and phone numbers.
- Store data encrypted with access restricted to the data science team.
- Implement a data subject rights portal allowing customers to view or delete their data.
- Log all data processing activities and model training runs.
- Regularly audit the system for compliance and update documentation.
Example Scenario: HIPAA-Compliant Medical Imaging Model
- Context: A healthcare provider develops an AI model to detect anomalies in medical images.
- Compliance Steps:
- Identify and classify all PHI in the dataset.
- Use pseudonymization to remove direct identifiers.
- Apply encryption for data at rest and in transit.
- Enforce strict access controls with multi-factor authentication.
- Sign Business Associate Agreements (BAAs) with all third-party vendors.
- Implement audit controls to track access and modifications.
- Prepare breach notification procedures aligned with HIPAA requirements.
Summary
Compliance with GDPR and HIPAA in scalable MLOps systems requires a combination of technical controls, process automation, and thorough documentation. By embedding privacy and security best practices into every stage of the model lifecycle—from data collection to deployment and monitoring—organizations can build trustworthy AI systems that respect user privacy and meet regulatory obligations.
9.4 Example: Implementing Role-Based Access Control in MLOps Platforms
Role-Based Access Control (RBAC) is a critical security practice in MLOps platforms to ensure that users have appropriate permissions to access data, models, and infrastructure components. Implementing RBAC helps protect sensitive information, maintain compliance, and reduce the risk of unauthorized actions.
What is RBAC?
RBAC is a method of regulating access to computer or network resources based on the roles of individual users within an organization. In MLOps, roles might include Data Scientist, ML Engineer, DevOps Engineer, and Business Analyst, each with different access needs.
Key Concepts of RBAC in MLOps
Mind Map: RBAC Key Concepts
Step-by-Step Example: Implementing RBAC in an MLOps Platform Using Kubernetes and MLflow
Define Roles and Permissions
| Role | Permissions | Description |
|---|---|---|
| Data Scientist | Read/Write datasets, Register models | Develop and register ML models |
| ML Engineer | Deploy models, Monitor deployments | Manage deployment and monitoring |
| DevOps Engineer | Manage infrastructure, Configure pipelines | Maintain platform and CI/CD pipelines |
| Business Analyst | Read model performance dashboards | Access insights without modifying models |
Configure Kubernetes RBAC
- Create Kubernetes Roles and RoleBindings to restrict access to namespaces, pods, and services.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: mlops
name: ml-engineer-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "watch", "create", "update", "delete"]
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: ml-engineer-binding
namespace: mlops
subjects:
- kind: User
name: [email protected]
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: ml-engineer-role
apiGroup: rbac.authorization.k8s.io
Implement MLflow Model Registry Access Controls
-
MLflow supports role-based permissions via integration with authentication providers.
-
Example: Using MLflow with OAuth and LDAP to restrict model registration and deployment.
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Example: Check if user has permission before registering a model
user_role = get_user_role() # Custom function
if user_role in ['Data Scientist', 'ML Engineer']:
client.create_registered_model("my_model")
else:
raise PermissionError("User does not have permission to register models.")
Secure Data Access
-
Use data access policies (e.g., Apache Ranger, AWS Lake Formation) to restrict dataset access.
-
Example: Data Scientist role granted read access to feature store, Business Analyst only to aggregated reports.
Enforce Access in CI/CD Pipelines
-
Integrate RBAC checks in pipeline orchestration tools like Airflow or Jenkins.
-
Example: Only ML Engineers can trigger deployment jobs.
# Airflow DAG snippet
from airflow.models import Variable
def check_user_permission(user):
allowed_roles = ['ML Engineer']
return user.role in allowed_roles
if not check_user_permission(current_user):
raise Exception("Unauthorized to deploy models")
Mind Map: RBAC Implementation Workflow
Best Practices for RBAC in MLOps
- Principle of Least Privilege: Assign users only the permissions they need.
- Role Granularity: Define roles granular enough to separate duties but not too complex.
- Audit Trails: Maintain logs of access and actions for compliance and troubleshooting.
- Automate Role Assignments: Use identity management systems to automate onboarding/offboarding.
- Regular Reviews: Periodically review roles and permissions to adapt to organizational changes.
Summary
Implementing RBAC in MLOps platforms is essential to secure the model lifecycle and data assets. By defining clear roles, configuring access controls in Kubernetes, MLflow, and data stores, and integrating these controls into CI/CD pipelines, organizations can build secure, scalable, and compliant MLOps systems.
This example demonstrated a practical approach combining Kubernetes RBAC, MLflow permissions, and pipeline enforcement, supported by mind maps to visualize the concepts and workflows.
10. Cost Optimization Strategies for Scalable MLOps
10.1 Resource Management and Efficient Compute Utilization
Efficient resource management is a cornerstone of scalable MLOps systems, directly impacting both performance and cost. Properly allocating compute, memory, and storage resources ensures that machine learning workloads run smoothly without unnecessary overhead or bottlenecks.
Key Concepts in Resource Management
- Resource Allocation: Assigning the right amount of CPU, GPU, memory, and storage to each stage of the ML pipeline.
- Resource Scheduling: Dynamically scheduling workloads based on priority, availability, and dependencies.
- Autoscaling: Automatically adjusting resources in response to workload demand.
- Resource Monitoring: Continuously tracking resource usage to identify inefficiencies and optimize allocation.
Mind Map: Resource Management Components
Best Practices for Efficient Compute Utilization
-
Right-sizing Compute Resources:
- Avoid over-provisioning by profiling workloads to understand their resource needs.
- Example: Profiling a TensorFlow training job to determine optimal GPU memory and CPU usage.
-
Leverage Spot Instances and Preemptible VMs:
- Use cost-effective compute options for non-critical or fault-tolerant workloads.
- Example: Running hyperparameter tuning jobs on AWS Spot Instances to reduce costs.
-
Implement Autoscaling Policies:
- Use Kubernetes Horizontal Pod Autoscaler (HPA) or custom autoscalers to scale pods based on CPU/GPU usage or custom metrics.
- Example: Autoscaling model inference pods based on request latency and throughput.
-
Use Batch Processing for Non-Real-Time Tasks:
- Schedule batch jobs during off-peak hours to optimize resource usage.
- Example: Nightly retraining pipelines that run on lower-cost compute nodes.
-
Monitor and Optimize Resource Utilization Continuously:
- Use monitoring tools like Prometheus and Grafana to visualize resource usage.
- Set alerts for underutilized or overutilized resources.
Mind Map: Efficient Compute Utilization Strategies
Example 1: Profiling and Right-sizing a Training Job
A machine learning engineer noticed that their model training job was consistently using only 30% of the allocated GPU memory and 40% of the CPU. By profiling the job using NVIDIA’s nvidia-smi and Linux top commands, they adjusted the Kubernetes pod resource requests and limits from 4 GPUs and 16 CPUs to 2 GPUs and 8 CPUs. This change reduced cloud costs by 50% without impacting training time.
Example 2: Autoscaling Model Serving Pods with Kubernetes HPA
An AI platform engineer deployed a model serving endpoint using TensorFlow Serving on Kubernetes. To handle variable traffic, they configured the Horizontal Pod Autoscaler to scale pods between 2 and 10 replicas based on CPU utilization:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: model-serving-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: model-serving-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
This setup ensured efficient compute utilization by scaling out during peak inference requests and scaling in during low traffic periods.
Example 3: Using Spot Instances for Hyperparameter Tuning
To reduce costs, a team running large-scale hyperparameter tuning jobs on AWS leveraged Spot Instances. They configured their training pipeline to checkpoint progress frequently and handle interruptions gracefully. When a Spot Instance was reclaimed, the job resumed on another instance without losing significant progress, resulting in a 70% cost reduction compared to on-demand instances.
Summary
Efficient resource management and compute utilization are vital for scalable MLOps systems. By right-sizing resources, leveraging cost-effective compute options, implementing autoscaling, and continuously monitoring usage, teams can optimize both performance and cost.
Additional Resources
- Kubernetes Horizontal Pod Autoscaler Documentation: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- NVIDIA Profiling Tools: https://developer.nvidia.com/nsight-systems
- AWS Spot Instances Best Practices: https://aws.amazon.com/ec2/spot/
- Prometheus Monitoring: https://prometheus.io/
- Grafana Visualization: https://grafana.com/
10.2 Spot Instances and Serverless Architectures
In the quest for cost optimization in scalable MLOps systems, leveraging spot instances and serverless architectures can significantly reduce compute expenses while maintaining flexibility and scalability. This section explores these two approaches, their benefits, challenges, and practical examples to help you integrate them effectively into your MLOps pipelines.
What are Spot Instances?
Spot instances are spare compute resources offered by cloud providers at a discounted rate compared to on-demand instances. These instances can be interrupted by the provider with little notice, making them ideal for fault-tolerant and flexible workloads.
Key Characteristics:
- Lower cost (up to 90% cheaper)
- Interruptible with short notice (typically 2 minutes)
- Suitable for batch jobs, training, and non-critical workloads
What are Serverless Architectures?
Serverless architectures abstract away server management, allowing you to run code or functions without provisioning or managing infrastructure. Billing is based on actual usage, which can lead to cost savings and easier scaling.
Key Characteristics:
- No server management
- Automatic scaling
- Pay-per-use pricing
- Ideal for event-driven workloads, inference, and lightweight tasks
Mind Map: Spot Instances in MLOps
Mind Map: Serverless Architectures in MLOps
Practical Examples
Example 1: Using Spot Instances for Model Training on AWS
Scenario: Training a deep learning model on a large dataset with TensorFlow.
Implementation:
- Use AWS EC2 Spot Instances to run distributed training jobs.
- Employ checkpointing to save model state periodically to S3.
- Use AWS Batch or Kubernetes with Karpenter to manage spot instance provisioning.
- Combine spot instances with on-demand instances to ensure baseline availability.
Benefits:
- Up to 70-90% cost reduction on compute.
- Efficient utilization of spare capacity.
Code Snippet (Checkpointing in TensorFlow):
import tensorflow as tf
checkpoint_dir = '/mnt/checkpoints/'
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_dir + 'ckpt-{epoch}',
save_weights_only=True,
save_freq='epoch')
model.fit(dataset, epochs=10, callbacks=[checkpoint_callback])
Example 2: Serverless Model Inference with AWS Lambda
Scenario: Deploy a lightweight image classification model for real-time inference.
Implementation:
- Package the model and inference code as an AWS Lambda function.
- Use AWS API Gateway to expose the Lambda function as a REST endpoint.
- Trigger inference on-demand with HTTP requests.
Benefits:
- No need to manage servers or scale infrastructure manually.
- Pay only for inference requests.
Considerations:
- Keep the model size small to reduce cold start latency.
- Use provisioned concurrency to mitigate cold starts if needed.
Example Lambda Handler (Python):
import json
import base64
from PIL import Image
import io
import torch
# Load model globally to reuse across invocations
model = torch.jit.load('model.pt')
model.eval()
def lambda_handler(event, context):
image_data = base64.b64decode(event['body'])
image = Image.open(io.BytesIO(image_data))
# Preprocess image and run inference
input_tensor = preprocess(image)
with torch.no_grad():
output = model(input_tensor)
prediction = postprocess(output)
return {
'statusCode': 200,
'body': json.dumps({'prediction': prediction})
}
Best Practices for Combining Spot Instances and Serverless Architectures
- Hybrid Pipelines: Use spot instances for heavy batch training and serverless functions for lightweight inference or preprocessing.
- Checkpointing & Fault Tolerance: Always implement checkpointing and design pipelines that can resume after interruptions.
- Cost Monitoring: Continuously monitor costs and adjust instance usage or function configurations accordingly.
- Automation: Use orchestration tools like Kubeflow Pipelines or AWS Step Functions to automate workflows that leverage both compute models.
Summary
Spot instances and serverless architectures offer complementary approaches to cost optimization in MLOps. Spot instances excel in cost-effective, large-scale training workloads with fault-tolerant designs, while serverless architectures provide scalable, event-driven compute for inference and lightweight tasks without infrastructure overhead. By understanding their strengths and limitations, and applying best practices with real-world examples, MLOps engineers can build highly cost-efficient and scalable production systems.
10.3 Monitoring and Controlling Cloud Spend
Managing cloud costs is a critical aspect of running scalable MLOps systems. Without proper monitoring and control, cloud expenses can quickly spiral out of control, especially when dealing with large-scale data processing, model training, and serving workloads. This section covers best practices, tools, and practical examples to help you keep your cloud spend in check.
Key Concepts in Cloud Cost Management
- Cost Visibility: Understanding where and how your cloud budget is being spent.
- Budgeting and Alerts: Setting budgets and receiving notifications when costs approach or exceed limits.
- Resource Optimization: Identifying and eliminating waste, such as idle resources or oversized instances.
- Automation: Using automated policies to shut down or scale resources based on usage.
Mind Map: Cloud Spend Monitoring and Control
Cost Visibility
Best Practice: Implement consistent tagging and labeling of all cloud resources related to your MLOps pipelines (e.g., data storage, compute instances, model serving endpoints). This enables granular cost tracking by project, team, or environment.
Example:
- Tag all Kubernetes clusters and nodes with labels such as
env:production,team:ml-engineering, andproject:model-training. - Use AWS Cost Explorer or Google Cloud Billing reports filtered by tags to identify the most expensive components.
Budgeting and Alerts
Best Practice: Define monthly or quarterly budgets for your MLOps workloads and configure alerts to notify stakeholders when spending approaches thresholds.
Example:
- In AWS, create a budget for your ML training account with a $10,000 monthly limit.
- Set up alerts to email the engineering team at 80%, 90%, and 100% of the budget.
- Use Google Cloud’s Budget and Alerts feature to trigger Pub/Sub notifications that can automate cost control actions.
Resource Optimization
Best Practice: Regularly analyze resource utilization metrics to identify underutilized or idle resources.
Example:
- Use AWS Compute Optimizer to get recommendations on downsizing EC2 instances used for model training.
- Detect idle GPU instances that have been running overnight without active jobs and schedule automatic shutdowns.
- Leverage spot instances for non-critical batch training jobs to reduce costs by up to 70%.
Mind Map: Resource Optimization Techniques
Automation for Cost Control
Best Practice: Automate cost-saving actions such as shutting down unused resources, scaling down during off-peak hours, and detecting anomalies.
Example:
- Implement Kubernetes Cluster Autoscaler to automatically scale down nodes when workloads decrease.
- Use AWS Lambda functions triggered by CloudWatch alarms to terminate idle EC2 instances.
- Integrate cost anomaly detection services (e.g., AWS Cost Anomaly Detection) with Slack notifications for immediate awareness.
Practical Example: Implementing Cloud Spend Monitoring in an MLOps Pipeline
Suppose you have an MLOps pipeline running on AWS with the following components:
- S3 buckets for data storage
- EC2 GPU instances for model training
- SageMaker endpoints for model serving
Steps to Monitor and Control Spend:
- Tagging: Apply tags like
Project:CustomerChurn,Environment:Prod, andOwner:MLTeamto all resources. - Cost Explorer: Use AWS Cost Explorer filtered by tags to visualize spending trends.
- Budgets: Set a $5,000 monthly budget for the project with alerts at 75%, 90%, and 100%.
- Rightsizing: Run AWS Compute Optimizer recommendations monthly to adjust instance sizes.
- Automation: Create Lambda functions to stop EC2 instances after 8 hours of inactivity.
- Spot Instances: Configure SageMaker training jobs to use spot instances with checkpointing enabled.
This approach ensures continuous visibility, proactive alerts, and automated cost-saving actions.
Summary
Monitoring and controlling cloud spend in scalable MLOps systems requires a combination of visibility, budgeting, optimization, and automation. By implementing tagging strategies, leveraging cloud-native tools, and automating cost controls, teams can maintain efficient and cost-effective production ML environments.
Additional Resources
- AWS Cost Management Tools
- Google Cloud Billing Documentation
- Kubecost: Kubernetes Cost Monitoring
- ML Ops Cost Optimization Strategies
10.4 Case Study: Cost-effective MLOps at Scale Using AWS and GCP
In this case study, we explore how a multinational company optimized their MLOps infrastructure costs while scaling their machine learning workloads using both AWS and Google Cloud Platform (GCP). The company faced challenges related to unpredictable workloads, expensive on-demand compute, and inefficient resource utilization.
Background
- The company runs multiple ML models for real-time fraud detection, customer segmentation, and recommendation systems.
- Workloads vary significantly during the day and across regions.
- Initial infrastructure was costly due to over-provisioning and lack of automation.
Objectives
- Reduce cloud infrastructure costs without compromising performance.
- Automate scaling and resource management.
- Implement multi-cloud strategies to leverage best pricing and services.
Approach Overview
AWS Cost Optimization Strategies
Spot Instances for Training
- Used Amazon EC2 Spot Instances for non-critical batch training jobs.
- Leveraged SageMaker Managed Spot Training to automatically handle interruptions.
Example:
import sagemaker
from sagemaker.estimator import Estimator
estimator = Estimator(
image_uri='123456789012.dkr.ecr.us-west-2.amazonaws.com/my-training-image:latest',
role='SageMakerRole',
instance_count=1,
instance_type='ml.c5.xlarge',
use_spot_instances=True,
max_run=3600,
max_wait=7200
)
estimator.fit('s3://my-bucket/training-data/')
This approach reduced training costs by up to 70%.
S3 Lifecycle Policies
- Implemented lifecycle policies to transition older model artifacts and logs to cheaper storage classes (e.g., S3 Glacier).
Example:
{
"Rules": [
{
"ID": "MoveToGlacierAfter30Days",
"Filter": {"Prefix": "model-artifacts/"},
"Status": "Enabled",
"Transitions": [
{
"Days": 30,
"StorageClass": "GLACIER"
}
]
}
]
}
Lambda for Automation
- Automated start/stop of development and staging environments using AWS Lambda and CloudWatch Events to avoid idle resource costs.
GCP Cost Optimization Strategies
Preemptible VMs for Batch Jobs
- Used GCP Preemptible VMs for batch model training and hyperparameter tuning.
- Integrated with Vertex AI Pipelines to manage job restarts on preemption.
Example:
trainingJob:
workerPoolSpecs:
- machineSpec:
machineType: n1-standard-4
preemptible: true
replicaCount: 1
BigQuery Storage Optimization
- Partitioned and clustered datasets to reduce query costs.
- Used table expiration policies to delete stale data automatically.
Example:
CREATE TABLE dataset.events_partitioned
PARTITION BY DATE(event_date)
CLUSTER BY user_id AS
SELECT * FROM dataset.events_raw;
Cloud Functions for Event-Driven Automation
- Automated cleanup of temporary storage and triggered model retraining only on data changes.
Multi-Cloud Strategy
- Distributed workloads based on cost and latency considerations.
- Replicated critical datasets between AWS S3 and GCP Cloud Storage using Apache Airflow DAGs.
Automation and Monitoring
- Implemented CI/CD pipelines with Jenkins and GitHub Actions to automate deployments.
- Configured auto-scaling groups and Kubernetes Horizontal Pod Autoscalers.
- Set up cost alerts using AWS Budgets and GCP Billing Alerts.
Example Jenkinsfile snippet:
pipeline {
agent any
stages {
stage('Deploy Model') {
steps {
sh 'kubectl apply -f deployment.yaml'
}
}
}
}
Results
| Metric | Before Optimization | After Optimization | Improvement |
|---|---|---|---|
| Monthly Cloud Spend (USD) | $120,000 | $65,000 | ~46% Cost Reduction |
| Training Job Completion Time | 3 hours | 3.5 hours | Slight increase due to spot/preemptible usage |
| Model Deployment Frequency | Weekly | Daily | Increased agility |
Key Takeaways
- Leveraging spot/preemptible instances significantly reduces compute costs.
- Automating environment lifecycle management avoids paying for idle resources.
- Multi-cloud strategies allow leveraging best-of-breed services and pricing.
- Continuous monitoring and alerts are essential to prevent cost overruns.
This case study demonstrates that with thoughtful architecture and automation, scalable MLOps systems can be both performant and cost-efficient on AWS and GCP.
11. Advanced Topics and Emerging Trends
11.1 Leveraging AutoML in Scalable MLOps Pipelines
Automated Machine Learning (AutoML) has emerged as a powerful approach to accelerate and democratize the development of machine learning models by automating repetitive and complex tasks such as feature engineering, model selection, and hyperparameter tuning. Integrating AutoML into scalable MLOps pipelines can significantly improve productivity, reduce time-to-market, and maintain consistent model quality at scale.
Why Use AutoML in Scalable MLOps?
- Speed and Efficiency: Automates time-consuming tasks, enabling faster experimentation and deployment.
- Standardization: Ensures consistent application of best practices across teams.
- Accessibility: Enables non-experts to build competitive models.
- Scalability: Easily integrates with distributed pipelines to handle large datasets and multiple projects.
Core Components of AutoML in MLOps Pipelines
Integrating AutoML into Scalable MLOps Pipelines
- Data Ingestion & Preprocessing: Use automated data validation and transformation tools to prepare data for AutoML.
- AutoML Model Search: Trigger AutoML jobs that explore multiple algorithms and hyperparameters in parallel using distributed compute resources.
- Experiment Tracking: Log all AutoML runs with metadata, metrics, and artifacts for reproducibility.
- Model Validation & Selection: Automatically select the best-performing model based on predefined criteria.
- Deployment Automation: Package and deploy the selected model using CI/CD pipelines.
- Monitoring & Retraining: Continuously monitor model performance and trigger AutoML retraining workflows when drift is detected.
Example: Using Google Cloud AutoML in an MLOps Pipeline
-
Scenario: A retail company wants to build a scalable image classification model for product categorization.
-
Pipeline Steps:
- Data ingestion from cloud storage.
- Automated data labeling and augmentation.
- Launch Google Cloud AutoML Vision training jobs with distributed compute.
- Track experiments and model metrics with Vertex AI Metadata.
- Deploy best model to Vertex AI Endpoint.
- Monitor model predictions and trigger retraining using Cloud Functions and Pub/Sub.
Example: Auto-sklearn in a Kubernetes-based MLOps Pipeline
-
Scenario: A financial institution automates credit risk modeling using Auto-sklearn integrated into Kubeflow Pipelines.
-
Pipeline Highlights:
- Data preprocessing component using Apache Beam.
- Auto-sklearn component runs hyperparameter optimization on distributed nodes.
- Model evaluation component selects best model.
- Model registry integration for versioning.
- Deployment to KFServing with autoscaling.
Best Practices for Leveraging AutoML in Scalable MLOps
- Define Clear Objectives: Specify metrics and constraints upfront to guide AutoML optimization.
- Automate Data Validation: Ensure data quality before feeding into AutoML to avoid garbage-in garbage-out.
- Use Experiment Tracking Tools: Maintain transparency and reproducibility of AutoML runs.
- Incorporate Explainability: Integrate interpretability tools to understand AutoML model decisions.
- Combine Human Expertise: Use AutoML outputs as candidates for expert review and refinement.
- Plan for Retraining: Automate retraining triggers based on monitoring insights.
Summary
Leveraging AutoML within scalable MLOps pipelines empowers teams to build robust, high-quality models faster and at scale. By automating key stages of the model lifecycle and integrating with orchestration, monitoring, and deployment tools, organizations can achieve efficient and reliable production ML systems.
References & Tools
- Google Cloud AutoML
- Auto-sklearn
- Kubeflow Pipelines
- MLflow
- Vertex AI
- KFServing
11.2 Incorporating Federated Learning and Edge Deployment
Introduction
Federated Learning (FL) and Edge Deployment represent cutting-edge approaches to building scalable, privacy-preserving, and efficient machine learning systems. By distributing model training and inference closer to data sources, these techniques reduce latency, enhance data privacy, and enable ML in resource-constrained environments.
What is Federated Learning?
Federated Learning is a decentralized ML approach where multiple edge devices collaboratively train a shared global model while keeping their data locally. This approach mitigates data privacy risks and reduces the need for centralized data storage.
Mind Map: Federated Learning Overview
Edge Deployment Explained
Edge Deployment refers to running ML models directly on edge devices such as smartphones, IoT sensors, or embedded systems. This reduces reliance on cloud infrastructure and enables real-time inference.
Mind Map: Edge Deployment Essentials
Integrating Federated Learning with Edge Deployment
Combining FL and edge deployment allows training models collaboratively across devices while performing inference locally. This synergy is ideal for applications requiring privacy, scalability, and low latency.
Mind Map: Integration of FL and Edge Deployment
Best Practices and Examples
Privacy-Preserving Collaborative Learning
- Practice: Use secure aggregation techniques such as homomorphic encryption or differential privacy to protect model updates.
- Example: Google’s Gboard keyboard uses federated learning to improve next-word prediction without uploading user text data.
Handling Non-IID Data
- Practice: Implement personalized federated learning approaches that adapt the global model to local data distributions.
- Example: In healthcare, hospitals train a shared model on diverse patient data while customizing it locally to their patient demographics.
Efficient Communication
- Practice: Compress model updates using techniques like sparsification or quantization to reduce bandwidth.
- Example: TensorFlow Federated supports update compression to optimize communication between clients and server.
Model Optimization for Edge Devices
- Practice: Apply model compression methods such as pruning and quantization to fit models within edge device constraints.
- Example: Deploying a quantized MobileNet model on Raspberry Pi for real-time image classification.
Orchestration and Monitoring
- Practice: Use MLOps pipelines that support federated workflows and edge deployment monitoring.
- Example: NVIDIA Clara Deploy framework enables federated learning orchestration in medical imaging with edge inference.
Practical Example: Federated Learning with Edge Deployment Using Flower Framework
Flower is an open-source framework for building federated learning systems.
Step-by-step:
- Define local training logic on edge devices (e.g., smartphones).
- Set up a central server to aggregate model updates.
- Deploy lightweight models optimized for edge inference.
- Implement secure communication between clients and server.
# Simplified client training example
import flwr as fl
def train(model, data):
# Local training logic
model.fit(data)
return model.get_weights()
class FlowerClient(fl.client.NumPyClient):
def get_parameters(self):
return model.get_weights()
def fit(self, parameters, config):
model.set_weights(parameters)
train(model, local_data)
return model.get_weights(), len(local_data), {}
def evaluate(self, parameters, config):
model.set_weights(parameters)
loss, accuracy = model.evaluate(test_data)
return loss, len(test_data), {"accuracy": accuracy}
fl.client.start_numpy_client(server_address="localhost:8080", client=FlowerClient())
Summary
Incorporating federated learning and edge deployment into scalable MLOps systems enables privacy-aware, low-latency, and efficient ML solutions. By following best practices such as secure aggregation, model optimization, and robust orchestration, engineers can build resilient production systems that leverage the power of distributed intelligence.
Further Reading and Tools
- Google Federated Learning: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
- TensorFlow Federated: https://www.tensorflow.org/federated
- Flower Framework: https://flower.dev/
- NVIDIA Clara Deploy: https://developer.nvidia.com/clara-deploy-sdk
- PyTorch Mobile: https://pytorch.org/mobile/home/
11.3 Using Explainable AI for Continuous Model Improvement
Explainable AI (XAI) has become a cornerstone in modern MLOps pipelines, especially when models are deployed in production environments where trust, transparency, and continuous improvement are critical. By integrating explainability techniques, teams can better understand model decisions, identify weaknesses, and iteratively improve models based on actionable insights.
What is Explainable AI?
Explainable AI refers to a set of methods and tools that help interpret and understand the decisions made by machine learning models. Unlike black-box models, XAI provides insights into why a model made a certain prediction, which features influenced the outcome, and how changes in input affect results.
Why Use Explainable AI for Continuous Model Improvement?
- Trust & Transparency: Helps stakeholders trust model predictions.
- Error Diagnosis: Identifies patterns in mispredictions.
- Bias Detection: Reveals potential fairness issues.
- Feature Importance: Guides feature engineering and selection.
- Model Refinement: Provides feedback loops for retraining.
Mind Map: Explainable AI in Continuous Model Improvement
Key Explainability Techniques and How They Aid Improvement
-
SHAP (SHapley Additive exPlanations)
- Provides local and global feature importance.
- Example: In a credit scoring model, SHAP reveals that “income” and “debt-to-income ratio” are the most influential features. If the model underperforms for a certain income bracket, this insight can trigger targeted data augmentation or feature engineering.
-
LIME (Local Interpretable Model-agnostic Explanations)
- Explains individual predictions by approximating the model locally with an interpretable model.
- Example: For a fraud detection model, LIME explains why a particular transaction was flagged, helping analysts identify false positives and refine model thresholds.
-
Integrated Gradients
- Used primarily with deep learning models to attribute prediction to input features.
- Example: In image classification, integrated gradients highlight which pixels influenced the decision, guiding data augmentation strategies.
-
Counterfactual Explanations
- Shows how minimal changes to input can alter the prediction.
- Example: In loan approval, counterfactuals can show that increasing income by a small amount changes the decision from reject to approve, suggesting actionable insights for customers and model adjustments.
Example Workflow: Using SHAP for Continuous Model Improvement
- Deploy model with SHAP integration: Collect SHAP values for predictions in production.
- Monitor feature importance drift: Detect changes in which features influence predictions over time.
- Analyze mispredictions: Use SHAP values on incorrect predictions to identify patterns.
- Identify data gaps: If certain feature values consistently cause errors, collect more data or engineer new features.
- Retrain model: Incorporate new data and insights.
- Validate improvements: Use explainability to confirm model behavior aligns with expectations.
Mind Map: SHAP-Driven Continuous Improvement Workflow
Practical Example: Improving a Customer Churn Model
- Scenario: A telecom company deploys a churn prediction model.
- Step 1: Use SHAP to explain individual churn predictions.
- Step 2: Identify that “customer tenure” and “monthly charges” are key drivers.
- Step 3: Notice that for customers with tenure < 3 months, the model performs poorly.
- Step 4: Collect more data on new customers and engineer features like “number of support calls in first month.”
- Step 5: Retrain the model and use SHAP again to verify improved explanations and accuracy.
Integrating Explainability into MLOps Pipelines
- Embed explainability tools (e.g., SHAP, LIME) into prediction pipelines.
- Automate generation and storage of explanation reports alongside predictions.
- Use dashboards to visualize feature importance and drift over time.
- Trigger alerts when explainability metrics indicate unusual model behavior.
Mind Map: Explainability in MLOps Pipeline
Summary
Using Explainable AI for continuous model improvement empowers ML engineers and AI platform engineers to maintain robust, fair, and trustworthy models in production. By systematically integrating explainability methods into MLOps workflows, teams can diagnose issues faster, reduce bias, and iteratively enhance model performance with clear, actionable insights.
11.4 Future Directions: MLOps with Reinforcement Learning and AI Governance
As MLOps continues to evolve, two critical frontiers are emerging that promise to reshape how machine learning models are developed, deployed, and governed: Reinforcement Learning (RL) integration into MLOps pipelines and the increasing importance of AI Governance frameworks. This section explores these future directions with detailed explanations, mind maps, and practical examples.
Integrating Reinforcement Learning into MLOps
Reinforcement Learning (RL) differs from traditional supervised learning by learning optimal policies through interaction with an environment, making it highly suitable for dynamic, sequential decision-making problems. Incorporating RL into MLOps pipelines introduces unique challenges and opportunities.
Key Considerations for RL in MLOps:
- Environment Management: Simulated or real environments must be integrated and versioned.
- Policy Versioning: RL agents (policies) require careful version control due to continuous learning.
- Reward Signal Monitoring: Tracking reward trends to detect training anomalies.
- Exploration vs Exploitation Balance: Automated tuning of exploration parameters.
- Safety Constraints: Ensuring policies do not violate operational constraints.
Mind Map: RL Integration in MLOps
Example: Automated RL Pipeline for Dynamic Pricing
An online retailer implements an RL agent to optimize product prices dynamically based on demand, competitor pricing, and inventory levels. The MLOps pipeline includes:
- Environment: A simulator mimicking customer behavior and market conditions.
- Training Pipeline: Automated retraining triggered by shifts in market data.
- Policy Registry: Versioned policies stored with metadata.
- Monitoring: Real-time reward tracking and alerting on performance degradation.
- Deployment: Canary deployments with rollback if safety thresholds are breached.
This setup ensures the RL model adapts while maintaining business constraints.
AI Governance in MLOps
AI Governance encompasses policies, processes, and controls to ensure AI systems are ethical, transparent, accountable, and compliant with regulations.
Core Components of AI Governance:
- Model Transparency: Explainability and interpretability of model decisions.
- Fairness and Bias Mitigation: Detecting and correcting biases.
- Auditability: Maintaining logs and traceability for compliance.
- Security and Privacy: Protecting sensitive data and model IP.
- Regulatory Compliance: GDPR, HIPAA, and emerging AI-specific laws.
Mind Map: AI Governance Framework in MLOps
Example: Implementing AI Governance with Explainability and Auditing
A financial institution deploys credit scoring models and integrates AI governance by:
- Using SHAP (SHapley Additive exPlanations) to provide transparent feature attributions for each decision.
- Logging all model inputs, outputs, and decision explanations in an immutable audit trail.
- Running automated bias detection tests on demographic groups monthly.
- Enforcing role-based access controls on model artifacts and data.
This governance framework ensures regulatory compliance and builds trust with stakeholders.
Synergies Between RL and AI Governance in MLOps
Combining RL with AI Governance introduces nuanced challenges:
- Safe RL: Incorporating constraints and ethical considerations into reward functions.
- Explainability of RL Policies: Developing interpretable policies for stakeholder trust.
- Continuous Compliance: Automated checks during continuous RL training and deployment.
Mind Map: RL and AI Governance Intersection
Example: Safe RL for Autonomous Systems
An autonomous drone delivery service uses RL for navigation policies but integrates AI governance by:
- Embedding no-fly zones and safety constraints directly into the reward function.
- Generating interpretable policy summaries for regulators.
- Continuously monitoring policy adherence to safety rules with automated alerts.
This approach balances innovation with responsibility.
Summary
The future of MLOps lies in embracing advanced learning paradigms like Reinforcement Learning while embedding robust AI Governance frameworks. Together, they enable scalable, adaptive, and trustworthy AI systems that meet evolving business and societal demands.
Further Reading & Resources
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction.
- Google Cloud AI Governance Framework: https://cloud.google.com/ai-governance
- OpenAI Safety Gym: https://openai.com/research/safety-gym
- SHAP Documentation: https://shap.readthedocs.io/
- Safe Reinforcement Learning Survey: https://arxiv.org/abs/1908.08796
12. Conclusion and Best Practice Summary
12.1 Recap of Scalable MLOps System Design Principles
In this section, we revisit the foundational principles that enable the design of scalable, robust, and efficient MLOps systems. These principles ensure that machine learning models can be developed, deployed, and maintained reliably at scale, supporting continuous innovation and business value.
Key Principles of Scalable MLOps System Design
Mind Map: Scalable MLOps System Design
Mind Map: Scalable MLOps System Design
Practical Examples Illustrating These Principles
Modularity & Microservices
Example: An e-commerce company decomposes its MLOps pipeline into separate microservices: data ingestion service, feature engineering service, model training service, and model serving service. Each service scales independently based on load. For example, during sales events, the serving service autoscale to handle increased prediction requests without affecting training.
Automation & CI/CD Pipelines
Example: Using GitHub Actions and Jenkins, a team automates the retraining pipeline triggered by new data arrival. The pipeline runs unit tests on data and code, trains models, validates performance against baseline, and automatically deploys the model if it passes all checks.
Data Management & Feature Engineering
Example: A fintech startup implements Feast as a feature store to centralize feature definitions and enable consistent feature serving for both batch training and online inference, reducing feature discrepancies and improving model accuracy.
Model Versioning & Registry
Example: MLflow Model Registry is used to track multiple versions of a fraud detection model. When a new model version underperforms in production, the team rolls back to the previous stable version seamlessly.
Monitoring & Observability
Example: A healthcare AI platform integrates Prometheus and Grafana dashboards to monitor model latency, accuracy, and data drift. Alerts notify engineers when performance degrades, enabling proactive remediation.
Scalable Infrastructure
Example: A media company deploys models on Kubernetes clusters with KFServing, enabling autoscaling based on request volume and seamless rollout of new model versions with zero downtime.
Security & Compliance
Example: A government agency enforces role-based access control (RBAC) in its MLOps platform, ensuring only authorized personnel can access sensitive patient data and models, maintaining HIPAA compliance.
Cost Optimization
Example: A startup uses spot instances on AWS for non-critical batch training jobs, reducing compute costs by 70% while maintaining reliability through checkpointing and job retries.
By internalizing these principles and applying them through practical tools and workflows, machine learning teams can build MLOps systems that not only scale with demand but also maintain reliability, security, and cost-effectiveness in production environments.
12.2 Summary of Automated Model Lifecycle Management Techniques
Automated Model Lifecycle Management (MLM) is a critical component in ensuring that machine learning models remain reliable, up-to-date, and performant throughout their production lifespan. This section summarizes key techniques and best practices for automating the model lifecycle, supported by mind maps and practical examples.
Key Techniques in Automated Model Lifecycle Management
-
Model Versioning and Registry
- Track different iterations of models systematically.
- Maintain metadata including training data, hyperparameters, performance metrics.
- Enable reproducibility and rollback.
-
Continuous Integration and Continuous Deployment (CI/CD)
- Automate testing, validation, and deployment of models.
- Integrate with code repositories and data pipelines.
-
Automated Model Validation and Testing
- Implement validation gates to check model quality.
- Include performance, fairness, and explainability checks.
-
Model Monitoring and Drift Detection
- Continuously monitor model predictions and input data.
- Detect data distribution shifts and performance degradation.
-
Model Promotion and Rollback Automation
- Automate promotion of models from staging to production.
- Enable quick rollback in case of failures.
-
Workflow Orchestration and Pipeline Automation
- Use tools like Airflow, Kubeflow Pipelines to automate end-to-end workflows.
Mind Map: Automated Model Lifecycle Management Overview
Example 1: Model Versioning and Registry with MLflow
MLflow Model Registry allows teams to register models, track versions, and manage lifecycle stages such as “Staging”, “Production”, and “Archived”.
import mlflow
# Log a model
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model")
mlflow.log_metric("accuracy", accuracy)
# Register model
result = mlflow.register_model(
"runs:/<run_id>/model", "MyModel"
)
# Transition model stage
client = mlflow.tracking.MlflowClient()
client.transition_model_version_stage(
name="MyModel",
version=result.version,
stage="Production"
)
This automation ensures models are versioned and promoted systematically.
Mind Map: CI/CD Pipeline for Model Deployment
Example 2: Automated Model Validation with Seldon Core
Seldon Core supports validation webhooks that automatically run tests before model deployment.
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: my-model
spec:
predictors:
- name: default
replicas: 1
graph:
name: classifier
implementation: SKLEARN_SERVER
modelUri: gs://models/my-model
componentSpecs:
- spec:
containers:
- name: classifier
image: seldonio/sklearnserver:1.10.0
validation:
webhook:
url: http://validation-service/validate
The webhook runs automated validation checks, preventing poor models from reaching production.
Mind Map: Monitoring and Drift Detection
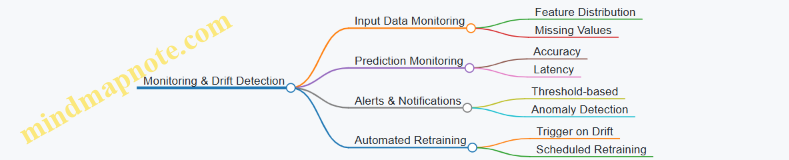
Example 3: Automated Retraining Trigger with Airflow
Using Airflow to automate retraining when drift is detected:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def detect_drift():
# Logic to detect data drift
drift_detected = check_data_drift()
if drift_detected:
return 'retrain_model'
else:
return 'skip_retraining'
def retrain_model():
# Retraining logic
train_new_model()
with DAG('model_lifecycle', start_date=datetime(2024, 1, 1), schedule_interval='@daily') as dag:
drift_check = PythonOperator(
task_id='detect_drift',
python_callable=detect_drift
)
retrain = PythonOperator(
task_id='retrain_model',
python_callable=retrain_model
)
drift_check >> retrain
This pipeline automates model retraining only when necessary, optimizing resource use.
Final Thoughts
Automated Model Lifecycle Management combines several interrelated techniques to ensure models are robust, compliant, and performant in production. By integrating versioning, CI/CD, validation, monitoring, and orchestration, teams can build scalable and maintainable MLOps systems.
For further reading and hands-on examples, explore tools like MLflow, Kubeflow Pipelines, Seldon Core, and Apache Airflow.
12.3 Checklist for Building Robust Production MLOps Pipelines
Building a robust production MLOps pipeline requires careful attention to multiple facets of the machine learning lifecycle, infrastructure, and operational best practices. Below is a comprehensive checklist organized into key focus areas, accompanied by mind maps and practical examples to guide implementation.
Data Management
- Ensure reliable and scalable data ingestion pipelines
- Implement data validation and quality checks
- Use feature stores for consistent feature engineering and serving
- Maintain data versioning and lineage tracking
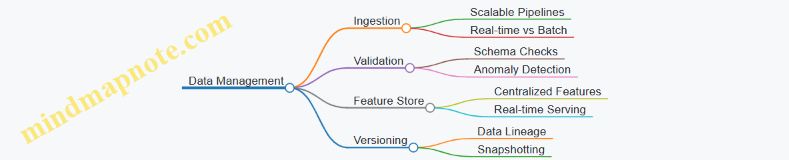
Example: Implement Feast as a feature store to centralize feature definitions and enable real-time feature serving, ensuring consistency between training and inference.
Model Training & Experimentation
- Automate training pipelines with reproducible environments
- Track experiments, hyperparameters, and metrics systematically
- Use automated hyperparameter tuning tools
- Enable continuous training triggered by new data or performance degradation
Example: Use MLflow to log experiments and parameters, combined with TFX pipelines for automated retraining when new labeled data arrives.
Model Validation & Testing
- Implement automated validation gates before deployment
- Check for model performance, fairness, and explainability
- Detect data and concept drift post-deployment
- Use shadow deployments or canary testing for safe rollout
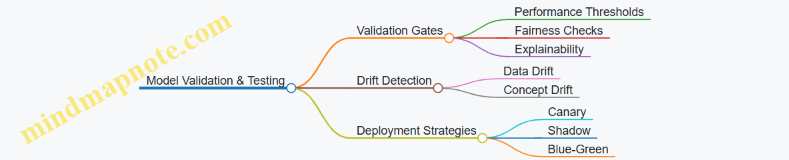
Example: Integrate Seldon Core’s validation framework to enforce performance and fairness checks automatically before promoting models to production.
Model Deployment & Serving
- Containerize models for portability
- Use orchestration platforms (Kubernetes, KFServing) for scalability
- Implement autoscaling and load balancing
- Support multiple deployment modes (batch, online, streaming)
Example: Deploy models using KFServing on Kubernetes with autoscaling enabled to handle variable traffic efficiently.
Model Lifecycle Management
- Maintain a centralized model registry with version control
- Automate promotion, rollback, and retirement of models
- Track model metadata, lineage, and audit logs
- Integrate lifecycle steps into CI/CD pipelines
Example: Use MLflow Model Registry integrated with Airflow pipelines to automate model promotion and rollback based on validation results.
Monitoring & Observability
- Monitor model performance metrics and system health continuously
- Log inference requests and responses for auditing
- Detect anomalies and trigger alerts automatically
- Visualize metrics with dashboards for real-time insights
Example: Implement Prometheus and Grafana dashboards to monitor latency, throughput, and prediction accuracy, combined with alerting on drift detection.
Security & Compliance
- Secure data pipelines and model artifacts with encryption
- Implement role-based access control (RBAC) and identity management
- Ensure compliance with GDPR, HIPAA, and other regulations
- Maintain audit trails for data and model access
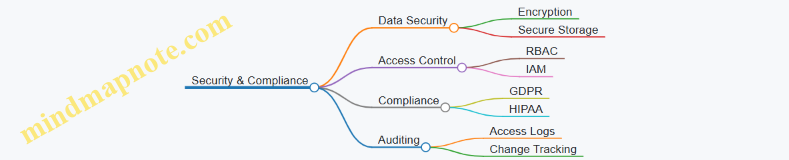
Example: Apply RBAC in Kubeflow pipelines and encrypt model artifacts at rest using cloud provider key management services.
Cost Optimization
- Monitor resource utilization and optimize compute usage
- Use spot instances or serverless architectures where appropriate
- Automate scaling down of idle resources
- Track and analyze cloud spend regularly
Example: Leverage AWS Spot Instances for batch training jobs and implement autoscaling policies to minimize idle resource costs.
Summary
This checklist serves as a practical guide to ensure your production MLOps pipelines are robust, scalable, and maintainable. By following these best practices and leveraging the examples and mind maps, Machine Learning and AI Platform Engineers can build systems that not only deploy models efficiently but also maintain their performance and compliance over time.
12.4 Final Thoughts and Resources for Further Learning
As we conclude this comprehensive exploration of scalable MLOps systems design and automated model lifecycle management, it’s essential to reflect on the key takeaways and provide you with valuable resources to deepen your expertise.
Final Thoughts
Building and maintaining scalable MLOps systems is a continuous journey that blends software engineering, data science, and operational excellence. The integration of automation, monitoring, and robust lifecycle management ensures that machine learning models deliver consistent value in production environments.
Key principles to remember:
-
Automation is your ally: Automate repetitive tasks such as data ingestion, model training, validation, deployment, and monitoring to reduce human error and accelerate iteration.
-
Design for scalability: Architect your pipelines and infrastructure to handle increasing data volumes and model complexity without performance degradation.
-
Emphasize observability: Continuous monitoring of model performance, data drift, and system health is critical to detect issues early and maintain trust.
-
Implement robust governance: Model versioning, access control, and compliance with regulations safeguard your system and data.
-
Iterate and improve: Use feedback loops from monitoring and explainability tools to refine models and pipelines continuously.
Mind Map: Core Pillars of Scalable MLOps
Mind Map: Automated Model Lifecycle Management
Practical Examples for Further Exploration
-
MLflow for Experiment Tracking and Model Registry
- Explore MLflow’s capabilities to track experiments, log parameters, and manage model versions.
- MLflow Documentation
-
Kubeflow Pipelines for Orchestrating Scalable Workflows
- Build reusable, scalable pipelines for training and deployment.
- Kubeflow Pipelines Guide
-
Feast Feature Store for Consistent Feature Management
- Manage and serve features at scale with real-time and batch capabilities.
- Feast Documentation
-
Seldon Core for Model Deployment and Monitoring
- Deploy models with built-in monitoring, explainability, and A/B testing.
- Seldon Core Docs
-
Prometheus and Grafana for Observability
- Set up metrics collection and visualization dashboards to monitor system health.
- Prometheus, Grafana
Recommended Books and Courses
- “Machine Learning Engineering” by Andriy Burkov — Covers practical MLOps and engineering principles.
- “Building Machine Learning Powered Applications” by Emmanuel Ameisen — Focuses on productionizing ML.
- Coursera: MLOps Specialization by DeepLearning.AI — Comprehensive course on MLOps best practices.
- Google Cloud: MLOps Fundamentals — Hands-on labs and tutorials for scalable MLOps.
Communities and Forums
- MLOps Community (https://mlops.community/) — Connect with practitioners and attend webinars.
- KubeFlow Slack and GitHub — Collaborate on open-source MLOps projects.
- Stack Overflow and Reddit r/MachineLearning — Ask questions and share knowledge.
By continuously learning and applying these best practices, you will be well-equipped to design, deploy, and maintain scalable MLOps systems that drive impactful AI solutions in production.
Happy MLOps journey!