Comprehensive Guide to Distributed Systems Architecture and Cloud Native Application Design
1. Introduction to Distributed Systems and Cloud Native Concepts
1.1 Understanding Distributed Systems: Definitions and Core Principles
What is a Distributed System?
A distributed system is a collection of independent computers that appear to users as a single coherent system. These computers communicate and coordinate their actions by passing messages to achieve a common goal.
Key characteristics:
- Multiple independent nodes
- Communication over a network
- No shared memory
- Coordination and cooperation
Core Principles of Distributed Systems
Transparency
- Access Transparency: Users access resources without knowing their location.
- Location Transparency: The system hides the physical location of resources.
- Replication Transparency: Users are unaware of data replication.
Scalability
- Ability to handle growth in workload by adding resources.
- Horizontal scaling (adding nodes) is preferred over vertical scaling.
Fault Tolerance
- System continues to operate despite failures of some components.
- Techniques: Replication, redundancy, failover mechanisms.
Concurrency
- Multiple processes operate simultaneously.
- Requires synchronization to avoid conflicts.
Consistency
- Ensures all nodes see the same data at the same time or eventually.
- Models: Strong consistency, eventual consistency.
Openness
- System supports interoperability and extensibility.
Security
- Protecting data and communication from unauthorized access.
Mind Map: Core Principles of Distributed Systems
Example 1: Google Search Engine
- Distributed System: Multiple data centers and servers worldwide.
- Transparency: Users don’t know which server handles their query.
- Scalability: Can handle billions of queries daily by adding servers.
- Fault Tolerance: If one data center fails, others take over.
Example 2: Online Banking System
- Concurrency: Multiple transactions processed simultaneously.
- Consistency: Account balances must be accurate and consistent.
- Security: Strong authentication and encrypted communication.
Mind Map: Example - Online Banking System Principles
Why Distributed Systems?
- Resource Sharing: Share hardware, software, and data.
- Reliability: Redundancy reduces single points of failure.
- Scalability: Easily add resources to meet demand.
- Flexibility: Heterogeneous systems can work together.
Challenges in Distributed Systems
- Network failures and latency
- Partial failures
- Data consistency
- Security across nodes
Summary
Distributed systems are foundational to modern cloud computing and large-scale applications. Understanding their core principles helps architects and engineers design robust, scalable, and efficient systems.
Additional Mind Map: Distributed Systems Overview
1.2 Cloud Native Applications: What They Are and Why They Matter
Cloud Native Applications represent a modern approach to designing, building, and running applications that fully leverage the advantages of cloud computing. Unlike traditional monolithic applications, cloud native apps are designed to be scalable, resilient, manageable, and observable in dynamic cloud environments.
What Are Cloud Native Applications?
Cloud native applications are software systems that are:
- Containerized: Packaged with all dependencies to run consistently across environments.
- Microservices-based: Decomposed into small, independently deployable services.
- Dynamically orchestrated: Managed by platforms like Kubernetes for scaling and healing.
- Declaratively managed: Infrastructure and configuration are defined as code.
These characteristics enable applications to be agile, scalable, and resilient.
Why Do Cloud Native Applications Matter?
- Scalability: Automatically scale up/down based on demand.
- Resilience: Recover quickly from failures with self-healing mechanisms.
- Faster Time-to-Market: Continuous delivery pipelines enable rapid updates.
- Cost Efficiency: Pay-as-you-go cloud resources optimize costs.
- Portability: Run consistently across different cloud providers or on-premises.
Mind Map: Core Characteristics of Cloud Native Applications
Example 1: Containerization with Docker
Scenario: You have a Node.js web application that you want to deploy consistently across development, staging, and production.
Best Practice: Use Docker to containerize the application.
# Dockerfile example
FROM node:16-alpine
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
CMD ["node", "server.js"]
This ensures the app runs identically regardless of the underlying environment.
Mind Map: Benefits of Microservices in Cloud Native Apps
Example 2: Microservices Decomposition
Scenario: An e-commerce platform splits its monolithic app into microservices such as User Service, Product Catalog Service, and Order Service.
Best Practice: Each microservice has its own database and API.
- User Service manages user profiles and authentication.
- Product Catalog Service handles product listings.
- Order Service processes orders and payments.
This separation allows teams to develop, deploy, and scale services independently.
Mind Map: Orchestration and Automation
Example 3: Kubernetes Deployment
Scenario: Deploying a microservice with automatic scaling and self-healing.
Best Practice: Use Kubernetes Deployment and Horizontal Pod Autoscaler (HPA).
apiVersion: apps/v1
kind: Deployment
metadata:
name: product-catalog
spec:
replicas: 3
selector:
matchLabels:
app: product-catalog
template:
metadata:
labels:
app: product-catalog
spec:
containers:
- name: product-catalog
image: myregistry/product-catalog:v1
ports:
- containerPort: 8080
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: product-catalog-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: product-catalog
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
This setup ensures the service scales based on CPU usage and recovers from pod failures automatically.
Summary
Cloud native applications are essential for modern software development, enabling organizations to build scalable, resilient, and manageable systems that thrive in cloud environments. By embracing containerization, microservices, orchestration, and automation, teams can accelerate innovation while maintaining operational excellence.
Understanding these concepts and applying best practices with real-world examples will empower cloud architects and senior engineers to design future-proof distributed systems.
1.3 Key Challenges in Distributed Systems and Cloud Native Design
Designing distributed systems and cloud native applications involves navigating a complex landscape of technical and operational challenges. Understanding these challenges early on helps architects and engineers build resilient, scalable, and maintainable systems.
Network Reliability and Latency
Distributed systems rely heavily on network communication, which is inherently unreliable and subject to latency. Network partitions, dropped packets, and variable latency can cause partial failures or inconsistent states.
Example: A microservices-based e-commerce platform where the payment service depends on the inventory service. If network latency spikes or the inventory service becomes unreachable, payment processing can fail or produce inconsistent results.
Mind Map:
Data Consistency and State Management
Maintaining data consistency across distributed nodes is difficult due to asynchronous communication and concurrent updates.
Example: In a distributed banking system, ensuring that a withdrawal transaction does not overdraft an account when multiple requests arrive simultaneously is critical.
Mind Map:
Fault Tolerance and Recovery
Failures are inevitable in distributed systems—hardware faults, software bugs, or network issues can cause partial or total system failures.
Example: A cloud native video streaming service must handle server crashes gracefully to avoid interrupting user playback.
Mind Map:
Scalability and Load Balancing
Designing systems that scale horizontally to handle increasing load without degradation is a core challenge.
Example: A social media platform needs to scale its user feed service to millions of concurrent users while maintaining low latency.
Mind Map:
Security and Compliance
Distributed and cloud native systems expose a larger attack surface and must comply with regulatory requirements.
Example: A healthcare application handling patient data must ensure HIPAA compliance and secure data transmission between microservices.
Mind Map:
Observability and Debugging
Monitoring distributed systems is complex due to their asynchronous and multi-component nature.
Example: Debugging a latency spike in a distributed payment processing system requires tracing requests across multiple microservices.
Mind Map:
Deployment and Continuous Delivery Complexity
Deploying updates without downtime or regressions is challenging when multiple interdependent services are involved.
Example: Rolling out a new feature in a multi-service cloud native app requires coordinated deployments and rollback strategies.
Mind Map:
Summary
Distributed systems and cloud native design require careful consideration of network reliability, data consistency, fault tolerance, scalability, security, observability, and deployment strategies. Each challenge can be addressed through established best practices and patterns, often demonstrated through real-world examples and iterative improvements.
1.4 Overview of Best Practices with Real-World Examples
Distributed systems and cloud native application design require a set of well-established best practices to ensure scalability, reliability, and maintainability. This section provides an integrated overview of these best practices, supported by real-world examples and mind maps to visualize the concepts.
Best Practices Mind Map
Scalability
Best Practice: Favor horizontal scaling over vertical scaling to handle increased load.
Example: Netflix uses microservices deployed on AWS with auto-scaling groups that automatically add or remove instances based on demand, enabling seamless horizontal scaling.
Mind Map Snippet:
Resilience & Fault Tolerance
Best Practice: Implement circuit breakers and retries with exponential backoff to prevent cascading failures.
Example: Amazon’s DynamoDB SDK uses retries with exponential backoff to handle transient errors gracefully.
Mind Map Snippet:
Consistency & Data Management
Best Practice: Choose the appropriate consistency model based on use case; use eventual consistency for high availability and strong consistency where accuracy is critical.
Example: Cassandra uses eventual consistency to achieve high availability, while Google Spanner provides strong consistency for global transactions.
Mind Map Snippet:
Communication
Best Practice: Prefer asynchronous communication via message queues for decoupling services and improving fault tolerance.
Example: Uber uses Kafka as an event streaming platform to decouple microservices and handle high throughput asynchronously.
Mind Map Snippet:
Security
Best Practice: Use mutual TLS for secure inter-service communication and centralized IAM for access control.
Example: Google’s Istio service mesh enforces mutual TLS between microservices, ensuring encrypted and authenticated communication.
Mind Map Snippet:
Deployment
Best Practice: Implement CI/CD pipelines with blue-green or canary deployments to minimize downtime and reduce risk.
Example: Etsy uses canary deployments to gradually roll out new features and monitor their impact before full release.
Mind Map Snippet:
Observability
Best Practice: Centralize logs, implement distributed tracing, and set up metrics with alerting to quickly detect and diagnose issues.
Example: LinkedIn uses Apache Kafka for centralized logging and OpenTracing for distributed tracing, enabling rapid troubleshooting.
Mind Map Snippet:
Integrated Example: E-Commerce Platform
Imagine designing a cloud native e-commerce platform:
- Scalability: Use stateless microservices behind a load balancer with auto-scaling groups.
- Resilience: Implement circuit breakers on payment service calls to external gateways.
- Consistency: Use eventual consistency for product catalog updates, strong consistency for order transactions.
- Communication: Employ asynchronous messaging for order processing workflows.
- Security: Secure APIs with OAuth 2.0 and mutual TLS between internal services.
- Deployment: Use CI/CD pipelines with blue-green deployments to release new features.
- Observability: Centralize logs in ELK stack, trace requests with Jaeger, and monitor key metrics with Prometheus.
This cohesive approach ensures a robust, scalable, and maintainable system.
By weaving these best practices with concrete examples and visual mind maps, architects and engineers can better grasp the foundational principles needed to design effective distributed systems and cloud native applications.
1.5 Setting Up Your Environment for Cloud Native Development
Setting up a robust and efficient environment is the foundational step toward successful cloud native application development. This section guides you through the essential tools, configurations, and workflows to establish a productive cloud native development environment.
Key Components of a Cloud Native Development Environment
Installing and Configuring Containerization Tools
Docker is the de facto containerization platform. Start by installing Docker Desktop (available for Windows, macOS, and Linux). After installation, verify by running:
docker --version
Example: Build and run a simple “Hello World” container:
docker run hello-world
This confirms Docker is working correctly.
Best Practice: Use multi-stage Dockerfiles to optimize image size and security.
Setting Up Local Kubernetes Clusters
For local orchestration, tools like Minikube and Kind are popular.
Example: Installing Minikube and starting a cluster:
minikube start
kubectl get nodes
This sets up a single-node Kubernetes cluster locally.
Best Practice: Use kubectl plugins and aliases to speed up cluster management.
Integrated Development Environments (IDEs) and Extensions
Choose an IDE that supports cloud native development:
- VS Code with extensions like Kubernetes, Docker, and YAML support.
- IntelliJ IDEA with Cloud Code plugin.
Example: Installing Kubernetes extension in VS Code enables you to view cluster resources and deploy manifests directly from the editor.
Configuring Continuous Integration/Continuous Deployment (CI/CD)
Set up pipelines to automate build, test, and deployment processes.
Example: A simple GitHub Actions workflow to build and push a Docker image:
name: CI
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Build Docker image
run: docker build -t myapp:${{ github.sha }} .
- name: Log in to Docker Hub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: Push Docker image
run: docker push myapp:${{ github.sha }}
Best Practice: Store secrets securely using GitHub Secrets or equivalent.
Infrastructure as Code (IaC) Setup
Automate provisioning of cloud resources using tools like Terraform or CloudFormation.
Example: A basic Terraform configuration to provision an AWS EC2 instance:
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
}
Run:
terraform init
terraform apply
Best Practice: Use remote state backends like S3 with locking to collaborate safely.
Setting Up Monitoring and Logging Locally
Use Prometheus and Grafana for monitoring, and EFK (Elasticsearch, Fluentd, Kibana) or Loki for logging.
Example: Deploy Prometheus and Grafana on your local Kubernetes cluster using Helm:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus prometheus-community/prometheus
helm install grafana grafana/grafana
Access Grafana dashboard to visualize metrics.
Managing Secrets and Configuration
Use tools like HashiCorp Vault, Kubernetes Secrets, or cloud provider secret managers.
Example: Creating a Kubernetes secret:
kubectl create secret generic db-password --from-literal=password='S3cr3tP@ssw0rd'
Reference secrets in your pods securely.
Best Practice: Avoid hardcoding secrets in code or config files.
Summary Checklist
- Install Docker and verify
- Set up local Kubernetes cluster (Minikube/Kind)
- Configure IDE with cloud native extensions
- Create CI/CD pipelines with secure secret management
- Define infrastructure as code with Terraform or CloudFormation
- Deploy monitoring and logging tools locally
- Implement secrets management best practices
By following these steps and best practices, you create a solid foundation for developing, testing, and deploying cloud native applications efficiently and securely.
2. Distributed Systems Architecture Fundamentals
2.1 Architectural Styles: Client-Server, Peer-to-Peer, and Microservices
Distributed systems are built upon various architectural styles that define how components interact, communicate, and collaborate. Understanding these styles is crucial for designing scalable, maintainable, and resilient systems. This section explores three foundational architectural styles: Client-Server, Peer-to-Peer (P2P), and Microservices. Each style is explained with easy-to-understand examples and accompanied by mind maps to visualize their structure.
Client-Server Architecture
Definition: Client-Server architecture is a model where multiple clients request and receive services from a centralized server. The server hosts, manages, and provides resources or services, while clients initiate requests.
Key Characteristics:
- Centralized control and management
- Clients are typically thin and rely on the server
- Easier to secure and maintain due to centralized resources
Example: A web application where browsers (clients) request web pages from a web server.
Best Practices:
- Use load balancers to distribute client requests across multiple servers for scalability.
- Implement caching on the client or server to reduce latency.
- Secure communication channels using TLS.
Mind Map:
Example Scenario: Imagine an online bookstore where users browse and purchase books. The client (browser or mobile app) sends requests to the server to fetch book details, add items to the cart, and process payments. The server handles these requests, manages inventory, and processes transactions.
Peer-to-Peer (P2P) Architecture
Definition: In P2P architecture, each node (peer) acts both as a client and a server, sharing resources directly without a centralized server.
Key Characteristics:
- Decentralized control
- Each peer can initiate or respond to requests
- Highly scalable and fault-tolerant
Example: File-sharing networks like BitTorrent, where users share pieces of files directly with each other.
Best Practices:
- Implement robust discovery mechanisms for peers.
- Use distributed hash tables (DHT) for efficient resource lookup.
- Design for eventual consistency and conflict resolution.
Mind Map:
Example Scenario: Consider a decentralized chat application where users connect directly to each other to exchange messages without relying on a central server. Each user’s device acts as a peer, sending and receiving messages, sharing presence information, and storing chat history locally.
Microservices Architecture
Definition: Microservices architecture decomposes an application into small, loosely coupled, independently deployable services, each responsible for a specific business capability.
Key Characteristics:
- Services communicate over lightweight protocols (e.g., HTTP/REST, gRPC)
- Independent deployment and scaling
- Decentralized data management
Example: An e-commerce platform where separate microservices handle user authentication, product catalog, order processing, and payment.
Best Practices:
- Design services around business capabilities.
- Use API gateways to manage and route requests.
- Implement service discovery and health checks.
- Employ centralized logging and distributed tracing for observability.
Mind Map:
Example Scenario: A ride-sharing app where the user service manages profiles, the ride service handles trip requests, the payment service processes transactions, and the notification service sends alerts. Each microservice can be developed, deployed, and scaled independently.
Summary Table of Architectural Styles
| Aspect | Client-Server | Peer-to-Peer (P2P) | Microservices |
|---|---|---|---|
| Control | Centralized | Decentralized | Decentralized |
| Scalability | Moderate (depends on server) | High | High |
| Fault Tolerance | Single point of failure risk | High (distributed) | High (service isolation) |
| Communication Model | Request-Response | Direct peer-to-peer | API calls / Messaging |
| Data Management | Centralized | Distributed | Decentralized (per service) |
| Deployment Complexity | Low to Moderate | Moderate | High |
Integrated Example: Designing a Social Media Platform
- Client-Server: The mobile app (client) requests user profiles and posts from a centralized server.
- Peer-to-Peer: Users share media files directly with friends to reduce server load.
- Microservices: Separate services manage user profiles, posts, notifications, and media storage, each deployed independently.
This hybrid approach leverages the strengths of each architectural style to build a scalable and resilient system.
By understanding these architectural styles, cloud solutions architects and senior software engineers can select and tailor the right approach for their distributed systems and cloud native applications, ensuring optimal performance, scalability, and maintainability.
2.2 Designing for Scalability: Horizontal vs Vertical Scaling
Scalability is a fundamental aspect of distributed systems architecture. It determines how well your system can handle increasing loads by adding resources. There are two primary approaches to scaling: vertical scaling and horizontal scaling. Understanding their differences, advantages, limitations, and best use cases is critical for designing robust, efficient, and cost-effective distributed systems.
What is Vertical Scaling?
Vertical scaling, also known as “scaling up,” involves adding more resources (CPU, RAM, storage) to a single machine or server.
Example: Upgrading a database server from 8 CPU cores and 32GB RAM to 32 CPU cores and 128GB RAM.
Advantages of Vertical Scaling:
- Simplicity: Easier to implement since it involves upgrading existing hardware or VM specs.
- No need to modify application architecture significantly.
- Useful for applications that are not designed for distributed workloads.
Limitations:
- Physical limits: There is a maximum capacity a single machine can reach.
- Single point of failure: If the machine goes down, the entire system is affected.
- Cost: High-end hardware can be expensive.
What is Horizontal Scaling?
Horizontal scaling, or “scaling out,” means adding more machines or instances to distribute the load.
Example: Adding more web server instances behind a load balancer to handle increased traffic.
Advantages of Horizontal Scaling:
- Virtually unlimited scalability by adding more nodes.
- Improved fault tolerance and availability.
- Cost-effective: Can use commodity hardware or cloud instances.
Limitations:
- Increased complexity in architecture and management.
- Requires applications to be designed for distributed environments.
- Data consistency and synchronization challenges.
Mind Map: Vertical vs Horizontal Scaling
When to Use Vertical Scaling?
- When the application is monolithic and not designed for distributed operation.
- When the workload requires strong consistency and low latency that is difficult to achieve in distributed setups.
- When scaling out is cost-prohibitive or operationally complex.
Example: A legacy ERP system running on a single powerful server.
When to Use Horizontal Scaling?
- When the application is designed as microservices or stateless components.
- When high availability and fault tolerance are critical.
- When workload is highly variable and needs elastic scaling.
Example: A cloud-native e-commerce platform with multiple web servers and replicated databases.
Practical Example: Scaling a Web Application
Scenario: You have a web application experiencing increased traffic.
-
Vertical Scaling Approach: Upgrade the existing web server VM from 4 CPUs and 8GB RAM to 16 CPUs and 64GB RAM.
- Pros: Quick upgrade, no code changes.
- Cons: Limited by max VM size, downtime during upgrade.
-
Horizontal Scaling Approach: Add more identical web server instances behind a load balancer.
- Pros: Can handle more traffic by adding instances, zero downtime deployments.
- Cons: Requires session management (e.g., sticky sessions or external session store), load balancer setup.
Best Practices for Designing Scalability
- Design for horizontal scaling first: Cloud-native applications should be stateless where possible to enable easy horizontal scaling.
- Use load balancers: Distribute traffic evenly across instances.
- Implement health checks and auto-scaling: Automatically add or remove instances based on load.
- Monitor resource utilization: Use metrics to decide when to scale vertically or horizontally.
- Combine both approaches: Sometimes a hybrid approach works best, e.g., scale vertically to a point, then scale horizontally.
Mind Map: Best Practices for Scalability Design
Summary
| Aspect | Vertical Scaling | Horizontal Scaling |
|---|---|---|
| Approach | Increase resources on one node | Add more nodes/instances |
| Complexity | Low | High |
| Fault Tolerance | Low (single point of failure) | High (distributed nodes) |
| Scalability Limits | Hardware limits | Practically unlimited |
| Cost | High for top-end hardware | Cost-effective with commodity nodes |
| Use Cases | Legacy apps, databases | Cloud-native, microservices |
Designing for scalability requires understanding your application’s architecture, workload characteristics, and operational constraints. By carefully choosing between vertical and horizontal scaling — or combining both — you can build systems that gracefully handle growth and maintain performance.
2.3 Fault Tolerance and Resilience Patterns with Practical Use Cases
Fault tolerance and resilience are critical pillars in designing distributed systems. These systems must gracefully handle failures — whether from hardware, network, or software — to maintain availability and reliability.
Understanding Fault Tolerance and Resilience
- Fault Tolerance: The ability of a system to continue operating properly in the event of the failure of some of its components.
- Resilience: The system’s capacity to recover quickly from difficulties and adapt to changing conditions.
Both concepts overlap but resilience often emphasizes recovery and adaptation, while fault tolerance focuses on continued operation despite faults.
Common Fault Tolerance and Resilience Patterns
Fault Tolerance and Resilience Patterns Mind Map
Retry Pattern
Retries help recover from transient faults like network glitches or temporary service unavailability.
Best Practice: Use exponential backoff with jitter to avoid overwhelming the system.
Example:
import time
import random
def retry_operation(operation, retries=5):
delay = 1
for attempt in range(retries):
try:
return operation()
except TransientError:
time.sleep(delay + random.uniform(0, 0.5))
delay *= 2
raise Exception("Operation failed after retries")
Circuit Breaker Pattern
Prevents a system from repeatedly trying an operation likely to fail, allowing it to recover.
States:
- Closed: Normal operation
- Open: Fail fast, reject requests
- Half-Open: Test if service has recovered
Example: Using Netflix Hystrix or Resilience4j in Java.
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("myCircuitBreaker");
Supplier<String> decoratedSupplier = CircuitBreaker.decorateSupplier(circuitBreaker, () -> remoteCall());
Try<String> result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback response");
Bulkhead Pattern
Isolates failures by partitioning resources so one failing component doesn’t bring down others.
Example: Thread pools per service or limiting concurrent calls.
# Kubernetes resource limits example for bulkhead
apiVersion: v1
kind: Pod
metadata:
name: service-a
spec:
containers:
- name: app
image: service-a:latest
resources:
limits:
cpu: "500m"
memory: "256Mi"
requests:
cpu: "250m"
memory: "128Mi"
Timeout Pattern
Avoids waiting indefinitely for an operation that may never complete.
Example: Setting HTTP client timeouts.
client := http.Client{
Timeout: 5 * time.Second,
}
resp, err := client.Get("https://example.com")
Failover
Automatically switching to a standby system when the primary fails.
Example: DNS failover or active-passive database clusters.
Graceful Degradation
Instead of complete failure, the system offers reduced functionality.
Example: A video streaming service lowering video quality during high load.
Health Checks & Self-Healing
Systems monitor their components and restart or replace unhealthy parts.
Example: Kubernetes liveness and readiness probes.
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
Idempotency
Ensures that retrying an operation won’t cause unintended effects.
Example: Using unique request IDs in APIs to detect duplicates.
Practical Use Case: Resilient Payment Processing Microservice
- Scenario: A payment service calls an external payment gateway.
- Challenges: Network failures, gateway downtime, high latency.
Applied Patterns:
- Retry with exponential backoff for transient errors.
- Circuit breaker to stop calling the gateway when it’s down.
- Timeout to avoid hanging requests.
- Bulkhead by isolating payment processing threads.
- Idempotency key to avoid double charges.
Example Flow:
flowchart TD
A[Receive Payment Request] --> B[Check Idempotency Key]
B -- Exists --> C[Return Previous Result]
B -- New --> D[Call Payment Gateway]
D -->|Success| E[Store Payment Confirmation]
D -->|Failure| F[Retry with Backoff]
F -->|Max Retries Exceeded| G[Circuit Breaker Opens]
G --> H[Return Failure to Client]
E --> I[Return Success to Client]
Summary
Implementing fault tolerance and resilience patterns is essential for building robust distributed systems. Combining these patterns thoughtfully, tailored to your system’s needs, ensures high availability and a better user experience even in the face of failures.
2.4 Consistency Models: Strong, Eventual, and Causal Consistency Explained
Distributed systems face a fundamental challenge: how to keep data consistent across multiple nodes or replicas, especially when network partitions or failures occur. Different consistency models provide varying guarantees about the visibility and ordering of updates.
Overview of Consistency Models
Strong Consistency
Definition: Strong consistency ensures that once a write completes, any subsequent read will see that write or a later one. This is often called linearizability.
Example:
Imagine a banking system where you transfer $100 from Account A to Account B. After the transfer completes, any read of Account A’s balance must reflect the deduction immediately.
Best Practice: Use strong consistency when correctness is critical and stale data cannot be tolerated.
Implementation Example:
- Distributed Locking: Use consensus protocols like Paxos or Raft to coordinate writes.
- Databases: Google Spanner provides strong consistency across global replicas.
Eventual Consistency
Definition: Eventual consistency guarantees that if no new updates are made to a given data item, eventually all replicas will converge to the same value. Temporary inconsistencies are allowed.
Example:
Consider a social media platform where a user posts a new status. Some friends might see the new post immediately, while others might see it after a delay due to replication lag.
Best Practice: Use eventual consistency when availability and partition tolerance are prioritized over immediate consistency.
Implementation Example:
- Amazon DynamoDB: Uses eventual consistency by default for faster reads.
- Caching Layers: CDN caches may serve stale content temporarily.
Causal Consistency
Definition: Causal consistency ensures that causally related operations are seen by all nodes in the same order, while concurrent operations may be seen in different orders.
Example:
In a collaborative document editing app, if User A writes a sentence and User B edits that sentence, all users must see User A’s write before User B’s edit. However, unrelated edits can be seen in any order.
Best Practice: Use causal consistency when preserving the cause-effect relationship is important but strong consistency is too costly.
Implementation Example:
- Vector Clocks: Track dependencies between operations.
- COPS (Clusters of Order-Preserving Servers): A system that provides causal consistency for key-value stores.
Summary Table
| Consistency Model | Guarantees | Latency | Availability | Use Cases |
|---|---|---|---|---|
| Strong Consistency | Reads see latest write immediately | Higher | Lower during partitions | Banking, Inventory |
| Eventual Consistency | Replicas converge eventually | Low | High | Social media, DNS |
| Causal Consistency | Preserves causal order | Moderate | Moderate | Collaborative apps, Messaging |
Practical Example: Shopping Cart Service
-
Strong Consistency: When a user adds an item to their cart, any subsequent read immediately reflects the addition. Useful if you want to prevent overselling.
-
Eventual Consistency: Updates to the cart may take time to propagate. The user might see an older version temporarily, but the system prioritizes availability.
-
Causal Consistency: If a user adds an item and then removes it, all replicas see the add before the remove, preserving the logical order.
Conclusion
Choosing the right consistency model depends on your application’s requirements for correctness, availability, and latency. Understanding these models and their trade-offs is essential for designing robust distributed systems.
Further Reading
- Designing Data-Intensive Applications by Martin Kleppmann
- CAP Theorem Explained
- Google Spanner Paper
- Amazon Dynamo Paper
2.5 Data Partitioning and Replication Strategies with Example Scenarios
Introduction
Data partitioning and replication are fundamental techniques in distributed systems to achieve scalability, availability, and fault tolerance. Properly designed partitioning and replication strategies ensure that data is efficiently distributed across nodes and remains accessible even in the event of failures.
Data Partitioning (Sharding)
Data partitioning, often called sharding, involves splitting a large dataset into smaller, more manageable pieces called partitions or shards. Each shard is stored on a different node or server.
Why Partition Data?
- Scalability: Distribute load across multiple servers.
- Performance: Reduce query latency by limiting data scanned.
- Manageability: Easier to maintain smaller datasets.
Common Partitioning Strategies
Mind Map: Data Partitioning Strategies
-
Range-based Partitioning
- Data is partitioned based on ranges of a key.
- Example: User IDs 1-1000 on shard 1, 1001-2000 on shard 2.
- Use Case: Time-series data or ordered data.
-
Hash-based Partitioning
- A hash function is applied to a key to determine the shard.
- Example:
shard = hash(user_id) % number_of_shards - Use Case: Uniform distribution, avoids hotspots.
-
List-based Partitioning
- Data is partitioned by explicitly listing key values per shard.
- Example: Country codes assigned to shards.
- Use Case: When data naturally groups by categories.
-
Vertical Partitioning
- Splitting a table by columns instead of rows.
- Example: User profile info on one shard, user activity logs on another.
-
Directory-based Partitioning
- A lookup service maintains a map of keys to shards.
- Use Case: Flexible but adds lookup overhead.
Example: Hash-based Partitioning
Suppose an e-commerce platform stores orders and wants to distribute them across 4 database shards.
# Simple hash-based shard calculation
def get_shard(order_id):
return hash(order_id) % 4
order_id = 123456
shard = get_shard(order_id) # e.g., shard 0, 1, 2, or 3
This ensures orders are evenly distributed, preventing any single shard from becoming a bottleneck.
Data Replication
Replication involves copying data across multiple nodes to improve availability and fault tolerance.
Benefits of Replication
- High Availability: Failover if a node goes down.
- Load Balancing: Read requests can be distributed.
- Disaster Recovery: Data durability in case of failures.
Replication Strategies
Mind Map: Data Replication Strategies
-
Synchronous Replication
- Writes are confirmed only after all replicas acknowledge.
- Guarantees strong consistency.
- Tradeoff: Higher write latency.
-
Asynchronous Replication
- Writes are confirmed immediately; replicas update later.
- Lower latency but eventual consistency.
-
Leader-Follower Replication
- One node (leader) handles writes; followers replicate data.
- Followers serve read requests.
-
Multi-Master Replication
- Multiple nodes accept writes.
- Conflict resolution mechanisms needed.
Example: Leader-Follower Replication in a Social Media App
- The leader node handles all user post creations.
- Followers replicate posts and serve read requests for timelines.
- If the leader fails, an election process promotes a follower to leader.
Combining Partitioning and Replication
In real-world systems, partitioning and replication are combined for optimal performance and reliability.
Mind Map: Combined Partitioning and Replication
Example Scenario: Global Online Retailer
- Partitioning: Orders partitioned by geographic region (list-based).
- Replication: Each partition is replicated synchronously across data centers in the region.
- Benefits: Low latency for local users, high availability with replicas.
Best Practices
- Choose partitioning strategy based on data access patterns.
- Use hash-based partitioning for uniform load distribution.
- Combine synchronous replication for critical data with asynchronous for less critical.
- Monitor shard sizes and rebalance partitions as data grows.
- Implement automated failover for replicas.
Summary
Data partitioning and replication are key to building scalable, reliable distributed systems. Understanding the trade-offs and selecting appropriate strategies based on application requirements is essential for cloud architects and engineers.
References
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Apache Cassandra Partitioning and Replication Documentation
- Kubernetes StatefulSets and Persistent Volumes
2.6 Service Discovery and Load Balancing Techniques in Distributed Systems
In distributed systems, service discovery and load balancing are critical components that ensure services can find each other dynamically and that client requests are efficiently distributed across multiple service instances. This section explores these concepts in detail, illustrating best practices with easy-to-understand examples and mind maps.
What is Service Discovery?
Service discovery is the automatic detection of devices and services offered by these devices on a computer network. In distributed systems, it enables services to dynamically locate other services without hardcoding network locations.
Why is Service Discovery Important?
- Services in distributed systems are often ephemeral and can scale up/down dynamically.
- IP addresses and ports can change frequently.
- Hardcoding service endpoints leads to brittle and unscalable systems.
Types of Service Discovery
- Static Discovery: Using fixed IP addresses or DNS entries. Simple but not scalable.
- Dynamic Discovery:
- Client-Side Discovery: Clients query a service registry to find service instances.
- Server-Side Discovery: Clients send requests to a load balancer which queries the registry.
- DNS-Based Discovery: Using DNS to resolve service names to IPs dynamically.
Service Discovery Components
Example: Client-Side Service Discovery with Consul
- Setup: Multiple instances of a payment service register themselves with Consul.
- Client: Queries Consul to get a list of healthy payment service instances.
- Load Balancing: Client picks an instance (e.g., round-robin) and sends request.
# Registering a service with Consul
curl --request PUT --data '{"ID": "payment1", "Name": "payment", "Address": "10.0.0.1", "Port": 8080}' http://localhost:8500/v1/agent/service/register
# Querying services
curl http://localhost:8500/v1/catalog/service/payment
What is Load Balancing?
Load balancing distributes incoming network traffic across multiple backend servers or service instances to ensure no single instance is overwhelmed, improving availability and responsiveness.
Load Balancing Algorithms
- Round Robin: Requests are distributed sequentially.
- Least Connections: Directs traffic to the server with the fewest active connections.
- IP Hash: Uses client IP to consistently route requests to the same server.
- Weighted Round Robin: Servers have weights; higher weight means more requests.
- Random: Requests distributed randomly.
Load Balancing Techniques
Example: Server-Side Load Balancing with NGINX
Scenario: Multiple instances of a web service running on ports 8081, 8082, 8083.
NGINX config snippet:
http {
upstream backend {
server 127.0.0.1:8081;
server 127.0.0.1:8082;
server 127.0.0.1:8083;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}
This config uses round-robin by default to distribute requests evenly.
Integrating Service Discovery with Load Balancing
In dynamic environments, service instances come and go. Integrating service discovery with load balancing ensures that the load balancer always routes traffic to healthy, available instances.
Example: Kubernetes Service Discovery and Load Balancing
- Kubernetes uses kube-dns for service discovery.
- Services get a stable DNS name.
- kube-proxy performs load balancing across pods.
Example:
# Get service cluster IP
kubectl get svc my-service
# Access service via DNS
curl http://my-service.default.svc.cluster.local
Kubernetes automatically load balances requests across healthy pods.
Best Practices
- Use health checks to ensure only healthy instances receive traffic.
- Prefer dynamic service discovery over static configurations.
- Combine client-side and server-side discovery where appropriate.
- Use circuit breakers and retries to handle failures gracefully.
- Monitor service registry and load balancer metrics.
Summary
Service discovery and load balancing are foundational to building resilient, scalable distributed systems. By leveraging dynamic registries and intelligent load balancing algorithms, systems can adapt to changing environments and maintain high availability.
Further Reading
- Consul Service Discovery
- NGINX Load Balancing
- Kubernetes Services
- Netflix Ribbon
3. Cloud Native Application Design Principles
3.1 Twelve-Factor App Methodology: Detailed Walkthrough with Examples
The Twelve-Factor App methodology is a set of best practices designed to enable building modern, scalable, and maintainable cloud native applications. Originally introduced by Heroku, it provides a blueprint for designing applications that can be deployed and operated reliably in distributed environments.
Below is a detailed walkthrough of each factor, accompanied by easy-to-understand examples and mind maps to visualize the concepts.
Factor 1: Codebase
One codebase tracked in revision control, many deploys.
- A single codebase is shared across all deployments.
- Multiple deployments (e.g., staging, production) can be created from the same codebase.
Example:
A Git repository contains the entire source code for an e-commerce microservice. The same repo is deployed to both staging and production environments, with environment-specific configurations.
Mind Map - Factor 1: Codebase
Factor 2: Dependencies
Explicitly declare and isolate dependencies.
- Dependencies must be declared explicitly (e.g., package.json for Node.js, requirements.txt for Python).
- Use dependency isolation tools like virtualenv, Docker containers.
Example:
A Python Flask app declares dependencies in requirements.txt and uses a virtual environment to isolate them.
Mind Map - Factor 2: Dependencies
Factor 3: Config
Store config in the environment.
- Configuration that varies between deploys (credentials, URLs) is stored in environment variables.
- Avoid hardcoding config in code.
Example:
Database connection strings are injected via environment variables DB_HOST, DB_USER, and DB_PASS rather than being hardcoded.
Mind Map - Factor 3: Config
Factor 4: Backing Services
Treat backing services as attached resources.
- Services like databases, message queues, caches are attached resources.
- They can be swapped without code changes by changing config.
Example:
Switching from a local Redis cache to a managed Redis service by updating environment variables.
Mind Map - Factor 4: Backing Services
Factor 5: Build, Release, Run
Strictly separate build and run stages.
- Build: compile code and dependencies into a build artifact.
- Release: combine build with config.
- Run: execute the app in the execution environment.
Example:
A CI/CD pipeline builds a Docker image (build), tags it with environment variables (release), and then deploys it to Kubernetes (run).
Mind Map - Factor 5: Build, Release, Run
Factor 6: Processes
Execute the app as one or more stateless processes.
- Processes should be stateless and share-nothing.
- Persisted data must be stored in backing services.
Example:
A Node.js microservice stores session data in a Redis cache instead of local memory.
Mind Map - Factor 6: Processes
Factor 7: Port Binding
Export services via port binding.
- The app is self-contained and exposes HTTP services by binding to a port.
Example:
A Go web server listens on port 8080 and serves HTTP requests directly without relying on an external web server.
Mind Map - Factor 7: Port Binding
Factor 8: Concurrency
Scale out via the process model.
- Scale by running multiple processes of different types.
Example:
A worker process handles background jobs, while multiple web processes handle HTTP requests, scaled independently.
Mind Map - Factor 8: Concurrency
Factor 9: Disposability
Fast startup and graceful shutdown.
- Processes should start quickly and shut down gracefully to enable rapid scaling and deployment.
Example:
A Java Spring Boot app implements shutdown hooks to close database connections before termination.
Mind Map - Factor 9: Disposability
Factor 10: Dev/Prod Parity
Keep development, staging, and production as similar as possible.
- Minimize gaps in time, personnel, and tools between environments.
Example:
Using Docker Compose locally to mimic the production Kubernetes environment.
Mind Map - Factor 10: Dev/Prod Parity
Factor 11: Logs
Treat logs as event streams.
- Applications should not manage log files.
- Write logs to stdout/stderr, and let the execution environment handle aggregation.
Example:
A microservice writes JSON logs to stdout, which are collected by Fluentd and sent to Elasticsearch.
Mind Map - Factor 11: Logs
Factor 12: Admin Processes
Run admin/management tasks as one-off processes.
- Tasks like database migrations or console commands run as ad-hoc processes in the same environment.
Example:
Running a Django management command for database migrations using the same Docker image as the app.
Mind Map - Factor 12: Admin Processes
Summary Mind Map of Twelve-Factor App
Practical Example: Building a Twelve-Factor Node.js Microservice
- Codebase: Single Git repo.
- Dependencies: Declared in
package.json. - Config: Use
dotenvto load environment variables. - Backing Services: Connect to MongoDB via URI in env variable.
- Build, Release, Run: Docker build for image, deploy with config injected.
- Processes: Stateless HTTP server.
- Port Binding: Listen on port from env variable.
- Concurrency: Scale replicas in Kubernetes.
- Disposability: Graceful shutdown on SIGTERM.
- Dev/Prod Parity: Use Docker Compose locally.
- Logs: Write JSON logs to stdout.
- Admin Processes: Run migration scripts as one-offs.
This approach ensures the app is cloud-ready, scalable, and maintainable.
By following the Twelve-Factor methodology, cloud solutions architects and senior software engineers can design distributed systems and cloud native applications that are robust, portable, and easy to operate.
3.2 Designing for Immutable Infrastructure and Infrastructure as Code
Introduction
Immutable infrastructure and Infrastructure as Code (IaC) are foundational principles in modern cloud native application design. They enable repeatability, consistency, and automation, reducing configuration drift and human error.
Immutable infrastructure means that once a server or component is deployed, it is never modified in place. Instead, any changes require creating a new instance and replacing the old one. IaC allows you to define and manage your infrastructure using code, making deployments more predictable and version-controlled.
Why Immutable Infrastructure?
- Consistency: Every deployment is identical, eliminating “works on my machine” problems.
- Reliability: Rollbacks are simpler by redeploying previous versions.
- Security: Reduces configuration drift and unauthorized changes.
- Scalability: Easier to scale out by replicating immutable images.
Core Concepts Mind Map
Infrastructure as Code (IaC) Explained
IaC is the practice of managing and provisioning infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
Example: Using Terraform to provision an AWS EC2 instance.
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0" # Amazon Linux 2 AMI
instance_type = "t2.micro"
tags = {
Name = "ImmutableExample"
}
}
This code can be version-controlled, reviewed, and reused. When changes are needed, you update the code and apply it, which creates new resources or modifies existing ones safely.
Designing Immutable Infrastructure
Image Baking
Creating machine images (e.g., AMIs for AWS, VM images for GCP/Azure) with all dependencies and configurations baked in.
Example: Using Packer to create an immutable AMI.
{
"builders": [{
"type": "amazon-ebs",
"region": "us-east-1",
"source_ami": "ami-0c55b159cbfafe1f0",
"instance_type": "t2.micro",
"ssh_username": "ec2-user",
"ami_name": "immutable-app-{{timestamp}}"
}],
"provisioners": [{
"type": "shell",
"inline": [
"sudo yum update -y",
"sudo yum install -y nginx"
]
}]
}
This AMI can then be deployed repeatedly without manual configuration.
Containerization
Containers are inherently immutable. Once built, container images are deployed as-is.
Example: Dockerfile for a Node.js app
FROM node:14-alpine
WORKDIR /app
COPY package.json .
RUN npm install
COPY . .
CMD ["node", "index.js"]
Build and deploy the container image without changing it at runtime.
Immutable Servers
Avoid SSHing into servers to make changes. Instead, replace servers with new instances built from updated images.
Best Practices for IaC and Immutable Infrastructure
- Modularize your code: Break down infrastructure code into reusable modules.
- Use version control: Store IaC code in Git or similar.
- Test your infrastructure code: Use tools like Terratest or kitchen-terraform.
- Automate deployments: Integrate IaC with CI/CD pipelines.
- Keep infrastructure stateless: Store state externally (e.g., databases, object storage).
- Use tagging and naming conventions: For easier management and cost tracking.
Example: Deploying Immutable Infrastructure with Terraform and Packer
- Use Packer to bake an AMI with your application and dependencies.
- Use Terraform to deploy EC2 instances using the baked AMI.
- When application updates are needed, bake a new AMI and update the Terraform configuration to use the new AMI ID.
- Apply Terraform to replace old instances with new ones seamlessly.
This approach ensures no manual changes on running servers and allows easy rollback by switching to a previous AMI.
Mind Map: Workflow for Immutable Infrastructure with IaC
Summary
Designing for immutable infrastructure combined with Infrastructure as Code empowers cloud architects and engineers to build reliable, scalable, and maintainable systems. By baking images, containerizing applications, and managing infrastructure declaratively, teams reduce errors, improve deployment speed, and simplify operations.
Additional Resources
- Terraform Documentation
- Packer Documentation
- Docker Best Practices
- 12-Factor App - Dev/prod parity
3.3 Containerization Best Practices: Docker and Beyond
Containerization has revolutionized how applications are developed, shipped, and run. Docker is the most popular container platform, but the ecosystem extends beyond Docker to include tools like Podman, containerd, and CRI-O. This section covers best practices for containerization with practical examples and mind maps to help you design efficient, secure, and maintainable containerized applications.
Why Containerization?
- Encapsulates application and dependencies
- Ensures consistent environments across development, testing, and production
- Enables microservices architecture and rapid scaling
Best Practices for Containerization
Use Minimal Base Images
- Choose lightweight base images (e.g., Alpine Linux) to reduce attack surface and image size.
- Avoid unnecessary packages to keep images lean.
Example:
FROM alpine:3.17
RUN apk add --no-cache python3
COPY app.py /app/
CMD ["python3", "/app/app.py"]
Multi-Stage Builds for Smaller Images
- Separate build environment from runtime environment.
- Compile or build artifacts in one stage, copy only necessary files to the final image.
Example:
# Build stage
FROM golang:1.20-alpine AS builder
WORKDIR /app
COPY . .
RUN go build -o myapp
# Final stage
FROM alpine:3.17
COPY --from=builder /app/myapp /usr/local/bin/myapp
CMD ["myapp"]
Avoid Running Containers as Root
- Use non-root users inside containers to improve security.
Example:
FROM node:18-alpine
RUN addgroup -S appgroup && adduser -S appuser -G appgroup
USER appuser
COPY . /app
WORKDIR /app
CMD ["node", "server.js"]
Keep Containers Stateless
- Store state outside containers (e.g., databases, object storage).
- Use volumes for persistent data if necessary.
Properly Manage Environment Variables and Secrets
- Pass configuration via environment variables.
- Use secret management tools (e.g., Kubernetes Secrets, HashiCorp Vault).
Example:
docker run -e DB_PASSWORD=supersecret myapp
Optimize Layer Caching
- Order Dockerfile instructions to maximize cache hits.
- Place frequently changing commands (e.g., copying source code) after installing dependencies.
Health Checks
- Define
HEALTHCHECKinstructions to monitor container health.
Example:
HEALTHCHECK --interval=30s --timeout=5s CMD curl -f http://localhost:8080/health || exit 1
Logging and Monitoring
- Write logs to stdout/stderr for container runtime to capture.
- Integrate with centralized logging and monitoring solutions.
Use Trusted and Up-to-Date Images
- Pull images from official or trusted registries.
- Regularly update images to patch vulnerabilities.
Container Runtime Alternatives Beyond Docker
- Podman: Daemonless, rootless container engine compatible with Docker CLI.
- containerd: Lightweight container runtime used by Kubernetes.
- CRI-O: Kubernetes-native container runtime.
Example:
# Run container with Podman
podman run -it alpine sh
Mind Maps
Mind Map 1: Containerization Best Practices Overview
Mind Map 2: Security Best Practices in Containers
Mind Map 3: Multi-Stage Build Workflow
Practical Example: Containerizing a Python Flask App
Dockerfile:
# Use official Python slim image
FROM python:3.11-slim
# Set working directory
WORKDIR /app
# Install dependencies
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code
COPY . .
# Use non-root user
RUN useradd -m appuser
USER appuser
# Expose port
EXPOSE 5000
# Healthcheck
HEALTHCHECK --interval=30s CMD curl -f http://localhost:5000/health || exit 1
# Run the app
CMD ["python", "app.py"]
Explanation:
- Uses a slim base image to reduce size.
- Installs dependencies first to leverage caching.
- Runs as a non-root user.
- Includes a health check.
Summary
Containerization best practices focus on creating secure, efficient, and maintainable images that run consistently across environments. Embracing minimal base images, multi-stage builds, non-root users, and proper secret management are foundational. Beyond Docker, exploring alternative runtimes like Podman can offer additional flexibility and security benefits.
By following these guidelines and examples, cloud architects and senior engineers can build robust cloud native applications that leverage the full power of containerization.
3.4 Orchestration with Kubernetes: Core Concepts and Practical Deployments
Kubernetes has become the de facto standard for container orchestration in cloud native application design. It automates deployment, scaling, and management of containerized applications, enabling distributed systems to operate efficiently and resiliently.
Core Concepts of Kubernetes
To understand Kubernetes orchestration, it’s essential to grasp its fundamental building blocks:
Kubernetes Core Concepts Mind Map
Practical Example: Deploying a Simple Web Application
Let’s walk through deploying a simple NGINX web server using Kubernetes.
- Create a Deployment YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
This manifest defines a Deployment that manages 3 replicas of an NGINX container.
- Create a Service to expose the Deployment:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
This Service exposes the NGINX pods on port 80 and uses a LoadBalancer to route external traffic.
- Apply the manifests:
kubectl apply -f nginx-deployment.yaml
kubectl apply -f nginx-service.yaml
- Verify the deployment:
kubectl get pods
kubectl get svc nginx-service
Best Practices for Kubernetes Orchestration
- Use Declarative Manifests: Manage your infrastructure as code using YAML manifests or Helm charts.
- Leverage Namespaces: Isolate environments (dev, staging, prod) using namespaces.
- Implement Health Checks: Define readiness and liveness probes to ensure pod health.
- Use Resource Requests and Limits: Prevent resource contention by specifying CPU and memory limits.
- Automate Rollouts and Rollbacks: Use Deployments to manage application updates safely.
- Secure Your Cluster: Use RBAC, Network Policies, and Secrets management.
Mind Map: Kubernetes Deployment Workflow
Advanced Example: Autoscaling with Horizontal Pod Autoscaler (HPA)
Autoscaling helps maintain performance under varying loads.
- Enable Metrics Server:
Ensure the metrics server is installed in your cluster to provide resource usage metrics.
- Create HPA YAML:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- Apply HPA:
kubectl apply -f nginx-hpa.yaml
- Monitor Autoscaling:
kubectl get hpa
This setup scales the number of NGINX pods between 2 and 10 based on CPU utilization.
Summary
Kubernetes orchestration empowers cloud native applications with automated deployment, scaling, and management. By mastering core concepts like Pods, Deployments, and Services, and applying best practices such as declarative configuration and autoscaling, architects and engineers can build resilient and scalable distributed systems.
For further reading, explore the Kubernetes official documentation and hands-on tutorials to deepen your practical knowledge.
3.5 Managing Configuration and Secrets Securely in Cloud Native Apps
Managing configuration and secrets securely is a cornerstone of building robust, maintainable, and secure cloud native applications. Mismanagement can lead to vulnerabilities, data breaches, and operational failures. This section covers best practices, tools, and practical examples to help you design secure configuration and secrets management.
Why Secure Configuration and Secrets Management Matters
- Configuration includes environment-specific settings such as database URLs, API endpoints, feature flags, and resource limits.
- Secrets are sensitive data like passwords, API keys, certificates, and tokens.
Hardcoding secrets or embedding them directly in code or container images can expose them to unauthorized access. Proper management ensures confidentiality, integrity, and availability.
Mind Map: Overview of Secure Configuration and Secrets Management
Best Practices with Examples
Avoid Hardcoding Secrets
Bad practice: Embedding API keys or passwords directly in source code.
# BAD: Hardcoded secret
API_KEY = "12345-secret-key"
Better approach: Use environment variables or external secret stores.
# Set environment variable
export API_KEY="12345-secret-key"
import os
API_KEY = os.getenv('API_KEY')
Use Kubernetes Secrets for Containerized Apps
- Kubernetes Secrets store sensitive data encoded in base64.
- Secrets can be mounted as files or injected as environment variables.
Example: Create a secret and use it in a pod.
kubectl create secret generic db-password --from-literal=password='S3cr3tP@ssw0rd'
Pod YAML snippet:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp
image: myapp-image
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-password
key: password
Use HashiCorp Vault for Dynamic Secrets
Vault provides dynamic secrets that are generated on demand and have limited lifetimes.
Example: Generating a dynamic database credential that expires automatically.
- Vault generates a username/password pair for a database user.
- The credential is valid only for a limited time.
- After expiration, Vault revokes access automatically.
This reduces risk from leaked credentials.
Encrypt Secrets at Rest and in Transit
- Use TLS to encrypt communication between your app and secret stores.
- Enable encryption on storage backends (e.g., AWS KMS with AWS Secrets Manager).
Implement Role-Based Access Control (RBAC)
- Limit access to secrets only to services or users that need them.
- Example: Kubernetes RBAC policies restrict who can read secrets.
Rotate Secrets Regularly
- Automate secret rotation to reduce risk from compromised secrets.
- Example: AWS Secrets Manager supports automatic rotation with Lambda.
Audit and Monitor Access
- Enable audit logs on secret management systems.
- Monitor for unusual access patterns.
Mind Map: Example Workflow for Secure Secrets Injection in Kubernetes
Practical Example: Using AWS Secrets Manager with a Cloud Native App
- Store secret:
aws secretsmanager create-secret --name MyAppDBPassword --secret-string "MySuperSecretPassword"
-
Grant IAM permissions: Attach a policy to your app’s IAM role to allow
secretsmanager:GetSecretValue. -
Retrieve secret in app (Python example):
import boto3
import base64
from botocore.exceptions import ClientError
secret_name = "MyAppDBPassword"
region_name = "us-west-2"
session = boto3.session.Session()
client = session.client(service_name='secretsmanager', region_name=region_name)
try:
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
except ClientError as e:
raise e
else:
secret = get_secret_value_response['SecretString']
print(f"Database password: {secret}")
- Use secret: Pass the retrieved password to your database connection logic.
Summary
- Never hardcode secrets; use environment variables or secret stores.
- Use platform-native secret management tools (Kubernetes Secrets, AWS Secrets Manager, Vault).
- Encrypt secrets at rest and in transit.
- Apply strict access control and audit all secret access.
- Automate secret rotation and handle secret injection dynamically.
By following these practices and leveraging the right tools, you can significantly reduce the risk of secret leakage and improve the security posture of your cloud native applications.
3.6 Observability: Logging, Monitoring, and Tracing with Real-World Tools
Observability is a cornerstone of maintaining and operating distributed systems and cloud native applications effectively. It provides insights into system behavior, performance, and failures by collecting and analyzing telemetry data such as logs, metrics, and traces.
What is Observability?
Observability is the ability to understand the internal state of a system based on the data it produces externally. It is crucial for diagnosing issues, optimizing performance, and ensuring reliability in complex distributed environments.
Core Pillars of Observability
Logging
Definition: Logging captures discrete events or messages generated by applications or infrastructure components.
Best Practices:
- Use structured logging (e.g., JSON format) for easier parsing and querying.
- Include contextual information such as request IDs, user IDs, timestamps.
- Centralize logs using tools like Elasticsearch, Fluentd, and Kibana (EFK stack) or Loki with Grafana.
- Implement log levels (DEBUG, INFO, WARN, ERROR) to filter noise.
Example:
{
"timestamp": "2024-06-01T12:00:00Z",
"level": "ERROR",
"service": "payment-service",
"request_id": "abc123",
"message": "Failed to process payment",
"error_code": "PAYMENT_TIMEOUT"
}
Real-World Tool:
- EFK Stack: Fluentd collects logs, Elasticsearch stores and indexes, Kibana visualizes.
- Grafana Loki: Lightweight log aggregation designed for cloud native environments.
Monitoring
Definition: Monitoring involves collecting and analyzing metrics that represent system health and performance over time.
Best Practices:
- Collect key performance indicators (KPIs) such as CPU, memory, request latency, error rates.
- Use time-series databases like Prometheus for efficient metric storage.
- Set up alerting rules to notify teams on threshold breaches.
- Build dashboards for real-time visualization and trend analysis.
Example:
- Track HTTP request latency percentiles (p50, p95, p99) to identify performance bottlenecks.
Real-World Tool:
- Prometheus: Open-source monitoring system with powerful query language (PromQL).
- Grafana: Visualization platform that integrates with Prometheus and other data sources.
Tracing
Definition: Distributed tracing tracks the flow of requests across multiple services, capturing timing and causal relationships.
Best Practices:
- Instrument services to propagate trace context (e.g., trace IDs) across RPC calls.
- Capture spans representing individual operations within a trace.
- Use sampling strategies to balance overhead and visibility.
- Analyze traces to pinpoint latency sources and error propagation.
Example:
- A user request flows from API Gateway → Auth Service → Payment Service → Database.
- Each service generates spans with start/end timestamps and metadata.
Real-World Tool:
- Jaeger: Open-source distributed tracing system.
- Zipkin: Another popular tracing system.
- OpenTelemetry: Vendor-neutral instrumentation framework supporting logs, metrics, and traces.
Integrated Observability Example: E-Commerce Checkout Flow
Imagine an e-commerce platform where a user places an order. Observability components work together:
- Logging: Payment service logs a timeout error with request ID.
- Monitoring: Prometheus alerts if payment service error rate exceeds 5%.
- Tracing: Jaeger trace shows the checkout request was delayed in the payment service due to database latency.
This integrated view helps engineers quickly identify and resolve the root cause.
Summary Table of Tools
| Observability Pillar | Popular Tools | Key Features |
|---|---|---|
| Logging | EFK Stack, Grafana Loki | Centralized log aggregation, structured logs |
| Monitoring | Prometheus, Grafana | Time-series metrics, alerting, dashboards |
| Tracing | Jaeger, Zipkin, OpenTelemetry | Distributed tracing, context propagation |
Final Tips
- Adopt OpenTelemetry to unify instrumentation across logs, metrics, and traces.
- Automate alerting to reduce mean time to detection (MTTD).
- Regularly review dashboards and traces to proactively identify issues.
- Use correlation IDs to link logs, metrics, and traces for holistic debugging.
By embedding observability deeply into your distributed systems and cloud native applications, you empower your teams to maintain high reliability, quickly troubleshoot issues, and continuously improve system performance.
4. Communication and Coordination in Distributed Systems
4.1 Inter-Service Communication Patterns: Synchronous vs Asynchronous
In distributed systems and cloud native architectures, communication between services is a fundamental aspect that impacts performance, reliability, scalability, and user experience. Understanding the differences between synchronous and asynchronous communication patterns is crucial for designing robust systems.
What is Inter-Service Communication?
Inter-service communication refers to how different services within a distributed system exchange data and coordinate actions. This communication can be broadly categorized into two patterns:
- Synchronous Communication
- Asynchronous Communication
Mind Map: Overview of Inter-Service Communication Patterns
Synchronous Communication
Definition: In synchronous communication, the client sends a request and waits (blocks) until it receives a response from the service.
Characteristics:
- Tight coupling in time: The caller waits for the callee.
- Simpler to reason about due to immediate response.
- Can lead to increased latency and reduced fault tolerance if the callee is slow or unavailable.
Common Protocols: HTTP/HTTPS (REST), gRPC, SOAP
Example Scenario:
Imagine an e-commerce application where the frontend service calls the payment service to process a payment. The frontend waits for the payment service to confirm the transaction before proceeding.
# Example: Synchronous REST API call in Python
import requests
response = requests.post('https://payment-service/api/pay', json={'order_id': 123, 'amount': 49.99})
if response.status_code == 200:
print('Payment successful')
else:
print('Payment failed')
Best Practices:
- Use synchronous communication when immediate response is required.
- Implement timeouts and retries to handle failures gracefully.
- Avoid cascading failures by using circuit breakers.
Mind Map: Synchronous Communication Details
Asynchronous Communication
Definition: In asynchronous communication, the client sends a request and does not wait for an immediate response. Instead, the response or event is handled later, allowing the client to continue processing.
Characteristics:
- Loose coupling in time: sender and receiver operate independently.
- Improves system scalability and resilience.
- More complex to design and debug.
Common Technologies: Message queues (RabbitMQ, AWS SQS), Event streaming platforms (Apache Kafka), Pub/Sub systems
Example Scenario:
In the same e-commerce app, after an order is placed, the order service publishes an event to a message queue for inventory service to update stock asynchronously.
# Example: Publishing a message to RabbitMQ asynchronously
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='order_events')
order_event = {'order_id': 123, 'status': 'PLACED'}
channel.basic_publish(exchange='', routing_key='order_events', body=str(order_event))
print('Order event published')
connection.close()
Best Practices:
- Use asynchronous communication to decouple services and improve scalability.
- Design idempotent consumers to handle duplicate messages.
- Implement dead-letter queues for failed message processing.
- Monitor message queues and set alerts for processing delays.
Mind Map: Asynchronous Communication Details
Comparing Synchronous vs Asynchronous Communication
| Aspect | Synchronous | Asynchronous |
|---|---|---|
| Coupling | Tight (time coupled) | Loose (time decoupled) |
| Response | Immediate | Delayed |
| Complexity | Simpler | More complex |
| Scalability | Limited by blocking calls | Highly scalable |
| Fault Tolerance | Lower (failures propagate quickly) | Higher (can retry, buffer messages) |
| Use Cases | Real-time requests, authentication | Event processing, background jobs |
Hybrid Approaches
Many systems combine both patterns to balance responsiveness and scalability. For example, a synchronous request might trigger asynchronous processing downstream.
Example:
A user uploads a photo (synchronous upload), and the image processing (resizing, filtering) happens asynchronously.
Summary
Choosing between synchronous and asynchronous communication depends on the use case, system requirements, and trade-offs:
- Use synchronous when immediate response and simplicity are priorities.
- Use asynchronous to improve scalability, resilience, and decouple services.
By understanding these patterns and applying best practices with real-world examples, architects and engineers can design distributed systems that are robust, efficient, and maintainable.
4.2 Message Queues and Event Streaming: Kafka, RabbitMQ, and Examples
Introduction
Message queues and event streaming platforms are fundamental components in modern distributed systems. They enable asynchronous communication, decoupling of services, and scalable data pipelines. This section explores two popular technologies — Apache Kafka and RabbitMQ — and illustrates best practices with easy-to-understand examples.
What Are Message Queues and Event Streaming?
- Message Queues: Systems that store messages temporarily until they are processed by consumers. They guarantee message delivery and support asynchronous communication.
- Event Streaming: Continuous flow of event data that can be processed in real-time or stored for later analysis.
Mind Map: Message Queues vs Event Streaming
Apache Kafka Overview
- Distributed event streaming platform designed for high throughput and fault tolerance.
- Stores streams of records in categories called topics.
- Supports partitioning and replication.
Kafka Core Concepts
- Producer: Sends data to Kafka topics.
- Consumer: Reads data from Kafka topics.
- Broker: Kafka server that stores data.
- Topic: Named stream of records.
- Partition: Subdivision of a topic for parallelism.
Example: Simple Kafka Producer and Consumer in Python
from kafka import KafkaProducer, KafkaConsumer
import json
# Producer example
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
message = {'order_id': 1234, 'status': 'created'}
producer.send('orders', message)
producer.flush()
# Consumer example
consumer = KafkaConsumer('orders',
bootstrap_servers='localhost:9092',
auto_offset_reset='earliest',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
for msg in consumer:
print(f"Received order: {msg.value}")
break
Best Practices with Kafka
- Use partitions to scale consumers.
- Enable replication for fault tolerance.
- Use consumer groups for load balancing.
- Monitor lag to ensure consumers keep up.
RabbitMQ Overview
- Message broker implementing Advanced Message Queuing Protocol (AMQP).
- Supports complex routing via exchanges and queues.
- Suitable for task queues, RPC, and pub/sub.
RabbitMQ Core Concepts
- Producer: Sends messages to an exchange.
- Exchange: Routes messages to queues based on rules.
- Queue: Stores messages until consumed.
- Consumer: Receives messages from queues.
Example: Simple RabbitMQ Producer and Consumer in Python
import pika
# Connection setup
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# Declare queue
channel.queue_declare(queue='task_queue', durable=True)
# Producer example
message = 'Process order 1234'
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
# Consumer example
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
# Simulate work
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
Best Practices with RabbitMQ
- Use durable queues and persistent messages to avoid data loss.
- Implement acknowledgments to ensure message processing.
- Use prefetch to limit unacknowledged messages per consumer.
- Design exchanges and routing keys carefully for scalability.
Comparing Kafka and RabbitMQ
Mind Map: Choosing Between Kafka and RabbitMQ
Real-World Example: Order Processing System
Scenario: An e-commerce platform processes orders asynchronously.
- RabbitMQ: Used for task queue to process payment and inventory updates.
- Kafka: Used to stream order events for analytics and auditing.
Flow:
- User places an order.
- Order service publishes order event to Kafka topic
orders. - Payment and inventory services consume from RabbitMQ queues to process tasks.
- Analytics service consumes Kafka topic to generate reports.
Summary
Message queues and event streaming platforms are essential for building scalable, resilient distributed systems. Kafka excels in high-throughput event streaming scenarios, while RabbitMQ shines in flexible messaging and task queues. Understanding their core concepts and best practices empowers architects and engineers to design robust cloud native applications.
Further Reading
- Apache Kafka Documentation
- RabbitMQ Tutorials
- [Designing Event-Driven Systems by Ben Stopford]
4.3 Consensus Algorithms: Paxos and Raft Simplified with Use Cases
Consensus algorithms are fundamental to distributed systems, enabling a group of nodes to agree on a single data value even in the presence of failures. This section explores two of the most widely used consensus algorithms: Paxos and Raft. We’ll simplify their concepts, provide mind maps to visualize their workflows, and illustrate their practical use cases with examples.
What is Consensus in Distributed Systems?
Consensus ensures that multiple nodes agree on a single value or sequence of values, which is critical for consistency and fault tolerance.
Key properties of consensus algorithms:
- Safety: No two nodes decide differently.
- Liveness: Eventually, a decision is made.
- Fault tolerance: Works despite some node failures.
Paxos Consensus Algorithm
Paxos is a family of protocols for solving consensus in a network of unreliable processors.
Paxos Roles
- Proposers: Suggest values to be agreed upon.
- Acceptors: Vote on proposed values.
- Learners: Learn the decided value.
Paxos Phases
- Prepare Phase: Proposer sends a prepare request with a proposal number to acceptors.
- Promise Phase: Acceptors promise not to accept proposals with lower numbers and reply with the highest accepted proposal.
- Accept Phase: Proposer sends an accept request with a proposal number and value.
- Accepted Phase: Acceptors accept the proposal and notify learners.
Mind Map: Paxos Workflow
Example: Distributed Lock Service Using Paxos
Imagine a distributed lock service where multiple clients want to acquire a lock on a resource.
- Each client acts as a proposer.
- Lock servers are acceptors.
- Once a lock is granted (consensus on the lock owner), learners are notified.
Best Practice: Use unique proposal numbers (e.g., timestamps combined with node IDs) to avoid conflicts.
Raft Consensus Algorithm
Raft is designed to be more understandable than Paxos while providing the same fault-tolerant consensus guarantees.
Raft Roles
- Leader: Handles client requests and log replication.
- Followers: Passive nodes that respond to leader.
- Candidates: Nodes that try to become leader during elections.
Raft Components
- Leader Election: Nodes elect a leader to coordinate consensus.
- Log Replication: Leader appends entries to logs and replicates to followers.
- Safety: Ensures committed entries are durable and consistent.
Mind Map: Raft Consensus Algorithm
Example: Distributed Key-Value Store Using Raft
Consider a distributed key-value store where consistency is critical.
- The leader receives client write requests.
- It appends the write to its log and replicates to followers.
- Once a majority acknowledges, the entry is committed.
- Followers apply the committed entry to their state machines.
Best Practice: Use heartbeat messages from leader to followers to maintain authority and detect failures quickly.
Comparing Paxos and Raft
| Aspect | Paxos | Raft |
|---|---|---|
| Understandability | More complex, harder to implement | Designed to be more understandable |
| Leader Election | Implicit, can be complex | Explicit leader election mechanism |
| Log Replication | Not part of basic Paxos, extended in Multi-Paxos | Built-in log replication mechanism |
| Use Cases | Consensus on single values, lock services | Distributed logs, replicated state machines |
Practical Use Cases
Distributed Databases
- Paxos and Raft ensure consistency across replicas.
- Example: Google’s Chubby uses Paxos; etcd and Consul use Raft.
Coordination Services
- Distributed locks, leader election.
- Example: ZooKeeper uses Zab (similar to Paxos).
Configuration Management
- Consistent configuration updates across distributed nodes.
Summary
- Consensus algorithms are essential for fault-tolerant distributed systems.
- Paxos is foundational but complex; Raft offers a more approachable alternative.
- Both algorithms have practical applications in cloud native systems.
For further reading, consider exploring:
- “Paxos Made Simple” by Leslie Lamport
- “In Search of an Understandable Consensus Algorithm (Raft)” by Diego Ongaro and John Ousterhout
4.4 Distributed Transactions and Saga Pattern Implementation
Distributed systems often require operations that span multiple services or databases. Ensuring data consistency across these distributed components is a challenging problem because traditional ACID transactions are difficult to implement at scale and across heterogeneous systems. This section explores distributed transactions and how the Saga pattern provides a practical solution.
What Are Distributed Transactions?
A distributed transaction is a transaction that involves multiple networked resources or services, each potentially with its own database or state. The goal is to ensure that either all parts of the transaction succeed or none do, maintaining consistency.
Challenges:
- Network failures
- Partial failures
- Latency
- Coordination overhead
Traditional two-phase commit (2PC) protocols can enforce atomicity but are often impractical due to blocking, complexity, and performance issues.
Introducing the Saga Pattern
The Saga pattern breaks a distributed transaction into a sequence of smaller, local transactions. Each local transaction updates a single service and publishes an event or message to trigger the next step.
If a step fails, compensating transactions are executed to undo the previous steps, ensuring eventual consistency.
Key Concepts:
- Local Transactions: Independent, atomic operations within a single service.
- Compensating Transactions: Undo operations to revert previous changes.
- Orchestration vs Choreography: Two ways to manage Saga execution.
Mind Map: Overview of Saga Pattern
Orchestration-Based Saga
In orchestration, a central Saga orchestrator (or coordinator) directs each step by sending commands to services and handling failures.
Example:
Imagine an e-commerce order processing system with these steps:
- Reserve inventory
- Charge payment
- Arrange shipping
If payment fails, the orchestrator triggers a compensating transaction to release the reserved inventory.
Code snippet (pseudo-code):
class OrderSagaOrchestrator:
def execute(self, order):
try:
reserve_inventory(order)
charge_payment(order)
arrange_shipping(order)
except PaymentFailed:
release_inventory(order)
mark_order_failed(order)
Choreography-Based Saga
In choreography, there is no central coordinator. Each service emits events after completing local transactions, and other services react accordingly.
Example:
- Inventory service reserves stock and emits
InventoryReservedevent. - Payment service listens for
InventoryReserved, charges payment, then emitsPaymentCharged. - Shipping service listens for
PaymentChargedand arranges shipping.
If payment fails, the payment service emits PaymentFailed, triggering inventory to release stock.
Diagram:
Inventory Service –> emits InventoryReserved –> Payment Service
Payment Service –> emits PaymentCharged or PaymentFailed –> Inventory Service / Shipping Service
Shipping Service –> listens PaymentCharged
Implementing Compensating Transactions
Compensating transactions are critical to rollback partial work. They must be carefully designed to undo side effects without violating business rules.
Example:
- If inventory was reserved, the compensating transaction releases that inventory.
- If payment was charged, the compensating transaction issues a refund.
Practical Example: Booking a Trip (Flight + Hotel)
Scenario:
- Step 1: Book flight
- Step 2: Book hotel
If hotel booking fails, the flight booking must be canceled.
Orchestration approach:
class TripBookingSaga:
def execute(self, trip):
try:
book_flight(trip)
book_hotel(trip)
except HotelBookingFailed:
cancel_flight(trip)
mark_trip_failed(trip)
Choreography approach:
- Flight service books flight and emits
FlightBookedevent. - Hotel service listens for
FlightBooked, attempts hotel booking. - If hotel booking fails, hotel service emits
HotelBookingFailedevent. - Flight service listens for
HotelBookingFailedand cancels flight.
Mind Map: Steps to Implement Saga Pattern
Best Practices
- Idempotency: Ensure all local and compensating transactions are idempotent to handle retries safely.
- Timeouts: Define timeouts for each step to avoid indefinite waits.
- Monitoring: Track saga progress and failures with distributed tracing.
- Data Consistency: Accept eventual consistency and design user experience accordingly.
- Error Handling: Plan for partial failures and provide clear rollback paths.
Summary
The Saga pattern offers a scalable, resilient alternative to traditional distributed transactions by decomposing a global transaction into manageable steps with compensations. Choosing between orchestration and choreography depends on system complexity, team preferences, and operational requirements.
By implementing sagas with clear compensations, idempotency, and robust messaging, distributed systems can maintain data consistency while embracing cloud native scalability and fault tolerance.
4.5 Handling Network Partitions and Latency with Practical Strategies
In distributed systems, network partitions and latency are inevitable challenges that can severely impact system availability, consistency, and user experience. Understanding how to handle these issues effectively is crucial for building resilient and performant cloud native applications.
What is a Network Partition?
A network partition occurs when a network failure splits a distributed system into two or more isolated segments that cannot communicate with each other. This can cause nodes to become unreachable, leading to inconsistencies or downtime if not handled properly.
What is Latency?
Latency is the delay between sending a request and receiving a response. In distributed systems, latency can be caused by network delays, processing time, or resource contention, and it affects the responsiveness and throughput of applications.
Mind Map: Causes and Effects of Network Partitions and Latency
Practical Strategies to Handle Network Partitions and Latency
Detection and Monitoring
- Best Practice: Implement health checks, heartbeat mechanisms, and network monitoring tools to detect partitions and latency spikes early.
- Example: Use Kubernetes liveness and readiness probes to detect pod unavailability due to network issues.
Graceful Degradation
- Best Practice: Design systems to degrade functionality gracefully rather than failing completely.
- Example: An e-commerce site might disable recommendation features if the recommendation service is unreachable, but still allow checkout.
Retry with Exponential Backoff and Jitter
- Best Practice: When requests fail due to network issues, retry with increasing delays and randomization to avoid overwhelming the network.
- Example: A microservice calling another service retries failed requests with exponential backoff and jitter to reduce retry storms.
Use of Circuit Breakers
- Best Practice: Prevent cascading failures by stopping requests to an unresponsive service temporarily.
- Example: Netflix’s Hystrix library implements circuit breakers to isolate failing services.
Choosing Appropriate Consistency Models
- Best Practice: Understand CAP theorem trade-offs and choose consistency models (e.g., eventual consistency) that tolerate partitions.
- Example: DynamoDB uses eventual consistency to remain available during partitions.
Idempotent Operations
- Best Practice: Design APIs so that repeated requests due to retries do not cause unintended side effects.
- Example: Payment processing APIs that safely handle duplicate requests without charging twice.
Data Replication and Conflict Resolution
- Best Practice: Replicate data across nodes and implement conflict resolution strategies to handle divergent states after partitions.
- Example: Using vector clocks or CRDTs (Conflict-free Replicated Data Types) to reconcile updates.
Timeout Settings and Load Shedding
- Best Practice: Configure appropriate timeouts to avoid waiting indefinitely and shed load when the system is overwhelmed.
- Example: API gateways returning 503 Service Unavailable when backend services are slow or down.
Mind Map: Handling Network Partitions and Latency Strategies
Example Scenario: Implementing Retry with Exponential Backoff and Circuit Breaker
Imagine a distributed payment processing system where Service A calls Service B to authorize payments.
- Problem: Network partitions cause Service B to become unreachable intermittently.
- Solution:
- Service A implements a retry mechanism with exponential backoff and jitter to avoid hammering Service B.
- A circuit breaker is placed around calls to Service B. If failures exceed a threshold, the circuit opens, and Service A immediately returns a fallback response or queues the request.
Code snippet (pseudo-code):
import random
import time
class CircuitBreaker:
def __init__(self, failure_threshold, recovery_time):
self.failure_threshold = failure_threshold
self.recovery_time = recovery_time
self.failure_count = 0
self.state = 'CLOSED'
self.last_failure_time = None
def call(self, func, *args, **kwargs):
if self.state == 'OPEN':
if time.time() - self.last_failure_time > self.recovery_time:
self.state = 'HALF_OPEN'
else:
raise Exception('Circuit is open')
try:
result = func(*args, **kwargs)
self.failure_count = 0
self.state = 'CLOSED'
return result
except Exception as e:
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = 'OPEN'
raise e
def call_service_b():
# Simulate network call
if random.random() < 0.5: # 50% failure
raise Exception('Service B unreachable')
return 'Success'
circuit_breaker = CircuitBreaker(failure_threshold=3, recovery_time=10)
max_retries = 5
base_delay = 0.5
for attempt in range(max_retries):
try:
response = circuit_breaker.call(call_service_b)
print(f'Response: {response}')
break
except Exception as e:
delay = base_delay * (2 ** attempt) + random.uniform(0, 0.1)
print(f'Attempt {attempt + 1} failed: {e}. Retrying in {delay:.2f} seconds...')
time.sleep(delay)
else:
print('All retries failed. Fallback or queue the request.')
Summary
Handling network partitions and latency requires a combination of detection, resilient design patterns, and thoughtful trade-offs between consistency and availability. By implementing retries with backoff, circuit breakers, graceful degradation, and appropriate data strategies, distributed systems can maintain robustness and deliver a better user experience even under adverse network conditions.
4.6 Designing Idempotent APIs for Reliable Distributed Operations
Introduction
In distributed systems, network failures, retries, and partial failures are common. To build reliable APIs that can gracefully handle these issues, designing idempotent APIs is critical. An idempotent API ensures that making the same request multiple times results in the same effect as making it once, preventing unintended side effects.
What is Idempotency?
- Definition: An operation is idempotent if applying it multiple times has the same effect as applying it once.
- Importance: Helps in safely retrying requests without causing duplicate effects.
Why Idempotency Matters in Distributed Systems
- Network failures can cause clients to retry requests.
- Without idempotency, retries can cause duplicated transactions, inconsistent states, or data corruption.
- Idempotency enables fault tolerance and improves user experience.
Key Concepts
HTTP Methods and Idempotency
| HTTP Method | Idempotent? | Description |
|---|---|---|
| GET | Yes | Safe, read-only operations. |
| PUT | Yes | Replace resource, same effect on multiple calls. |
| DELETE | Yes | Deleting a resource multiple times has same effect. |
| POST | No | Usually creates new resources, not idempotent by default. |
| PATCH | No | Partial updates, generally non-idempotent. |
Best Practices for Designing Idempotent APIs
Use Idempotency Keys
- Clients generate a unique key per operation.
- Server stores the key with the operation result.
- On retry with the same key, server returns the original response without re-executing.
Example: Payment processing API
POST /payments
Headers: Idempotency-Key: 123e4567-e89b-12d3-a456-426614174000
Body: { "amount": 100, "currency": "USD" }
If the client retries with the same Idempotency-Key, the server returns the original payment confirmation without charging twice.
Use Safe HTTP Methods When Possible
- Prefer PUT or DELETE for updates or deletions.
- Design APIs so that repeated PUT requests with the same payload do not change the state beyond the first request.
Example:
PUT /users/123
Body: { "email": "[email protected]" }
Multiple identical PUT requests update the user email to the same value, resulting in no side effect after the first.
Conditional Requests
- Use HTTP headers like
If-MatchorIf-None-Matchwith ETags to ensure updates only happen if resource state matches.
Example:
PUT /documents/456
Headers: If-Match: "etag-value"
Body: { "content": "updated content" }
If the ETag doesn’t match, the server rejects the update, preventing unintended overwrites.
Design Operations to be Naturally Idempotent
- For example, setting a resource attribute to a specific value is idempotent.
- Avoid operations like “increment” which are not idempotent unless carefully handled.
Example:
POST /cart/123/items
Body: { "productId": "abc", "quantity": 5 }
If this API increments quantity by 5 each call, it is not idempotent. Instead, design it to set quantity to 5.
Implementing Idempotency Keys: Detailed Example
Code snippet (pseudo-code):
idempotency_key = request.headers.get('Idempotency-Key')
if idempotency_key:
cached_response = cache.get(idempotency_key)
if cached_response:
return cached_response
response = process_request(request)
cache.set(idempotency_key, response)
return response
else:
return process_request(request)
Handling Idempotency in Asynchronous Operations
- For long-running or async tasks, return a resource ID or operation ID.
- Clients can query operation status using this ID.
- Idempotency keys can be used to ensure the operation is only started once.
Example:
POST /video-transcode
Headers: Idempotency-Key: abc-123
Body: { "videoUrl": "http://example.com/video.mp4" }
Client retries with same key will not start multiple transcode jobs.
Common Pitfalls and How to Avoid Them
| Pitfall | Description | Mitigation |
|---|---|---|
| No idempotency key on POST | Causes duplicate resource creation | Enforce idempotency key header validation |
| Storing large responses | Can cause memory overhead | Store minimal metadata or use TTL on cache |
| Non-idempotent side effects | E.g., sending emails multiple times | Separate side effects from main operation or use event deduplication |
Summary
- Idempotency is essential for reliable distributed APIs.
- Use idempotency keys, safe HTTP methods, and conditional requests.
- Design operations to be naturally idempotent where possible.
- Implement caching and state management carefully.
Additional Mind Map: Idempotent API Design Checklist
5. Data Management in Distributed and Cloud Native Systems
5.1 Choosing the Right Database: SQL, NoSQL, NewSQL Explained
Choosing the right database technology is a foundational decision in designing distributed systems and cloud native applications. The choice impacts scalability, consistency, latency, and overall system complexity. In this section, we will explore the three major database paradigms: SQL, NoSQL, and NewSQL, highlighting their characteristics, use cases, and best practices with easy-to-understand examples.
Overview of Database Types
SQL Databases
Characteristics
- Relational Model: Data is organized into tables with predefined schemas.
- ACID Transactions: Guarantees Atomicity, Consistency, Isolation, Durability.
- Strong Consistency: Ensures data correctness and integrity.
Best Practices
- Use when data relationships are complex and require joins.
- Ideal for systems where consistency is critical.
- Schema migrations should be managed carefully in distributed environments.
Example: E-Commerce Order Management
Imagine an e-commerce platform managing orders, customers, and inventory. SQL databases like PostgreSQL are perfect here because:
- Orders relate to customers and products via foreign keys.
- Transactions ensure inventory counts are accurate.
Example Query:
BEGIN;
UPDATE inventory SET stock = stock - 1 WHERE product_id = 123 AND stock > 0;
INSERT INTO orders (customer_id, product_id, quantity) VALUES (456, 123, 1);
COMMIT;
This transaction ensures stock is decremented only if available, maintaining consistency.
NoSQL Databases
Characteristics
- Non-relational: Data stored as documents, key-value pairs, wide-columns, or graphs.
- Schema Flexibility: Allows evolving data models.
- BASE Properties: Basically Available, Soft state, Eventual consistency.
Types and Use Cases
- Document Stores (MongoDB): Store JSON-like documents, great for content management.
- Key-Value Stores (Redis): Ultra-fast caching and session storage.
- Column-family Stores (Cassandra): High write throughput and scalability.
- Graph Databases (Neo4j): Manage complex relationships like social networks.
Best Practices
- Choose based on data model and access patterns.
- Accept eventual consistency where appropriate for scalability.
- Use TTL (Time To Live) features for ephemeral data.
Example: Real-Time Session Store with Redis
A web application needs to store user sessions with fast read/write and expiration.
Example:
import redis
r = redis.Redis(host='localhost', port=6379)
# Set session with expiry
r.setex('session:abc123', 3600, 'user_data')
# Retrieve session
session_data = r.get('session:abc123')
Redis provides blazing fast key-value storage with built-in expiration, ideal for this use case.
NewSQL Databases
Characteristics
- Combine the relational model and ACID guarantees of SQL with the horizontal scalability of NoSQL.
- Designed for distributed cloud environments.
Examples
- Google Spanner: Globally distributed, strongly consistent database.
- CockroachDB: Open-source, scalable SQL database.
- VoltDB: In-memory NewSQL database for high throughput.
Best Practices
- Use when you need strong consistency and SQL capabilities at scale.
- Evaluate latency requirements, as distributed consensus can add overhead.
Example: Global Financial Ledger with CockroachDB
A financial app needs a distributed ledger with strong consistency across regions.
Example:
CREATE TABLE transactions (
id UUID PRIMARY KEY,
account_id UUID,
amount DECIMAL,
timestamp TIMESTAMPTZ
);
INSERT INTO transactions (id, account_id, amount, timestamp) VALUES (...);
CockroachDB ensures ACID compliance and replicates data globally, maintaining consistency.
Decision Factors When Choosing a Database
Summary Table
| Database Type | Strengths | Weaknesses | Ideal Use Cases |
|---|---|---|---|
| SQL | Strong consistency, complex queries, mature tooling | Scaling horizontally is challenging | Financial systems, ERP, CRM |
| NoSQL | Flexible schema, high scalability, fast writes | Eventual consistency, limited joins | Real-time analytics, caching, content stores |
| NewSQL | Combines SQL features with horizontal scalability | Complexity, newer technology | Global transactional systems, cloud native apps |
Final Example: Choosing a Database for a Social Media Application
- User Profiles & Relationships: Graph database (Neo4j) to model connections.
- Posts & Comments: Document store (MongoDB) for flexible content.
- Session Management: Key-value store (Redis) for fast access.
- Billing & Payments: NewSQL (CockroachDB) for transactional consistency across regions.
This polyglot persistence approach leverages strengths of each database type.
By understanding the characteristics, trade-offs, and best practices of SQL, NoSQL, and NewSQL databases, cloud solutions architects and senior software engineers can design robust, scalable, and maintainable distributed systems tailored to their application’s needs.
5.2 Data Consistency and Integrity in Distributed Databases
Distributed databases introduce unique challenges around maintaining data consistency and integrity due to their nature of spanning multiple nodes, regions, or even continents. This section explores the core concepts, trade-offs, and practical examples to help architects and engineers design robust distributed data systems.
Understanding Data Consistency Models
Consistency defines the guarantee about the visibility and ordering of updates across distributed nodes. The choice of consistency model impacts system performance, availability, and user experience.
Common Consistency Models:
- Strong Consistency: All nodes see the same data at the same time. Reads always return the most recent write.
- Eventual Consistency: Updates propagate asynchronously; nodes may temporarily see stale data but will converge eventually.
- Causal Consistency: Writes that are causally related are seen in the same order by all nodes, but concurrent writes may be seen in different orders.
Mind Map: Data Consistency Models
Data Integrity in Distributed Systems
Data integrity ensures correctness, accuracy, and trustworthiness of data throughout its lifecycle. In distributed databases, integrity is challenged by network partitions, concurrent updates, and replication delays.
Key mechanisms include:
- Atomicity: Transactions are all-or-nothing.
- Isolation: Concurrent transactions do not interfere.
- Durability: Once committed, data persists despite failures.
- Validation and Constraints: Enforcing schema rules and business logic.
CAP Theorem and Its Impact
The CAP theorem states that a distributed system can provide only two of the following three guarantees simultaneously:
- Consistency
- Availability
- Partition Tolerance
In practice, network partitions are inevitable, so systems must choose between consistency and availability.
Mind Map: CAP Theorem
Practical Examples of Consistency Models
Example 1: Strong Consistency with Spanner (Google)
Google Spanner uses TrueTime API to provide globally-distributed strong consistency with external consistency guarantees. It uses synchronized clocks and two-phase commit protocols.
- Use Case: Financial transactions where stale reads are unacceptable.
- Best Practice: Use strong consistency when correctness is critical, but expect higher latency.
Example 2: Eventual Consistency with Amazon DynamoDB
DynamoDB offers tunable consistency; by default, it provides eventual consistency for higher availability and performance.
- Use Case: Social media feeds where slight delays in updates are tolerable.
- Best Practice: Tune consistency level based on application requirements.
Example 3: Causal Consistency in Collaborative Applications
Systems like COPS provide causal consistency, ensuring that dependent updates are seen in order, which is crucial for collaborative editing tools.
- Use Case: Real-time document collaboration.
- Best Practice: Use causal consistency to balance performance and correctness in user-facing apps.
Techniques to Maintain Data Integrity
- Distributed Transactions and Two-Phase Commit (2PC): Ensures atomic commit across nodes but can impact availability.
- Conflict-Free Replicated Data Types (CRDTs): Allow concurrent updates with automatic conflict resolution.
- Sagas Pattern: Breaks distributed transactions into a sequence of local transactions with compensating actions.
Mind Map: Data Integrity Techniques
Example: Implementing Saga Pattern in E-Commerce Order Processing
- Local Transaction 1: Reserve inventory
- Local Transaction 2: Charge payment
- Local Transaction 3: Confirm order
If payment fails, a compensating transaction releases reserved inventory.
This approach avoids locking resources across services and improves availability.
Summary Best Practices
- Choose the consistency model aligned with your application’s tolerance for stale data and latency.
- Use strong consistency for critical data (e.g., payments, user authentication).
- Leverage eventual or causal consistency for high-throughput, user-facing features.
- Implement data integrity mechanisms like distributed transactions or sagas to maintain correctness.
- Monitor and test consistency behaviors under network partitions and failures.
References and Further Reading
- Brewer’s CAP Theorem: https://en.wikipedia.org/wiki/CAP_theorem
- Google Spanner Paper: https://research.google/pubs/pub39966/
- DynamoDB Consistency Models: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.ReadConsistency.html
- Saga Pattern: https://microservices.io/patterns/data/saga.html
This section equips cloud architects and senior engineers with foundational knowledge and practical insights to design distributed databases that balance consistency, integrity, and performance effectively.
5.3 Event Sourcing and CQRS: Concepts and Practical Examples
Introduction
Event Sourcing and CQRS (Command Query Responsibility Segregation) are powerful architectural patterns widely used in distributed systems and cloud native applications to handle complex business logic, improve scalability, and maintain data consistency.
What is Event Sourcing?
Event Sourcing is a pattern where state changes of an application are stored as a sequence of immutable events rather than just storing the current state. The system’s state can be reconstructed by replaying these events.
Key Benefits:
- Complete audit trail of all changes
- Easy to debug and troubleshoot
- Enables temporal queries (e.g., “What was the state at time T?”)
- Facilitates event-driven architectures
Example: Consider a simple bank account system:
- Instead of storing the current balance, every deposit and withdrawal is stored as an event.
- The current balance is calculated by replaying all deposit and withdrawal events.
{
"events": [
{ "type": "Deposit", "amount": 100, "timestamp": "2024-06-01T10:00:00Z" },
{ "type": "Withdrawal", "amount": 30, "timestamp": "2024-06-02T15:30:00Z" }
]
}
Replaying these events results in a balance of 70.
What is CQRS?
CQRS stands for Command Query Responsibility Segregation. It separates the read and write operations of a system into different models:
- Command Model: Handles all writes/updates (commands).
- Query Model: Handles all reads (queries).
This separation allows optimization of each side independently, improving scalability and performance.
Example: In an e-commerce system:
- Commands update inventory, place orders, etc.
- Queries fetch product details, order status, etc.
How Event Sourcing and CQRS Work Together
Event Sourcing stores all changes as events (write model), while CQRS separates the read and write sides:
- The write side records events (commands).
- The read side builds projections or views by processing these events asynchronously.
This combination enables:
- High scalability
- Event-driven workflows
- Flexible read models optimized for queries
Mind Map: Event Sourcing Overview
Mind Map: CQRS Overview
Practical Example: Implementing Event Sourcing and CQRS in a ToDo Application
Scenario: A ToDo app where users can add, complete, and delete tasks.
Event Sourcing Events:
- TaskCreated
- TaskCompleted
- TaskDeleted
Commands:
- CreateTask
- CompleteTask
- DeleteTask
Step 1: Write Model (Command Handling and Event Storage)
- When a user issues a
CreateTaskcommand, validate and store aTaskCreatedevent. - Similarly for
CompleteTaskandDeleteTaskcommands.
Step 2: Event Store
- Append events to an event log.
Step 3: Read Model (Projection)
- Build a current state projection by replaying events.
- This projection is optimized for queries like “List all active tasks.”
Example Event Log:
[
{ "type": "TaskCreated", "taskId": "1", "title": "Buy groceries", "timestamp": "2024-06-01T09:00:00Z" },
{ "type": "TaskCompleted", "taskId": "1", "timestamp": "2024-06-02T12:00:00Z" },
{ "type": "TaskCreated", "taskId": "2", "title": "Write blog post", "timestamp": "2024-06-03T08:00:00Z" }
]
Resulting Projection:
| Task ID | Title | Status |
|---|---|---|
| 1 | Buy groceries | Completed |
| 2 | Write blog post | Active |
Best Practices
- Event Versioning: Design events to handle schema evolution gracefully.
- Idempotency: Ensure event handlers are idempotent to handle retries.
- Snapshotting: Use snapshots to speed up state reconstruction for large event logs.
- Async Projections: Keep read models eventually consistent but highly performant.
- Monitoring: Track event processing lag and failures.
Additional Mind Map: Event Sourcing + CQRS Workflow
Summary
Event Sourcing combined with CQRS provides a robust framework for building scalable, auditable, and maintainable distributed systems and cloud native applications. By capturing every state change as an event and separating read/write responsibilities, architects and engineers can optimize system performance and reliability while maintaining a rich history of all operations.
5.4 Managing State in Stateless Cloud Native Applications
Statelessness is a core principle in cloud native application design, enabling scalability, resilience, and easier deployment. However, many applications inherently require managing state—user sessions, transactions, or application data. This section explores best practices and patterns to manage state effectively while keeping your cloud native applications stateless.
Why Statelessness?
- Scalability: Stateless services can be scaled horizontally without worrying about session affinity.
- Resilience: Failure of one instance doesn’t affect the overall system.
- Simplified Deployment: Instances can be replaced or updated without complex state migration.
Challenges of State in Stateless Apps
- Need to persist user session data.
- Managing transactional data across distributed components.
- Ensuring data consistency and availability.
Common Patterns for Managing State
Externalizing State
Move state out of the application instance to external storage or services.
- Databases: Relational (PostgreSQL, MySQL), NoSQL (Redis, Cassandra).
- Distributed Caches: Redis, Memcached.
- Object Storage: S3, Azure Blob Storage.
Example: A shopping cart microservice stores cart items in Redis instead of in-memory variables, allowing any instance to serve the user.
Client-Side State Management
Store state on the client, reducing server-side state management.
- Cookies, localStorage, or JWT tokens.
Example: Using JWT tokens to store user authentication claims, so backend services remain stateless.
Stateful Services via Stateful Sets or Stateful Workloads
When stateful behavior is unavoidable, use Kubernetes StatefulSets or managed stateful services.
Example: Deploying a Kafka cluster with StatefulSets to maintain broker identity and persistent storage.
Event Sourcing and CQRS
Store state changes as a sequence of events rather than current state snapshots.
Example: An order management system records each order event; the current state is rebuilt by replaying events.
Mind Map: Managing State in Stateless Cloud Native Applications
Example: Shopping Cart with Externalized State
Scenario: A cloud native e-commerce app where users add items to their cart.
Traditional approach: Store cart in server memory (stateful) — not scalable.
Cloud native approach: Store cart data in Redis.
import redis
r = redis.Redis(host='redis-service', port=6379)
# Add item to cart
user_id = 'user123'
item_id = 'item456'
r.hset(f'cart:{user_id}', item_id, 1)
# Get cart items
cart_items = r.hgetall(f'cart:{user_id}')
print(cart_items)
This allows any instance of the cart service to retrieve and update the cart without relying on local memory.
Example: Using JWT for Stateless Authentication
Scenario: Authenticate users without server-side session storage.
- Server issues a JWT token containing user info and expiration.
- Client stores token and sends it with each request.
- Server validates token signature and extracts user info.
{
"alg": "HS256",
"typ": "JWT"
}
{
"sub": "user123",
"name": "John Doe",
"iat": 1516239022
}
This eliminates the need for server-side session storage, keeping services stateless.
Best Practices
- Choose the right storage: Use low-latency caches for ephemeral data, durable databases for critical state.
- Design for eventual consistency: Accept that distributed state may not be instantly consistent.
- Encrypt sensitive state data: Both at rest and in transit.
- Use idempotent operations: To handle retries safely in distributed calls.
- Monitor and backup external state stores: To prevent data loss.
Summary
Managing state in stateless cloud native applications requires thoughtful design to externalize or offload state. Leveraging external stores, client-side storage, and event-driven patterns enables scalable, resilient, and maintainable systems.
5.5 Backup, Recovery, and Disaster Recovery Strategies
In distributed systems and cloud native applications, ensuring data durability and availability is critical. Backup, recovery, and disaster recovery (DR) strategies protect against data loss, system failures, and catastrophic events. This section covers best practices, practical examples, and mind maps to help you design robust backup and recovery plans.
Key Concepts
- Backup: Creating copies of data at specific points in time.
- Recovery: Restoring data from backups after data loss or corruption.
- Disaster Recovery: Comprehensive strategies to recover systems and data after major outages or disasters.
Mind Map: Backup, Recovery, and Disaster Recovery Overview
Backup Strategies
Full Backup
A full backup copies all data. It is simple but time-consuming and storage-heavy.
Example: A nightly full backup of a database stored in Amazon S3.
Incremental Backup
Only backs up data changed since the last backup (full or incremental). Saves storage and time.
Example: After a Sunday full backup, Monday’s incremental backup only stores changes made on Monday.
Differential Backup
Backs up data changed since the last full backup.
Example: Tuesday’s differential backup includes all changes since Sunday’s full backup.
Snapshot-based Backup
Uses storage-level snapshots to quickly capture the state of volumes.
Example: Using EBS snapshots in AWS to back up a database volume.
Mind Map: Backup Strategies
Recovery Techniques
Point-in-Time Recovery (PITR)
Allows restoring data to a specific moment, useful for recovering from accidental deletions or corruption.
Example: PostgreSQL WAL (Write Ahead Log) based PITR to restore database to 2 hours before a faulty transaction.
Continuous Data Protection (CDP)
Captures every data change in real-time or near real-time.
Example: Cloud-native databases like Google Cloud Spanner provide continuous backups enabling near-zero data loss.
Disaster Recovery (DR) Planning
DR is about restoring entire systems, not just data.
- Recovery Time Objective (RTO): Maximum acceptable downtime.
- Recovery Point Objective (RPO): Maximum acceptable data loss.
Example: An e-commerce platform defines RTO=1 hour and RPO=15 minutes, meaning it must recover within 1 hour and lose no more than 15 minutes of data.
Multi-Region Replication
Replicating data and services across multiple geographic regions to improve availability and fault tolerance.
Example: Using AWS Aurora Global Database replicating across US East and Europe regions.
Failover Mechanisms
Automated switching to standby systems when primary systems fail.
Example: Kubernetes clusters with multi-zone deployments and automated pod failover.
Mind Map: Disaster Recovery Components
Tools and Technologies
- Cloud Provider Services: AWS Backup, Azure Backup, Google Cloud Backup and DR
- Open Source Tools: Velero (Kubernetes backup), Restic (encrypted backups), Bacula
- Automation: Infrastructure as Code (Terraform, Ansible) to automate backup and recovery workflows
Best Practices
- Automate backups and recovery tests regularly.
- Encrypt backups both at rest and in transit.
- Store backups in multiple locations (e.g., different cloud regions).
- Define clear RTO and RPO aligned with business needs.
- Regularly perform disaster recovery drills to validate procedures.
- Monitor backup jobs and alert on failures.
Example Scenario: Backup and DR for a Cloud Native Microservices Application
Context: A microservices-based e-commerce platform running on Kubernetes with a PostgreSQL database.
- Backup: Use Velero to snapshot Kubernetes cluster state and persistent volumes daily.
- Database Backup: Configure PostgreSQL PITR with WAL archiving to S3.
- Disaster Recovery: Multi-region deployment with active-passive failover. Use Route 53 health checks to switch traffic.
- Testing: Monthly DR drills to restore backups and validate failover.
Mind Map: Example Backup and DR Workflow
By integrating these backup, recovery, and disaster recovery strategies, cloud architects and engineers can build resilient distributed systems that minimize downtime and data loss, ensuring business continuity even in the face of failures or disasters.
5.6 Data Privacy and Compliance in Cloud Native Environments
Ensuring data privacy and meeting compliance requirements are critical when designing and operating cloud native applications. Distributed systems often span multiple geographic regions and jurisdictions, which adds complexity to privacy and regulatory adherence. This section explores best practices, frameworks, and practical examples to help architects and engineers build compliant and privacy-conscious cloud native systems.
Key Concepts in Data Privacy and Compliance
- Data Privacy: Protecting personal and sensitive data from unauthorized access and misuse.
- Compliance: Adhering to legal and regulatory requirements such as GDPR, HIPAA, CCPA, and others.
- Data Sovereignty: Ensuring data is stored and processed in accordance with local jurisdiction laws.
- Data Minimization: Collecting and retaining only the data necessary for the intended purpose.
- Encryption: Protecting data at rest and in transit using cryptographic methods.
Mind Map: Core Pillars of Data Privacy & Compliance in Cloud Native Environments
Regulatory Frameworks and Their Impact
Example: A healthcare cloud native app must comply with HIPAA, which mandates strict controls on Protected Health Information (PHI). This includes encryption, access logging, and audit trails.
- GDPR: Requires explicit consent for data collection, right to erasure, and data portability.
- HIPAA: Focuses on safeguarding PHI with administrative, physical, and technical safeguards.
- CCPA: Grants California residents rights to know, delete, and opt-out of sale of personal data.
Best Practice: Implement a compliance matrix mapping application components and data flows to regulatory requirements.
Mind Map: Compliance Implementation Workflow
Data Governance in Cloud Native Systems
Example: Using Kubernetes namespaces and RBAC (Role-Based Access Control) to isolate and control access to sensitive data and workloads.
- Data Classification: Label data as public, internal, confidential, or restricted.
- Data Minimization: Avoid storing unnecessary PII (Personally Identifiable Information).
- Data Retention: Automate data lifecycle policies using cloud provider tools (e.g., AWS S3 lifecycle policies).
Best Practice: Integrate data governance policies into CI/CD pipelines to enforce compliance before deployment.
Encryption Strategies
- At Rest: Use cloud provider managed encryption (e.g., AWS KMS, Azure Key Vault) or self-managed keys.
- In Transit: Enforce TLS 1.2+ for all service-to-service communication.
Example: A microservices architecture uses mutual TLS (mTLS) within a service mesh (e.g., Istio) to secure inter-service communication.
Best Practice: Regularly rotate encryption keys and audit key usage.
Access Controls and Identity Management
- Implement least privilege principle using fine-grained IAM roles.
- Use multi-factor authentication (MFA) for administrative access.
- Leverage service accounts with scoped permissions for applications.
Example: AWS IAM policies restrict access to S3 buckets containing sensitive data only to authorized services.
Monitoring, Auditing, and Incident Response
- Enable audit logging for all access and changes to sensitive data.
- Use cloud-native monitoring tools (e.g., AWS CloudTrail, Azure Monitor) to detect anomalies.
- Prepare incident response plans aligned with compliance requirements.
Example: A breach detection system triggers alerts when unusual data access patterns are detected, enabling rapid response.
Mind Map: Incident Response Lifecycle
Practical Example: Implementing GDPR Compliance in a Cloud Native App
- Consent Management: Use a consent service to track user permissions.
- Data Minimization: Store only necessary user data in databases.
- Right to Erasure: Implement API endpoints to delete user data on request.
- Data Portability: Provide export functionality in common formats (JSON, CSV).
- Encryption: Encrypt user data at rest and in transit.
- Audit Logging: Log all data access and modification events.
Summary
Data privacy and compliance in cloud native environments require a holistic approach combining regulatory understanding, strong governance, security controls, and continuous monitoring. By embedding these practices into architecture and development workflows, organizations can build trustworthy and compliant distributed systems.
Further Reading & Tools
- NIST Privacy Framework
- OWASP Cloud Security Guidelines
- Kubernetes RBAC Documentation
- Istio Security Concepts
- AWS Compliance Programs
6. Security Best Practices for Distributed Systems and Cloud Native Apps
6.1 Identity and Access Management (IAM) in Cloud Environments
Introduction
Identity and Access Management (IAM) is a foundational security discipline in cloud environments. It ensures that the right individuals and services have appropriate access to resources, minimizing risks of unauthorized access or data breaches.
Core Concepts of IAM
- Identity: Represents users, groups, or services that need access.
- Authentication: Verifying the identity of a user or service.
- Authorization: Granting or denying access to resources based on permissions.
- Policies: Rules that define what identities can do.
- Roles: Collections of permissions assigned to identities.
Mind Map: IAM Core Components
Best Practices in IAM
- Principle of Least Privilege: Grant only the minimum permissions necessary.
- Use Roles Instead of Users for Permissions: Assign permissions to roles and then assign roles to users or services.
- Enable Multi-Factor Authentication (MFA): Adds an extra layer of security.
- Use Federated Identities: Integrate with corporate directories or third-party identity providers.
- Regularly Audit IAM Policies and Access Logs: Detect and remediate anomalies.
- Automate IAM Management: Use Infrastructure as Code (IaC) to manage IAM policies for consistency.
Mind Map: IAM Best Practices
Example 1: AWS IAM Role Creation and Assignment
Scenario: You want to allow an EC2 instance to access an S3 bucket securely.
Step-by-step:
- Create an IAM Role with a policy granting
s3:GetObjectpermission on the specific bucket. - Attach the IAM Role to the EC2 instance.
- The EC2 instance can now access the S3 bucket without embedding credentials.
Policy Example:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject"],
"Resource": ["arn:aws:s3:::example-bucket/*"]
}
]
}
Example 2: Google Cloud IAM with Service Accounts
Scenario: A Cloud Function needs to write logs to Cloud Logging.
Steps:
- Create a service account for the Cloud Function.
- Assign the
roles/logging.logWriterrole to the service account. - Deploy the Cloud Function using this service account.
This approach avoids using user credentials and scopes permissions tightly.
Federated Identity and Single Sign-On (SSO)
Federated identity allows users to authenticate using an external identity provider (IdP) such as Google Workspace, Azure AD, or Okta.
Benefits:
- Centralized user management
- Reduced password fatigue
- Enhanced security through corporate policies
Mind Map: Federated Identity Flow
Example 3: Azure AD Integration with Azure IAM
Scenario: Employees use their corporate Azure AD credentials to access Azure resources.
Implementation:
- Configure Azure AD as the identity provider.
- Assign Azure RBAC roles to Azure AD groups.
- Users inherit permissions based on group membership.
This simplifies access management and leverages existing identity infrastructure.
Auditing and Monitoring IAM
Continuous monitoring of IAM activities is critical to detect suspicious behavior.
Key Activities:
- Track login attempts and failures.
- Monitor privilege escalations.
- Review policy changes.
Example Tools:
- AWS CloudTrail
- Google Cloud Audit Logs
- Azure Monitor
Example 4: Detecting Anomalous IAM Activity with AWS CloudTrail
Scenario: Detect if a user suddenly gains admin privileges.
Approach:
- Enable CloudTrail to log IAM API calls.
- Set up CloudWatch alarms for policy changes or role assignments.
- Trigger alerts for security team investigation.
Summary
IAM is a critical pillar in securing cloud environments. By understanding core concepts, applying best practices, and leveraging cloud-native IAM features, architects and engineers can build secure, scalable, and manageable systems.
References & Further Reading
- AWS IAM Best Practices
- Google Cloud IAM Overview
- Azure RBAC Documentation
- NIST Digital Identity Guidelines
6.2 Securing Inter-Service Communication with Mutual TLS
Introduction
In distributed systems and cloud native applications, services often communicate over the network. Ensuring that this communication is secure is critical to prevent eavesdropping, tampering, and impersonation attacks. Mutual TLS (mTLS) is a robust security mechanism that provides both encryption and mutual authentication between communicating services.
What is Mutual TLS?
Mutual TLS is an extension of the standard TLS protocol where both client and server authenticate each other using X.509 certificates. Unlike traditional TLS where only the server is authenticated, mTLS requires both parties to present and verify certificates, establishing a trusted connection.
Why Use Mutual TLS in Distributed Systems?
- Strong Authentication: Both services verify each other’s identity.
- Encrypted Communication: Data is encrypted in transit.
- Mitigates Man-in-the-Middle Attacks: Prevents unauthorized interception.
- Zero Trust Security Model: Enforces strict identity verification.
Mind Map: Overview of Mutual TLS
How Mutual TLS Works: Step-by-Step
- Client Hello: Client initiates connection, sends supported TLS versions and cipher suites.
- Server Hello: Server responds with chosen TLS version and cipher suite.
- Server Certificate: Server sends its certificate to client.
- Client Certificate Request: Server requests client’s certificate.
- Client Certificate: Client sends its certificate.
- Certificate Verification: Both sides verify each other’s certificates against trusted CA.
- Key Exchange: Both parties generate shared secret keys.
- Secure Communication Established: Encrypted data transfer begins.
Example: Enabling mTLS Between Two Microservices
Consider two microservices, Service A (client) and Service B (server), communicating over HTTPS.
Step 1: Generate Certificates
Using OpenSSL, generate a CA, server, and client certificates.
# Generate CA private key and self-signed certificate
openssl genrsa -out ca.key 2048
openssl req -x509 -new -nodes -key ca.key -sha256 -days 3650 -out ca.crt -subj "/CN=MyRootCA"
# Generate server key and CSR
openssl genrsa -out server.key 2048
openssl req -new -key server.key -out server.csr -subj "/CN=service-b"
# Sign server certificate with CA
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -days 365 -sha256
# Generate client key and CSR
openssl genrsa -out client.key 2048
openssl req -new -key client.key -out client.csr -subj "/CN=service-a"
# Sign client certificate with CA
openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -days 365 -sha256
Step 2: Configure Service B (Server) to Require Client Certificate
Example using Node.js with Express:
const https = require('https');
const fs = require('fs');
const express = require('express');
const app = express();
app.get('/', (req, res) => {
res.send('Hello from Service B with mTLS!');
});
const options = {
key: fs.readFileSync('server.key'),
cert: fs.readFileSync('server.crt'),
ca: fs.readFileSync('ca.crt'),
requestCert: true,
rejectUnauthorized: true
};
https.createServer(options, app).listen(8443, () => {
console.log('Service B listening on port 8443 with mTLS');
});
Step 3: Configure Service A (Client) to Present Certificate
Example using Node.js HTTPS client:
const https = require('https');
const fs = require('fs');
const options = {
hostname: 'localhost',
port: 8443,
path: '/',
method: 'GET',
key: fs.readFileSync('client.key'),
cert: fs.readFileSync('client.crt'),
ca: fs.readFileSync('ca.crt'),
rejectUnauthorized: true
};
const req = https.request(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log('Response:', data);
});
});
req.on('error', (e) => {
console.error(e);
});
req.end();
Mind Map: Certificate Management in mTLS
Best Practices for Implementing mTLS
- Automate Certificate Lifecycle: Use tools like HashiCorp Vault, cert-manager, or AWS Certificate Manager.
- Use a Private CA for Internal Services: Avoid public CAs for internal communication.
- Enforce Strict Certificate Validation: Reject unauthorized or expired certificates.
- Monitor and Audit mTLS Traffic: Detect anomalies or unauthorized access.
- Integrate with Service Meshes: Istio, Linkerd provide built-in mTLS support simplifying implementation.
Example: Using Istio Service Mesh for mTLS
Istio can automatically enable mTLS between services without manual certificate management.
# Enable mTLS in Istio for the default namespace
kubectl label namespace default istio-injection=enabled
# Apply PeerAuthentication policy to enforce mTLS
kubectl apply -f - <<EOF
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: default
spec:
mtls:
mode: STRICT
EOF
This policy ensures all services in the namespace communicate over mTLS transparently.
Troubleshooting Tips
- Certificate Mismatch: Ensure client and server certificates are signed by the same CA.
- Expired Certificates: Regularly check and renew certificates.
- Clock Skew Issues: Synchronize system clocks to avoid validation errors.
- Network Issues: Verify ports and firewall rules allow TLS traffic.
Summary
Mutual TLS is a powerful technique to secure inter-service communication by providing encryption and mutual authentication. While it introduces complexity in certificate management, automation tools and service meshes can simplify adoption. Implementing mTLS is a best practice for building secure, resilient distributed systems and cloud native applications.
6.3 Implementing Zero Trust Architecture in Distributed Systems
Introduction
Zero Trust Architecture (ZTA) is a security paradigm that assumes no implicit trust, whether inside or outside the network perimeter. Every access request must be verified, authenticated, and authorized before granting access to resources. This approach is especially critical in distributed systems where components are spread across multiple environments and cloud platforms.
Core Principles of Zero Trust Architecture
- Verify Explicitly: Authenticate and authorize every access request using all available data points.
- Use Least Privilege Access: Limit user and system access to the minimum necessary.
- Assume Breach: Design systems assuming attackers are already inside the network.
Mind Map: Zero Trust Architecture Core Components
Implementing Zero Trust in Distributed Systems
Distributed systems introduce complexity due to multiple services, APIs, and data stores communicating across networks. Implementing Zero Trust requires a layered approach:
Identity and Access Management (IAM)
- Use strong identity verification for users and services.
- Example: Implement OAuth 2.0 with OpenID Connect for service-to-service authentication.
Microsegmentation
- Divide the network into granular zones to restrict lateral movement.
- Example: Use Kubernetes Network Policies to restrict pod-to-pod communication only to necessary services.
Encrypted Communication
- Enforce TLS for all communication channels.
- Example: Use mutual TLS (mTLS) between microservices to authenticate both client and server.
Continuous Monitoring and Analytics
- Monitor traffic and behavior to detect anomalies.
- Example: Integrate with tools like Prometheus and Grafana for metrics, and use SIEM systems for log analysis.
Mind Map: Zero Trust Implementation Steps in Distributed Systems
Practical Example: Implementing Zero Trust in a Kubernetes-Based Distributed System
Scenario: A microservices application running on Kubernetes needs to secure inter-service communication and user access.
-
Identity Verification:
- Use an Identity Provider (IdP) like Keycloak to manage user identities.
- Services authenticate using JWT tokens issued by the IdP.
-
Microsegmentation:
- Define Kubernetes Network Policies to allow only specific pods to communicate.
-
Encrypted Communication:
- Deploy a service mesh like Istio to enable mTLS between services automatically.
-
Access Control:
- Apply RBAC policies within Kubernetes to restrict access to resources.
-
Monitoring:
- Use Istio telemetry along with Prometheus and Grafana dashboards to monitor traffic and detect anomalies.
Example YAML snippet for a Kubernetes Network Policy:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-frontend-to-backend
namespace: production
spec:
podSelector:
matchLabels:
app: backend
ingress:
- from:
- podSelector:
matchLabels:
app: frontend
ports:
- protocol: TCP
port: 8080
This policy ensures only pods labeled frontend can access the backend pods on port 8080.
Example: Mutual TLS (mTLS) Between Microservices
Concept: Both client and server authenticate each other using certificates, preventing unauthorized access.
Implementation Steps:
- Generate certificates for each microservice.
- Configure services to require client certificates.
- Use a service mesh (e.g., Istio) to automate certificate management and enforce mTLS.
Benefits:
- Prevents man-in-the-middle attacks.
- Ensures encrypted and authenticated communication.
Challenges and Best Practices
Summary
Implementing Zero Trust Architecture in distributed systems requires a holistic approach covering identity, network segmentation, encrypted communication, access control, and continuous monitoring. Leveraging modern tools like service meshes, IAM platforms, and automated policy management helps enforce Zero Trust principles effectively.
References & Further Reading
- NIST Zero Trust Architecture (SP 800-207): https://csrc.nist.gov/publications/detail/sp/800-207/final
- Istio Service Mesh: https://istio.io/latest/docs/concepts/security/
- Kubernetes Network Policies: https://kubernetes.io/docs/concepts/services-networking/network-policies/
- OAuth 2.0 and OpenID Connect: https://oauth.net/2/
- Keycloak Identity and Access Management: https://www.keycloak.org/
6.4 Secrets Management: Vaults and Encryption Techniques
Managing secrets securely is a critical aspect of distributed systems and cloud native application design. Secrets include sensitive data such as API keys, passwords, certificates, and encryption keys. Improper handling can lead to security breaches, data leaks, and compliance violations.
Why Secrets Management Matters
- Secrets are often embedded in code or configuration files, increasing risk.
- Distributed systems increase the attack surface due to multiple services communicating.
- Cloud environments require dynamic, scalable, and secure secret handling.
Core Principles of Secrets Management
- Least Privilege Access: Only authorized entities can access secrets.
- Encryption at Rest and in Transit: Secrets must be encrypted everywhere.
- Audit and Monitoring: Track access and changes to secrets.
- Automated Rotation: Regularly update secrets to reduce exposure.
Mind Map: Secrets Management Overview
Vaults: Centralized Secret Storage
Vaults provide a secure, centralized system to store, access, and manage secrets.
Example: HashiCorp Vault
- Dynamic Secrets: Generates secrets on-demand (e.g., database credentials).
- Leases and Renewal: Secrets have TTLs and can be revoked.
- Encryption as a Service: Vault can encrypt/decrypt data without storing it.
- Access Policies: Fine-grained control over who can access what.
Example Use Case: Dynamic Database Credentials
# Request dynamic credentials from Vault
vault read database/creds/my-role
This returns a username and password valid for a limited time, reducing risk from leaked static credentials.
Encryption Techniques
Encryption at Rest
- Secrets stored in vaults or databases must be encrypted using strong algorithms (e.g., AES-256).
- Cloud providers often offer built-in encryption for storage services.
Encryption in Transit
- Use TLS/SSL to protect secrets when transmitted between services and vaults.
- Mutual TLS (mTLS) can be used for stronger authentication.
Mind Map: Encryption Techniques
Best Practices with Examples
| Practice | Description | Example |
|---|---|---|
| Use Vaults for Secret Storage | Centralize secrets to reduce sprawl and improve control | HashiCorp Vault integrated with Kubernetes using Vault Agent injector |
| Implement RBAC and IAM Policies | Restrict secret access to only necessary services and users | AWS IAM policies granting Lambda functions access to specific secrets |
| Encrypt Secrets at Rest | Ensure secrets are encrypted when stored | Enable AWS KMS encryption for Secrets Manager secrets |
| Encrypt Secrets in Transit | Use TLS/mTLS for all secret transmissions | Configure Vault and clients to communicate over TLS with client certificates |
| Automate Secret Rotation | Regularly rotate secrets to minimize exposure | Use Vault’s dynamic secrets for databases or scheduled rotation of API keys |
| Audit Access and Usage | Monitor and log all secret access events | Enable Vault audit devices and integrate with SIEM tools |
Example: Integrating Vault with Kubernetes
- Deploy Vault: Run Vault server with storage backend (e.g., Consul).
- Configure Kubernetes Auth: Enable Kubernetes auth method in Vault.
- Define Policies: Create Vault policies restricting secret access.
- Inject Secrets: Use Vault Agent Injector to inject secrets as environment variables or files.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
template:
metadata:
annotations:
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/role: "my-app-role"
vault.hashicorp.com/agent-inject-secret-config: "secret/data/my-app/config"
spec:
containers:
- name: app
image: my-app-image
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: vault-secret
key: password
This approach avoids storing secrets in Kubernetes manifests or container images.
Summary
Secrets management is foundational for secure distributed and cloud native systems. Leveraging vaults and strong encryption techniques, combined with strict access controls, automated rotation, and auditing, helps protect sensitive data and maintain compliance.
Further Reading
- HashiCorp Vault Documentation
- AWS Secrets Manager Best Practices
- Kubernetes Secrets Management
- NIST Guidelines on Managing Secrets
6.5 Threat Modeling and Penetration Testing for Cloud Native Apps
Introduction
Threat modeling and penetration testing are critical components of securing cloud native applications. As these applications are distributed, dynamic, and often ephemeral, traditional security approaches must evolve to address unique cloud native challenges. This section covers practical methodologies, mind maps to visualize threat landscapes, and examples to help architects and engineers build secure cloud native solutions.
What is Threat Modeling?
Threat modeling is a structured approach to identifying, enumerating, and prioritizing potential threats to a system. It helps teams anticipate security risks early in the design phase and implement mitigations proactively.
Key Goals:
- Identify assets and entry points
- Understand attacker capabilities and motivations
- Enumerate potential threats and vulnerabilities
- Prioritize risks based on impact and likelihood
Mind Map: Threat Modeling Process
STRIDE Threat Model Framework
A widely used model for categorizing threats is STRIDE:
| Threat Type | Description | Example in Cloud Native Context |
|---|---|---|
| Spoofing | Pretending to be something or someone else | Fake service identity to access APIs |
| Tampering | Modifying data or code unauthorized | Altering container images |
| Repudiation | Denying an action without proof | User denies performing a transaction |
| Information Disclosure | Exposing information to unauthorized parties | Leaking secrets through logs |
| Denial of Service | Exhausting resources to deny service | Overloading API gateway |
| Elevation of Privilege | Gaining higher access than authorized | Exploiting misconfigured RBAC in Kubernetes |
Example: Threat Modeling a Cloud Native Microservices App
Consider an e-commerce platform composed of microservices:
- User Service
- Order Service
- Payment Service
- Inventory Service
Step 1: Define Scope
- Focus on Order and Payment Services
Step 2: Identify Assets
- Customer payment data
- Order details
Step 3: Architecture Diagram
- Services communicate via REST APIs
- Authentication via OAuth 2.0 tokens
Step 4: Identify Threats (using STRIDE)
- Spoofing: Attacker impersonates Order Service to Payment Service
- Tampering: Altering order data in transit
- Information Disclosure: Payment data logged in plaintext
Step 5: Prioritize
- Payment data exposure has highest impact
Step 6: Mitigations
- Mutual TLS between services
- Encrypt sensitive data at rest and in transit
- Implement strict logging policies
What is Penetration Testing?
Penetration testing (pen testing) is a simulated cyberattack against your application to identify exploitable vulnerabilities. It complements threat modeling by validating security controls in practice.
Types of Penetration Testing for Cloud Native Apps
- Network Penetration Testing: Test network boundaries, firewall rules, and service exposure.
- API Penetration Testing: Test REST/gRPC endpoints for injection, authentication bypass, etc.
- Container Security Testing: Check container images for vulnerabilities, misconfigurations.
- Kubernetes Security Testing: Validate RBAC, pod security policies, and cluster configurations.
- CI/CD Pipeline Testing: Assess pipeline security to prevent supply chain attacks.
Mind Map: Penetration Testing Workflow
Example: Penetration Testing a Kubernetes Cluster
Scenario: A cloud native app deployed on Kubernetes with multiple microservices.
Step 1: Reconnaissance
- Use tools like
kubectl(with limited permissions) andkube-hunterto discover exposed services and misconfigurations.
Step 2: Vulnerability Analysis
- Scan container images with tools like
Trivyto find outdated packages. - Check for overly permissive RBAC roles.
Step 3: Exploitation
- Exploit a misconfigured service account to gain access to secrets.
- Use compromised credentials to access other pods.
Step 4: Post-Exploitation
- Extract sensitive environment variables.
- Attempt lateral movement within the cluster.
Step 5: Reporting
- Document all findings with severity levels.
- Provide actionable recommendations such as tightening RBAC, enabling network policies, and scanning images regularly.
Best Practices for Threat Modeling and Penetration Testing in Cloud Native Apps
- Integrate Early and Often: Conduct threat modeling during design and update regularly.
- Automate Scanning: Use CI/CD integrated tools for vulnerability scanning.
- Use Realistic Test Environments: Mirror production as closely as possible.
- Leverage Open Source Tools: Examples include OWASP Threat Dragon for modeling, and
kube-hunter,Trivy,Metasploitfor testing. - Collaborate Across Teams: Security, development, and operations should work together.
- Document and Track: Maintain clear records of threats and test results.
Summary
Threat modeling and penetration testing are indispensable for securing cloud native applications. By systematically identifying threats and validating defenses through testing, teams can reduce risk and build resilient systems. The mind maps and examples provided offer practical guidance to embed security deeply into your cloud native architecture.
6.6 Compliance and Governance: Practical Frameworks and Tools
In distributed systems and cloud native applications, compliance and governance are critical to ensure that systems meet legal, regulatory, and organizational standards. This section explores practical frameworks and tools that help architects and engineers build compliant and well-governed systems, with examples and mind maps to clarify concepts.
Why Compliance and Governance Matter
- Protect sensitive data and maintain privacy
- Avoid legal penalties and fines
- Build customer trust and brand reputation
- Ensure operational consistency and risk management
Key Compliance Frameworks for Cloud Native and Distributed Systems
GDPR (General Data Protection Regulation)
- Focus: Data privacy and protection for EU citizens
- Requirements: Data minimization, consent, right to be forgotten, breach notification
HIPAA (Health Insurance Portability and Accountability Act)
- Focus: Protecting healthcare data in the US
- Requirements: Access controls, audit trails, encryption, risk analysis
SOC 2 (System and Organization Controls)
- Focus: Security, availability, processing integrity, confidentiality, privacy
- Requirements: Policies, monitoring, incident response, vendor management
PCI DSS (Payment Card Industry Data Security Standard)
- Focus: Protecting payment card data
- Requirements: Network security, encryption, access control, vulnerability management
ISO/IEC 27001
- Focus: Information security management systems (ISMS)
- Requirements: Risk assessment, controls, continuous improvement
Practical Governance Frameworks
- Cloud Security Alliance (CSA) Cloud Controls Matrix (CCM): Provides a controls framework tailored for cloud providers and consumers.
- NIST Cybersecurity Framework: Risk-based approach to managing cybersecurity risks.
- COBIT (Control Objectives for Information and Related Technologies): IT governance and management framework.
Mind Map: Compliance and Governance Overview
Tools to Implement Compliance and Governance
| Tool Category | Examples | Description & Use Case |
|---|---|---|
| Policy as Code | Open Policy Agent (OPA), HashiCorp Sentinel | Define and enforce compliance policies programmatically across infrastructure and applications. Example: OPA enforces Kubernetes pod security policies automatically during deployment. |
| Compliance Scanning | Prisma Cloud, Aqua Security, Cloud Custodian | Automated scanning of cloud resources for compliance violations. Example: Cloud Custodian can shut down non-compliant S3 buckets that are publicly accessible. |
| Audit Logging & Monitoring | ELK Stack, Splunk, AWS CloudTrail | Collect and analyze logs for audit trails and anomaly detection. Example: AWS CloudTrail logs API calls to track user activity for SOC 2 audits. |
| Encryption & Key Management | HashiCorp Vault, AWS KMS, Azure Key Vault | Securely manage secrets and encryption keys. Example: Vault dynamically generates database credentials to minimize exposure. |
Example: Implementing GDPR Compliance with OPA and Kubernetes
- Define a policy to restrict deployment of pods that do not encrypt data at rest.
- Write OPA Rego policy that denies pods without volume encryption annotations.
- Integrate OPA as an admission controller in Kubernetes to enforce the policy.
- Monitor violations via audit logs and alert security teams.
This approach ensures automated compliance enforcement and reduces manual errors.
Mind Map: Policy as Code Workflow
Best Practices for Compliance and Governance
- Shift Left Compliance: Integrate compliance checks early in the development lifecycle.
- Automate Wherever Possible: Use tools to automatically enforce policies and detect violations.
- Maintain Comprehensive Audit Trails: Ensure all access and changes are logged and immutable.
- Regularly Update Policies: Reflect changes in regulations and business requirements.
- Train Teams: Educate developers and operators on compliance responsibilities.
Summary
Compliance and governance in distributed systems and cloud native applications require a combination of well-established frameworks, automated tools, and best practices. By embedding compliance into the architecture and development processes, teams can reduce risks, ensure regulatory adherence, and maintain trust with users and stakeholders.
7. Deployment Strategies and Continuous Delivery
7.1 Blue-Green and Canary Deployments Explained with Examples
Introduction
In modern cloud native application development, deployment strategies play a crucial role in ensuring minimal downtime, reducing risk, and enabling smooth rollouts of new features or fixes. Two of the most popular deployment strategies are Blue-Green Deployment and Canary Deployment. Both approaches help teams achieve continuous delivery with high availability and reliability.
Blue-Green Deployment
Blue-Green Deployment is a technique that reduces downtime and risk by running two identical production environments called Blue and Green. At any time, only one environment (say Blue) is live and serving all production traffic. The new version of the application is deployed to the inactive environment (Green). Once the new version is tested and verified, traffic is switched from Blue to Green.
Key Benefits
- Instant rollback by switching traffic back to the old environment
- Zero downtime deployments
- Easy to test new versions in production-like environment
Mind Map: Blue-Green Deployment
Example Scenario
Imagine an e-commerce platform currently running version 1.0 on the Blue environment. The team develops version 2.0 and deploys it to the Green environment. After running smoke tests and verifying performance, the load balancer is updated to route all user traffic to Green. If any critical issues are detected, traffic can be switched back to Blue immediately.
Sample Implementation with Kubernetes
- Two identical Kubernetes namespaces or clusters:
blueandgreen - Deploy version 1.0 to
bluenamespace - Deploy version 2.0 to
greennamespace - Use a Kubernetes Service or Ingress to route traffic
- Switch service selector from
bluepods togreenpods
apiVersion: v1
kind: Service
metadata:
name: frontend-service
spec:
selector:
app: frontend
version: blue # Change to green to switch
ports:
- protocol: TCP
port: 80
targetPort: 8080
Canary Deployment
Canary Deployment is a strategy where the new version of an application is gradually rolled out to a small subset of users before being fully deployed. This allows teams to monitor the new version’s behavior with real user traffic and detect issues early.
Key Benefits
- Reduced risk by limiting exposure of new changes
- Real user feedback before full rollout
- Ability to incrementally increase traffic to new version
Mind Map: Canary Deployment
Example Scenario
A video streaming service wants to release a new recommendation algorithm. Instead of deploying to all users, they route 5% of traffic to the new version (canary). They monitor CPU usage, error rates, and user engagement. If metrics are stable, they increase to 25%, then 50%, and finally 100%. If any problem arises, they immediately stop routing traffic to the canary version.
Sample Implementation with Istio Service Mesh
Istio supports weighted routing to implement canary deployments easily.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: frontend
spec:
hosts:
- frontend.example.com
http:
- route:
- destination:
host: frontend
subset: v1
weight: 90
- destination:
host: frontend
subset: v2
weight: 10
In this example, 10% of traffic is routed to version 2 (canary), and 90% to version 1.
Comparison: Blue-Green vs Canary
| Aspect | Blue-Green Deployment | Canary Deployment |
|---|---|---|
| Traffic Switch | Instant switch from old to new environment | Gradual traffic shifting to new version |
| Rollback Speed | Immediate rollback by switching environments | Rollback by stopping canary traffic |
| Risk Level | Medium (all users switched at once) | Low (small user subset exposed initially) |
| Infrastructure Cost | Requires duplicate environments | Usually single environment with routing |
| Use Cases | Large updates, zero downtime requirements | Feature releases, incremental testing |
Best Practices
-
Blue-Green:
- Automate environment provisioning to reduce cost
- Use health checks before switching traffic
- Monitor both environments during switch
-
Canary:
- Define clear metrics and alerting
- Automate traffic shifting based on success criteria
- Use feature flags to control exposure
Summary
Both Blue-Green and Canary deployments are powerful strategies that help cloud architects and engineers deliver updates safely and reliably. Choosing the right strategy depends on your application’s requirements, infrastructure, and risk tolerance.
Additional Resources
- Martin Fowler on Blue-Green Deployment
- Canary Releases with Kubernetes and Istio
- Continuous Delivery Patterns
7.2 Continuous Integration and Continuous Deployment (CI/CD) Pipelines
Continuous Integration (CI) and Continuous Deployment (CD) are fundamental practices in modern software development, especially for distributed systems and cloud native applications. They enable teams to deliver code changes more frequently, reliably, and with higher quality.
What is CI/CD?
- Continuous Integration (CI): The practice of automatically integrating code changes from multiple contributors into a shared repository several times a day. Each integration is verified by an automated build and automated tests.
- Continuous Deployment (CD): The practice of automatically deploying every change that passes the automated tests to production or staging environments.
Benefits of CI/CD in Distributed Systems and Cloud Native Apps
- Faster feedback loops
- Reduced integration problems
- Improved code quality
- Automated deployments reduce human error
- Enables rapid iteration and innovation
Core Components of a CI/CD Pipeline
Example: Simple CI/CD Pipeline with GitHub Actions
name: CI/CD Pipeline
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
- name: Build with Maven
run: mvn clean install
- name: Run Unit Tests
run: mvn test
docker:
needs: build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker Image
run: |
docker build -t myapp:${{ github.sha }} .
- name: Log in to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: Push Docker Image
run: |
docker push myapp:${{ github.sha }}
deploy:
needs: docker
runs-on: ubuntu-latest
steps:
- name: Deploy to Kubernetes
uses: azure/k8s-deploy@v3
with:
manifests: |
./k8s/deployment.yaml
images: |
myapp:${{ github.sha }}
Best Practices for CI/CD Pipelines
Example: Implementing Rollbacks with Kubernetes and Helm
When deploying with Helm, you can easily rollback to a previous release if the new deployment fails.
# Deploy new release
helm upgrade --install myapp ./chart --set image.tag=1.2.0
# If failure detected, rollback
helm rollback myapp 1
This rollback can be triggered automatically by monitoring tools integrated into the pipeline.
Integrating Automated Testing in CI/CD
Testing is crucial to ensure reliability in distributed systems.
Example: Running integration tests in a pipeline step:
- name: Run Integration Tests
run: |
./gradlew integrationTest
Example: Multi-Environment Deployment Pipeline
Example GitHub Actions snippet for manual approval before production deployment:
jobs:
deploy-prod:
needs: deploy-staging
runs-on: ubuntu-latest
if: github.event_name == 'workflow_dispatch'
steps:
- name: Deploy to Production
run: |
kubectl apply -f ./k8s/prod-deployment.yaml
Summary
CI/CD pipelines are essential for accelerating delivery and improving reliability in distributed systems and cloud native applications. By automating builds, tests, and deployments, teams can reduce errors, increase deployment frequency, and maintain high quality. Incorporating best practices such as automated rollbacks, secure secrets management, and multi-environment deployments ensures robust and scalable pipelines.
Further Reading & Tools
- Jenkins, GitHub Actions, GitLab CI, CircleCI
- Helm for Kubernetes deployments
- SonarQube for code quality
- Prometheus and Grafana for monitoring pipeline health
- HashiCorp Vault for secrets management
7.3 Infrastructure as Code (IaC) with Terraform and CloudFormation
Infrastructure as Code (IaC) is a foundational practice in modern cloud native application design and distributed systems architecture. It allows you to define and provision infrastructure through machine-readable configuration files, enabling automation, repeatability, and version control.
What is Infrastructure as Code?
IaC means managing and provisioning computing infrastructure through code instead of manual processes. This approach brings software engineering practices such as testing, versioning, and collaboration to infrastructure management.
Why Use IaC?
- Consistency: Avoid configuration drift by applying the same code repeatedly.
- Automation: Reduce manual errors and speed up deployments.
- Version Control: Track changes, rollbacks, and audits.
- Collaboration: Teams can review and improve infrastructure code.
Popular IaC Tools: Terraform and CloudFormation
| Feature | Terraform | CloudFormation |
|---|---|---|
| Provider Support | Multi-cloud (AWS, Azure, GCP, etc.) | AWS only |
| Language | HashiCorp Configuration Language (HCL) | JSON or YAML |
| State Management | Remote or local state files | Managed by AWS |
| Modularity | Modules | Nested stacks |
| Community & Ecosystem | Large, active community | AWS native integration |
Mind Map: Key Concepts of IaC
Terraform: Hands-On Example
Let’s create a simple AWS EC2 instance using Terraform.
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0" # Amazon Linux 2 AMI
instance_type = "t2.micro"
tags = {
Name = "TerraformExampleInstance"
}
}
Steps to deploy:
- Initialize Terraform:
terraform init - Preview changes:
terraform plan - Apply changes:
terraform apply
Best Practice: Use variables for AMI and instance type to make the code reusable.
variable "region" {
default = "us-east-1"
}
variable "instance_type" {
default = "t2.micro"
}
provider "aws" {
region = var.region
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = var.instance_type
tags = {
Name = "TerraformExampleInstance"
}
}
CloudFormation: Equivalent Example
CloudFormation template in YAML to create an EC2 instance:
AWSTemplateFormatVersion: '2010-09-09'
Description: Simple EC2 instance
Resources:
ExampleInstance:
Type: 'AWS::EC2::Instance'
Properties:
ImageId: ami-0c55b159cbfafe1f0
InstanceType: t2.micro
Tags:
- Key: Name
Value: CloudFormationExampleInstance
Deploying:
- Use AWS Console or AWS CLI:
aws cloudformation deploy --template-file template.yaml --stack-name example-stack
Best Practice: Use Parameters section to make templates reusable.
Parameters:
InstanceType:
Type: String
Default: t2.micro
Resources:
ExampleInstance:
Type: 'AWS::EC2::Instance'
Properties:
ImageId: ami-0c55b159cbfafe1f0
InstanceType: !Ref InstanceType
Tags:
- Key: Name
Value: CloudFormationExampleInstance
Mind Map: Terraform vs CloudFormation
Best Practices for IaC
- Version Control: Store IaC code in Git repositories.
- Modularization: Break infrastructure into reusable modules or nested stacks.
- State Management: Use remote backends (e.g., S3 + DynamoDB for Terraform) to avoid state conflicts.
- Security: Avoid hardcoding secrets; use vaults or AWS Secrets Manager.
- Testing: Use tools like
terraform validate,terraform fmt, and CloudFormation Linter. - Automation: Integrate IaC deployment into CI/CD pipelines.
Example: Modular Terraform Code for VPC and EC2
VPC module (modules/vpc/main.tf):
resource "aws_vpc" "main" {
cidr_block = var.cidr_block
tags = {
Name = var.vpc_name
}
}
variable "cidr_block" {}
variable "vpc_name" {}
Root module:
module "vpc" {
source = "./modules/vpc"
cidr_block = "10.0.0.0/16"
vpc_name = "MyVPC"
}
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
subnet_id = module.vpc.public_subnet_id
tags = {
Name = "WebServer"
}
}
This modular approach improves maintainability and reuse.
Summary
Infrastructure as Code with Terraform and CloudFormation empowers cloud architects and engineers to manage infrastructure reliably and efficiently. By adopting best practices such as modularization, version control, and automation, teams can reduce errors, accelerate deployments, and maintain consistent environments.
7.4 Automated Testing Strategies for Distributed and Cloud Native Apps
Automated testing is a cornerstone of reliable, maintainable, and scalable distributed systems and cloud native applications. Given the complexity and dynamic nature of these environments, traditional testing approaches must evolve to address challenges such as service dependencies, network variability, and asynchronous communication.
Key Testing Types in Distributed and Cloud Native Contexts
- Unit Testing: Validates individual components or functions in isolation.
- Integration Testing: Ensures that multiple components or services work together correctly.
- Contract Testing: Verifies that service interfaces adhere to agreed contracts.
- End-to-End (E2E) Testing: Tests complete workflows across the system.
- Chaos Testing: Introduces failures to test system resilience.
- Performance Testing: Measures responsiveness and stability under load.
- Security Testing: Validates security controls and vulnerabilities.
Mind Map: Automated Testing Strategies Overview
Unit Testing in Distributed Systems
Best Practice: Isolate components using mocks or stubs to simulate dependencies.
Example: In a microservice that processes orders, mock the payment gateway API to test order validation logic without external calls.
# Example using pytest and unittest.mock
from unittest.mock import Mock
def test_order_validation():
payment_gateway = Mock()
payment_gateway.process_payment.return_value = True
order_service = OrderService(payment_gateway)
assert order_service.validate_order(order_data) == True
Integration Testing with Service Virtualization
Best Practice: Use lightweight containers or service mocks to simulate dependent services.
Example: Use Testcontainers to spin up a temporary Redis instance for testing caching behavior.
// Example using Testcontainers in Java
public class CacheIntegrationTest {
@Container
public GenericContainer redis = new GenericContainer("redis:5.0.3-alpine").withExposedPorts(6379);
@Test
public void testCachePutAndGet() {
String address = redis.getHost() + ":" + redis.getFirstMappedPort();
Cache cache = new RedisCache(address);
cache.put("key", "value");
assertEquals("value", cache.get("key"));
}
}
Contract Testing for Service Interoperability
Best Practice: Use consumer-driven contracts to ensure backward-compatible API changes.
Example: Using Pact to define expected interactions between a frontend and a backend service.
// Pact contract example snippet
{
"consumer": { "name": "FrontendApp" },
"provider": { "name": "OrderService" },
"interactions": [
{
"description": "a request to create an order",
"request": {
"method": "POST",
"path": "/orders",
"body": { "item": "book", "quantity": 1 }
},
"response": {
"status": 201,
"body": { "orderId": 123 }
}
}
]
}
End-to-End Testing for User Journeys
Best Practice: Automate workflows that span multiple services and user interactions.
Example: Using Cypress to automate a user login and purchase flow in a cloud native e-commerce app.
// Cypress test example
describe('E-commerce purchase flow', () => {
it('logs in and completes purchase', () => {
cy.visit('/login');
cy.get('#username').type('user1');
cy.get('#password').type('password');
cy.get('button[type=submit]').click();
cy.url().should('include', '/dashboard');
cy.visit('/products/123');
cy.get('button.add-to-cart').click();
cy.visit('/cart');
cy.get('button.checkout').click();
cy.get('button.confirm').click();
cy.contains('Thank you for your purchase');
});
});
Chaos Testing to Validate Resilience
Best Practice: Introduce controlled failures to verify system behavior under stress.
Example: Using Chaos Monkey to randomly terminate instances in a Kubernetes cluster and observe recovery.
# Example Chaos Monkey command to kill a pod
kubectl delete pod <pod-name> -n <namespace>
Monitor system logs and alerts to ensure failover mechanisms activate correctly.
Performance Testing with Load Simulation
Best Practice: Simulate realistic traffic patterns to identify bottlenecks.
Example: Using Apache JMeter to simulate 1000 concurrent users hitting a REST API.
<!-- JMeter test plan snippet -->
<ThreadGroup guiclass="ThreadGroupGui" testclass="ThreadGroup" testname="Load Test" enabled="true">
<stringProp name="ThreadGroup.num_threads">1000</stringProp>
<stringProp name="ThreadGroup.ramp_time">60</stringProp>
<HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="API Request" enabled="true">
<stringProp name="HTTPSampler.domain">api.example.com</stringProp>
<stringProp name="HTTPSampler.path">/orders</stringProp>
<stringProp name="HTTPSampler.method">GET</stringProp>
</HTTPSamplerProxy>
</ThreadGroup>
Security Testing Automation
Best Practice: Integrate static code analysis and dynamic scanning into CI/CD pipelines.
Example: Using OWASP ZAP in automated scans for REST APIs.
# Run OWASP ZAP baseline scan
zap-baseline.py -t https://api.example.com -r zap_report.html
Mind Map: Automated Testing Workflow in Cloud Native Apps
Summary
Automated testing in distributed and cloud native systems demands a multi-layered approach that covers everything from isolated units to full system workflows and resilience under failure. Leveraging modern tools and best practices ensures high quality, reliability, and faster delivery cycles.
By integrating these strategies into your development lifecycle, you can confidently build and operate complex distributed applications that meet business and technical requirements.
7.5 Rollback and Recovery Procedures in Production Environments
In distributed systems and cloud native applications, rollback and recovery procedures are critical to maintaining system stability and minimizing downtime during failures or faulty deployments. This section covers best practices, strategies, and practical examples to implement effective rollback and recovery mechanisms.
Understanding Rollback and Recovery
- Rollback: The process of reverting an application or service to a previous stable state after a failed deployment or detected issue.
- Recovery: The broader process of restoring system functionality after failures, which may include rollback, data restoration, and system healing.
Key Principles for Rollback and Recovery
- Automate Rollbacks: Manual rollbacks are error-prone and slow. Automate rollback triggers based on health checks and monitoring.
- Maintain Backward Compatibility: Design deployments so that new versions can coexist with old ones during rollback.
- Data Consistency: Ensure that rollback does not corrupt data or leave the system in an inconsistent state.
- Test Rollback Procedures: Regularly test rollback and recovery in staging environments.
Common Rollback Strategies
Blue-Green Deployment Rollback
- Maintain two identical environments: Blue (current live) and Green (new version).
- Switch traffic from Blue to Green during deployment.
- If issues arise, switch back to Blue instantly.
Example:
Canary Deployment Rollback
- Deploy new version to a small subset of users.
- Monitor metrics and errors.
- Rollback by redirecting traffic back to stable version if anomalies detected.
Example:
Database Rollbacks
- Use database migration tools with reversible scripts.
- Backup data before applying schema changes.
- Rollback by applying down migrations and restoring backups if needed.
Example:
Automated Rollback with Kubernetes
Kubernetes supports automated rollback via deployments.
- Use
kubectl rollout undo deployment/<deployment-name>to rollback. - Configure readiness and liveness probes to detect unhealthy pods.
- Use deployment strategies like RollingUpdate with maxUnavailable and maxSurge settings.
Example:
# Rollback to previous revision
kubectl rollout undo deployment/my-app
# Check rollout status
kubectl rollout status deployment/my-app
Mindmap:
Recovery Procedures
- Incident Detection: Use monitoring tools (Prometheus, Datadog) and alerting.
- Isolation: Isolate faulty components or services.
- Rollback: Trigger automated/manual rollback.
- Data Recovery: Restore from backups or replay event logs.
- Postmortem: Analyze root cause and improve processes.
Practical Example: Rollback Scenario in a Microservices Architecture
Imagine a microservices-based e-commerce platform where a new version of the payment service is deployed.
- Deployment uses canary strategy with 5% traffic.
- Monitoring detects increased error rates and latency.
- Automated rollback triggers, redirecting all traffic to the previous stable version.
- Database schema changes are backward compatible; no rollback needed.
- Postmortem identifies a bug in the new payment logic.
Mindmap:
Summary Checklist for Rollback and Recovery
- Automate rollback triggers based on health metrics
- Use deployment strategies that support easy rollback (blue-green, canary)
- Ensure backward compatibility for data and APIs
- Test rollback procedures regularly
- Maintain reliable backups and migration scripts
- Monitor continuously and alert proactively
- Document and rehearse recovery runbooks
By integrating these rollback and recovery practices into your production workflows, you can significantly reduce downtime and improve the reliability of your distributed and cloud native applications.
7.6 Managing Multi-Cloud and Hybrid Cloud Deployments
Managing multi-cloud and hybrid cloud deployments has become a critical skill for cloud solutions architects and senior software engineers aiming to leverage the best of multiple cloud providers or combine on-premises infrastructure with public clouds. This section explores best practices, challenges, and practical examples to help you design, deploy, and maintain robust multi-cloud and hybrid cloud architectures.
Understanding Multi-Cloud vs Hybrid Cloud
- Multi-Cloud: Utilization of two or more public cloud providers (e.g., AWS, Azure, GCP) to avoid vendor lock-in, optimize costs, or leverage specific services.
- Hybrid Cloud: Integration of on-premises infrastructure (private cloud or data center) with public cloud resources, enabling workload portability and data sovereignty.
Key Benefits
- Resilience and Redundancy: Avoid single points of failure by distributing workloads.
- Cost Optimization: Leverage competitive pricing and spot instances.
- Regulatory Compliance: Keep sensitive data on-premises while using cloud for scalability.
- Flexibility: Use best-of-breed services from different providers.
Challenges
- Complexity in networking and security.
- Data consistency and synchronization.
- Unified monitoring and management.
- Deployment and automation across heterogeneous environments.
Best Practices
Unified Networking and Connectivity
- Use VPNs, dedicated interconnects (e.g., AWS Direct Connect, Azure ExpressRoute), or SD-WAN solutions.
- Example: Establish a secure IPSec VPN tunnel between on-premises data center and AWS VPC, and a separate tunnel to Azure Virtual Network, enabling seamless communication.
Centralized Identity and Access Management (IAM)
- Implement federated identity with tools like Azure AD, AWS IAM Identity Center, or open standards like SAML/OAuth.
- Example: Use Azure AD as a central identity provider to manage user access across AWS and on-premises resources.
Infrastructure as Code (IaC) for Multi-Cloud
- Use tools like Terraform or Pulumi that support multiple cloud providers.
- Example: Define AWS EC2 instances and Azure VMs in a single Terraform configuration, enabling consistent provisioning.
Containerization and Orchestration
- Deploy containerized workloads using Kubernetes clusters that span multiple clouds or integrate on-premises clusters.
- Example: Use Anthos or Rancher to manage Kubernetes clusters across GCP, AWS, and on-premises.
Data Management and Synchronization
- Use data replication tools or distributed databases that support multi-region/multi-cloud setups.
- Example: Employ Apache Cassandra or CockroachDB for globally distributed data with eventual consistency.
Monitoring and Logging
- Centralize logs and metrics using tools like Prometheus, Grafana, or cloud-native solutions (e.g., AWS CloudWatch, Azure Monitor) aggregated via ELK stack or Splunk.
Security and Compliance
- Apply consistent security policies using tools like HashiCorp Vault for secrets management.
- Implement Zero Trust principles across environments.
Mind Map: Multi-Cloud and Hybrid Cloud Deployment Considerations
Example Scenario: Deploying a Multi-Cloud Web Application
Context: A retail company wants to deploy a web application with front-end services on AWS for global reach, back-end APIs on Azure for integration with Microsoft services, and sensitive customer data stored on-premises for compliance.
Implementation Steps:
- Networking: Set up VPN tunnels between on-premises data center, AWS VPC, and Azure VNet.
- Identity: Use Azure AD to federate user access across all environments.
- IaC: Use Terraform to provision AWS EC2 instances for front-end, Azure App Services for APIs, and configure on-premises VMs.
- Containers: Package APIs in Docker containers orchestrated by Azure Kubernetes Service (AKS).
- Data: Store sensitive data in on-premises SQL Server with secure replication to Azure SQL Database for reporting.
- Monitoring: Aggregate logs from AWS CloudWatch, Azure Monitor, and on-premises Splunk into a central dashboard.
- Security: Manage secrets with HashiCorp Vault deployed on-premises and synchronized with cloud environments.
Example Code Snippet: Terraform Multi-Cloud Resource Provisioning
provider "aws" {
region = "us-east-1"
}
provider "azurerm" {
features = {}
}
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.micro"
tags = {
Name = "AWS-Web-Server"
}
}
resource "azurerm_resource_group" "rg" {
name = "example-resources"
location = "East US"
}
resource "azurerm_app_service_plan" "asp" {
name = "example-appserviceplan"
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
sku {
tier = "Basic"
size = "B1"
}
}
resource "azurerm_app_service" "app" {
name = "example-appservice"
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
app_service_plan_id = azurerm_app_service_plan.asp.id
}
Summary
Managing multi-cloud and hybrid cloud deployments requires a holistic approach that covers networking, identity, infrastructure automation, data consistency, security, and monitoring. Leveraging container orchestration and IaC tools simplifies deployment complexity, while centralized security and monitoring ensure operational excellence. By following these best practices and learning from real-world examples, cloud architects and engineers can build resilient, scalable, and compliant distributed systems across diverse environments.
8. Performance Optimization and Cost Management
8.1 Profiling and Benchmarking Distributed Systems
Profiling and benchmarking are critical activities in the lifecycle of distributed systems. These processes help architects and engineers understand system behavior under various loads, identify bottlenecks, and optimize performance for scalability and reliability.
What is Profiling?
Profiling is the process of measuring the behavior of a system, focusing on resource usage such as CPU, memory, network, and I/O. It helps pinpoint inefficient code paths, resource leaks, or contention points.
What is Benchmarking?
Benchmarking involves running a set of standardized tests to evaluate the performance of a system or component under controlled conditions. It provides quantitative metrics like throughput, latency, and error rates.
Why Profiling and Benchmarking Matter in Distributed Systems
- Complexity: Distributed systems consist of multiple interacting components, making it challenging to isolate performance issues.
- Network Overhead: Latency and bandwidth can significantly impact system responsiveness.
- Concurrency: Multiple nodes/processes working in parallel require careful synchronization and resource management.
- Scalability: Understanding how performance scales with load is essential for capacity planning.
Key Metrics to Profile and Benchmark
- Latency: Time taken to process a request.
- Throughput: Number of requests processed per unit time.
- Resource Utilization: CPU, memory, disk I/O, and network usage.
- Error Rate: Frequency of failures or exceptions.
- Garbage Collection (GC) Impact: Pauses affecting latency.
Profiling Techniques and Tools
CPU and Memory Profiling
- Example Tool:
perf(Linux), VisualVM (Java),pprof(Go) - Example: Profiling a microservice to find a CPU-intensive JSON serialization step.
Distributed Tracing
- Example Tool: Jaeger, Zipkin, OpenTelemetry
- Example: Tracing a request through multiple microservices to identify latency hotspots.
Network Profiling
- Example Tool: Wireshark, tcpdump
- Example: Detecting packet loss or retransmissions causing delays.
Application Logs and Metrics
- Example Tool: Prometheus, Grafana
- Example: Monitoring request rates and error counts to correlate with performance dips.
Benchmarking Strategies
Load Testing
- Simulate expected and peak loads to observe system behavior.
- Example Tool: Apache JMeter, Locust, Gatling
Stress Testing
- Push the system beyond its limits to identify breaking points.
- Example: Increasing concurrent users until response time degrades beyond SLA.
Soak Testing
- Run the system under load for extended periods to detect memory leaks or degradation.
Component-Level Benchmarking
- Isolate components (e.g., database, cache) to benchmark independently.
Mind Map: Profiling and Benchmarking Workflow
Example: Profiling a Distributed E-commerce Checkout Service
Scenario: Users report slow checkout times during peak hours.
Steps:
- Distributed Tracing: Use Jaeger to trace checkout requests. Identify that the payment service is taking longer than expected.
- CPU Profiling: Profile the payment service using
pprofand find excessive CPU usage during encryption. - Network Profiling: Check network latency between payment and inventory services; find no significant delays.
- Load Testing: Simulate peak traffic with Locust to reproduce the issue.
Outcome: Optimized encryption algorithm and introduced caching for payment tokens, reducing latency by 40%.
Best Practices
- Profile in Production-like Environments: Avoid profiling only in development; real workloads reveal true bottlenecks.
- Use Distributed Tracing Early: Instrument services from the start to gain visibility.
- Automate Benchmarking: Integrate load tests into CI/CD pipelines.
- Correlate Metrics: Combine logs, traces, and metrics for holistic analysis.
- Iterate: Profiling and benchmarking should be continuous activities.
Summary
Profiling and benchmarking distributed systems require a combination of tools and strategies to capture the complex interactions and resource usage patterns. By systematically applying these techniques, cloud solutions architects and senior engineers can optimize system performance, ensure scalability, and maintain reliability under varying loads.
8.2 Autoscaling Strategies and Resource Optimization
Autoscaling and resource optimization are critical components in managing distributed systems and cloud native applications efficiently. They ensure that your application can handle varying loads without over-provisioning resources, which helps control costs and maintain performance.
What is Autoscaling?
Autoscaling is the process of automatically adjusting the number of compute resources (e.g., virtual machines, containers) based on current demand. It helps maintain application availability and performance while optimizing costs.
Key Autoscaling Strategies
Horizontal Scaling (Scale Out/In)
- Adding or removing instances of a service or application.
- Common in microservices and containerized environments.
Vertical Scaling (Scale Up/Down)
- Increasing or decreasing the resource capacity (CPU, memory) of a single instance.
- Limited by the maximum capacity of the underlying hardware.
Scheduled Scaling
- Scaling based on known usage patterns (e.g., business hours).
- Reduces latency in scaling actions.
Predictive Scaling
- Uses machine learning or historical data to anticipate demand and scale proactively.
Reactive Scaling
- Responds to real-time metrics like CPU usage, memory consumption, or request rates.
Autoscaling Metrics
Common metrics used to trigger autoscaling:
- CPU Utilization
- Memory Usage
- Request Rate / Throughput
- Latency / Response Time
- Custom Application Metrics (e.g., queue length)
Autoscaling in Kubernetes: A Practical Example
Kubernetes supports autoscaling through the Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler.
Example: Horizontal Pod Autoscaler (HPA)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: frontend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
This configuration scales the “frontend” deployment pods between 2 and 10 replicas based on CPU utilization, targeting 50% average CPU use.
Resource Optimization Best Practices
- Right-sizing Resources: Continuously monitor and adjust resource requests and limits to avoid over-provisioning.
- Use Spot Instances or Preemptible VMs: For non-critical workloads to reduce costs.
- Leverage Serverless Architectures: Where applicable, to abstract away infrastructure management.
- Implement Efficient Load Balancing: To distribute traffic evenly and avoid hotspots.
- Optimize Application Code: To reduce CPU and memory consumption.
Mind Map: Autoscaling Strategies Overview
Mind Map: Resource Optimization Techniques
Example Scenario: Autoscaling a Web Application
Context: A retail web application experiences high traffic spikes during sales events.
Challenge: Maintain responsiveness without paying for idle resources during off-peak hours.
Solution:
- Use Kubernetes HPA to scale pods based on CPU and request rate.
- Implement scheduled scaling to increase minimum replicas during expected peak hours.
- Use predictive scaling with historical sales data to pre-scale before events.
- Optimize backend services to reduce resource consumption.
Outcome:
- The application scales out automatically during spikes, maintaining low latency.
- Costs are minimized by scaling in during quiet periods.
Summary
Autoscaling and resource optimization are vital for building resilient, cost-effective distributed systems and cloud native applications. By combining multiple strategies and continuously monitoring your workloads, you can achieve a balance between performance and cost-efficiency.
References & Tools
- Kubernetes Autoscaling Documentation: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- AWS Auto Scaling: https://aws.amazon.com/autoscaling/
- Google Cloud Autoscaler: https://cloud.google.com/compute/docs/autoscaler
- Prometheus & Grafana for monitoring metrics
- KEDA (Kubernetes Event-driven Autoscaling) for event-based scaling
8.3 Caching Patterns and CDN Integration for Cloud Native Apps
Caching is a critical technique to improve the performance, scalability, and user experience of cloud native applications. By temporarily storing frequently accessed data closer to the user or application, caching reduces latency, lowers backend load, and optimizes resource utilization.
Key Caching Patterns
Below is a mind map illustrating common caching patterns used in distributed and cloud native systems:
Caching Patterns Mind Map
Best Practices with Examples
Cache Aside Pattern (Lazy Loading)
Description: The application first tries to read data from the cache. If the data is not present (cache miss), it fetches from the database, then populates the cache.
Example:
import redis
cache = redis.Redis(host='localhost', port=6379)
def get_user_profile(user_id):
cache_key = f'user_profile:{user_id}'
profile = cache.get(cache_key)
if profile:
return profile # Cache hit
# Cache miss - fetch from DB
profile = fetch_profile_from_db(user_id)
cache.set(cache_key, profile, ex=3600) # Cache for 1 hour
return profile
Best Practice: Set appropriate TTL (time-to-live) to avoid stale data.
Write-Through Cache
Description: Writes are synchronously sent to both cache and database, ensuring strong consistency.
Example:
def update_user_profile(user_id, new_data):
cache_key = f'user_profile:{user_id}'
# Update DB
update_profile_in_db(user_id, new_data)
# Update cache
cache.set(cache_key, new_data, ex=3600)
Best Practice: Use when data consistency is critical.
CDN Integration
Content Delivery Networks (CDNs) cache static and dynamic content geographically closer to end users, reducing latency and bandwidth usage.
Example Use Case: Serving images, videos, CSS, JS files for a global web application.
Popular CDNs: Cloudflare, AWS CloudFront, Akamai, Fastly
CDN Integration Mind Map
CDN Integration Mind Map
Example: Using AWS CloudFront with S3
- Host static assets (images, CSS, JS) in an S3 bucket.
- Create a CloudFront distribution pointing to the S3 bucket as origin.
- Configure cache behaviors and TTLs.
- Use cache invalidation to refresh content after updates.
Sample CloudFront Cache-Control Header:
Cache-Control: max-age=86400, public
This tells the CDN and browsers to cache the content for 24 hours.
Combining Caching Patterns and CDN
For cloud native apps, combining backend caching (e.g., Redis) with CDN caching creates a layered caching strategy:
- Edge Layer: CDN caches static assets and API responses close to users.
- Application Layer: Redis or Memcached caches frequently accessed data.
- Database Layer: Persistent storage with fallback on cache misses.
Example Architecture:
Summary
- Choose caching patterns based on consistency and performance needs.
- Use TTLs and cache invalidation to manage data freshness.
- Integrate CDNs to reduce latency and offload origin servers.
- Monitor cache hit ratios and tune caching strategies accordingly.
By thoughtfully applying caching patterns and CDN integration, cloud native applications can achieve high performance, scalability, and reliability.
8.4 Cost Monitoring and Optimization in Cloud Environments
Cloud cost management is a critical aspect of running distributed systems and cloud native applications efficiently. Without proper monitoring and optimization, cloud expenses can spiral out of control, impacting budgets and project viability. This section covers best practices, tools, and real-world examples to help you gain visibility into your cloud spend and optimize costs effectively.
Why Cost Monitoring Matters
- Cloud resources are billed based on usage — compute hours, storage, network bandwidth, API calls, etc.
- Unmonitored resources lead to “cloud waste” — paying for idle or underutilized services.
- Cost spikes can indicate misconfigurations, inefficient architectures, or security issues.
Key Concepts in Cloud Cost Monitoring
Best Practices for Cost Monitoring
-
Implement Resource Tagging
- Tag resources by project, team, environment (dev, staging, prod).
- Example: Tag EC2 instances with
Environment=ProductionandTeam=Payments. - Enables granular cost allocation and accountability.
-
Use Cloud Provider Native Cost Tools
- AWS Cost Explorer, Azure Cost Management, Google Cloud Billing Reports.
- Set up budgets and alerts to detect overspending early.
-
Leverage Third-Party Cost Management Platforms
- Tools like CloudHealth, Cloudability, or Kubecost provide multi-cloud visibility.
- Example: Kubecost integrates with Kubernetes to monitor pod-level costs.
-
Establish Regular Cost Reviews
- Schedule monthly or quarterly reviews with stakeholders.
- Identify trends, anomalies, and optimization opportunities.
Cost Optimization Strategies
Example 1: Rightsizing Compute Resources
Scenario: A SaaS company notices high AWS EC2 costs.
Action: Using AWS Cost Explorer and CloudWatch metrics, they identify several m5.large instances running at 10-20% CPU utilization.
Optimization: They downsize these instances to t3.medium, saving approximately 50% on compute costs without impacting performance.
Result: Monthly compute spend reduced by $5,000.
Example 2: Leveraging Spot Instances
Scenario: A data processing pipeline runs batch jobs that are fault tolerant.
Action: The engineering team configures Kubernetes to use AWS Spot Instances for worker nodes.
Optimization: Spot Instances provide up to 70-90% discount compared to on-demand.
Result: Batch processing costs drop significantly, enabling more frequent data refreshes within budget.
Example 3: Storage Lifecycle Policies
Scenario: A media company stores large volumes of user-uploaded videos.
Action: They implement S3 lifecycle policies to transition videos older than 30 days to S3 Glacier.
Optimization: Glacier storage is much cheaper for infrequently accessed data.
Result: Storage costs decrease by 60%, with minimal impact on user experience.
Monitoring Tools Overview
| Tool | Description | Example Use Case |
|---|---|---|
| AWS Cost Explorer | Native AWS cost visualization and analysis | Track EC2 and RDS spend trends |
| Azure Cost Management | Azure’s integrated cost monitoring | Budget alerts for resource groups |
| Google Cloud Billing Reports | GCP’s cost breakdown and forecasting | Analyze BigQuery query costs |
| Kubecost | Kubernetes cost monitoring and allocation | Pod-level cost visibility in EKS clusters |
| CloudHealth | Multi-cloud cost management platform | Enterprise-wide cost governance |
Setting Up Alerts for Cost Anomalies
- Define budgets per project or environment.
- Configure alerts to notify teams when spend exceeds thresholds.
- Example: Alert sent to Slack channel if daily spend exceeds $1,000.
Summary
Effective cost monitoring and optimization require a combination of tooling, process, and culture. By implementing tagging, leveraging native and third-party tools, and applying optimization strategies like rightsizing and spot instances, organizations can significantly reduce cloud spend while maintaining performance and reliability.
Additional Resources
- AWS Well-Architected Framework - Cost Optimization Pillar
- Google Cloud Cost Management Best Practices
- Kubecost Documentation
- Azure Cost Management and Billing
8.5 Load Testing and Stress Testing with Practical Tools
Load testing and stress testing are critical to ensure that distributed systems and cloud native applications perform reliably under expected and extreme conditions. This section covers the concepts, best practices, and practical tools with examples to help you design effective testing strategies.
What is Load Testing?
Load testing evaluates how a system behaves under expected user loads. It helps identify bottlenecks and ensures the system can handle anticipated traffic.
What is Stress Testing?
Stress testing pushes the system beyond normal operational capacity to observe how it behaves under extreme conditions, including failure modes.
Mind Map: Load Testing vs Stress Testing
Key Metrics to Monitor
- Throughput: Number of requests processed per second.
- Response Time: Time taken to respond to a request.
- Error Rate: Percentage of failed requests.
- CPU/Memory Usage: Resource consumption during tests.
- Latency: Delay between request and response.
Best Practices for Load and Stress Testing
- Define realistic scenarios: Model user behavior accurately.
- Start small, then scale: Gradually increase load to identify thresholds.
- Test in production-like environments: Avoid discrepancies.
- Monitor system health: Use observability tools alongside tests.
- Automate tests: Integrate into CI/CD pipelines.
- Analyze and iterate: Use results to optimize architecture.
Practical Tools and Examples
Apache JMeter
- Open-source load testing tool.
- Supports HTTP, HTTPS, SOAP, REST, and more.
Example: Load testing a REST API endpoint.
# Create a test plan with 100 users ramping up over 1 minute
# Sample JMeter CLI command to run the test
jmeter -n -t load_test_plan.jmx -l results.jtl
Sample JMeter Test Plan Snippet:
<ThreadGroup guiclass="ThreadGroupGui" testclass="ThreadGroup" testname="Load Test Group" enabled="true">
<stringProp name="ThreadGroup.num_threads">100</stringProp>
<stringProp name="ThreadGroup.ramp_time">60</stringProp>
<boolProp name="ThreadGroup.scheduler">false</boolProp>
</ThreadGroup>
Locust
- Python-based, easy to write test scenarios.
- Supports distributed load generation.
Example: Simulate 50 users hitting an API.
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
@task
def index(self):
self.client.get("/")
Run with:
locust -f locustfile.py --users 50 --spawn-rate 5
k6
- Modern CLI tool for load testing with scripting in JavaScript.
- Integrates well with CI/CD.
Example: Stress test with increasing virtual users.
import http from 'k6/http';
import { sleep } from 'k6';
export let options = {
stages: [
{ duration: '1m', target: 20 },
{ duration: '2m', target: 50 },
{ duration: '1m', target: 0 },
],
};
export default function () {
http.get('https://api.example.com/data');
sleep(1);
}
Run with:
k6 run script.js
Mind Map: Load Testing Workflow
Integrating Load Testing in CI/CD Pipelines
- Automate tests using Jenkins, GitLab CI, or GitHub Actions.
- Example: Run k6 tests post-deployment and fail builds on SLA breaches.
# GitHub Actions snippet
name: Load Test
on: [push]
jobs:
load_test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Run k6 Load Test
run: |
k6 run script.js
Handling Distributed Systems Specific Challenges
- Simulate multi-region traffic.
- Test service dependencies and cascading failures.
- Use chaos engineering tools (e.g., Chaos Monkey) alongside stress tests.
Summary
Load and stress testing are indispensable for building resilient distributed and cloud native applications. By leveraging practical tools like JMeter, Locust, and k6, and following best practices, architects and engineers can ensure their systems meet performance expectations and gracefully handle failures.
8.6 Balancing Performance and Reliability: Trade-offs and Examples
Balancing performance and reliability is a critical challenge in designing distributed systems and cloud native applications. Optimizing for one often impacts the other, and understanding these trade-offs is essential for building robust, efficient systems.
Understanding the Trade-offs
- Performance focuses on system responsiveness and throughput.
- Reliability emphasizes system availability, fault tolerance, and correctness.
Improving performance might involve aggressive caching or reduced consistency guarantees, which can reduce reliability. Conversely, prioritizing reliability often requires redundancy and consistency checks that can degrade performance.
Mind Map: Balancing Performance and Reliability
Key Trade-offs Explained
Consistency vs Latency
- Example: In a distributed database, choosing strong consistency ensures all nodes see the same data but increases latency due to coordination overhead.
- Practice: Use eventual consistency for read-heavy workloads where slight data staleness is acceptable (e.g., social media feeds).
Redundancy vs Cost
- Example: Replicating services across multiple regions improves availability but increases infrastructure costs.
- Practice: Employ multi-region failover only for critical services; use single-region for less critical components.
Caching vs Data Freshness
- Example: Caching improves read performance but risks serving stale data.
- Practice: Implement cache invalidation strategies like TTL (time-to-live) or event-driven cache updates.
Failover Speed vs System Complexity
- Example: Fast failover mechanisms reduce downtime but add complexity to the system design.
- Practice: Use automated health checks and circuit breakers to balance failover speed and maintainability.
Practical Examples
Example 1: E-commerce Checkout System
- Challenge: Ensure reliable order processing while maintaining low latency.
- Approach:
- Use a message queue to decouple order placement from payment processing (improves reliability).
- Employ idempotent payment APIs to handle retries without duplicate charges.
- Cache product availability with short TTL to reduce latency but validate inventory during checkout to ensure accuracy.
Example 2: Real-time Messaging Platform
- Challenge: Deliver messages with minimal delay while ensuring message durability.
- Approach:
- Use in-memory caching for recent messages to reduce latency.
- Persist messages asynchronously to durable storage to maintain reliability.
- Implement backpressure and circuit breakers to handle load spikes gracefully.
Example 3: Financial Transaction Processing
- Challenge: Guarantee transaction correctness and availability.
- Approach:
- Use strong consistency models for transaction data.
- Employ synchronous replication with quorum writes to ensure durability.
- Accept higher latency as a trade-off for absolute reliability.
Strategies to Balance Performance and Reliability
- Graceful Degradation: Design systems to reduce functionality under load instead of failing completely.
- Circuit Breakers: Prevent cascading failures by stopping requests to failing services.
- Idempotent Operations: Allow safe retries without side effects.
- Retry Policies: Implement exponential backoff to avoid overwhelming services.
- Autoscaling: Dynamically adjust resources to meet demand without over-provisioning.
Mind Map: Strategies for Balancing
Summary
Balancing performance and reliability requires a deep understanding of system requirements and workload characteristics. By carefully evaluating trade-offs and applying best practices such as graceful degradation, circuit breakers, and appropriate consistency models, architects and engineers can design distributed systems and cloud native applications that meet both performance and reliability goals.
References and Further Reading
- “Designing Data-Intensive Applications” by Martin Kleppmann
- “Site Reliability Engineering” by Google
- Kubernetes Patterns: “Circuit Breaker” and “Retry” patterns
- Cloud provider documentation on autoscaling and failover best practices
9. Case Studies and Real-World Implementations
9.1 Building a Scalable E-Commerce Platform Using Microservices
Introduction
Building a scalable e-commerce platform is a classic use case for microservices architecture. Microservices enable modular, independently deployable components that can scale based on demand, improving fault isolation and accelerating development cycles.
In this section, we’ll explore how to design and implement a scalable e-commerce platform using microservices, weaving in best practices and real-world examples.
Key Microservices Components for an E-Commerce Platform
Best Practice: Single Responsibility Principle
Each microservice should have a single responsibility. For example, the ProductService handles only product-related data and logic, while OrderService manages order lifecycle.
Example:
- ProductService exposes APIs like
/products,/products/{id},/products/{id}/inventory. - OrderService exposes
/orders,/orders/{id},/orders/{id}/status.
This separation allows independent scaling and deployment.
Designing for Scalability
Horizontal Scaling:
- Each microservice can be deployed in multiple instances behind a load balancer.
- For example, during a sale, OrderService instances can be increased to handle order spikes.
Example:
- Kubernetes Deployment with replicas set to 5 for OrderService during peak hours.
Caching:
- Use caching layers (e.g., Redis) in front of ProductService to reduce database load.
Communication Patterns
Synchronous Communication: REST or gRPC calls for request-response interactions.
Example:
- CartService calls ProductService to validate product availability before adding to cart.
Asynchronous Communication: Event-driven architecture using message brokers (e.g., Kafka, RabbitMQ).
Example:
- OrderService publishes an
OrderPlacedevent. - NotificationService subscribes to send confirmation emails.
Data Management
Each microservice owns its own database to ensure loose coupling.
Example:
- ProductService uses a NoSQL database like MongoDB for flexible product schemas.
- OrderService uses a relational database like PostgreSQL for transactional integrity.
Best Practice: Avoid direct database sharing between services to prevent tight coupling.
Handling Transactions Across Microservices
Distributed transactions are challenging. Use Saga pattern to manage eventual consistency.
Example:
- When placing an order:
- OrderService creates an order with status “Pending”.
- InventoryService reserves stock.
- PaymentService processes payment.
- OrderService updates order status to “Confirmed” or “Failed”.
If any step fails, compensating transactions roll back previous steps.
Fault Tolerance and Resilience
Circuit Breaker Pattern: Prevent cascading failures.
Example:
- If ProductService is down, CartService returns cached product info or a friendly error.
Retries with Exponential Backoff:
- Automatically retry failed requests with increasing delay.
Bulkheads:
- Isolate microservices so failure in one does not impact others.
Deployment Example
Using Kubernetes:
- Each microservice is containerized with Docker.
- Deployments and Services manage scaling and load balancing.
- Use Helm charts for templated deployments.
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service
spec:
replicas: 3
selector:
matchLabels:
app: order-service
template:
metadata:
labels:
app: order-service
spec:
containers:
- name: order-service
image: myrepo/order-service:latest
ports:
- containerPort: 8080
Monitoring and Observability
Best Practice: Implement centralized logging, metrics, and tracing.
Example Tools:
- Prometheus for metrics collection.
- Grafana for dashboards.
- Jaeger for distributed tracing.
Trace a user placing an order across services to identify bottlenecks.
Security Considerations
- Use OAuth2 / OpenID Connect for authentication.
- Secure inter-service communication with mutual TLS.
- Validate and sanitize all inputs to prevent injection attacks.
Summary
Building a scalable e-commerce platform with microservices involves careful design of service boundaries, communication patterns, data management, and deployment strategies. By applying best practices such as single responsibility, asynchronous communication, and fault tolerance, you can create a resilient and scalable system.
Additional Resources
- Microservices Patterns by Chris Richardson
- The Twelve-Factor App
- Kubernetes Official Documentation
This completes the detailed guide on building a scalable e-commerce platform using microservices.
9.2 Designing a Real-Time Analytics Pipeline with Event Streaming
Introduction
Real-time analytics pipelines enable organizations to process and analyze data streams as they are generated, providing immediate insights and enabling rapid decision-making. Event streaming platforms like Apache Kafka, Apache Pulsar, and AWS Kinesis have become foundational technologies for building such pipelines.
In this section, we will explore the architecture, best practices, and practical examples for designing a robust real-time analytics pipeline using event streaming.
Mind Map: Real-Time Analytics Pipeline Components
Step 1: Identify Data Sources
Best Practice: Clearly define and categorize your data sources to ensure proper ingestion and schema management.
Example: An e-commerce platform collects clickstream data from its website, transaction events from its payment system, and inventory updates from its warehouse management system.
Step 2: Choose an Event Streaming Platform
Best Practice: Select a platform that supports high throughput, low latency, scalability, and fault tolerance.
Example: Using Apache Kafka for its mature ecosystem and rich client APIs.
Step 3: Define Event Schemas and Serialization
Best Practice: Use schema registries (e.g., Confluent Schema Registry) and serialization formats like Avro or Protobuf to enforce schema evolution and compatibility.
Example: Define an Avro schema for user click events with fields like userId, timestamp, pageUrl, and actionType.
Step 4: Implement Stream Processing
Best Practice: Perform transformations, enrichments, filtering, and aggregations in the stream processing layer.
Example: Using Kafka Streams to aggregate page views per user every minute.
Code Snippet:
KStream<String, ClickEvent> clickStream = builder.stream("click-events");
KTable<Windowed<String>, Long> pageViews = clickStream
.groupBy((key, value) -> value.getUserId())
.windowedBy(TimeWindows.of(Duration.ofMinutes(1)))
.count();
pageViews.toStream().to("user-pageviews", Produced.with(WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long()));
Step 5: Data Storage and Serving Layer
Best Practice: Store processed data in scalable storage systems optimized for analytical queries.
Example: Store aggregated results in Amazon Redshift for BI tools to query.
Step 6: Visualization and Alerting
Best Practice: Integrate with visualization tools and set up alerts for anomalies or threshold breaches.
Example: Use Grafana dashboards connected to Prometheus metrics and Kafka consumer lag monitoring.
Mind Map: Event Streaming Pipeline Data Flow
Example: Real-Time Fraud Detection Pipeline
Scenario: Detect fraudulent transactions in real-time for a payment processing system.
- Data Sources: Transaction events from payment gateways.
- Event Streaming: Apache Kafka topics for transaction events.
- Stream Processing: Apache Flink job that applies machine learning models to score transactions.
- Storage: Fraud alerts stored in Cassandra for quick lookup.
- Visualization: Kibana dashboards for fraud analysts.
Key Practices:
- Use windowed joins to correlate transactions with historical user behavior.
- Implement exactly-once processing semantics to avoid duplicate alerts.
- Monitor processing latency to ensure real-time constraints.
Best Practices Summary
- Schema Evolution: Use schema registries to manage changes without breaking consumers.
- Idempotency: Design producers and processors to handle retries safely.
- Backpressure Handling: Ensure stream processors can handle spikes gracefully.
- Security: Encrypt data in transit and at rest; authenticate producers and consumers.
- Monitoring: Track consumer lag, throughput, and error rates continuously.
Conclusion
Designing a real-time analytics pipeline with event streaming requires careful consideration of data sources, streaming platform capabilities, processing frameworks, and storage solutions. By following best practices and leveraging mature tools, architects and engineers can build scalable, fault-tolerant, and insightful analytics systems that drive business value.
References
- Apache Kafka Documentation: https://kafka.apache.org/documentation/
- Confluent Schema Registry: https://docs.confluent.io/platform/current/schema-registry/index.html
- Apache Flink: https://flink.apache.org/
- Kafka Streams API: https://kafka.apache.org/documentation/streams/
- Real-Time Analytics Patterns: https://martinfowler.com/articles/real-time-streaming.html
9.3 Migrating Legacy Systems to Cloud Native Architectures
Migrating legacy systems to cloud native architectures is a critical step for organizations aiming to leverage the scalability, flexibility, and resilience of modern cloud environments. This section provides a comprehensive guide on how to approach such migrations, integrating best practices with easy-to-understand examples and mind maps to visualize the process.
Understanding Legacy Systems
Legacy systems are often monolithic, tightly coupled applications running on on-premises infrastructure. They typically have:
- Large codebases
- Complex dependencies
- Limited scalability
- Manual deployment processes
Migrating these systems requires careful planning to avoid downtime and data loss.
Migration Strategies
There are several strategies to migrate legacy systems to cloud native architectures:
- Rehost (Lift and Shift): Move the application as-is to the cloud.
- Replatform: Make minimal changes to optimize for the cloud.
- Refactor/Re-architect: Redesign the application to be cloud native.
- Replace: Swap the legacy system with a new cloud native solution.
Mind Map: Migration Strategies
Best Practices for Migration
Assess and Analyze
- Inventory existing applications and dependencies.
- Identify components suitable for cloud native redesign.
- Evaluate data storage and integration points.
Define Clear Objectives
- Performance improvements
- Cost optimization
- Scalability and availability
Incremental Migration
- Migrate components in phases.
- Use strangler pattern to gradually replace legacy parts.
Automate Deployments
- Implement CI/CD pipelines.
- Use Infrastructure as Code (IaC) tools.
Monitor and Optimize
- Implement observability from day one.
- Continuously optimize based on metrics.
Example: Migrating a Monolithic E-Commerce Application
Step 1: Assessment
- Monolith handles product catalog, orders, payments.
- Runs on on-premises VMs.
- Database is a single SQL Server instance.
Step 2: Choose Strategy
- Refactor to microservices for scalability and agility.
Step 3: Decompose Monolith
- Extract product catalog service.
- Extract order management service.
- Extract payment processing service.
Step 4: Containerize Services
- Use Docker to containerize each microservice.
Step 5: Orchestrate with Kubernetes
- Deploy containers on a managed Kubernetes cluster.
Step 6: Migrate Database
- Move to cloud managed database (e.g., Amazon RDS).
- Use database per service pattern where feasible.
Step 7: Implement CI/CD
- Automate build, test, and deployment pipelines.
Step 8: Monitor and Iterate
- Use Prometheus and Grafana for monitoring.
- Optimize based on performance data.
Mind Map: E-Commerce Migration Example
Tools and Technologies
- Containers: Docker
- Orchestration: Kubernetes, OpenShift
- CI/CD: Jenkins, GitLab CI, GitHub Actions
- IaC: Terraform, AWS CloudFormation
- Monitoring: Prometheus, Grafana, ELK Stack
- Messaging: Kafka, RabbitMQ (for decoupling services)
Common Challenges and Solutions
Summary
Migrating legacy systems to cloud native architectures is a journey that requires strategic planning, phased execution, and continuous improvement. By leveraging best practices such as incremental migration, containerization, orchestration, and automation, organizations can modernize their applications effectively while minimizing risk.
For further reading, refer to:
- The Twelve-Factor App
- Cloud Native Computing Foundation (CNCF) Resources
- AWS Migration Hub
9.4 Implementing a Global Distributed Database with Multi-Region Replication
Introduction
Implementing a global distributed database with multi-region replication is a critical architectural choice for applications that demand high availability, low latency, and disaster recovery across geographically dispersed users. This section explores best practices, architectural patterns, and practical examples to help cloud solutions architects and senior software engineers design and implement such systems effectively.
Why Multi-Region Replication?
- Low Latency Access: Serve users from the nearest region to reduce read/write latency.
- High Availability: Maintain uptime even if one region fails.
- Disaster Recovery: Data redundancy across regions protects against data loss.
- Compliance: Some regulations require data residency in specific regions.
Key Concepts and Terminology
- Replication: Copying data from one database node to another.
- Multi-Region: Deploying database nodes in multiple geographic regions.
- Consistency Models: Trade-offs between strong consistency and eventual consistency.
- Conflict Resolution: Handling data conflicts that arise from concurrent writes.
Mind Map: Core Components of Multi-Region Distributed Database
Replication Strategies
Synchronous Replication
- Writes are committed to multiple regions before acknowledging success.
- Guarantees strong consistency.
- Higher write latency due to network delays.
Asynchronous Replication
- Writes are committed locally and propagated to other regions later.
- Lower latency but eventual consistency.
Example: Using Amazon Aurora Global Database
- Aurora replicates data across multiple AWS regions asynchronously.
- Provides low-latency reads in secondary regions.
# Example Aurora Global Database setup snippet
GlobalCluster:
Type: AWS::RDS::GlobalCluster
Properties:
GlobalClusterIdentifier: my-global-db
SourceDBClusterIdentifier: arn:aws:rds:us-east-1:123456789012:cluster:primary-db
Consistency Models and Their Trade-offs
| Model | Description | Use Cases | Pros | Cons |
|---|---|---|---|---|
| Strong Consistency | All reads see the latest write | Financial transactions, inventory | Data correctness guaranteed | Higher latency |
| Eventual Consistency | Reads may see stale data temporarily | Social media feeds, caching | Low latency, high availability | Possible stale reads |
| Causal Consistency | Preserves cause-effect relationships | Collaborative apps | Balance between strong and eventual | More complex implementation |
Conflict Resolution Techniques
- Last Write Wins (LWW): Simplest approach; the latest timestamped write wins.
- Vector Clocks: Track causality between updates to detect conflicts.
- Application-Level Resolution: Business logic resolves conflicts (e.g., merging shopping cart items).
Example: Conflict Resolution Using Vector Clocks in a Shopping Cart Application
class VectorClock:
def __init__(self):
self.clock = {}
def update(self, node_id):
self.clock[node_id] = self.clock.get(node_id, 0) + 1
def compare(self, other):
# Returns -1 if self < other, 0 if equal, 1 if self > other, None if concurrent
less = False
greater = False
for node in set(self.clock.keys()).union(other.clock.keys()):
self_val = self.clock.get(node, 0)
other_val = other.clock.get(node, 0)
if self_val < other_val:
less = True
elif self_val > other_val:
greater = True
if less and not greater:
return -1
elif greater and not less:
return 1
elif not less and not greater:
return 0
else:
return None # concurrent updates
# Usage example
vc1 = VectorClock()
vc1.update('region1')
vc2 = VectorClock()
vc2.update('region2')
result = vc1.compare(vc2)
if result is None:
print('Conflict detected, apply merge logic')
Partitioning and Geo-Partitioning
- Sharding: Splitting data horizontally by key range or hash.
- Geo-Partitioning: Data is partitioned by geographic region to localize reads/writes.
Example:
- User data for Europe stored in EU region shard.
- User data for Asia stored in Asia region shard.
Practical Example: Multi-Region Replication with Cassandra
Apache Cassandra supports multi-region replication with tunable consistency.
- Define keyspaces with replication strategy:
CREATE KEYSPACE user_data WITH replication = {
'class': 'NetworkTopologyStrategy',
'us_east': 3,
'eu_west': 3
};
- Read/write consistency levels:
LOCAL_QUORUMfor low latency within regionQUORUMfor cross-region consistency
Failover and Disaster Recovery
- Automatic failover to secondary regions.
- Backup and restore strategies across regions.
Example:
- Use AWS Route 53 latency-based routing to direct traffic to healthy regions.
Security Considerations
- Encrypt data at rest and in transit.
- Use IAM roles and policies to restrict access.
- Audit replication and access logs.
Monitoring and Observability
- Track replication lag metrics.
- Alert on region failures or high latency.
Example tools:
- Prometheus + Grafana for metrics visualization.
- Cloud provider native monitoring (e.g., AWS CloudWatch).
Summary Checklist
- Choose replication strategy based on consistency and latency needs.
- Design conflict resolution mechanisms.
- Partition data to optimize locality.
- Implement failover and disaster recovery plans.
- Secure data and access.
- Monitor replication health and performance.
Further Reading
- “Designing Data-Intensive Applications” by Martin Kleppmann
- AWS Aurora Global Database Documentation
- Apache Cassandra Multi-Region Deployment Guides
By following these guidelines and examples, architects and engineers can build robust, scalable, and resilient global distributed databases that meet the demands of modern cloud-native applications.
9.5 Securing a Financial Application in a Cloud Native Environment
Securing financial applications in a cloud native environment is a critical and complex task. These applications handle sensitive data, require compliance with stringent regulations, and must maintain high availability and integrity. This section explores best practices, strategies, and real-world examples to help architects and engineers build secure financial applications leveraging cloud native technologies.
Key Security Considerations for Financial Applications
- Data Confidentiality and Integrity
- Identity and Access Management (IAM)
- Network Security and Segmentation
- Secrets Management
- Compliance and Auditing
- Incident Response and Monitoring
Mind Map: Core Security Domains for Financial Cloud Native Apps
Data Security: Encryption and Masking
Best Practice: Encrypt all sensitive data both at rest and in transit.
Example:
- Use AWS KMS or Azure Key Vault to manage encryption keys.
- Enable TLS 1.2+ for all service-to-service communication.
Code Snippet (Kubernetes TLS Secret):
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
type: kubernetes.io/tls
stringData:
tls.crt: |-
-----BEGIN CERTIFICATE-----
...certificate data...
-----END CERTIFICATE-----
tls.key: |-
-----BEGIN PRIVATE KEY-----
...private key data...
-----END PRIVATE KEY-----
Data Masking Example:
- Mask credit card numbers in logs and UI by showing only last 4 digits.
Identity and Access Management (IAM)
Best Practice: Implement fine-grained RBAC and enforce MFA for all users.
Example:
- Use Kubernetes RBAC to restrict access to namespaces and resources.
- Integrate with cloud IAM (AWS IAM, Azure AD) for centralized identity management.
Example RBAC Role Binding:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: finance-readonly-binding
namespace: finance-app
subjects:
- kind: User
name: [email protected]
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: finance-readonly
apiGroup: rbac.authorization.k8s.io
MFA Implementation:
- Enforce MFA on cloud console and API access.
Network Security and Segmentation
Best Practice: Use network segmentation to isolate financial services.
Example:
- Deploy financial microservices in a dedicated VPC or subnet.
- Use Kubernetes Network Policies to restrict pod communication.
Example Network Policy:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-only-frontend
namespace: finance-app
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 443
Service Mesh Security:
- Implement mutual TLS (mTLS) with Istio or Linkerd to encrypt service-to-service traffic.
Secrets Management
Best Practice: Never store secrets in plaintext; use dedicated secret management tools.
Example:
- Use HashiCorp Vault or cloud-native secret stores.
- Automate secret injection into pods via CSI drivers.
Example Vault Policy:
path "secret/data/finance/*" {
capabilities = ["read"]
}
Example Kubernetes Secret Injection:
apiVersion: v1
kind: Pod
metadata:
name: finance-app
spec:
containers:
- name: app
image: finance-app:latest
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-secret
key: password
Compliance and Auditing
Best Practice: Maintain audit trails and ensure compliance with financial regulations.
Example:
- Enable audit logging on Kubernetes API server.
- Use cloud provider’s compliance tools (AWS Config, Azure Policy).
Audit Logging Example:
- Capture user actions, API calls, and system events.
Monitoring, Incident Response, and Threat Detection
Best Practice: Implement continuous monitoring and automated alerting.
Example:
- Integrate Prometheus and Grafana for metrics.
- Use ELK stack or cloud-native logging for log aggregation.
- Set up alerts for suspicious activities (e.g., multiple failed logins).
Real-World Example: Securing a Payment Processing Microservice
- Scenario: A payment microservice processes transactions and stores sensitive card data.
- Implementation:
- All card data encrypted using AWS KMS.
- Service communicates over mTLS via Istio service mesh.
- Access to the service restricted via Kubernetes RBAC and cloud IAM.
- Secrets (API keys, DB passwords) managed via HashiCorp Vault with automatic rotation.
- Network policies restrict access to only authorized frontend services.
- Audit logs collected and forwarded to a SIEM for compliance reporting.
Summary
Securing financial applications in cloud native environments requires a holistic approach that spans data protection, identity management, network security, secrets management, compliance, and monitoring. By leveraging cloud native tools and best practices, architects and engineers can build resilient, secure, and compliant financial systems that inspire trust and meet regulatory demands.
9.6 Lessons Learned from Failures and Outages in Distributed Systems
Distributed systems are inherently complex, and failures or outages are inevitable. However, these incidents provide invaluable lessons that help architects and engineers design more resilient systems. In this section, we explore common failure modes, root causes, and best practices learned from real-world outages, supported by illustrative mind maps and examples.
Common Causes of Failures in Distributed Systems
- Network Partitions
- Resource Exhaustion
- Configuration Errors
- Software Bugs
- Cascading Failures
- Data Inconsistency
- Security Breaches
Mind Map: Root Causes of Distributed System Failures
Case Study 1: Netflix Chaos Monkey and Resilience Engineering
Netflix popularized the concept of Chaos Engineering by intentionally injecting failures into their distributed system to identify weaknesses before they cause outages. Lessons learned include:
- Designing systems to fail fast and recover gracefully
- Implementing circuit breakers to prevent cascading failures
- Emphasizing automated monitoring and alerting
Example: When Chaos Monkey terminates a service instance, the system automatically reroutes traffic to healthy instances, demonstrating graceful degradation.
Case Study 2: Amazon S3 Outage (2017)
Root Cause: A simple human error during a command execution led to removal of a larger set of servers than intended, causing a cascading failure.
Lessons Learned:
- Importance of access controls and command safeguards
- Need for automated rollback mechanisms
- Criticality of redundancy and failover strategies
Example: Post-incident, Amazon implemented stricter safeguards and enhanced automation to prevent manual errors from propagating.
Mind Map: Strategies to Mitigate Failures
Best Practices Derived from Failures
-
Implement Circuit Breakers and Bulkheads
- Prevent cascading failures by isolating faults.
- Example: Netflix Hystrix library usage.
-
Design for Idempotency
- Ensure repeated requests do not cause unintended side effects.
- Example: Payment processing APIs that safely retry.
-
Use Graceful Degradation
- Allow partial functionality during outages.
- Example: Serving cached content when backend services are down.
-
Automate Recovery and Rollbacks
- Reduce human error impact.
- Example: Kubernetes automated pod restarts and rollback on failed deployments.
-
Comprehensive Monitoring and Alerting
- Detect issues early.
- Example: Using Prometheus and Grafana dashboards with alert rules.
-
Practice Chaos Engineering Regularly
- Proactively identify weaknesses.
- Example: Running Chaos Monkey in staging and production environments.
-
Implement Strong Access Controls
- Limit blast radius of human errors and attacks.
- Example: Role-Based Access Control (RBAC) in cloud environments.
Example: Handling Network Partition with the Saga Pattern
Scenario: A distributed order processing system experiences a network partition causing partial transaction failures.
Lesson: Using the Saga pattern to manage distributed transactions helps maintain data consistency by executing compensating transactions when failures occur.
Mind Map:
Summary
Failures and outages in distributed systems are inevitable but manageable. By studying past incidents, adopting resilience patterns, automating recovery, and continuously testing system robustness, architects and engineers can build systems that withstand failures gracefully.
Remember, the goal is not to eliminate failures entirely but to minimize impact and recover quickly.
Further Reading
- “Site Reliability Engineering” by Google
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Netflix Tech Blog on Chaos Engineering
- AWS Well-Architected Framework
10. Future Trends and Emerging Technologies
10.1 Serverless Architectures: Benefits and Limitations
Serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. Developers write and deploy code without worrying about the underlying infrastructure. This paradigm has gained significant traction due to its scalability, cost-effectiveness, and ease of use.
What is Serverless Architecture?
- Definition: An architecture where applications rely on third-party services or managed cloud services to handle server management tasks.
- Core Concept: Developers focus on writing functions or small units of code that execute in response to events.
- Popular Platforms: AWS Lambda, Azure Functions, Google Cloud Functions.
Mind Map: Serverless Architecture Overview
Benefits of Serverless Architectures
-
Cost Efficiency
- Pay only for actual execution time.
- No charges for idle resources.
- Example: A photo-processing app that triggers functions only when a user uploads an image, avoiding constant server costs.
-
Automatic Scalability
- Functions scale automatically based on demand.
- Example: An e-commerce site handling flash sales without manual intervention.
-
Reduced Operational Complexity
- No need to manage servers, patch OS, or handle capacity planning.
- Developers focus on business logic.
-
Faster Time to Market
- Quick deployment of individual functions.
- Easier to update and maintain small code units.
-
Event-driven Architecture
- Functions respond to events like HTTP requests, database changes, or messaging queues.
- Example: Automatically resizing images when uploaded to cloud storage.
Mind Map: Benefits of Serverless
Limitations of Serverless Architectures
-
Cold Start Latency
- Initial invocation delay when a function is not warm.
- Example: A REST API endpoint experiencing a delay on the first request after inactivity.
-
Execution Time Limits
- Functions have maximum execution durations (e.g., AWS Lambda max 15 minutes).
- Not suitable for long-running processes.
-
Vendor Lock-in
- Heavy reliance on specific cloud provider services.
- Migrating to another provider can be complex.
-
Debugging and Monitoring Challenges
- Distributed nature complicates tracing issues.
- Requires specialized tools for observability.
-
Resource Limits
- Memory, CPU, and concurrency limits may restrict workloads.
-
Complexity in State Management
- Stateless functions require external state management.
- Example: Using cloud databases or caches to maintain session data.
Mind Map: Limitations of Serverless
Practical Example: Building a Serverless Image Resizer
Scenario: A web application allows users to upload images. Each upload triggers an automatic resizing function to generate thumbnails.
- Architecture:
- User uploads image to cloud storage (e.g., AWS S3).
- Storage event triggers a Lambda function.
- Lambda resizes the image and stores thumbnails back in storage.
Benefits Illustrated:
- No servers to manage.
- Scales automatically with upload volume.
- Cost-effective since function runs only on uploads.
Limitations Encountered:
- Cold start may cause slight delay on first upload after inactivity.
- Function must complete resizing within execution time limits.
Best Practices for Serverless Architectures
- Minimize cold start impact by keeping functions warm or using provisioned concurrency.
- Design functions to be stateless and idempotent.
- Use managed services for stateful components (databases, caches).
- Monitor and log extensively using cloud-native tools.
- Modularize functions to keep them small and focused.
- Plan for vendor lock-in by abstracting cloud-specific code where possible.
Summary
Serverless architectures offer compelling benefits for building scalable, cost-effective, and maintainable cloud native applications. However, understanding their limitations and designing accordingly is crucial for success. By leveraging best practices and carefully evaluating use cases, architects and engineers can harness serverless computing to accelerate innovation and reduce operational overhead.
10.2 Service Meshes: Istio, Linkerd, and Practical Use Cases
Service meshes have emerged as a critical infrastructure layer for managing complex microservices architectures, especially in cloud native environments. They provide a dedicated infrastructure for service-to-service communication, offering features like traffic management, security, observability, and reliability without requiring changes to application code.
What is a Service Mesh?
A service mesh is an infrastructure layer that facilitates service-to-service communications in a secure, observable, and reliable way. It typically consists of a control plane and a data plane:
- Control Plane: Manages configuration and policies.
- Data Plane: Consists of lightweight proxies (sidecars) deployed alongside each service instance to intercept and manage network traffic.
Why Use a Service Mesh?
- Traffic Control: Fine-grained routing, load balancing, and failover.
- Security: Mutual TLS, authentication, and authorization between services.
- Observability: Metrics, logging, and distributed tracing.
- Resilience: Circuit breaking, retries, and timeouts.
Popular Service Meshes: Istio and Linkerd
| Feature | Istio | Linkerd |
|---|---|---|
| Architecture | Envoy-based sidecar proxy + control plane | Lightweight Rust-based proxy + control plane |
| Complexity | More feature-rich, steeper learning curve | Simpler, easier to operate |
| Security | Strong mTLS support, RBAC | mTLS by default, simple security model |
| Observability | Advanced telemetry, tracing, dashboards | Lightweight metrics and tracing |
| Extensibility | Highly extensible with Mixer adapters | Limited extensibility |
Mind Map: Service Mesh Core Components
Istio Overview
Istio uses Envoy proxies as sidecars injected alongside each microservice pod. Its control plane components include Pilot (traffic management), Citadel (security), and Mixer (policy and telemetry).
Example: Traffic Routing with Istio
Suppose you have two versions of a service reviews: v1 and v2. Istio allows you to route 90% of traffic to v1 and 10% to v2 for canary testing.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 90
- destination:
host: reviews
subset: v2
weight: 10
This example demonstrates Istio’s powerful traffic management capabilities without changing application code.
Linkerd Overview
Linkerd is designed to be lightweight and simple to operate. It automatically injects a Rust-based proxy as a sidecar and provides mTLS encryption by default.
Example: Enabling mTLS with Linkerd
Linkerd automatically encrypts service-to-service communication. To verify mTLS is enabled:
linkerd tap deploy/my-service
This command shows live traffic and confirms encrypted communication.
Mind Map: Practical Use Cases of Service Meshes
Use Case 1: Canary Deployment with Istio
Scenario: You want to deploy a new version of a payment service but only expose it to 5% of users initially.
Solution: Use Istio’s VirtualService to route 5% of traffic to the new version.
Benefits: Safe rollout, quick rollback if issues arise.
Use Case 2: Secure Service-to-Service Communication
Scenario: Your microservices handle sensitive data and require encrypted communication.
Solution: Enable mTLS with Linkerd or Istio to automatically encrypt all traffic between services.
Example: Istio’s Citadel issues certificates and manages keys transparently.
Use Case 3: Observability with Distributed Tracing
Scenario: Debugging latency issues in a microservices environment.
Solution: Use Istio’s integration with Jaeger or Linkerd’s built-in tracing to visualize request flows.
Example: Trace a request path across multiple services to identify bottlenecks.
Best Practices for Implementing Service Meshes
- Start Small: Begin with observability features before enabling complex traffic management.
- Automate Sidecar Injection: Use namespace-level automatic injection for consistency.
- Monitor Resource Usage: Sidecars add overhead; monitor CPU and memory.
- Secure Control Plane: Protect control plane components with RBAC and network policies.
- Test in Staging: Validate service mesh configurations before production rollout.
Summary
Service meshes like Istio and Linkerd provide powerful, transparent capabilities to manage microservices communication in cloud native architectures. By adopting service meshes, architects and engineers gain fine-grained control over traffic, enhanced security, deep observability, and improved resilience — all critical for modern distributed systems.
Further Reading and Tools
- Istio Documentation
- Linkerd Documentation
- Envoy Proxy
- Jaeger Tracing
- Prometheus Monitoring
10.3 Edge Computing and Its Impact on Distributed Systems Design
Introduction to Edge Computing
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the sources of data, such as IoT devices, sensors, and local edge servers. This approach reduces latency, conserves bandwidth, and enhances real-time data processing capabilities.
Why Edge Computing Matters in Distributed Systems
Traditional cloud architectures centralize processing in large data centers, which can introduce latency and bandwidth bottlenecks, especially for applications requiring real-time responsiveness or operating in bandwidth-constrained environments. Edge computing addresses these challenges by decentralizing computation, enabling faster decision-making and improved reliability.
Mind Map: Edge Computing Overview
Architectural Impact on Distributed Systems
-
Decentralization of Processing: Unlike traditional cloud-centric models, edge computing distributes processing across multiple nodes closer to data sources.
-
Data Filtering and Aggregation: Edge nodes can preprocess data to reduce the volume sent to the cloud, optimizing bandwidth and storage.
-
Latency-Sensitive Applications: Applications like autonomous driving or real-time analytics benefit from edge computing’s low-latency processing.
-
Resilience and Fault Tolerance: Edge nodes can continue operating independently during cloud outages or network disruptions.
-
Security and Privacy: Sensitive data can be processed locally, reducing exposure and compliance risks.
Mind Map: Impact on Distributed Systems Design
Best Practices for Designing Edge-Enabled Distributed Systems
-
Hybrid Architecture Design: Combine edge and cloud resources effectively. Use edge for latency-sensitive tasks and cloud for heavy processing and long-term storage.
-
Data Management Strategy: Implement data filtering, aggregation, and summarization at the edge to reduce cloud load.
-
Service Orchestration: Use container orchestration platforms that support edge deployments (e.g., K3s, OpenYurt).
-
Security Measures: Employ encryption, secure boot, and zero-trust models at edge nodes.
-
Monitoring and Observability: Implement distributed tracing and monitoring that spans edge and cloud components.
-
Resilience Planning: Design for intermittent connectivity and enable local fallback mechanisms.
Example: Smart Traffic Management System
Scenario: A city implements a smart traffic management system to optimize traffic flow and reduce congestion using edge computing.
-
Edge Components: Cameras and sensors at intersections collect real-time traffic data.
-
Edge Processing: Edge gateways analyze traffic density locally to adjust traffic lights dynamically.
-
Cloud Components: Aggregated data is sent to the cloud for historical analysis, machine learning model training, and city-wide traffic pattern prediction.
-
Benefits: Reduced latency in traffic light adjustments, lower bandwidth usage by sending only summarized data to the cloud, and improved system resilience during network outages.
Mind Map: Smart Traffic Management System
Example: Industrial IoT Predictive Maintenance
Scenario: A manufacturing plant uses edge computing to monitor equipment health and predict failures.
-
Edge Devices: Sensors on machinery collect vibration, temperature, and pressure data.
-
Edge Analytics: Edge servers run anomaly detection algorithms locally to identify potential failures.
-
Cloud Integration: Periodic summaries and alerts are sent to the cloud for centralized monitoring and long-term trend analysis.
-
Outcome: Faster detection of issues, reduced downtime, and optimized maintenance schedules.
Challenges and Considerations
-
Resource Constraints: Edge devices often have limited compute, storage, and power.
-
Network Variability: Edge nodes may face intermittent connectivity.
-
Security Risks: Distributed attack surfaces require robust security controls.
-
Management Complexity: Orchestrating and updating distributed edge nodes can be complex.
-
Data Consistency: Ensuring consistency between edge and cloud data stores can be challenging.
Summary
Edge computing fundamentally reshapes distributed systems design by pushing computation closer to data sources. It enables low-latency, bandwidth-efficient, and resilient applications, especially in IoT, real-time analytics, and latency-critical domains. Incorporating edge computing requires thoughtful architecture, security, and operational strategies to fully realize its benefits.
Further Reading & Tools
- K3s: Lightweight Kubernetes for edge computing
- OpenYurt: Kubernetes native edge computing platform
- AWS Greengrass: Edge computing service
- Azure IoT Edge: Microsoft’s edge computing solution
This section integrates best practices and real-world examples to provide a comprehensive understanding of edge computing’s role in distributed systems design.
10.4 AI and Machine Learning Integration in Cloud Native Apps
Integrating AI and Machine Learning (ML) into cloud native applications is rapidly becoming a critical capability for modern software systems. Cloud native architectures provide the scalability, flexibility, and resilience needed to deploy AI/ML workloads effectively. This section explores best practices, architectural patterns, and practical examples to seamlessly embed AI/ML into cloud native apps.
Why Integrate AI/ML in Cloud Native Apps?
- Scalability: Cloud native platforms can elastically scale AI/ML workloads based on demand.
- Resilience: Container orchestration and microservices provide fault tolerance for AI components.
- Flexibility: Decoupled services allow independent development and deployment of AI models.
- Cost Efficiency: Pay-as-you-go cloud resources optimize costs for compute-intensive AI tasks.
Key Architectural Patterns for AI/ML in Cloud Native Apps
Mind Map: AI/ML Integration Architectural Patterns
Best Practices for AI/ML Integration
-
Decouple Model Training and Inference:
- Use separate pipelines for training and serving.
- Example: Train models offline with batch jobs; deploy inference as RESTful microservices.
-
Containerize ML Models:
- Package models with dependencies in Docker containers.
- Example: Use TensorFlow Serving Docker images.
-
Use Kubernetes for Orchestration:
- Manage scaling, rolling updates, and health checks.
- Example: Deploy model microservices with Horizontal Pod Autoscaler.
-
Implement CI/CD for Models:
- Automate retraining, testing, and deployment.
- Example: Use Jenkins or GitHub Actions to trigger model retraining and deployment pipelines.
-
Monitor Model Performance:
- Track inference latency, accuracy drift, and data quality.
- Example: Use Prometheus and Grafana dashboards.
-
Secure Model APIs:
- Authenticate and authorize access to inference endpoints.
- Example: Use OAuth2 or mTLS.
Example: Deploying a Sentiment Analysis Model as a Cloud Native Microservice
-
Scenario: A cloud native e-commerce app wants to analyze customer reviews in real-time.
-
Architecture:
- Model trained offline using Python and scikit-learn.
- Model serialized and containerized using Flask API.
- Deployed on Kubernetes with autoscaling.
- Frontend sends review text to the model microservice for sentiment prediction.
Mind Map: Sentiment Analysis Microservice Architecture
Example Code Snippet: Flask API for Model Serving
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load('sentiment_model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
text = data.get('review_text', '')
# Preprocess text here
prediction = model.predict([text])
return jsonify({'sentiment': prediction[0]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Tools and Platforms Supporting AI/ML in Cloud Native Environments
Mind Map: AI/ML Tools in Cloud Native
Challenges and Mitigation Strategies
| Challenge | Mitigation Strategy | Example |
|---|---|---|
| Model Drift | Continuous monitoring and retraining | Automated retraining pipeline triggered by data drift detection |
| Latency in Real-Time Inference | Use optimized model formats (e.g., TensorRT), edge caching | Deploy lightweight models on edge devices |
| Data Privacy and Compliance | Anonymize data, use federated learning | Use differential privacy techniques in training |
Summary
Integrating AI and ML into cloud native applications unlocks powerful capabilities but requires thoughtful architecture and best practices. By leveraging containerization, orchestration, CI/CD, and monitoring, architects and engineers can build scalable, resilient, and maintainable AI-powered cloud native apps.
For further reading, explore Kubeflow for ML pipelines, Seldon Core for model serving, and cloud provider AI/ML managed services like AWS SageMaker, Google AI Platform, and Azure ML.
10.5 Quantum Computing and Its Potential Influence on Distributed Systems
Quantum computing represents a paradigm shift in computational capabilities, leveraging principles of quantum mechanics such as superposition and entanglement to solve problems that are intractable for classical computers. While still in its nascent stages, quantum computing holds promising implications for distributed systems architecture and cloud native application design.
Understanding Quantum Computing Basics
- Qubits: Unlike classical bits, qubits can exist in multiple states simultaneously (superposition).
- Entanglement: Qubits can be correlated in ways that classical bits cannot, enabling new communication protocols.
- Quantum Gates: Operations on qubits that manipulate their states.
Potential Influences on Distributed Systems
-
Quantum-enhanced Communication Protocols
- Quantum Key Distribution (QKD) for ultra-secure communication channels.
- Use of entanglement to reduce latency in synchronization across distributed nodes.
-
Optimization and Problem Solving
- Quantum algorithms (e.g., Grover’s, Shor’s) can accelerate complex computations such as routing, scheduling, and consensus.
-
New Models of Computation and Coordination
- Hybrid classical-quantum distributed systems where quantum processors handle specific tasks.
-
Security Paradigm Shifts
- Quantum computing threatens classical cryptography, necessitating quantum-resistant algorithms in distributed systems.
Mind Map: Quantum Computing Impact on Distributed Systems
Example 1: Quantum Key Distribution (QKD) in Distributed Systems
Scenario: A distributed financial application requires secure communication between geographically dispersed nodes.
Traditional Approach: Use TLS with classical cryptography.
Quantum Approach: Implement QKD protocols to exchange encryption keys securely using quantum channels.
Benefit: Any eavesdropping attempt alters the quantum state, alerting the system to a security breach.
Integration Example:
- Deploy QKD-enabled hardware links between data centers.
- Use quantum-generated keys to encrypt messages in the distributed system.
Example 2: Quantum-Assisted Optimization in Distributed Scheduling
Scenario: A cloud provider needs to optimize resource allocation across multiple data centers to minimize latency and cost.
Classical Challenge: The scheduling problem is NP-hard and computationally expensive at scale.
Quantum Solution: Use quantum annealers or gate-model quantum computers to run optimization algorithms faster.
Example Workflow:
- Encode scheduling constraints into a quantum optimization problem.
- Run the problem on a quantum processor.
- Use results to inform resource allocation decisions in the distributed system.
Mind Map: Hybrid Classical-Quantum Distributed Architecture
Challenges and Considerations
- Hardware Maturity: Quantum computers currently have limited qubits and high error rates.
- Error Correction: Quantum error correction is complex and resource-intensive.
- Integration Complexity: Combining classical distributed systems with quantum processors requires new middleware and protocols.
- Security Transition: Preparing distributed systems for a post-quantum cryptography world is critical.
Summary
Quantum computing promises transformative impacts on distributed systems, particularly in security, optimization, and communication. While practical, large-scale quantum distributed systems are still emerging, cloud architects and senior engineers should begin exploring hybrid architectures and quantum-safe designs to future-proof their systems.
Further Reading and Tools
- IBM Quantum Experience (https://quantum-computing.ibm.com/)
- Microsoft Quantum Development Kit (Q#)
- Research papers on Quantum Key Distribution and Quantum Algorithms
- NIST Post-Quantum Cryptography Standardization
10.6 Preparing for the Next Generation of Cloud Native Technologies
As cloud native technologies rapidly evolve, preparing for the next generation involves understanding emerging trends, adopting flexible architectures, and continuously upskilling. This section explores key strategies and practical examples to help Cloud Solutions Architects and Senior Software Engineers stay ahead.
Key Areas to Focus On
Embrace Serverless and Event-Driven Architectures
Serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Functions abstract infrastructure management, enabling rapid development and scaling.
Example:
A retail company implements an order processing system using AWS Lambda triggered by events on an S3 bucket (new order files). This reduces operational overhead and scales automatically with demand.
Best Practice: Design functions to be stateless and idempotent to handle retries gracefully.
Adopt Service Meshes for Advanced Traffic Management
Service meshes like Istio and Linkerd provide observability, security, and traffic control at the service-to-service communication layer.
Example:
A microservices-based fintech app uses Istio to implement canary deployments with fine-grained traffic shifting and automatic retries, improving deployment safety.
Best Practice: Start with a pilot service mesh on a small subset of services before full adoption.
Prepare for Edge Computing and Distributed Cloud
Edge computing pushes compute closer to users/devices, reducing latency and bandwidth usage.
Example:
An IoT company deploys lightweight Kubernetes clusters at edge locations to process sensor data locally, sending only aggregated results to the cloud.
Best Practice: Architect applications to gracefully handle intermittent connectivity and data synchronization.
Integrate AI/ML into Cloud Native Applications
AI/ML workloads are becoming integral to cloud applications for personalization, anomaly detection, and automation.
Example:
A streaming platform integrates a recommendation engine using TensorFlow Serving deployed on Kubernetes, scaling inference pods based on traffic.
Best Practice: Separate model training (batch jobs) from inference (real-time services) for scalability.
Embrace GitOps and Declarative Infrastructure
GitOps uses Git repositories as the single source of truth for infrastructure and application deployments, enabling automated, auditable, and repeatable operations.
Example:
A SaaS provider uses FluxCD to continuously sync Kubernetes manifests from Git, enabling rapid rollback and audit trails.
Best Practice: Enforce pull request reviews and automated testing on GitOps manifests.
Strengthen Security with Zero Trust Architecture
Zero Trust assumes no implicit trust inside or outside the network, enforcing strict identity verification.
Example:
An enterprise migrates to a zero trust model by implementing mutual TLS, identity-aware proxies, and continuous monitoring across microservices.
Best Practice: Integrate security checks into CI/CD pipelines and use automated policy enforcement.
Continuous Learning and Culture Shift
Technology evolves fast; fostering a culture of continuous learning and cross-team collaboration is essential.
Example:
Teams hold regular knowledge-sharing sessions on new cloud native tools and conduct blameless postmortems to learn from failures.
Best Practice: Invest in training, certifications, and encourage experimentation in sandbox environments.
Summary Mindmap
By proactively adopting these strategies and technologies, cloud architects and engineers can build resilient, scalable, and secure cloud native applications ready for the future.
11. Appendix and Resources
11.1 Glossary of Key Terms in Distributed Systems and Cloud Native Design
This glossary provides clear definitions and examples of essential terms used in distributed systems and cloud native application design. Each term is accompanied by a mind map in format to visually represent its relationships and components.
Distributed System
Definition: A collection of independent computers that appear to the users as a single coherent system.
Example: A global e-commerce platform where multiple servers handle user requests, inventory, and payments across different regions.
Mind Map:
Cloud Native Application
Definition: Applications designed specifically to run in cloud environments, leveraging microservices, containers, and dynamic orchestration.
Example: A microservices-based photo sharing app deployed on Kubernetes that scales automatically based on user demand.
Mind Map:
Microservices
Definition: An architectural style that structures an application as a collection of loosely coupled services.
Example: An online banking system where authentication, transaction processing, and notification are separate microservices.
Mind Map:
Containerization
Definition: Packaging software code and its dependencies into a single container image that can run reliably across different computing environments.
Example: Using Docker to package a Node.js application with all its libraries and runtime.
Mind Map:
Kubernetes
Definition: An open-source container orchestration platform for automating deployment, scaling, and management of containerized applications.
Example: Deploying a multi-container web app with automatic scaling and self-healing on a Kubernetes cluster.
Mind Map:
Eventual Consistency
Definition: A consistency model where updates to a distributed system will propagate and all nodes will eventually become consistent.
Example: A DNS system where changes to domain records propagate asynchronously but eventually all DNS servers reflect the update.
Mind Map:
Saga Pattern
Definition: A design pattern for managing distributed transactions by breaking them into a sequence of local transactions with compensating actions.
Example: In an e-commerce order process, if payment succeeds but inventory update fails, the payment is rolled back using a compensating transaction.
Mind Map:
Immutable Infrastructure
Definition: Infrastructure that is never modified after deployment; changes are made by replacing components rather than updating them.
Example: Deploying a new version of a web server by creating new instances and decommissioning old ones instead of patching in place.
Mind Map:
Service Mesh
Definition: A dedicated infrastructure layer for handling service-to-service communication, providing features like load balancing, authentication, and observability.
Example: Using Istio to manage traffic routing and secure communication between microservices in a Kubernetes cluster.
Mind Map:
Idempotency
Definition: The property of an operation whereby it can be applied multiple times without changing the result beyond the initial application.
Example: A payment API that safely handles repeated requests without charging the customer multiple times.
Mind Map:
Observability
Definition: The ability to understand the internal state of a system based on the data it produces: logs, metrics, and traces.
Example: Using Prometheus and Jaeger to monitor and trace requests in a distributed microservices application.
Mind Map:
Infrastructure as Code (IaC)
Definition: Managing and provisioning computing infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
Example: Using Terraform scripts to provision AWS resources like EC2 instances, S3 buckets, and networking.
Mind Map:
This glossary serves as a foundational reference for architects and engineers working with distributed systems and cloud native applications, helping bridge conceptual understanding with practical implementation.
11.2 Recommended Tools and Frameworks with Usage Examples
Distributed systems and cloud native application design rely heavily on a robust ecosystem of tools and frameworks that simplify development, deployment, monitoring, and maintenance. This section provides an overview of essential tools categorized by their purpose, along with practical usage examples and mind maps to help visualize their roles and interactions.
Containerization & Orchestration
Example: Docker + Kubernetes Deployment
-
Dockerfile example snippet:
FROM node:16-alpine WORKDIR /app COPY package*.json ./ RUN npm install COPY . . CMD ["node", "server.js"] -
Kubernetes Deployment YAML snippet:
apiVersion: apps/v1 kind: Deployment metadata: name: my-node-app spec: replicas: 3 selector: matchLabels: app: node-app template: metadata: labels: app: node-app spec: containers: - name: node-container image: myrepo/my-node-app:latest ports: - containerPort: 3000
This setup enables scalable, resilient deployment of a Node.js app in a distributed environment.
Messaging & Event Streaming
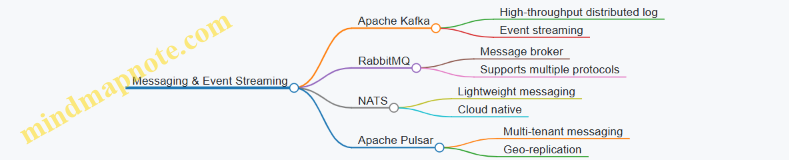
Example: Producing and Consuming Kafka Messages (Python)
-
Producer:
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='localhost:9092') producer.send('orders', b'order_id:1234') producer.flush() -
Consumer:
from kafka import KafkaConsumer consumer = KafkaConsumer('orders', bootstrap_servers='localhost:9092') for message in consumer: print(f"Received: {message.value.decode('utf-8')}")
This example demonstrates asynchronous communication, essential for decoupling microservices.
Monitoring & Observability
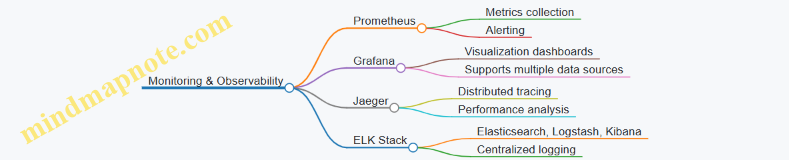
Example: Prometheus Metrics Exporter in Go
package main
import (
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
httpRequests = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Number of HTTP requests",
},
[]string{"path"},
)
)
func main() {
prometheus.MustRegister(httpRequests)
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
httpRequests.WithLabelValues(r.URL.Path).Inc()
w.Write([]byte("Hello, world!"))
})
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8080", nil)
}
This code exposes metrics that Prometheus can scrape, enabling real-time monitoring.
Infrastructure as Code (IaC)
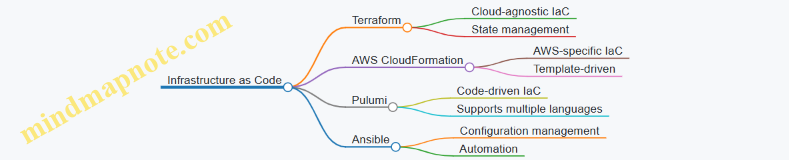
Example: Terraform AWS EC2 Instance
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
tags = {
Name = "TerraformExample"
}
}
This example provisions a simple EC2 instance on AWS using Terraform.
API Gateways & Service Meshes
Example: Istio VirtualService YAML
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews.prod.svc.cluster.local
http:
- route:
- destination:
host: reviews.prod.svc.cluster.local
subset: v2
weight: 90
- route:
- destination:
host: reviews.prod.svc.cluster.local
subset: v1
weight: 10
This configuration enables traffic splitting between two versions of a microservice, facilitating canary deployments.
CI/CD Tools
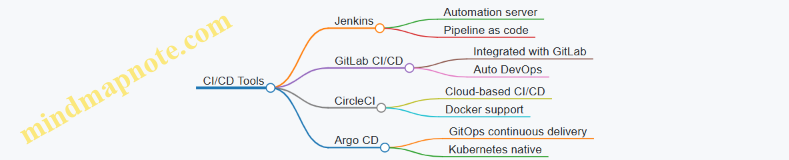
Example: GitLab CI Pipeline Snippet
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- docker build -t myapp:latest .
- docker push myapp:latest
test_job:
stage: test
script:
- npm test
deploy_job:
stage: deploy
script:
- kubectl apply -f k8s/deployment.yaml
only:
- main
This pipeline automates building, testing, and deploying a containerized app.
Summary Table of Tools
| Category | Tools / Frameworks | Primary Use Case |
|---|---|---|
| Containerization | Docker, Podman | Container image creation and runtime |
| Orchestration | Kubernetes, OpenShift, Helm | Managing containerized workloads |
| Messaging | Kafka, RabbitMQ, NATS | Asynchronous communication |
| Monitoring | Prometheus, Grafana, Jaeger, ELK | Metrics, tracing, logging |
| Infrastructure as Code | Terraform, CloudFormation, Pulumi | Automated infrastructure provisioning |
| API Management | Kong, AWS API Gateway, Apigee | API routing, security, rate limiting |
| Service Mesh | Istio, Linkerd, Consul Connect | Service-to-service communication control |
| CI/CD | Jenkins, GitLab CI, CircleCI, ArgoCD | Build, test, deploy automation |
By integrating these tools and frameworks into your distributed systems and cloud native application workflows, you can significantly improve reliability, scalability, and maintainability. Each tool comes with rich ecosystems and community support, making them indispensable for modern cloud architects and senior engineers.
11.3 Further Reading and Online Courses
To deepen your understanding of distributed systems architecture and cloud native application design, here is a curated list of books, articles, and online courses. Each resource is paired with examples or mind maps to help you visualize and apply the concepts effectively.
Books
-
“Designing Data-Intensive Applications” by Martin Kleppmann
- Why read? A comprehensive exploration of data systems, consistency models, and distributed system design.
- Example: The book’s chapter on consensus algorithms includes a detailed explanation of Raft with diagrams.
-
“Cloud Native Patterns” by Cornelia Davis
- Why read? Focuses on patterns for building cloud native applications, including microservices and event-driven architectures.
- Example: Includes practical examples of implementing the Circuit Breaker pattern.
-
“Site Reliability Engineering” by Google
- Why read? Offers insights into managing large-scale distributed systems with reliability and scalability.
- Example: Real-world case studies on incident management and monitoring.
Articles and Papers
- The Twelve-Factor App Methodology (https://12factor.net/)
- Summary: A foundational guide for building cloud native applications.
- Mind Map:
-
Google’s Site Reliability Workbook (https://sre.google/workbook/)
- Summary: Practical approaches to reliability engineering.
- Example: Exercises on error budgeting and service level objectives (SLOs).
-
CAP Theorem Explained by Eric Brewer
- Summary: Understanding trade-offs between consistency, availability, and partition tolerance.
- Mind Map:
Online Courses
-
Coursera: Cloud Computing Specialization by University of Illinois
- Description: Covers cloud infrastructure, services, and architecture.
- Example: Hands-on labs deploying microservices on AWS.
-
edX: Distributed Systems by Delft University of Technology
- Description: Deep dive into distributed algorithms, fault tolerance, and consensus.
- Example: Implementing a simplified Paxos algorithm.
-
Udemy: Kubernetes for the Absolute Beginners - Hands-on
- Description: Practical course on container orchestration.
- Example: Deploying a multi-container app with Kubernetes manifests.
-
Pluralsight: Designing Distributed Systems
- Description: Focuses on architectural patterns and best practices.
- Example: Designing event-driven microservices with messaging queues.
Mind Map: Learning Path for Distributed Systems and Cloud Native Design
Example: Applying Further Reading to a Real Project
Imagine you are designing a cloud native e-commerce platform:
- Use “Designing Data-Intensive Applications” to select appropriate database replication and partitioning strategies.
- Follow the Twelve-Factor App methodology to structure your microservices for portability and maintainability.
- Apply lessons from Google’s SRE Workbook to establish SLOs and monitoring.
- Take the Kubernetes course to deploy and manage your services efficiently.
This integrated approach ensures your design is robust, scalable, and maintainable.
By leveraging these resources, you can build a solid foundation and stay updated with evolving best practices in distributed systems and cloud native application design.
11.4 Community and Support Channels for Cloud Architects and Engineers
Engaging with communities and utilizing support channels is essential for Cloud Solutions Architects and Senior Software Engineers to stay updated, solve complex problems, and share knowledge. This section explores the most valuable communities, forums, and support resources, along with examples and mind maps to help you navigate and leverage them effectively.
Why Community and Support Channels Matter
- Knowledge Sharing: Learn from peers’ experiences and best practices.
- Problem Solving: Get quick help on technical challenges.
- Networking: Connect with industry experts and thought leaders.
- Staying Updated: Follow the latest trends, tools, and technologies.
Key Community Types and Platforms
Mind Map: Community and Support Channels Overview
Online Forums
Stack Overflow
- Use Case: Ask specific technical questions and get answers from a large developer community.
- Example: Searching for “Kubernetes pod autoscaling best practices” returns detailed answers and code snippets.
- Subreddits:
- r/devops: Discussions on CI/CD, automation.
- r/cloudcomputing: Cloud architecture and provider-specific topics.
- Example: A post about “Best practices for multi-cloud deployments” sparks a detailed community discussion.
Cloud Provider Forums
- AWS, Azure, and GCP have dedicated forums where engineers discuss service-specific issues.
- Example: AWS Developer Forums provide insights on Lambda cold start optimization.
Social Media Groups
LinkedIn Groups
- Groups like “Cloud Computing Professionals” and “Kubernetes Users” offer curated discussions and job postings.
- Example: Sharing a blog post on microservices design can lead to insightful comments and connections.
- Follow hashtags like #CloudNative, #DistributedSystems, and #DevOps.
- Example: Industry leaders often share updates and tutorials via Twitter threads.
Chat Platforms
Slack Communities
- CNCF Slack: Channels for Kubernetes, Prometheus, Envoy, etc.
- Example: Asking about best practices for service mesh implementation in #istio-users channel.
Discord Servers
- Emerging platform for real-time discussions.
- Example: Discord servers dedicated to cloud native technologies provide quick peer support.
Mind Map: Chat Platforms for Cloud Engineers
Professional Organizations
Cloud Native Computing Foundation (CNCF)
- Provides certifications, webinars, and community projects.
- Example: Joining CNCF SIGs (Special Interest Groups) to contribute to open-source projects.
IEEE Cloud Computing
- Offers research papers, standards, and conferences.
- Example: Accessing whitepapers on distributed system reliability.
Conferences and Meetups
KubeCon + CloudNativeCon
- Largest cloud native conference with workshops and networking.
- Example: Attending sessions on Kubernetes security best practices.
Local Meetups
- Great for face-to-face networking and knowledge exchange.
- Example: Meetup groups focused on microservices architecture.
Documentation & Official Support
Vendor Support Portals
- AWS Support, Azure Support, GCP Support provide SLA-backed assistance.
- Example: Opening a support ticket for a critical production issue.
GitHub Issues & Discussions
- Report bugs or request features directly from open-source projects.
- Example: Submitting a pull request to improve documentation on a distributed tracing tool.
Practical Tips for Engaging with Communities
- Be Clear and Concise: When asking questions, provide context and code snippets.
- Contribute Back: Share your solutions and experiences.
- Respect Community Guidelines: Follow rules and be courteous.
- Leverage Multiple Channels: Combine forums, chat, and social media for best results.
Example Scenario: Troubleshooting Kubernetes Deployment
- Post a detailed question on Stack Overflow with error logs.
- Share the issue in the #kubernetes-users channel on CNCF Slack.
- Search Reddit for similar issues and solutions.
- Check GitHub issues for the Kubernetes project.
- If using a managed service (e.g., EKS), open a support ticket.
Summary
Building a strong network through community and support channels empowers cloud architects and engineers to solve problems faster, stay current with evolving technologies, and contribute to the broader ecosystem. Regular participation and knowledge sharing are key to professional growth in distributed systems and cloud native application design.
11.5 Templates and Checklists for Designing Distributed Systems
Designing distributed systems can be complex, involving multiple layers of architecture, communication, data management, and operational concerns. To help architects and engineers streamline this process, this section provides practical templates, checklists, and mind maps that serve as guides during system design. Each template is accompanied by examples to illustrate its application.
Distributed Systems Design Checklist
This checklist ensures that critical aspects of distributed system design are considered before implementation.
-
Requirements Gathering
- Define functional requirements clearly.
- Identify non-functional requirements: scalability, availability, latency, consistency.
- Understand user load and traffic patterns.
-
Architecture & Components
- Choose architectural style (e.g., microservices, event-driven).
- Define service boundaries and responsibilities.
- Plan for service discovery and load balancing.
-
Data Management
- Select appropriate database(s) based on consistency and latency needs.
- Define data partitioning and replication strategies.
- Plan for backup, recovery, and disaster recovery.
-
Communication & Coordination
- Decide on communication patterns (sync vs async).
- Choose messaging infrastructure (e.g., Kafka, RabbitMQ).
- Implement consensus or coordination mechanisms if needed.
-
Fault Tolerance & Resilience
- Design for graceful degradation.
- Implement retries, circuit breakers, and fallback strategies.
- Plan for monitoring and alerting.
-
Security
- Define authentication and authorization mechanisms.
- Secure communication channels (e.g., TLS).
- Manage secrets and sensitive data securely.
-
Deployment & Operations
- Choose deployment strategy (blue-green, canary).
- Automate CI/CD pipelines.
- Plan for observability: logging, tracing, monitoring.
Mind Map: Distributed Systems Design Overview
Template: Service Design Document
| Section | Description | Example Snippet |
|---|---|---|
| Service Name | Unique identifier for the service | User Profile Service |
| Purpose | What the service does | Manages user profile data including preferences and settings. |
| API Endpoints | List of exposed APIs with methods and payloads | GET /users/{id}, POST /users |
| Data Storage | Database type and schema overview | PostgreSQL with tables: users, preferences |
| Communication | How this service communicates with others | Publishes events to Kafka topic user-updates; consumes from auth-events |
| Scalability Requirements | Expected load and scaling approach | Handle 10k requests/sec; horizontal scaling with Kubernetes pods |
| Fault Tolerance | Strategies for handling failures | Circuit breaker on downstream auth service; retry with exponential backoff |
| Security | Authentication and authorization mechanisms | OAuth 2.0 tokens; role-based access control |
| Monitoring & Logging | Metrics and logs to collect | Request latency, error rates, user update events logs |
Example: Applying the Checklist and Template
Imagine designing a distributed order processing system for an e-commerce platform.
-
Requirements:
- High availability and low latency order processing.
- Eventual consistency acceptable for inventory updates.
-
Architecture:
- Microservices: Order Service, Inventory Service, Payment Service.
-
Data Management:
- Order Service uses SQL database.
- Inventory Service uses NoSQL for fast updates.
-
Communication:
- Asynchronous messaging via Kafka for order events.
-
Fault Tolerance:
- Circuit breakers on payment gateway calls.
-
Security:
- JWT-based authentication.
-
Deployment:
- Canary deployments with Kubernetes.
Using the service design document template, each microservice is documented with its API, data storage, communication, and fault tolerance mechanisms.
Mind Map: Fault Tolerance Strategies
Quick Reference Checklist for Cloud Native Distributed Systems
- Containerize all services.
- Use Kubernetes for orchestration.
- Implement health probes (readiness/liveness).
- Externalize configuration.
- Use service mesh for secure communication.
- Enable distributed tracing.
- Automate CI/CD pipelines.
- Use Infrastructure as Code.
- Implement automated rollback.
These templates and checklists serve as living documents that can be adapted and extended based on specific project needs. They help ensure comprehensive coverage of critical design aspects and foster communication among team members.
11.6 Troubleshooting Common Issues in Cloud Native Applications
Troubleshooting cloud native applications can be challenging due to their distributed nature, dynamic environments, and complex dependencies. This section provides a structured approach to identifying and resolving common issues, supported by mind maps and practical examples.
Common Troubleshooting Areas
Infrastructure Issues
Networking Problems
- Symptoms: Service unreachable, timeouts, DNS failures.
- Example: A microservice cannot reach the database due to network policy restrictions.
Troubleshooting Steps:
- Check pod-to-pod connectivity using
kubectl execandcurlorping. - Verify Network Policies or Security Groups.
- Inspect DNS resolution with tools like
nslookupordiginside pods.
Example:
kubectl exec -it myservice-pod -- curl http://database-service:5432
Resource Limits
- Symptoms: Pods getting OOMKilled, CPU throttling.
- Example: A container crashes frequently due to insufficient memory.
Troubleshooting Steps:
- Check pod events and logs for OOMKilled messages.
- Review resource requests and limits in deployment manifests.
- Adjust limits based on observed usage.
Example:
kubectl describe pod myservice-pod
kubectl top pod myservice-pod
Storage Issues
- Symptoms: PersistentVolumeClaims not bound, data loss.
- Example: Stateful application fails to start due to missing volume.
Troubleshooting Steps:
- Verify PVC and PV status.
- Check storage class configurations.
- Inspect logs for mount errors.
Application Issues
Application Crashes
- Symptoms: Pods restarting frequently.
- Example: Null pointer exceptions causing container crashes.
Troubleshooting Steps:
- Inspect container logs with
kubectl logs. - Enable core dumps or debug mode.
- Use liveness and readiness probes to detect unhealthy states.
Example:
kubectl logs myservice-pod
Performance Degradation
- Symptoms: Slow response times, increased latency.
- Example: API calls taking longer after a new release.
Troubleshooting Steps:
- Analyze metrics from monitoring tools (Prometheus, Grafana).
- Profile application to identify bottlenecks.
- Check for resource contention or throttling.
Configuration Errors
- Symptoms: Misbehavior due to incorrect environment variables or config maps.
- Example: Service unable to connect to external API due to wrong endpoint.
Troubleshooting Steps:
- Verify environment variables and config maps.
- Use
kubectl describeto inspect applied configs. - Test configuration changes in staging before production.
Security Issues
Authentication Failures
- Symptoms: Unauthorized errors, failed login attempts.
- Example: Service account tokens expired or misconfigured.
Troubleshooting Steps:
- Check token validity and permissions.
- Review RBAC policies.
- Inspect authentication service logs.
Authorization Problems
- Symptoms: Access denied errors.
- Example: Microservice unable to access required resources.
Troubleshooting Steps:
- Audit RBAC roles and bindings.
- Validate IAM policies in cloud provider.
Secrets Management
- Symptoms: Secrets not injected or outdated.
- Example: Application fails to authenticate to database due to wrong password.
Troubleshooting Steps:
- Verify secrets in Kubernetes or Vault.
- Check mounting or injection methods.
Observability Issues
Logging Gaps
- Symptoms: Missing logs or incomplete traces.
- Example: Logs not showing error details.
Troubleshooting Steps:
- Ensure logging libraries are properly configured.
- Centralize logs using tools like ELK or Fluentd.
Monitoring Alerts
- Symptoms: False positives or missing alerts.
- Example: CPU usage alert not triggered.
Troubleshooting Steps:
- Validate alert rules.
- Test alerting pipelines.
Tracing Problems
- Symptoms: Incomplete distributed traces.
- Example: Missing spans in Jaeger or Zipkin.
Troubleshooting Steps:
- Verify instrumentation of services.
- Check sampling rates.
Deployment Issues
Rollback Failures
- Symptoms: New version causing failures, rollback not working.
- Example: Canary deployment breaks production.
Troubleshooting Steps:
- Use deployment strategies like blue-green or canary.
- Automate rollback in CI/CD pipelines.
CI/CD Pipeline Failures
- Symptoms: Build or deploy jobs failing.
- Example: Pipeline stuck due to failed tests.
Troubleshooting Steps:
- Inspect pipeline logs.
- Fix failing tests or deployment scripts.
Mind Map: Troubleshooting Workflow
Practical Example: Debugging a Service Crash Due to Configuration Error
- Symptom: Service pod keeps restarting.
- Check logs:
kubectl logs myservice-pod
Logs show connection refused to external API. 3. Inspect config:
kubectl describe configmap myservice-config
Endpoint URL is incorrect. 4. Fix config: Update ConfigMap with correct endpoint. 5. Restart pod:
kubectl rollout restart deployment/myservice
- Verify: Logs show successful connection.
Summary
Troubleshooting cloud native applications requires a systematic approach combining observability, understanding of distributed system behaviors, and knowledge of cloud platform specifics. Using structured mind maps and examples helps engineers quickly isolate and resolve issues, improving system reliability and developer productivity.