Practical Synthetic Biology Systems for Engineers
1. Introduction to Synthetic Biology Systems
1.1 Defining Synthetic Biology: Concepts and Scope
Synthetic biology is an interdisciplinary field that combines principles from biology, engineering, computer science, and chemistry to design, construct, and optimize new biological parts, devices, and systems or redesign existing natural biological systems for useful purposes. It aims to make biology easier to engineer by applying standardized design and fabrication approaches.
Core Concepts of Synthetic Biology
- Design-Build-Test-Learn (DBTL) Cycle: A systematic engineering approach to iteratively design genetic constructs, build them, test their function, and learn from the results to improve future designs.
- Modularity: Biological parts (e.g., promoters, ribosome binding sites, coding sequences) are treated as standardized modules that can be assembled in various combinations.
- Abstraction: Breaking down complex biological systems into hierarchical layers (parts, devices, systems) to simplify design and communication.
- Standardization: Use of common formats and protocols (e.g., BioBricks, SBOL) to ensure compatibility and reproducibility.
- Orthogonality: Designing components that function independently without interfering with native cellular processes.
Mind Map: Core Concepts of Synthetic Biology
Scope of Synthetic Biology
Synthetic biology encompasses a broad range of activities and applications, including but not limited to:
- Genetic Circuit Engineering: Designing synthetic gene networks that perform logical operations, oscillations, or signal processing.
- Metabolic Engineering: Reprogramming cellular metabolism to produce valuable chemicals, fuels, or pharmaceuticals.
- Genome Editing and Synthesis: Precise modification or synthesis of entire genomes for creating minimal cells or novel organisms.
- Biosensors: Engineering cells or biomolecules to detect environmental signals or disease biomarkers.
- Cell-Free Systems: Using biological components outside living cells for rapid prototyping or biosynthesis.
Mind Map: Scope of Synthetic Biology
Practical Example: The Genetic Toggle Switch
One of the earliest and most illustrative examples of synthetic biology is the genetic toggle switch, first demonstrated by Gardner, Cantor, and Collins in 2000. It is a synthetic, bistable gene regulatory network that can switch between two stable states in response to external stimuli.
- Concept: Two repressors mutually inhibit each other’s expression, creating a system with two stable states (ON/OFF).
- Application: Acts as a biological memory device, useful in biosensing and synthetic circuits.
Example Diagram (simplified):
This example demonstrates how engineering principles such as feedback loops and modularity are applied to biological systems to create predictable and controllable behavior.
Summary
Synthetic biology is a transformative engineering discipline that leverages biological components and systems to create novel functionalities. Its concepts of modularity, standardization, and iterative design enable engineers and scientists to build complex biological systems with applications spanning healthcare, environment, and industry.
1.2 Historical Evolution and Milestones in Synthetic Biology
Synthetic biology, as an interdisciplinary field, merges biology, engineering, and computational sciences to design and construct new biological parts, devices, and systems. Understanding its historical evolution provides context for current practices and future innovations.
Early Foundations (1970s - 1990s)
- 1973: The first recombinant DNA molecules were created by Paul Berg, marking the dawn of genetic engineering.
- 1975: Boyer and Cohen developed methods for DNA cloning, enabling gene transfer between organisms.
- 1980s: Development of PCR (Polymerase Chain Reaction) by Kary Mullis accelerated DNA amplification.
Example: The creation of the first genetically modified bacteria capable of producing human insulin laid groundwork for synthetic biology applications.
Birth of Synthetic Biology (2000s)
- 2000: The term “synthetic biology” began to be widely used, emphasizing the engineering approach to biology.
- 2003: Completion of the Human Genome Project provided a comprehensive genetic blueprint.
- 2004: The Registry of Standard Biological Parts (BioBricks) was established, promoting modular design.
Example: The MIT iGEM competition, launched in 2004, became a pivotal platform for students to design synthetic biological systems using standardized parts.
Key Milestones and Breakthroughs
- 2005: Construction of the first synthetic genetic toggle switch by Gardner et al., demonstrating engineered gene regulation.
- 2006: Development of synthetic oscillators (repressilators) showcased dynamic control in genetic circuits.
- 2010: Craig Venter’s team synthesized the first bacterial genome (Mycoplasma mycoides JCVI-syn1.0), creating a cell controlled by a synthetic genome.
- 2013: CRISPR-Cas9 genome editing technology revolutionized precise genetic modifications.
Example: The synthetic toggle switch is a bistable genetic circuit that can flip between two states, analogous to an electronic switch, enabling engineered control over gene expression.
Modern Synthetic Biology (2015 - Present)
- Expansion into metabolic engineering for biofuel and pharmaceutical production.
- Integration of computational modeling and AI for design automation.
- Advances in cell-free synthetic biology enabling rapid prototyping.
Example: Engineering yeast strains to produce artemisinic acid, a precursor to the antimalarial drug artemisinin, exemplifies practical synthetic biology applications.
Mind Maps
Mind Map 1: Timeline of Synthetic Biology Evolution
Mind Map 2: Major Technologies Driving Synthetic Biology
Mind Map 3: Example - Synthetic Genetic Toggle Switch
Summary
The historical evolution of synthetic biology reflects a journey from basic genetic manipulation to sophisticated engineering of biological systems. Each milestone introduced new tools and concepts that have shaped best practices today, such as standardization, modularity, and integration of computational design. Understanding these developments helps engineers appreciate the field’s complexity and potential, guiding practical system design with informed perspectives.
1.3 Key Components of Synthetic Biology Systems
Synthetic biology systems are engineered constructs that combine biological parts, devices, and systems to perform novel functions or improve existing biological processes. Understanding the key components that make up these systems is essential for bioengineers and systems engineers to design, build, and optimize synthetic biology applications effectively.
Core Components Overview
At a high level, synthetic biology systems can be broken down into the following key components:
- Biological Parts (BioParts)
- Devices
- Systems
- Chassis (Host Organisms)
- Regulatory Elements
- Sensors and Actuators
- Interfaces and Communication Modules
Below is a mind map illustrating these components and their relationships:
Biological Parts (BioParts)
Biological parts are the fundamental building blocks of synthetic biology. These standardized DNA sequences encode specific functions and can be combined to create devices and systems.
- Promoters: DNA sequences where RNA polymerase binds to initiate transcription.
- Ribosome Binding Sites (RBS): Sequences that facilitate translation initiation.
- Coding Sequences (CDS): DNA that encodes proteins or functional RNAs.
- Terminators: Sequences signaling transcription termination.
- Regulatory Proteins: Transcription factors that modulate gene expression.
Example:
A common BioPart is the lac promoter, which can be induced by IPTG to control gene expression in E. coli. This allows engineers to turn gene expression on or off in response to an external chemical.
Devices
Devices are assemblies of biological parts designed to perform a specific function, often analogous to electronic circuits.
- Genetic Circuits: Networks of genes and regulatory elements that process inputs and generate outputs.
- Logic Gates: Biological implementations of AND, OR, NOT gates.
- Oscillators: Circuits that produce rhythmic outputs.
- Switches: Systems that toggle between states.
Example:
The genetic toggle switch is a device composed of two repressors that mutually inhibit each other, allowing the system to maintain one of two stable states. This was one of the first synthetic biology devices constructed.
Systems
Systems are higher-order assemblies of devices and parts that perform complex functions, often mimicking natural biological pathways.
- Metabolic Pathways: Engineered sequences of enzymatic reactions to produce desired compounds.
- Signal Transduction Networks: Synthetic pathways that transmit and process signals within cells.
Example:
Engineering a metabolic pathway in yeast to produce artemisinic acid, a precursor to the antimalarial drug artemisinin, is a classic example of a synthetic biology system.
Chassis (Host Organisms)
The chassis is the living organism that hosts the synthetic system. Choice of chassis affects system performance, stability, and scalability.
- Common chassis include E. coli, Saccharomyces cerevisiae, and mammalian cells.
Example:
E. coli is often chosen for its fast growth and well-characterized genetics, making it ideal for prototyping genetic circuits.
Regulatory Elements
These components control the timing, location, and level of gene expression.
- Inducible Promoters: Activated by specific molecules.
- Repressors and Activators: Proteins that inhibit or enhance transcription.
Example:
The arabinose-inducible promoter (pBAD) allows gene expression only in the presence of arabinose sugar, providing tight control.
Sensors and Actuators
- Sensors: Detect environmental or intracellular signals.
- Actuators: Generate measurable outputs like fluorescence or metabolite production.
Example:
A quorum sensing system that detects bacterial population density and triggers expression of a fluorescent protein acts as a sensor-actuator pair.
Interfaces and Communication Modules
Synthetic biology systems often require communication within or between cells.
- Cell-Cell Communication: Using signaling molecules like AHLs (acyl-homoserine lactones).
- Synthetic Signaling Pathways: Engineered cascades to relay information.
Example:
Programming bacteria to coordinate behavior via quorum sensing molecules enables population-level control.
Integrated Example: Building a Synthetic Biosensor System
Consider designing a biosensor to detect arsenic in water:
- Biological Parts: Use an arsenic-responsive promoter (sensor) and a fluorescent protein gene (actuator).
- Device: Assemble a genetic circuit where arsenic presence activates the promoter, triggering fluorescence.
- System: Incorporate the device into E. coli chassis.
- Regulatory Elements: Use a strong terminator to ensure clean transcriptional stop.
- Communication: Optionally, engineer cell-cell signaling to amplify the response.
This example demonstrates how the components come together to create a functional synthetic biology system.
Understanding these key components and their interplay is foundational for engineers aiming to design practical and reliable synthetic biology systems.
1.4 Overview of Engineering Principles Applied to Biology
Synthetic biology uniquely blends engineering principles with biological systems to create predictable, reliable, and scalable biological functions. This section explores the core engineering concepts adapted for biology, illustrated with practical examples and mind maps to clarify their application.
Key Engineering Principles in Synthetic Biology
- Modularity: Breaking down complex biological systems into discrete, interchangeable parts.
- Standardization: Defining common interfaces and formats for biological parts to ensure compatibility.
- Abstraction: Layering complexity by separating design levels (e.g., DNA sequences, genetic circuits, cellular behavior).
- Design-Build-Test-Learn (DBTL) Cycle: Iterative process to design, construct, evaluate, and improve biological systems.
- Robustness and Reliability: Ensuring systems function consistently despite biological variability.
- Control Theory: Applying feedback and regulatory mechanisms to maintain system stability.
Mind Map: Core Engineering Principles in Synthetic Biology
Modularity in Practice
Example: Using BioBricks to build a genetic toggle switch.
- Concept: Each BioBrick is a standardized DNA part (e.g., promoter, repressor gene).
- Practice: Engineers can swap promoters or coding sequences without redesigning the entire system.
- Benefit: Simplifies troubleshooting and accelerates design iterations.
Standardization: The Backbone of Compatibility
Example: The BioBrick RFC[10] standard.
- Defines specific restriction sites flanking parts.
- Enables seamless assembly of parts from different labs.
- Facilitates sharing and reuse of genetic components.
Abstraction Layers Explained
Mind Map: Abstraction Layers in Synthetic Biology
Example: Designing a biosensor circuit.
- At the DNA level, select a promoter responsive to a target molecule.
- At the circuit level, integrate logic gates to refine signal output.
- At the cellular level, measure fluorescence as a readout.
The DBTL Cycle in Action
Example: Engineering E. coli to produce a biofuel precursor.
- Design: Use computational models to predict pathway efficiency.
- Build: Assemble genes encoding enzymes using Golden Gate cloning.
- Test: Measure product yield and cell growth.
- Learn: Analyze data to identify bottlenecks and redesign accordingly.
Robustness and Control Theory
Example: Implementing negative feedback to stabilize gene expression.
- A gene produces a protein that represses its own promoter.
- This feedback reduces expression variability caused by environmental fluctuations.
Mind Map: Control Strategies in Synthetic Biology
Summary
Applying engineering principles to biology enables synthetic biologists to design systems that are predictable, modular, and scalable. Through modularity, standardization, abstraction, iterative DBTL cycles, and control strategies, complex biological functions can be engineered with increasing precision and reliability.
This foundational understanding equips bioengineers and systems engineers to approach biological design with the rigor and methodology characteristic of traditional engineering disciplines.
1.5 Practical Example: Building a Simple Genetic Toggle Switch
A genetic toggle switch is one of the foundational synthetic biology systems demonstrating bistability — the ability to maintain one of two stable states. It acts like a biological flip-flop, switching between two gene expression states in response to external stimuli. This example will walk you through the design, components, and practical considerations of building a simple genetic toggle switch.
What is a Genetic Toggle Switch?
- A synthetic genetic circuit composed of two repressors that mutually inhibit each other.
- The system can stably exist in either of two states: one repressor ON and the other OFF, or vice versa.
- External inputs (chemical inducers) can flip the switch from one state to the other.
Mind Map: Core Components of a Genetic Toggle Switch
Step 1: Selecting the Repressors and Promoters
- Repressors: Use well-characterized repressors such as LacI and TetR.
- Promoters: Use promoters that are repressed by these repressors, e.g., P_Lac (repressed by LacI) and P_Tet (repressed by TetR).
Example:
- LacI represses P_Lac promoter.
- TetR represses P_Tet promoter.
This mutual repression forms the basis of bistability.
Step 2: Constructing the Circuit
- Place the gene encoding LacI under the control of P_Tet promoter.
- Place the gene encoding TetR under the control of P_Lac promoter.
- Add a reporter gene (e.g., GFP) downstream of one promoter to monitor the state.
Diagram :
Step 3: Understanding the Switching Mechanism
- State 1: LacI is expressed, repressing P_Lac, so TetR and GFP are OFF.
- State 2: TetR is expressed, repressing P_Tet, so LacI is OFF and GFP is ON.
Switching Inputs:
- IPTG binds LacI, inhibiting its repression, allowing TetR expression.
- aTc binds TetR, inhibiting its repression, allowing LacI expression.
Mind Map: Switching Logic
Step 4: Practical Considerations and Best Practices
- Promoter Strength: Balance promoter strengths to avoid leaky expression that can destabilize the switch.
- Repressor Expression Levels: Optimize ribosome binding sites (RBS) to tune repressor protein levels.
- Host Strain: Use a strain with minimal background expression of repressors.
- Plasmid Copy Number: Use compatible plasmids with controlled copy numbers to maintain stable expression.
- Reporter Selection: Choose reporters with fast maturation times for real-time monitoring.
Step 5: Experimental Example
- Host: E. coli DH5α
- Plasmids: Two compatible plasmids, one carrying LacI under P_Tet, the other TetR under P_Lac.
- Inducers: IPTG (1 mM) and aTc (200 ng/mL)
- Reporter: GFP downstream of P_Lac
Protocol:
- Transform E. coli with both plasmids.
- Grow cells to mid-log phase.
- Add IPTG to flip switch to State 2 (GFP ON).
- Wash cells and add aTc to flip back to State 1 (GFP OFF).
Observation: Fluorescence microscopy or flow cytometry shows bistable GFP expression corresponding to switch states.
Mind Map: Experimental Workflow
Summary
Building a genetic toggle switch is a practical introduction to synthetic biology systems engineering. It demonstrates how biological components can be engineered to create predictable, switchable states. By carefully selecting repressors, promoters, and tuning expression levels, engineers can design robust bistable systems useful in biosensing, memory storage, and synthetic control circuits.
Additional Resources
- Gardner, T. S., Cantor, C. R., & Collins, J. J. (2000). Construction of a genetic toggle switch in Escherichia coli. Nature, 403(6767), 339-342.
- BioBricks Foundation: Standard biological parts repository.
- Benchling or SnapGene for plasmid design and simulation.
This example integrates design principles, practical tips, and experimental steps to provide a comprehensive guide for engineers venturing into synthetic biology circuit construction.
2. Design Principles in Synthetic Biology
2.1 Modular Design and Standardization of Biological Parts
Modular design and standardization are foundational principles in synthetic biology that enable engineers to build complex biological systems with predictable behavior. By breaking down biological systems into discrete, interchangeable parts, synthetic biologists can design, assemble, and troubleshoot genetic constructs more efficiently and reliably.
What is Modular Design in Synthetic Biology?
Modular design refers to the practice of decomposing biological systems into smaller, well-defined functional units or “modules”. Each module performs a specific function and can be combined with other modules to create more complex systems.
- Advantages:
- Simplifies design and debugging
- Facilitates reuse of parts
- Enables parallel development and testing
Standardization of Biological Parts
Standardization involves defining common formats, interfaces, and characterization methods for biological parts to ensure compatibility and predictability when assembled.
- Key aspects:
- Physical standards (e.g., DNA assembly methods)
- Functional standards (e.g., promoter strength characterization)
- Documentation standards (e.g., metadata, sequence annotation)
Mind Map: Modular Design and Standardization
Examples of Modular Design and Standardization
Example 1: BioBricks Standard
BioBricks are one of the earliest and most widely adopted standards for physical DNA parts. Each BioBrick part has defined prefix and suffix sequences that allow easy assembly using restriction enzymes.
- Modularity: Parts like promoters, coding sequences, and terminators can be mixed and matched.
- Standardization: The assembly method and part format are consistent, enabling interoperability.
Practical Example:
- Constructing a simple reporter system by combining a BioBrick promoter, a GFP coding sequence, and a terminator.
Example 2: Golden Gate Assembly
Golden Gate uses Type IIS restriction enzymes to enable scarless and efficient assembly of multiple parts in a single reaction.
- Modularity: Allows assembly of multiple standardized parts in a defined order.
- Standardization: Parts are designed with specific overhangs to ensure compatibility.
Practical Example:
- Rapidly assembling a multi-gene operon for a metabolic pathway by combining standardized promoters, genes, and terminators.
Example 3: Standardized Promoter Libraries
Characterizing promoters under standard conditions allows engineers to select parts based on quantitative strength data.
- Modularity: Promoters can be swapped to tune gene expression.
- Standardization: Expression levels are measured using consistent reporter systems and conditions.
Practical Example:
- Using a promoter library to optimize the expression of an enzyme in a synthetic pathway for improved yield.
Best Practices for Modular Design and Standardization
- Adopt widely accepted standards: Use formats like BioBricks or Golden Gate compatible parts.
- Characterize parts thoroughly: Quantify function under relevant conditions.
- Document metadata: Include sequence, function, and experimental context.
- Use modular cloning toolkits: Leverage available kits to speed up assembly.
- Iterate and validate: Test modules individually before system integration.
Summary
Modular design and standardization empower synthetic biologists and bioengineers to build complex biological systems predictably and efficiently. By leveraging standardized parts and assembly methods, engineers can focus on system-level design and innovation, reducing trial-and-error and accelerating development cycles.
2.2 Abstraction Layers: From DNA to Systems
In synthetic biology, abstraction layers are essential for managing the complexity of biological systems by breaking down the design process into manageable, hierarchical components. This approach allows engineers to focus on different levels of detail, from the molecular scale of DNA sequences to the holistic behavior of entire biological systems.
What are Abstraction Layers?
Abstraction layers in synthetic biology refer to the conceptual separation of biological design into distinct levels, each representing a different scale or complexity. This modular approach simplifies design, debugging, and communication among interdisciplinary teams.
Common Abstraction Layers in Synthetic Biology
Layer 1: DNA Level
This is the most fundamental layer, dealing with raw nucleotide sequences. Here, engineers work with sequences encoding promoters, coding regions, terminators, and other genetic elements.
Example: Designing a promoter sequence to control gene expression strength.
Layer 2: Part Level
Parts are standardized DNA sequences with defined functions, such as BioBricks. They can be combined to form devices.
Best Practice: Use well-characterized parts from repositories like the iGEM Registry to ensure predictable behavior.
Example: Combining a promoter, RBS, and coding sequence to create a functional gene expression cassette.
Layer 3: Device Level
Devices are assemblies of parts that perform a specific function, such as a genetic toggle switch or a biosensor.
Example: A genetic oscillator device built by combining feedback loops and regulatory parts.
Mind Map:
Layer 4: System Level
At this highest level, devices are integrated into complex systems that govern cellular behavior or synthetic organisms.
Example: Engineering a microbial consortium where different strains communicate via quorum sensing devices to perform coordinated tasks.
Mind Map:
Integrated Example: From DNA to System
Consider engineering a biosensor system that detects arsenic in water:
- DNA Level: Design promoter sequences sensitive to arsenic.
- Part Level: Assemble promoter with reporter gene (e.g., GFP) and terminator.
- Device Level: Create a genetic circuit that amplifies the signal and produces a measurable output.
- System Level: Integrate the device into a bacterial host optimized for environmental robustness.
This layered approach allows engineers to troubleshoot at the appropriate level, reuse components, and scale designs efficiently.
Summary of Best Practices
- Standardize parts to enable modular design and reuse.
- Characterize parts and devices thoroughly to predict system behavior.
- Use abstraction layers to manage complexity and facilitate collaboration.
- Leverage computational tools that support multi-layer design, such as SBOL (Synthetic Biology Open Language).
By embracing abstraction layers, bioengineers can effectively design, build, and optimize synthetic biology systems with clarity and precision.
2.3 Best Practice: Using BioBricks for Reliable Part Assembly
BioBricks represent a foundational standard in synthetic biology for the modular assembly of genetic parts. They enable engineers to design, share, and reliably assemble DNA sequences in a standardized way, facilitating reproducibility and scalability in synthetic biology projects.
What are BioBricks?
BioBricks are standardized DNA sequences with defined prefix and suffix restriction sites that allow easy and predictable assembly of multiple parts into larger constructs. Each BioBrick part typically encodes a functional element such as a promoter, ribosome binding site (RBS), coding sequence (CDS), or terminator.
Why Use BioBricks?
- Modularity: Parts can be mixed and matched like building blocks.
- Standardization: Uniform restriction sites ensure compatibility.
- Reusability: Parts can be shared and reused across projects.
- Reliability: Reduced errors in assembly due to standardized protocols.
BioBrick Assembly Standard (RFC10)
The most commonly used BioBrick assembly standard (RFC10) uses four restriction enzymes: EcoRI, XbaI, SpeI, and PstI.
- Prefix: EcoRI - XbaI
- Suffix: SpeI - PstI
Two parts can be combined by digesting one with EcoRI and SpeI, and the other with XbaI and PstI, then ligating them. The resulting composite part retains the BioBrick prefix and suffix, allowing iterative assembly.
Mind Map: BioBrick Assembly Workflow
Best Practices for Reliable BioBrick Assembly
- Verify Part Sequences Before Assembly: Always sequence your parts to confirm accuracy.
- Check for Internal Restriction Sites: Ensure parts do not contain internal EcoRI, XbaI, SpeI, or PstI sites to avoid unwanted cuts.
- Use High-Fidelity Enzymes and PCR: Minimize mutations during amplification.
- Optimize Ligation Conditions: Use appropriate molar ratios and ligase concentrations.
- Include Controls: Negative controls help identify background ligation.
- Use Standardized Vectors: Employ vectors compatible with BioBrick assembly.
Example: Assembling a Promoter and GFP Coding Sequence
Goal: Create a construct expressing GFP under a constitutive promoter.
- Parts:
- Promoter (BBa_J23100)
- RBS (BBa_B0034)
- GFP CDS (BBa_E0040)
- Terminator (BBa_B0015)
Step-by-step:
- Digest Promoter part with EcoRI and SpeI.
- Digest RBS part with XbaI and PstI.
- Ligate Promoter and RBS parts.
- Digest the ligation product with EcoRI and SpeI.
- Digest GFP CDS part with XbaI and PstI.
- Ligate the combined Promoter-RBS with GFP CDS.
- Repeat digestion and ligation to add Terminator.
- Transform into E. coli and verify via colony PCR and sequencing.
Mind Map: Example Assembly of Promoter-GFP Construct
Troubleshooting Tips
- No Colonies After Transformation: Check enzyme activity and ligation efficiency.
- Unexpected Band Sizes: Verify digestion completeness and check for star activity.
- Mutations in Final Construct: Use high-fidelity polymerases and minimize PCR cycles.
Summary
Using BioBricks for part assembly streamlines synthetic biology workflows by promoting modularity and standardization. Adhering to best practices such as sequence verification, avoiding internal restriction sites, and optimizing ligation conditions ensures reliable and reproducible construction of genetic circuits.
For engineers, mastering BioBrick assembly is a critical skill that bridges biological complexity with engineering precision, enabling the design of scalable and robust synthetic biology systems.
2.4 Design Automation Tools and Their Practical Use Cases
Design automation tools have revolutionized synthetic biology by enabling engineers to design, simulate, and optimize biological systems with greater efficiency and accuracy. These tools help translate complex biological designs into executable DNA sequences, reducing trial-and-error cycles and accelerating the development pipeline.
Key Design Automation Tools
- SBOLDesigner: A graphical tool for designing and visualizing synthetic biology constructs using the Synthetic Biology Open Language (SBOL) standard.
- Cello: A platform that automates genetic circuit design by converting high-level logic specifications into DNA sequences.
- Geneious: An integrated suite for sequence analysis, cloning, and primer design.
- Benchling: Cloud-based platform combining sequence design, lab notebook, and collaboration tools.
- GenoCAD: A grammar-based design tool that allows users to create genetic constructs using predefined biological parts.
- iBioSim: Software for modeling, analysis, and design of genetic circuits with support for SBML and SBOL.
Mind Map: Overview of Design Automation Tools
Practical Use Case 1: Automating Genetic Circuit Design with Cello
Scenario: An engineer wants to design a genetic circuit that performs a logical AND operation responding to two input signals.
Process:
- Define the logic function (AND gate) in Cello’s high-level language.
- Cello maps the logic to genetic parts from its database, considering host-specific constraints.
- The tool outputs a DNA sequence ready for synthesis.
Best Practice: Use Cello’s host-specific libraries to ensure compatibility and optimize circuit performance.
Example: Designing a two-input AND gate in E. coli to control expression of a reporter gene only when both inducers are present.
Mind Map: Cello Workflow
Practical Use Case 2: Construct Design and Visualization with SBOLDesigner
Scenario: A bioengineer needs to design a multi-gene construct for metabolic pathway engineering.
Process:
- Use SBOLDesigner to drag and drop standardized parts (promoters, CDS, terminators).
- Visualize the construct architecture clearly.
- Export the design in SBOL format for sharing or further analysis.
Best Practice: Maintain part standardization to facilitate reuse and interoperability.
Example: Designing a three-gene operon for enhanced biosynthesis of a target metabolite.
Mind Map: SBOLDesigner Features
Practical Use Case 3: Integrated Sequence Analysis and Primer Design with Geneious
Scenario: Preparing DNA constructs for cloning requires designing primers and verifying sequences.
Process:
- Import sequences into Geneious.
- Use built-in tools to design primers with optimal melting temperatures and minimal secondary structures.
- Simulate cloning strategies and verify sequence integrity.
Best Practice: Validate primer specificity using in silico PCR simulations before ordering.
Example: Designing primers for Gibson assembly of a synthetic operon.
Summary
Design automation tools empower synthetic biology engineers to bridge the gap between conceptual design and physical implementation. By leveraging these platforms, engineers can:
- Rapidly prototype genetic circuits and constructs.
- Reduce errors through standardized parts and automated checks.
- Collaborate effectively via shared formats and cloud platforms.
- Integrate computational modeling with experimental workflows.
Incorporating these tools into your synthetic biology projects will streamline design cycles and enhance reproducibility.
For further exploration, consider hands-on tutorials available on the official websites of these tools, many of which provide example datasets and step-by-step guides tailored for engineers transitioning into synthetic biology design automation.
2.5 Example: Designing a Biosensor Circuit for Environmental Monitoring
Introduction
Biosensors are engineered biological systems designed to detect specific environmental signals and produce a measurable output. In this example, we will design a genetic biosensor circuit capable of detecting heavy metal contamination, such as arsenic, in water samples. This practical example will integrate design principles, modular parts, and best practices to create a robust, sensitive, and specific biosensor.
Step 1: Define the Sensing Objective
- Target analyte: Arsenic (As³⁺)
- Detection environment: Contaminated water
- Output: Fluorescent protein expression (e.g., GFP) for easy visualization
Step 2: Select Biological Parts
- Sensor module: Arsenic-responsive promoter (Pars)
- Regulatory protein: ArsR repressor protein
- Reporter gene: GFP (Green Fluorescent Protein)
- Host organism: Escherichia coli (commonly used chassis for biosensors)
Step 3: Circuit Design Overview
The biosensor circuit relies on the ArsR repressor binding to the Pars promoter to inhibit GFP expression. In the presence of arsenic, ArsR undergoes conformational change, detaches from Pars, and allows transcription of GFP.
Mind Map: Biosensor Circuit Components
Step 4: Genetic Circuit Construction
- Clone the Pars promoter upstream of the GFP coding sequence.
- Constitutively express ArsR from a separate promoter to ensure constant repressor availability.
- Use a plasmid backbone compatible with E. coli and include a selectable marker.
Step 5: Best Practices in Design
- Modularity: Separate sensor and reporter modules to allow easy swapping of parts.
- Standardization: Use BioBrick-compatible parts for ease of assembly and sharing.
- Tuning Sensitivity: Adjust ArsR expression levels to optimize the detection threshold.
- Noise Reduction: Incorporate feedback loops or degradation tags on GFP to reduce background signal.
Mind Map: Best Practices for Biosensor Design
Step 6: Example Experimental Workflow
- Assemble plasmid: Use Golden Gate assembly to combine Pars-GFP and constitutive ArsR expression cassettes.
- Transform E. coli: Introduce plasmid into competent cells.
- Induce with arsenic: Expose cultures to varying arsenic concentrations.
- Measure fluorescence: Use a plate reader or flow cytometer to quantify GFP expression.
- Analyze data: Determine detection limit and dynamic range.
Step 7: Example Data Interpretation
- Low arsenic concentrations show minimal GFP expression due to ArsR repression.
- Increasing arsenic leads to derepression and increased fluorescence.
- Saturation occurs at high arsenic levels where all ArsR proteins are bound by arsenic.
Step 8: Extensions and Applications
- Multiplexed sensing: Combine multiple metal-responsive promoters for simultaneous detection.
- Signal amplification: Use genetic amplifiers to increase sensitivity.
- Field deployment: Engineer biosensor strains with lyophilization capability for transport.
Mind Map: Future Enhancements
Summary
This example demonstrates a practical approach to designing a synthetic biology biosensor circuit for environmental monitoring. By combining modular genetic parts, applying best practices, and validating through experimentation, engineers can create effective biosensors tailored to specific applications.
3. Genetic Circuit Engineering
3.1 Fundamentals of Genetic Circuits and Logic Gates
Genetic circuits are engineered networks of genes and regulatory elements designed to perform logical operations inside living cells, similar to electronic circuits. These circuits enable cells to process inputs, make decisions, and produce specific outputs, thereby expanding the capabilities of synthetic biology systems.
What Are Genetic Circuits?
- Definition: Assemblies of DNA sequences that interact through transcriptional and translational regulation to control cellular behavior.
- Components: Promoters, operators, repressors, activators, ribosome binding sites, terminators.
- Function: Mimic digital logic by integrating multiple biological signals.
Logic Gates in Synthetic Biology
Logic gates are the fundamental building blocks of digital circuits, and their biological equivalents regulate gene expression based on input signals.
| Logic Gate | Function | Biological Equivalent | Example |
|---|---|---|---|
| AND | Output ON only if all inputs are ON | Promoter activated only when multiple transcription factors bind | Expression of a reporter gene only when two inducers are present |
| OR | Output ON if any input is ON | Promoter activated by either of two transcription factors | Gene expressed if either of two sugars is present |
| NOT | Output ON if input is OFF | Repressor protein inhibits gene expression | Gene turned off in presence of a repressor molecule |
| NAND | Output OFF only if all inputs are ON | Combination of repressors and activators | Synthetic toggle switch |
Mind Map: Components of Genetic Circuits
Mind Map: Types of Biological Logic Gates
Example 1: Simple Genetic AND Gate
Design: A promoter that requires two different transcription factors (TF1 and TF2) to activate transcription.
Implementation:
- Two inducers (e.g., arabinose and IPTG) induce TF1 and TF2 respectively.
- Only when both inducers are present, the promoter is activated.
- Output gene (e.g., GFP) is expressed.
Best Practice: Use well-characterized promoters and transcription factors to ensure predictable behavior.
Example 2: Genetic Toggle Switch (NAND Gate Behavior)
Design: Two mutually repressing genes create a bistable system.
Implementation:
- Gene A produces repressor protein that inhibits Gene B.
- Gene B produces repressor protein that inhibits Gene A.
- The system can flip between two stable states depending on initial conditions or inputs.
Use Case: Memory storage in cells or switchable gene expression.
Best Practice: Carefully tune promoter strengths and degradation rates to maintain stability.
Practical Tips for Engineers
- Modularity: Design circuits with interchangeable parts to facilitate troubleshooting and upgrades.
- Orthogonality: Use components that do not interfere with host cell machinery or other circuits.
- Characterization: Quantify input-output relationships experimentally to validate models.
- Noise Management: Incorporate feedback loops or redundancy to reduce stochastic fluctuations.
Understanding the fundamentals of genetic circuits and logic gates equips bioengineers with the tools to design sophisticated synthetic biology systems that can sense, compute, and respond to complex biological environments.
3.2 Engineering Robustness and Noise Reduction in Circuits
Synthetic genetic circuits often operate in inherently noisy biological environments. Noise arises from stochastic gene expression, environmental fluctuations, and variability in cellular components. Engineering robustness and minimizing noise are critical to ensure predictable and reliable circuit behavior, especially for applications in therapeutics, biosensing, and metabolic engineering.
Understanding Noise in Genetic Circuits
Noise can be broadly classified into two types:
- Intrinsic noise: Variability arising from the stochastic nature of biochemical reactions within a single cell.
- Extrinsic noise: Variability caused by fluctuations in cellular components or environmental factors affecting multiple genes simultaneously.
Strategies to Engineer Robustness and Reduce Noise
Mind Map: Strategies for Noise Reduction and Robustness
Negative Feedback Loops
Negative feedback reduces variability by adjusting the output based on the current state. It stabilizes gene expression levels and dampens fluctuations.
Example: The classic lac operon repressor system can be engineered to include negative feedback by expressing the repressor protein under the control of the same promoter it regulates.
Mind Map: Negative Feedback Loop
Practical Example:
- Construct a genetic circuit where GFP expression is repressed by a repressor protein whose expression is driven by the same promoter as GFP.
- Measure fluorescence variability with and without feedback.
- Observe reduced noise and tighter expression distribution with feedback.
Positive Feedback and Bistability
Positive feedback can create bistable switches that maintain stable ON or OFF states, making the system robust against small perturbations.
Example: The genetic toggle switch engineered by Gardner et al. (2000) uses mutual repression to create bistability.
Mind Map: Positive Feedback and Bistability
Practical Example:
- Build a toggle switch with two repressors inhibiting each other.
- Use chemical inducers to flip states.
- Demonstrate that once switched, the state is maintained despite noise.
Redundancy and Parallel Pathways
Redundancy involves multiple components performing the same function, reducing the impact of failure or noise in any single element.
Example: Using multiple promoters driving the same gene or multiple copies of a gene to buffer expression variability.
Molecular Tools for Noise Reduction
- Insulator sequences: DNA elements that prevent crosstalk between adjacent genetic parts.
- RNA-based regulation: Riboswitches and small RNAs can provide fine-tuned control.
- Protein degradation tags: Control protein half-life to reduce accumulation and variability.
Example: Adding ssrA degradation tags to fluorescent proteins to reduce variability in protein levels.
Host Cell Optimization
Minimizing metabolic burden and ensuring stable plasmid maintenance reduce extrinsic noise.
Example: Using low-copy plasmids or integrating circuits into the genome.
Environmental Control
Consistent growth conditions and microfluidic devices can reduce environmental fluctuations.
Example: Using microfluidic chemostats to maintain constant nutrient levels and temperature.
Computational Modeling and Simulation
Modeling noise using stochastic simulations (e.g., Gillespie algorithm) helps predict circuit behavior and design for robustness.
Mind Map: Computational Approaches
Example: Simulate a genetic oscillator with and without feedback to compare noise levels.
Summary
Engineering robustness and noise reduction in synthetic genetic circuits is a multifaceted challenge. Combining design principles like feedback control, molecular tools, host optimization, and computational modeling enables bioengineers to build circuits with predictable, reliable behaviors suitable for real-world applications.
References
- Gardner, T. S., Cantor, C. R., & Collins, J. J. (2000). Construction of a genetic toggle switch in Escherichia coli. Nature, 403(6767), 339–342.
- Elowitz, M. B., & Leibler, S. (2000). A synthetic oscillatory network of transcriptional regulators. Nature, 403(6767), 335–338.
- Becskei, A., & Serrano, L. (2000). Engineering stability in gene networks by autoregulation. Nature, 405(6786), 590–593.
3.3 Best Practice: Implementing Feedback Control in Genetic Circuits
Feedback control is a cornerstone concept in engineering that has been effectively adapted to synthetic biology to enhance the robustness, stability, and dynamic behavior of genetic circuits. Implementing feedback loops allows engineered biological systems to self-regulate, maintain homeostasis, and adapt to environmental or internal fluctuations.
What is Feedback Control in Genetic Circuits?
Feedback control involves a system where the output influences its own activity through a feedback loop. In genetic circuits, this typically means that the expression of a gene or set of genes is regulated by the products they produce or by downstream signals.
- Negative Feedback: The output inhibits its own production, stabilizing the system and reducing noise.
- Positive Feedback: The output enhances its own production, enabling bistability or switch-like behavior.
Why Implement Feedback Control?
- Robustness: Systems can maintain function despite perturbations.
- Noise Reduction: Minimizes stochastic fluctuations in gene expression.
- Dynamic Response: Enables adaptation to changing environments.
- Bistability and Memory: Positive feedback can create switch-like states.
Mind Map: Feedback Control in Genetic Circuits
Example 1: Negative Feedback to Reduce Noise in Gene Expression
Context: Noise in gene expression can cause variability in cellular behavior, which is undesirable in many synthetic biology applications.
Implementation: A gene encoding a transcription factor represses its own promoter.
Outcome: The negative feedback loop stabilizes the expression level, reducing cell-to-cell variability.
Diagram (simplified):
Gene A –> Protein A
Protein A –| Promoter of Gene A
Practical Tip: Use well-characterized repressors like TetR or LacI for predictable negative feedback loops.
Example 2: Positive Feedback for a Genetic Toggle Switch
Context: A toggle switch is a bistable system that can maintain one of two states, useful for memory storage in cells.
Implementation: Two genes mutually repress each other, creating a positive feedback loop.
Outcome: The system can be flipped between states by transient stimuli and maintain the state after stimulus removal.
Diagram (simplified):
Gene A –| Gene B
Gene B –| Gene A
Practical Tip: Balance promoter strengths and degradation rates to ensure stable bistability.
Example 3: Feedback Control in Synthetic Oscillators
Context: Oscillators require carefully tuned feedback loops to generate sustained rhythmic behavior.
Implementation: Negative feedback with time delays is used to create oscillations, e.g., the Repressilator.
Outcome: Periodic expression of genes with predictable frequency and amplitude.
Diagram (simplified):
Gene A –| Gene B
Gene B –| Gene C
Gene C –| Gene A
Practical Tip: Incorporate degradation tags to control protein half-life and tune oscillation period.
Best Practices for Implementing Feedback Control
- Model the Circuit Computationally: Use ODE or stochastic models to predict system behavior before wet-lab implementation.
- Use Modular and Orthogonal Parts: Minimize crosstalk and unintended interactions.
- Characterize Components Individually: Understand promoter strengths, repressor efficiencies, and degradation rates.
- Incorporate Tunable Elements: Use inducible promoters or riboregulators to fine-tune feedback strength.
- Iterative Testing and Optimization: Combine modeling with experimental data to refine the circuit.
Summary
Implementing feedback control in genetic circuits is essential for creating reliable, robust, and adaptable synthetic biological systems. By leveraging negative and positive feedback loops, bioengineers can design circuits that reduce noise, maintain stable states, or generate complex dynamic behaviors such as oscillations. Combining computational modeling, modular design, and iterative experimentation forms the best practice framework for successful feedback control implementation.
Additional Mind Map: Best Practices Workflow
3.4 Case Study: Synthetic Oscillators and Their Applications
Synthetic oscillators are engineered genetic circuits designed to produce rhythmic, periodic outputs within living cells. These oscillators mimic natural biological rhythms such as circadian clocks, cell cycles, and metabolic cycles, but are constructed with synthetic components to achieve predictable and tunable oscillations.
Understanding Synthetic Oscillators
At their core, synthetic oscillators rely on feedback loops—both negative and positive—to generate sustained oscillations. The most famous example is the Repressilator, a synthetic genetic oscillator first demonstrated by Elowitz and Leibler in 2000.
Key components:
- Transcriptional repressors arranged in a cyclic inhibitory network
- Promoters responsive to repressors
- Reporter genes (e.g., GFP) to visualize oscillations
Mind Map: Core Concepts of Synthetic Oscillators
Example 1: The Repressilator
- Design: Three genes encoding repressors arranged in a ring, each inhibiting the next.
- Behavior: Produces oscillations in gene expression with a period of several hours.
- Best Practices: Use well-characterized promoters and repressors; tune degradation rates for consistent oscillations.
Mind Map: Repressilator Design and Function
Example 2: Dual Feedback Oscillator
- Combines positive and negative feedback loops to improve robustness and tunability.
- Often uses activators and repressors to create sharper oscillations.
- Practical application includes timed drug delivery systems.
Applications of Synthetic Oscillators
-
Timed Drug Delivery: Oscillators can control the timing of therapeutic protein expression, enabling pulsatile drug release.
-
Biosensing: Oscillatory signals can enhance sensitivity by encoding information in frequency or amplitude.
-
Metabolic Engineering: Oscillators regulate metabolic fluxes dynamically to optimize production yields.
-
Developmental Biology Models: Synthetic oscillators help study natural rhythmic processes like somitogenesis.
Mind Map: Applications of Synthetic Oscillators
Best Practices for Engineering Synthetic Oscillators
- Component Characterization: Use well-characterized parts with predictable kinetics.
- Tuning Parameters: Adjust promoter strengths, degradation tags, and plasmid copy numbers.
- Modeling and Simulation: Employ computational models (ODEs, stochastic) to predict behavior before wet-lab implementation.
- Noise Management: Design circuits robust to intrinsic and extrinsic noise.
- Validation: Use time-lapse fluorescence microscopy to monitor oscillations in single cells.
Hands-On Example: Building a Simple Synthetic Oscillator
- Select Parts: Choose three repressors (e.g., LacI, TetR, CI) and corresponding promoters.
- Assemble Circuit: Use modular cloning techniques to assemble the cyclic inhibitory network.
- Introduce Reporter: Add GFP under control of one promoter to visualize oscillations.
- Transform Host: Introduce plasmid into E. coli.
- Monitor Oscillations: Use fluorescence microscopy and flow cytometry to measure oscillation period and amplitude.
Synthetic oscillators exemplify the power of synthetic biology to engineer dynamic behaviors in living systems. By integrating design principles, computational modeling, and experimental validation, engineers can create robust oscillatory systems with diverse applications across medicine, industry, and research.
3.5 Hands-on Example: Constructing a Quorum Sensing-Based Circuit
Quorum sensing (QS) is a cell-to-cell communication mechanism used by bacteria to coordinate gene expression based on population density. Synthetic biologists harness QS systems to engineer genetic circuits that respond dynamically to cell density, enabling applications such as synchronized gene expression, population control, and biosensing.
Objective
Build a synthetic genetic circuit in Escherichia coli that uses quorum sensing to activate a reporter gene (e.g., GFP) once the bacterial population reaches a threshold density.
Step 1: Understanding the Quorum Sensing System
The most commonly used QS system in synthetic biology is the LuxI/LuxR system from Vibrio fischeri.
- LuxI: Synthesizes the signaling molecule N-acyl homoserine lactone (AHL).
- AHL: Diffuses freely across cell membranes and accumulates in the environment.
- LuxR: A transcription factor that binds AHL; the LuxR-AHL complex activates transcription from the lux promoter (Plux).
When the population density is low, AHL concentration is insufficient to activate LuxR. As the population grows, AHL accumulates, binds LuxR, and triggers gene expression.
Mind Map: Components of LuxI/LuxR Quorum Sensing Circuit
Step 2: Circuit Design
The circuit consists of two main modules:
- Signal Production Module: Constitutive expression of LuxI to produce AHL.
- Signal Detection Module: LuxR expressed constitutively; upon binding AHL, activates Plux promoter driving GFP expression.
Best Practice: Use well-characterized promoters and ribosome binding sites (RBS) to tune expression levels and avoid metabolic burden.
Step 3: DNA Assembly
- Clone luxI gene under a medium-strength constitutive promoter (e.g., J23110).
- Clone luxR gene under a constitutive promoter (e.g., J23100).
- Place GFP under control of Plux promoter.
- Assemble the parts into a single plasmid or two compatible plasmids.
Example: Using Golden Gate Assembly for modular cloning.
Step 4: Transformation and Testing
- Transform E. coli with the constructed plasmid(s).
- Grow cultures at varying initial densities.
- Measure GFP fluorescence over time using a plate reader or flow cytometer.
Expected outcome: GFP expression remains low at low cell density and increases sharply once AHL concentration crosses the threshold.
Mind Map: Experimental Workflow
Step 5: Troubleshooting and Optimization
- Low GFP signal: Check promoter strengths; increase luxI or luxR expression.
- High background expression: Use tighter repressible promoters or add degradation tags to GFP.
- Slow response time: Optimize AHL diffusion by adjusting culture volume or shaking speed.
Best Practice: Use computational modeling (e.g., ODE simulations) to predict circuit behavior before experiments.
Example: Simple ODE Model of the QS Circuit
Let:
- [AHL] = concentration of autoinducer
- [LuxR] = concentration of LuxR protein
- [GFP] = concentration of GFP
Equations:
d[AHL]/dt = k_synth * [LuxI] - k_deg * [AHL]
Activation = [LuxR] * [AHL] / (K_d + [AHL])
d[GFP]/dt = k_expr * Activation - k_deg_gfp * [GFP]
Simulating these equations helps predict the threshold and dynamics of GFP expression.
Summary
Constructing a quorum sensing-based genetic circuit involves integrating biological parts that produce and detect signaling molecules, enabling population-density-dependent gene expression. By following modular design principles, leveraging standardized parts, and validating with both experiments and modeling, engineers can build robust synthetic biology systems.
Additional Resources
- iGEM Registry of Standard Biological Parts
- Synthetic Biology Open Language (SBOL)
- COPASI for modeling biochemical networks
This hands-on example provides a foundational approach to engineering QS circuits, which can be expanded for complex applications such as synchronized oscillators, population control, or biosensing platforms.
4. Host Selection and Genome Engineering
4.1 Criteria for Selecting Host Organisms in Synthetic Biology
Selecting the appropriate host organism is a foundational step in synthetic biology projects. The choice directly impacts the success of genetic circuit implementation, metabolic engineering, and overall system performance. This section explores the key criteria engineers should consider when choosing host organisms, supported by practical examples and mind maps to clarify decision-making.
Key Criteria for Host Selection
-
Genetic Accessibility
- Ease of genetic manipulation (transformation, genome editing)
- Availability of genetic tools and well-characterized parts
-
Growth Characteristics
- Growth rate and doubling time
- Culture conditions (temperature, media requirements)
- Scalability for industrial applications
-
Metabolic Compatibility
- Native metabolic pathways relevant to the target product
- Ability to support heterologous pathway expression
-
Safety and Regulatory Status
- Biosafety level (BSL)
- GRAS (Generally Recognized As Safe) status for industrial or clinical use
-
Stability and Robustness
- Genetic stability of inserted constructs
- Resistance to environmental stresses
-
Compatibility with Downstream Processing
- Ease of product extraction and purification
-
Community and Resource Availability
- Availability of genomic data, databases, and community support
Mind Map: Criteria for Selecting Host Organisms
Practical Examples
Example 1: Choosing Escherichia coli for Rapid Prototyping
- Genetic Accessibility: E. coli is one of the most genetically tractable organisms with a vast array of cloning vectors, genome editing tools (CRISPR, recombineering), and standardized parts (BioBricks).
- Growth Characteristics: Fast doubling time (~20 min), easy to culture in simple media.
- Metabolic Compatibility: Well-understood metabolism, suitable for expressing many heterologous proteins.
- Safety: Classified as BSL-1, widely used in labs.
Use Case: Rapid prototyping of genetic circuits such as toggle switches or oscillators.
Example 2: Using Saccharomyces cerevisiae for Metabolic Engineering
- Genetic Accessibility: Advanced genome editing tools available, though slower than E. coli.
- Growth Characteristics: Moderate growth rate, requires more complex media.
- Metabolic Compatibility: Eukaryotic metabolism allows for post-translational modifications.
- Safety: GRAS status, widely used in food and pharmaceutical industries.
Use Case: Production of complex natural products like artemisinic acid.
Example 3: Employing Bacillus subtilis for Protein Secretion
- Genetic Accessibility: Good genetic tools, though less extensive than E. coli.
- Growth Characteristics: Robust growth, forms spores for long-term storage.
- Metabolic Compatibility: Efficient secretion pathways.
- Safety: BSL-1, considered safe for industrial use.
Use Case: Production and secretion of industrial enzymes.
Mind Map: Example Host Organisms and Their Strengths
Summary
Selecting the right host organism requires balancing multiple factors including genetic tractability, growth conditions, metabolic capabilities, safety, and downstream processing needs. By carefully evaluating these criteria and leveraging community knowledge and resources, bioengineers can optimize synthetic biology systems for their specific applications.
Additional Resources
- Registry of Standard Biological Parts
- NCBI Genome Database
- Addgene Plasmid Repository
This comprehensive approach ensures that engineers can make informed decisions that streamline development cycles and improve system reliability.
4.2 Genome Editing Techniques: CRISPR, TALENs, and Beyond
Genome editing has revolutionized synthetic biology by enabling precise, efficient, and programmable modifications of an organism’s DNA. This section explores the most widely used genome editing tools—CRISPR-Cas systems, TALENs, and other emerging technologies—highlighting their mechanisms, applications, and best practices through clear examples and mind maps.
Overview of Genome Editing Tools
Genome Editing Techniques Mind Map
CRISPR-Cas Systems
Mechanism: Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and CRISPR-associated (Cas) proteins form an adaptive immune system in bacteria. In genome editing, a guide RNA (gRNA) directs the Cas nuclease to a specific DNA sequence, where it introduces a double-strand break (DSB). The cell repairs the break via non-homologous end joining (NHEJ) or homology-directed repair (HDR), enabling targeted gene disruption or insertion.
Best Practice:
- Design highly specific gRNAs using computational tools to minimize off-target effects.
- Use high-fidelity Cas variants (e.g., SpCas9-HF1) for increased specificity.
- Validate edits with sequencing and phenotypic assays.
Example: Engineering E. coli to knock out the lacZ gene using CRISPR-Cas9:
- Design gRNA targeting lacZ.
- Deliver Cas9 and gRNA plasmid into E. coli.
- Select mutants by blue-white screening (white colonies indicate successful knockout).
TALENs (Transcription Activator-Like Effector Nucleases)
Mechanism: TALENs are engineered proteins combining a customizable DNA-binding domain derived from transcription activator-like effectors (TALEs) and a FokI nuclease domain. Each TALE repeat recognizes a single nucleotide, allowing modular assembly to target specific DNA sequences. FokI dimerization induces DSBs at the target site.
Best Practice:
- Carefully design TALE arrays for specificity.
- Use paired TALENs to ensure nuclease dimerization and reduce off-target cleavage.
- Validate cleavage efficiency in vitro before in vivo application.
Example: Targeted disruption of the tyr gene in zebrafish to study pigmentation:
- Assemble TALEN pairs targeting tyr exon.
- Inject mRNA encoding TALENs into zebrafish embryos.
- Observe pigmentation loss in larvae as phenotypic confirmation.
Beyond CRISPR and TALENs: Emerging Genome Editing Technologies
-
Base Editors: Enable direct conversion of one base pair to another (e.g., C→T or A→G) without DSBs.
Example: Correcting a point mutation in the HBB gene responsible for sickle cell anemia using cytosine base editors.
-
Prime Editors: Use a reverse transcriptase fused to Cas9 nickase and a prime editing guide RNA (pegRNA) to write new genetic information directly into a target site.
Example: Precise insertion of a short DNA sequence in mammalian cells without donor DNA templates.
-
CRISPR-associated Transposases: Facilitate RNA-guided DNA insertions without DSBs.
Example: Site-specific integration of large DNA fragments in bacterial genomes.
Emerging Genome Editing Techniques Mind Map
Practical Example: Using CRISPR-Cas12a for Multiplexed Editing in Yeast
- Cas12a (Cpf1) recognizes a T-rich PAM and processes its own CRISPR array, enabling multiplex editing.
- Design a CRISPR array with multiple gRNAs targeting metabolic genes.
- Transform Saccharomyces cerevisiae with Cas12a and CRISPR array plasmid.
- Achieve simultaneous knockout of multiple genes to optimize a biosynthetic pathway.
Summary of Best Practices
- Target Design: Use computational tools (e.g., Benchling, CHOPCHOP) for gRNA and TALEN design to maximize specificity.
- Validation: Combine molecular assays (PCR, sequencing) with phenotypic screens.
- Minimize Off-Target Effects: Employ high-fidelity nucleases and carefully validate.
- Delivery Methods: Choose appropriate delivery (plasmid, RNP complexes, viral vectors) based on host and application.
- Safety: Follow biosafety guidelines and ethical considerations when editing genomes.
This section equips bioengineers and systems engineers with a practical understanding of genome editing tools, empowering them to select and implement the most suitable techniques for their synthetic biology projects.
4.3 Best Practice: Minimizing Off-Target Effects in Genome Editing
Genome editing technologies such as CRISPR-Cas9, TALENs, and Zinc Finger Nucleases have revolutionized synthetic biology by enabling precise modifications of genetic material. However, one of the critical challenges in genome editing is minimizing off-target effects — unintended modifications at genomic sites other than the intended target. These off-target edits can lead to undesired mutations, potentially compromising the function of engineered systems or causing safety concerns.
Understanding Off-Target Effects
Off-target effects occur when the genome editing tool binds and cleaves DNA sequences similar but not identical to the target sequence. Factors influencing off-target activity include:
- Sequence similarity to the target site
- Chromatin accessibility
- Concentration and delivery method of the editing components
- Guide RNA design (in CRISPR systems)
Mind Map: Factors Influencing Off-Target Effects
Best Practices to Minimize Off-Target Effects
-
Careful Guide RNA Design (for CRISPR-Cas Systems):
- Use computational tools (e.g., CRISPOR, Benchling, CHOPCHOP) to design guide RNAs with minimal predicted off-target sites.
- Select guides with high specificity scores and low off-target potential.
- Avoid guides with homology to repetitive or highly conserved genomic regions.
-
Use High-Fidelity Nucleases:
- Employ engineered Cas9 variants (e.g., eSpCas9, SpCas9-HF1) with reduced off-target cleavage.
- Consider alternative nucleases like Cas12a (Cpf1) which may have different specificity profiles.
-
Optimize Delivery Methods:
- Deliver ribonucleoprotein (RNP) complexes instead of plasmids to reduce nuclease exposure time.
- Use transient delivery systems to limit nuclease activity duration.
-
Titrate Nuclease and Guide RNA Concentrations:
- Use the minimal effective concentration to achieve editing, reducing off-target risk.
-
Validate Off-Target Sites Experimentally:
- Use unbiased genome-wide off-target detection methods such as GUIDE-seq, Digenome-seq, or SITE-seq.
- Perform targeted deep sequencing of predicted off-target loci.
-
Employ Paired Nickases or Base Editors:
- Use Cas9 nickase mutants that create single-strand breaks requiring two guides, increasing specificity.
- Use base editors to make precise nucleotide changes without double-strand breaks.
Mind Map: Strategies to Minimize Off-Target Effects
Practical Example: Minimizing Off-Target Effects in Engineering E. coli with CRISPR-Cas9
Scenario: Engineering E. coli to optimize a metabolic pathway by knocking out a repressor gene using CRISPR-Cas9.
Step 1: Guide RNA Design
- Use the CHOPCHOP tool to design sgRNAs targeting the repressor gene.
- Select sgRNAs with the highest specificity scores and no predicted off-targets in essential genes.
Step 2: Use High-Fidelity Cas9 Variant
- Choose SpCas9-HF1 to reduce off-target cleavage.
Step 3: Delivery Method
- Deliver Cas9 protein complexed with sgRNA as an RNP to E. coli via electroporation, limiting nuclease exposure.
Step 4: Validation
- Perform targeted deep sequencing of the top 5 predicted off-target sites.
- Confirm absence of unintended edits.
Outcome: Efficient knockout of the repressor gene with no detectable off-target mutations, resulting in enhanced metabolic flux.
Additional Example: Using Paired Nickases in Mammalian Cells
Context: Correcting a point mutation in a mammalian cell line.
- Design two sgRNAs targeting opposite strands near the mutation site.
- Use Cas9 nickase mutants (D10A or H840A) to create single-strand breaks.
- The paired nicks induce a double-strand break only at the target site, reducing off-target cleavage.
- Validate editing via sequencing and off-target analysis.
Summary
Minimizing off-target effects is critical for the safety, reliability, and efficiency of genome editing in synthetic biology. By combining thoughtful guide design, use of high-fidelity nucleases, optimized delivery, and thorough validation, bioengineers can significantly reduce unintended genomic alterations. Integrating these best practices into workflows ensures robust and predictable synthetic biology systems.
4.4 Practical Example: Engineering E. coli for Metabolic Pathway Optimization
Metabolic pathway optimization in Escherichia coli is a cornerstone practice in synthetic biology, enabling enhanced production of valuable compounds such as biofuels, pharmaceuticals, and specialty chemicals. This section walks through a practical example of engineering E. coli to optimize a metabolic pathway, integrating best practices, design considerations, and illustrative mind maps.
Overview
The goal is to optimize the production of L-tryptophan, an essential amino acid with applications in nutrition and pharmaceuticals, by engineering the native metabolic pathways in E. coli.
Step 1: Understanding the Native Pathway
The L-tryptophan biosynthesis pathway in E. coli involves several enzymatic steps converting chorismate to L-tryptophan. Key enzymes include TrpE, TrpD, TrpC, TrpB, and TrpA.
Mind Map: Native L-Tryptophan Biosynthesis Pathway in E. coli
Step 2: Identifying Bottlenecks and Regulatory Points
- Feedback inhibition by L-tryptophan on TrpE
- Limited precursor availability (chorismate)
- Competing pathways consuming chorismate
Mind Map: Bottlenecks in L-Tryptophan Production
Step 3: Engineering Strategies
- Relieve Feedback Inhibition
- Mutate TrpE to a feedback-resistant variant
- Increase Precursor Supply
- Overexpress genes in the shikimate pathway leading to chorismate
- Reduce Competing Pathways
- Knockout genes leading to phenylalanine and tyrosine biosynthesis
- Enhance Pathway Flux
- Overexpress trp operon genes
- Optimize Cofactor Availability
- Ensure sufficient supply of phosphoribosyl pyrophosphate (PRPP)
Mind Map: Engineering Strategies for Optimization
Step 4: Implementation Example
- Genetic Constructs:
- Use plasmids or genomic integration to overexpress aroG (DAHP synthase), aroB, aroD, aroE, and trp operon genes.
- Introduce feedback-resistant mutation in aroG (e.g., aroGfbr) and trpE.
- Gene Knockouts:
- Use CRISPR-Cas9 or lambda-Red recombineering to knockout pheA and tyrA.
- Promoter Selection:
- Use strong constitutive or inducible promoters (e.g., Ptac, PBAD) for controlled expression.
Mind Map: Genetic Engineering Implementation
Step 5: Validation and Optimization
- Metabolite Analysis: Use HPLC or LC-MS to quantify L-tryptophan production.
- Growth Monitoring: Ensure cell growth is not severely compromised.
- Flux Analysis: Use 13C metabolic flux analysis to verify pathway flux changes.
- Iterative Optimization: Adjust promoter strengths, copy numbers, and culture conditions.
Mind Map: Validation and Optimization Workflow
Example Outcome
A study implementing these strategies achieved a 5- to 10-fold increase in L-tryptophan titer compared to wild-type E. coli. This demonstrates the power of combining genetic engineering with systems-level understanding.
Summary of Best Practices
- Map native pathways and regulatory mechanisms thoroughly.
- Use modular genetic parts for flexible design.
- Employ feedback-resistant enzyme variants to bypass natural inhibition.
- Balance precursor supply and competing pathways.
- Validate with quantitative metabolite and flux analyses.
- Iterate design-build-test cycles for optimization.
This practical example illustrates how bioengineers and synthetic biologists can systematically optimize metabolic pathways in E. coli by integrating genetic engineering, computational analysis, and experimental validation.
4.5 Safety and Containment Strategies in Engineered Hosts
Ensuring safety and effective containment of engineered hosts is a cornerstone of responsible synthetic biology practice. This section explores the strategies used to minimize risks associated with genetically modified organisms (GMOs), focusing on practical approaches, design principles, and real-world examples.
Why Safety and Containment Matter
- Prevent unintended environmental release
- Avoid horizontal gene transfer to native species
- Protect human health and ecosystems
- Comply with regulatory frameworks
Key Safety and Containment Strategies
Physical Containment
- Use of controlled laboratory environments (biosafety cabinets, clean rooms)
- Facility design with multiple containment barriers
- Example: Working with E. coli K-12 strains in BSL-1 labs
Biological Containment
- Engineering genetic safeguards into host organisms
- Kill switches and auxotrophy
- Genetic firewalling to prevent gene transfer
Chemical Containment
- Dependency on synthetic nutrients or chemicals absent in nature
- Example: Synthetic auxotrophy requiring non-natural amino acids
Ecological Containment
- Designing hosts with limited survival outside controlled conditions
- Temperature-sensitive mutants
Mind Map: Overview of Safety and Containment Strategies
Biological Containment in Detail
Kill Switches
- Genetically encoded circuits that trigger cell death under specific conditions
- Types:
- Inducible kill switches (activated by external signals)
- Fail-safe kill switches (triggered by loss of synthetic molecule)
Example:
- The ‘Deadman’ kill switch: engineered to activate toxin expression when a synthetic inducer is absent, ensuring cells die if released into the environment.
Auxotrophy
- Engineering hosts to require synthetic nutrients or metabolites not found in nature
- Prevents survival outside lab conditions
Example:
- E. coli strains engineered to require synthetic amino acids like p-aminophenylalanine, which are not naturally available.
Genetic Firewalling
- Use of recoded genomes or synthetic base pairs to prevent horizontal gene transfer
Example:
- Organisms with recoded genetic codes that are incompatible with natural organisms, reducing gene flow risk.
Mind Map: Biological Containment Strategies
Chemical Containment: Synthetic Auxotrophy
- Hosts engineered to depend on non-natural chemicals
- Ensures survival only in presence of supplied compound
Example:
- A synthetic organism requiring a non-natural amino acid for protein synthesis, preventing growth outside lab-supplied media.
Ecological Containment
- Engineering hosts with limited environmental fitness
- Examples:
- Temperature-sensitive mutants that cannot survive outside controlled temperature ranges
- Reduced motility or nutrient uptake capabilities
Example:
- Temperature-sensitive Saccharomyces cerevisiae strains used in fermentation that cannot survive ambient temperatures.
Integrated Safety Design: Combining Strategies
- Layered approach enhances robustness
- Example:
- An engineered E. coli strain with:
- Auxotrophy for synthetic amino acid
- Kill switch activated by absence of inducer
- Physical containment in BSL-2 lab
- An engineered E. coli strain with:
Mind Map: Integrated Safety Design
Real-World Example: Safe Engineering of E. coli for Bioproduction
- Objective: Produce biofuels safely at pilot scale
- Strategies implemented:
- Auxotrophy for synthetic amino acid to prevent environmental survival
- Kill switch triggered by absence of lab-specific inducer molecule
- Work conducted in contained bioreactors with controlled waste treatment
Outcome: No detectable survival of engineered strains outside containment, meeting regulatory safety standards.
Best Practices Summary
- Employ multiple containment strategies simultaneously
- Validate kill switch efficacy under varied conditions
- Monitor for genetic mutations that disable safeguards
- Maintain rigorous physical containment protocols
- Engage with regulatory bodies early in design
Conclusion
Safety and containment are fundamental to the responsible engineering of synthetic biology hosts. By integrating physical, biological, chemical, and ecological strategies, engineers can design systems that minimize risk while enabling innovation. Practical examples and layered approaches provide a roadmap for achieving robust containment in diverse applications.
5. Computational Tools and Modeling
5.1 Role of Computational Biology in Synthetic Systems Design
Computational biology plays a pivotal role in the design, analysis, and optimization of synthetic biology systems. By integrating computational methods with biological data, engineers can predict system behavior, optimize genetic circuits, and reduce costly trial-and-error experiments. This section explores the multifaceted contributions of computational biology to synthetic systems design, supported by illustrative mind maps and practical examples.
Why Computational Biology is Essential in Synthetic Biology
- Predictive Modeling: Anticipate the behavior of genetic circuits before physical implementation.
- Design Optimization: Refine genetic constructs for efficiency, stability, and robustness.
- Data Integration: Combine multi-omics datasets to inform system design.
- Simulation of Dynamics: Understand temporal behavior and stochasticity in biological systems.
- Automation and High-Throughput Analysis: Process large datasets from synthetic biology experiments.
Mind Map: Core Roles of Computational Biology in Synthetic Systems Design
Computational Approaches in Synthetic Biology
-
Mathematical Modeling
- Ordinary Differential Equations (ODEs) model gene expression dynamics.
- Stochastic simulations capture intrinsic noise in small populations.
-
Bioinformatics Tools
- Sequence analysis for designing promoters, ribosome binding sites, and terminators.
- Predicting off-target effects in genome editing.
-
Machine Learning and AI
- Predicting functional outcomes of genetic modifications.
- Optimizing metabolic pathways based on large datasets.
-
Design Automation Software
- Tools like SBOL (Synthetic Biology Open Language) enable standardized design exchange.
- CAD tools for circuit design and simulation.
Mind Map: Computational Approaches and Tools
Practical Example 1: Predicting a Genetic Toggle Switch Behavior
Scenario: Designing a bistable genetic toggle switch that flips between two states in response to an inducer.
Computational Role:
- Use ODE-based models to simulate the switch’s response to varying inducer concentrations.
- Perform sensitivity analysis to identify parameters critical for stable switching.
- Optimize promoter strengths and degradation rates computationally before lab implementation.
Outcome:
- Reduced experimental iterations.
- Enhanced understanding of system robustness.
Practical Example 2: Integrating Multi-Omics Data for Metabolic Pathway Design
Scenario: Engineering a microbial strain to produce a novel biofuel.
Computational Role:
- Integrate genomics, transcriptomics, and proteomics data to identify bottlenecks.
- Model metabolic fluxes to predict the impact of gene knockouts or overexpression.
- Use machine learning to predict enzyme variants with improved activity.
Outcome:
- Rational design of metabolic pathways.
- Increased yield and productivity.
Mind Map: Example Workflow for Computational Design in Synthetic Biology
Summary
Computational biology serves as the backbone for modern synthetic biology system design. By leveraging mathematical models, bioinformatics, machine learning, and automation tools, engineers can design more reliable, efficient, and innovative biological systems. The integration of computational approaches not only accelerates the design-build-test cycle but also deepens our understanding of complex biological networks.
5.2 Modeling Genetic Circuits Using ODEs and Stochastic Methods
Modeling genetic circuits is a cornerstone of synthetic biology, enabling engineers to predict system behavior, optimize designs, and understand dynamic responses before experimental implementation. Two primary modeling approaches dominate this field: deterministic models using Ordinary Differential Equations (ODEs) and stochastic models that capture the inherent randomness in biological systems.
Overview of Modeling Approaches
- Deterministic Models (ODEs): Assume continuous concentrations and average behavior over large populations of molecules.
- Stochastic Models: Capture discrete molecular events and random fluctuations, crucial for low-copy-number species.
Mind Map: Modeling Genetic Circuits
Ordinary Differential Equations (ODEs) in Genetic Circuits
ODEs describe the time evolution of molecular species concentrations by expressing the rate of change as functions of current concentrations and parameters.
Example: Simple Repressor Circuit
Consider a gene producing a protein (P) that represses its own expression.
- Let (m(t)) be mRNA concentration.
- Let (P(t)) be protein concentration.
The system can be modeled as:
\[ \frac{dm}{dt} = \frac{\alpha}{1 + (P/K)^n} - \delta_m m \]
\[ \frac{dP}{dt} = \beta m - \delta_p P \]
Where:
- \(\alpha\): maximum transcription rate
- \(K\): repression threshold
- \(n\): Hill coefficient (cooperativity)
- \(\delta_m, \delta_p\): degradation rates
- \(\beta\): translation rate
Mind Map: ODE Modeling Workflow
Practical Example: Modeling a Genetic Toggle Switch
The genetic toggle switch consists of two genes mutually repressing each other, creating bistability.
ODEs:
\[ \frac{dP_1}{dt} = \frac{\alpha_1}{1 + (P_2/K_2)^{n_2}} - \delta_1 P_1 \]
\[ \frac{dP_2}{dt} = \frac{\alpha_2}{1 + (P_1/K_1)^{n_1}} - \delta_2 P_2 \]
By solving these equations numerically, one can observe two stable steady states corresponding to high \(P_1\)/low \(P_2\) and low \(P_1\)/high \(P_2\).
Stochastic Modeling of Genetic Circuits
Biological systems often operate with small numbers of molecules, where random fluctuations (noise) significantly impact behavior. Stochastic models simulate individual reaction events probabilistically.
Key Methods:
- Gillespie Algorithm: Exact stochastic simulation of reaction events.
- Tau-leaping: Approximate method for faster simulations.
Mind Map: Stochastic Modeling Concepts
Example: Stochastic Simulation of a Birth-Death Process
Consider a protein synthesized at rate \(k_s\) and degraded at rate \(k_d\).
- Reactions:
- Synthesis: \(\emptyset \xrightarrow{k_s} P\)
- Degradation: \(P \xrightarrow{k_d} \emptyset\)
Using Gillespie’s algorithm, simulate the time evolution of protein counts. The simulation reveals fluctuations around the mean predicted by the deterministic model.
Integrating Deterministic and Stochastic Models
Hybrid approaches combine ODEs for abundant species and stochastic methods for low-copy species, balancing accuracy and computational efficiency.
Best Practices for Modeling Genetic Circuits
- Start Simple: Begin with deterministic models to capture overall dynamics.
- Incorporate Stochasticity: Use stochastic simulations when noise impacts function.
- Parameter Sensitivity Analysis: Identify critical parameters influencing behavior.
- Validate Models: Compare predictions with experimental data iteratively.
- Use Established Tools: Leverage software like COPASI, BioNetGen, or StochPy.
Summary
Modeling genetic circuits using ODEs and stochastic methods provides complementary insights into system dynamics and noise. Engineers can leverage these tools to design robust synthetic biology systems, anticipate variability, and optimize circuit performance before experimental implementation.
5.3 Best Practice: Integrating Experimental Data with Predictive Models
Integrating experimental data with predictive models is a cornerstone best practice in synthetic biology and computational biology. This integration enables engineers and scientists to refine models, validate hypotheses, and accelerate the design-build-test-learn cycle. By combining real-world data with computational predictions, synthetic biology systems become more robust, reliable, and scalable.
Why Integrate Experimental Data with Predictive Models?
- Model Validation: Ensures that computational models accurately reflect biological reality.
- Parameter Estimation: Experimental data helps in fine-tuning model parameters for better predictions.
- Hypothesis Testing: Models can be used to generate hypotheses that are then tested experimentally.
- Design Optimization: Iterative integration refines system designs for improved performance.
Key Steps in Integration
Practical Example: Modeling a Synthetic Genetic Oscillator
Context: A synthetic biologist engineers a genetic oscillator circuit in E. coli to produce rhythmic protein expression. The goal is to predict oscillation period and amplitude under varying conditions.
Step 1: Collect Experimental Data
- Measure protein fluorescence over time using flow cytometry.
- Obtain time-series data at different inducer concentrations.
Step 2: Preprocess Data
- Normalize fluorescence intensity to cell count.
- Smooth noisy data using moving averages.
Step 3: Select Model
- Use a system of ordinary differential equations (ODEs) representing gene expression and protein degradation.
Step 4: Parameter Estimation
- Apply nonlinear least squares fitting to estimate transcription rates, degradation constants.
- Use Bayesian inference to quantify parameter uncertainties.
Step 5: Model Validation
- Compare predicted oscillation periods with experimental observations.
- Perform residual analysis to identify model discrepancies.
Step 6: Iterative Refinement
- Adjust model structure to include additional feedback loops based on discrepancies.
- Design new experiments to test updated model predictions.
Mind Map: Workflow for Integrating Data and Models in Synthetic Biology
Additional Example: Predicting Metabolic Fluxes in Engineered Yeast
Scenario: Engineers want to optimize the production of a biofuel precursor by modifying yeast metabolism.
- Experimental Data: 13C metabolic flux analysis (MFA) data collected under different growth conditions.
- Model: Constraint-based metabolic model (Flux Balance Analysis).
- Integration: Use MFA data to constrain and validate flux predictions.
- Outcome: Identification of bottlenecks and targets for genetic modification.
Tips for Effective Integration
- Ensure high-quality, reproducible experimental data.
- Use appropriate statistical methods to handle noise and variability.
- Choose models that balance complexity and interpretability.
- Employ iterative cycles of modeling and experimentation.
- Document assumptions and limitations clearly.
By embracing this best practice, bioengineers and systems engineers can harness the full power of synthetic biology, transforming raw experimental data into actionable insights and predictive capabilities that drive innovation.
5.4 Software Platforms: COPASI, CellDesigner, and SBOL
In synthetic biology and computational biology, software platforms play a crucial role in designing, modeling, simulating, and sharing biological systems. This section explores three widely used platforms — COPASI, CellDesigner, and SBOL — highlighting their features, use cases, and practical examples to help engineers effectively leverage these tools.
COPASI (COmplex PAthway SImulator)
COPASI is a powerful software application for simulation and analysis of biochemical networks and their dynamics. It supports deterministic and stochastic simulations, parameter estimation, sensitivity analysis, and steady-state analysis.
Key Features:
- Supports ODE-based deterministic and stochastic simulations.
- Parameter estimation and optimization tools.
- Sensitivity and metabolic control analysis.
- User-friendly GUI and command-line interface.
- Import/export support for SBML (Systems Biology Markup Language).
Mind Map: COPASI Core Functionalities
Example Use Case:
Modeling a Synthetic Genetic Oscillator
An engineer can use COPASI to simulate a synthetic oscillator circuit by defining the reaction network and kinetic parameters. By running stochastic simulations, they can observe oscillation robustness under noise and perform sensitivity analysis to identify critical parameters.
CellDesigner
CellDesigner is a structured diagram editor for drawing gene-regulatory and biochemical networks. It integrates graphical modeling with simulation capabilities and supports SBML standards.
Key Features:
- Intuitive graphical interface for pathway and network design.
- Supports SBML for model exchange.
- Integration with simulation engines (e.g., COPASI).
- Annotation and compartmentalization of biological components.
- Export diagrams in various formats (SBML, PNG, PDF).
Mind Map: CellDesigner Functional Overview
Example Use Case:
Designing a Biosynthetic Pathway
A bioengineer can use CellDesigner to visually construct a metabolic pathway for producing a target compound. The graphical model can then be exported to COPASI for dynamic simulation, enabling iterative design and optimization.
SBOL (Synthetic Biology Open Language)
SBOL is a standardized data format and language designed to represent synthetic biology designs, focusing on genetic parts, devices, and systems. It facilitates sharing and reuse of designs across tools and teams.
Key Features:
- Standardized representation of genetic constructs and annotations.
- Supports hierarchical design (parts, devices, systems).
- Compatible with many synthetic biology design tools.
- Enables interoperability and reproducibility.
Mind Map: SBOL Structure and Usage
Example Use Case:
Sharing a Genetic Circuit Design
A systems engineer designs a genetic toggle switch using SBOL-compliant software. The design is saved in SBOL format, allowing seamless sharing with collaborators who can import the design into other tools for simulation or physical assembly.
Integrated Workflow Example
- Design: Use CellDesigner to graphically build a gene regulatory network for a biosensor.
- Export: Save the design in SBML format.
- Simulate: Import the SBML file into COPASI to run deterministic and stochastic simulations, analyze system behavior, and optimize parameters.
- Share: Export the design in SBOL format for documentation and collaboration.
Summary Table
| Platform | Primary Function | Strengths | Example Application |
|---|---|---|---|
| COPASI | Simulation and analysis | Robust simulation, parameter fitting | Modeling genetic oscillators |
| CellDesigner | Graphical network design | Intuitive GUI, SBML support | Designing metabolic pathways |
| SBOL | Standardized design exchange | Interoperability, hierarchical design | Sharing genetic circuit designs |
By mastering these platforms, bioengineers and systems engineers can streamline the design-build-test cycle in synthetic biology, ensuring reproducibility, scalability, and collaboration across projects.
5.5 Example: Simulating a Synthetic Metabolic Pathway for Biofuel Production
Synthetic biology offers powerful tools to engineer microorganisms for biofuel production, enabling sustainable alternatives to fossil fuels. Computational simulation of metabolic pathways is a crucial step to predict system behavior, optimize yields, and guide experimental design.
Overview
This example walks through simulating a synthetic metabolic pathway engineered in Escherichia coli to produce isobutanol, a promising biofuel. We will cover pathway design, model formulation, parameter selection, simulation, and interpretation of results.
Step 1: Defining the Synthetic Metabolic Pathway
The engineered pathway diverts pyruvate from central metabolism to isobutanol via the keto-acid pathway. Key enzymes include:
- Acetolactate synthase (ALS)
- Ketol-acid reductoisomerase (KARI)
- Dihydroxyacid dehydratase (DHAD)
- Ketoacid decarboxylase (KDC)
- Alcohol dehydrogenase (ADH)
Mind Map: Synthetic Isobutanol Pathway
Step 2: Formulating the Model
We use ordinary differential equations (ODEs) to describe metabolite concentrations over time. Each reaction rate is modeled using Michaelis-Menten kinetics or mass-action kinetics where appropriate.
Example ODE for pyruvate concentration:
\[ \frac{d[Pyruvate]}{dt} = v_{glycolysis} - v_{ALS} - v_{competing}\]
Where:
- \(v_{glycolysis}\): rate of pyruvate formation from glucose
- \(v_{ALS}\): flux into synthetic pathway
- \(v_{competing}\): flux into competing pathways
Step 3: Parameter Selection and Initial Conditions
Parameters include enzyme kinetic constants (Km, Vmax), metabolite initial concentrations, and enzyme expression levels. Sources for parameters:
- Literature values
- Experimental data
- Estimations based on similar enzymes
Example parameter table:
| Parameter | Value | Unit | Source |
|---|---|---|---|
| Km_ALS | 0.1 | mM | [Ref1] |
| Vmax_ALS | 50 | µM/s | [Ref2] |
| Initial Pyruvate | 1.0 | mM | Assumed |
Step 4: Simulation Using COPASI
COPASI is a popular tool for biochemical system simulation.
Procedure:
- Define species (metabolites).
- Add reactions with kinetic laws.
- Input parameters.
- Set simulation time and method (e.g., deterministic ODE solver).
- Run time-course simulation.
Mind Map: Simulation Workflow in COPASI
Step 5: Interpreting Simulation Results
Typical outputs include metabolite concentration over time and flux through each reaction.
Example findings:
- Pyruvate pool depletion rate
- Isobutanol accumulation curve
- Identification of bottleneck enzymes (e.g., low flux through KDC)
Best Practice: Use sensitivity analysis to identify parameters with the greatest impact on isobutanol yield.
Step 6: Iterative Optimization
Based on simulation insights:
- Increase expression of bottleneck enzymes
- Knockout competing pathways
- Modify kinetic parameters via protein engineering
Re-run simulations to predict improved yields before experimental validation.
Summary Mind Map
Mind Map: Simulating Synthetic Metabolic Pathway for Biofuel
Additional Example: Python-Based Simulation Using Tellurium
import tellurium as te
# Define model in Antimony language
model = '''
model isobutanol_pathway
// Species
species Glucose, Pyruvate, Intermediate, Isobutanol;
// Parameters
k1 = 1.0; k2 = 0.5; k3 = 0.3;
// Reactions
J0: Glucose -> Pyruvate; k1*Glucose;
J1: Pyruvate -> Intermediate; k2*Pyruvate;
J2: Intermediate -> Isobutanol; k3*Intermediate;
// Initial concentrations
Glucose = 10; Pyruvate = 0; Intermediate = 0; Isobutanol = 0;
end
'''
r = te.loadAntimonyModel(model)
result = r.simulate(0, 50, 100)
r.plot(result)
This simple model can be expanded with detailed kinetics and additional metabolites to closely mimic the real pathway.
Conclusion
Simulating synthetic metabolic pathways is an essential practice for bioengineers to predict system behavior, optimize biofuel production, and reduce experimental costs. By combining pathway design, kinetic modeling, parameter estimation, and computational tools, engineers can iteratively refine synthetic systems toward industrial viability.
6. DNA Synthesis and Assembly Techniques
6.1 Overview of DNA Synthesis Technologies
DNA synthesis is a foundational technology in synthetic biology, enabling the creation of custom DNA sequences for engineering biological systems. This section explores the main DNA synthesis technologies, their principles, advantages, limitations, and practical examples.
Key DNA Synthesis Technologies
DNA Synthesis Technologies Mind Map
Chemical DNA Synthesis
The most widely used method for synthesizing short DNA oligonucleotides (typically up to 200 bases) is the phosphoramidite solid-phase synthesis. This method sequentially adds nucleotides to a growing chain anchored to a solid support.
-
Process:
- Deprotection of the 5’ hydroxyl group
- Coupling of the next nucleotide phosphoramidite
- Capping of unreacted ends
- Oxidation to stabilize the linkage
-
Best Practice: Use high-purity reagents and optimize coupling times to reduce errors.
-
Example: Synthesizing a 60-base promoter sequence for a genetic circuit.
Enzymatic DNA Synthesis
Emerging enzymatic methods aim to overcome length and error limitations of chemical synthesis by using enzymes like Terminal Deoxynucleotidyl Transferase (TdT) to add nucleotides without a template.
-
Advantages: Potential for longer sequences, environmentally friendly.
-
Challenges: Controlling sequence specificity and error rates.
-
Example: Experimental synthesis of long homopolymer tails for DNA barcoding.
DNA Assembly Methods
Since chemical synthesis is limited in length, longer DNA constructs are assembled from shorter oligos using various methods:
a. PCR-based Assembly
- Overlapping oligos are extended and amplified.
- Example: Assembling a synthetic gene from 40-mer oligos.
b. Gibson Assembly
- Uses exonuclease, polymerase, and ligase in one pot to join overlapping DNA fragments seamlessly.
- Best Practice: Design overlaps of 20-40 bp for efficient assembly.
- Example: Constructing a 5 kb plasmid containing multiple genes.
c. Golden Gate Assembly
- Employs Type IIS restriction enzymes and ligase for scarless, directional assembly.
- Example: Modular assembly of genetic parts into a standardized vector.
d. Modular Cloning (MoClo)
- A standardized Golden Gate-based system for hierarchical assembly.
- Example: Building multi-gene pathways for metabolic engineering.
Commercial DNA Synthesis Services
Many companies provide custom DNA synthesis, offering oligos, gene fragments, and entire plasmids.
-
Considerations: Cost, turnaround time, sequence complexity, and error correction options.
-
Best Practice: Use codon optimization and sequence verification to improve success rates.
-
Example: Ordering a codon-optimized synthetic gene for expression in yeast.
Summary Mind Map
Practical Example: Designing a Synthetic Promoter
- Step 1: Order chemically synthesized oligos encoding promoter elements (~60 bp).
- Step 2: Use PCR assembly to join overlapping oligos into a full promoter sequence.
- Step 3: Clone the promoter into a plasmid using Gibson Assembly.
- Step 4: Verify sequence accuracy by Sanger sequencing.
This workflow exemplifies integrating DNA synthesis technologies with assembly methods to create functional genetic parts.
By understanding the strengths and limitations of each DNA synthesis technology, bioengineers can select the best approach tailored to their synthetic biology projects, ensuring efficient and reliable construction of genetic systems.
6.2 Assembly Methods: Gibson, Golden Gate, and Modular Cloning
Synthetic biology relies heavily on efficient and reliable DNA assembly methods to construct complex genetic circuits and pathways. In this section, we explore three widely-used assembly techniques: Gibson Assembly, Golden Gate Assembly, and Modular Cloning (MoClo). Each method has unique advantages, best practices, and practical examples to help bioengineers select the most appropriate strategy for their projects.
Gibson Assembly
Overview: Gibson Assembly is an isothermal, seamless DNA assembly method that joins multiple DNA fragments with overlapping ends in a single reaction. It uses three enzymatic activities: exonuclease, DNA polymerase, and DNA ligase.
Key Features:
- Seamless assembly without scars
- Can assemble multiple fragments (up to 10 or more)
- Requires overlapping sequences (~20-40 bp)
Best Practices:
- Design overlaps carefully to avoid secondary structures and ensure specificity
- Use high-fidelity polymerase to amplify fragments
- Purify DNA fragments to remove inhibitors
Example: Assembling a 3-gene operon for a biosynthetic pathway:
- Design primers to add 30 bp overlaps between adjacent genes
- PCR amplify each gene fragment
- Mix fragments with Gibson Assembly Master Mix and incubate at 50°C for 1 hour
- Transform into E. coli and screen colonies by colony PCR
Mind Map:
Golden Gate Assembly
Overview: Golden Gate Assembly uses Type IIS restriction enzymes that cut outside their recognition sites, creating custom overhangs that enable directional and scarless assembly of multiple DNA fragments in one pot.
Key Features:
- Uses Type IIS enzymes (e.g., BsaI, BsmBI)
- Directional and scarless assembly
- Highly efficient for modular cloning
- One-pot digestion-ligation reaction
Best Practices:
- Design unique 4 bp overhangs for each junction
- Avoid internal Type IIS sites in parts or remove them via site-directed mutagenesis
- Use high-quality enzymes and fresh ligase
Example: Constructing a synthetic promoter-gene-terminator cassette:
- Design parts flanked by BsaI sites with specific overhangs
- Mix parts, BsaI, T4 DNA ligase, buffer in one tube
- Cycle between 37°C (digestion) and 16°C (ligation) for 30 cycles
- Transform and verify correct assembly
Mind Map:
Modular Cloning (MoClo)
Overview: Modular Cloning is a standardized Golden Gate-based system that uses hierarchical assembly levels to build complex genetic constructs from standardized parts.
Key Features:
- Hierarchical assembly: Level 0 (basic parts), Level 1 (transcription units), Level 2 (multi-gene constructs)
- Standardized syntax for parts
- Reusable and combinable modules
Best Practices:
- Follow the MoClo standard for part overhangs
- Validate Level 0 parts before assembly
- Use appropriate vectors for each assembly level
Example: Building a multi-gene pathway:
- Clone promoters, CDS, terminators as Level 0 parts
- Assemble transcription units at Level 1
- Combine multiple transcription units at Level 2
- Transform and verify by restriction digest or sequencing
Mind Map:
Comparative Summary Table
| Feature | Gibson Assembly | Golden Gate Assembly | Modular Cloning (MoClo) |
|---|---|---|---|
| Enzymes Used | Exonuclease, Polymerase, Ligase | Type IIS Restriction Enzyme + Ligase | Type IIS Restriction Enzyme + Ligase |
| Reaction Type | Isothermal | Thermal cycling | Thermal cycling |
| Assembly Style | Overlap-based | Overhang-based | Hierarchical Golden Gate |
| Number of Fragments | Up to 10+ | Multiple (up to 20+) | Multiple (hierarchical) |
| Scarless Assembly | Yes | Yes | Yes |
| Standardization | Low | Medium | High |
| Typical Applications | Multi-gene plasmids, pathway assembly | Modular parts, combinatorial libraries | Complex synthetic circuits, pathways |
Practical Tips for Choosing an Assembly Method
- Use Gibson Assembly when you have fragments with natural overlaps or when assembling fewer fragments with longer overlaps.
- Choose Golden Gate Assembly for rapid and efficient assembly of multiple standardized parts with defined overhangs.
- Opt for Modular Cloning (MoClo) when building complex, multi-gene constructs requiring hierarchical and reusable parts.
Summary
Understanding the strengths and limitations of Gibson, Golden Gate, and Modular Cloning methods empowers bioengineers to design and build synthetic biology systems efficiently. Combining these methods with best practices and thoughtful design accelerates the path from concept to functional biological systems.
6.3 Best Practice: Error Minimization and Quality Control in DNA Assembly
DNA assembly is a cornerstone of synthetic biology, enabling the construction of complex genetic constructs from smaller DNA fragments. However, errors during synthesis and assembly can lead to mutations, frame shifts, or incomplete constructs, which compromise downstream applications. Implementing robust error minimization and quality control (QC) strategies is essential for reliable and reproducible synthetic biology workflows.
Key Sources of Errors in DNA Assembly
- Synthesis Errors: Base misincorporations, deletions, or insertions during oligonucleotide synthesis.
- PCR Amplification Errors: Polymerase errors leading to mutations.
- Assembly Errors: Incorrect ligation, misaligned fragments, or incomplete assembly.
- Contamination: Cross-contamination causing mixed or unintended sequences.
Mind Map: Error Minimization Strategies in DNA Assembly
Best Practices for Error Minimization
-
Design with Redundancy and Checks:
- Incorporate unique restriction sites or barcode sequences to verify correct assembly.
- Use software tools (e.g., Benchling, SnapGene) to simulate assembly and identify potential issues.
-
Use High-Fidelity Enzymes:
- Employ proofreading polymerases such as Phusion or Q5 to reduce PCR errors.
- Select ligases and exonucleases optimized for your assembly method.
-
Optimize Reaction Conditions:
- Fine-tune temperature, time, and reagent concentrations to maximize assembly efficiency.
- Perform pilot reactions to identify optimal parameters.
-
Fragment Purification and Quantification:
- Purify PCR products or synthesized fragments to remove inhibitors.
- Use fluorometric methods (Qubit) for accurate DNA quantification rather than spectrophotometry.
-
Implement Rigorous Controls:
- Include negative controls to detect contamination.
- Use positive controls with known outcomes to validate assembly success.
-
Sequence Verification:
- Sequence multiple clones to identify and exclude erroneous constructs.
- For large assemblies, consider NGS or long-read sequencing.
Mind Map: Quality Control Workflow in DNA Assembly
Practical Example: Minimizing Errors in Gibson Assembly of a Multi-Gene Construct
Scenario: Assembling a 5-gene operon using Gibson Assembly.
Steps and Best Practices:
-
Fragment Design:
- Design 20-40 bp overlapping regions with balanced GC content.
- Avoid secondary structures in overlaps.
-
Fragment Preparation:
- PCR amplify each gene fragment using Q5 polymerase.
- Purify PCR products using spin columns.
- Quantify DNA with Qubit fluorometer.
-
Assembly Reaction:
- Use freshly prepared Gibson Assembly Master Mix.
- Optimize fragment molar ratios (equimolar or slight excess of smaller fragments).
- Incubate at 50°C for 60 minutes.
-
Transformation and Screening:
- Transform into high-efficiency competent cells.
- Screen colonies by colony PCR targeting junctions.
-
Sequence Verification:
- Sequence multiple positive clones covering all junctions and internal regions.
- Confirm absence of mutations or rearrangements.
-
Iterate if Necessary:
- If errors are detected, redesign problematic overlaps or optimize PCR conditions.
Additional Tips
- Use error-correcting synthesis services when ordering long DNA fragments.
- Employ digital droplet PCR (ddPCR) for precise quantification when needed.
- Maintain a clean workspace and use filter tips to reduce contamination risk.
- Document all steps meticulously to enable troubleshooting and reproducibility.
By integrating these error minimization and quality control practices into your DNA assembly workflows, you can significantly improve the reliability and efficiency of synthetic biology projects, reducing costly iterations and accelerating development timelines.
6.4 Practical Example: Rapid Prototyping of Multi-Gene Constructs
Rapid prototyping of multi-gene constructs is a cornerstone technique in synthetic biology that enables bioengineers to quickly design, assemble, and test complex genetic circuits or metabolic pathways. This section will guide you through the practical steps, best practices, and examples to efficiently prototype multi-gene constructs using modern DNA assembly techniques.
Why Rapid Prototyping Matters
- Accelerates the Design-Build-Test cycle
- Enables iterative optimization of genetic circuits
- Facilitates combinatorial assembly of gene variants
Step 1: Define Your Genetic Circuit or Pathway
- Identify the genes of interest
- Determine regulatory elements (promoters, RBS, terminators)
- Plan the order and orientation of genes
Mind Map: Defining Multi-Gene Constructs
Step 2: Choose an Assembly Method
- Golden Gate Assembly: Uses Type IIS restriction enzymes for scarless, one-pot assembly
- Gibson Assembly: Overlap-based, seamless assembly ideal for larger constructs
- Modular Cloning (MoClo): Hierarchical assembly using standardized parts
Best Practice:
Use Golden Gate for rapid, multi-part assembly when parts are standardized and free of internal restriction sites. Use Gibson for flexible, scarless assembly when overlaps can be designed.
Step 3: Design DNA Parts and Overlaps
- Use software tools like Benchling, SnapGene, or Geneious to design parts
- Ensure compatibility of overhangs or overlaps
- Include unique barcodes or identifiers if screening multiple variants
Mind Map: DNA Part Design Considerations
Step 4: DNA Synthesis and Preparation
- Order synthetic DNA fragments or oligonucleotides
- PCR amplify parts if necessary
- Purify DNA fragments to remove contaminants
Step 5: Assembly Reaction Setup
- Mix equimolar amounts of DNA parts
- Add enzymes (ligase, polymerase, restriction enzymes depending on method)
- Incubate under recommended conditions
Step 6: Transformation and Screening
- Transform assembled DNA into competent cells (e.g., E. coli)
- Plate on selective media
- Screen colonies using colony PCR, restriction digest, or sequencing
Example: Rapid Assembly of a Three-Gene Operon Using Golden Gate
Objective: Assemble a construct expressing three enzymes (GeneA, GeneB, GeneC) under a single promoter for a metabolic pathway.
Process:
- Design each gene with standardized 4 bp overhangs compatible with Golden Gate assembly.
- Include a strong constitutive promoter upstream and a terminator downstream.
- Order synthetic gene fragments free of BsaI sites.
- Set up a one-pot Golden Gate reaction with BsaI and T4 ligase.
- Transform into E. coli and plate on antibiotic media.
- Screen colonies by colony PCR targeting junctions between genes.
Outcome: Within 2 days, obtain multiple clones with correctly assembled operon ready for functional testing.
Mind Map: Rapid Prototyping Workflow
Tips for Successful Rapid Prototyping
- Validate parts individually before multi-gene assembly
- Use standardized parts and repositories (e.g., iGEM Registry, Addgene)
- Maintain detailed records of part sequences and assembly conditions
- Employ automation tools where possible to increase throughput
Summary
Rapid prototyping of multi-gene constructs combines thoughtful design, choice of appropriate assembly methods, and efficient screening strategies. By integrating these best practices, bioengineers can accelerate the development of complex synthetic biology systems, enabling faster iteration and optimization.
References and Tools
- Golden Gate Assembly Protocol
- Gibson Assembly Method
- Benchling (https://benchling.com)
- SnapGene (https://www.snapgene.com)
- iGEM Registry of Standard Biological Parts (http://parts.igem.org)
This practical example illustrates how combining modular design with efficient assembly techniques empowers engineers to prototype multi-gene constructs rapidly, bridging the gap between design and functional implementation.
6.5 Scaling Up: From Bench to Pilot-Scale DNA Assembly
Scaling DNA assembly from bench-scale experiments to pilot-scale production is a critical step for bioengineers aiming to transition synthetic biology projects into real-world applications. This section explores best practices, challenges, and practical examples to help engineers navigate this scale-up process effectively.
Key Considerations in Scaling Up DNA Assembly
- Reproducibility: Ensuring that assembly protocols yield consistent results at larger volumes.
- Cost Efficiency: Optimizing reagent use and workflow to reduce costs without sacrificing quality.
- Automation Compatibility: Integrating automated liquid handling and quality control systems.
- Quality Control: Implementing robust QC measures to detect errors early.
- Throughput: Balancing speed and accuracy to meet project timelines.
Mind Map: Scaling Up DNA Assembly Workflow
Best Practices for Scaling Up
-
Optimize Reaction Volumes and Concentrations: Larger volumes may require adjusting enzyme and DNA concentrations to maintain reaction efficiency.
-
Use High-Fidelity Enzymes: To minimize errors during assembly, especially important when producing constructs for downstream applications.
-
Implement Batch Controls: Include positive and negative controls in each batch to monitor assembly success.
-
Leverage Automation: Employ robotic pipetting systems to reduce human error and increase throughput.
-
Standardize Protocols: Develop SOPs that are scalable and reproducible across different operators and equipment.
-
Regular Quality Checks: Incorporate checkpoints after each major step to catch issues early.
Example 1: Scaling Gibson Assembly from 20 µL to 1 mL Reaction Volumes
Context: A synthetic biology team needed to assemble a 10-gene pathway construct for metabolic engineering.
Approach:
- Started with standard 20 µL Gibson Assembly reactions at bench scale.
- Gradually increased reaction volume to 1 mL using scaled reagent concentrations.
- Optimized incubation times and temperatures to maintain efficiency.
- Used magnetic bead purification to handle larger volumes efficiently.
- Validated assembly success via gel electrophoresis and Sanger sequencing.
Outcome:
- Achieved consistent assembly efficiency (>90%) at 1 mL scale.
- Reduced per-reaction cost by 30% due to bulk reagent purchasing.
- Enabled production of sufficient DNA for pilot-scale transformation and downstream applications.
Mind Map: Challenges and Solutions in Scaling DNA Assembly
Example 2: Automation Integration for Pilot-Scale Golden Gate Assembly
Context: A systems engineering group aimed to assemble hundreds of combinatorial variants of a genetic circuit.
Approach:
- Designed a Golden Gate assembly workflow compatible with 96-well plate format.
- Programmed liquid handling robots to perform digestion, ligation, and transformation steps.
- Incorporated barcode tracking for each variant.
- Automated colony picking and plasmid extraction.
Outcome:
- Increased throughput from tens to hundreds of assemblies per week.
- Reduced hands-on time by 70%.
- Improved reproducibility and traceability of constructs.
Practical Tips for Transitioning to Pilot-Scale
- Pilot Runs: Conduct intermediate scale runs (e.g., 100 µL to 500 µL) before full pilot scale to identify issues.
- Documentation: Maintain detailed logs of all parameters and outcomes to inform troubleshooting.
- Cross-Disciplinary Collaboration: Work closely with automation engineers and quality assurance teams.
- Scalable Storage Solutions: Plan for storage and handling of larger DNA quantities.
- Regulatory Compliance: Ensure protocols meet any applicable regulatory standards for production.
Summary
Scaling DNA assembly from bench to pilot scale requires careful optimization of protocols, integration of automation, and rigorous quality control. By applying best practices and learning from practical examples, bioengineers can effectively bridge the gap between research and application, enabling the production of complex synthetic biology constructs at meaningful scales.
7. Metabolic Engineering and Pathway Optimization
7.1 Principles of Metabolic Flux Analysis
Metabolic Flux Analysis (MFA) is a powerful quantitative tool used to analyze the flow of metabolites through metabolic pathways within a biological system. It enables bioengineers and systems engineers to understand cellular metabolism at a systems level, identify bottlenecks, and optimize pathways for improved production of desired compounds.
What is Metabolic Flux?
- Metabolic flux refers to the rate at which substrates and intermediates flow through a metabolic network.
- It reflects the dynamic state of metabolism rather than just static metabolite concentrations.
Why Perform Metabolic Flux Analysis?
- To quantify intracellular pathway activities.
- To identify rate-limiting steps and metabolic bottlenecks.
- To guide metabolic engineering strategies for pathway optimization.
- To validate computational models of metabolism.
Core Concepts in Metabolic Flux Analysis
Types of Metabolic Flux Analysis
-
Stoichiometric (Constraint-Based) MFA
- Uses stoichiometric models and mass balance equations.
- Assumes steady-state conditions (metabolite concentrations remain constant).
- Requires measurements of extracellular fluxes (e.g., substrate uptake, product secretion).
-
Isotopic Labeling MFA (13C-MFA)
- Uses isotopically labeled substrates (e.g., 13C-glucose).
- Tracks label incorporation into metabolites to resolve intracellular fluxes.
- Provides higher resolution and insight into pathway branching.
-
Dynamic MFA
- Accounts for time-dependent changes in metabolite concentrations.
- Useful for non-steady-state conditions.
Step-by-Step Workflow of Stoichiometric MFA
Example: MFA in E. coli for Biofuel Production
Scenario: Engineering E. coli to produce bioethanol from glucose.
- Objective: Quantify fluxes through glycolysis, pentose phosphate pathway, and ethanol fermentation.
- Approach: Use stoichiometric MFA with measured glucose uptake and ethanol secretion rates.
Step 1: Define network including key pathways.
Step 2: Construct stoichiometric matrix.
Step 3: Measure extracellular fluxes:
- Glucose uptake: 10 mmol/gDW/h
- Ethanol secretion: 8 mmol/gDW/h
Step 4: Solve mass balance equations to estimate intracellular fluxes.
Outcome: Identify that the pentose phosphate pathway flux is low, suggesting a bottleneck in NADPH generation.
Best Practice: Use this insight to engineer enzymes in the pentose phosphate pathway to enhance cofactor availability and improve ethanol yield.
Practical Tips and Best Practices
- Accurate Measurement: Ensure precise quantification of extracellular fluxes (substrate uptake, product secretion) as they anchor the flux calculations.
- Model Validation: Cross-validate MFA results with isotopic labeling experiments when possible.
- Iterative Refinement: Use MFA outcomes to iteratively refine metabolic models and engineering strategies.
- Software Tools: Utilize tools like COBRA Toolbox, OpenFLUX, or 13CFLUX2 for computational analysis.
Summary
Metabolic Flux Analysis is an indispensable technique for bioengineers aiming to optimize synthetic biology systems. By quantifying the flow of metabolites, MFA provides actionable insights into cellular metabolism, enabling rational design and engineering of metabolic pathways for enhanced production of valuable compounds.
7.2 Strategies for Pathway Balancing and Bottleneck Removal
In metabolic engineering, optimizing synthetic pathways is critical to maximize product yield, reduce by-products, and improve overall system efficiency. Pathway balancing and bottleneck removal are essential strategies that bioengineers use to fine-tune metabolic fluxes and ensure smooth operation of engineered pathways.
Understanding Pathway Balancing
Pathway balancing involves adjusting the expression levels and activities of enzymes in a metabolic pathway to ensure that intermediates are efficiently converted without accumulation or depletion. Imbalanced pathways often lead to bottlenecks, accumulation of toxic intermediates, or metabolic burden on the host.
Key goals of pathway balancing:
- Equalizing flux through all steps
- Preventing intermediate accumulation
- Minimizing metabolic burden
- Improving product yield and purity
Common Causes of Bottlenecks
- Low enzyme activity or expression
- Cofactor limitations
- Toxic intermediate accumulation
- Feedback inhibition
- Competing pathways diverting flux
Strategies for Pathway Balancing and Bottleneck Removal
Promoter and RBS Tuning
Adjusting promoter strength and ribosome binding site (RBS) sequences to modulate enzyme expression levels.
- Use libraries of promoters with graded strengths.
- Employ RBS calculators to predict translation initiation rates.
Example: In engineering a lycopene biosynthesis pathway in E. coli, tuning the promoter strength of the crtE gene improved flux balance and increased lycopene yield by 30%.
Gene Copy Number Variation
Altering the number of copies of pathway genes via plasmid copy number or chromosomal integration.
- High copy number plasmids for rate-limiting enzymes.
- Single-copy integration for enzymes prone to toxicity.
Enzyme Engineering
Improving enzyme kinetics or stability through directed evolution or rational design.
- Increase catalytic efficiency (kcat/Km).
- Reduce feedback inhibition sensitivity.
Example: Engineering a feedback-resistant variant of DAHP synthase relieved pathway inhibition in aromatic amino acid biosynthesis.
Cofactor Balancing
Ensuring sufficient availability of cofactors such as NADH, NADPH, ATP.
- Overexpress cofactor regeneration enzymes.
- Redirect metabolic fluxes to increase cofactor pools.
Dynamic Regulation
Using inducible or feedback-responsive promoters to dynamically balance pathway expression based on metabolite levels.
- Synthetic riboswitches or metabolite sensors.
- CRISPRi-based tunable repression.
Competing Pathway Knockouts
Deleting or downregulating genes in competing pathways to reduce flux diversion.
- Use CRISPR-Cas9 or recombineering for precise knockouts.
Substrate Channeling and Scaffold Engineering
Bringing enzymes into close proximity to facilitate substrate transfer and reduce intermediate loss.
- Use synthetic scaffolds or fusion proteins.
Mind Map: Strategies for Pathway Balancing and Bottleneck Removal
Practical Example: Balancing the Mevalonate Pathway for Isoprenoid Production
The mevalonate pathway is a common synthetic biology target for producing isoprenoids, valuable compounds used in pharmaceuticals and biofuels. Initial engineering efforts often face bottlenecks due to imbalanced enzyme expression and cofactor limitations.
Stepwise approach:
- Identify bottlenecks: Measure intermediate accumulation; HMG-CoA reductase often limits flux.
- Promoter tuning: Use a strong promoter for HMG-CoA reductase and moderate promoters for upstream enzymes.
- Gene copy adjustment: Increase copy number of rate-limiting genes on plasmids.
- Cofactor balancing: Overexpress NADPH regeneration enzymes to support reductase activity.
- Knockout competing pathways: Delete genes diverting acetyl-CoA to fatty acid synthesis.
- Dynamic control: Implement a feedback-regulated promoter responsive to isoprenoid levels.
Outcome: Balanced pathway expression led to a 5-fold increase in isoprenoid titer with reduced intermediate toxicity.
Summary
Effective pathway balancing and bottleneck removal require a combination of genetic, enzymatic, and regulatory strategies. By iteratively tuning expression, engineering enzymes, managing cofactors, and controlling competing pathways, bioengineers can optimize synthetic pathways for enhanced productivity and stability.
References & Tools
- RBS Calculator: https://salislab.net/software/
- CRISPR-Cas9 genome editing protocols
- Directed evolution techniques
- Metabolic flux analysis software (e.g., COBRA toolbox)
This section equips engineers with practical strategies and examples to systematically address pathway imbalances and bottlenecks, enabling robust synthetic biology system design.
7.3 Best Practice: Using Adaptive Laboratory Evolution to Enhance Performance
Adaptive Laboratory Evolution (ALE) is a powerful strategy to improve microbial strains by harnessing natural selection under controlled laboratory conditions. It involves cultivating microorganisms over many generations under specific selective pressures to enrich for beneficial mutations that enhance desired phenotypes such as growth rate, tolerance to stress, or production yield.
What is Adaptive Laboratory Evolution?
- Definition: A method where microbes are cultured under defined conditions to promote the emergence of advantageous genetic variants.
- Goal: To evolve strains with improved traits without prior knowledge of the underlying genetic changes.
Why Use ALE in Synthetic Biology?
- Overcomes limitations of rational design by exploring evolutionary solutions.
- Can improve strain robustness, metabolic efficiency, and stress tolerance.
- Complements computational and genetic engineering approaches.
Key Steps in ALE
Best Practices for Effective ALE
-
Define Clear Selective Pressure:
- Choose conditions that directly relate to the desired trait (e.g., high substrate concentration for tolerance).
- Example: Evolving E. coli to tolerate high ethanol concentrations by gradually increasing ethanol in the medium.
-
Maintain Appropriate Population Size:
- Large populations increase genetic diversity and reduce genetic drift.
- Use batch cultures with sufficient volume or continuous cultures.
-
Control Culture Conditions Precisely:
- Maintain consistent temperature, pH, and nutrient supply.
- Use bioreactors or chemostats for stable environments.
-
Monitor Phenotypic Changes Regularly:
- Track growth rates, metabolite production, or stress tolerance.
- Example: Measuring optical density and product titers every 24 hours.
-
Use Replicates to Avoid False Positives:
- Run parallel evolution experiments to distinguish true adaptive mutations from random drift.
-
Combine ALE with Genomic Analysis:
- Sequence evolved strains to identify beneficial mutations.
- Integrate findings with computational models for rational strain improvement.
Example: Enhancing Lactic Acid Production in Lactobacillus via ALE
- Objective: Increase lactic acid yield and acid tolerance.
- Selective Pressure: Gradually lower pH in the growth medium.
- Process: Serial passaging over 300 generations with decreasing pH from 6.0 to 4.0.
- Outcome: Evolved strains showed 30% higher lactic acid production and improved growth at low pH.
- Analysis: Whole-genome sequencing revealed mutations in membrane transporters and stress response regulators.
Example: Improving Thermotolerance in Saccharomyces cerevisiae
- Objective: Develop yeast strains that can ferment at elevated temperatures to reduce cooling costs.
- Selective Pressure: Incremental increase of incubation temperature from 30°C to 40°C.
- Process: Continuous culture in a chemostat with temperature ramping over 500 generations.
- Outcome: Strains capable of stable growth and ethanol production at 40°C.
- Analysis: Mutations identified in heat shock proteins and membrane composition genes.
Integrating ALE with Synthetic Biology Workflows
Summary
Adaptive Laboratory Evolution is a practical and complementary approach to traditional synthetic biology engineering. By applying evolutionary principles in a controlled manner, engineers can enhance microbial performance in ways that are difficult to predict or design rationally. Combining ALE with genetic engineering, computational modeling, and thorough analysis enables the development of robust, high-performing synthetic biology systems.
References & Further Reading
- Dragosits, M., & Mattanovich, D. (2013). Adaptive laboratory evolution – principles and applications for biotechnology. Microbial Cell Factories, 12, 64.
- Sandberg, T. E., et al. (2019). Evolution of Escherichia coli to 42 °C and Subsequent Genetic Engineering Reveals Adaptive Mechanisms and Novel Mutations. Molecular Biology and Evolution, 36(7), 1477–1489.
- LaCroix, R. A., et al. (2015). Use of Adaptive Laboratory Evolution To Discover Key Mutations Enabling Rapid Growth of Escherichia coli K-12 MG1655 on Glucose Minimal Medium. Applied and Environmental Microbiology, 81(1), 17–30.
7.4 Case Study: Engineering Yeast for High-Yield Production of Pharmaceuticals
Synthetic biology has revolutionized the way we approach pharmaceutical production, with yeast emerging as a powerful host organism due to its eukaryotic machinery, ease of genetic manipulation, and scalability. This case study explores the engineering of Saccharomyces cerevisiae (baker’s yeast) for the high-yield biosynthesis of complex pharmaceutical compounds, focusing on best practices, design strategies, and practical examples.
Overview
Yeast is widely used to produce a variety of pharmaceuticals, including insulin, vaccines, and complex natural products like artemisinic acid, a precursor to the antimalarial drug artemisinin. The engineering process involves pathway reconstruction, optimization of metabolic flux, and balancing cellular resources to maximize yield.
Mind Map: Engineering Yeast for Pharmaceutical Production
Step 1: Pathway Reconstruction and Gene Integration
- Example: Production of artemisinic acid in yeast (Paddon et al., 2013)
- Heterologous expression of plant-derived genes encoding enzymes for the artemisinic acid pathway.
- Codon optimization of plant genes for yeast expression.
- Use of strong constitutive and inducible promoters to control expression levels.
Best Practice: Use modular cloning systems (e.g., Golden Gate) to assemble multi-gene pathways efficiently and test different promoter-gene combinations for optimal expression.
Step 2: Metabolic Flux Optimization
- Enhancing precursor availability such as acetyl-CoA and NADPH is critical.
- Knocking out competing pathways that drain precursors or cofactors.
Example: Overexpression of genes involved in the mevalonate pathway to increase precursor supply for terpenoid synthesis.
Mind Map: Metabolic Flux Optimization
Step 3: Genetic Toolkits and Genome Editing
- CRISPR/Cas9 enables precise and multiplexed genome edits.
- Multi-copy integration of pathway genes can boost production.
- Promoter libraries allow fine-tuning of gene expression.
Example: Use of CRISPR to knock out ERG9 gene (squalene synthase) to redirect flux away from sterol synthesis towards artemisinic acid.
Best Practice: Combine genome editing with high-throughput screening to identify optimal strain variants.
Step 4: Fermentation and Process Optimization
- Optimize pH, temperature, oxygen levels, and nutrient supply.
- Fed-batch fermentation strategies to maintain substrate availability.
Example: Controlled fed-batch fermentation of engineered yeast producing artemisinic acid increased titer from milligrams to grams per liter.
Analytical and Validation Techniques
- Use HPLC and GC-MS for quantifying pharmaceutical compounds.
- Metabolic flux analysis (MFA) to understand pathway bottlenecks.
- Omics approaches (transcriptomics, proteomics) to monitor host response.
Summary Table: Key Engineering Strategies and Examples
| Strategy | Description | Example Application |
|---|---|---|
| Pathway Reconstruction | Heterologous gene expression, codon optimization | Artemisinic acid pathway in yeast |
| Metabolic Flux Optimization | Enhance precursor/cofactor supply, knockouts | Mevalonate pathway overexpression |
| Genome Editing | CRISPR/Cas9 mediated gene knockouts/integrations | ERG9 knockout to redirect flux |
| Promoter Engineering | Fine-tuning gene expression levels | Use of inducible promoters for dynamic control |
| Fermentation Optimization | Control of culture conditions | Fed-batch fermentation for increased yield |
Practical Example: Engineering Yeast to Produce Opioid Precursors
- Introduction of plant enzymes to convert simple sugars into thebaine and hydrocodone precursors.
- Use of synthetic scaffolds to colocalize enzymes and improve pathway efficiency.
- Dynamic regulation of pathway genes to balance growth and production.
Mind Map: Opioid Precursor Production in Yeast
Conclusion
Engineering yeast for high-yield pharmaceutical production is a multidisciplinary challenge combining synthetic biology, metabolic engineering, computational modeling, and process engineering. By following best practices such as modular pathway assembly, metabolic flux optimization, precise genome editing, and thorough process optimization, bioengineers can develop robust yeast strains capable of producing complex pharmaceuticals at industrially relevant scales.
This case study highlights the importance of integrating design, experimentation, and analysis to achieve successful synthetic biology systems tailored for pharmaceutical applications.
7.5 Example: Computational Design of Synthetic Pathways for Novel Compounds
Computational design of synthetic metabolic pathways is a cornerstone in modern synthetic biology, enabling bioengineers to create novel compounds efficiently by leveraging in silico tools before experimental implementation. This approach reduces trial-and-error cycles, optimizes resource use, and accelerates the development of innovative bioproducts.
Overview
Computational pathway design involves identifying enzymatic reactions and sequences that convert available substrates into desired target compounds. This process integrates databases, algorithms, and modeling techniques to propose feasible biosynthetic routes.
Key Steps in Computational Pathway Design
Mind Map: Computational Design Workflow
Example Case Study: Designing a Synthetic Pathway for 1,4-Butanediol (BDO)
1,4-Butanediol is an industrially important chemical used in plastics and solvents. Natural biosynthesis is limited, so synthetic pathways have been computationally designed and implemented in E. coli.
Step 1: Target Definition
- Chemical formula: C4H10O2
- Desired pathway to produce BDO from glucose
Step 2: Precursor Identification
- Glucose as starting substrate
- Intermediate metabolites like succinate, 4-hydroxybutyrate
Step 3: Reaction Mining
- Search KEGG and MetaCyc for reactions converting intermediates to BDO
Step 4: Pathway Construction
- Proposed pathway:
- Glucose → Succinyl-CoA → 4-Hydroxybutyrate → 1,4-BDO
Step 5: Feasibility Analysis
- Thermodynamic calculations show favorable Gibbs free energy changes
- Enzymes identified from various organisms for each step
Step 6: Optimization
- Flux balance analysis (FBA) used to predict metabolic fluxes
- Bottlenecks identified and targeted for enzyme overexpression
Step 7: Experimental Validation
- Genes encoding enzymes synthesized and expressed in E. coli
- Production of BDO confirmed via chromatography
Mind Map: BDO Synthetic Pathway Design
Best Practices Highlighted in This Example
- Integrate multiple databases to ensure comprehensive reaction coverage.
- Perform thermodynamic feasibility checks early to avoid unproductive pathways.
- Use flux balance analysis to predict pathway bottlenecks and optimize enzyme expression.
- Select enzymes from diverse organisms to maximize catalytic efficiency and compatibility.
- Iterate between computational predictions and experimental validation for robust pathway development.
Additional Example: Computational Design for Novel Antibiotic Precursors
- Target compound: Novel polyketide antibiotic derivative
- Approach:
- Use retrosynthesis algorithms to break down target into known metabolites
- Identify enzyme candidates with promiscuous activity
- Model pathway fluxes under different host conditions
- Outcome:
- Proposed pathway with 5 enzymatic steps
- Predicted yield improvements via enzyme engineering
Mind Map: Antibiotic Precursor Pathway Design
Summary
Computational design of synthetic pathways is a powerful approach that combines chemical knowledge, biological data, and computational modeling to engineer novel biosynthetic routes. By following structured workflows and integrating best practices, bioengineers can efficiently create pathways for new compounds, accelerating innovation in synthetic biology and metabolic engineering.
8. Biosensors and Synthetic Biology Applications
8.1 Design and Engineering of Biological Sensors
Biological sensors, or biosensors, are analytical devices that convert a biological response into a measurable signal. In synthetic biology, engineering biosensors involves designing genetic circuits or molecular systems that detect specific molecules or environmental conditions and produce a quantifiable output, such as fluorescence, color change, or electrical signals.
Key Components of Biological Sensors
- Recognition Element: The biological component that specifically interacts with the target analyte (e.g., proteins, nucleic acids, aptamers).
- Transducer: Converts the recognition event into a measurable signal.
- Signal Output: The measurable response (fluorescence, luminescence, colorimetric change, electrical signal).
Mind Map: Core Design Elements of Biological Sensors
Engineering Strategies
-
Selection of Recognition Element: Choose a biological molecule with high specificity and affinity for the target analyte. For example, a transcription factor that naturally binds a small molecule can be repurposed.
-
Signal Transduction Design: Couple the recognition event to a reporter gene or output signal. This often involves engineering promoters or riboswitches that respond to the analyte-binding event.
-
Host Optimization: Select or engineer a host organism that supports sensor function, ensuring minimal background noise and robust signal.
-
Tuning Sensitivity and Dynamic Range: Modify promoter strength, copy number, or degradation rates to achieve desired sensor performance.
-
Minimizing Crosstalk: Design orthogonal parts and circuits to reduce interference from endogenous cellular components.
Mind Map: Engineering Workflow for a Synthetic Biological Sensor
Practical Example: Engineering a Synthetic Biosensor for Arsenic Detection
Context: Arsenic contamination in water is a serious health hazard. A biosensor that detects arsenic ions (As(III)) can provide a low-cost, field-deployable solution.
Design Steps:
-
Recognition Element: Use the ArsR transcriptional repressor from E. coli, which naturally binds arsenic ions.
-
Signal Transduction: ArsR represses the ars operon promoter (Pars). In the presence of arsenic, ArsR dissociates, activating transcription.
-
Reporter: Place GFP under control of Pars promoter to produce fluorescence when arsenic is present.
-
Host: Engineer E. coli strain with the Pars-GFP construct.
-
Optimization: Tune promoter strength and plasmid copy number to maximize sensitivity and minimize background.
Outcome: The engineered E. coli fluoresces proportionally to arsenic concentration, enabling quantitative detection.
Mind Map: Arsenic Biosensor Design
Additional Examples
-
Quorum Sensing-Based Biosensors: Engineering bacteria to detect population density or specific signaling molecules (e.g., AHLs) and respond with a measurable output.
-
Riboswitch Sensors: RNA elements that change conformation upon ligand binding, controlling gene expression directly without protein intermediates.
-
Cell-Free Biosensors: Freeze-dried synthetic biology components that activate in the presence of analytes, useful for point-of-care diagnostics.
Summary
Designing biological sensors in synthetic biology requires integrating molecular recognition with signal transduction and host engineering. By leveraging modular parts and iterative design, engineers can create sensitive, specific, and robust biosensors for diverse applications ranging from environmental monitoring to medical diagnostics.
8.2 Best Practice: Enhancing Sensitivity and Specificity in Biosensors
Enhancing sensitivity and specificity in biosensors is crucial for reliable detection of target analytes, especially in complex biological or environmental samples. Sensitivity refers to the biosensor’s ability to detect low concentrations of the analyte, while specificity ensures that the biosensor responds only to the intended target, minimizing false positives.
Key Strategies to Enhance Sensitivity and Specificity
Choice of Recognition Elements
The core of any biosensor is the recognition element that binds specifically to the target molecule.
- Antibodies offer high specificity but can be sensitive to environmental conditions.
- Aptamers are synthetic oligonucleotides that can be engineered for high affinity and stability.
- Enzymes provide catalytic activity that can amplify signals.
- Synthetic receptors can be designed for novel targets.
Example: Using a DNA aptamer specific for mercury ions (Hg2+) in a biosensor to detect contamination in water with high specificity and nanomolar sensitivity.
Signal Amplification Techniques
Amplifying the detection signal improves sensitivity.
- Enzymatic amplification: Coupling recognition with enzymes that generate multiple product molecules per analyte binding event.
- Nanomaterial-based amplification: Using nanoparticles (e.g., gold nanoparticles) to enhance optical or electrochemical signals.
- Genetic circuit amplification: Engineering cells with synthetic circuits that produce amplified reporter signals upon analyte detection.
Example: A biosensor using horseradish peroxidase (HRP) enzyme linked to an antibody to amplify electrochemical signals in glucose detection.
Minimizing Background Noise
Non-specific binding and environmental interference reduce specificity.
- Surface passivation: Coating sensor surfaces with inert molecules (e.g., PEG) to prevent non-specific adsorption.
- Selective membrane coatings: Allow only target molecules to reach the sensor.
- Optimized washing protocols: Remove loosely bound non-target molecules.
Example: Applying polyethylene glycol (PEG) coatings on electrode surfaces to reduce protein fouling in blood glucose sensors.
Multiplexing and Orthogonal Detection
Using multiple recognition elements or detection modes can cross-validate signals and improve specificity.
Example: A biosensor array detecting multiple bacterial pathogens simultaneously using different aptamers, reducing false positives through orthogonal signal confirmation.
Engineering Genetic Circuits for Specificity
Synthetic biology enables design of genetic circuits that respond only when multiple conditions are met.
- Logic gating: AND gates ensure output only when all inputs (signals) are present.
- Feedback loops: Enhance signal robustness and reduce noise.
Example: A bacterial biosensor engineered with an AND gate circuit that fluoresces only when both arsenic and lead ions are detected, increasing specificity in environmental monitoring.
Sample Preparation and Pre-treatment
Pre-processing samples can concentrate targets and remove interferents.
- Filtration to remove particulates
- Chemical treatments to remove inhibitors
Example: Concentrating viral particles from wastewater samples before detection to improve sensitivity of SARS-CoV-2 biosensors.
Device Design and Integration
Microfluidic platforms allow precise control over sample delivery and reaction conditions.
- Reduces sample volume
- Enhances reaction kinetics
Example: A microfluidic biosensor that isolates circulating tumor cells from blood and detects specific cancer markers with high sensitivity.
Computational Modeling and Data Analysis
Advanced algorithms help distinguish true signals from noise.
- Machine learning models trained on sensor data can improve detection accuracy.
- Signal processing filters enhance signal-to-noise ratio.
Example: Using neural networks to analyze electrochemical biosensor data for early detection of biomarkers in complex biological fluids.
Integrated Example: Mercury Ion Biosensor
- Recognition element: DNA aptamer specific to Hg2+
- Signal amplification: Gold nanoparticle-enhanced electrochemical signal
- Surface passivation: PEG coating to reduce non-specific binding
- Microfluidics: Controlled sample flow to sensor surface
- Data analysis: Machine learning algorithm to distinguish signal from noise
This integrated approach achieves detection limits in the low nanomolar range with high specificity against other metal ions.
By combining these best practices in a cohesive manner, engineers can design biosensors that are both highly sensitive and specific, suitable for real-world applications in healthcare, environmental monitoring, and industrial biotechnology.
8.3 Application Example: Synthetic Biosensors for Heavy Metal Detection
Synthetic biosensors have emerged as powerful tools for detecting environmental contaminants, including heavy metals such as lead (Pb), mercury (Hg), cadmium (Cd), and arsenic (As). These biosensors leverage engineered biological components to provide sensitive, specific, and often real-time detection capabilities that surpass traditional chemical assays in cost-effectiveness and portability.
Overview of Heavy Metal Biosensors
Heavy metals pose significant health and environmental risks even at low concentrations. Synthetic biosensors designed for heavy metal detection typically combine a metal-responsive genetic element with a reporter system to translate metal presence into a measurable signal.
Key Components of Heavy Metal Synthetic Biosensors
Design Strategy: Example of a Lead (Pb) Biosensor
- Metal Sensing Module: Use the pbrR gene, a metalloregulatory protein from Cupriavidus metallidurans, which specifically binds lead ions.
- Promoter Element: The pbr promoter is repressed by PbrR in the absence of lead; binding of lead ions to PbrR derepresses the promoter.
- Reporter Gene: Green Fluorescent Protein (GFP) gene placed downstream of the pbr promoter.
When lead is present, PbrR releases the promoter, allowing GFP expression, which can be measured via fluorescence.
Best Practices in Engineering Heavy Metal Biosensors
- Specificity Tuning: Engineer metalloregulatory proteins or promoters to reduce cross-reactivity with other metals.
- Signal Amplification: Incorporate genetic amplifiers or positive feedback loops to enhance sensitivity.
- Host Optimization: Use strains with minimal background fluorescence and robust growth in environmental samples.
- Calibration and Quantification: Develop standard curves correlating signal intensity with metal concentration.
Example: Colorimetric Arsenic Biosensor
- Sensing Element: ArsR repressor protein from E. coli that binds arsenic.
- Reporter: β-galactosidase (LacZ) producing a color change in presence of X-gal substrate.
This biosensor provides a visible color change detectable by the naked eye, suitable for field testing.
Cell-Free Synthetic Biosensors for Heavy Metals
Cell-free systems eliminate the need for living cells, enhancing biosafety and stability. They contain transcription-translation machinery and synthetic genetic circuits encapsulated in vitro.
Example: A cell-free biosensor using a mercury-responsive promoter controlling expression of a fluorescent RNA aptamer.
Real-World Application Case Study: Industrial Wastewater Monitoring
- Problem: Heavy metal contamination in wastewater from mining operations.
- Solution: Deploy engineered E. coli biosensors with lead and cadmium responsive promoters.
- Outcome: Real-time monitoring with fluorescence readouts enables rapid detection and remediation.
Summary
Synthetic biosensors for heavy metal detection combine the specificity of metalloregulatory proteins with versatile reporter systems to create sensitive, portable, and cost-effective detection platforms. By integrating best practices such as specificity tuning, signal amplification, and host optimization, engineers can design biosensors tailored for diverse environmental and industrial applications.
Further Reading and Tools
- Registry of Standard Biological Parts (BioBricks) for metal-responsive elements
- Software: Cello for genetic circuit design
- Protocols for cell-free biosensor assembly
This section illustrates how synthetic biology principles translate into practical biosensing systems, empowering engineers to address critical environmental challenges with innovative biological solutions.
8.4 Integration of Biosensors with Electronic Systems
The integration of biosensors with electronic systems represents a critical frontier in synthetic biology, enabling real-time monitoring, data acquisition, and responsive control in a variety of applications ranging from healthcare to environmental monitoring. This section explores the principles, challenges, and practical examples of combining biological sensing elements with electronic hardware and software.
Key Concepts in Biosensor-Electronics Integration
- Signal Transduction: Converting biological signals (e.g., chemical, optical, electrical) into electronic signals.
- Interface Design: Physical and chemical interfaces that connect biological components to electronic devices.
- Data Acquisition: Techniques for capturing, amplifying, and digitizing biosensor outputs.
- Signal Processing: Filtering, analyzing, and interpreting sensor data.
- Feedback and Control: Using electronic outputs to trigger biological or mechanical responses.
Mind Map: Components of Biosensor-Electronic Integration
Practical Example 1: Electrochemical Glucose Biosensor with Microcontroller
Overview: A classic example of biosensor-electronic integration is the glucose sensor used in diabetes management. The biological element (glucose oxidase enzyme) reacts with glucose, producing an electrochemical signal proportional to glucose concentration.
Integration Steps:
- Biological Component: Immobilize glucose oxidase on an electrode surface.
- Transduction: Electrochemical reaction generates current.
- Signal Conditioning: Use an operational amplifier to amplify the current signal.
- Data Acquisition: Analog-to-digital converter (ADC) on a microcontroller digitizes the signal.
- Processing: Microcontroller processes data and displays glucose levels.
- Communication: Data can be sent wirelessly to smartphones or cloud platforms.
Best Practice: Ensure stable enzyme immobilization and minimize noise in signal amplification to improve accuracy.
Mind Map: Electrochemical Biosensor Workflow
Practical Example 2: Optical Biosensor Integrated with Photodetector and IoT
Overview: Optical biosensors detect changes in light properties (absorbance, fluorescence) upon interaction with target molecules. Integration with photodetectors and IoT modules enables remote sensing.
Integration Steps:
- Biological Component: Fluorescent aptamer that binds a pollutant.
- Transduction: Binding event changes fluorescence intensity.
- Detection: Photodiode or photomultiplier tube converts light changes to electrical signals.
- Signal Processing: Microcontroller processes signal, compensates for background noise.
- Connectivity: Wi-Fi or Bluetooth module transmits data to cloud.
- User Interface: Web or mobile app visualizes pollutant levels in real time.
Best Practice: Calibrate sensor regularly and implement temperature compensation algorithms.
Mind Map: Optical Biosensor Integration
Challenges and Solutions
| Challenge | Description | Best Practice / Solution |
|---|---|---|
| Signal Noise | Biological signals are often weak and noisy | Use low-noise amplifiers and shielding techniques |
| Biocompatibility | Electronic materials may affect biological activity | Employ biocompatible coatings and materials |
| Power Consumption | Portable devices require low power | Optimize circuit design and use energy-efficient components |
| Data Security and Privacy | Sensitive biological data requires protection | Implement encryption and secure communication protocols |
Emerging Trends
- Flexible Electronics: Integration of biosensors on flexible substrates for wearable devices.
- Lab-on-a-Chip Systems: Miniaturized platforms combining biosensing and electronics for point-of-care diagnostics.
- Machine Learning: Advanced algorithms for improved signal interpretation and predictive analytics.
- Wireless Powering: Techniques such as NFC and inductive coupling to power biosensors without batteries.
Summary
Integrating biosensors with electronic systems bridges the gap between biological detection and actionable data. By combining biological specificity with electronic precision, engineers can develop sophisticated devices that provide real-time insights and control. Emphasizing robust interface design, noise reduction, and data security ensures reliable and practical synthetic biology applications.
8.5 Future Trends: Wearable and Implantable Synthetic Biology Devices
Synthetic biology is rapidly advancing towards the integration of living systems with electronics and materials science, enabling the development of wearable and implantable devices that harness biological functions for real-time sensing, diagnostics, and therapeutic interventions. This section explores the emerging trends, design considerations, and practical examples of these cutting-edge devices.
Overview
Wearable and implantable synthetic biology devices combine engineered biological components with materials and electronics to create systems capable of monitoring physiological states, detecting environmental signals, and responding autonomously or semi-autonomously. These devices promise to revolutionize personalized medicine, environmental monitoring, and human-machine interfaces.
Mind Map: Key Components and Trends in Wearable & Implantable Synthetic Biology Devices
Design Considerations and Best Practices
- Biocompatibility: Ensuring materials and engineered biological components do not provoke immune responses or toxicity.
- Stability and Longevity: Designing circuits and cells that maintain function over extended periods in vivo or on the body surface.
- Signal Sensitivity and Specificity: Engineering biosensors with high selectivity to target analytes amidst complex biological environments.
- Power Efficiency: Utilizing low-power biological circuits and integrating energy harvesting to minimize external power needs.
- Data Integration: Combining biological signals with electronic processing for real-time analysis and feedback.
Example 1: Wearable Synthetic Biology Patch for Glucose Monitoring
Description: A flexible skin patch embedded with engineered bacteria that fluoresce in response to glucose levels in sweat.
- Biological System: Genetically modified E. coli expressing a glucose-responsive promoter controlling GFP expression.
- Material: Biocompatible hydrogel matrix allowing nutrient and analyte diffusion.
- Readout: Optical detection via smartphone camera.
Best Practice Highlight: Use of modular genetic circuits with feedback loops to reduce noise and improve signal reliability in fluctuating sweat glucose concentrations.
Example 2: Implantable Synthetic Probiotic for Inflammatory Bowel Disease (IBD) Therapy
Description: Engineered gut bacteria implanted to detect inflammation markers and release anti-inflammatory molecules on demand.
- Biological System: Lactococcus lactis engineered with a synthetic gene circuit that senses nitric oxide (inflammation marker) and produces IL-10 cytokine.
- Delivery: Oral capsule that colonizes the gut.
- Safety: Kill-switch mechanisms to prevent uncontrolled proliferation.
Best Practice Highlight: Incorporation of multi-layered genetic safeguards and environmental sensing to ensure precise therapeutic delivery.
Mind Map: Challenges and Opportunities
Emerging Technologies
- Cell-Free Synthetic Biology Devices: Utilizing freeze-dried cell-free systems embedded in wearables for rapid, on-demand sensing without live cells.
- Bioelectronic Interfaces: Hybrid devices that translate biological signals into electronic outputs for seamless integration with smartphones and IoT.
- 3D Bioprinting: Fabrication of complex implantable devices with spatially organized synthetic biological components.
Summary
Wearable and implantable synthetic biology devices represent a frontier where engineering, biology, and materials science converge to create smart, responsive systems. By adhering to best practices in design, leveraging modular synthetic biology tools, and addressing challenges proactively, engineers can develop practical devices that improve health outcomes and expand the capabilities of biological sensing and actuation.
References and Further Reading
- Nguyen, P. Q., et al. (2021). Wearable materials with embedded synthetic biology sensors for biomolecule detection. Nature Biotechnology, 39(9), 1054–1063.
- Mimee, M., et al. (2018). An ingestible bacterial-electronic system to monitor gastrointestinal health. Science, 360(6391), 915–918.
- Pardee, K., et al. (2016). Paper-based synthetic gene networks. Cell, 159(4), 940–954.
9. Automation and High-Throughput Synthetic Biology
9.1 Laboratory Automation for Synthetic Biology Workflows
Laboratory automation has become a cornerstone in advancing synthetic biology by enabling higher throughput, reproducibility, and efficiency. Automating workflows reduces human error, accelerates experimental cycles, and allows bioengineers to focus on design and analysis rather than repetitive manual tasks.
Key Components of Laboratory Automation in Synthetic Biology
- Liquid Handling Systems: Automated pipetting robots for precise reagent dispensing.
- Automated Colony Pickers: For selecting and transferring microbial colonies.
- Integrated Incubators and Shakers: Controlled environments for cell growth.
- High-Throughput Screening Platforms: Automated measurement and data collection.
- Data Management Systems: LIMS (Laboratory Information Management Systems) for tracking samples and experiments.
Mind Map: Core Elements of Synthetic Biology Automation
Workflow Example: Automated DNA Assembly and Screening
- Design Input: Synthetic biology design software exports assembly instructions.
- Automated Pipetting: Liquid handler robot assembles DNA parts using Gibson or Golden Gate protocols.
- Thermal Cycling: Automated PCR machines perform amplification.
- Transformation: Robotic systems plate transformed cells.
- Colony Picking: Automated colony pickers select clones for culturing.
- Culturing: Integrated incubators grow cultures under controlled conditions.
- Screening: High-throughput fluorescence or absorbance measurements identify successful constructs.
- Data Capture: Results are automatically logged into LIMS for analysis.
Best Practice Example: Implementing a Robotic Liquid Handling System
- Context: A synthetic biology lab aiming to optimize metabolic pathways by testing hundreds of gene variants.
- Automation Role: A liquid handling robot is programmed to assemble combinatorial DNA libraries in 96-well plates.
- Benefits:
- Reduced pipetting errors and cross-contamination.
- Increased throughput from manual 10 samples/day to automated 200 samples/day.
- Consistent reagent volumes improve reproducibility.
Mind Map: Benefits of Laboratory Automation
Challenges and Solutions
| Challenge | Solution | Example |
|---|---|---|
| High Initial Cost | Phased implementation and shared core facilities | University labs sharing robotic platforms |
| Complex Programming | Use of user-friendly software and training | GUI-based liquid handler programming |
| Integration of Diverse Devices | Middleware and standardized communication protocols | Use of APIs and OPC-UA standards |
| Data Overload | Automated data processing pipelines | Real-time analytics dashboards |
Practical Example: Microfluidics-Based Automation
Microfluidic platforms automate synthetic biology workflows at microscale, enabling rapid mixing, reaction, and analysis with minimal reagent use.
- Use Case: Automated droplet-based DNA assembly and screening.
- Advantages: Ultra-high throughput, reduced reagent cost, and precise control over reaction conditions.
Summary
Laboratory automation in synthetic biology workflows is essential for scaling experiments, improving accuracy, and accelerating innovation. By integrating robotic liquid handlers, automated colony pickers, and high-throughput screening systems with robust data management, bioengineers can streamline complex workflows and focus on system design and optimization.
For further reading and tools, consider exploring:
- Opentrons: Open-source liquid handling robots
- Labcyte Echo: Acoustic liquid handling
- Benchling and TeselaGen: Workflow and data management platforms
9.2 Best Practice: Implementing Robotic Platforms for DNA Assembly and Screening
Robotic platforms have revolutionized synthetic biology by automating repetitive, labor-intensive tasks such as DNA assembly and screening. This not only accelerates the design-build-test cycle but also enhances reproducibility and scalability. In this section, we explore best practices for integrating robotic systems into DNA assembly workflows and screening processes, supported by practical examples and mind maps to clarify concepts.
Why Use Robotic Platforms?
- Increased Throughput: Robots can process hundreds to thousands of samples simultaneously.
- Enhanced Precision: Minimizes human error in pipetting and sample handling.
- Reproducibility: Standardized protocols ensure consistent results.
- Scalability: Easily scale experiments from small to large libraries.
Key Components of Robotic DNA Assembly and Screening Platforms
Best Practices for Implementing Robotic Platforms
Define Clear Workflow Objectives
- Identify which parts of the assembly and screening process benefit most from automation.
- Example: Automating Golden Gate assembly steps and colony picking to reduce manual labor.
Choose the Right Robotic System
- Consider throughput needs, flexibility, and compatibility with existing labware.
- Example: Using a liquid handling robot like the Opentrons OT-2 for flexible pipetting tasks.
Optimize Protocols for Automation
- Adapt manual protocols to robotic-compatible formats.
- Minimize steps requiring manual intervention.
- Example: Designing assembly reactions in 96-well plates for robotic pipetting.
Integrate Quality Control Steps
- Include checkpoints such as automated gel electrophoresis or fluorescence readouts.
- Example: Using plate readers integrated with the robot to verify assembly success.
Implement Robust Data Management
- Use Laboratory Information Management Systems (LIMS) to track samples and results.
- Automate data capture from screening instruments.
Train Personnel and Maintain Equipment
- Ensure operators understand both biological protocols and robotic operation.
- Schedule regular maintenance to prevent downtime.
Example Workflow: Automated Golden Gate Assembly and Screening
Description:
- The robot prepares and mixes DNA parts for Golden Gate assembly in 96-well plates.
- Thermal cycler integrated with the robot performs digestion-ligation cycles.
- Post-assembly, the robot handles bacterial transformation and plates colonies.
- Colony picker selects colonies for inoculation.
- Screening via fluorescence plate reader identifies successful constructs.
- Data is automatically logged and analyzed to inform next design iteration.
Practical Example: Opentrons OT-2 for DNA Assembly
- Setup: Use OT-2 with a magnetic module for bead-based purification and a temperature module for incubation.
- Protocol: Automate PCR setup, purification, and assembly reaction mixing.
- Screening: Transfer assembled DNA to competent cells, plate, and pick colonies using an integrated colony picker.
Outcome: Reduced hands-on time by 70%, increased assembly throughput by 5x, and improved reproducibility.
Challenges and Solutions
| Challenge | Solution |
|---|---|
| Cross-contamination | Use filtered tips, regular cleaning protocols |
| Protocol complexity | Modularize protocols into smaller, testable steps |
| Equipment calibration | Schedule routine calibration and validation |
| Data integration | Use open-source APIs and standardized data formats (e.g., SBOL) |
Summary
Automating DNA assembly and screening with robotic platforms is a powerful best practice that accelerates synthetic biology workflows. By carefully selecting systems, optimizing protocols, and integrating data management, bioengineers can achieve higher throughput, better reproducibility, and scalable operations. Practical examples like the Opentrons OT-2 demonstrate how accessible automation can transform lab productivity.
Additional Resources
- Opentrons Protocol Library
- Synthetic Biology Open Language (SBOL)
- BioAutomation: Best Practices
9.3 Data Management and LIMS Integration
Effective data management is a cornerstone of modern synthetic biology workflows, especially as projects scale in complexity and throughput. Laboratory Information Management Systems (LIMS) play a critical role in organizing, tracking, and analyzing experimental data, enabling bioengineers and systems engineers to maintain data integrity, ensure reproducibility, and accelerate discovery.
Why Data Management Matters in Synthetic Biology
- Volume and Complexity: Synthetic biology experiments generate vast amounts of heterogeneous data, including DNA sequences, experimental protocols, phenotypic measurements, and computational models.
- Traceability: Tracking samples, reagents, and experimental conditions is essential for reproducibility and regulatory compliance.
- Collaboration: Centralized data repositories facilitate collaboration across multidisciplinary teams.
- Automation Integration: Seamless data flow between automated platforms and analysis tools reduces errors and speeds up workflows.
Core Features of LIMS for Synthetic Biology
- Sample and Inventory Tracking: Manage biological samples, reagents, and consumables with barcode/RFID integration.
- Protocol and Workflow Management: Standardize and document experimental procedures.
- Data Capture and Storage: Store raw and processed data with metadata for context.
- Data Analysis Integration: Connect with computational tools for modeling and visualization.
- Reporting and Compliance: Generate audit trails and reports to meet regulatory standards.
Mind Map: Key Components of Data Management and LIMS Integration
Best Practices for Data Management in Synthetic Biology
- Standardize Data Formats: Adopt community standards such as SBOL (Synthetic Biology Open Language) for genetic designs and ISA-Tab for experimental metadata.
- Automate Data Capture: Integrate instruments and robotic platforms directly with LIMS to minimize manual entry errors.
- Implement Version Control: Track changes in protocols, genetic constructs, and datasets to maintain historical records.
- Ensure Data Security: Use encryption and role-based access to protect sensitive information.
- Enable Interoperability: Choose LIMS that support APIs and data exchange formats to connect with bioinformatics and modeling tools.
Example: Integrating LIMS with a DNA Assembly Automation Platform
Scenario: A synthetic biology lab uses a robotic platform for high-throughput DNA assembly (e.g., Golden Gate cloning). To streamline operations, the lab integrates their LIMS with the automation system.
- Step 1: The LIMS stores design files and assembly protocols.
- Step 2: When a new assembly batch is scheduled, the LIMS sends instructions to the robotic platform.
- Step 3: The robot performs assembly and updates the LIMS with status and QC data.
- Step 4: The LIMS links assembly results with sample metadata and experimental outcomes.
This integration reduces manual data handling, improves traceability, and accelerates iterative design cycles.
Mind Map: Workflow of LIMS Integration with Automation
Practical Tips for Selecting and Implementing a LIMS
- Assess Scalability: Ensure the system can handle increasing data volumes and user numbers.
- Customization: Look for flexible platforms that can be tailored to synthetic biology workflows.
- Integration Capabilities: Verify compatibility with existing instruments, software, and databases.
- User Training and Support: Choose vendors offering comprehensive training and responsive support.
- Open Source vs Commercial: Balance cost considerations with feature requirements and community support.
Example: Using an Open-Source LIMS for Synthetic Biology Projects
Lab: A university bioengineering group adopts an open-source LIMS (e.g., OpenLabFramework) to manage their synthetic biology experiments.
- They customize the system to include modules for genetic part inventory, assembly tracking, and phenotype data.
- Integration with Jupyter notebooks allows direct data analysis and visualization within the platform.
- The system supports multi-user collaboration with role-based access controls.
This approach provides a cost-effective, flexible solution that grows with the lab’s needs.
Summary
Data management and LIMS integration are pivotal for the success of synthetic biology engineering projects. By adopting best practices, leveraging automation, and choosing the right systems, engineers can enhance reproducibility, accelerate innovation, and maintain rigorous data governance.
References & Further Reading:
- Synthetic Biology Open Language (SBOL): https://sbolstandard.org/
- ISA-Tab Metadata Standard: https://isa-tools.org/
- COPASI LIMS Integration Examples
- OpenLabFramework: https://openlabframework.org/
- Review Article: “Laboratory Information Management Systems in Synthetic Biology” (Journal of Biological Engineering, 2020)
9.4 Example: High-Throughput Screening of Genetic Variants Using Microfluidics
High-throughput screening (HTS) is a cornerstone technique in synthetic biology, enabling rapid evaluation of thousands to millions of genetic variants to identify those with desired traits. Microfluidics, the manipulation of fluids at the sub-millimeter scale, has revolutionized HTS by allowing miniaturization, automation, and precise control over reaction environments.
What is Microfluidics-Based High-Throughput Screening?
Microfluidic HTS involves encapsulating individual genetic variants or cells within tiny droplets or chambers, allowing parallel assays in a massively scaled-down format. This approach drastically reduces reagent consumption, increases speed, and improves data quality.
Key Components and Workflow
Mind Map: Microfluidics-Based HTS Workflow
Practical Example: Screening Enzyme Variants for Improved Activity
Objective: Identify variants of an enzyme with enhanced catalytic efficiency from a mutagenized library.
Step 1: Library Preparation
- Generate a library of enzyme variants via error-prone PCR.
- Clone variants into expression vectors and transform into a suitable host (e.g., E. coli).
Step 2: Microfluidic Droplet Generation
- Encapsulate single cells expressing enzyme variants into picoliter droplets containing substrate and fluorescent reporter.
- Use flow-focusing microfluidic chips to generate uniform droplets at rates of thousands per second.
Step 3: Incubation and Reaction
- Incubate droplets off-chip or on-chip to allow enzymatic reaction.
- Enzymatic activity converts substrate to a fluorescent product.
Step 4: Sorting
- Use Fluorescence-Activated Droplet Sorting (FADS) to isolate droplets exhibiting high fluorescence, indicating high enzyme activity.
Step 5: Recovery and Validation
- Recover cells from sorted droplets.
- Sequence and characterize top hits in bulk assays.
Best Practices for Microfluidic HTS
Mind Map: Best Practices in Microfluidic HTS
Additional Example: Screening Genetic Circuits for Dynamic Response
Scenario: Identify genetic circuit variants with rapid response times to an inducer.
- Encapsulate cells harboring circuit variants in droplets with inducer.
- Monitor fluorescence over time using time-lapse microscopy integrated with microfluidic chips.
- Sort droplets with desired dynamic profiles using automated sorting.
This approach allows simultaneous screening of thousands of circuit variants for kinetic properties, which is challenging with traditional plate-based assays.
Summary
Microfluidics-enabled high-throughput screening offers bioengineers a powerful platform to accelerate the design-build-test-learn cycle. By combining precise fluid control, miniaturized assays, and automated sorting, engineers can efficiently explore vast genetic landscapes with minimal resource use.
References and Tools
- Microfluidic Platforms: Droplet microfluidics, digital microfluidics
- Sorting Techniques: Fluorescence-Activated Droplet Sorting (FADS), Magnetic sorting
- Software: ImageJ/Fiji for fluorescence analysis, custom Python scripts for data processing
This example highlights how integrating microfluidics into synthetic biology workflows can transform screening processes, enabling rapid discovery and optimization of genetic variants.
9.5 Challenges and Solutions in Scaling Synthetic Biology Automation
Scaling automation in synthetic biology presents unique challenges that span technical, operational, and organizational domains. Addressing these challenges effectively is crucial for accelerating research, improving reproducibility, and enabling industrial-scale applications.
Key Challenges in Scaling Synthetic Biology Automation
Integration Complexity
Challenge: Synthetic biology workflows often involve diverse instruments such as liquid handlers, PCR machines, incubators, and sequencing platforms. Integrating these heterogeneous systems into a seamless automated pipeline is complex.
Solution:
- Use middleware platforms that support multiple instrument protocols (e.g., SiLA, Antha).
- Develop standardized APIs and communication protocols.
- Adopt modular automation architecture to allow incremental integration.
Example: A bioengineering lab integrated a liquid handler with a robotic arm and a plate reader using a custom middleware layer, enabling fully automated DNA assembly and screening without manual intervention.
Data Management
Challenge: High-throughput automation generates massive datasets including experimental metadata, sequencing reads, and phenotypic outputs. Managing, storing, and analyzing this data efficiently is challenging.
Solution:
- Implement Laboratory Information Management Systems (LIMS) tailored for synthetic biology.
- Use standardized data formats like SBOL (Synthetic Biology Open Language) for design and metadata.
- Employ cloud-based storage and scalable computational resources.
Example: A synthetic biology startup adopted a cloud LIMS integrated with their automation platform, enabling real-time experiment tracking and rapid data analysis across multiple projects.
Equipment Compatibility and Maintenance
Challenge: Different manufacturers’ instruments may have incompatible software or hardware interfaces, complicating automation.
Solution:
- Prioritize instruments with open APIs and community support.
- Use universal robotic platforms that can interface with multiple devices.
- Schedule regular maintenance and calibration to minimize downtime.
Example: A systems engineering team selected liquid handlers and incubators from vendors supporting RESTful APIs, simplifying integration and reducing troubleshooting time.
Error Propagation and Quality Control
Challenge: Automated systems can propagate errors rapidly if not detected early, leading to wasted resources and unreliable results.
Solution:
- Incorporate real-time sensors and feedback loops for monitoring.
- Implement automated error detection algorithms and alerts.
- Design workflows with checkpoints for manual or automated validation.
Example: An automated DNA assembly pipeline included fluorescence-based quality control steps after each ligation, allowing immediate identification and correction of failed reactions.
Workflow Standardization
Challenge: Lack of standardized protocols and formats can hinder reproducibility and scalability.
Solution:
- Develop and adopt community standards for protocols (e.g., protocols.io).
- Use modular and reusable workflow components.
- Document all steps rigorously and maintain version control.
Example: A bioengineering group standardized their cloning workflows using a protocol repository, enabling rapid sharing and replication across different labs.
Throughput Bottlenecks
Challenge: Certain steps such as cell culture or sequencing can become bottlenecks limiting overall throughput.
Solution:
- Parallelize bottleneck steps using multi-well plates or microfluidics.
- Optimize incubation times and reagent concentrations.
- Use predictive modeling to balance workflow stages.
Example: By implementing microfluidic droplet sorting, a lab increased screening throughput tenfold, effectively removing the bottleneck caused by manual colony picking.
Skill Gaps
Challenge: Operating and maintaining complex automation systems requires interdisciplinary skills that may be scarce.
Solution:
- Invest in cross-training programs combining biology, engineering, and data science.
- Collaborate with automation specialists and software engineers.
- Use user-friendly interfaces and comprehensive documentation.
Example: A synthetic biology company established an internal training academy, reducing onboarding time for new engineers and improving system uptime.
Cost Management
Challenge: High initial investment and operational costs can be prohibitive.
Solution:
- Start with modular automation to spread costs over time.
- Use open-source hardware and software where possible.
- Perform cost-benefit analyses to prioritize automation targets.
Example: A university lab leveraged open-source liquid handling robots and community-developed software, achieving automation at a fraction of commercial system costs.
Regulatory Compliance
Challenge: Automated synthetic biology workflows must comply with biosafety and data security regulations.
Solution:
- Integrate compliance checks into automation workflows.
- Maintain audit trails and secure data storage.
- Engage with regulatory bodies early in development.
Example: An industrial synthetic biology facility implemented automated documentation and access controls, ensuring compliance with FDA regulations during scale-up.
Summary Mind Map of Solutions
Scaling synthetic biology automation is a multi-faceted challenge that requires a holistic approach combining technical innovation, operational excellence, and organizational readiness. By adopting best practices and leveraging emerging technologies, engineers can overcome these barriers and unlock the full potential of synthetic biology at scale.
10. Ethical, Safety, and Regulatory Considerations
10.1 Biosafety Levels and Containment Practices
Synthetic biology involves manipulating living organisms, which necessitates strict adherence to biosafety protocols to protect researchers, the environment, and the public. Understanding biosafety levels (BSLs) and containment practices is crucial for bioengineers and systems engineers working with engineered biological systems.
Overview of Biosafety Levels (BSLs)
Biosafety levels are a series of protections ranked from 1 to 4, designed to safeguard against biological hazards based on the risk posed by the organisms or materials handled.
| BSL | Description | Examples of Organisms | Containment Practices |
|---|---|---|---|
| BSL-1 | Lowest risk; work with well-characterized agents not known to cause disease in healthy adults | Non-pathogenic E. coli strains | Standard microbiological practices, no special containment |
| BSL-2 | Moderate risk; agents associated with human disease but with treatments available | Staphylococcus aureus, Salmonella spp. | Limited access, biohazard warning signs, use of biosafety cabinets (Class II) |
| BSL-3 | High risk; agents that can cause serious or potentially lethal disease via inhalation | Mycobacterium tuberculosis, SARS-CoV-2 | Controlled access, directional airflow, respiratory protection, sealed lab |
| BSL-4 | Highest risk; dangerous/exotic agents with high risk of aerosol transmission and no treatment | Ebola virus, Marburg virus | Maximum containment, full-body air-supplied suits, isolated facilities |
Mind Map: Biosafety Levels and Key Features
Containment Practices in Synthetic Biology
Containment practices are designed to prevent accidental release or exposure to engineered organisms. They include physical, biological, and procedural controls.
-
Physical Containment:
- Use of biosafety cabinets (Class II or III) for aerosol-generating procedures.
- Laboratory design with directional airflow and air filtration (HEPA filters).
- Autoclaving and sterilization of waste materials.
-
Biological Containment:
- Engineering organisms with auxotrophy (dependence on synthetic nutrients).
- Use of kill switches that trigger cell death under specific conditions.
- Genetic safeguards such as synthetic amino acid dependence.
-
Procedural Controls:
- Access restrictions and training for personnel.
- Standard operating procedures (SOPs) for handling and disposal.
- Incident reporting and emergency response plans.
Mind Map: Containment Strategies in Synthetic Biology
Practical Examples
Example 1: Working with Engineered E. coli at BSL-1
- Organism: Non-pathogenic E. coli strain engineered to produce a fluorescent protein.
- Containment: Standard microbiological practices, gloves, lab coats.
- Biosafety cabinet not required but recommended for aerosol-generating steps.
- Waste autoclaved before disposal.
Example 2: Engineering a Pathogen-Derived Biosensor at BSL-2
- Organism: Modified Salmonella strain designed to detect environmental toxins.
- Containment: Restricted lab access, use of Class II biosafety cabinet.
- Personnel wear gloves, lab coats, eye protection.
- Engineered kill switch incorporated to prevent survival outside lab.
Example 3: Synthetic Biology Research Involving Viral Vectors at BSL-3
- Organism: Lentiviral vectors used for gene delivery.
- Containment: Sealed lab with directional airflow.
- Respiratory protection and full PPE required.
- Rigorous decontamination protocols for equipment and waste.
Best Practices for Engineers
- Risk Assessment: Evaluate the hazards associated with the engineered organism and procedures.
- Documentation: Maintain detailed records of containment measures and training.
- Training: Ensure all personnel understand biosafety protocols and emergency procedures.
- Design for Safety: Incorporate biological containment features into synthetic constructs.
- Regular Audits: Conduct periodic reviews of biosafety compliance and facility integrity.
Summary
Understanding and implementing appropriate biosafety levels and containment practices is essential for safe and responsible synthetic biology engineering. Combining physical, biological, and procedural controls ensures protection for personnel, the environment, and society.
For further reading:
- CDC Biosafety in Microbiological and Biomedical Laboratories (BMBL) 6th Edition
- NIH Guidelines for Research Involving Recombinant or Synthetic Nucleic Acid Molecules
- Synthetic Biology Open Language (SBOL) for documenting biological parts and safety features
10.2 Ethical Implications of Synthetic Biology Engineering
Synthetic biology, by its very nature, challenges traditional boundaries between natural and artificial life. As engineers push the limits of designing and constructing new biological systems, it is crucial to carefully consider the ethical implications that arise. This section explores key ethical concerns, frameworks for responsible innovation, and practical examples illustrating these challenges.
Key Ethical Concerns in Synthetic Biology
-
Creation of Novel Life Forms
- What responsibilities do we have when creating organisms that have never existed before?
- Potential ecological impacts and unintended consequences.
-
Dual-Use Research
- Technologies that can be used for beneficial or harmful purposes.
- Biosecurity risks, including bioterrorism.
-
Intellectual Property and Access
- Ownership of synthetic biology parts and organisms.
- Equity in access to synthetic biology benefits.
-
Environmental Impact and Biosafety
- Risks of releasing engineered organisms into the environment.
- Horizontal gene transfer and ecosystem disruption.
-
Human Enhancement and Synthetic Life Ethics
- Ethical boundaries in modifying human cells or creating synthetic life.
Mind Map: Ethical Dimensions of Synthetic Biology
Frameworks for Ethical Decision-Making
-
Precautionary Principle
- Act cautiously when scientific knowledge is incomplete.
- Example: Restricting release of genetically modified organisms until safety is assured.
-
Responsible Research and Innovation (RRI)
- Inclusive stakeholder engagement.
- Transparency and accountability.
-
Ethical Review Boards and Oversight
- Institutional biosafety committees.
- National and international regulatory bodies.
Example 1: Gene Drive Technologies
Gene drives are synthetic biology tools designed to spread genetic traits rapidly through populations, potentially eradicating disease vectors like mosquitoes.
-
Ethical Concerns:
- Unintended ecological consequences.
- Consent from affected communities.
- Potential misuse.
-
Best Practices:
- Extensive ecological risk assessment.
- Transparent public engagement.
- International collaboration for governance.
Mind Map: Ethical Considerations for Gene Drives
Example 2: Synthetic Biology in Human Therapeutics
Engineering synthetic cells or circuits for therapeutic purposes (e.g., CAR-T cells) raises ethical questions:
- Safety: Off-target effects and long-term impacts.
- Consent: Fully informed patient consent for novel therapies.
- Equity: Access to advanced treatments.
Mind Map: Ethical Issues in Synthetic Therapeutics
Practical Recommendations for Engineers
- Engage with ethicists and social scientists early in project design.
- Incorporate ethical impact assessments alongside technical evaluations.
- Foster transparent communication with the public and stakeholders.
- Prioritize biosafety and biosecurity in system design.
- Advocate for policies that balance innovation with societal well-being.
Summary
Ethical implications in synthetic biology engineering are multifaceted and require a proactive, interdisciplinary approach. By integrating ethical reflection into the engineering process, bioengineers and systems engineers can help ensure that synthetic biology advances responsibly, safely, and equitably.
10.3 Best Practice: Compliance with International Regulatory Frameworks
Compliance with international regulatory frameworks is a cornerstone of responsible synthetic biology engineering. Given the potential risks and ethical considerations involved in manipulating living systems, engineers must navigate a complex landscape of laws, guidelines, and standards to ensure safety, efficacy, and public trust.
Understanding the Regulatory Landscape
Synthetic biology is governed by a variety of international and national regulations that address biosafety, biosecurity, environmental impact, and ethical concerns. Key frameworks include:
- Cartagena Protocol on Biosafety: Focuses on the safe handling, transport, and use of living modified organisms (LMOs) resulting from modern biotechnology.
- Nagoya Protocol: Addresses access to genetic resources and the fair sharing of benefits arising from their utilization.
- OECD Guidelines: Provide recommendations for the safety assessment of biotechnology products.
- FDA (U.S.) and EMA (Europe): Regulate synthetic biology products intended for medical or food use.
Mind Map: Regulatory Framework Components
Best Practices for Compliance
-
Early Engagement with Regulatory Bodies
- Initiate dialogue during project planning to understand applicable regulations.
- Example: A bioengineering team developing a synthetic probiotic consulted the FDA early to clarify classification and approval pathways.
-
Comprehensive Risk Assessment
- Evaluate potential environmental, health, and safety risks.
- Use standardized risk assessment frameworks such as those recommended by the WHO or OECD.
- Example: Before releasing engineered microbes for bioremediation, a company conducted extensive ecological impact studies.
-
Documentation and Traceability
- Maintain detailed records of genetic constructs, host organisms, and experimental procedures.
- Implement Laboratory Information Management Systems (LIMS) for traceability.
-
Adherence to Containment and Biosafety Levels
- Follow guidelines for physical and biological containment appropriate to the risk group.
- Example: Engineering work with pathogenic organisms is performed in BSL-3 or BSL-4 labs as required.
-
Training and Awareness
- Provide regular training on regulatory requirements and biosafety to all team members.
-
Ethical Review and Public Engagement
- Obtain approvals from Institutional Biosafety Committees (IBCs) or Ethics Boards.
- Engage with stakeholders and the public to build trust and transparency.
Mind Map: Steps to Ensure Regulatory Compliance
Practical Example: Navigating Compliance for a Synthetic Biology Product
Scenario: A bioengineering startup is developing a genetically engineered yeast strain to produce a novel biofuel.
-
Step 1: Regulatory Research
- The team identifies that their product falls under GMO regulations in their country and must comply with international biosafety protocols.
-
Step 2: Risk Assessment
- They conduct environmental risk assessments focusing on potential gene transfer and ecological impact.
-
Step 3: Documentation
- All genetic modifications and experimental data are logged in a LIMS.
-
Step 4: Institutional Review
- The project is submitted to the Institutional Biosafety Committee for approval.
-
Step 5: Regulatory Submission
- Necessary dossiers are prepared for the national regulatory authority, including safety data and containment plans.
-
Step 6: Training
- Lab personnel undergo biosafety and compliance training.
-
Step 7: Monitoring
- After pilot-scale release, the team implements environmental monitoring and reports findings as required.
Summary
Compliance with international regulatory frameworks is not just a legal obligation but a best practice that ensures the safe and ethical advancement of synthetic biology. By integrating regulatory considerations early and throughout the engineering process, bioengineers can mitigate risks, foster innovation, and maintain public confidence.
For further reading and resources:
- Cartagena Protocol on Biosafety
- OECD Safety Assessment of Biotechnology Products
- FDA Guidance on Biotechnology
- Synthetic Biology Open Language (SBOL) for Documentation
10.4 Case Study: Risk Assessment in Release of Engineered Organisms
Introduction
Releasing engineered organisms into the environment is a critical step that requires thorough risk assessment to ensure biosafety and minimize unintended consequences. This case study explores the comprehensive risk assessment process for a genetically engineered bacterium designed to degrade environmental pollutants.
Background
A synthetic biology team developed a strain of Pseudomonas putida engineered to metabolize and break down polycyclic aromatic hydrocarbons (PAHs) in contaminated soil. The goal was to deploy this organism in situ to accelerate bioremediation.
Step 1: Hazard Identification
- Potential Hazards:
- Horizontal gene transfer (HGT) of engineered genes to native microbes
- Unintended ecological disruption
- Pathogenicity or toxicity to non-target organisms
- Persistence and uncontrolled spread
Step 2: Exposure Assessment
- Release Scenarios:
- Direct soil inoculation at contaminated sites
- Possible migration through water runoff
- Exposure Pathways:
- Soil microbiome interaction
- Aquatic ecosystems downstream
Step 3: Consequence Analysis
- Ecological Impact:
- Displacement of native microbial communities
- Effects on soil nutrient cycles
- Human Health:
- Potential allergenicity or toxicity
- Exposure via water or food chain
Step 4: Risk Characterization
- Combining likelihood of exposure with severity of consequences to estimate overall risk.
Step 5: Risk Management Strategies
- Genetic Safeguards:
- Use of kill switches activated by environmental signals
- Auxotrophy to limit survival outside target environment
- Physical Containment:
- Controlled release zones
- Monitoring and remediation plans
Mind Map: Risk Assessment Workflow
Practical Example: Kill Switch Implementation
The engineered P. putida was equipped with a temperature-sensitive kill switch that triggers cell death if the bacteria move outside the designated remediation site (where temperature is controlled). This reduces the risk of uncontrolled spread.
Mind Map: Genetic Safeguards
Monitoring and Post-Release Evaluation
- Regular sampling of soil and water to detect engineered bacteria
- Metagenomic analysis to monitor gene transfer events
- Ecological surveys to assess impact on native species
Mind Map: Post-Release Monitoring
Lessons Learned
- Early integration of risk assessment in design phase improves safety
- Multiple layers of containment reduce overall risk
- Transparent communication with regulatory bodies and public is essential
Summary
This case study highlights the importance of a structured risk assessment framework for the release of engineered organisms. Combining hazard identification, exposure assessment, consequence analysis, and risk management ensures responsible deployment of synthetic biology solutions.
References & Further Reading
- National Academies of Sciences, Engineering, and Medicine. “Gene Drives on the Horizon: Advancing Science, Navigating Uncertainty, and Aligning Research with Public Values.” (2016)
- Oye, K. A., et al. “Regulating gene drives.” Science 345.6197 (2014): 626-628.
- Wright, O., Stan, G.-B., & Ellis, T. “Building-in biosafety for synthetic biology.” Microbiology, 159(7), 1221-1235 (2013).
10.5 Public Engagement and Communication Strategies
Effective public engagement and communication are critical components in the responsible development and deployment of synthetic biology systems. Engineers and scientists must not only innovate but also build trust, address ethical concerns, and foster informed dialogue with diverse stakeholders. This section explores practical strategies, supported by examples and mind maps, to enhance public understanding and participation.
Why Public Engagement Matters
- Builds trust and transparency
- Addresses ethical, social, and environmental concerns
- Encourages informed decision-making
- Facilitates regulatory acceptance
- Promotes responsible innovation
Key Principles of Effective Communication
- Clarity: Use simple, jargon-free language
- Transparency: Share both benefits and risks honestly
- Dialogue: Encourage two-way communication rather than one-way dissemination
- Inclusivity: Engage diverse audiences including non-experts
- Relevance: Tailor messages to audience values and concerns
Mind Map: Core Components of Public Engagement
Practical Strategies for Public Engagement
-
Organize Interactive Workshops and Forums
- Example: A synthetic biology lab hosts a community workshop demonstrating how engineered bacteria can help clean pollutants. Participants engage in hands-on activities and Q&A sessions.
-
Leverage Social Media and Digital Platforms
- Example: Use Twitter threads and Instagram stories to share bite-sized explanations of synthetic biology projects, addressing common myths.
-
Develop Educational Outreach Programs
- Example: Collaborate with schools to introduce synthetic biology modules, including simple experiments like creating glowing bacteria.
-
Implement Citizen Science Projects
- Example: Invite the public to help monitor environmental samples using biosensors developed by synthetic biology teams.
-
Engage with Policy Makers Through Briefings and Reports
- Example: Prepare clear, concise policy briefs outlining the benefits and risks of synthetic biology applications relevant to public health.
-
Use Visual Storytelling and Analogies
- Example: Explain genetic circuits as “biological computer programs” to make the concept more relatable.
Mind Map: Communication Channels and Their Uses
Example: Successful Public Engagement Campaign
Project: Engineering Synthetic Probiotics for Gut Health
- Challenge: Public skepticism about genetically modified organisms (GMOs) in food.
- Approach:
- Hosted open lab days where visitors could see the research process.
- Created animated videos explaining how synthetic probiotics work and their safety measures.
- Partnered with patient advocacy groups to co-host webinars.
- Shared progress transparently via social media.
- Outcome: Increased public awareness and positive sentiment measured through surveys.
Addressing Misinformation and Ethical Concerns
- Monitor social media and public discourse to identify misconceptions.
- Respond promptly with evidence-based information.
- Highlight ethical frameworks guiding research.
- Foster open discussions about potential risks and benefits.
Mind Map: Ethical Communication Framework
Summary
Public engagement in synthetic biology is not a one-off task but an ongoing, dynamic process. By combining clear communication, interactive participation, and ethical transparency, engineers can foster a supportive environment that accelerates innovation while respecting societal values.
Further Reading & Resources
- Synthetic Biology Leadership Excellence Accelerator Program (SynBioLEAP) Public Engagement Toolkit
- The Wilson Center’s Synthetic Biology Project
- iGEM Foundation Public Engagement Resources
11. Case Studies in Synthetic Biology Systems Engineering
11.1 Engineering Microbial Factories for Sustainable Chemical Production
Synthetic biology has revolutionized the way we approach chemical production by enabling the engineering of microbial factories—microorganisms tailored to produce valuable chemicals sustainably and efficiently. This section delves into the strategies, best practices, and real-world examples of engineering microbial systems for sustainable chemical manufacturing.
Overview
Microbial factories leverage the natural metabolic capabilities of microbes such as bacteria, yeast, and fungi, which are genetically engineered to produce target compounds ranging from biofuels and pharmaceuticals to specialty chemicals and bioplastics. The goal is to replace traditional petrochemical processes with greener, renewable biological routes.
Key Steps in Engineering Microbial Factories
Mind Map: Engineering Microbial Factories Workflow
Best Practices
-
Host Selection: Choose a host organism with well-characterized genetics, fast growth, and compatibility with the target pathway. For example, E. coli is favored for rapid prototyping, while yeast is preferred for complex eukaryotic pathways.
-
Modular Pathway Design: Use standardized genetic parts to assemble pathways, enabling easy swapping and tuning of enzymes.
-
Metabolic Balancing: Avoid accumulation of toxic intermediates by balancing enzyme expression levels and cofactor availability.
-
Use of Computational Tools: Employ metabolic models and flux analysis to predict pathway bottlenecks and optimize yields before experimental implementation.
-
Iterative Design-Build-Test-Learn Cycle: Continuously refine the microbial factory through cycles of genetic modification, phenotypic testing, and data-driven learning.
Example 1: Engineering E. coli for 1,4-Butanediol (BDO) Production
1,4-Butanediol is an important industrial chemical used in plastics and solvents. Traditionally produced from petroleum, synthetic biology offers a sustainable alternative.
-
Pathway Introduction: Genes from multiple organisms encoding enzymes for converting succinate to BDO were introduced into E. coli.
-
Optimization: Promoter strengths were tuned to balance enzyme expression, and competing pathways were knocked out to increase precursor availability.
-
Outcome: Achieved titers exceeding 100 g/L in fed-batch fermentation, demonstrating commercial viability.
Mind Map: BDO Production in E. coli
Example 2: Yeast Engineering for Artemisinic Acid Production
Artemisinic acid is a precursor to artemisinin, an antimalarial drug. Engineering Saccharomyces cerevisiae to produce artemisinic acid has enabled scalable, cost-effective production.
-
Heterologous Pathway: Plant-derived genes for the mevalonate pathway and artemisinic acid synthesis were introduced.
-
Metabolic Engineering: Overexpression of rate-limiting enzymes and elimination of competing pathways improved flux.
-
Scale-Up: Optimized fermentation conditions led to high titers suitable for industrial production.
Mind Map: Artemisinic Acid Production in Yeast
Practical Tips for Bioengineers
- Start with a well-characterized chassis organism to reduce unpredictability.
- Use modular cloning systems (e.g., Golden Gate) to rapidly assemble and test pathway variants.
- Incorporate biosensors to monitor intermediate metabolites in real-time.
- Leverage machine learning models trained on experimental data to guide pathway optimization.
- Collaborate closely with fermentation engineers to ensure lab-scale designs translate well to industrial bioreactors.
Summary
Engineering microbial factories is a multidisciplinary effort combining genetic engineering, metabolic modeling, and process optimization. By following best practices and learning from successful examples like BDO-producing E. coli and artemisinic acid-producing yeast, engineers can design sustainable systems that replace traditional chemical manufacturing with greener, biologically-driven processes.
11.2 Synthetic Biology Approaches to Disease Diagnostics
Synthetic biology has revolutionized the field of disease diagnostics by enabling the design and construction of highly specific, sensitive, and programmable biological systems. These systems can detect biomarkers, pathogens, or physiological changes with unprecedented precision, often integrating sensing, signal processing, and reporting functions within living cells or cell-free platforms.
Key Concepts in Synthetic Biology Diagnostics
- Biosensors: Engineered biological components that detect specific molecules or environmental conditions.
- Genetic Circuits: Synthetic networks that process input signals and produce measurable outputs.
- Cell-Free Systems: In vitro platforms that perform biological reactions without living cells, enhancing safety and modularity.
- Programmability: Ability to customize diagnostic systems for different targets and contexts.
Mind Map: Synthetic Biology Diagnostic Components
Example 1: CRISPR-Based Diagnostics (SHERLOCK and DETECTR)
CRISPR technology has been adapted for rapid, sensitive detection of nucleic acids from pathogens or disease markers.
- SHERLOCK (Specific High-sensitivity Enzymatic Reporter unLOCKing): Utilizes Cas13a enzyme to detect RNA sequences. Upon target recognition, Cas13a cleaves reporter RNA, producing a fluorescent signal.
- DETECTR: Employs Cas12a to detect DNA targets, triggering collateral cleavage of a reporter molecule.
Best Practice: Integrate isothermal amplification (e.g., RPA or LAMP) upstream to enhance sensitivity without complex thermal cycling.
Practical Example: Rapid detection of SARS-CoV-2 RNA from patient samples within 30-60 minutes using a paper-based lateral flow assay.
Mind Map: CRISPR-Based Diagnostic Workflow
Example 2: Whole-Cell Biosensors for Metabolite Detection
Engineered bacteria can be programmed to detect disease-related metabolites or toxins and produce a measurable output.
- Case Study: E. coli engineered to detect elevated levels of phenylalanine for phenylketonuria (PKU) monitoring.
- Mechanism: A genetic circuit senses phenylalanine concentration and triggers expression of a fluorescent protein.
Best Practice: Use modular promoters and ribosome binding sites to fine-tune sensitivity and dynamic range.
Practical Example: A wearable biosensor patch containing engineered microbes that change color in response to sweat biomarkers.
Mind Map: Whole-Cell Biosensor Design
Example 3: Cell-Free Synthetic Biology Diagnostics
Cell-free systems leverage the transcription-translation machinery extracted from cells to perform diagnostics without living organisms.
- Advantages: Reduced biosafety concerns, rapid prototyping, and easy customization.
- Example: Paper-based cell-free sensors that detect Zika virus RNA by producing a visible color change.
Best Practice: Optimize reaction conditions and lyophilization methods for stability and shelf-life.
Practical Example: A portable, low-cost diagnostic kit for field detection of infectious diseases in resource-limited settings.
Mind Map: Cell-Free Diagnostic Platform
Integration and Future Directions
- Combining synthetic biology diagnostics with microfluidics and electronics for point-of-care devices.
- Developing multiplexed systems capable of detecting multiple disease markers simultaneously.
- Leveraging machine learning to design more efficient genetic circuits and improve diagnostic accuracy.
Summary
Synthetic biology approaches to disease diagnostics offer transformative potential through modular, programmable, and highly sensitive systems. By integrating biosensors, genetic circuits, and innovative platforms such as CRISPR-based tools, whole-cell biosensors, and cell-free systems, engineers can develop next-generation diagnostic devices tailored for rapid, accurate, and accessible healthcare solutions.
11.3 Best Practice: Collaborative Design and Iterative Testing
Collaborative design and iterative testing are foundational best practices in synthetic biology systems engineering. These approaches enable multidisciplinary teams—comprising bioengineers, systems engineers, computational biologists, and applied scientists—to co-develop robust, scalable, and efficient synthetic biology solutions. By integrating diverse expertise and continuously refining designs through iterative cycles, teams can accelerate development, reduce errors, and optimize system performance.
Why Collaborative Design?
- Diverse Expertise: Synthetic biology spans molecular biology, engineering, computer science, and more. Collaboration ensures all perspectives are considered.
- Shared Knowledge: Facilitates knowledge transfer and reduces silos.
- Problem Solving: Complex problems benefit from multiple viewpoints.
- Resource Optimization: Shared tools, data, and infrastructure improve efficiency.
Why Iterative Testing?
- Incremental Improvement: Small, manageable changes reduce risk.
- Rapid Feedback: Early detection of design flaws.
- Data-Driven Decisions: Empirical results guide next steps.
- Adaptability: Allows pivoting based on experimental outcomes.
Mind Map: Collaborative Design and Iterative Testing Workflow
Practical Example: Engineering a Synthetic Probiotic for Gut Health
Scenario: A team aims to engineer a probiotic bacterium that senses inflammation markers in the gut and produces an anti-inflammatory compound.
Collaborative Design:
- Bioengineers: Design genetic circuits to detect inflammation signals.
- Computational Biologists: Model circuit dynamics and predict behavior.
- Systems Engineers: Develop control strategies for stable gene expression.
- Applied Scientists: Plan experimental validation and in vivo testing.
Iterative Testing Cycle:
- Design: Create a modular genetic circuit with sensor, actuator, and reporter modules.
- Build: Assemble DNA constructs using Golden Gate cloning.
- Test: Measure sensor sensitivity and actuator output in vitro.
- Analyze: Compare experimental data with model predictions; identify discrepancies.
- Iterate: Modify promoter strengths or ribosome binding sites to optimize response.
- Repeat: Continue cycles until desired performance is achieved.
Mind Map: Example Iterative Testing Cycle for Synthetic Probiotic
Tips for Effective Collaborative Design and Iterative Testing
- Use Collaborative Platforms: Tools like Benchling, GitHub, or Jupyter Notebooks enable real-time sharing and version control.
- Establish Clear Communication: Regular meetings, shared documentation, and defined roles prevent misunderstandings.
- Adopt Standardized Parts and Protocols: Facilitates reproducibility and modularity.
- Leverage Automation: Use robotic platforms for high-throughput testing to accelerate iteration.
- Incorporate Computational Models Early: Predictive modeling guides design choices and reduces trial-and-error.
- Document Every Iteration: Maintain detailed records of design changes, test results, and analyses.
Additional Example: Collaborative Development of a Biosensor for Heavy Metal Detection
- Initial Design: Computational biologists model metal-binding protein dynamics.
- Build: Bioengineers assemble sensor circuits with fluorescent reporters.
- Test: Systems engineers develop microfluidic platforms for rapid screening.
- Iterate: Based on test results, teams optimize sensor sensitivity and specificity.
This collaborative and iterative approach led to a biosensor with improved detection limits and robustness, demonstrating the power of integrated teamwork and continuous refinement.
In summary, embracing collaborative design and iterative testing empowers synthetic biology engineers to tackle complex challenges effectively. By fostering cross-disciplinary cooperation and continuously refining systems based on empirical data, teams can deliver innovative, reliable, and scalable synthetic biology solutions.
11.4 Example: Development of a Synthetic Probiotic for Gut Health
Synthetic probiotics represent a cutting-edge application of synthetic biology, aiming to engineer microorganisms that can beneficially modulate the gut microbiome, enhance host health, and treat or prevent diseases. This section explores the design, engineering, and practical considerations involved in developing a synthetic probiotic.
Overview of Synthetic Probiotics
- Engineered microbes designed to perform specific functions in the gastrointestinal tract.
- Goals include pathogen inhibition, metabolite production, immune modulation, and gut barrier enhancement.
Mind Map: Key Components in Synthetic Probiotic Development
Step 1: Host Selection
Choosing a suitable microbial chassis is critical. Common probiotic strains such as Lactobacillus and Bifidobacterium are preferred due to their established safety profiles and ability to colonize the gut.
Example: Engineering Lactobacillus reuteri for enhanced mucosal adhesion.
Step 2: Genetic Circuit Design
The synthetic probiotic must sense relevant gut environmental signals and respond appropriately.
- Sensing Module: Detect molecules like inflammation markers (e.g., nitric oxide), pH changes, or pathogen-associated molecules.
- Response Module: Produce anti-inflammatory cytokines, antimicrobial peptides, or enzymes.
- Control Systems: Incorporate feedback loops to avoid overproduction and include kill switches for safety.
Example: A genetic toggle switch that activates production of IL-10 (an anti-inflammatory cytokine) only when inflammation markers are detected.
Mind Map: Genetic Circuit Design Example
Step 3: Metabolic Engineering
Enhancing the probiotic’s metabolic pathways to produce beneficial compounds or inhibit pathogens.
Example: Engineering Bifidobacterium to overproduce short-chain fatty acids (SCFAs) like butyrate, which support gut epithelial health.
Step 4: Delivery and Stability
Ensuring the synthetic probiotic survives the acidic stomach environment and reaches the intestines.
- Microencapsulation with acid-resistant polymers.
- Engineering acid tolerance genes.
Example: Encapsulating engineered Lactobacillus in alginate beads for oral delivery.
Step 5: Safety and Containment
Implementing genetic safeguards to prevent uncontrolled proliferation or horizontal gene transfer.
- Auxotrophic strains requiring supplemented nutrients.
- Kill switches triggered by environmental cues outside the gut.
Example: A kill switch activated by oxygen exposure to prevent survival outside the anaerobic gut.
Integrated Practical Example: Engineering a Synthetic Probiotic to Combat Clostridioides difficile Infection
- Host: Lactobacillus casei chosen for gut colonization.
- Sensing: Genetic circuit senses C. difficile toxin presence.
- Response: Produces bacteriocins specifically targeting C. difficile.
- Safety: Kill switch activated if bacteria leave the gut environment.
- Delivery: Encapsulation in acid-resistant capsules.
Mind Map: Case Study Workflow
Summary of Best Practices
- Use well-characterized, safe microbial hosts.
- Design modular, tightly controlled genetic circuits.
- Incorporate multiple safety layers (kill switches, auxotrophy).
- Validate function in physiologically relevant models.
- Consider regulatory and ethical implications early.
By integrating engineering principles with biological insights, synthetic probiotics can be rationally designed to improve gut health with precision and safety. This example underscores the importance of a systems-level approach combining host selection, circuit design, metabolic engineering, and safety mechanisms.
11.5 Lessons Learned and Future Directions
Synthetic biology systems engineering has rapidly evolved into a multidisciplinary field that combines biology, engineering, and computational sciences. Reflecting on the case studies and practical examples discussed, several key lessons emerge that can guide future efforts and innovations.
Lessons Learned
-
Interdisciplinary Collaboration is Essential
- Successful synthetic biology projects require seamless collaboration between molecular biologists, bioengineers, computational modelers, and systems engineers.
- Example: The development of synthetic probiotics for gut health involved microbiologists, immunologists, and engineers working together to design, test, and optimize the system.
-
Iterative Design and Testing Accelerate Progress
- Employing iterative cycles of design-build-test-learn (DBTL) is critical for refining genetic circuits and metabolic pathways.
- Example: The microbial factories for sustainable chemical production improved yields significantly by iterative pathway balancing and adaptive laboratory evolution.
-
Standardization and Modularization Reduce Complexity
- Using standardized biological parts (e.g., BioBricks) and modular design principles simplifies assembly and troubleshooting.
- Example: Biosensor circuits designed with modular promoters and reporters enabled rapid swapping and optimization of components.
-
Computational Modeling Enhances Predictability
- Integrating computational models with experimental data helps predict system behavior and guides design decisions.
- Example: Simulating synthetic metabolic pathways prior to wet-lab implementation saved time and resources.
-
Automation and High-Throughput Screening are Game Changers
- Automation platforms and microfluidics enable rapid prototyping and screening of large genetic variant libraries.
- Example: High-throughput screening of genetic variants using microfluidic droplets accelerated identification of high-performing strains.
-
Ethical and Safety Considerations Must be Integrated Early
- Proactively addressing biosafety, biosecurity, and ethical concerns ensures responsible innovation.
- Example: Risk assessments and containment strategies were integral in the release planning of engineered organisms.
Future Directions
- Mind Map: Emerging Trends in Synthetic Biology Systems Engineering
-
Example: AI-Driven Design of Genetic Circuits
- Machine learning algorithms trained on large datasets of genetic parts can predict promoter strength, ribosome binding site efficiency, and circuit behavior, enabling more reliable designs.
-
Mind Map: Challenges and Opportunities Ahead
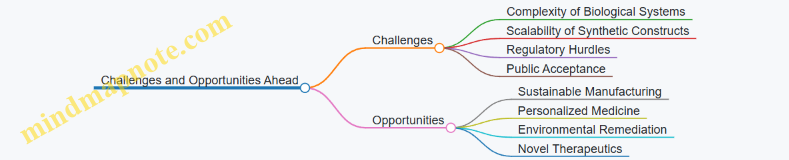
-
Example: Cell-Free Synthetic Biology for Rapid Response
- Cell-free systems allow for on-demand synthesis of proteins or biosensors without living cells, useful in diagnostics and emergency biodefense.
-
Vision: Towards Fully Programmable Synthetic Organisms
- Future synthetic biology aims to create organisms with fully programmable genomes that can dynamically adapt to environmental cues, self-repair, and perform complex tasks.
Summary Mind Map: Key Takeaways and Future Outlook
By embracing these lessons and exploring emerging technologies, bioengineers and systems engineers can drive synthetic biology towards impactful real-world applications that address global challenges in health, environment, and industry.
12. Future Perspectives and Emerging Technologies
12.1 Advances in Synthetic Genomics and Minimal Cells
Synthetic genomics and minimal cells represent some of the most groundbreaking frontiers in synthetic biology, offering unprecedented control over biological systems by designing and constructing entire genomes from scratch or reducing existing genomes to their essential components. This section explores the latest advances, practical examples, and engineering best practices in this exciting domain.
What is Synthetic Genomics?
Synthetic genomics involves the design, synthesis, and assembly of entire genomes, often from chemically synthesized DNA fragments. Unlike traditional genetic engineering that modifies individual genes, synthetic genomics enables the creation of entirely new organisms or reprogramming existing ones at the genome scale.
What are Minimal Cells?
Minimal cells are engineered organisms with genomes stripped down to the smallest set of genes necessary for life under specific conditions. These cells serve as simplified chassis for synthetic biology applications, reducing complexity and increasing predictability.
Mind Map: Overview of Synthetic Genomics and Minimal Cells
Key Advances in Synthetic Genomics
-
De Novo Genome Synthesis:
- The synthesis of the first bacterial genome, Mycoplasma mycoides JCVI-syn1.0, by the J. Craig Venter Institute marked a milestone. The genome (~1.08 Mbp) was chemically synthesized and transplanted into a recipient cell, creating a self-replicating synthetic organism.
-
Genome Minimization:
- Researchers have systematically reduced genomes to identify essential genes, culminating in the creation of Mycoplasma mycoides JCVI-syn3.0, with only 473 genes, the smallest genome of any free-living organism known.
-
Modular Genome Design:
- Advances allow genomes to be designed in modular segments, facilitating easier assembly, debugging, and functional replacement.
-
Improved DNA Assembly Techniques:
- Yeast-based homologous recombination enables assembly of large DNA constructs (>1 Mbp) with high fidelity.
-
Genome Transplantation:
- Transferring synthetic genomes into recipient cells to reboot cellular functions has become more reliable, enabling creation of synthetic life forms.
Mind Map: Workflow for Creating a Minimal Cell
Practical Example: Constructing a Minimal Cell for Bioproduction
Context: A bioengineer aims to create a minimal bacterial chassis optimized for producing a high-value pharmaceutical compound.
Step-by-step approach:
-
Identify essential genes: Use transposon sequencing data from E. coli to define a minimal gene set required for growth in defined media.
-
Design genome: Remove genes related to unnecessary metabolic pathways and mobile elements. Add synthetic operons encoding the pharmaceutical biosynthetic pathway.
-
Synthesize and assemble: Divide the designed genome into ~100 kb segments synthesized chemically and assembled using yeast homologous recombination.
-
Genome transplantation: Transfer the synthetic genome into a genome-free recipient cell (e.g., Mycoplasma species).
-
Test and optimize: Validate growth and production levels; iterate design to improve yield and stability.
Best Practice: Maintain detailed documentation and version control of genome designs using standards like SBOL (Synthetic Biology Open Language) to facilitate reproducibility and collaboration.
Challenges and Engineering Considerations
-
Genome Complexity: Even minimal genomes contain hundreds of genes with complex interactions, requiring sophisticated computational models to predict viability.
-
Error Rates in DNA Synthesis: Large-scale synthesis can introduce mutations; rigorous quality control and sequencing are essential.
-
Functional Unknowns: Many genes in minimal genomes have unknown functions, complicating design decisions.
-
Ethical and Safety Concerns: Creating synthetic life raises biosafety and biosecurity issues, necessitating compliance with regulatory frameworks.
Summary
Synthetic genomics and minimal cells empower engineers to build highly controlled biological systems with reduced complexity and enhanced functionality. By integrating genome design, advanced DNA assembly, and transplantation techniques, bioengineers can create tailor-made chassis for diverse applications ranging from pharmaceuticals to environmental biosensing. Embracing best practices in design documentation, validation, and ethical considerations will be critical to advancing this transformative field.
12.2 Integration of AI and Machine Learning in Synthetic Biology Design
Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing synthetic biology by enabling the design, optimization, and prediction of complex biological systems with unprecedented speed and accuracy. This section explores how AI/ML techniques are integrated into synthetic biology workflows, highlighting best practices and practical examples.
Why AI and ML in Synthetic Biology?
- Biological systems are inherently complex and nonlinear.
- Traditional trial-and-error approaches are time-consuming and costly.
- AI/ML can extract patterns from large datasets, enabling predictive modeling and rational design.
Key Applications of AI/ML in Synthetic Biology
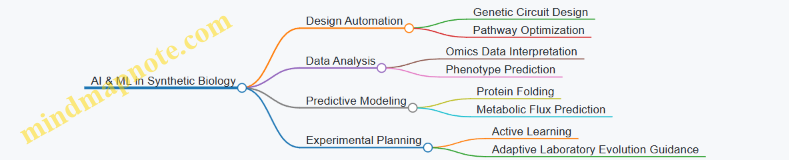
Best Practices for Integrating AI/ML
-
Data Quality and Quantity
- Ensure high-quality, standardized datasets.
- Use data augmentation where possible.
-
Feature Engineering
- Extract meaningful biological features (e.g., promoter strength, codon usage).
- Use domain knowledge to guide feature selection.
-
Model Selection and Validation
- Start with interpretable models (e.g., decision trees) before moving to complex ones (e.g., deep learning).
- Use cross-validation and independent test sets.
-
Iterative Design Cycle
- Combine AI predictions with experimental feedback.
- Continuously update models with new data.
Example 1: AI-Driven Genetic Circuit Design
Scenario: Designing a genetic toggle switch with optimized switching speed and stability.
- Approach: Use a supervised ML model trained on experimental data of toggle switches with different promoter and repressor combinations.
- Process:
- Collect data on circuit performance metrics.
- Extract features such as promoter strength, repressor binding affinity.
- Train a random forest model to predict switching speed.
- Use the model to suggest new promoter-repressor pairs.
Example 2: Machine Learning for Metabolic Pathway Optimization
Scenario: Enhancing biofuel production in engineered microbes.
- Approach: Use reinforcement learning (RL) to optimize gene expression levels for pathway enzymes.
- Process:
- Define state space as gene expression profiles.
- Define reward as biofuel yield.
- Use RL agent to iteratively suggest expression adjustments.
- Validate predictions experimentally and update the model.
Example 3: Protein Engineering Using Deep Learning
Scenario: Designing enzymes with improved catalytic efficiency.
- Approach: Use deep generative models (e.g., variational autoencoders) to generate novel protein sequences.
- Process:
- Train model on known enzyme sequences.
- Generate candidate sequences.
- Use ML classifiers to predict stability and activity.
- Select top candidates for synthesis and testing.
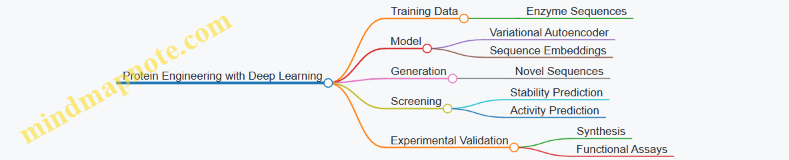
Challenges and Considerations
- Data Scarcity: Biological datasets can be limited; transfer learning and synthetic data can help.
- Interpretability: Complex models may be black boxes; combining with mechanistic models improves trust.
- Integration: Seamless integration with wet-lab workflows is essential for rapid iteration.
Summary
AI and ML are powerful enablers for synthetic biology, transforming design from intuition-driven to data-driven engineering. By following best practices and leveraging examples like genetic circuit design, metabolic optimization, and protein engineering, bioengineers can accelerate innovation and build more robust synthetic systems.
12.3 Best Practice: Leveraging Big Data for System Optimization
In synthetic biology, the integration of big data analytics has become a cornerstone for optimizing complex biological systems. Big data refers to the vast volumes of diverse and high-velocity biological information generated from high-throughput experiments, sequencing technologies, omics datasets, and real-time biosensor outputs. Effectively harnessing this data enables bioengineers and systems engineers to refine synthetic constructs, predict system behavior, and accelerate design-build-test-learn (DBTL) cycles.
Why Leverage Big Data?
- Complexity Management: Synthetic biology systems often involve multiple interacting components. Big data helps unravel these interactions.
- Predictive Modeling: Large datasets improve the accuracy of computational models.
- Optimization: Data-driven insights guide pathway tuning and host engineering.
- Scalability: Enables handling of large combinatorial libraries and screening results.
Key Data Types in Synthetic Biology
Best Practices for Leveraging Big Data
-
Data Integration and Standardization:
- Use standardized formats such as SBOL (Synthetic Biology Open Language) and ISA-Tab to ensure interoperability.
- Integrate multi-omics data for holistic system understanding.
-
Data Quality Control:
- Implement rigorous QC pipelines to filter noise and artifacts.
- Use replicates and controls to validate data reliability.
-
Advanced Analytics and Machine Learning:
- Employ unsupervised learning (e.g., clustering) to identify patterns.
- Use supervised models (e.g., random forests, neural networks) to predict system outputs.
-
Iterative DBTL Cycle Enhancement:
- Feed data insights back into design to refine genetic circuits or metabolic pathways.
-
Visualization and Interpretation:
- Use interactive dashboards and network graphs to explore data.
Mind Map: Best Practices Workflow
Example 1: Optimizing a Synthetic Metabolic Pathway Using Multi-Omics Data
A team engineered E. coli to produce a high-value biofuel precursor. They collected transcriptomic, proteomic, and metabolomic data from various pathway variants. By integrating these datasets, they identified bottlenecks where enzyme expression was suboptimal and metabolites accumulated undesirably.
-
Approach:
- Used RNA-seq data to quantify gene expression.
- Proteomics to measure enzyme abundance.
- Metabolomics to detect intermediate accumulation.
- Applied machine learning regression models to correlate expression levels with product yield.
-
Outcome:
- Targeted promoter engineering increased expression of limiting enzymes.
- Reduced toxic intermediate buildup.
- Achieved a 3-fold increase in biofuel precursor titer.
Example 2: Machine Learning-Driven Genetic Circuit Optimization
In designing a synthetic toggle switch, variability in gene expression caused inconsistent switching behavior. Researchers generated a large dataset of circuit variants with different ribosome binding site (RBS) strengths and promoter combinations.
-
Approach:
- High-throughput fluorescence measurements captured circuit output.
- Random forest models predicted circuit stability based on sequence features.
- Identified sequence combinations that minimized noise and improved switching fidelity.
-
Outcome:
- Selected optimized variants with robust bistability.
- Reduced experimental iterations by 60%.
Tools and Platforms for Big Data in Synthetic Biology
- Data Repositories: NCBI GEO, EMBL-EBI, SynBioHub
- Analysis Tools: Galaxy, Bioconductor, scikit-learn
- Visualization: Cytoscape, Plotly Dash, Jupyter Notebooks
Summary
Leveraging big data in synthetic biology systems engineering empowers practitioners to move beyond trial-and-error approaches. By systematically collecting, integrating, and analyzing large datasets, engineers can optimize biological systems with greater precision and speed. The best practices outlined here, supported by real-world examples and mind maps, provide a roadmap for effectively incorporating big data into your synthetic biology projects.
12.4 Emerging Tools: Cell-Free Systems and In Vitro Synthetic Biology
Cell-free systems and in vitro synthetic biology represent a transformative frontier in engineering biological functions outside living cells. These platforms enable rapid prototyping, precise control, and novel applications that are often challenging or impossible within cellular environments.
What are Cell-Free Systems?
Cell-free systems are biochemical reaction environments that contain the molecular machinery necessary for gene expression (transcription and translation) but lack living cells. They typically include extracts from organisms such as E. coli, wheat germ, or rabbit reticulocytes, combined with energy sources, nucleotides, amino acids, and cofactors.
Advantages:
- Rapid prototyping of genetic circuits without cloning or transformation.
- Reduced complexity and interference from cellular metabolism.
- Open systems allowing direct manipulation and measurement.
- Safer for handling toxic or synthetic components.
What is In Vitro Synthetic Biology?
In vitro synthetic biology extends beyond cell-free expression to reconstitute or engineer biological systems entirely outside living cells. This can include synthetic metabolic pathways, minimal cell mimics, or artificial organelles.
Mind Map: Overview of Cell-Free Systems and In Vitro Synthetic Biology
Best Practices for Using Cell-Free Systems
- Optimize Extract Preparation: Use high-quality, fresh extracts or commercially available kits to ensure reproducibility.
- Energy Regeneration Systems: Incorporate efficient ATP regeneration to prolong reaction times.
- Template Design: Use linear or plasmid DNA optimized for expression in cell-free systems.
- Reaction Conditions: Carefully control temperature, ion concentrations, and reaction volume.
- Modular Testing: Start with simple constructs and progressively increase complexity.
Example 1: Rapid Prototyping of a Genetic Oscillator
Context: Designing a synthetic genetic oscillator traditionally requires cloning, transformation, and cell culturing, which can take days.
Cell-Free Approach:
- Prepare an E. coli cell-free extract.
- Add DNA templates encoding oscillator components (e.g., repressors, promoters).
- Monitor fluorescence output in real-time to observe oscillations.
Outcome:
- Oscillatory behavior observed within hours.
- Parameters such as promoter strength and degradation tags can be rapidly tuned.
Mind Map: Genetic Oscillator Prototyping Workflow
Example 2: Cell-Free Biosensor for Heavy Metal Detection
Concept: Use a cell-free system to detect the presence of mercury ions by expressing a reporter gene under a metal-responsive promoter.
Implementation:
- Incorporate a mercury-sensitive transcription factor and promoter in the DNA template.
- Add the template to a cell-free reaction mix.
- Introduce water samples potentially containing mercury.
- Detect reporter expression (colorimetric or fluorescent) indicating mercury presence.
Advantages:
- Portable and field-deployable.
- No need for live cells, reducing biosafety concerns.
Mind Map: Cell-Free Biosensor Design
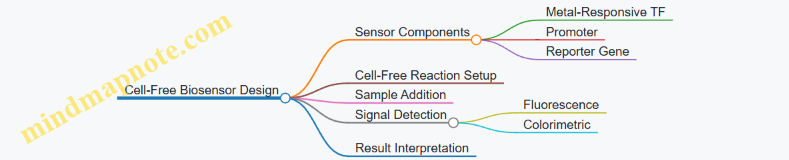
Emerging Trends and Integration
- Microfluidics: Combining cell-free systems with microfluidic devices enables high-throughput screening and multiplexed assays.
- Artificial Cells: Encapsulation of cell-free reactions inside lipid vesicles to mimic cellular compartments.
- On-Demand Biomanufacturing: Portable devices producing therapeutics or enzymes on-site using freeze-dried cell-free systems.
Summary
Cell-free systems and in vitro synthetic biology provide powerful platforms for synthetic biologists and engineers to design, test, and deploy biological functions rapidly and safely. By embracing these emerging tools, engineers can accelerate innovation cycles, reduce costs, and explore novel applications beyond the constraints of living cells.
12.5 Vision: Towards Fully Programmable Synthetic Organisms
The future of synthetic biology envisions the creation of fully programmable synthetic organisms—living systems designed from the ground up with precise, customizable functions. This transformative goal combines advances in genome synthesis, computational design, and systems engineering to enable organisms that can be tailored for diverse applications, from medicine to environmental remediation.
Key Concepts in Fully Programmable Synthetic Organisms
- Complete Genome Design: Synthesizing entire genomes with desired traits.
- Modular and Reconfigurable Systems: Organisms built with interchangeable genetic modules.
- Dynamic and Responsive Behavior: Organisms that adapt their functions in real-time.
- Safety and Containment: Built-in safeguards to prevent unintended consequences.
Mind Map: Components of Fully Programmable Synthetic Organisms
Example 1: Minimal Synthetic Cell – JCVI-syn3.0
One of the landmark achievements towards programmable organisms is the creation of JCVI-syn3.0 by the J. Craig Venter Institute. This bacterium has a minimal genome of 473 genes, synthesized and assembled from scratch, representing the smallest set of genes required for life.
- Best Practice Highlight: Iterative design-build-test cycles were used to identify essential genes and optimize genome functionality.
- Engineering Insight: The minimal genome provides a blank slate for adding custom modules without interference from redundant pathways.
Example 2: Programmable Logic in Synthetic Cells
Researchers have engineered synthetic cells equipped with genetic logic gates that respond to multiple environmental inputs, enabling programmable decision-making.
- Example: A synthetic cell that produces a therapeutic molecule only when two specific chemical signals are present.
- Best Practice: Modular circuit design allows easy swapping of input sensors and output effectors.
Mind Map: Workflow for Engineering a Fully Programmable Synthetic Organism
Emerging Technologies Accelerating Programmable Organisms
- Synthetic Genomes: Advances in long-read DNA synthesis and assembly enable construction of entire chromosomes.
- AI and Machine Learning: Algorithms predict gene interactions and optimize genome designs.
- Cell-Free Systems: Rapid prototyping of genetic circuits outside living cells accelerates design cycles.
- CRISPR-based Genome Editing: Precise, multiplexed editing facilitates dynamic reprogramming.
Practical Example: Designing a Programmable Microbial Factory
- Objective: Engineer a microbe to produce a biofuel only under nutrient-limited conditions.
- Design: Incorporate a nutrient sensor genetic circuit controlling the biofuel synthesis pathway.
- Implementation: Use modular genetic parts assembled via Golden Gate cloning.
- Testing: Simulate circuit behavior computationally, then validate in vivo.
- Optimization: Introduce feedback loops to stabilize production and minimize metabolic burden.
Summary
The vision of fully programmable synthetic organisms is becoming increasingly tangible through the integration of synthetic genomics, modular circuit design, computational modeling, and robust safety mechanisms. These organisms promise revolutionary advances across biotechnology, but require careful engineering and ethical considerations to realize their full potential safely and effectively.